Table of Contents for
The IDA Pro Book, 2nd Edition
 The IDA Pro Book, 2nd Edition
Published by
No Starch Press, 2011
The IDA Pro Book, 2nd Edition
Published by
No Starch Press, 2011
- Cover
- The IDA Pro Book
- PRAISE FOR THE FIRST EDITION OF THE IDA PRO BOOK
- Acknowledgments
- Introduction
- I. Introduction to IDA
- 1. Introduction to Disassembly
- The What of Disassembly
- The Why of Disassembly
- The How of Disassembly
- Summary
- 2. Reversing and Disassembly Tools
- Summary Tools
- Deep Inspection Tools
- Summary
- 3. IDA Pro Background
- Obtaining IDA Pro
- IDA Support Resources
- Your IDA Installation
- Thoughts on IDA’s User Interface
- Summary
- II. Basic IDA Usage
- 4. Getting Started with IDA
- IDA Database Files
- Introduction to the IDA Desktop
- Desktop Behavior During Initial Analysis
- IDA Desktop Tips and Tricks
- Reporting Bugs
- Summary
- 5. IDA Data Displays
- Secondary IDA Displays
- Tertiary IDA Displays
- Summary
- 6. Disassembly Navigation
- Stack Frames
- Searching the Database
- Summary
- 7. Disassembly Manipulation
- Commenting in IDA
- Basic Code Transformations
- Basic Data Transformations
- Summary
- 8. Datatypes and Data Structures
- Creating IDA Structures
- Using Structure Templates
- Importing New Structures
- Using Standard Structures
- IDA TIL Files
- C++ Reversing Primer
- Summary
- 9. Cross-References and Graphing
- IDA Graphing
- Summary
- 10. The Many Faces of IDA
- Using IDA’s Batch Mode
- Summary
- III. Advanced IDA Usage
- 11. Customizing IDA
- Additional IDA Configuration Options
- Summary
- 12. Library Recognition Using FLIRT Signatures
- Applying FLIRT Signatures
- Creating FLIRT Signature Files
- Summary
- 13. Extending IDA’s Knowledge
- Augmenting Predefined Comments with loadint
- Summary
- 14. Patching Binaries and Other IDA Limitations
- IDA Output Files and Patch Generation
- Summary
- IV. Extending IDA’s Capabilities
- 15. IDA Scripting
- The IDC Language
- Associating IDC Scripts with Hotkeys
- Useful IDC Functions
- IDC Scripting Examples
- IDAPython
- IDAPython Scripting Examples
- Summary
- 16. The IDA Software Development Kit
- The IDA Application Programming Interface
- Summary
- 17. The IDA Plug-in Architecture
- Building Your Plug-ins
- Installing Plug-ins
- Configuring Plug-ins
- Extending IDC
- Plug-in User Interface Options
- Scripted Plug-ins
- Summary
- 18. Binary Files and IDA Loader Modules
- Manually Loading a Windows PE File
- IDA Loader Modules
- Writing an IDA Loader Using the SDK
- Alternative Loader Strategies
- Writing a Scripted Loader
- Summary
- 19. IDA Processor Modules
- The Python Interpreter
- Writing a Processor Module Using the SDK
- Building Processor Modules
- Customizing Existing Processors
- Processor Module Architecture
- Scripting a Processor Module
- Summary
- V. Real-World Applications
- 20. Compiler Personalities
- RTTI Implementations
- Locating main
- Debug vs. Release Binaries
- Alternative Calling Conventions
- Summary
- 21. Obfuscated Code Analysis
- Anti–Dynamic Analysis Techniques
- Static De-obfuscation of Binaries Using IDA
- Virtual Machine-Based Obfuscation
- Summary
- 22. Vulnerability Analysis
- After-the-Fact Vulnerability Discovery with IDA
- IDA and the Exploit-Development Process
- Analyzing Shellcode
- Summary
- 23. Real-World IDA Plug-ins
- IDAPython
- collabREate
- ida-x86emu
- Class Informer
- MyNav
- IdaPdf
- Summary
- VI. The IDA Debugger
- 24. The IDA Debugger
- Basic Debugger Displays
- Process Control
- Automating Debugger Tasks
- Summary
- 25. Disassembler/Debugger Integration
- IDA Databases and the IDA Debugger
- Debugging Obfuscated Code
- IdaStealth
- Dealing with Exceptions
- Summary
- 26. Additional Debugger Features
- Debugging with Bochs
- Appcall
- Summary
- A. Using IDA Freeware 5.0
- Using IDA Freeware
- B. IDC/SDK Cross-Reference
- Index
- About the Author
Now that you’re well versed in the purposes of disassembly, it’s time to move on to how the process actually works. Consider a typical daunting task faced by a disassembler: Take these 100KB, distinguish code from data, convert the code to assembly language for display to a user, and please don’t miss anything along the way. We could tack any number of special requests on the end of this, such as asking the disassembler to locate functions, recognize jump tables, and identify local variables, making the disassembler’s job that much more difficult.
In order to accommodate all of our demands, any disassembler will need to pick and choose from a variety of algorithms as it navigates through the files that we feed it. The quality of the generated disassembly listing will be directly related to the quality of the algorithms utilized and how well they have been implemented. In this section we will discuss two of the fundamental algorithms in use today for disassembling machine code. As we present these algorithms, we will also point out their shortcomings in order to prepare you for situations in which your disassembler appears to fail. By understanding a disassembler’s limitations, you will be able to manually intervene to improve the overall quality of the disassembly output.
For starters, let’s develop a simple algorithm for accepting machine language as input and producing assembly language as output. In doing so, we will gain an understanding of the challenges, assumptions, and compromises that underlie an automated disassembly process.
- Step 1
The first step in the disassembly process is to identify a region of code to disassemble. This is not necessarily as straightforward as it may seem. Instructions are generally mixed with data, and it is important to distinguish between the two. In the most common case, disassembly of an executable file, the file will conform to a common format for executable files such as the Portable Executable (PE) format used on Windows or the Executable and Linking Format (ELF) common on many Unix-based systems. These formats typically contain mechanisms (often in the form of hierarchical file headers) for locating the sections of the file that contain code and entry points[2] into that code.
- Step 2
Given an initial address of an instruction, the next step is to read the value contained at that address (or file offset) and perform a table lookup to match the binary opcode value to its assembly language mnemonic. Depending on the complexity of the instruction set being disassembled, this may be a trivial process, or it may involve several additional operations such as understanding any prefixes that may modify the instruction’s behavior and determining any operands required by the instruction. For instruction sets with variable-length instructions, such as the Intel x86, additional instruction bytes may need to be retrieved in order to completely disassemble a single instruction.
- Step 3
Once an instruction has been fetched and any required operands decoded, its assembly language equivalent is formatted and output as part of the disassembly listing. It may be possible to choose from more than one assembly language output syntax. For example, the two predominant formats for x86 assembly language are the Intel format and the AT&T format.
- Step 4
Following the output of an instruction, we need to advance to the next instruction and repeat the previous process until we have disassembled every instruction in the file.
Various algorithms exist for determining where to begin a disassembly, how to choose the next instruction to be disassembled, how to distinguish code from data, and how to determine when the last instruction has been disassembled. The two predominant disassembly algorithms are linear sweep and recursive descent.
The linear sweep disassembly algorithm takes a very straightforward approach to locating instructions to disassemble: Where one instruction ends, another begins. As a result, the most difficult decision faced is where to begin. The usual solution is to assume that everything contained in sections of a program marked as code (typically specified by the program file’s headers) represents machine language instructions. Disassembly begins with the first byte in a code section and moves, in a linear fashion, through the section, disassembling one instruction after another until the end of the section is reached. No effort is made to understand the program’s control flow through recognition of nonlinear instructions such as branches.
During the disassembly process, a pointer can be maintained to mark the beginning of the instruction currently being disassembled. As part of the disassembly process, the length of each instruction is computed and used to determine the location of the next instruction to be disassembled. Instruction sets with fixed-length instructions (MIPS, for example) are somewhat easier to disassemble, as locating subsequent instructions is straightforward.
The main advantage of the linear sweep algorithm is that it provides complete coverage of a program’s code sections. One of the primary disadvantages of the linear sweep method is that it fails to account for the fact that data may be comingled with code. This is evident in Example 1-1, which shows the output of a function disassembled with a linear sweep disassembler. This function contains a switch statement, and the compiler used in this case has elected to implement the switch using a jump table. Furthermore, the compiler has elected to embed the jump table within the function itself. The jmp statement at 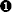 ,
, 401250, references an address table starting at 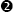 ,
, 401257. Unfortunately, the disassembler treats as if it were an instruction and incorrectly generates the corresponding assembly language representation:
Example 1-1. Linear sweep disassembly
40123f: 55 push ebp 401240: 8b ec mov ebp,esp 401242: 33 c0 xor eax,eax 401244: 8b 55 08 mov edx,DWORD PTR [ebp+8] 401247: 83 fa 0c cmp edx,0xc 40124a: 0f 87 90 00 00 00 ja 0x4012e0
If we examine successive 4-byte groups as little-endian[3] values beginning at , we see that each represents a pointer to a nearby address that is in fact the destination for one of various jumps (004012e0, 0040128b, 00401290, . . .). Thus, the loopne instruction at is not an instruction at all. Instead, it indicates a failure of the linear sweep algorithm to properly distinguish embedded data from code.
Linear sweep is used by the disassembly engines contained in the GNU debugger (gdb), Microsoft’s WinDbg debugger, and the objdump utility.
Recursive descent takes a different approach to locating instructions. Recursive descent focuses on the concept of control flow, which determines whether an instruction should be disassembled or not based on whether it is referenced by another instruction. To understand recursive descent, it is helpful to classify instructions according to how they affect the CPU instruction pointer.
Sequential flow instructions pass execution to the instruction that immediately follows. Examples of sequential flow instructions include simple arithmetic instructions, such as add; register-to-memory transfer instructions, such as mov; and stack-manipulation operations, such as push and pop. For such instructions, disassembly proceeds as with linear sweep.
Conditional branching instructions, such as the x86 jnz, offer two possible execution paths. If the condition evaluates to true, the branch is taken, and the instruction pointer must be changed to reflect the target of the branch. However, if the condition is false, execution continues in a linear fashion, and a linear sweep methodology can be used to disassemble the next instruction. As it is generally not possible in a static context to determine the outcome of a conditional test, the recursive descent algorithm disassembles both paths, deferring disassembly of the branch target instruction by adding the address of the target instruction to a list of addresses to be disassembled at a later point.
Unconditional branches do not follow the linear flow model and therefore are handled differently by the recursive descent algorithm. As with the sequential flow instructions, execution can flow to only one instruction; however, that instruction need not immediately follow the branch instruction. In fact, as seen in Example 1-1, there is no requirement at all for an instruction to immediately follow an unconditional branch. Therefore, there is no reason to disassemble the bytes that follow an unconditional branch.
A recursive descent disassembler will attempt to determine the target of the unconditional jump and add the destination address to the list of addresses that have yet to be explored. Unfortunately, some unconditional branches can cause problems for recursive descent disassemblers. When the target of a jump instruction depends on a runtime value, it may not be possible to determine the destination of the jump using static analysis. The x86 instruction jmp eax demonstrates this problem. The eax register contains a value only when the program is actually running. Since the register contains no value during static analysis, we have no way to determine the target of the jump instruction, and consequently, we have no way to determine where to continue the disassembly process.
Function call instructions operate in a manner very similar to unconditional jump instructions (including the inability of the disassembler to determine the target of instructions such as call eax), with the additional expectation that execution usually returns to the instruction immediately following the call instruction once the function completes. In this regard, they are similar to conditional branch instructions in that they generate two execution paths. The target address of the call instruction is added to a list for deferred disassembly, while the instruction immediately following the call is disassembled in a manner similar to linear sweep.
Recursive descent can fail if programs do not behave as expected when returning from called functions. For example, code in a function can deliberately manipulate the return address of that function so that upon completion, control returns to a location different from the one expected by the disassembler. A simple example is shown in the following incorrect listing, where function foo simply adds 1 to the return address before returning to the caller.
foo proc near FF 04 24 inc dword ptr [esp] ; increments saved return addr C3 retn foo endp ; ------------------------------------- bar: E8 F7 FF FF FF call foo 05 89 45 F8 90
As a result, control does not actually pass to the add instruction at following the call to foo. A proper disassembly appears below:
foo proc near FF 04 24 inc dword ptr [esp] C3 retn foo endp ; ------------------------------------- bar: E8 F7 FF FF FF call foo 05 db 5 ;formerly the first byte of the add instruction 89 45 F8
This listing more clearly shows the actual flow of the program in which function foo actually returns to the mov instruction at . It is important to understand that a linear sweep disassembler will also fail to properly disassemble this code, though for slightly different reasons.
In some cases, the recursive descent algorithm runs out of paths to follow. A function return instruction (x86 ret, for example) offers no information about what instruction will be executed next. If the program were actually running, an address would be taken from the top of the runtime stack, and execution would resume at that address. Disassemblers do not have the benefit of access to a stack. Instead, disassembly abruptly comes to a halt. It is at this point that the recursive descent disassembler turns to the list of addresses it has been setting aside for deferred disassembly. An address is removed from this list, and the disassembly process is continued from this address. This is the recursive process that lends the disassembly algorithm its name.
One of the principle advantages of the recursive descent algorithm is its superior ability to distinguish code from data. As a control flow–based algorithm, it is much less likely to incorrectly disassemble data values as code. The main disadvantage of recursive descent is the inability to follow indirect code paths, such as jumps or calls, which utilize tables of pointers to look up a target address. However, with the addition of some heuristics to identify pointers to code, recursive descent disassemblers can provide very complete code coverage and excellent recognition of code versus data. Example 1-2 shows the output of a recursive descent disassembler used on the same switch statement shown earlier in Example 1-1.
Example 1-2. Recursive descent disassembly
0040123F push ebp 00401240 mov ebp, esp 00401242 xor eax, eax 00401244 mov edx, [ebp+arg_0] 00401247 cmp edx, 0Ch ; switch 13 cases 0040124A ja loc_4012E0 ; default 0040124A ; jumptable 00401250 case 0 00401250 jmp ds:off_401257[edx*4] ; switch jump 00401250 ; --------------------------------------------------- 00401257 off_401257: 00401257 dd offset loc_4012E0 ; DATA XREF: sub_40123F+11r 00401257 dd offset loc_40128B ; jump table for switch statement 00401257 dd offset loc_401290 00401257 dd offset loc_401295 00401257 dd offset loc_40129A 00401257 dd offset loc_4012A2 00401257 dd offset loc_4012AA 00401257 dd offset loc_4012B2 00401257 dd offset loc_4012BA 00401257 dd offset loc_4012C2 00401257 dd offset loc_4012CA 00401257 dd offset loc_4012D2 00401257 dd offset loc_4012DA 0040128B ; --------------------------------------------------- 0040128B 0040128B loc_40128B: ; CODE XREF: sub_40123F+11j 0040128B ; DATA XREF: sub_40123F:off_401257o 0040128B mov eax, [ebp+arg_4] ; jumptable 00401250 case 1 0040128E jmp short loc_4012E0 ; default 0040128E ; jumptable 00401250 case 0
Note that the table of jump destinations has been recognized and formatted accordingly. IDA Pro is the most prominent example of a recursive descent disassembler. An understanding of the recursive descent process will help us recognize situations in which IDA may produce less than optimal disassemblies and allow us to develop strategies to improve IDA’s output.
[2] A program entry point is simply the address of the instruction to which the operating system passes control once a program has been loaded into memory.
[3] A CPU is described as either big-endian or little-endian depending on whether the CPU saves the most significant byte of a multibyte value first (big-endian) or whether it stores the least significant byte first (little-endian).