
While the Discovery Service holds information about the state and location of each service, it does not make the decision of which host/node the service should be deployed on. This process is known as host selection and is the job of a scheduler:
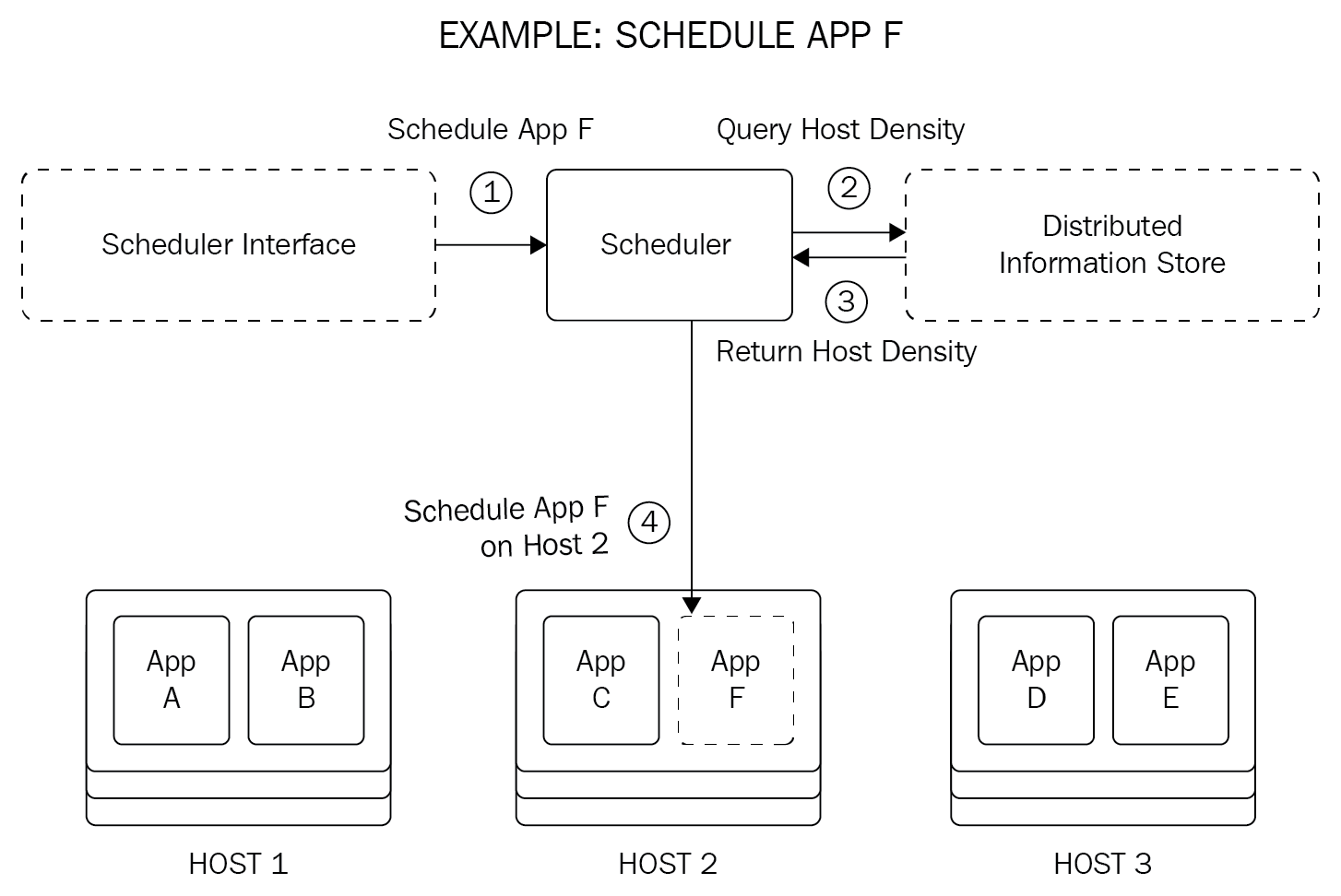
The scheduler's decision can be based on a set of rules, called policies, which takes into account the following:
- The nature of the request.
- Cluster configuration/settings.
- Host density: An indication of how busy a the host system on the node is. If there are multiple nodes inside the cluster, we should prefer to deploy any new services on a node with the lowest host density. This information can be obtained from the Discovery Service, which holds information about all deployed services.
- Service (anti-)affinity: Whether two services should be deployed together on the same host. This depends on:
- Redundancy requirements: The same application should not be deployed on the same node(s) if there are other nodes that are not running the service. For instance, if our API service has already been deployed on two of three hosts, the scheduler may prefer to deploy on the remaining host to ensure maximum redundancy.
- Data locality: The scheduler should try placing computation code next to the data it needs to consume to reduce network latency.
- Resource requirements: Of existing services running on nodes, as well as the service to be deployed
- Hardware/software constraints
- Other policies/rules set by the cluster administrator