
This program basically revolves around two functions: compress and decompress.
The decompress function is really simple because it only consists of variable declarations, a line of code, which actually does something, and the following return statement. The code line which does something is the following one:
while (ss >> c >> n) { r << string(n, c); }
It continuously reads the character, c, and the counter variable, n, out of the string stream, ss. The stringstream class hides a lot of string parsing magic from us at this point. While that succeeds, it constructs a decompressed string chunk into the string stream, from which the final result string can be returned back to the caller of decompress. If c = 'a' and n = 5, the expression string(n, c) will result in a string with the content, "aaaaa".
The compress function is more complex. We also wrote a little helper function for it. We called that helper function occurences. So, let's first have a glance at occurrences. The following diagram shows how it works:
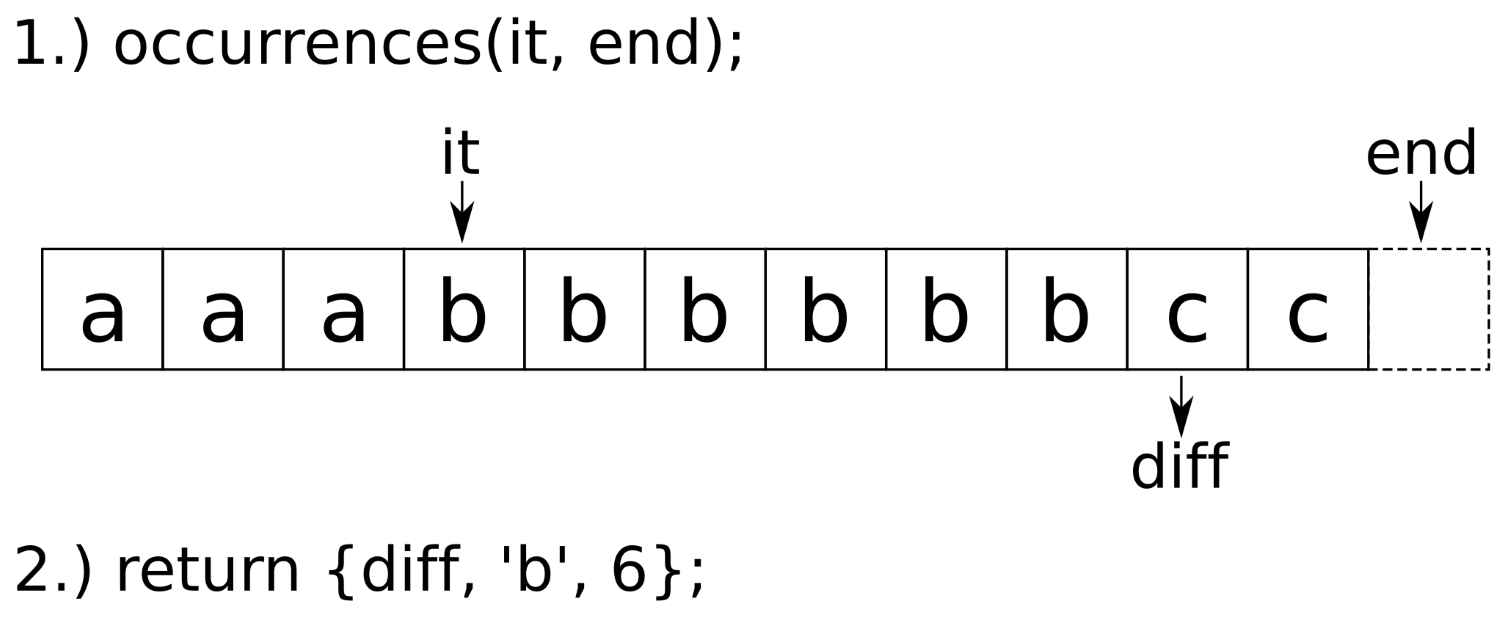
The occurences function accepts two parameters: an iterator pointing to the beginning of a character sequence within a range and the end iterator of that range. Using find_if, it finds the first character that is different from the character initially being pointed at. In the diagram, this is the iterator, diff. The difference between that new position and the old iterator position is the number of equal items (diff - it equals 6 in the diagram). After calculating this information, the diff iterator can be reused in order to execute the next search. Therefore, we pack diff, the character of the subrange, and the length of the subrange into a tuple and return it.
With the information lined up like this, we can jump from subrange to subrange and push the intermediate results into the compressed target string:
for (auto it (begin(s)); it != end_it;) {
const auto [next_diff, c, n] (occurrences(it, end_it));
r << c << n;
it = next_diff;
}