Table of Contents for
QGIS: Becoming a GIS Power User
 QGIS: Becoming a GIS Power User
Published by
Packt Publishing, 2017
QGIS: Becoming a GIS Power User
Published by
Packt Publishing, 2017
- Cover
- Table of Contents
- QGIS: Becoming a GIS Power User
- QGIS: Becoming a GIS Power User
- QGIS: Becoming a GIS Power User
- Credits
- Preface
- What you need for this learning path
- Who this learning path is for
- Reader feedback
- Customer support
- 1. Module 1
- 1. Getting Started with QGIS
- Running QGIS for the first time
- Introducing the QGIS user interface
- Finding help and reporting issues
- Summary
- 2. Viewing Spatial Data
- Dealing with coordinate reference systems
- Loading raster files
- Loading data from databases
- Loading data from OGC web services
- Styling raster layers
- Styling vector layers
- Loading background maps
- Dealing with project files
- Summary
- 3. Data Creation and Editing
- Working with feature selection tools
- Editing vector geometries
- Using measuring tools
- Editing attributes
- Reprojecting and converting vector and raster data
- Joining tabular data
- Using temporary scratch layers
- Checking for topological errors and fixing them
- Adding data to spatial databases
- Summary
- 4. Spatial Analysis
- Combining raster and vector data
- Vector and raster analysis with Processing
- Leveraging the power of spatial databases
- Summary
- 5. Creating Great Maps
- Labeling
- Designing print maps
- Presenting your maps online
- Summary
- 6. Extending QGIS with Python
- Getting to know the Python Console
- Creating custom geoprocessing scripts using Python
- Developing your first plugin
- Summary
- 2. Module 2
- 1. Exploring Places – from Concept to Interface
- Acquiring data for geospatial applications
- Visualizing GIS data
- The basemap
- Summary
- 2. Identifying the Best Places
- Raster analysis
- Publishing the results as a web application
- Summary
- 3. Discovering Physical Relationships
- Spatial join for a performant operational layer interaction
- The CartoDB platform
- Leaflet and an external API: CartoDB SQL
- Summary
- 4. Finding the Best Way to Get There
- OpenStreetMap data for topology
- Database importing and topological relationships
- Creating the travel time isochron polygons
- Generating the shortest paths for all students
- Web applications – creating safe corridors
- Summary
- 5. Demonstrating Change
- TopoJSON
- The D3 data visualization library
- Summary
- 6. Estimating Unknown Values
- Interpolated model values
- A dynamic web application – OpenLayers AJAX with Python and SpatiaLite
- Summary
- 7. Mapping for Enterprises and Communities
- The cartographic rendering of geospatial data – MBTiles and UTFGrid
- Interacting with Mapbox services
- Putting it all together
- Going further – local MBTiles hosting with TileStream
- Summary
- 3. Module 3
- 1. Data Input and Output
- Finding geospatial data on your computer
- Describing data sources
- Importing data from text files
- Importing KML/KMZ files
- Importing DXF/DWG files
- Opening a NetCDF file
- Saving a vector layer
- Saving a raster layer
- Reprojecting a layer
- Batch format conversion
- Batch reprojection
- Loading vector layers into SpatiaLite
- Loading vector layers into PostGIS
- 2. Data Management
- Joining layer data
- Cleaning up the attribute table
- Configuring relations
- Joining tables in databases
- Creating views in SpatiaLite
- Creating views in PostGIS
- Creating spatial indexes
- Georeferencing rasters
- Georeferencing vector layers
- Creating raster overviews (pyramids)
- Building virtual rasters (catalogs)
- 3. Common Data Preprocessing Steps
- Converting points to lines to polygons and back – QGIS
- Converting points to lines to polygons and back – SpatiaLite
- Converting points to lines to polygons and back – PostGIS
- Cropping rasters
- Clipping vectors
- Extracting vectors
- Converting rasters to vectors
- Converting vectors to rasters
- Building DateTime strings
- Geotagging photos
- 4. Data Exploration
- Listing unique values in a column
- Exploring numeric value distribution in a column
- Exploring spatiotemporal vector data using Time Manager
- Creating animations using Time Manager
- Designing time-dependent styles
- Loading BaseMaps with the QuickMapServices plugin
- Loading BaseMaps with the OpenLayers plugin
- Viewing geotagged photos
- 5. Classic Vector Analysis
- Selecting optimum sites
- Dasymetric mapping
- Calculating regional statistics
- Estimating density heatmaps
- Estimating values based on samples
- 6. Network Analysis
- Creating a simple routing network
- Calculating the shortest paths using the Road graph plugin
- Routing with one-way streets in the Road graph plugin
- Calculating the shortest paths with the QGIS network analysis library
- Routing point sequences
- Automating multiple route computation using batch processing
- Matching points to the nearest line
- Creating a routing network for pgRouting
- Visualizing the pgRouting results in QGIS
- Using the pgRoutingLayer plugin for convenience
- Getting network data from the OSM
- 7. Raster Analysis I
- Using the raster calculator
- Preparing elevation data
- Calculating a slope
- Calculating a hillshade layer
- Analyzing hydrology
- Calculating a topographic index
- Automating analysis tasks using the graphical modeler
- 8. Raster Analysis II
- Calculating NDVI
- Handling null values
- Setting extents with masks
- Sampling a raster layer
- Visualizing multispectral layers
- Modifying and reclassifying values in raster layers
- Performing supervised classification of raster layers
- 9. QGIS and the Web
- Using web services
- Using WFS and WFS-T
- Searching CSW
- Using WMS and WMS Tiles
- Using WCS
- Using GDAL
- Serving web maps with the QGIS server
- Scale-dependent rendering
- Hooking up web clients
- Managing GeoServer from QGIS
- 10. Cartography Tips
- Using Rule Based Rendering
- Handling transparencies
- Understanding the feature and layer blending modes
- Saving and loading styles
- Configuring data-defined labels
- Creating custom SVG graphics
- Making pretty graticules in any projection
- Making useful graticules in printed maps
- Creating a map series using Atlas
- 11. Extending QGIS
- Defining custom projections
- Working near the dateline
- Working offline
- Using the QspatiaLite plugin
- Adding plugins with Python dependencies
- Using the Python console
- Writing Processing algorithms
- Writing QGIS plugins
- Using external tools
- 12. Up and Coming
- Preparing LiDAR data
- Opening File Geodatabases with the OpenFileGDB driver
- Using Geopackages
- The PostGIS Topology Editor plugin
- The Topology Checker plugin
- GRASS Topology tools
- Hunting for bugs
- Reporting bugs
- Bibliography
- Index
In this chapter, we will encounter the visualization and analytical techniques of exploring the relationships between place and time and between the places themselves.
The data derived from temporal and spatial relationships is useful in learning more about the geographic objects that we are studying—from hydrological features to population units. This is particularly true if the data is not directly available for the geographic object of interest: either for a particular variable, for a particular time, or at all.
In this example, we will look at the demographic data from the US Census applied to the State House Districts, for election purposes. Elected officials often want to understand how the neighborhoods in their jurisdictions are changing demographically. Are their constituents becoming younger or more affluent? Is unemployment rising? Demographic factors can be used to predict the issues that will be of interest to potential voters and thus may be used for promotional purposes by the campaigns.
In this chapter, we will cover the following topics:
- Using spatial relationships to leverage data
- Preparing data relationships for static production
- Vector simplification
- Using TopoJSON for vector data size reduction and performance
- D3 data visualization for API
- Animated time series maps
So far, we've looked at the methods of analysis that take advantage of the continuity of the gridded raster data or of the geometric formality of the topological network data.
For ordinary vector data, we need a more abstract method of analysis, which is establishing the formal relationships based on the conditions in the spatial arrangement of geometric objects.
For most of this section, we will gather and prepare the data in ways that will be familiar. When we get to preparing the boundary data, which is leveraging the State House Districts data from the census tracts, we will be covering new territory—using the spatial relationships to construct the data for a given geographic unit.
First, we will gather data from the sections of the US Census website. Though this workflow will be particularly useful for those working with the US demographic data, it will also be instructive for those dealing with any kind of data linked to geographic boundaries.
To begin with, obtain the boundary data with a unique identifier. After doing this, obtain the tabular data with the same unique identifier and then join on the identifier.
Download 2014 TIGER/Line Census Tracts and State Congressional Districts from the US Census at https://www.census.gov/geo/maps-data/data/tiger-line.html.
- Select 2014 from the tabs displayed; this should be the default year.
- Click on the Download accordion heading and click on Web interface.
- Under Select a layer type, select Census Tracts and click on submit; under Census Tract, select Pennsylvania and click on Download.
- Use the back arrow if necessary to select State Legislative Districts, and click on submit; select Pennsylvania for State Legislative Districts - Lower Chamber (current) and click on Download.
- Move both the directories to
c5/data/originaland extract them.
Many different demographic datasets are available on the American FactFinder site. These complement the TIGER/Line data mentioned before with the attribute data for the TIGER/Line geographic boundaries. The main trick is to select the matching geographic boundary level and extent between the attribute and the geographic boundary data. Perform the following steps:
- Go to the US Census American FactFinder site at http://factfinder.census.gov.
- Click on the ADVANCED SEARCH tab.
- In the topic or table name input, enter
Whiteand select B02008: WHITE ALONE OR IN COMBINATION WITH ONE OR MORE RACES in the suggested options. Then, click on GO. - From the sidebar, in the Select a geographic type: dropdown in the Geographies section, select Census Tract - 140.
- Under select a state, select Pennsylvania; under Select a county, select Philadelphia; and under Select one or more geographic areas and click Add to Your Selections:, select All Census Tracts within Philadelphia County, Pennsylvania. Then, click on ADD TO YOUR SELECTIONS.
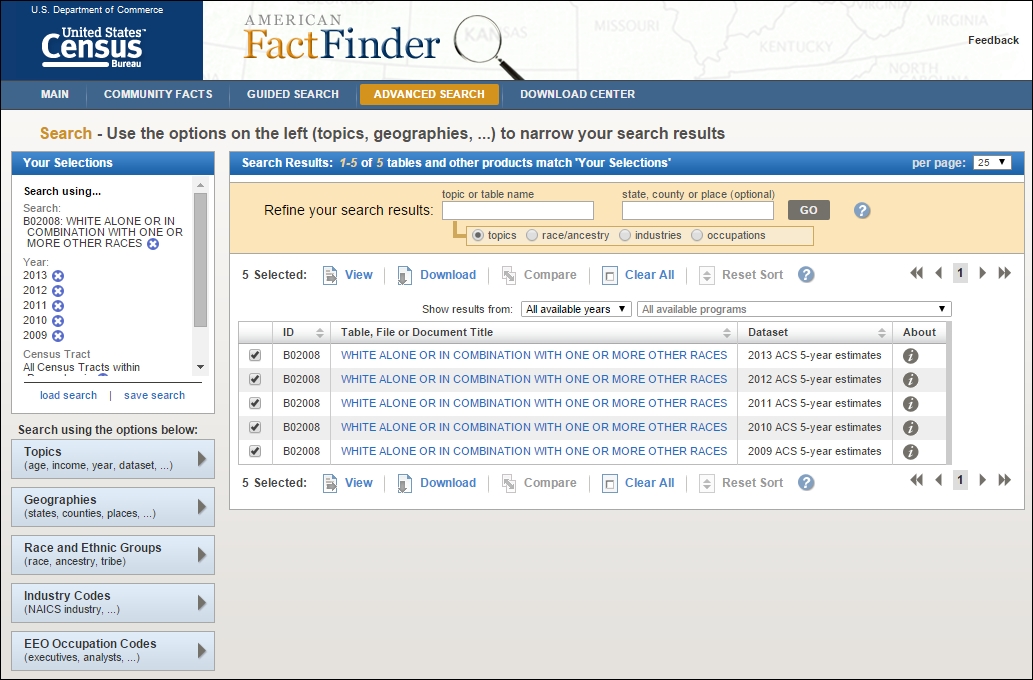
- From the sidebar, go to the Topics section. Here, in the Select Topics to add to 'Your Selections' under Year, click on each year available from 2009 to 2013, adding each to Your Selections to be then downloaded.
- Check each of the five datasets offered under the Search Results tab. All checked datasets are added to the selection to be downloaded, as shown in the following screenshot:
- Now, remove B02008: WHITE ALONE OR IN COMBINATION WITH ONE OR MORE RACES from the search filter showing selections in the upper-left corner of the page.
- Enter
totalinto the topic or table name field, selecting B01003: TOTAL POPULATION from the suggested datasets, and then click on GO. - Select the five 2009 to 2013 total population 5-year estimates and then click on GO.
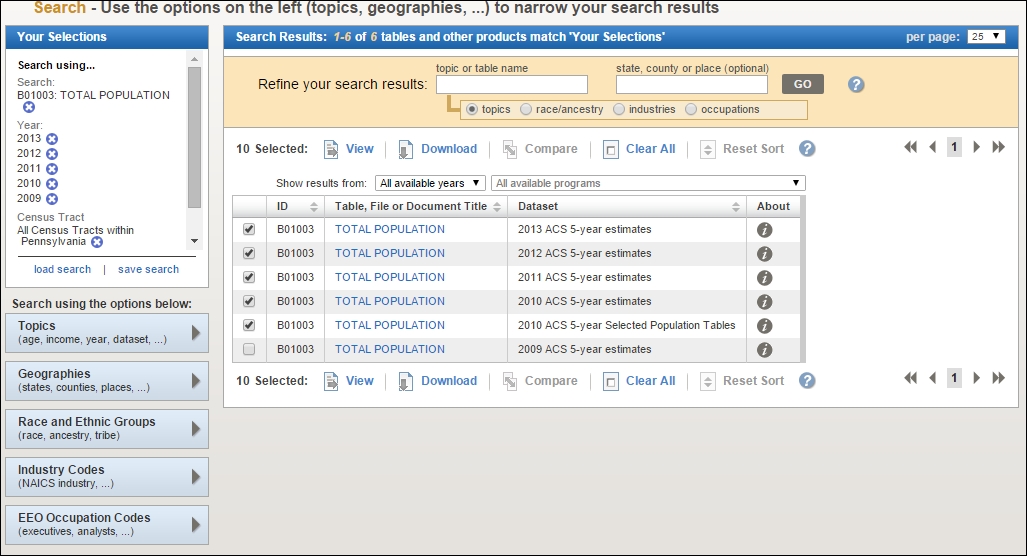
- Click on Download to download these 10 datasets, as shown in the preceding screenshot.
- Once you see the Your file is complete message, click on DOWNLOAD again to download the files. These will download as a
aff_download.zipdirectory. - Move this directory to
c5/data/originaland then extract it.
First, we will cover the steps for tabular data preparation and exporting, which are fairly similar to those we've done before. Next, we will cover the steps for preparing the boundary data, which will be more novel. We need to prepare this data based on the spatial relationships between layers, requiring the use of SQLite, since this cannot easily be done with the out-of-the-box or plugin functionality in QGIS.
Our tabular data is of the census tract white population. We only need to have the parseable latitude and longitude fields in this data for plotting later and, therefore, can leave it in this generic tabular format.
To combine this yearly data, we can join each table on a common GEOID field in QGIS. Perform the following steps:
- Open QGIS and import all the boundary shapefiles (the tracts and state house boundaries) and data tables (all the census tract years downloaded). The single boundary shapefile will be in its extracted directory with the
.shpextension. Data tables will be named something similar tox_with_ann.csv. You need to do this the same way you did earlier, which was through Add Vector Layer under the Layer menu. Here is a list of all the files to add:tl_2014_42_tract.shpACS_09_5YR B01003_with_ann.csvACS_10_5YR B01003_with_ann.csvACS_11_5YR B01003_with_ann.csvACS_12_5YR B01003_with_ann.csvACS_13_5YR B01003_with_ann.csv
- Select the tract boundaries shapefile,
tl_2014_42_tract, from the Layers panel. - Navigate to Layers | Properties.
- For each white population data table (ending in
x_B02008_with_ann), perform the following steps:- On the Joins tab, click on the green plus sign (+) to add a join.
- Select a data table as the Join layer.
- Select GEO.id2 in the Join field tab.
- Target field: GEOID
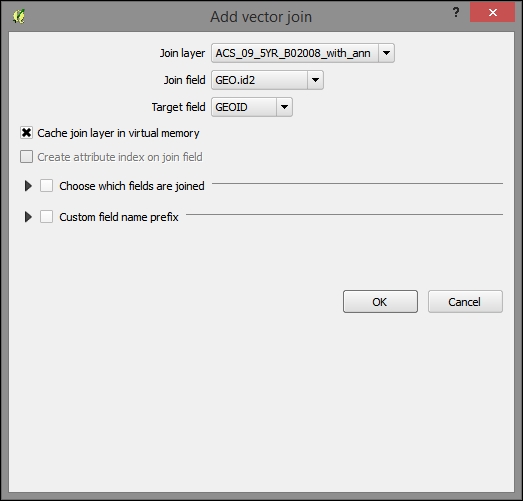
After joining all the tables, you will find many rows in the attribute table containing null values. If you sort them a few years later, you will find that we have the same number of rows populated for more recent years as we have in the Philadelphia tracts layer. However, the year 2009 (ACS_09_5YR B01003_with_ann.csv) has many rows that could not be populated due to the changes in the unique identifier used in the 2014 boundary data. For this reason, we will exclude the year 2009 from our analysis. You can remove the 2009 data table from the joined tables so that we don't have any issue with this later.
Now, export the joined layer as a new DBF database file, which we need to do to be able to make some final changes:
- Ensure that only the rows with the populated data columns are selected in the tracts layer. Attribute the table (you can do this by sorting the attribute table on that field, for example).
- Select the tracts layer from the Layers panel.
- Navigate to Layer | Save as, fulfilling the following parameters:
- Format: DBF File
- Save only the selected features
- Add the saved file to the map
- Save as:
c5/data/output/whites.dbf - Leave the other options as they are by default
QGIS allows us to calculate the coordinates for the geographic features and populate an attribute field with them. On the layer for the new DBF, calculate the latitude and longitude fields in the expected format and eliminate the unnecessary fields by performing the following steps:
- Open the Attribute table for the whites DBF layer and click on the Open Field Calculator button.
- Calculate a new
lonfield and fulfill the following parameters:- Output field name:
lon. - Output field type: Decimal number (real).
- Output field width: 10.
- Precision: 7.
- Expression:
"INTPLON". You can choose this from the Fields and Values sections in the tree under the Functions panel.
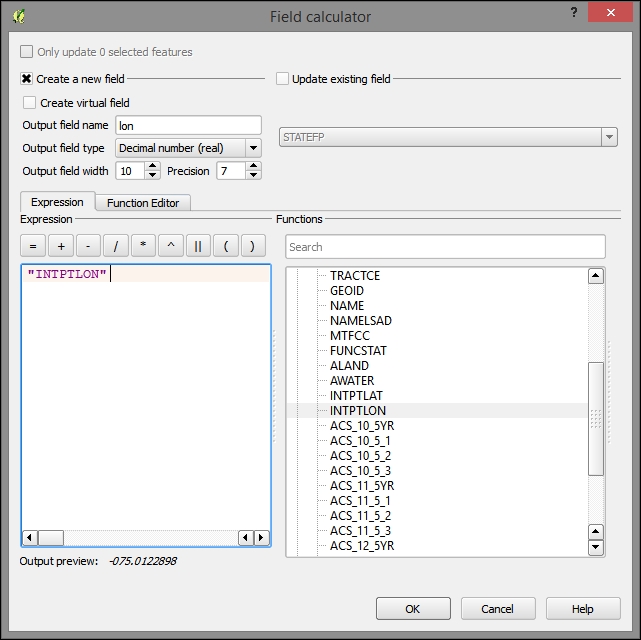
- Output field name:
- Repeat these steps with latitude, making a
latfield fromINTPLAT. - Create the following fields using the field calculator with the expression on the right:
- Output field name:
name; Output field type: Text; Output field width: 50; Expression:NAMESLAD - Output field name:
Jan-11; Output field type: Whole number (integer); Expression:"ACS_11_5_2"-"ACS_10_5_2" - Output field name:
Jan-12; Output field type: Whole number (integer); Expression:"ACS_12_5_2"-"ACS_11_5_2" - Output field name:
Jan-13; Output field type: Whole number (integer); Expression:"ACS_13_5_2"-"ACS_12_5_2"
- Output field name:
- Remove all the old fields (except
name,Jan-11,Jan-12,Jan-13,lat, andlon). This will remove all the unnecessary identification fields and those with a margin of error from the table. - Toggle the editing mode and save when prompted.
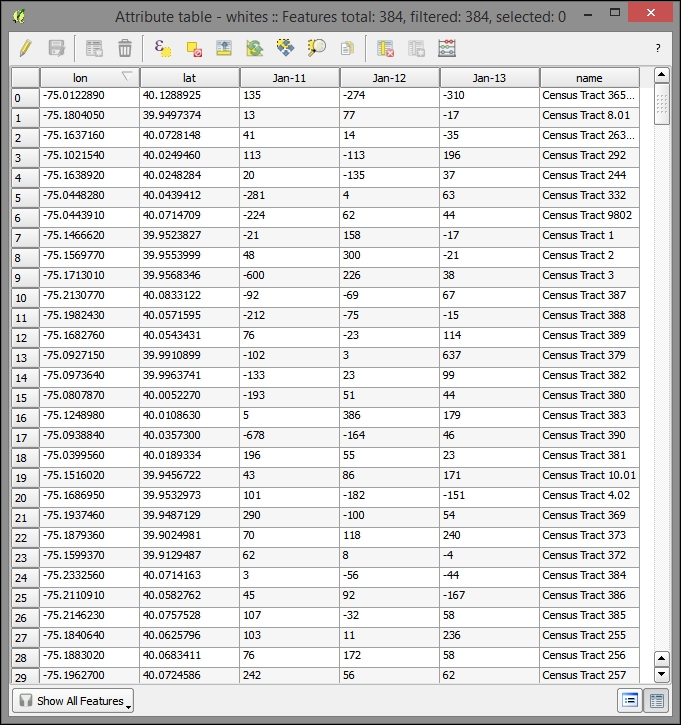
Finally, export the modified table as a new CSV data table, from which we will create our map visualization. Perform the following steps:
Although we have the boundary data for the census tracts, we are only interested in visualizing the State House Districts in our application. Our stakeholders are interested in visualizing change for these districts. However, as we do not have the population data by race for these boundary units, let alone by the yearly population, we need to leverage the spatial relationship between the State House Districts and the tracts to derive this information. This is a useful workflow whenever you have the data at a different level than the geographic unit you wish to visualize or query.
Now, we will construct a field that contains the average yearly change in the white population between 2010 and 2013. Perform the following steps:
- As mentioned previously, join the total population tables (ending in
B01003_with_ann) to the joined tract layer,tl_2014_42_tract, on the same GEO.id2, GEO fields from the new total population tables, and the tract layer respectively. Do not join the 2009 table, because we discovered that there were many null values in the join fields for the white-only version of this. - As before, select the 384 rows in the attribute table having the populated join columns from this table. Save only the selected rows, calling the saved shapefile dataset
tract_changeand adding this to the map. - Open the Attribute table and then open Field Calculator.
- Create a new field.
- Output field name:
avg_change. - Output field type: Decimal number (real).
- Output field width: 4, Precision: 2.
- The following expression is the difference of each year from the previous year divided by the previous year to find the fractional change. This is then divided by three to find the average over three years and finally multiplied by 100 to find the percentage, as follows:
((("ACS_11_5_2" - "ACS_10_5_2")/ "ACS_10_5_2" )+ (("ACS_12_5_2" - "ACS_11_5_2")/ "ACS_11_5_2" )+ (("ACS_13_5_2" - "ACS_12_5_2")/ "ACS_12_5_2" ))/3 * 100
- After this, click on OK.
Now that we have a value for the average change in white population by tract, let's attach this to the unit of interest, which are the State House Districts. We will do this by doing a spatial join, specifically by joining all the records that intersect our House District bounds to that House District. As more than one tract will intersect each State House District, we'll need to aggregate the attribute data from the intersected tracts to match with the single district that the tracts will be joined to.
We will use SpatiaLite for doing this. Similar to PostGIS for Postgres, SpatiaLite is the spatial extension for SQLite. It is file-based; rather than requiring a continuous server listening for connections, a database is stored on a file, and client programs directly connect to it. Also, SpatiaLite comes with QGIS out of the box, making it very easy to begin to use. As with PostGIS, SpatiaLite comes with a rich set of spatial relationship functions, making it a good choice when the existing plugins do not support the relationship we are trying to model.
To do this, perform the following steps:
- Create a new SpatiaLite database.
- Navigate to Layer | Create Layer | New Spatialite Layer.
- Using the ellipses button (…), browse to and create a database at
c5/data/output/district_join.sqlite. - After clicking on Save, you will be notified that a new database has been registered. You have now created a new SpatiaLite database. You can now close this dialog.
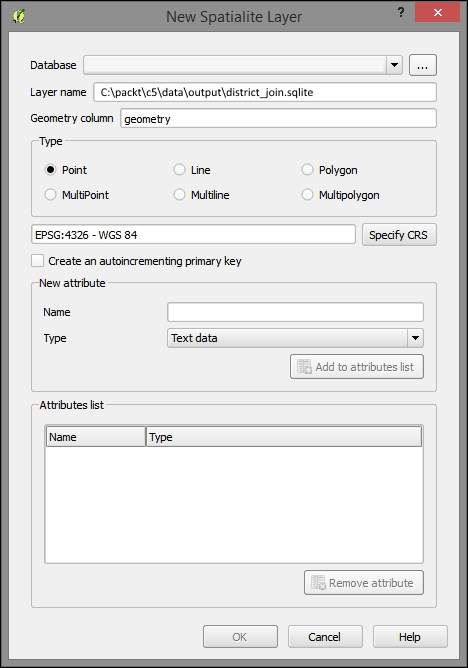
To import layers to SpatiaLite, you can perform the following steps:
- Navigate to Database | DB Manager | DB Manage.
- Click on the refresh button. The new database should now be visible under the SpatiaLite section of the tree.
- Navigate to Table | Import layer/file (
tract_changeandtl_2014_42_sldl). - Click on Update options.
- Select Create single-part geometries instead of multi-part.
- Select Create spatial index.
- Click on OK to finish importing the table to the database (you may need to hit the refresh button again for table to be indicated as imported).
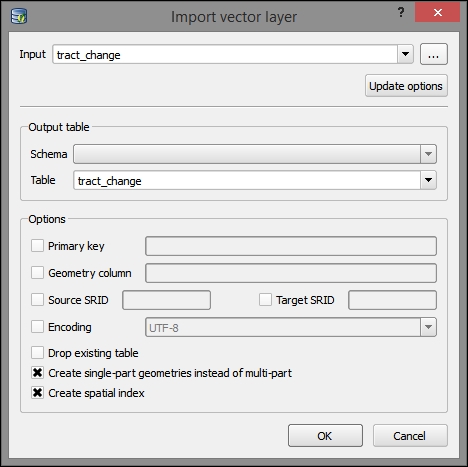
Now, repeat these steps with the House Districts layer (tl_2014_42_sldl), and deselect Create single-part geometries instead of multi-part as this seems to cause an error with this file, perhaps due to some part of a multi-part feature that would not be able to remain on its own under the SpatiaLite data requirements.
Next, we use the DB Manager to query the SpatiaLite database, adding the results to the QGIS layers panel.
We will use the MBRIntersects criteria here, which provides a performance advantage over a regular Intersects function as it only checks for the intersection of the extent (bounding box). In this example, we are dealing with a few features of limited complexity that are not done dynamically during a web request, so this shortcut does not provide a major advantage—we do this here so as to demonstrate its use for more complicated datasets.
- If it isn't already open, open DB Manager.
- Navigate to Database | SQL window.
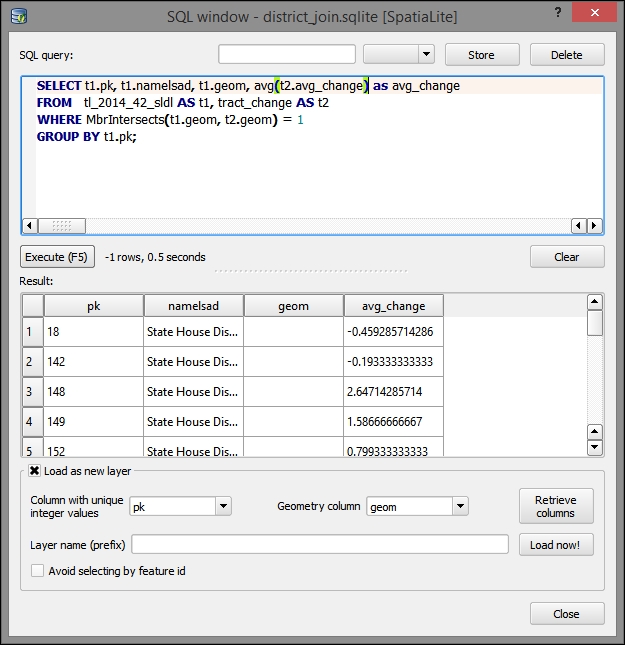
- Fill the respective input fields in the SQL query dialog:
- The following SQL query selects the fields from the
tract_changeandtl_2014_42_sldl(State Legislative District) tables, where they overlap. It also performs an aggregate (average) of the change by the State Legislative Districts overlying the census tract boundaries:SELECT t1.pk, t1.namelsad, t1.geom, avg(t2.avg_change)*1.0 as avg_change FROM tl_2014_42_sldl AS t1, tract_change AS t2 WHERE MbrIntersects(t1.geom, t2.geom) = 1 GROUP BY t1.pk;
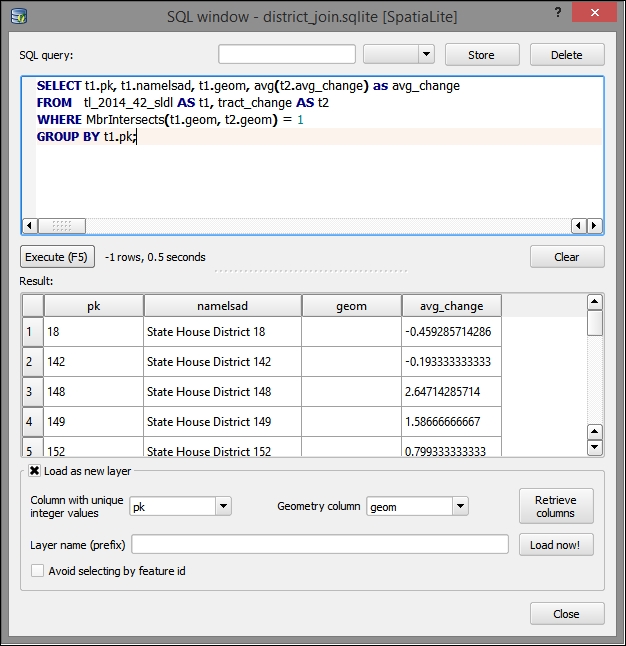
- Then, click on Load now!.
- You will be prompted to select a value for the Column with unique integer values field. For this, select pk.
- You will also be prompted to select a value for the Geometry column field; for this, select geom.
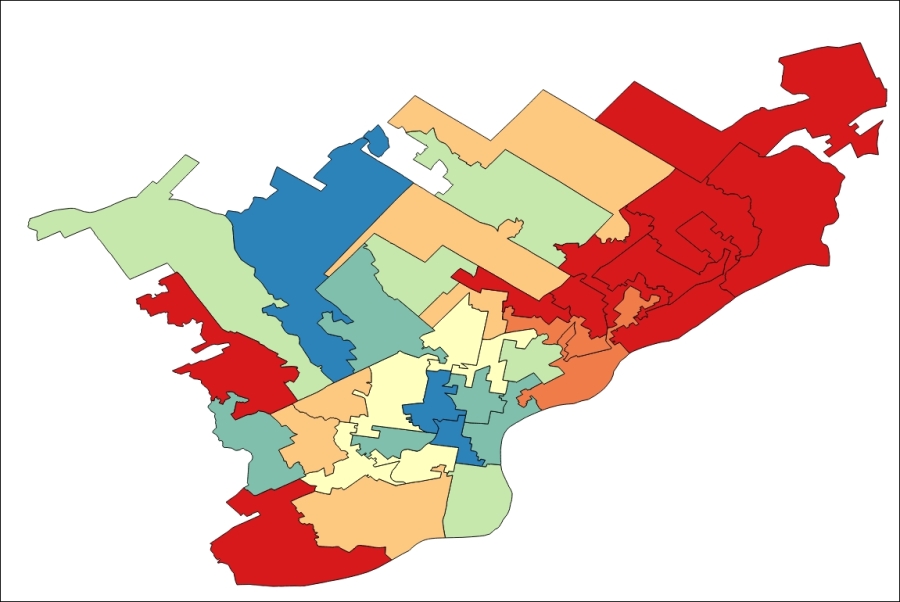
The symbolized result of the spatial relationship join showing the average white population change over a 4-year period for the State House Districts' census tracts intersection will look something similar to the following image: