Table of Contents for
Your Code as a Crime Scene
 Your Code as a Crime Scene
Published by
Pragmatic Bookshelf, 2015
Your Code as a Crime Scene
Published by
Pragmatic Bookshelf, 2015
- Title Page
- Your Code as a Crime Scene
- Your Code as a Crime Scene
- For the Best Reading Experience...
- Table of Contents
- Early praise for Your Code as a Crime Scene
- Foreword by Michael Feathers
- Acknowledgments
- Chapter 1: Welcome!
- About This Book
- Optimize for Understanding
- How to Read This Book
- Toward a New Approach
- Get Your Investigative Tools
- Part 1: Evolving Software
- Chapter 2: Code as a Crime Scene
- Meet the Problems of Scale
- Get a Crash Course in Offender Profiling
- Profiling the Ripper
- Apply Geographical Offender Profiling to Code
- Learn from the Spatial Movement of Programmers
- Find Your Own Hotspots
- Chapter 3: Creating an Offender Profile
- Mining Evolutionary Data
- Automated Mining with Code Maat
- Add the Complexity Dimension
- Merge Complexity and Effort
- Limitations of the Hotspot Criteria
- Use Hotspots as a Guide
- Dig Deeper
- Chapter 4: Analyze Hotspots in Large-Scale Systems
- Analyze a Large Codebase
- Visualize Hotspots
- Explore the Visualization
- Study the Distribution of Hotspots
- Differentiate Between True Problems and False Positives
- Chapter 5: Judge Hotspots with the Power of Names
- Know the Cognitive Advantages of Good Names
- Investigate a Hotspot by Its Name
- Understand the Limitations of Heuristics
- Chapter 6: Calculate Complexity Trends from Your Code’s Shape
- Complexity by the Visual Shape of Programs
- Learn About the Negative Space in Code
- Analyze Complexity Trends in Hotspots
- Evaluate the Growth Patterns
- From Individual Hotspots to Architectures
- Part 2: Dissect Your Architecture
- Chapter 7: Treat Your Code As a Cooperative Witness
- Know How Your Brain Deceives You
- Learn the Modus Operandi of a Code Change
- Use Temporal Coupling to Reduce Bias
- Prepare to Analyze Temporal Coupling
- Chapter 8: Detect Architectural Decay
- Support Your Redesigns with Data
- Analyze Temporal Coupling
- Catch Architectural Decay
- React to Structural Trends
- Scale to System Architectures
- Chapter 9: Build a Safety Net for Your Architecture
- Know What’s in an Architecture
- Analyze the Evolution on a System Level
- Differentiate Between the Level of Tests
- Create a Safety Net for Your Automated Tests
- Know the Costs of Automation Gone Wrong
- Chapter 10: Use Beauty as a Guiding Principle
- Learn Why Attractiveness Matters
- Write Beautiful Code
- Avoid Surprises in Your Architecture
- Analyze Layered Architectures
- Find Surprising Change Patterns
- Expand Your Analyses
- Part 3: Master the Social Aspects of Code
- Chapter 11: Norms, Groups, and False Serial Killers
- Learn Why the Right People Don’t Speak Up
- Understand Pluralistic Ignorance
- Witness Groupthink in Action
- Discover Your Team’s Modus Operandi
- Mine Organizational Metrics from Code
- Chapter 12: Discover Organizational Metrics in Your Codebase
- Let’s Work in the Communication Business
- Find the Social Problems of Scale
- Measure Temporal Coupling over Organizational Boundaries
- Evaluate Communication Costs
- Take It Step by Step
- Chapter 13: Build a Knowledge Map of Your System
- Know Your Knowledge Distribution
- Grow Your Mental Maps
- Investigate Knowledge in the Scala Repository
- Visualize Knowledge Loss
- Get More Details with Code Churn
- Chapter 14: Dive Deeper with Code Churn
- Cure the Disease, Not the Symptoms
- Discover Your Process Loss from Code
- Investigate the Disposal Sites of Killers and Code
- Predict Defects
- Time to Move On
- Chapter 15: Toward the Future
- Let Your Questions Guide Your Analysis
- Take Other Approaches
- Let’s Look into the Future
- Write to Evolve
- Appendix 1: Refactoring Hotspots
- Refactor Guided by Names
- Bibliography
- You May Be Interested In…
Apply Geographical Offender Profiling to Code
As I learned about geographical offender profiling in criminal psychology, I was struck by its possible applications to software. What if we could devise techniques that let us identify hotspots in large software systems? A hotspot analysis that could narrow down a large system to a few critical modules would be a big win in our profession.
Instead of speculating about potential design problems among million lines of code, geographical profiling would give us a prioritized lists of sections that need refactoring. It would also be dynamic, reflecting shifts in development focus over time.
Explore the Geography of Code
We need a geography of code. Despite its lack of physics, software is easy to visualize. My favorite tool is Code City.[6] It’s fun to work with and matches the offender-profiling metaphor well. The following figure shows a sample city generated by the tool.
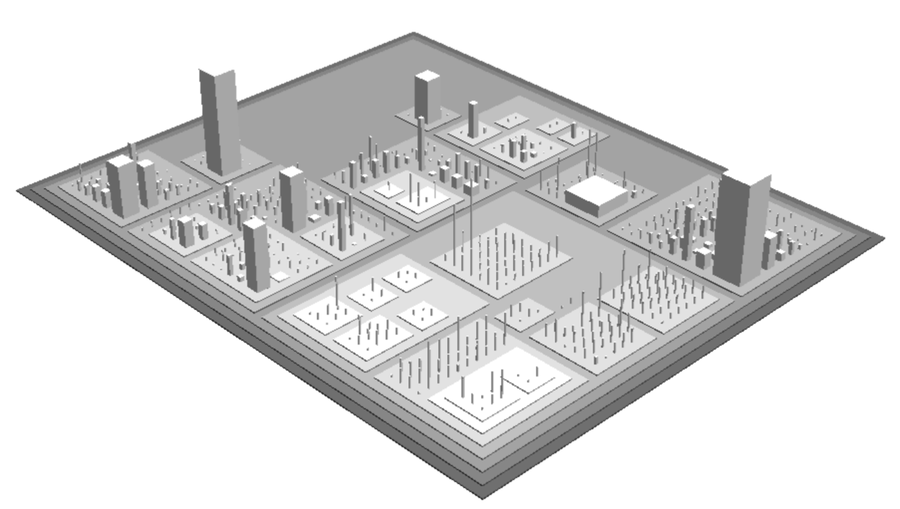
A city block represents a package, and each class is a building. The number of methods defines the height, and the number of attributes specifies the base of the building. Try out Code City, and you’ll notice new patterns you didn’t spot before in the code itself.
Code City is a nice starting point, but it limits us to looking at only object-oriented designs. Today’s software world is increasingly polyglot. Even when you use the same language, you may have complex configurations in scripts, XML, and other markup formats. A geography must present a holistic picture, no matter what languages we choose. We’ll soon explore other options, but before that we need to address a more serious limitation of our data.
Look at the large buildings in our city map again. If that information is all we have, those large buildings would be our hotspots. But there’s nothing in the illustration to indicate on which building we should actually spend our efforts. Perhaps those large classes have been stable for years, are well-tested, and have little developer activity. It doesn’t make sense to start there when other buildings may require immediate attention. In this case, the code doesn’t tell the whole story.

Since Jack the Ripper was never caught, how do we know if the geographical offender profile is any good?
As of September 2014, there were reports of mitochondrial DNA evidence that presumably links one of the suspects, Aaron Kosminski, to a Jack the Ripper victim. There is a lot of controversy and debate around the claim, so let me introduce you to another likely suspect: James Maybrick.
|
In the early 1990s, a diary supposedly written by Liverpool cotton merchant James Maybrick surfaced. In this diary, Maybrick claimed to be the Ripper. Since its publication in The Diary of Jack the Ripper [Har10], thousands of Ripperologists around the world have tried to expose the diary as a forgery using techniques such as handwriting analysis and chemical ink tests. No one has yet managed to prove the diary is fake, and its legitimacy is still under dispute. |

|
The interesting part about the diary for us is the fact that Maybrick wrote that he used to rent a room on Middlesex Street whenever he visited London. You can see Middlesex Street right inside our hotspot.
But what about Aaron Kosminiski’s homebase? It, too, fits the profile, although not as well as Maybrick’s does. Kosminski’s probable home at the time of the murders is just a little bit east of the high-probability hotspot area.