
Regular expressions (or regex in short) are extremely useful. They can look really cryptic, but it is worth learning how they work. A short regex can spare us writing many lines of code if we did the matching manually.
In this recipe, we first instantiated an object of type regex. We fed its constructor with a string that describes a regular expression. A very simple regular expression is ".", which matches every character because a dot is the regex wildcard. If we write "a", then this matches only on the 'a' characters. If we write "ab*", then this means "one a, and zero or arbitrarily many b characters". And so on. Regular expressions are another large topic, and there are great explanations on Wikipedia and other websites or literature.
Let's have another look at our regular expression that matches what we assume to be HTML links. A simple HTML link can look like <a href="some_url.com/foo">A great link</a>. We want the some_url.com/foo part, as well as A great link. So we came up with the following regular expression, which contains groups for matching substrings:
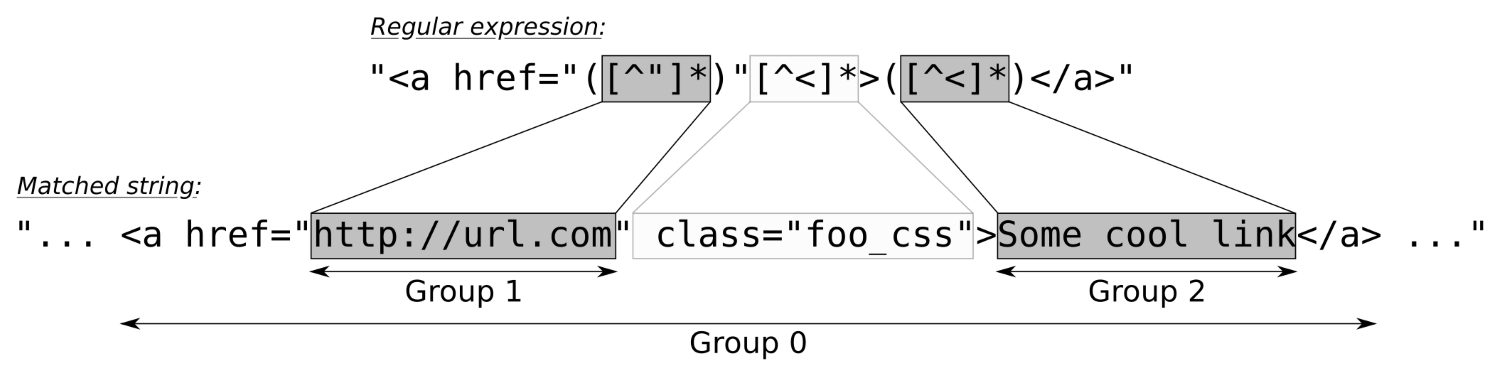
The whole match itself is always Group 0. In this case, this is the full <a href ..... </a> string. The quoted href-part that contains the URL being linked to is Group 1. The ( ) parentheses in the regular expression define such a . The other one is the part between the <a ...> and </a>, which contains the link description.
There are various STL functions that accept regex objects, but we directly used a regex token iterator adapter, which is a high-level abstraction that uses std::regex_search under the hood in order to automate recurring matching work. We instantiated it like this:
sregex_token_iterator it {begin(in), end(in), link_re, {1, 2}};
The begin and end part denote our input string over which the regex token iterator shall iterate and match all links. The is, of course, the complex regular expression we implemented to match links. The {1, 2} part is the next complicated looking thing. It instructs the token iterator to stop on each full match and first yield Group 1, then after incrementing the iterator to yield Group 2, and after incrementing it again, it would finally search for the next match in the string. This somewhat intelligent behavior really spares us some code lines.
Let's have a look at another example to make sure we got the idea. Let's imagine the regular expression, "a(b*)(c*)". It will match strings that contain an a character, then none or arbitrarily many b characters, and then none or arbitrarily many c characters:
const string s {" abc abbccc "};
const regex re {"a(b*)(c*)"};
sregex_token_iterator it {begin(s), end(s), re, {1, 2}};
print( *it ); // prints b
++it;
print( *it ); // prints c
++it;
print( *it ); // prints bb
++it;
print( *it ); // prints ccc
There is also the std::regex_iterator class, which emits the substrings that are between regex matches.