Table of Contents for
Your Code as a Crime Scene
 Your Code as a Crime Scene
Published by
Pragmatic Bookshelf, 2015
Your Code as a Crime Scene
Published by
Pragmatic Bookshelf, 2015
- Title Page
- Your Code as a Crime Scene
- Your Code as a Crime Scene
- For the Best Reading Experience...
- Table of Contents
- Early praise for Your Code as a Crime Scene
- Foreword by Michael Feathers
- Acknowledgments
- Chapter 1: Welcome!
- About This Book
- Optimize for Understanding
- How to Read This Book
- Toward a New Approach
- Get Your Investigative Tools
- Part 1: Evolving Software
- Chapter 2: Code as a Crime Scene
- Meet the Problems of Scale
- Get a Crash Course in Offender Profiling
- Profiling the Ripper
- Apply Geographical Offender Profiling to Code
- Learn from the Spatial Movement of Programmers
- Find Your Own Hotspots
- Chapter 3: Creating an Offender Profile
- Mining Evolutionary Data
- Automated Mining with Code Maat
- Add the Complexity Dimension
- Merge Complexity and Effort
- Limitations of the Hotspot Criteria
- Use Hotspots as a Guide
- Dig Deeper
- Chapter 4: Analyze Hotspots in Large-Scale Systems
- Analyze a Large Codebase
- Visualize Hotspots
- Explore the Visualization
- Study the Distribution of Hotspots
- Differentiate Between True Problems and False Positives
- Chapter 5: Judge Hotspots with the Power of Names
- Know the Cognitive Advantages of Good Names
- Investigate a Hotspot by Its Name
- Understand the Limitations of Heuristics
- Chapter 6: Calculate Complexity Trends from Your Code’s Shape
- Complexity by the Visual Shape of Programs
- Learn About the Negative Space in Code
- Analyze Complexity Trends in Hotspots
- Evaluate the Growth Patterns
- From Individual Hotspots to Architectures
- Part 2: Dissect Your Architecture
- Chapter 7: Treat Your Code As a Cooperative Witness
- Know How Your Brain Deceives You
- Learn the Modus Operandi of a Code Change
- Use Temporal Coupling to Reduce Bias
- Prepare to Analyze Temporal Coupling
- Chapter 8: Detect Architectural Decay
- Support Your Redesigns with Data
- Analyze Temporal Coupling
- Catch Architectural Decay
- React to Structural Trends
- Scale to System Architectures
- Chapter 9: Build a Safety Net for Your Architecture
- Know What’s in an Architecture
- Analyze the Evolution on a System Level
- Differentiate Between the Level of Tests
- Create a Safety Net for Your Automated Tests
- Know the Costs of Automation Gone Wrong
- Chapter 10: Use Beauty as a Guiding Principle
- Learn Why Attractiveness Matters
- Write Beautiful Code
- Avoid Surprises in Your Architecture
- Analyze Layered Architectures
- Find Surprising Change Patterns
- Expand Your Analyses
- Part 3: Master the Social Aspects of Code
- Chapter 11: Norms, Groups, and False Serial Killers
- Learn Why the Right People Don’t Speak Up
- Understand Pluralistic Ignorance
- Witness Groupthink in Action
- Discover Your Team’s Modus Operandi
- Mine Organizational Metrics from Code
- Chapter 12: Discover Organizational Metrics in Your Codebase
- Let’s Work in the Communication Business
- Find the Social Problems of Scale
- Measure Temporal Coupling over Organizational Boundaries
- Evaluate Communication Costs
- Take It Step by Step
- Chapter 13: Build a Knowledge Map of Your System
- Know Your Knowledge Distribution
- Grow Your Mental Maps
- Investigate Knowledge in the Scala Repository
- Visualize Knowledge Loss
- Get More Details with Code Churn
- Chapter 14: Dive Deeper with Code Churn
- Cure the Disease, Not the Symptoms
- Discover Your Process Loss from Code
- Investigate the Disposal Sites of Killers and Code
- Predict Defects
- Time to Move On
- Chapter 15: Toward the Future
- Let Your Questions Guide Your Analysis
- Take Other Approaches
- Let’s Look into the Future
- Write to Evolve
- Appendix 1: Refactoring Hotspots
- Refactor Guided by Names
- Bibliography
- You May Be Interested In…
Expand Your Analyses
When we uncover problems in our analyses, we want to react. We typically reconsider some architectural principles, perhaps even the overall patterns we built on. As a result, we evolve parts of our system into a new direction. As we do this, we want to be able to track that as well.
The techniques you’ve learned will be there to support you, since the analyses aren’t limited to the patterns we’ve discussed in this chapter. Understanding the underlying ideas lets you apply the analyses to new situations. So before we move on to the final part of the book, let’s have a quick look at some different architectural styles you may encounter.
Analyze Microservices
At the time of this writing, microservices are gaining rapid popularity. That means many of tomorrow’s legacy systems are likely to be microservice architectures. Let’s stay a step ahead and see what we would want to analyze when we come across such systems.
Microservices are based on an old idea where you organize your code by feature. You keep each part small and orthogonal to others, and use a simple mechanism to glue everything together (for example, a message bus or an HTTP API). In fact, these are the same principles on which UNIX has built since the dawn of curly braces in code.
A microservice architecture attempts to encapsulate each fine-grained responsibility in a service. This principle implies that a microservice architecture is attractive when it allows us to modify and replace individual services without affecting other services. The warning sign in a microservices architecture is a commit that affects multiple services:
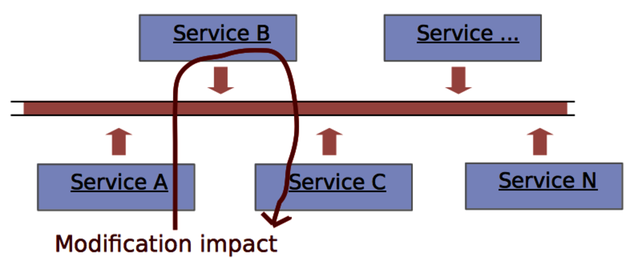
When we analyze microservices, we want to consider each service an architectural boundary. That’s what we specify in our transformations. As soon as we see changes that ripple through multiple services, we know that ugliness is creeping into our system, and we can react immediately.
Reverse-Engineer Your Principles from Code
As you saw in the microservice example, we use the same techniques to analyze all kinds of architectures. But what if we don’t have any existing principles on which we can base our reasonings? What if we just inherited a monster codebase without any obvious structure or style? Well, our focus changes. Let’s see how.
All codebases, even the worst spaghetti monsters, have some principles. All programmers have their own style. It may change over time, but we can find and build upon consistencies.
When you find yourself wading through legacy code, take the time to step back. Look at the records in your version-control system. Often, you can spot patterns. Complement that information with what you learn as you make changes to the code. Perhaps most of the database access is located in an inaptly named utility module. Maybe each subscreen in the GUI is backed by its own class. Fine—you just uncovered your first principles.
As you start to reverse-engineer more principles, tailor the analyses in this chapter accordingly. Look for changes that break the principles. The principles may not be ideal, and the system may not be what you want. But at least this strategy will give you an opportunity to assess how consistent the system is. Used that way, the analyses will help you improve the situation and make code changes more predictable over time.
Use Your Suite of Analysis Techniques
Now you have a set of new skills that allow you to analyze everything from individual design elements all the way up to architectures and automated tests. With these techniques, you’ll be able to detect when your programs start to evolve in a direction your architecture cannot support.
The key to these high-level analyses is to formulate simple rules based on your architectural principles. We introduced beauty as a supporting tool, and you set up your analyses to capture the cases where we break it.
Once you’ve formulated your rules, run the analyses frequently. Use the results as an early warning system and as the basis for design discussions. You also want to complement the temporal coupling results with a hotspot analysis. Hotspots help you assess the severity of your temporal couples.
Throughout Part II, we have focused on how to interview our codebase and evaluate the code’s health. But the challenges of large-scale software go beyond technology. Many of the problems you’ll find in a forensic code analysis have social roots.
In Part III, we’ll move into this fascinating area. You’ll meet new techniques to identify the organizational problems that creep into your code. You’ll also learn about social biases that influence your development team and how to avoid classic pitfalls when scaling your development efforts. Of course, we’ll mine supporting evidence for all claims. Let’s move on to people!