
REmote DIctionary Server (Redis) is an open source, key-value, single-threaded, in-memory data store that is commonly referred to as a data structure server.[9] It is capable of functioning as a NoSQL database, key/value store, a cache layer, and a message broker (among other things). Redis is known for its speed, as it can store complex data structures in memory, and serve them to multiple users or applications.
Redis was primarily designed to serve as an in-memory cache, intended to support atomic operations on a single server. It was written (in C) by Salvatore Sanfilippo, who used it to replace the MySQL instance running at his start-up. Clustering options are available (as of Redis 3.0) with the advent of Redis Cluster. It is important to note that in terms of distributed systems, these two configurations do behave differently:
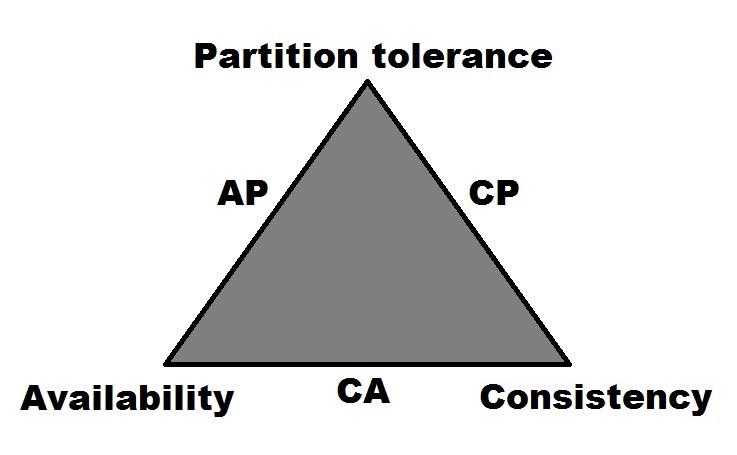
When looking at Redis within the context of Brewer's CAP theorem (formerly known as both Brewer's CAP principle and Brewer's CAP conjecture), its designation would be as a CA system (Brewer, Fox, 1999, p.1). It earns this designation by being able to support both consistency (C) and availability (A), while partition tolerance for a single instance configuration is not a concern.
However, when Redis Cluster is used, this designation becomes harder to pinpoint. Redis's creator Salvatore Sanfilippo states that Redis Cluster[10] is more biased toward consistency than availability. That being said, there are times (however small) when acknowledged writes may be lost during re-hashing or election periods.[4] It is also possible that slave nodes can be configured to serve dirty reads, with the client potentially reading stale data during a small window of time. This (like many NoSQL databases) allows Redis to continue to serve its data during periods of server or (partial) network outages. These factors make it difficult for Redis to fully support strong consistency, despite its intent.
Given the available data, this author can only conclude that Redis Cluster would earn an AP CAP designation. While the possibility of reading stale data does not sound desirable, the alternatives of returning an error or making a client application wait for consistency to be achieved can be even more undesirable. For instance, in a high-performance web client environment, the possibility of returning stale data (say, for a small window of double-digit milliseconds) is preferable to returning nothing.
In any case, Redis aims to provide high-performance, in-memory data storage. With multiple nodes working together using Redis Cluster, it is also capable of scaling linearly to meet operational workloads of increasing throughput. Application architects should perform adequate testing while observing both consistency and availability, to ensure that the tenant application's requirements are being met.