
Conventionally, there are two methods to route requests to replicated components:
-
Load balancing: A load balancer sits in-between the client and the server instances, intercepting the requests and distributing them among all instances:

The way requests are distributed depends on the load balancing algorithm used. Apart from "random" selection, the simplest algorithm is the round-robin algorithm. This is where requests are sequentially routed to each instance in order. For example, if there are two backend servers, A and B, the first request will be routed to A, the second to B, the third back to A, the fourth to B, and so on. This results in requests being evenly distributed:
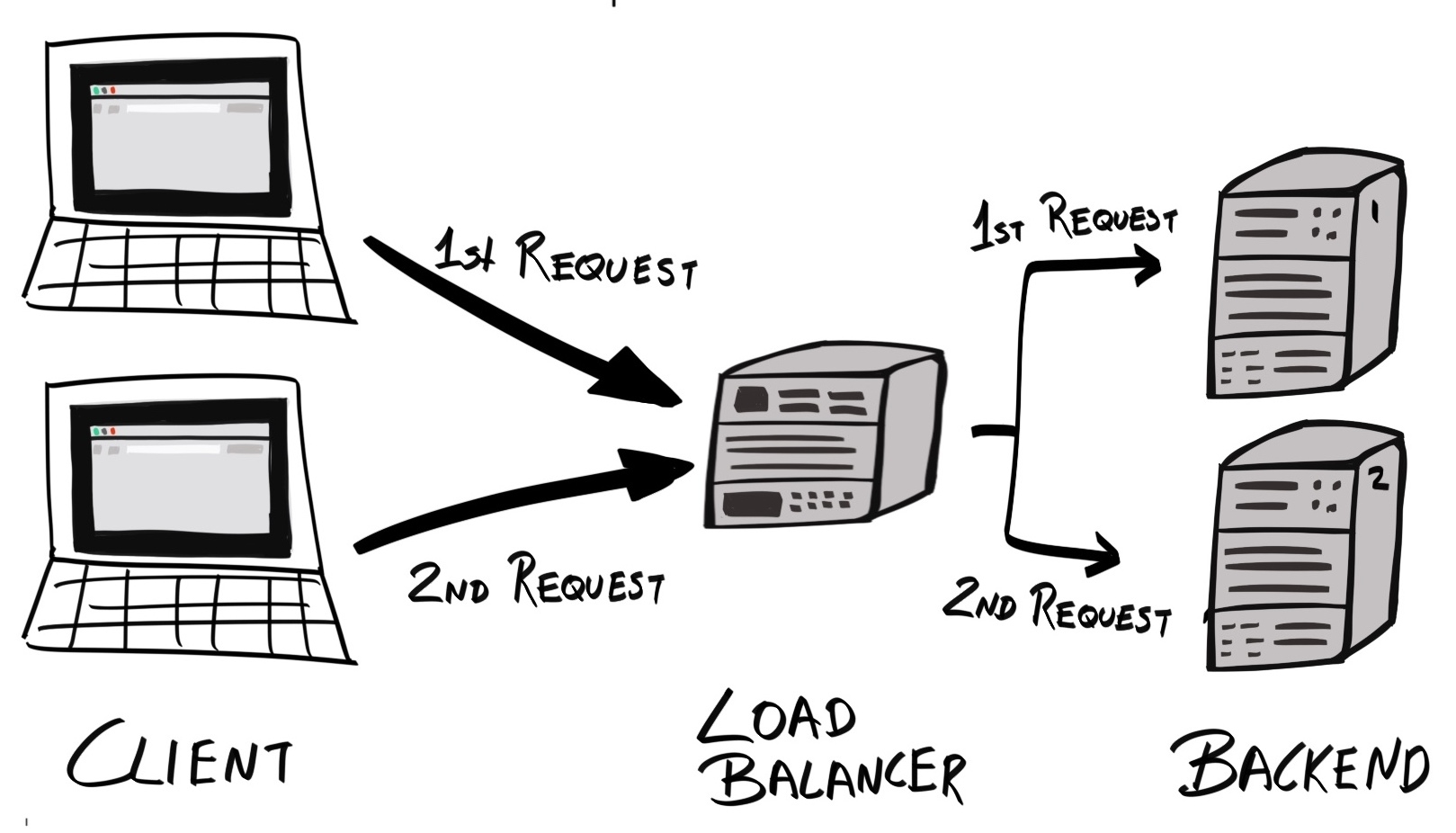
While round-robin is the simplest scheme to implement, it assumes that all nodes are equal – in terms of available resources, current load, and network congestion. This is often not the case. Therefore, dynamic round-robin is often used, which will route more traffic to hosts with more available resources and/or lower load.
-
Failover: Requests are routed to a single primary instance. If and when the primary instance fails, subsequent requests are routed to a different secondary, or standby, instance:
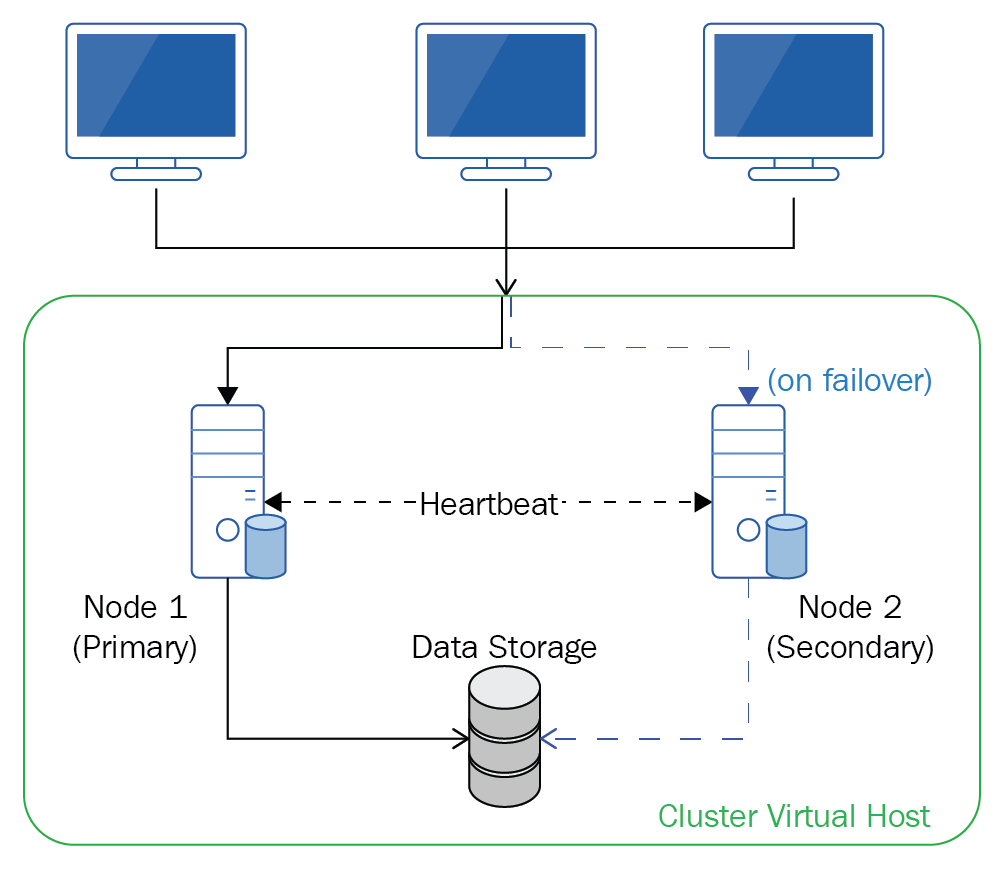
As with all things, there are pros and cons of each method:
- Resource Utilization: With the failover approach, only a single instance is running at any one time; this means you'll be paying for server resources that do not contribute to the normal running of your application, nor improve its performance or throughput. On the other hand, the objective of load balancing is to maximize resource usage; providing high availability is simply a useful side effect.
- Statefulness: Sometimes, failover is the only viable method. Many real-world, perhaps legacy, applications are stateful, and the state can become corrupted if multiple instances of the application are running at the same time. Although you can refactor the application to cater for this, it's still a fact that not all applications can be served behind a load balancer.
- Scalability: With failover, to improve performance and throughput, you must scale the primary node vertically (by increasing its resources). With load balancing, you can scale both vertically and horizontally (by adding more machines).
Since our application is stateless, using a distributed load balancer makes more sense as it allows us to fully utilize all resources and provide better performance.