
Cassandra is designed to solve problems associated with operating at a large (web) scale. It was designed under similar principles discussed in Amazon's Dynamo paper,[7, p.205] where in a large, complicated system of interconnected hardware, something is always in a state of failure. Given Cassandra's masterless architecture, it is able to continue to perform operations despite a small (albeit significant) number of hardware failures.
In addition to high availability, Cassandra also provides network partition tolerance. When using a traditional RDBMS, reaching the limits of a particular server's resources can only be solved by vertical scaling or scaling up. Essentially, the database server is augmented with additional memory, CPU cores, or disks in an attempt to meet the growing dataset or operational load. Cassandra, on the other hand, embraces the concept of horizontal scaling or scaling out. That is, instead of adding more hardware resources to a server, the additional server is added to the existing Cassandra cluster:
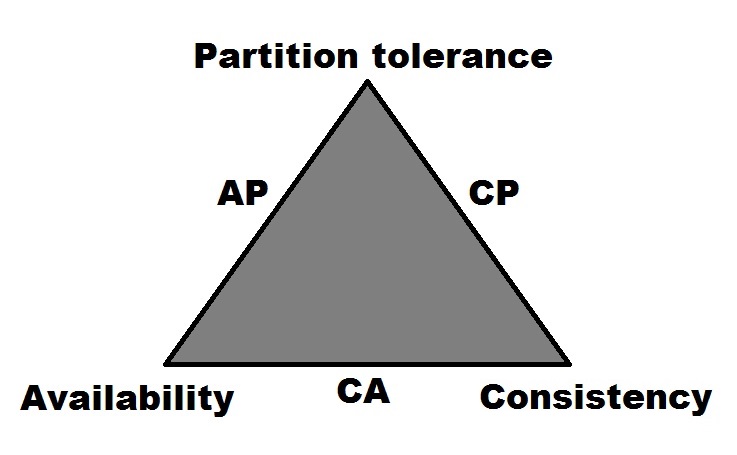
Given this information, if you were to look at Cassandra within the context of Brewer's CAP theorem, Cassandra would be designated as an AP system[4, p.1]. It earns this designation by being able to support both high Availability (A) and Partition tolerance (P), at the expense of Consistency (C).
Essentially, Cassandra offers the ability to serve large amounts of data at web-scale. Its features of linear scalability and distributed masterless architecture allow it to achieve high performance in a fast-paced environment, with minimal downtime.