Table of Contents for
PHP 7: Real World Application Development
 PHP 7: Real World Application Development
Published by
Packt Publishing, 2016
PHP 7: Real World Application Development
Published by
Packt Publishing, 2016
- Cover
- Table of Contents
- PHP 7: Real World Application Development
- PHP 7: Real World Application Development
- PHP 7: Real World Application Development
- Credits
- Preface
- What you need for this learning path
- Who this learning path is for
- Reader feedback
- Customer support
- 1. Module 1
- 1. Building a Foundation
- PHP 7 installation considerations
- Using the built-in PHP web server
- Defining a test MySQL database
- Installing PHPUnit
- Implementing class autoloading
- Hoovering a website
- Building a deep web scanner
- Creating a PHP 5 to PHP 7 code converter
- 2. Using PHP 7 High Performance Features
- Understanding the abstract syntax tree
- Understanding differences in parsing
- Understanding differences in foreach() handling
- Improving performance using PHP 7 enhancements
- Iterating through a massive file
- Uploading a spreadsheet into a database
- Recursive directory iterator
- 3. Working with PHP Functions
- Developing functions
- Hinting at data types
- Using return value data typing
- Using iterators
- Writing your own iterator using generators
- 4. Working with PHP Object-Oriented Programming
- Developing classes
- Extending classes
- Using static properties and methods
- Using namespaces
- Defining visibility
- Using interfaces
- Using traits
- Implementing anonymous classes
- 5. Interacting with a Database
- Using PDO to connect to a database
- Building an OOP SQL query builder
- Handling pagination
- Defining entities to match database tables
- Tying entity classes to RDBMS queries
- Embedding secondary lookups into query results
- Implementing jQuery DataTables PHP lookups
- 6. Building Scalable Websites
- Creating a generic form element generator
- Creating an HTML radio element generator
- Creating an HTML select element generator
- Implementing a form factory
- Chaining $_POST filters
- Chaining $_POST validators
- Tying validation to a form
- 7. Accessing Web Services
- Converting between PHP and XML
- Creating a simple REST client
- Creating a simple REST server
- Creating a simple SOAP client
- Creating a simple SOAP server
- 8. Working with Date/Time and International Aspects
- Using emoticons or emoji in a view script
- Converting complex characters
- Getting the locale from browser data
- Formatting numbers by locale
- Handling currency by locale
- Formatting date/time by locale
- Creating an HTML international calendar generator
- Building a recurring events generator
- Handling translation without gettext
- 9. Developing Middleware
- Authenticating with middleware
- Using middleware to implement access control
- Improving performance using the cache
- Implementing routing
- Making inter-framework system calls
- Using middleware to cross languages
- 10. Looking at Advanced Algorithms
- Using getters and setters
- Implementing a linked list
- Building a bubble sort
- Implementing a stack
- Building a binary search class
- Implementing a search engine
- Displaying a multi-dimensional array and accumulating totals
- 11. Implementing Software Design Patterns
- Creating an array to object hydrator
- Building an object to array hydrator
- Implementing a strategy pattern
- Defining a mapper
- Implementing object-relational mapping
- Implementing the Pub/Sub design pattern
- 12. Improving Web Security
- Filtering $_POST data
- Validating $_POST data
- Safeguarding the PHP session
- Securing forms with a token
- Building a secure password generator
- Safeguarding forms with a CAPTCHA
- Encrypting/decrypting without mcrypt
- 13. Best Practices, Testing, and Debugging
- Using Traits and Interfaces
- Universal exception handler
- Universal error handler
- Writing a simple test
- Writing a test suite
- Generating fake test data
- Customizing sessions using session_start parameters
- A. Defining PSR-7 Classes
- Implementing PSR-7 value object classes
- Developing a PSR-7 Request class
- Defining a PSR-7 Response class
- 2. Module 2
- 1. Setting Up the Environment
- Setting up Debian or Ubuntu
- Setting up CentOS
- Setting up Vagrant
- Summary
- 2. New Features in PHP 7
- New operators
- Uniform variable syntax
- Miscellaneous features and changes
- Summary
- 3. Improving PHP 7 Application Performance
- HTTP server optimization
- HTTP persistent connection
- Content Delivery Network (CDN)
- CSS and JavaScript optimization
- Full page caching
- Varnish
- The infrastructure
- Summary
- 4. Improving Database Performance
- Storage engines
- The Percona Server - a fork of MySQL
- MySQL performance monitoring tools
- Percona XtraDB Cluster (PXC)
- Redis – the key-value cache store
- Memcached key-value cache store
- Summary
- 5. Debugging and Profiling
- Profiling with Xdebug
- PHP DebugBar
- Summary
- 6. Stress/Load Testing PHP Applications
- ApacheBench (ab)
- Siege
- Load testing real-world applications
- Summary
- 7. Best Practices in PHP Programming
- Test-driven development (TDD)
- Design patterns
- Service-oriented architecture (SOA)
- Being object-oriented and reusable always
- PHP frameworks
- Version control system (VCS) and Git
- Deployment and Continuous Integration (CI)
- Summary
- A. Tools to Make Life Easy
- Git – A version control system
- Grunt watch
- Summary
- B. MVC and Frameworks
- Laravel
- Lumen
- Apigility
- Summary
- 3. Module 3
- 1. Ecosystem Overview
- Summary
- 2. GoF Design Patterns
- Structural patterns
- Behavioral patterns
- Summary
- 3. SOLID Design Principles
- Open/closed principle
- Liskov substitution principle
- Interface Segregation Principle
- Dependency inversion principle
- Summary
- 4. Requirement Specification for a Modular Web Shop App
- Wireframing
- Defining a technology stack
- Summary
- 5. Symfony at a Glance
- Creating a blank project
- Using Symfony console
- Controller
- Routing
- Templates
- Forms
- Configuring Symfony
- The bundle system
- Databases and Doctrine
- Testing
- Validation
- Summary
- 6. Building the Core Module
- Dependencies
- Implementation
- Unit testing
- Functional testing
- Summary
- 7. Building the Catalog Module
- Dependencies
- Implementation
- Unit testing
- Functional testing
- Summary
- 8. Building the Customer Module
- Dependencies
- Implementation
- Unit testing
- Functional testing
- Summary
- 9. Building the Payment Module
- Dependencies
- Implementation
- Unit testing
- Functional testing
- Summary
- 10. Building the Shipment Module
- Dependencies
- Implementation
- Unit testing
- Functional testing
- Summary
- 11. Building the Sales Module
- Dependencies
- Implementation
- Unit testing
- Functional testing
- Summary
- 12. Integrating and Distributing Modules
- Understanding GitHub
- Understanding Composer
- Understanding Packagist
- Summary
- Bibliography
- Index
Very frequently, it is of interest to scan a website and extract information from specific tags. This basic mechanism can be used to trawl the web in search of useful bits of information. At other times you need to get a list of <IMG> tags and the SRC attribute, or <A> tags and the corresponding HREF attribute. The possibilities are endless.
- First of all, we need to grab the contents of the target website. At first glance it seems that we should make a cURL request, or simply use
file_get_contents(). The problem with these approaches is that we will end up having to do a massive amount of string manipulation, most likely having to make inordinate use of the dreaded regular expression. In order to avoid all of this, we'll simply take advantage of an already existing PHP 7 classDOMDocument. So we create aDOMDocumentinstance, setting it to UTF-8. We don't care about whitespace, and use the handyloadHTMLFile()method to load the contents of the website into the object:public function getContent($url) { if (!$this->content) { if (stripos($url, 'http') !== 0) { $url = 'http://' . $url; } $this->content = new DOMDocument('1.0', 'utf-8'); $this->content->preserveWhiteSpace = FALSE; // @ used to suppress warnings generated from // improperly configured web pages @$this->content->loadHTMLFile($url); } return $this->content; }Tip
Note that we precede the call to the
loadHTMLFile()method with an@. This is not done to obscure bad coding (!) as was often the case in PHP 5! Rather, the@suppresses notices generated when the parser encounters poorly written HTML. Presumably, we could capture the notices and log them, possibly giving ourHooverclass a diagnostic capability as well. - Next, we need to extract the tags which are of interest. We use the
getElementsByTagName()method for this purpose. If we wish to extract all tags, we can supply*as an argument:public function getTags($url, $tag) { $count = 0; $result = array(); $elements = $this->getContent($url) ->getElementsByTagName($tag); foreach ($elements as $node) { $result[$count]['value'] = trim(preg_replace('/\s+/', ' ', $node->nodeValue)); if ($node->hasAttributes()) { foreach ($node->attributes as $name => $attr) { $result[$count]['attributes'][$name] = $attr->value; } } $count++; } return $result; } - It might also be of interest to extract certain attributes rather than tags. Accordingly, we define another method for this purpose. In this case, we need to parse through all tags and use
getAttribute(). You'll notice that there is a parameter for the DNS domain. We've added this in order to keep the scan within the same domain (if you're building a web tree, for example):public function getAttribute($url, $attr, $domain = NULL) { $result = array(); $elements = $this->getContent($url) ->getElementsByTagName('*'); foreach ($elements as $node) { if ($node->hasAttribute($attr)) { $value = $node->getAttribute($attr); if ($domain) { if (stripos($value, $domain) !== FALSE) { $result[] = trim($value); } } else { $result[] = trim($value); } } } return $result; }
In order to use the new Hoover class, initialize the autoloader (described previously) and create an instance of the Hoover class. You can then run the Hoover::getTags() method to produce an array of tags from the URL you specify as an argument.
Here is a block of code from chap_01_vacuuming_website.php that uses the Hoover class to scan the O'Reilly website for <A> tags:
<?php
// modify as needed
define('DEFAULT_URL', 'http://oreilly.com/');
define('DEFAULT_TAG', 'a');
require __DIR__ . '/../Application/Autoload/Loader.php';
Application\Autoload\Loader::init(__DIR__ . '/..');
// get "vacuum" class
$vac = new Application\Web\Hoover();
// NOTE: the PHP 7 null coalesce operator is used
$url = strip_tags($_GET['url'] ?? DEFAULT_URL);
$tag = strip_tags($_GET['tag'] ?? DEFAULT_TAG);
echo 'Dump of Tags: ' . PHP_EOL;
var_dump($vac->getTags($url, $tag));The output will look something like this:
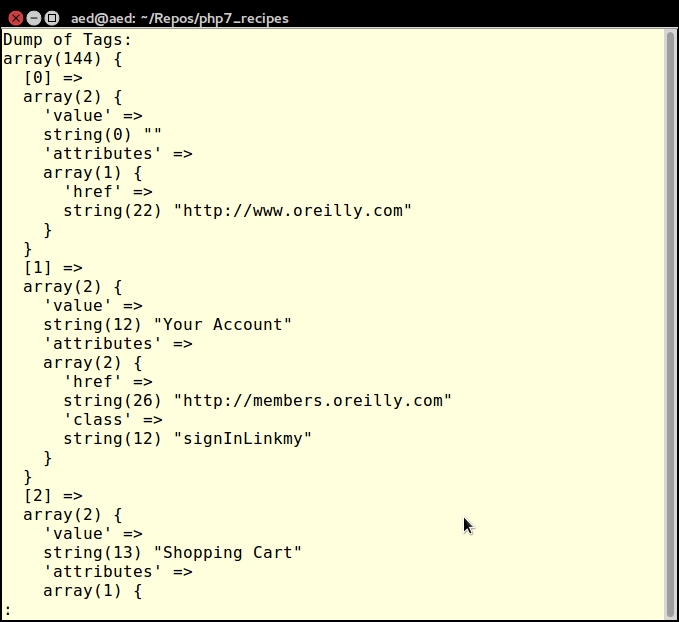
For more information on DOM, see the PHP reference page at http://php.net/manual/en/class.domdocument.php.