Table of Contents for
QGIS: Becoming a GIS Power User
 QGIS: Becoming a GIS Power User
Published by
Packt Publishing, 2017
QGIS: Becoming a GIS Power User
Published by
Packt Publishing, 2017
- Cover
- Table of Contents
- QGIS: Becoming a GIS Power User
- QGIS: Becoming a GIS Power User
- QGIS: Becoming a GIS Power User
- Credits
- Preface
- What you need for this learning path
- Who this learning path is for
- Reader feedback
- Customer support
- 1. Module 1
- 1. Getting Started with QGIS
- Running QGIS for the first time
- Introducing the QGIS user interface
- Finding help and reporting issues
- Summary
- 2. Viewing Spatial Data
- Dealing with coordinate reference systems
- Loading raster files
- Loading data from databases
- Loading data from OGC web services
- Styling raster layers
- Styling vector layers
- Loading background maps
- Dealing with project files
- Summary
- 3. Data Creation and Editing
- Working with feature selection tools
- Editing vector geometries
- Using measuring tools
- Editing attributes
- Reprojecting and converting vector and raster data
- Joining tabular data
- Using temporary scratch layers
- Checking for topological errors and fixing them
- Adding data to spatial databases
- Summary
- 4. Spatial Analysis
- Combining raster and vector data
- Vector and raster analysis with Processing
- Leveraging the power of spatial databases
- Summary
- 5. Creating Great Maps
- Labeling
- Designing print maps
- Presenting your maps online
- Summary
- 6. Extending QGIS with Python
- Getting to know the Python Console
- Creating custom geoprocessing scripts using Python
- Developing your first plugin
- Summary
- 2. Module 2
- 1. Exploring Places – from Concept to Interface
- Acquiring data for geospatial applications
- Visualizing GIS data
- The basemap
- Summary
- 2. Identifying the Best Places
- Raster analysis
- Publishing the results as a web application
- Summary
- 3. Discovering Physical Relationships
- Spatial join for a performant operational layer interaction
- The CartoDB platform
- Leaflet and an external API: CartoDB SQL
- Summary
- 4. Finding the Best Way to Get There
- OpenStreetMap data for topology
- Database importing and topological relationships
- Creating the travel time isochron polygons
- Generating the shortest paths for all students
- Web applications – creating safe corridors
- Summary
- 5. Demonstrating Change
- TopoJSON
- The D3 data visualization library
- Summary
- 6. Estimating Unknown Values
- Interpolated model values
- A dynamic web application – OpenLayers AJAX with Python and SpatiaLite
- Summary
- 7. Mapping for Enterprises and Communities
- The cartographic rendering of geospatial data – MBTiles and UTFGrid
- Interacting with Mapbox services
- Putting it all together
- Going further – local MBTiles hosting with TileStream
- Summary
- 3. Module 3
- 1. Data Input and Output
- Finding geospatial data on your computer
- Describing data sources
- Importing data from text files
- Importing KML/KMZ files
- Importing DXF/DWG files
- Opening a NetCDF file
- Saving a vector layer
- Saving a raster layer
- Reprojecting a layer
- Batch format conversion
- Batch reprojection
- Loading vector layers into SpatiaLite
- Loading vector layers into PostGIS
- 2. Data Management
- Joining layer data
- Cleaning up the attribute table
- Configuring relations
- Joining tables in databases
- Creating views in SpatiaLite
- Creating views in PostGIS
- Creating spatial indexes
- Georeferencing rasters
- Georeferencing vector layers
- Creating raster overviews (pyramids)
- Building virtual rasters (catalogs)
- 3. Common Data Preprocessing Steps
- Converting points to lines to polygons and back – QGIS
- Converting points to lines to polygons and back – SpatiaLite
- Converting points to lines to polygons and back – PostGIS
- Cropping rasters
- Clipping vectors
- Extracting vectors
- Converting rasters to vectors
- Converting vectors to rasters
- Building DateTime strings
- Geotagging photos
- 4. Data Exploration
- Listing unique values in a column
- Exploring numeric value distribution in a column
- Exploring spatiotemporal vector data using Time Manager
- Creating animations using Time Manager
- Designing time-dependent styles
- Loading BaseMaps with the QuickMapServices plugin
- Loading BaseMaps with the OpenLayers plugin
- Viewing geotagged photos
- 5. Classic Vector Analysis
- Selecting optimum sites
- Dasymetric mapping
- Calculating regional statistics
- Estimating density heatmaps
- Estimating values based on samples
- 6. Network Analysis
- Creating a simple routing network
- Calculating the shortest paths using the Road graph plugin
- Routing with one-way streets in the Road graph plugin
- Calculating the shortest paths with the QGIS network analysis library
- Routing point sequences
- Automating multiple route computation using batch processing
- Matching points to the nearest line
- Creating a routing network for pgRouting
- Visualizing the pgRouting results in QGIS
- Using the pgRoutingLayer plugin for convenience
- Getting network data from the OSM
- 7. Raster Analysis I
- Using the raster calculator
- Preparing elevation data
- Calculating a slope
- Calculating a hillshade layer
- Analyzing hydrology
- Calculating a topographic index
- Automating analysis tasks using the graphical modeler
- 8. Raster Analysis II
- Calculating NDVI
- Handling null values
- Setting extents with masks
- Sampling a raster layer
- Visualizing multispectral layers
- Modifying and reclassifying values in raster layers
- Performing supervised classification of raster layers
- 9. QGIS and the Web
- Using web services
- Using WFS and WFS-T
- Searching CSW
- Using WMS and WMS Tiles
- Using WCS
- Using GDAL
- Serving web maps with the QGIS server
- Scale-dependent rendering
- Hooking up web clients
- Managing GeoServer from QGIS
- 10. Cartography Tips
- Using Rule Based Rendering
- Handling transparencies
- Understanding the feature and layer blending modes
- Saving and loading styles
- Configuring data-defined labels
- Creating custom SVG graphics
- Making pretty graticules in any projection
- Making useful graticules in printed maps
- Creating a map series using Atlas
- 11. Extending QGIS
- Defining custom projections
- Working near the dateline
- Working offline
- Using the QspatiaLite plugin
- Adding plugins with Python dependencies
- Using the Python console
- Writing Processing algorithms
- Writing QGIS plugins
- Using external tools
- 12. Up and Coming
- Preparing LiDAR data
- Opening File Geodatabases with the OpenFileGDB driver
- Using Geopackages
- The PostGIS Topology Editor plugin
- The Topology Checker plugin
- GRASS Topology tools
- Hunting for bugs
- Reporting bugs
- Bibliography
- Index
Raster data, by organizing the data in uniform grids, is useful to analyze continuous phenomena or find some information at the subobject level. We will use continuous elevation and proximity data in this case, and we will look at the subapplicant object level —at the 30 meter-square cell level. You would choose a cell size depending on the resolution of the data source (for example, from sensors roughly 30 meters apart), the roughness of the analysis (regional versus local), and any hardware limitations.
First, let's make a few notes about raster data:
- Nodata refers to the cells that are included with the raster grid because a grid can't have completely undefined cells; however, these cells should really be considered off the layer.
- QGIS's raster renderer is more limited than in its proprietary competitors. You will want to use the Identify tool as well as custom styles (Singleband Pseudocolor) to make sense of your outputs.
- In this example, we will rely heavily on the GDAL and SAGA libraries that have been wrapped for QGIS. These are available directly through the processing framework with no additional preparation beyond the ordinary raster ETL. For additional functionality, you will want to consider the GRASS libraries. These are wrapped and provided for QGIS but require the additional preparation of a GRASS workspace.
Now that all our data is in the raster format, we can work through how to derive information from these layers and combine this information in order to select the best sites.
Map algebra is a useful concept to work with multiple raster layers and analysis steps, providing arithmetic operations between cells in aligned grids. These produce an output grid with the respective value of the arithmetic solution for each set of cells. We will be using map algebra in this example for additive modeling.
Now that all our data is in the raster format, we can begin to model for the purpose of site selection. We want to discover which cells are best according to a set of criteria which has either been established for the domain area (for example, the agricultural conservation site selection) by convention or selected at the time of modeling. Additive modeling refers to this process of adding up all the criteria and associated weights to find the best areas, which will have the greatest value.
In this case, we have selected some criteria that are loosely known to affect the agricultural conservation site selection, as shown in the following table:
|
Layer |
Criteria |
Rule |
|---|---|---|
|
|
Is applicant | |
|
|
Proximity |
< 2000 m |
|
|
Land use, proximity |
< 100 m |
|
|
Slope |
=> 2 and <= 5, average |
|
|
Land use, proximity |
> 500 m |
|
|
Proximity |
> 100m |
The Proximity grid tool will generate a layer of cells with each cell having a value equal to its distance from the nearest non-nodata cell in another grid. The distance value is given in the CRS units of the other grid. It also generates direction and allocation grids with the direction and ID of the nearest nodata cell.
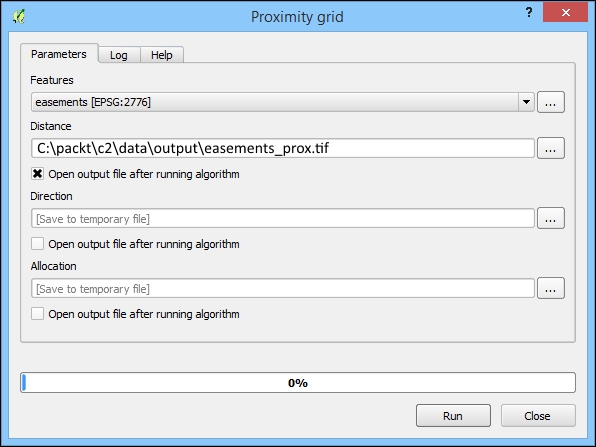
- Navigate to Processing Toolbox.
- Search for
proximityin this toolbox. Ensure that you have the Advanced Interface selected. - Once you've located the Proximity grid tool under SAGA, double-click on it to run it.
- Select easements for the Features field.
- Specify an output file for Distance at
c2/data/output/easements_prox.tif. - Uncheck Open output file after running algorithm for the other two outputs, as shown in the following screenshot:
The resulting grid is of the distance to the closest easement cell.
- Repeat these steps to create proximity grids for
agriculture,developed, androads. Finally, you will see the following output: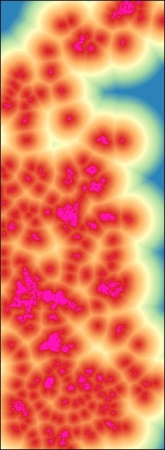
The Slope command creates a grid where the value of each cell is equal to the upgradient slope in percent terms. In other words, it is equal to how steep the terrain is at the current cell in the percentage of rise in elevation unit per horizontal distance unit. Perform the following steps:
- Install and activate the Raster Terrain Analysis plugin if you have not already done so.
- Navigate to Raster | Terrain Analysis | Slope.
- Select dem, the Digital Elevation Model, for the Elevation layer field.
- Save your output in
c2/data/output. You can keep the other inputs as default.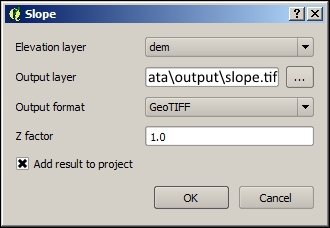
- The output will be the steepness of each cell in the percentage of of vertical elevation over horizontal distance ("rise over run").
- Ensure that all the criteria grids (
proximity,agriculture,developed,road, andslope) appear in the Layers panel. If they don't, add them. - Bring up the Raster calculator dialog.
- Navigate to Raster | Raster calculator
- Enter the map algebra expression.
- Add the raster layers by double-clicking on them in the Raster bands selection area
- Add the operators by typing them out or clicking on the buttons in the operators area
- The expression entered should be as follows:
("slope@1" < 8) + ("applicants@1" = 1) + ("easement_prox@1"<2000) + ("roads_prox@1">100) + ("developed_prox@1" > 500) + ("agriculture@1" < 100)
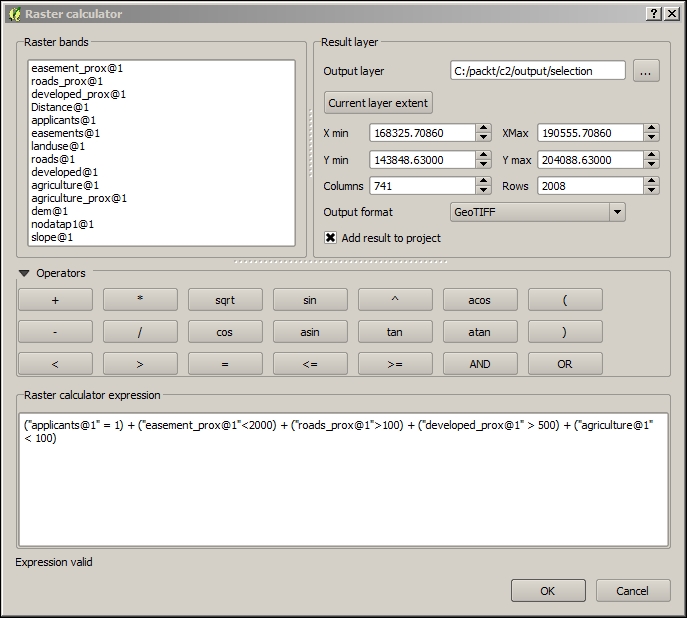
- Add a name and path for the output file and hit Enter.
- You may need to set a style if it seems like nothing happened. By default, the nonzero value is set to display in white (the same color as our background).
Here's a close up of the preceding map image so that you can see the variability in suitability:
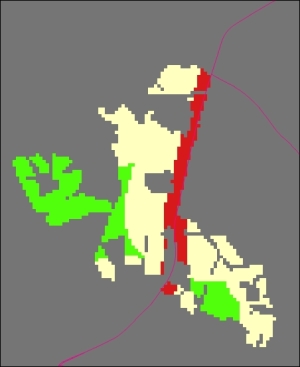
In the preceding screenshot, cells are scored as follows:
- Green = 5 (high)
- Yellow = 4 (middle)
- Red = 3 (low)
Zonal statistics are calculated from the cells that fall within polygons. Using zonal statistics, we can get a better idea of what the raster data tells us about a particular cell group, geographic object, or polygon. In this case, zonal statistics will give us an average score for a particular applicant. Perform the following steps:
- Install and activate the Zonal Statistics plugin.
- Navigate to Raster | Zonal Statistics | Zonal statistics, as shown in the following image:
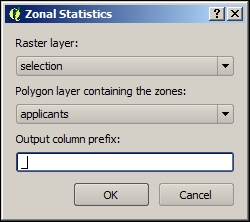
- Input a raster layer for the values used to calculate a statistic and a polygon layer that are used to define the boundaries of the cells used. Here, we will use the applicants and land use to count the number of cells in each applicant cell group.
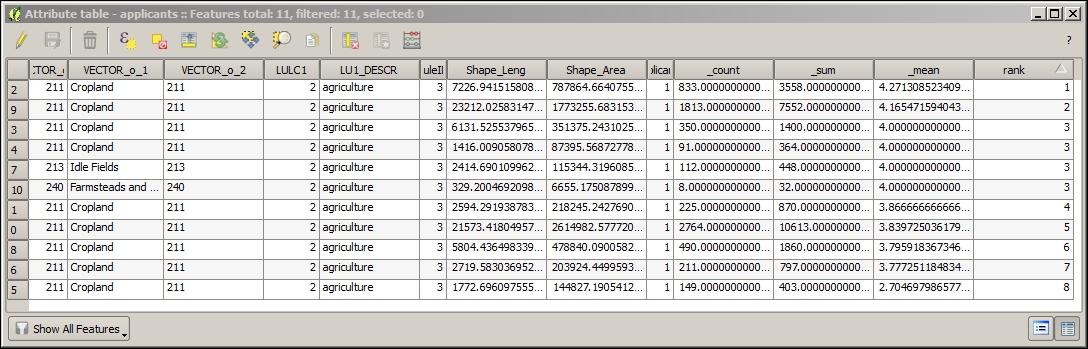
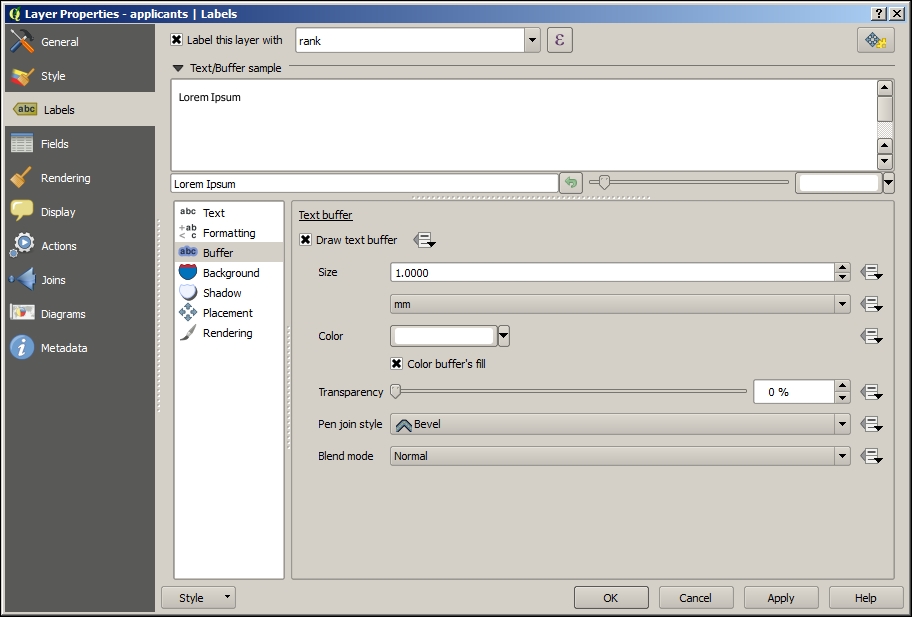
- Create a
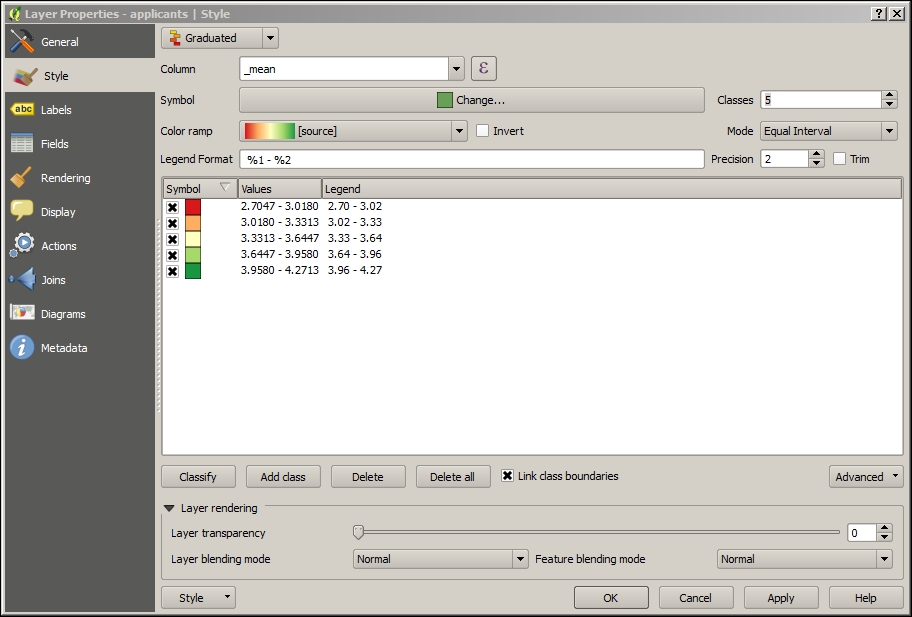
rankfield, editing each value manually according to the_meanfield created by the zonal statistics step. This is a measure of the mean suitability per cell. We will use this field for a label to communicate the relative suitability to a general audience; so, we want a rank instead of the rough mean value. - Now, label the layer.
- Add a style to the layer.
After you've completed these steps, your map will look something similar to this: