
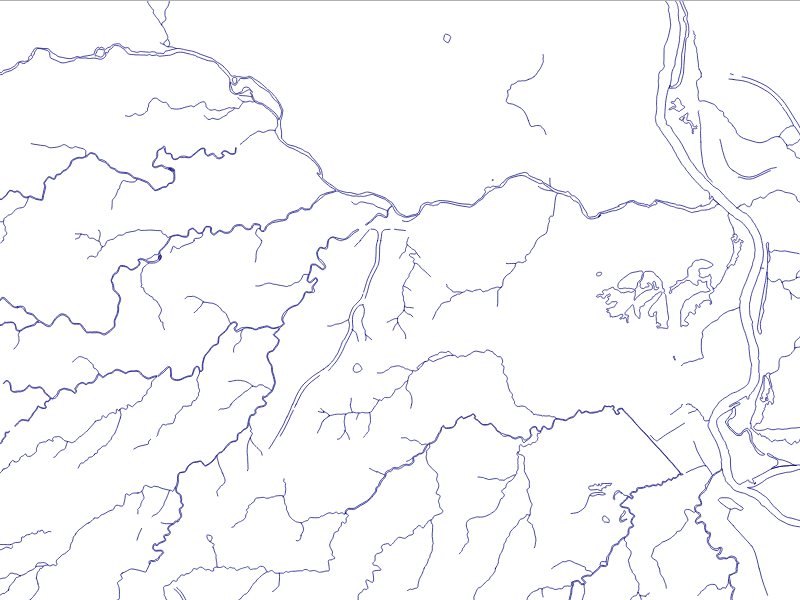
The data we will be using is hydrology data that has been modified from engineering blue lines (see the following screenshot), that is, hydrologic data that is very detailed and is meant to be used at scales approaching 1:600. The data in its original application aided, as breaklines, in detailed digital terrain modeling.
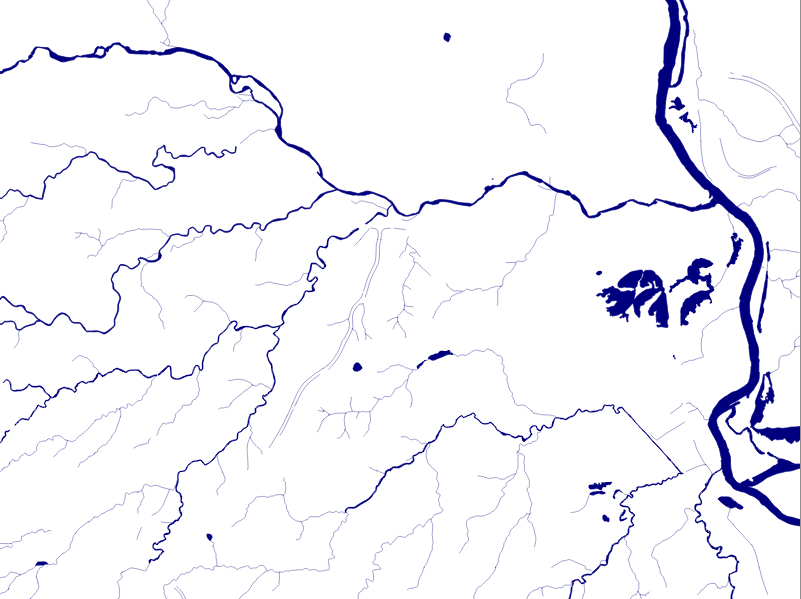
While useful in itself, the data was further manipulated, separating the linear features from area features, with additional polygonization of the area features, as shown in the following screenshot:
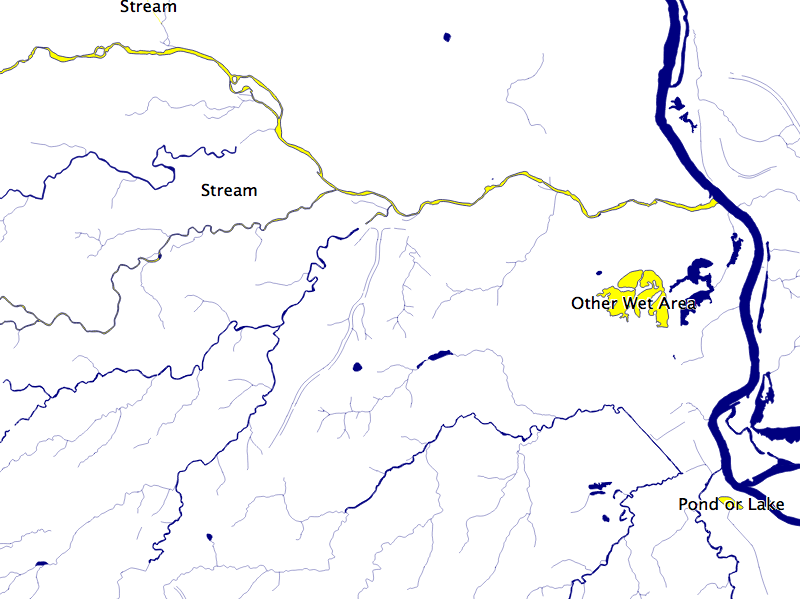
Finally, the data was classified into basic waterway categories, as follows:
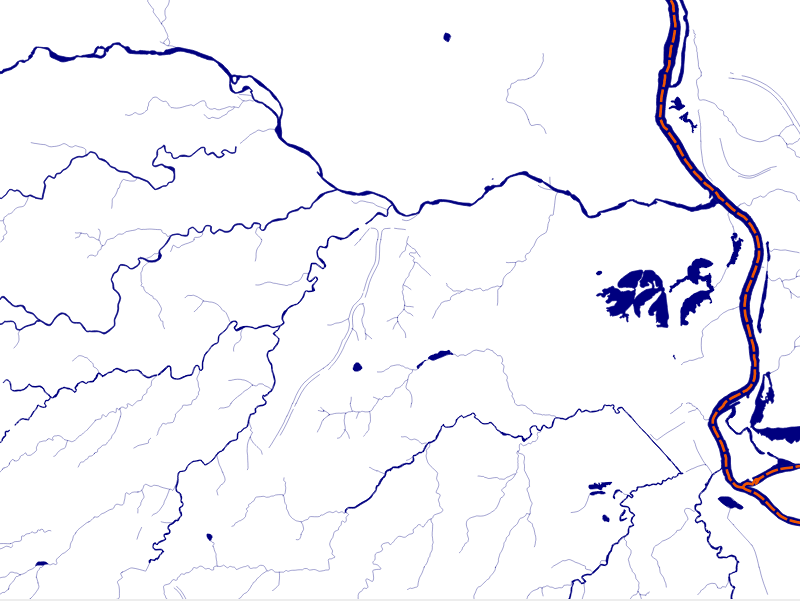
In addition, a process was undertaken to generate centerlines for polygon features such as streams, which are effectively linear features, as follows:
Hence, we have three separate but related datasets:
- cuyahoga_hydro_polygon
- cuyahoga_hydro_polyline
- cuyahoga_river_centerlines
Now, let us look at the structure of the tabular data. Unzip the hydrology file from the book repository and go to that directory. The ogrinfo utility can help us with this, as shown in the following command:
> ogrinfo cuyahoga_hydro_polygon.shp -al -so
The output is as follows:
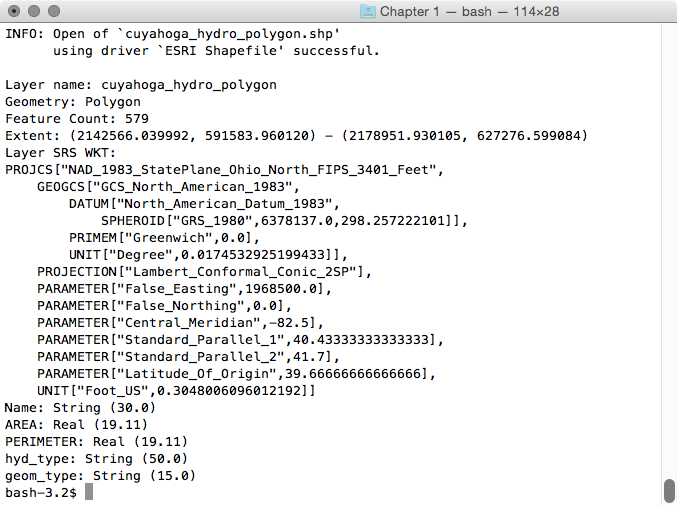
Executing this query on each of the shapefiles, we see the following fields that are common to all the shapefiles:
- name
- hyd_type
- geom_type
It is by understanding our common fields that we can apply inheritance to completely structure our data.