Table of Contents for
Your Code as a Crime Scene
 Your Code as a Crime Scene
Published by
Pragmatic Bookshelf, 2015
Your Code as a Crime Scene
Published by
Pragmatic Bookshelf, 2015
- Title Page
- Your Code as a Crime Scene
- Your Code as a Crime Scene
- For the Best Reading Experience...
- Table of Contents
- Early praise for Your Code as a Crime Scene
- Foreword by Michael Feathers
- Acknowledgments
- Chapter 1: Welcome!
- About This Book
- Optimize for Understanding
- How to Read This Book
- Toward a New Approach
- Get Your Investigative Tools
- Part 1: Evolving Software
- Chapter 2: Code as a Crime Scene
- Meet the Problems of Scale
- Get a Crash Course in Offender Profiling
- Profiling the Ripper
- Apply Geographical Offender Profiling to Code
- Learn from the Spatial Movement of Programmers
- Find Your Own Hotspots
- Chapter 3: Creating an Offender Profile
- Mining Evolutionary Data
- Automated Mining with Code Maat
- Add the Complexity Dimension
- Merge Complexity and Effort
- Limitations of the Hotspot Criteria
- Use Hotspots as a Guide
- Dig Deeper
- Chapter 4: Analyze Hotspots in Large-Scale Systems
- Analyze a Large Codebase
- Visualize Hotspots
- Explore the Visualization
- Study the Distribution of Hotspots
- Differentiate Between True Problems and False Positives
- Chapter 5: Judge Hotspots with the Power of Names
- Know the Cognitive Advantages of Good Names
- Investigate a Hotspot by Its Name
- Understand the Limitations of Heuristics
- Chapter 6: Calculate Complexity Trends from Your Code’s Shape
- Complexity by the Visual Shape of Programs
- Learn About the Negative Space in Code
- Analyze Complexity Trends in Hotspots
- Evaluate the Growth Patterns
- From Individual Hotspots to Architectures
- Part 2: Dissect Your Architecture
- Chapter 7: Treat Your Code As a Cooperative Witness
- Know How Your Brain Deceives You
- Learn the Modus Operandi of a Code Change
- Use Temporal Coupling to Reduce Bias
- Prepare to Analyze Temporal Coupling
- Chapter 8: Detect Architectural Decay
- Support Your Redesigns with Data
- Analyze Temporal Coupling
- Catch Architectural Decay
- React to Structural Trends
- Scale to System Architectures
- Chapter 9: Build a Safety Net for Your Architecture
- Know What’s in an Architecture
- Analyze the Evolution on a System Level
- Differentiate Between the Level of Tests
- Create a Safety Net for Your Automated Tests
- Know the Costs of Automation Gone Wrong
- Chapter 10: Use Beauty as a Guiding Principle
- Learn Why Attractiveness Matters
- Write Beautiful Code
- Avoid Surprises in Your Architecture
- Analyze Layered Architectures
- Find Surprising Change Patterns
- Expand Your Analyses
- Part 3: Master the Social Aspects of Code
- Chapter 11: Norms, Groups, and False Serial Killers
- Learn Why the Right People Don’t Speak Up
- Understand Pluralistic Ignorance
- Witness Groupthink in Action
- Discover Your Team’s Modus Operandi
- Mine Organizational Metrics from Code
- Chapter 12: Discover Organizational Metrics in Your Codebase
- Let’s Work in the Communication Business
- Find the Social Problems of Scale
- Measure Temporal Coupling over Organizational Boundaries
- Evaluate Communication Costs
- Take It Step by Step
- Chapter 13: Build a Knowledge Map of Your System
- Know Your Knowledge Distribution
- Grow Your Mental Maps
- Investigate Knowledge in the Scala Repository
- Visualize Knowledge Loss
- Get More Details with Code Churn
- Chapter 14: Dive Deeper with Code Churn
- Cure the Disease, Not the Symptoms
- Discover Your Process Loss from Code
- Investigate the Disposal Sites of Killers and Code
- Predict Defects
- Time to Move On
- Chapter 15: Toward the Future
- Let Your Questions Guide Your Analysis
- Take Other Approaches
- Let’s Look into the Future
- Write to Evolve
- Appendix 1: Refactoring Hotspots
- Refactor Guided by Names
- Bibliography
- You May Be Interested In…
Cure the Disease, Not the Symptoms
So, how much do you enjoy merging code from different development branches? Not at all? Neither do I. If you’re like me, you’ve probably had your fair share of merge nightmares. Remember the project I talked about in Chapter 12, Discover Organizational Metrics in Your Codebase? You know, the story of the project that got stacked with four times as many developers as needed to get it done “faster”?
In that project, one of the major bottlenecks turned out to be parallel work. We often spent a few hours adding a feature, only to find out that the relevant code had been rewritten in another branch. Not only is that way of working frustrating, it’s also expensive and a sure way to breed defects. We don’t want that.
Better tools like Git and Mercurial have improved the situation, but we cannot expect our tools to cure dysfunctional practices. Let’s see how code churn can uncover them.
Meet Code Churn
Code churn refers to a family of measures that reflect how rapidly your codebase evolves. Each time you commit a change to your source code, your version-control system records the lines you’ve added, modified, and deleted. The following image shows how it looks in Git.
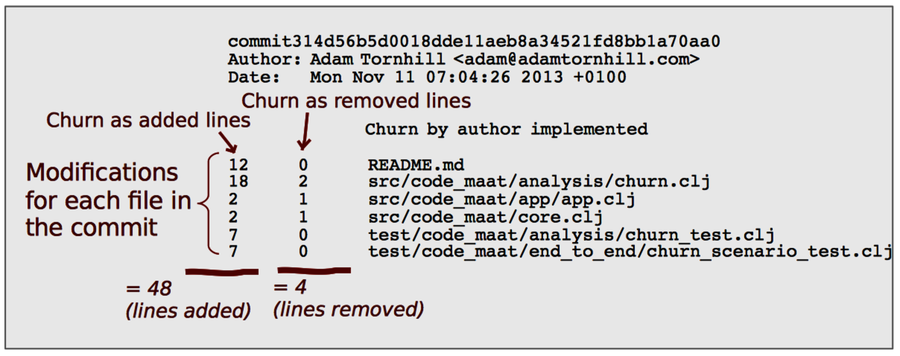
Over time, we get thousands of such small churn contributions in our repositories. Each one of them provides a small hint about how we work. Let’s see how we can use that to discover process loss in our organization.