
While using intersection checks with buffer zones only yields Boolean results (inside or outside), calculating the minimum distance from the reference geometry holds other advantages. For example, our customer can ask which of the houses are the farthest from those noisy areas. By querying the distances, we can easily answer that question. We can even order our results by the combined distances using ORDER BY at the end of our query. Let's remove the buffer-based query's layer, and modify the distance-based one's expression by right-clicking on it, and selecting Update Sql Layer:
WITH main_roads AS (
SELECT ST_Collect(geom) AS geom
FROM spatial.roads r
WHERE r.fclass LIKE 'primary%' OR r.fclass LIKE 'motorway%'),
industrial_areas AS (
SELECT ST_Collect(geom) AS geom
FROM spatial.landuse l
WHERE l.fclass = 'industrial' OR l.fclass = 'quarry')
SELECT h.*, ST_Distance(h.geom, mr.geom) AS dist_road,
ST_Distance(h.geom, ia.geom) AS dist_ind
FROM spatial.houses h, main_roads mr, industrial_areas ia
WHERE dist_road > 200 AND dist_ind > 500
ORDER BY dist_road + dist_ind DESC;
In theory, we are now asking PostgreSQL to evaluate the two distance checks, and return them to us in the dist_road and dist_ind columns. Then we simply use those columns to select only the correct houses, and order the results in descending order.
What happens if we run this query? It returns an error with the message "dist_road" does not exists. We tried to use a field which had not yet been calculated when PostgreSQL tried to call it. We simply cannot use computed fields in other queries on the same level. Let's modify our query a little bit, as follows:
WITH main_roads AS (
SELECT ST_Collect(geom) AS geom
FROM spatial.roads r
WHERE r.fclass LIKE 'primary%' OR r.fclass LIKE 'motorway%'),
industrial_areas AS (
SELECT ST_Collect(geom) AS geom
FROM spatial.landuse l
WHERE l.fclass = 'industrial' OR l.fclass = 'quarry')
SELECT h.*, ST_Distance(h.geom, mr.geom) AS dist_road,
ST_Distance(h.geom, ia.geom) AS dist_ind
FROM spatial.houses h, main_roads mr, industrial_areas ia
WHERE ST_Distance(h.geom, mr.geom) > 200 AND ST_Distance(h.geom,
ia.geom) > 500
ORDER BY ST_Distance(h.geom, mr.geom) + ST_Distance(h.geom,
ia.geom) DESC;
The new query works, although the distances are calculated three times, slowing down the execution, which is bad. On the other hand, we have the distance values, and our features are ordered based on their combined distances from noisy areas:
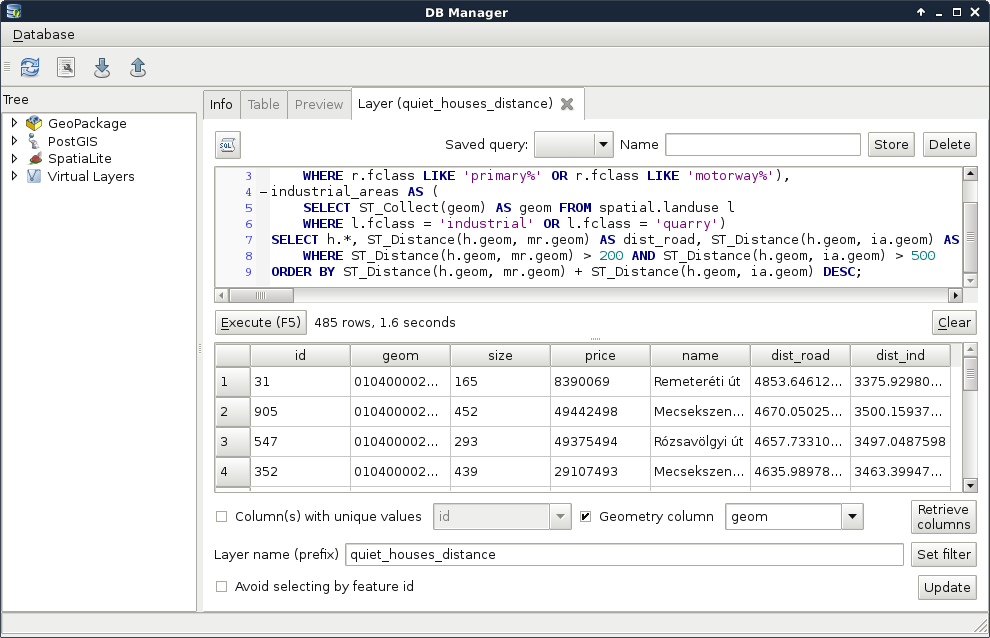
We should still do something about this query, as it is quite inconvenient to declare the same calculations multiple times. If we wish to change some of the distance columns, we would have to change them in three places. This is the case when a subquery proves useful. We can calculate the houses table with the distance columns as a new table called hwd (houses with distances). Then we can simply refer to the columns of that table in the other two occurrences:
WITH main_roads AS (
SELECT ST_Collect(geom) AS geom
FROM spatial.roads r
WHERE r.fclass LIKE 'primary%' OR r.fclass LIKE 'motorway%'),
industrial_areas AS (
SELECT ST_Collect(geom) AS geom
FROM spatial.landuse l
WHERE l.fclass = 'industrial' OR l.fclass = 'quarry')
SELECT * FROM
(SELECT h.*, ST_Distance(h.geom, mr.geom) AS dist_road,
ST_Distance(h.geom, ia.geom) AS dist_ind
FROM spatial.houses h, main_roads mr, industrial_areas ia) AS hwd
WHERE hwd.dist_road > 200 AND hwd.dist_ind > 500
ORDER BY hwd.dist_road + hwd.dist_ind DESC;
The calculation time is the same, as PostgreSQL has to query the distances for every house before it can query the relevant rows. Additionally, using subqueries makes the code harder to read and interpret. Luckily, PostgreSQL offers us an even better method for creating columns, which can be cross-referenced--lateral subqueries. By using the keyword LATERAL before a subquery, we only need to include the formulae for the dynamically calculated columns, and we can use them outside of the subquery.
Lateral subqueries can be added to the tables we select from, and, therefore, in the FROM clause. We only need to provide the computed columns and their formulae in the subquery as follows:
WITH main_roads AS (
SELECT ST_Collect(geom) AS geom FROM spatial.roads r
WHERE r.fclass LIKE 'primary%' OR r.fclass LIKE 'motorway%'),
industrial_areas AS (
SELECT ST_Collect(geom) AS geom FROM spatial.landuse l
WHERE l.fclass = 'industrial' OR l.fclass = 'quarry')
SELECT h.*, hwd.dist_road, hwd.dist_ind
FROM spatial.houses h, main_roads mr, industrial_areas ia,
LATERAL (SELECT ST_Distance(h.geom, mr.geom) AS dist_road,
ST_Distance(h.geom, ia.geom) AS dist_ind) AS hwd
WHERE hwd.dist_road > 200 AND hwd.dist_ind > 500
ORDER BY hwd.dist_road + hwd.dist_ind DESC;
With this query, we not only made the code more readable, but also increased its performance by almost 30%. As PostgreSQL could optimize our new lateral query better, we get similar performance as with the precise buffering technique, acquired the distances from the noisy areas, and ordered our features according to them. With this final optimization, there is no more doubt that distance calculations should be preferred over buffering in PostGIS for proximity analysis.