
To configure your node properly, you will need your machine's IP address (assume 192.168.0.100, for this exercise). Once you have that, look inside your configuration directory ($CASSANDRA_HOME/conf for Tarball installs, /etc/cassandra for apt-get installs) and you will notice several files: cassandra.yaml, cassandra-env.sh, and cassandra-rackdc.properties among them.
In the cassandra.yaml file, make the following adjustments:
I'll name the cluster PermanentWaves:
cluster_name: "PermanentWaves"
Next, I'll designate this node as a seed node. Basically, this means other nodes will look for this node when joining the cluster. Do not make all of your nodes seed nodes:
seeds: "192.168.0.100"
Usually, listen_address and rpc_address will be set to the same IP address. In some cloud implementations, it may be necessary to also set broadcast_address and/or broadcast_rpc_address to your instances' external IP address, instead. But for a basic, on-the-metal setup, this will work fine:
listen_address: 192.168.0.100
rpc_address: 192.168.0.100
By default, Cassandra sets your endpoint_snitch to the SimpleSnitch. The snitch is a component that makes Cassandra aware of your network topology. This way, the snitch can efficiently route requests, and ensure that an appropriate amount of replicas are being written in each data center. Change the endpoint_snitch to the following:
endpoint_snitch: GossipingPropertyFileSnitch
The GossipingPropertyFileSnitch will require additional configuration to the cassandra-rackdc.properties file, which will be detailed shortly.
Like many NoSQL databases, Cassandra comes with all security features completely disabled. While it is recommended to run Cassandra on a network secured by an enterprise-grade firewall, that alone is not enough. High profile hackings of unsecured MongoDB databases have made their way into the news.[3] Shortly thereafter, an unknown hacker attacked unsecured Cassandra databases around the world,[5] giving everyone a warning by simply creating a new keyspace on their clusters named your_db_is_not_secure. Long story short, enabling user authentication and authorization should be one of the first things that you configure on a new cluster:
authenticator: PasswordAuthenticator
authorizer: CassandraAuthorizer
Configuring the authenticator and the authorizer, as mentioned, will create the system_auth keyspace, with a default username and password of cassandra/cassandra. Obviously, you should change those once you start your cluster.
In the cassandra-rackdc.properties file, you can define the data center and rack for this particular node. For cloud deployments, you should define the data center as your cloud provider's region, and logical rack as the availability zone (or an equivalent thereof). The idea is that Cassandra will use the snitch to figure out which nodes are on which racks, and store replicas in each as appropriate. In this way, you could lose an entire rack (or availability zone), and your cluster could continue to function:
dc=LakesidePark
rack=r40
Next, you will want to configure settings specific to your JVM and desired method of garbage collection. If you are running on a release of Cassandra prior to version 3, these changes are made in the cassandra-env.sh file. For version 3 and up, these settings can be altered in the jvm.options file.
By default, Cassandra will use concurrent mark and sweep (CMS) as its method of garbage collection. It will also specify the minimum/maximum JVM heap sizes and new generation size, based on the node's maximum RAM and CPU cores. Heap size is determined by this formula:
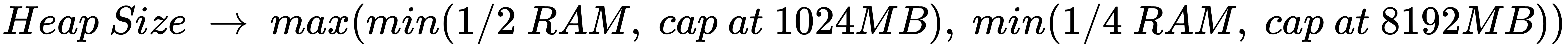
Essentially, if left to the defaults, your heap size will be between 1 GB and 8 GB. This may be fine for a local development configuration, but for a cluster, in production (and even a commonly used development or staging cluster), you will want to override these settings.
It is my opinion that an entire chapter (or even a book) could be written about efficient tuning and configuration of your JVM's garbage collector. Given the limited overview that is being provided here, some quick guidelines will be given. If your cluster will be provisioned with smaller nodes, and your JVM heap will be small (8 GB or less), CMS garbage collection should be used. It is not recommended to exceed an 8 GB heap size while using CMS garbage collection, unless you know what you are doing.
However, if you have the available RAM, there are some gains to be realized with Cassandra while using the newer Garbage-First Garbage Collector (G1GC). Good (JVM option) starting points for G1GC are:
+UseG1GC
-Xms=20GB
-Xmx=20GB
G1RSetUpdatingPauseTimePercent=5
InitiatingHeapOccupancyPercent=25
G1HeapRegionSize=32m
MaxGCPauseMillis=500
The heap size will be dependent on how much RAM you have available. A good starting point is 20 GB, assuming that your node has at least 32 GB of RAM. It is important to note, that you should not set a young generation size (mn) for G1GC. The main property to watch here is MaxGCPauseMillis. If you find that GC pauses inhibit your workload, reduce the target pause time down to 300 ms or so.