
The dataset we will be working with is a trails dataset that has linear extents for a set of trails in a park system. The data is the typical data that comes from the GIS world; as a flat shapefile, there are no explicit relational constructs in the data.
First, unzip the trails.zip file and use the command line to go into it, then load the data using the following command:
shp2pgsql -s 3734 -d -i -I -W LATIN1 -g the_geom trails chp02.trails | psql -U me -d postgis_cookbook
Looking at the linear data, we have some categories for the use type:
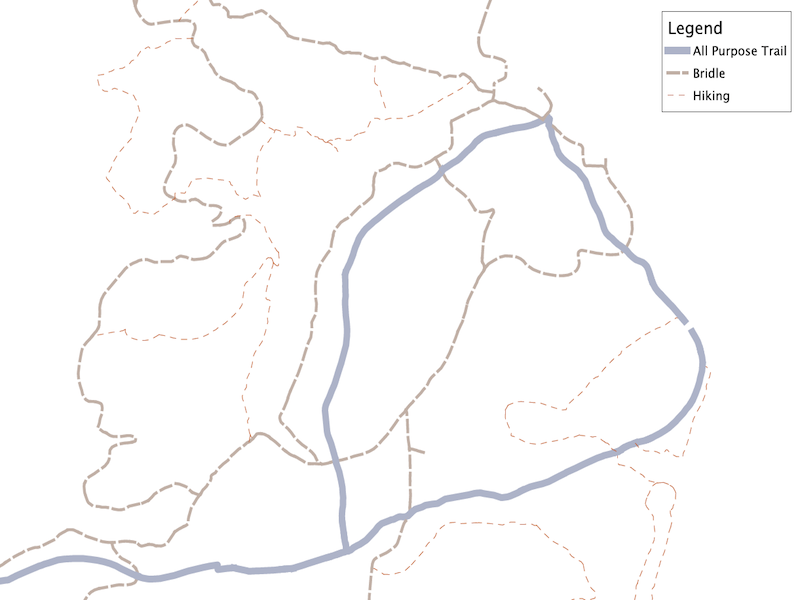
We want to retain this information as well as the name. Unfortunately, the label_name field is a messy field with a variety of related names concatenated with an ampersand (&), as shown in the following query:
SELECT DISTINCT label_name FROM chp02.trails WHERE label_name LIKE '%&%' LIMIT 10;
It will return the following output:

This is where the normalization of our table will begin.