
We are interested in the recall score, because that is the metric that will help us try to capture the most fraudulent transactions. If you think how accuracy, precision, and recall work for a confusion matrix, recall would be the most interesting because we comprehend a lot more.
- Accuracy = (TP+TN)/total, where TP depicts true positive, TN depicts true negative
- Precision = TP/(TP+FP), where TP depicts true positive, FP depicts false positive
- Recall = TP/(TP+FN), where TP depicts true positive, TP depicts true positive, FN depicts false negative
The following diagram will help you understand the preceding definitions:
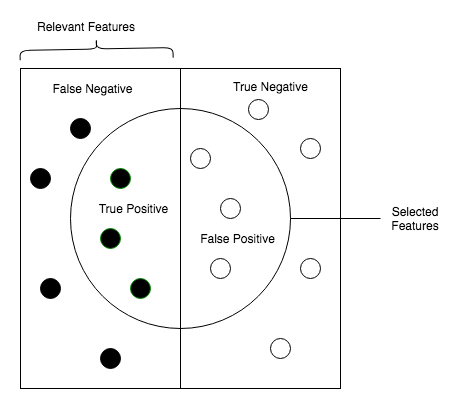
As we know, due to the imbalance of data, many observations could be predicted as False Negatives. However, in our case, that is not so; we do not predict a normal transaction. The transaction is in fact a fraudulent one. We can prove this with the Recall.
- Obviously, trying to increase recall tends to come with a decrease in precision. However, in our case, if we predict that a transaction is fraudulent and it turns out not to be, it is not a massive problem compared to the opposite.
- We could even apply a cost function when having FN and FP with different weights for each type of error, but let's leave that for now as that will be an overkill for this situation:
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import KFold, cross_val_score, GridSearchCV
from sklearn.metrics import confusion_matrix,precision_recall_curve,auc,roc_auc_score,roc_curve,recall_score,classification_report
Ad-hoc function to print K_fold_scores:
c_param_range = [0.01,0.1,1,10,100]
print("# Tuning hyper-parameters for %s" % score)
print()
clf = GridSearchCV(LogisticRegression(), {"C": c_param_range}, cv=5, scoring='recall')
clf.fit(X_train_undersample,y_train_undersample)
print "Best parameters set found on development set:"
print clf.bestparams
print "Grid scores on development set:"
means = clf.cv_results_['mean_test_score']
stds = clf.cv_results_['std_test_score']
for mean, std, params in zip(means, stds, clf.cv_results_['params']):
print("%0.3f (+/-%0.03f) for %r"
% (mean, std * 2, params))
print "Detailed classification report:"
print "The model is trained on the full development set."
print "The scores are computed on the full evaluation set."
y_true, y_pred = y_test, clf.predict(X_test)
print(classification_report(y_true, y_pred))
print()
The problem is too easy: the hyperparameter plateau is too flat and the output model is the same for precision and recall with ties in quality.