
We utilized four different ways to use std::search in order to get exactly the same result. Which one should we prefer in what situation?
Let's assume our large string within which we search the pattern is called s, and the pattern is called p. Then, std::search(begin(s), end(s), begin(p), end(p)); and std::search(begin(s), end(s), default_searcher(begin(p), end(p)); do exactly the same thing.
The other searcher function objects are implemented with more sophisticated search algorithms:
- std::default_searcher: This redirects to legacy std::search implementation
- std::boyer_moore_searcher: This uses the Boyer-Moore search algorithm
- std::boyer_moore_horspool_searcher: This analogously uses the Boyer-Moore-Horspool algorithm
What makes the other algorithms so special? The Boyer-Moore algorithm was developed with a specific idea--the search pattern is compared with the string, beginning at the pattern's end, from right to left. If the character in the search string differs from the character in the pattern at the overlay position and does not even occur in the pattern, then it is clear that the pattern can be shifted over the search string by its full length. Have a look at the following diagram, where this happens in step 1. If the character being currently compared differs from the pattern's character at this position but is contained by the pattern, then the algorithm knows by how many characters the pattern needs to be shifted to the right in order to correctly align to at least that character, and then, it starts over with the right-to-left comparison. In the diagram, this happens in step 2. This way, the Boyer-Moore algorithm can omit a whole lot of unnecessary comparisons, compared with a naive search implementation:
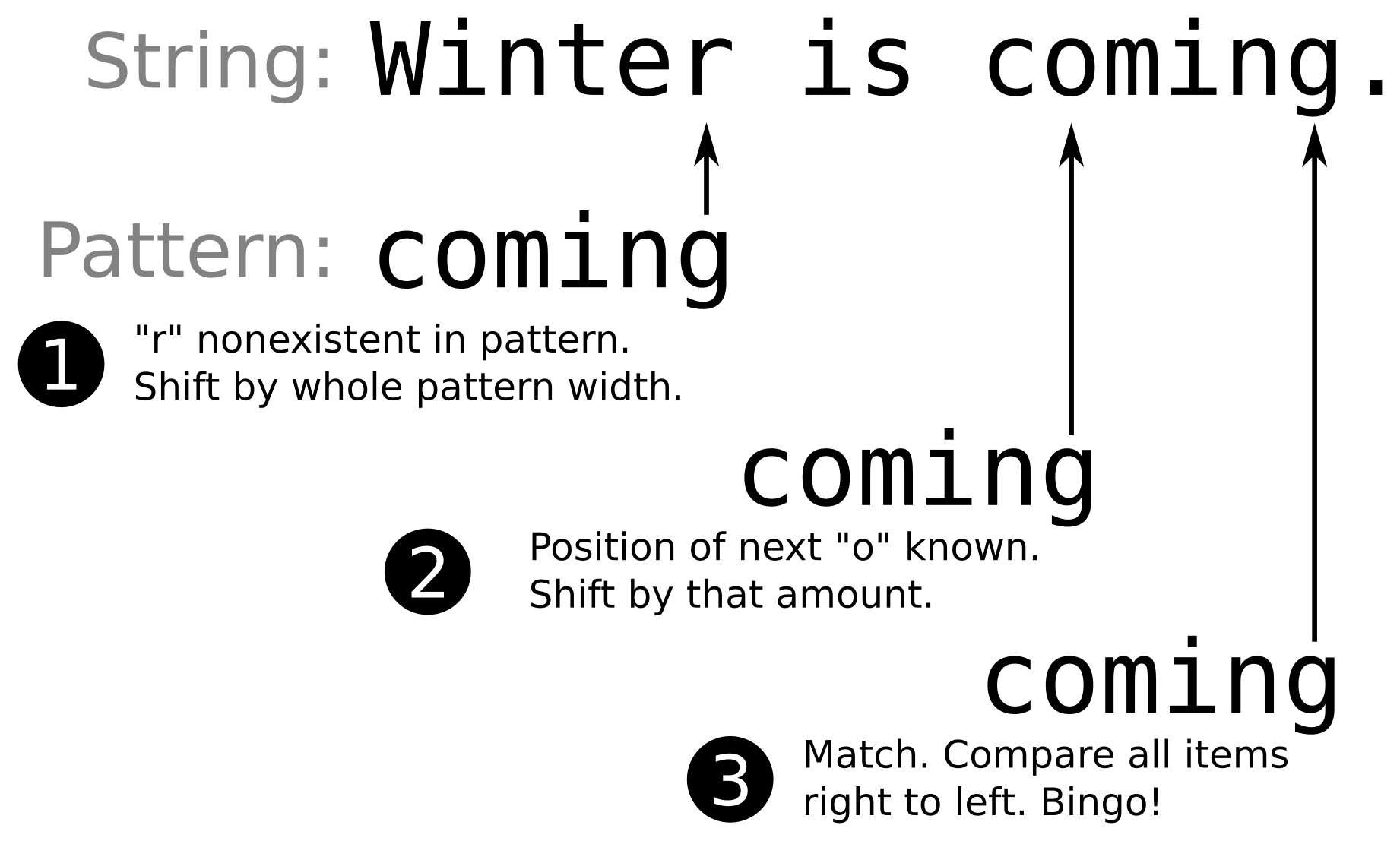
Of course, this would have become the new default search algorithm if it hadn't brought its own trade-offs. It is faster than the default algorithm, but it needs fast lookup data structures in order to determine which characters are contained in the search pattern and at which offset they are located. The compiler will select differently complex implementations of those, depending on the underlying types of which the pattern consists (varying between hash maps for complex types and primitive lookup tables for types such as char). In the end, this means that the default search implementation will be faster if the search string is not too large. If the search itself takes some significant time, then the Boyer-Moore algorithm can lead to performance gains in the dimension of a constant factor.
The Boyer-Moore-Horspool algorithm is a simplification of the Boyer-Moore algorithm. It drops the bad character rule, which leads to shifts of the whole pattern width if a search string character that does not occur in the pattern string is found. The trade-off of this decision is that it is slightly slower than the unmodified version of Boyer-Moore, but it also needs fewer data structures for its operation.