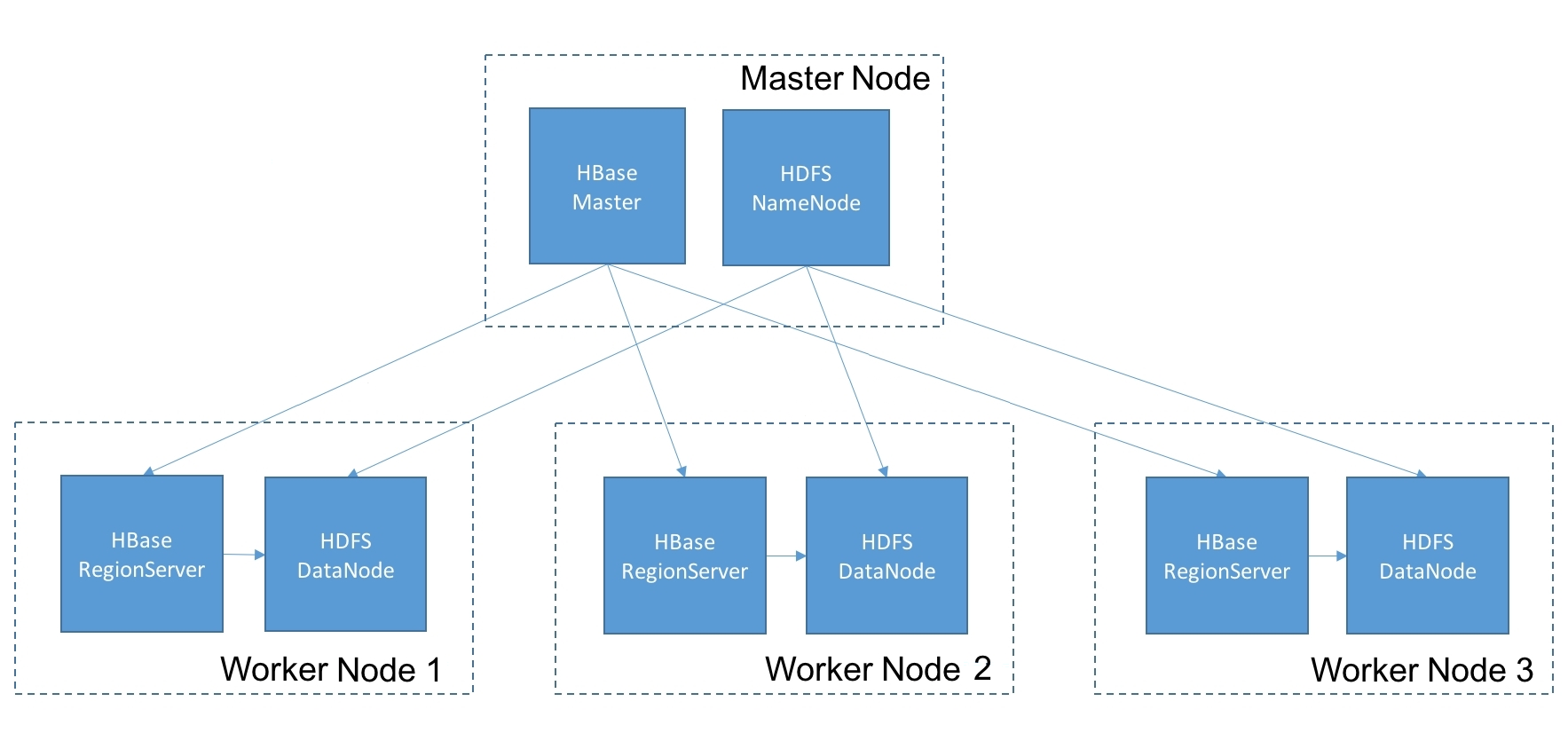
HDFS is the Hadoop Distributed File System. Modeled on GFS, Google File System, it allows the storage and processing of large amounts of data. HDFS is modeled as a file system, with support for files larger than what could fit on a single machine. Files are stored as collections of blocks, spread out across a collection of machines.
The data blocks are stored at DataNodes, which handles all of the I/O for the blocks they are responsible for. The block assignment metadata is stored at the NameNode. The NameNode is responsible for admin and meta operations, such as creating directories, listing directories, file moves, and so on. The HDFS client implements the file system interface and provides client applications the logical abstraction of dealing with single, large files, hiding the complexity of dealing with a distributed file system behind the scenes. To read or write a file, the HDFS client interacts with the NameNode, which identifies the DataNode to read or write the block to. After that, the client directly interacts with the DataNode for the block I/O.
HDFS provides the persistent storage for HBase. It's a similar sort of relationship to GFS and Bigtable. HBase uses the HDFS client to store collections of records as data blocks in HDFS. The commit logs are also stored in HDFS. We'll cover these file structures in more detail in a later section.
Through its inherent replication capabilities, HDFS provides high availability to HBase. Since block writes to HDFS can be replicated across multiple DataNodes, even if a RegionServer process goes down, it can come back quickly without losing data. If the DataNode process went down, the RegionServer can still fetch data from a replica DataNode.
There are two questions that always come up in the context of HBase and HDFS. When do we use HBase, and when should we pick HDFS for a given use case?
HDFS exposes a file system interface, while HBase exposes a key-value API. HDFS optimizes for throughput. HBase optimizes for low-latency reads or updates to a small set of keys. The fact that HBase achieves random reads/writes on top of an append-only file system is remarkable.
So, if you have a batch processing use case that needs to scan a dataset in its entirety and compute some aggregates, HDFS is what you need. If you also need random reads and writes to that dataset, HBase is what you should go with: