Table of Contents for
Your Code as a Crime Scene
 Your Code as a Crime Scene
Published by
Pragmatic Bookshelf, 2015
Your Code as a Crime Scene
Published by
Pragmatic Bookshelf, 2015
- Title Page
- Your Code as a Crime Scene
- Your Code as a Crime Scene
- For the Best Reading Experience...
- Table of Contents
- Early praise for Your Code as a Crime Scene
- Foreword by Michael Feathers
- Acknowledgments
- Chapter 1: Welcome!
- About This Book
- Optimize for Understanding
- How to Read This Book
- Toward a New Approach
- Get Your Investigative Tools
- Part 1: Evolving Software
- Chapter 2: Code as a Crime Scene
- Meet the Problems of Scale
- Get a Crash Course in Offender Profiling
- Profiling the Ripper
- Apply Geographical Offender Profiling to Code
- Learn from the Spatial Movement of Programmers
- Find Your Own Hotspots
- Chapter 3: Creating an Offender Profile
- Mining Evolutionary Data
- Automated Mining with Code Maat
- Add the Complexity Dimension
- Merge Complexity and Effort
- Limitations of the Hotspot Criteria
- Use Hotspots as a Guide
- Dig Deeper
- Chapter 4: Analyze Hotspots in Large-Scale Systems
- Analyze a Large Codebase
- Visualize Hotspots
- Explore the Visualization
- Study the Distribution of Hotspots
- Differentiate Between True Problems and False Positives
- Chapter 5: Judge Hotspots with the Power of Names
- Know the Cognitive Advantages of Good Names
- Investigate a Hotspot by Its Name
- Understand the Limitations of Heuristics
- Chapter 6: Calculate Complexity Trends from Your Code’s Shape
- Complexity by the Visual Shape of Programs
- Learn About the Negative Space in Code
- Analyze Complexity Trends in Hotspots
- Evaluate the Growth Patterns
- From Individual Hotspots to Architectures
- Part 2: Dissect Your Architecture
- Chapter 7: Treat Your Code As a Cooperative Witness
- Know How Your Brain Deceives You
- Learn the Modus Operandi of a Code Change
- Use Temporal Coupling to Reduce Bias
- Prepare to Analyze Temporal Coupling
- Chapter 8: Detect Architectural Decay
- Support Your Redesigns with Data
- Analyze Temporal Coupling
- Catch Architectural Decay
- React to Structural Trends
- Scale to System Architectures
- Chapter 9: Build a Safety Net for Your Architecture
- Know What’s in an Architecture
- Analyze the Evolution on a System Level
- Differentiate Between the Level of Tests
- Create a Safety Net for Your Automated Tests
- Know the Costs of Automation Gone Wrong
- Chapter 10: Use Beauty as a Guiding Principle
- Learn Why Attractiveness Matters
- Write Beautiful Code
- Avoid Surprises in Your Architecture
- Analyze Layered Architectures
- Find Surprising Change Patterns
- Expand Your Analyses
- Part 3: Master the Social Aspects of Code
- Chapter 11: Norms, Groups, and False Serial Killers
- Learn Why the Right People Don’t Speak Up
- Understand Pluralistic Ignorance
- Witness Groupthink in Action
- Discover Your Team’s Modus Operandi
- Mine Organizational Metrics from Code
- Chapter 12: Discover Organizational Metrics in Your Codebase
- Let’s Work in the Communication Business
- Find the Social Problems of Scale
- Measure Temporal Coupling over Organizational Boundaries
- Evaluate Communication Costs
- Take It Step by Step
- Chapter 13: Build a Knowledge Map of Your System
- Know Your Knowledge Distribution
- Grow Your Mental Maps
- Investigate Knowledge in the Scala Repository
- Visualize Knowledge Loss
- Get More Details with Code Churn
- Chapter 14: Dive Deeper with Code Churn
- Cure the Disease, Not the Symptoms
- Discover Your Process Loss from Code
- Investigate the Disposal Sites of Killers and Code
- Predict Defects
- Time to Move On
- Chapter 15: Toward the Future
- Let Your Questions Guide Your Analysis
- Take Other Approaches
- Let’s Look into the Future
- Write to Evolve
- Appendix 1: Refactoring Hotspots
- Refactor Guided by Names
- Bibliography
- You May Be Interested In…
Visualize Knowledge Loss
Think back to the last project you worked on. What if one of the core developers suddenly left? Literally just walked out the door. What parts of the code would now be left in the wild? And what parts should the next developer start to look at? Most of the time, we don’t know the answers. Let’s see how our knowledge map puts us in a better position.
Learn the Predictive Power of Abandoned Code
Practices such as good documentation, close collaboration, and code reviews help to spread the knowledge of the codebase. But even under ideal conditions, practices can never replace the intricate knowledge that comes from working with a piece of code over time. That’s one reason why the number of ex-developers who have worked on a component is a good predictor of the number of post-release defects the code will have. (See The Influence of Organizational Structure on Software Quality [NMB08] for the original research.)
In early 2014, the Scala project faced that challenge. Paul Phillips, who’d worked on the codebase for five years, left the project–you can watch him tell the story here.[39] Let’s see if we can find the resulting knowledge gap.
Identify Abandoned Code
You’ve already seen how the knowledge map lets you identify the main contributors for each module. When it comes to identifying abandoned code—that’s code written by a programmer who’s no longer in the company—we can simplify it. The only thing we actually need is a color to identify the ex-programmers.
In this case, we just assign a color to Paul Phillips:
| | author,color |
| | Paul Phillips,green |
Save the CSV as scala_ex_programmers.csv and generate a JSON document for our new visualization:
| | prompt> python scripts/csv_main_dev_as_knowledge_json.py \ |
| | --structure scala_lines.csv --owners scala_main_dev.csv \ |
| | --authors scala_ex_programmers.csv > scala_knowledge_loss.json |
You should now have a scala_knowledge_loss.json ready to visualize the knowledge drain in the Scala project. All we need to do is open the scala_knowledge.html file and point to our own JSON file. The figure shows the resulting knowledge loss.
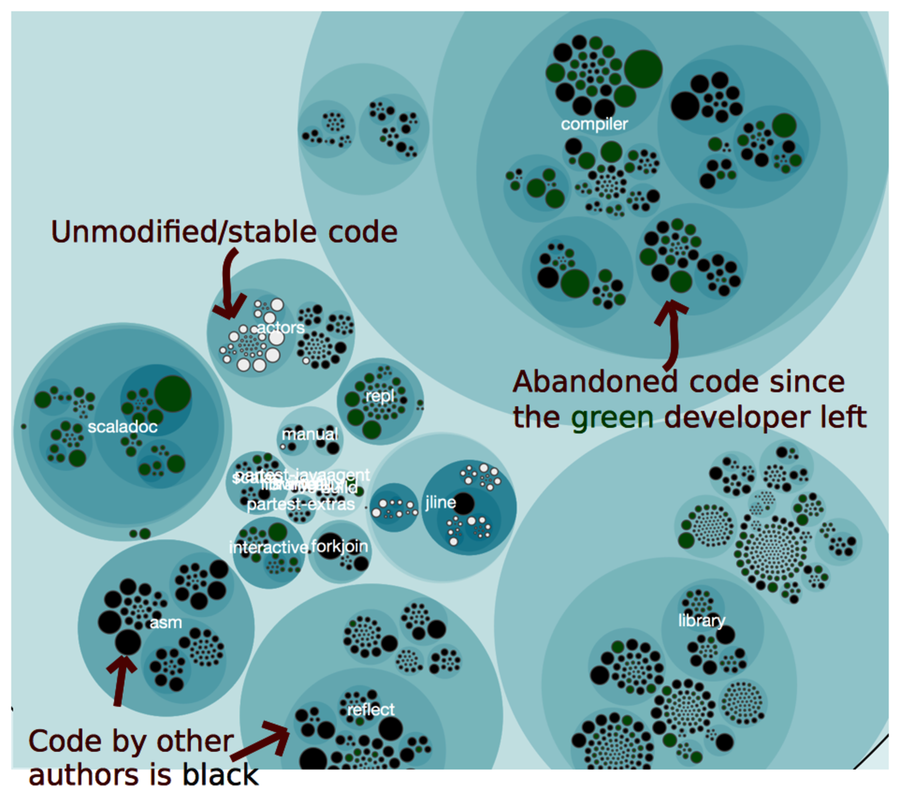
Figure 2. The green color marks code written by a programmer who’s no longer with the company.
A good programmer like Paul Phillips is, of course, impossible to replace. What we can do, however, is to use our knowledge of where the abandoned code is as an input to planning and risk assessments. Since we now know where our blind spots are, we need to allocate extra time in case we plan modifications to them. It’s still hard, but at least we know that up front.
Know the Uses and Misuses
The knowledge map is useful to everyone on a project:
-
We developers use it to identify peers who can help out with code reviews, design discussions, and debugging tasks.
-
New project members use the knowledge as a communication aid.
-
Testers grab a digital copy of the map to find the developer who’s most likely to know about a particular feature.
-
Finally, technical leaders use the information to evaluate how well the system structure fits the team structure, identify knowledge loss, and ensure that we get the natural informal communication channels we need to write great code.
A knowledge map is also a great supplement to a temporal coupling analysis. When you identify components that are temporally coupled, you want to break that dependency. In the meantime, you want to ensure that the main developers of the coupled components work closely together.
Unfortunately, it’s easy to misuse the knowledge map. It’s not a summary of individual productivity, nor is it a way to evaluate people. Used that way, the information does more harm than good. Eventually, we developers learn to game the metric, and the quality of the code and the work environment suffers in the process. Don’t go there.