Table of Contents for
QGIS: Becoming a GIS Power User
 QGIS: Becoming a GIS Power User
Published by
Packt Publishing, 2017
QGIS: Becoming a GIS Power User
Published by
Packt Publishing, 2017
- Cover
- Table of Contents
- QGIS: Becoming a GIS Power User
- QGIS: Becoming a GIS Power User
- QGIS: Becoming a GIS Power User
- Credits
- Preface
- What you need for this learning path
- Who this learning path is for
- Reader feedback
- Customer support
- 1. Module 1
- 1. Getting Started with QGIS
- Running QGIS for the first time
- Introducing the QGIS user interface
- Finding help and reporting issues
- Summary
- 2. Viewing Spatial Data
- Dealing with coordinate reference systems
- Loading raster files
- Loading data from databases
- Loading data from OGC web services
- Styling raster layers
- Styling vector layers
- Loading background maps
- Dealing with project files
- Summary
- 3. Data Creation and Editing
- Working with feature selection tools
- Editing vector geometries
- Using measuring tools
- Editing attributes
- Reprojecting and converting vector and raster data
- Joining tabular data
- Using temporary scratch layers
- Checking for topological errors and fixing them
- Adding data to spatial databases
- Summary
- 4. Spatial Analysis
- Combining raster and vector data
- Vector and raster analysis with Processing
- Leveraging the power of spatial databases
- Summary
- 5. Creating Great Maps
- Labeling
- Designing print maps
- Presenting your maps online
- Summary
- 6. Extending QGIS with Python
- Getting to know the Python Console
- Creating custom geoprocessing scripts using Python
- Developing your first plugin
- Summary
- 2. Module 2
- 1. Exploring Places – from Concept to Interface
- Acquiring data for geospatial applications
- Visualizing GIS data
- The basemap
- Summary
- 2. Identifying the Best Places
- Raster analysis
- Publishing the results as a web application
- Summary
- 3. Discovering Physical Relationships
- Spatial join for a performant operational layer interaction
- The CartoDB platform
- Leaflet and an external API: CartoDB SQL
- Summary
- 4. Finding the Best Way to Get There
- OpenStreetMap data for topology
- Database importing and topological relationships
- Creating the travel time isochron polygons
- Generating the shortest paths for all students
- Web applications – creating safe corridors
- Summary
- 5. Demonstrating Change
- TopoJSON
- The D3 data visualization library
- Summary
- 6. Estimating Unknown Values
- Interpolated model values
- A dynamic web application – OpenLayers AJAX with Python and SpatiaLite
- Summary
- 7. Mapping for Enterprises and Communities
- The cartographic rendering of geospatial data – MBTiles and UTFGrid
- Interacting with Mapbox services
- Putting it all together
- Going further – local MBTiles hosting with TileStream
- Summary
- 3. Module 3
- 1. Data Input and Output
- Finding geospatial data on your computer
- Describing data sources
- Importing data from text files
- Importing KML/KMZ files
- Importing DXF/DWG files
- Opening a NetCDF file
- Saving a vector layer
- Saving a raster layer
- Reprojecting a layer
- Batch format conversion
- Batch reprojection
- Loading vector layers into SpatiaLite
- Loading vector layers into PostGIS
- 2. Data Management
- Joining layer data
- Cleaning up the attribute table
- Configuring relations
- Joining tables in databases
- Creating views in SpatiaLite
- Creating views in PostGIS
- Creating spatial indexes
- Georeferencing rasters
- Georeferencing vector layers
- Creating raster overviews (pyramids)
- Building virtual rasters (catalogs)
- 3. Common Data Preprocessing Steps
- Converting points to lines to polygons and back – QGIS
- Converting points to lines to polygons and back – SpatiaLite
- Converting points to lines to polygons and back – PostGIS
- Cropping rasters
- Clipping vectors
- Extracting vectors
- Converting rasters to vectors
- Converting vectors to rasters
- Building DateTime strings
- Geotagging photos
- 4. Data Exploration
- Listing unique values in a column
- Exploring numeric value distribution in a column
- Exploring spatiotemporal vector data using Time Manager
- Creating animations using Time Manager
- Designing time-dependent styles
- Loading BaseMaps with the QuickMapServices plugin
- Loading BaseMaps with the OpenLayers plugin
- Viewing geotagged photos
- 5. Classic Vector Analysis
- Selecting optimum sites
- Dasymetric mapping
- Calculating regional statistics
- Estimating density heatmaps
- Estimating values based on samples
- 6. Network Analysis
- Creating a simple routing network
- Calculating the shortest paths using the Road graph plugin
- Routing with one-way streets in the Road graph plugin
- Calculating the shortest paths with the QGIS network analysis library
- Routing point sequences
- Automating multiple route computation using batch processing
- Matching points to the nearest line
- Creating a routing network for pgRouting
- Visualizing the pgRouting results in QGIS
- Using the pgRoutingLayer plugin for convenience
- Getting network data from the OSM
- 7. Raster Analysis I
- Using the raster calculator
- Preparing elevation data
- Calculating a slope
- Calculating a hillshade layer
- Analyzing hydrology
- Calculating a topographic index
- Automating analysis tasks using the graphical modeler
- 8. Raster Analysis II
- Calculating NDVI
- Handling null values
- Setting extents with masks
- Sampling a raster layer
- Visualizing multispectral layers
- Modifying and reclassifying values in raster layers
- Performing supervised classification of raster layers
- 9. QGIS and the Web
- Using web services
- Using WFS and WFS-T
- Searching CSW
- Using WMS and WMS Tiles
- Using WCS
- Using GDAL
- Serving web maps with the QGIS server
- Scale-dependent rendering
- Hooking up web clients
- Managing GeoServer from QGIS
- 10. Cartography Tips
- Using Rule Based Rendering
- Handling transparencies
- Understanding the feature and layer blending modes
- Saving and loading styles
- Configuring data-defined labels
- Creating custom SVG graphics
- Making pretty graticules in any projection
- Making useful graticules in printed maps
- Creating a map series using Atlas
- 11. Extending QGIS
- Defining custom projections
- Working near the dateline
- Working offline
- Using the QspatiaLite plugin
- Adding plugins with Python dependencies
- Using the Python console
- Writing Processing algorithms
- Writing QGIS plugins
- Using external tools
- 12. Up and Coming
- Preparing LiDAR data
- Opening File Geodatabases with the OpenFileGDB driver
- Using Geopackages
- The PostGIS Topology Editor plugin
- The Topology Checker plugin
- GRASS Topology tools
- Hunting for bugs
- Reporting bugs
- Bibliography
- Index
We often get data in different formats and information spread over multiple files. Therefore, one important skill to know is how to join attribute data from different layers. Joining data is a way to combine data from multiple tables based on common values, such as IDs or categories.
This exercise shows you how to use the join functionality in Layer Properties to join geographic census tract data to tabular population data and how to save the results to a new file.
To follow this exercise, load the census tracts in census_wake2000.shp using Add Vector Layer (you can also drag and drop the shapefile from the file browser to QGIS) and population data in census_wake2000_pop.csv using Add Delimited Text Layer.
Tip
You can also load the .csv text file using Add Vector Layer, but this will load all data as text columns because the .csv file does not come with a .csvt file to specify data types. Instead, the Add Delimited Text Layer tool will scan the data and determine the most suitable data type for each column.
To join two layers, there has to be a column with values/IDs that both layers have in common. If we check the attribute tables of the two layers that we just loaded, we will see that both have the STFID field in common. So, to join the population data to the census tracts, use the following steps:
- Open the Layer Properties option of the
census_wake2000layer (for example, by double-clicking on the layer name in the Layers list) and go to Joins. - To set up a new join action, press the green + button in the lower-left corner of the dialog.
- The following screenshot shows the Add vector join dialog, which allows you to configure the join by selecting Join layer, which you want to use to join the census tracts and the columns containing the common values/IDs (Join field and Target field):
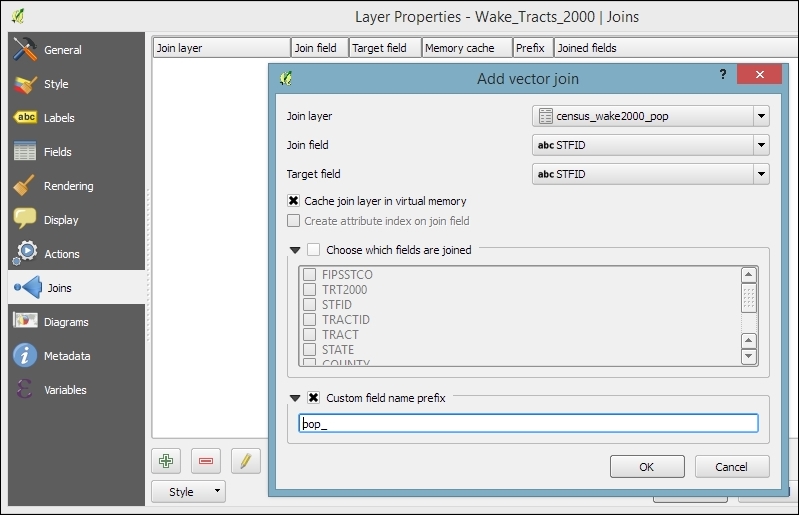
- When you press OK, the join definition will be added to the list of joins, as shown in the following screenshot.
- To verify that you set up the join correctly, close Layer Properties and open attribute table to see whether the population columns have been added and are filled with data.
Joins can be used to join vector layers and tabular layers from many different file and database sources, including (but not limited to) Shapefiles, PostGIS, CSV, Excel sheets, and more.
When two layers are joined, the attributes of Join layer are appended to the original layer's attribute table. If you want, you can use the Choose which fields are joined option to select which of the fields from the population layer should be joined to the census tracts. Otherwise, by default, all fields will be added. The number of features in the original layer is not changed. Whenever there is a match between the values in the join and the target field, the new attribute values will be filled; otherwise, there will be NULL values in the new columns.
By default, the names of the new columns are constructed from join layer name with underscore followed by join layer column name. For example, the STATE column of census_wake2000_pop becomes census_wake2000_pop_STATE. You can change this default behavior by enabling the Custom field name prefix option, as shown in the previous screenshot. With these settings, the STATE column becomes pop_STATE, which is considerably shorter and, thus, easier to handle.
The join that you've created now only exists in memory. None of the original files have been altered. However, it's possible to create a new file from the joined layers. To do this, just use Save as … from the Layer menu or Context menu. You can choose between a variety of data formats, including the ESRI shapefile, Mapinfo MIF, or GML.
Shapefiles are a very common choice as they are still the de facto standard GIS data exchange format, but if you are familiar with GIS data formats, you will have noticed that the names of the joined columns are too long for the 10 character-name length limit of the shapefile format. QGIS ensures that all columns in the exported shapefiles have unique names even after the names have been shortened to only 10 characters. To do this, QGIS adds incrementing numbers to the end of, otherwise, duplicate column names. If you save the join from this example as a shapefile, you will see that the column names are altered to census_w_1, census_w_2, and so on. Of course, these names are less than optimal to continue working with the data. As described in How it works... in this recipe, the names for the joined columns are a combination of joined layer name and column name. Therefore, we can use the following trick if we want to create a shapefile from the join: we can shorten the layer name. Just rename the layer in the layer list. You can even have a completely empty layer name! If you change the joined layer name to an empty string, the joined column names will be _STATE, _COUNTY, and so on instead of census_wake2000_pop_STATE and census_wake2000_pop_COUNTY. In any case, it is good practice to document your data and provide a description of the attribute table columns in the metadata.
In any case, it is very likely that you will want to clean up the attribute table of the new dataset, and this is exactly what we are going to do in the next exercise.