Table of Contents for
Your Code as a Crime Scene
 Your Code as a Crime Scene
Published by
Pragmatic Bookshelf, 2015
Your Code as a Crime Scene
Published by
Pragmatic Bookshelf, 2015
- Title Page
- Your Code as a Crime Scene
- Your Code as a Crime Scene
- For the Best Reading Experience...
- Table of Contents
- Early praise for Your Code as a Crime Scene
- Foreword by Michael Feathers
- Acknowledgments
- Chapter 1: Welcome!
- About This Book
- Optimize for Understanding
- How to Read This Book
- Toward a New Approach
- Get Your Investigative Tools
- Part 1: Evolving Software
- Chapter 2: Code as a Crime Scene
- Meet the Problems of Scale
- Get a Crash Course in Offender Profiling
- Profiling the Ripper
- Apply Geographical Offender Profiling to Code
- Learn from the Spatial Movement of Programmers
- Find Your Own Hotspots
- Chapter 3: Creating an Offender Profile
- Mining Evolutionary Data
- Automated Mining with Code Maat
- Add the Complexity Dimension
- Merge Complexity and Effort
- Limitations of the Hotspot Criteria
- Use Hotspots as a Guide
- Dig Deeper
- Chapter 4: Analyze Hotspots in Large-Scale Systems
- Analyze a Large Codebase
- Visualize Hotspots
- Explore the Visualization
- Study the Distribution of Hotspots
- Differentiate Between True Problems and False Positives
- Chapter 5: Judge Hotspots with the Power of Names
- Know the Cognitive Advantages of Good Names
- Investigate a Hotspot by Its Name
- Understand the Limitations of Heuristics
- Chapter 6: Calculate Complexity Trends from Your Code’s Shape
- Complexity by the Visual Shape of Programs
- Learn About the Negative Space in Code
- Analyze Complexity Trends in Hotspots
- Evaluate the Growth Patterns
- From Individual Hotspots to Architectures
- Part 2: Dissect Your Architecture
- Chapter 7: Treat Your Code As a Cooperative Witness
- Know How Your Brain Deceives You
- Learn the Modus Operandi of a Code Change
- Use Temporal Coupling to Reduce Bias
- Prepare to Analyze Temporal Coupling
- Chapter 8: Detect Architectural Decay
- Support Your Redesigns with Data
- Analyze Temporal Coupling
- Catch Architectural Decay
- React to Structural Trends
- Scale to System Architectures
- Chapter 9: Build a Safety Net for Your Architecture
- Know What’s in an Architecture
- Analyze the Evolution on a System Level
- Differentiate Between the Level of Tests
- Create a Safety Net for Your Automated Tests
- Know the Costs of Automation Gone Wrong
- Chapter 10: Use Beauty as a Guiding Principle
- Learn Why Attractiveness Matters
- Write Beautiful Code
- Avoid Surprises in Your Architecture
- Analyze Layered Architectures
- Find Surprising Change Patterns
- Expand Your Analyses
- Part 3: Master the Social Aspects of Code
- Chapter 11: Norms, Groups, and False Serial Killers
- Learn Why the Right People Don’t Speak Up
- Understand Pluralistic Ignorance
- Witness Groupthink in Action
- Discover Your Team’s Modus Operandi
- Mine Organizational Metrics from Code
- Chapter 12: Discover Organizational Metrics in Your Codebase
- Let’s Work in the Communication Business
- Find the Social Problems of Scale
- Measure Temporal Coupling over Organizational Boundaries
- Evaluate Communication Costs
- Take It Step by Step
- Chapter 13: Build a Knowledge Map of Your System
- Know Your Knowledge Distribution
- Grow Your Mental Maps
- Investigate Knowledge in the Scala Repository
- Visualize Knowledge Loss
- Get More Details with Code Churn
- Chapter 14: Dive Deeper with Code Churn
- Cure the Disease, Not the Symptoms
- Discover Your Process Loss from Code
- Investigate the Disposal Sites of Killers and Code
- Predict Defects
- Time to Move On
- Chapter 15: Toward the Future
- Let Your Questions Guide Your Analysis
- Take Other Approaches
- Let’s Look into the Future
- Write to Evolve
- Appendix 1: Refactoring Hotspots
- Refactor Guided by Names
- Bibliography
- You May Be Interested In…
Know How Your Brain Deceives You
If you’ve worked in the software industry for some time, you’re probably all too familiar with the following scenario. You are working on a product in which you or your company has invested money. This product will need to improve as users demand new features.
At first, the changes are small. For example, you tweak the FuelInjector algorithm. As you do, you realize that the Engine abstraction depends on details of the FuelInjector algorithm, so you modify the Engine implementation, too. But before you can ship the code, you discover by accident that the logging tool still shows the old values. You need to change the Diagnostics module, too. Phew—you almost missed that one.
If you had run a hotspot analysis on this fictional codebase, Engine and Diagnostics probably would’ve popped up as hotspots. But what the analysis would’ve failed to tell you is that they have an implicit dependency on each other. Changes to one of them means changes in the other. They’re entangled.
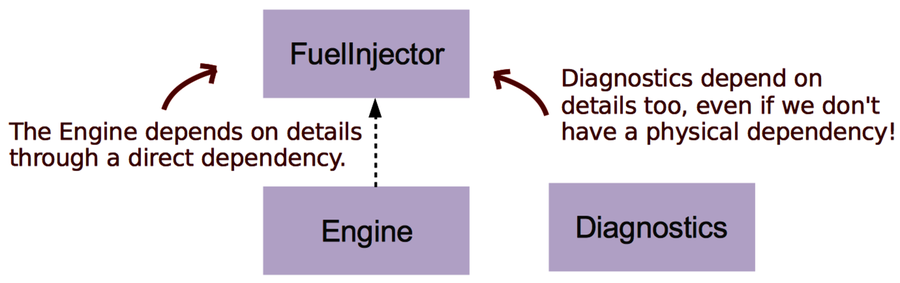
The problem gets worse if there isn’t any explicit dependency between them, as you can see in our example. Perhaps the modules use an intermediate format to communicate over a network or message bus. Or perhaps it’s just copy-paste code that’s been tweaked. In both cases, there’s nothing in the structure of your code that points at the problem. In this scenario, dependency graphs or static-analysis tools won’t help you.
If you spend a lot of time with the system, you’ll eventually find out about these issues. Perhaps you’ll even remember them when you need to, even when you’re under a time crunch, stressed, and not really at your best. Most of us fail sometimes. Our human memory is everything but precise. Follow along to see how it deceives us.
The Paradox of False Memories
But if I’m confident in a memory, it must be correct, right?
Sorry to disappoint you, but no, confidence doesn’t guarantee a correct memory. To see what I mean, let’s look into the scary field of false memories.
A false memory sounds like a paradox. False memories happen when we remember a situation or an event differently from how it actually looked or occurred. It’s a common phenomenon and usually harmless. Perhaps you remember rain on your first day of school, while in fact the sun shone. But sometimes, particularly in criminal investigations, false memories can have serious consequences. Innocent people have gone to jail.
There are multiple reasons why we have false memories. First of all, our memory is constructive, meaning the information we get after an event can shape how we recall the original situation. Our memory organizes the new information as part of the old information, and we forget when we learned each piece. This is what happened in the Father Pagano case we’ll work on in this chapter.
Our memory is also sensitive to suggestibility. In witness interviews, leading questions can alter how the person recalls the original event. Worse, we may trust false memories even when we are explicitly warned about potential misinformation. And if we get positive feedback on our false recall, our future confidence in the (false) memory increases.
Keep a Decision Log | |
|---|---|
|
|
In software, we can always look back at the code and verify our assumptions. But the code doesn’t record the whole story. Your recollection of why you did something or chose a particular solution is sensitive to bias and misinformation, too. That’s why I recommend keeping a decision log to record the rationale behind larger design decisions. The mind is a strange place. |
Meet the Innocent Robber
Our human memory is a constructive process. That means our memories are often sketchy, and we fill out the details ourselves as we recall the memory. This process makes memories sensitive to biases. This is something Father Pagano learned the hard way.
Back in 1979, several towns in Delaware and Pennsylvania were struck by a series of robberies. The salient characteristic of these robberies was the perpetrator’s polite manners. Several witnesses identified a priest named Father Pagano as the robber. Case solved, right?

Father Pagano probably would have gone to jail if it hadn’t been for the true robber, Roland Clouser, and his dramatic confession. Clouser showed up during the trial, and Father Pagano walked free.
Let’s see why all those witnesses were wrong andsee if that tells us something about programming.
Verify Your Intuitions
Roland Clouser and Father Pagano looked nothing alike. So what led the witnesses to make their erroneous statements?
First of all, politeness is a trait many people associate with a priest. This came up because the police mentioned that the suspect might be a priest. To make things worse, of all the suspects the police had, Father Pagano was the only one wearing a clerical collar (see A reconciliation of the evidence on eyewitness testimony: Comments on McCloskey and Zaragoza [TT89]).
The witnesses weren’t necessarily to blame, either. The procedures in how eyewitness testimony was collected were also flawed. As Forensic Psychology [FW08] points out, the “police receive surprisingly little instruction on how to interview cooperative witnesses.”
Law-enforcement agencies in many countries have learned from and improved their techniques thanks to case studies like this. New interview procedures focus on tape-recording conversations, comparing interview information with other pieces of evidence, and avoiding leading questions. These are things we could use as we look at our code, too.
In programming, our code is also cooperative—it’s there to solve our problems. It doesn’t try to hide or deceive. It does what we told it to do. So how do we treat our code as a cooperative witness while avoiding our own memory’s traps?
Reduce Memory Biases with Supporting Evidence | |
|---|---|
|
|
A common memory bias is misattribution. Our memories are often sketchy. We may remember a particularly tricky design change well, but misremember when it occurred or even in what codebase. And as we move on, we forget the problem, and it comes back to haunt us or another developer later. You need supporting data in other situations, too. On larger projects, you can’t see the whole picture by yourself. The temporal coupling analysis we go over in this chapter lets you collect data across teams, subsystems, and related programs, such as automated system tests. Software is so complex that we need all the support we can get. |