
AWS provide a version of DynamoDB for local installation. It supports the creation of an application without the web services or connection. It reduces provisioned throughput, data storage, and transfers by allowing local databases. When we are ready for deployment, we can make some changes for it to be used with AWS.
To use DynamoDB locally, we have to use the .jar executable file. We can download .tar or .zip, based on the operating system we are using. For the Unix OS, we have to use .tar, and for Windows, we have to download a .zip file.
Use the following links to download the respective files:
- .tar file: http://dynamodb-local.s3-website-us-west-2.amazonaws.com/dynamodb_local_latest.tar.gz
- .zip file: http://dynamodb-local.s3-website-us-west-2.amazonaws.com/dynamodb_local_latest.zip
Once the file is downloaded, we have to extract the content. We have to go to the directory where we have DynamoDBLocal.jar and run the following command:

Now DynamoDB is set up locally, and you can use it to connect your application. In the preceding command, we used the -sharedDb option. This instructs DynamoDB to use a single database file instead of separate files for each credential and region. If you specify the -sharedDb option, all clients will interact with the same set of tables, regardless of the credential files and region.
By default, DynamoDB SDK uses an endpoint for AWS; to use locally, we have to specify the local endpoint http://localhost:8000.
To access DynamoDB, use the following command locally:

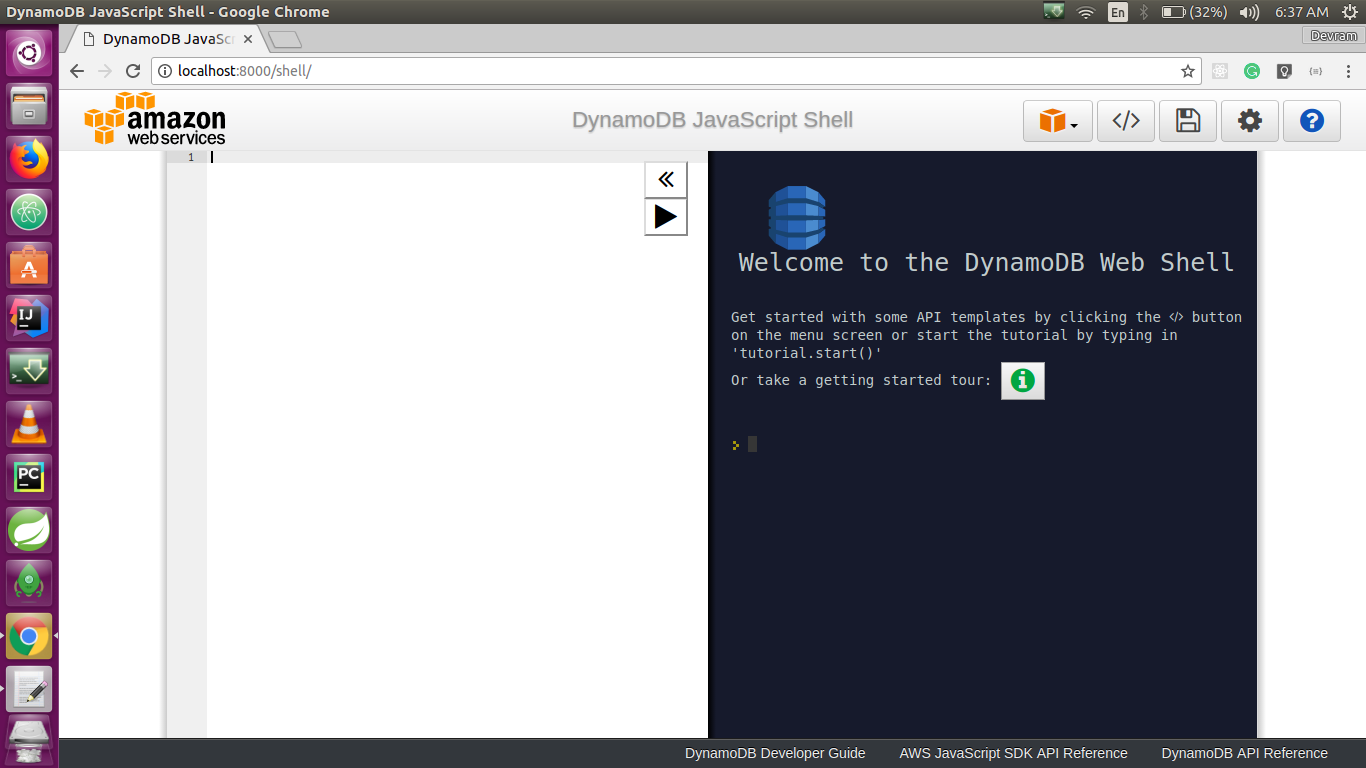
We can also access the user interface for local installation through http://localhost:8000/shell. It has a console to execute the request, as shown in the following screenshot:
The preceding command uses a local endpoint and lists all the tables currently available.
Except for the endpoint, an application that runs with the downloadable version of DynamoDB should also work with DynamoDB web services. However, while using DynamoDB locally, we should consider the following points:
- If we use the -shareDb option, DynamoDB creates a single database file name shared-local-instance.db. Every program that connects to DynamoDB accesses this file. If you delete this file, you will lose all the data.
- If you skip the -shareDb option, the database file will be named myaccesskeyid_region.db, with the AWS access key ID and region that you configured in the application.
- If you use the -inMemory option, DynamoDB does not write any database file. All data is written in memory, and once you exit DynamoDB, all data is lost.
- If you use the -optimizeDbBeforeStartup option, you must specify the dbPath parameter so that DynamoDB can find the database file.
- The AWS SDK for DynamoDB requires that your application configuration must define the access key value and the AWS region value. If you do not use the -sharedDb and -inMemory options, DynamoDB will use this value to create local database files.