Table of Contents for
Using SQLite
 Using SQLite
Published by
O'Reilly Media, Inc., 2010
Using SQLite
Published by
O'Reilly Media, Inc., 2010
- Cover
- Using SQLite
- O'Reilly Strata Conference
- Using SQLite
- Dedication
- A Note Regarding Supplemental Files
- Preface
- SQLite Versions
- Email Lists
- Example Code Download
- How We Got Here
- Conventions Used in This Book
- Using Code Examples
- Safari® Books Online
- How to Contact Us
- 1. What Is SQLite?
- Self-Contained, No Server Required
- Single File Database
- Zero Configuration
- Embedded Device Support
- Unique Features
- Compatible License
- Highly Reliable
- 2. Uses of SQLite
- Database Junior
- Application Files
- Application Cache
- Archives and Data Stores
- Client/Server Stand-in
- Teaching Tool
- Generic SQL Engine
- Not the Best Choice
- Big Name Users
- 3. Building and Installing SQLite
- SQLite Products
- Precompiled Distributions
- Documentation Distribution
- Source Distributions
- Building
- Build and Installation Options
- An sqlite3 Primer
- Summary
- 4. The SQL Language
- Learning SQL
- Brief Background
- General Syntax
- SQL Data Languages
- Data Definition Language
- Data Manipulation Language
- Transaction Control Language
- System Catalogs
- Wrap-up
- 5. The SELECT Command
- SQL Tables
- The SELECT Pipeline
- Advanced Techniques
- SELECT Examples
- What’s Next
- 6. Database Design
- Tables and Keys
- Common Structures and Relationships
- Normal Form
- Indexes
- Transferring Design Experience
- Closing
- 7. C Programming Interface
- API Overview
- Library Initialization
- Database Connections
- Prepared Statements
- Bound Parameters
- Convenience Functions
- Result Codes and Error Codes
- Utility Functions
- Summary
- 8. Additional Features and APIs
- Date and Time Features
- ICU Internationalization Extension
- Full-Text Search Module
- R*Trees and Spatial Indexing Module
- Scripting Languages and Other Interfaces
- Mobile and Embedded Development
- Additional Extensions
- 9. SQL Functions and Extensions
- Scalar Functions
- Aggregate Functions
- Collation Functions
- SQLite Extensions
- 10. Virtual Tables and Modules
- Introduction to Modules
- Module API
- Simple Example: dblist Module
- Advanced Example: weblog Module
- Best Index and Filter
- Wrap-Up
- A. SQLite Build Options
- Shell Directives
- ENABLE_READLINE
- Default Values
- SQLITE_DEFAULT_AUTOVACUUM
- SQLITE_DEFAULT_CACHE_SIZE
- SQLITE_DEFAULT_FILE_FORMAT
- SQLITE_DEFAULT_JOURNAL_SIZE_LIMIT
- SQLITE_DEFAULT_MEMSTATUS
- SQLITE_DEFAULT_PAGE_SIZE
- SQLITE_DEFAULT_TEMP_CACHE_SIZE
- YYSTACKDEPTH
- Sizes and Limits
- SQLITE_MAX_ATTACHED
- SQLITE_MAX_COLUMN
- SQLITE_MAX_COMPOUND_SELECT
- SQLITE_MAX_DEFAULT_PAGE_SIZE
- SQLITE_MAX_EXPR_DEPTH
- SQLITE_MAX_FUNCTION_ARG
- SQLITE_MAX_LENGTH
- SQLITE_MAX_LIKE_PATTERN_LENGTH
- SQLITE_MAX_PAGE_COUNT
- SQLITE_MAX_PAGE_SIZE
- SQLITE_MAX_SQL_LENGTH
- SQLITE_MAX_TRIGGER_DEPTH
- SQLITE_MAX_VARIABLE_NUMBER
- Operation and Behavior
- SQLITE_CASE_SENSITIVE_LIKE
- SQLITE_HAVE_ISNAN
- SQLITE_OS_OTHER
- SQLITE_SECURE_DELETE
- SQLITE_THREADSAFE
- SQLITE_TEMP_STORE
- Debug Settings
- SQLITE_DEBUG
- SQLITE_MEMDEBUG
- Enable Extensions
- SQLITE_ENABLE_ATOMIC_WRITE
- SQLITE_ENABLE_COLUMN_METADATA
- SQLITE_ENABLE_FTS3
- SQLITE_ENABLE_FTS3_PARENTHESIS
- SQLITE_ENABLE_ICU
- SQLITE_ENABLE_IOTRACE
- SQLITE_ENABLE_LOCKING_STYLE
- SQLITE_ENABLE_MEMORY_MANAGEMENT
- SQLITE_ENABLE_MEMSYS3
- SQLITE_ENABLE_MEMSYS5
- SQLITE_ENABLE_RTREE
- SQLITE_ENABLE_STAT2
- SQLITE_ENABLE_UPDATE_DELETE_LIMIT
- SQLITE_ENABLE_UNLOCK_NOTIFY
- YYTRACKMAXSTACKDEPTH
- Limit Features
- SQLITE_DISABLE_LFS
- SQLITE_DISABLE_DIRSYNC
- SQLITE_ZERO_MALLOC
- Omit Core Features
- B. sqlite3 Command Reference
- Command-Line Options
- Interactive Dot-Commands
- .backup
- .bail
- .databases
- .dump
- .echo
- .exit
- .explain
- .headers
- .help
- .import
- .indices
- .iotrace
- .load
- .log
- .mode
- .nullvalue
- .output
- .prompt
- .quit
- .read
- .restore
- .schema
- .separator
- .show
- .tables
- .timeout
- .timer
- .width
- C. SQLite SQL Command Reference
- SQLite SQL Commands
- ALTER TABLE
- ANALYZE
- ATTACH DATABASE
- BEGIN TRANSACTION
- COMMIT TRANSACTION
- CREATE INDEX
- CREATE TABLE
- CREATE TRIGGER
- CREATE VIEW
- CREATE VIRTUAL TABLE
- DELETE
- DETACH DATABASE
- DROP INDEX
- DROP TABLE
- DROP TRIGGER
- DROP VIEW
- END TRANSACTION
- EXPLAIN
- INSERT
- PRAGMA
- REINDEX
- RELEASE SAVEPOINT
- REPLACE
- ROLLBACK TRANSACTION
- SAVEPOINT
- SELECT
- UPDATE
- VACUUM
- D. SQLite SQL Expression Reference
- Literal Expressions
- Logic Representations
- Unary Expressions
- Binary Expressions
- Function Calls
- Column Names
- General Expressions
- AND
- BETWEEN
- CASE
- CAST
- COLLATE
- EXISTS
- GLOB
- IN
- IS
- ISNULL
- LIKE
- MATCH
- NOTNULL
- OR
- RAISE
- REGEXP
- SELECT
- E. SQLite SQL Function Reference
- Scalar Functions
- abs()
- changes()
- coalesce()
- date()
- datetime()
- glob()
- ifnull()
- hex()
- julianday()
- last_insert_rowid()
- length()
- like()
- load_extension()
- lower()
- ltrim()
- match()
- max()
- min()
- nullif()
- quote()
- random()
- randomblob()
- regex()
- replace()
- round()
- rtrim()
- sqlite_compileoption_get()
- sqlite_compileoption_used()
- sqlite_source_id()
- sqlite_version()
- strftime()
- substr()
- time()
- total_changes()
- trim()
- typeof()
- upper()
- zeroblob()
- Aggregate Functions
- avg()
- count()
- group_concat()
- max()
- min()
- sum()
- total()
- F. SQLite SQL PRAGMA Reference
- SQLite PRAGMAs
- auto_vacuum
- cache_size
- case_sensitive_like
- collation_list
- count_changes
- database_list
- default_cache_size
- encoding
- foreign_keys
- foreign_key_list
- freelist_count
- full_column_names
- fullfsync
- ignore_check_constraints
- incremental_vacuum
- index_info
- index_list
- integrity_check
- journal_mode
- journal_size_limit
- legacy_file_format
- locking_mode
- lock_proxy_file
- lock_status
- max_page_count
- omit_readlock
- page_count
- page_size
- parser_trace
- quick_check
- read_uncommitted
- recursive_triggers
- reverse_unordered_selects
- schema_version
- secure_delete
- short_column_names
- sql_trace
- synchronous
- table_info
- temp_store
- temp_store_directory
- user_version
- vdbe_trace
- vdbe_listing
- writable_schema
- G. SQLite C API Reference
- API Datatypes
- sqlite3
- sqlite3_backup
- sqlite3_blob
- sqlite3_context
- sqlite3_int64, sqlite3_uint64, sqlite_int64, sqlite_uint64
- sqlite3_module
- sqlite3_mutex
- sqlite3_stmt
- sqlite3_value
- sqlite3_vfs
- API Functions
- sqlite3_aggregate_context()
- sqlite3_auto_extension()
- sqlite3_backup_finish()
- sqlite3_backup_init()
- sqlite3_backup_pagecount()
- sqlite3_backup_remaining()
- sqlite3_backup_step()
- sqlite3_bind_xxx()
- sqlite3_bind_parameter_count()
- sqlite3_bind_parameter_index()
- sqlite3_bind_parameter_name()
- sqlite3_blob_bytes()
- sqlite3_blob_close()
- sqlite3_blob_open()
- sqlite3_blob_read()
- sqlite3_blob_write()
- sqlite3_busy_handler()
- sqlite3_busy_timeout()
- sqlite3_changes()
- sqlite3_clear_bindings()
- sqlite3_close()
- sqlite3_collation_needed()
- sqlite3_column_xxx()
- sqlite3_column_bytes()
- sqlite3_column_count()
- sqlite3_column_database_name()
- sqlite3_column_decltype()
- sqlite3_column_name()
- sqlite3_column_origin_name()
- sqlite3_column_table_name()
- sqlite3_column_type()
- sqlite3_commit_hook()
- sqlite3_compileoption_get()
- sqlite3_compileoption_used()
- sqlite3_complete()
- sqlite3_config()
- sqlite3_context_db_handle()
- sqlite3_create_collation()
- sqlite3_create_function()
- sqlite3_create_module()
- sqlite3_data_count()
- sqlite3_db_config()
- sqlite3_db_handle()
- sqlite3_db_mutex()
- sqlite3_db_status()
- sqlite3_declare_vtab()
- sqlite3_enable_load_extension()
- sqlite3_enable_shared_cache()
- sqlite3_errcode()
- sqlite3_errmsg()
- sqlite3_exec()
- sqlite3_extended_errcode()
- sqlite3_extended_result_codes()
- sqlite3_file_control()
- sqlite3_finalize()
- sqlite3_free()
- sqlite3_free_table()
- sqlite3_get_autocommit()
- sqlite3_get_auxdata()
- sqlite3_get_table()
- sqlite3_initialize()
- sqlite3_interrupt()
- sqlite3_last_insert_rowid()
- sqlite3_libversion()
- sqlite3_libversion_number()
- sqlite3_limit()
- sqlite3_load_extension()
- sqlite3_log()
- sqlite3_malloc()
- sqlite3_memory_highwater()
- sqlite3_memory_used()
- sqlite3_mprintf()
- sqlite3_mutex_alloc()
- sqlite3_mutex_enter()
- sqlite3_mutex_free()
- sqlite3_mutex_held()
- sqlite3_mutex_leave()
- sqlite3_mutex_notheld()
- sqlite3_mutex_try()
- sqlite3_next_stmt()
- sqlite3_open()
- sqlite3_open_v2()
- sqlite3_overload_function()
- sqlite3_prepare_xxx()
- sqlite3_profile()
- sqlite3_progress_handler()
- sqlite3_randomness()
- sqlite3_realloc()
- sqlite3_release_memory()
- sqlite3_reset()
- sqlite3_reset_auto_extension()
- sqlite3_result_xxx()
- sqlite3_result_error_xxx()
- sqlite3_rollback_hook()
- sqlite3_set_authorizer()
- sqlite3_set_auxdata()
- sqlite3_shutdown()
- sqlite3_sleep()
- sqlite3_snprintf()
- sqlite3_soft_heap_limit()
- sqlite3_sourceid()
- sqlite3_sql()
- sqlite3_status()
- sqlite3_step()
- sqlite3_stmt_status()
- sqlite3_strnicmp()
- sqlite3_table_column_metadata()
- sqlite3_threadsafe()
- sqlite3_total_changes()
- sqlite3_trace()
- sqlite3_unlock_notify()
- sqlite3_update_hook()
- sqlite3_user_data()
- sqlite3_value_xxx()
- sqlite3_value_bytes()
- sqlite3_value_numeric_type()
- sqlite3_value_type()
- sqlite3_version[]
- sqlite3_vfs_find()
- sqlite3_vfs_register()
- sqlite3_vfs_unregister()
- sqlite3_vmprintf()
- Index
- About the Author
- Colophon
- Copyright
Common Structures and Relationships
Database design has a small number of design structures and relationships that act as basic building blocks. Once you master how to use them and how to manipulate them, you can use these building blocks to build much larger and more complex data representations.
One-to-One Relationships
The most basic kind of inter-table relationship is the one-to-one relationship. As you can guess, this type of relationship establishes a reference from a single row in one table to a single row in another table. Most commonly, one-to-one relationships are represented by having a foreign key in one table reference a primary key in another table. If the foreign key column is made unique, only one reference will be allowed. As Figure 6-3 illustrates, a unique foreign key creates a one-to-one relationship between the rows of the two tables.
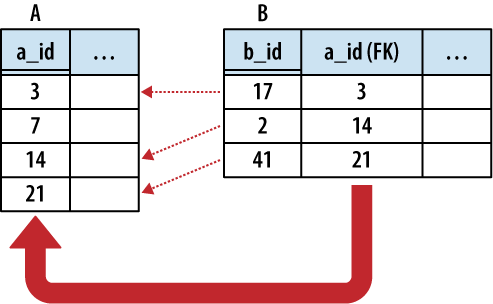
In the strictest sense, a foreign key relationship is a one-to-(zero or one) relationship. When two tables are involved in a one-to-one relationship, there is nothing to enforce that every primary key has an incoming reference from a foreign key. For that matter, if the foreign key allows NULLs, there may be unassigned foreign keys as well.
One-to-one relationships are commonly used to create detail tables. As the name implies, a detail table typically holds details that are linked to the records in a more prominent table. Detail tables can be used to hold data that is only relevant to a small subsection of the database application. Breaking the detail data apart from the main tables allows different sections of the database design to evolve and grow much more independently.
Detail tables can also be helpful when extended
data only applies to a limited number of records. For example, a
website might have a sales_items
table that lists common information (price, inventory, weight, etc.)
for all available items. Type-specific data can then be held in detail
tables, such as cd_info for CDs
(artist name, album name, etc.) or dvd_info (directors, studio, etc.) for DVDs. Although
the sales_items table would have a
unique one-to-one relationship with every type-specific info table,
each individual row in the sales_item table would be referenced by only one type
of detail table.
One-to-one relationships can also be used to
isolate very large data elements, such as BLOBs. Consider an employee database that contains an
image of each employee. Due to the data storage and I/O overhead, it
might be unwise to include a photo
column directly in the employee
table, but it is easy to create a photo table that references the
employee table. Consider these two tables:
CREATE TABLE employee (
employee_id INTEGER NOT NULL PRIMARY KEY,
name TEXT NOT NULL
/* ...etc... */
);
CREATE TABLE employee_photo (
employee_id INTEGER NOT NULL PRIMARY KEY
REFERENCES employee,
photo_data BLOB
/* ...etc... */
);This example is a bit unique, because the employee_photo.employee_id column is
both the primary key for the employee_photo table, as well as a foreign key to the
employee table. Since we want
a one-to-one relationship, it makes sense to just pair up primary
keys. Because this foreign key does not allow NULL keys, every
employee_photo row must be
matched to a specific employee row.
The database does not guarantee that every employee will have a matching employee_photo, however.
One-to-Many Relationships
One-to-many relationships establish a link between a single row in one table to multiple rows in another table. This is done by expanding a one-to-one relationship, allowing one side to contain duplicate keys. One-to-many relationships are often used to associate lists or arrays of items back to a single row. For example, multiple shipping addresses can be linked to a single account. Unless otherwise specified, “many” usually means “zero or more.”
The only difference between a one-to-one relationship and a one-to-many relationship is that the one-to-many relationship allows for duplicate foreign key values. This allows multiple rows in one table (the many table) to refer back to a single row in another table (the One table). In building a one-to-many relationship, the foreign key must always be on the many side.
Figure 6-4 illustrates the relationship in more detail.
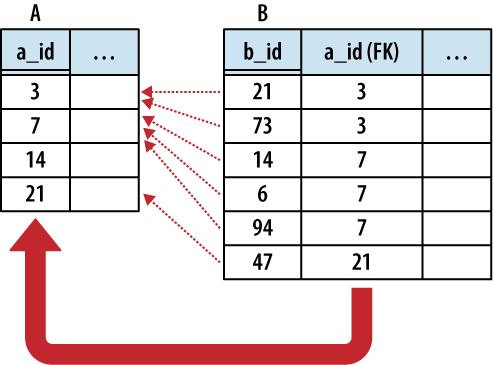
Any time you find yourself wondering how to stuff an array or list into the column of a table, the solution is to separate the array elements out into their own table and establish a one-to-many relationship.
The same is true any time you start to contemplate
sets of columns, such as item0,
item1, item2, etc., that are all designed to
hold instances of the same type of value. Such designs have inherent
limits, and the insert, update, and removal process becomes quite
complex. It is much easier to just break the data out into its own
table and establish a proper relationship.
One example of a one-to-many relationship is music albums, and the songs they contain. Each album has a list of songs associated with that album. For example:
CREATE TABLE albums (
album_id INTEGER NOT NULL PRIMARY KEY,
album_name TEXT );
CREATE TABLE tracks (
track_id INTEGER NOT NULL PRIMARY KEY,
track_name TEXT,
track_number INTEGER,
track_length INTEGER, -- in seconds
album_id INTEGER NOT NULL REFERENCES albums );Each album and track has a unique ID. Each track also has a foreign key reference back to its album. Consider:
INSERT INTO albums VALUES ( 1, "The Indigo Album" ); INSERT INTO tracks VALUES ( 1, "Metal Onion", 1, 137, 1 ); INSERT INTO tracks VALUES ( 2, "Smooth Snake", 2, 212, 1 ); INSERT INTO tracks VALUES ( 3, "Turn A", 3, 255, 1 ); INSERT INTO albums VALUES ( 2, "Morning Jazz" ); INSERT INTO tracks VALUES ( 4, "In the Bed", 1, 214, 2 ); INSERT INTO tracks VALUES ( 5, "Water All Around", 2, 194, 2 ); INSERT INTO tracks VALUES ( 6, "Time Soars", 3, 265, 2 ); INSERT INTO tracks VALUES ( 7, "Liquid Awareness", 4, 175, 2 );
To get a simple list of tracks and their associated album, we just join the tables back together. We can also sort by both album name and track number:
sqlite>SELECT album_name, track_name, track_number...>FROM albums JOIN tracks USING ( album_id )...>ORDER BY album_name, track_number;album_name track_name track_number ------------ ---------- ------------ Morning Jazz In the Bed 1 Morning Jazz Water All 2 Morning Jazz Time Soars 3 Morning Jazz Liquid Awa 4 The Indigo A Metal Onio 1 The Indigo A Smooth Sna 2 The Indigo A Turn A 3
We can also manipulate the track groupings:
sqlite>SELECT album_name, sum( track_length ) AS runtime, count(*) AS tracks...>FROM albums JOIN tracks USING ( album_id )...>GROUP BY album_id;album_name runtime tracks ---------------- ---------- ---------- The Indigo Album 604 3 Morning Jazz 848 4
This query groups the tracks based off their album, and then aggregates the track data together.
Many-to-Many Relationships
The next step is the many-to-many relationship. A many-to-many relationship associates one row in the first table to many rows in the second table while simultaneously allowing individual rows in the second table to be linked to multiple rows in the first table. In a sense, a many-to-many relationship is really two one-to-many relationships built across each other.
Figure 6-5 shows the classic many-to-many example of people and groups. One person can belong to many different groups, while each group is made up of many different people. Common operations are to find all the groups a person belongs to, or to find all the people in a group.
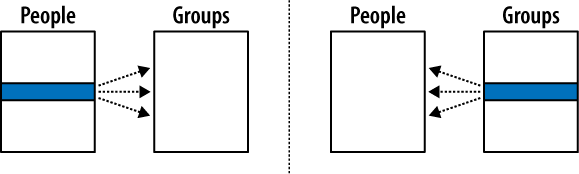
Many-to-many relationships are a bit more complex than other relationships. Although the tables have a many-to-many relationship with each other, the entries in both tables must remain unique. We cannot duplicate either person rows or group rows for the purpose of matching keys. This is a problem, since each foreign key can only reference one row. This makes it impossible for a foreign key of one table (such as a group) to refer to multiple rows of another table (such as people).
To solve this, we go back to the advice from before: if you need to add a list to a row, break out that list into its own table and establish a one-to-many relationship with the new table. You cannot directly represent a many-to-many relationship with only two tables, but you can take a pair of one-to-many relationships and link them together. The link requires a small table, known as a link table, or bridge table, that sits between the two many tables. Each many-to-many relationship requires a unique bridge table.
In its most basic form, the bridge table consists of nothing but two foreign keys—one for each of the tables it is linking together. Each row of the bridge table links one row in the first many table to one row in the second many table. In our People-to-Groups example, the link table defines a membership of one person in one group. This is illustrated in Figure 6-6.
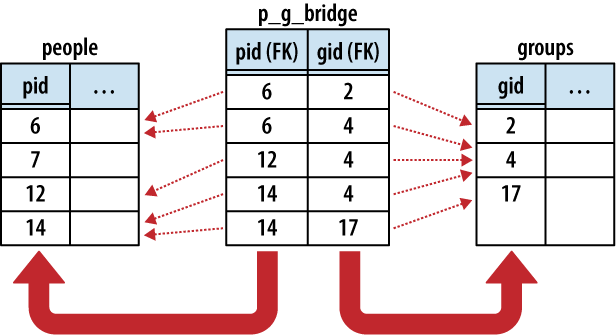
The logical representation of a many-to-many relationship is actually a one-to-many-to-one relationship, with the bridge table (acting as a record of membership) in the middle. Each person has a one-to-many relationship with memberships, just as groups have a one-to-many relationship with memberships. In addition to binding the two tables together, the bridge table can also hold additional information about the membership itself, such as a first-joined date or an expiration date.
Here are three tables. The people and groups table are obvious enough. The p_g_bridge table acts as the bridge
table between the people table and
groups table. The two columns
are both foreign key references, one to people and one to groups. Establishing a primary key across both
foreign key columns ensures the memberships remain unique:
CREATE TABLE people ( pid INTEGER PRIMARY KEY, name TEXT, ... );
CREATE TABLE groups ( gid INTEGER PRIMARY KEY, name TEXT, ... );
CREATE TABLE p_g_bridge(
pid INTEGER NOT NULL REFERENCES people,
gid INTEGER NOT NULL REFERENCES groups,
PRIMARY KEY ( pid, gid )
);This query will list all the groups that a person belongs to:
SELECT groups.name AS group_name
FROM people JOIN p_g_bridge USING ( pid ) JOIN groups USING ( gid )
WHERE people.name = search_person_name;The query simply links people to groups
using the bridge table, and then filters out the appropriate
rows.
We don’t always need all three tables. This query
counts all the members of a group without utilizing the people table:
SELECT name AS group_name, count(*) AS members FROM groups JOIN p_g_bridge USING ( gid ) GROUP BY gid;
There are many other queries we can do, like finding all the groups that have no members:
SELECT name AS group_name FROM groups LEFT OUTER JOIN p_g_bridge USING ( gid ) WHERE pid IS NULL;
This query performs an outer join from the
groups table to the p_g_bridge table. Any unmatched group
rows will be padded out with a NULL in the p_g_bridge.pid column. Since this column is marked
NOT NULL, we know the only
possible way for a row to be NULL in that column is from the outer
join, meaning the row is unmatched to any memberships. A very similar
query could be used to find any people that have no memberships.
Hierarchies and Trees
Hierarchies and other tree-style data relationships are common and frequently show up in database design. Modeling one in a database can be a challenge because you tend to ask different types of questions when dealing with hierarchies.
Common tree operations include finding all the sub-nodes under a given node, or querying the depth of a given node. These operations have an inherent recursion in them—a concept that SQL doesn’t support. This can lead to clumsy queries or complex representations.
There are two common methods for representing a tree relation using database tables. The first is the adjacency model, which uses a simple representation that is easy to modify but complex to query. The other common representation is the nested set, which allows relatively simple queries, but at the cost of a more complex representation that can be expensive to modify.
Adjacency Model
A tree is basically a series of nodes that have a one-to-many relationship between the parents and the children. We already know how to define a one-to-many relationship: give each child a foreign key that points to the primary key of the parent. The only trick is that the same table is sitting on both sides of the relationship.
For example, here is a basic adjacency model table:
CREATE TABLE tree (
node INTEGER NOT NULL PRIMARY KEY,
name TEXT,
parent INTEGER REFERENCES tree );Each node in the tree will have a unique node identifier. Each node will also have a reference to its parent node. The root of the tree can simply have a NULL parent reference. This allows multiple trees to be stored in the same table, as multiple nodes can be defined as a root node of different trees.
If we want to represent this tree:
A
A.1
A.1.a
A.2
A.2.a
A.2.b
A.3We would use the following data:
INSERT INTO tree VALUES ( 1, 'A', NULL ); INSERT INTO tree VALUES ( 2, 'A.1', 1 ); INSERT INTO tree VALUES ( 3, 'A.1.a', 2 ); INSERT INTO tree VALUES ( 4, 'A.2', 1 ); INSERT INTO tree VALUES ( 5, 'A.2.a', 4 ); INSERT INTO tree VALUES ( 6, 'A.2.b', 4 ); INSERT INTO tree VALUES ( 7, 'A.3', 1 );
The following query will give a list of nodes and parents by joining the tree table to itself:
sqlite>SELECT n.name AS node, p.name AS parent...>FROM tree AS n JOIN tree AS p ON n.parent = p.node;node parent ---------- ---------- A.1 A A.1.a A.1 A.2 A A.2.a A.2 A.2.b A.2 A.3 A
Inserting or removing nodes is fairly straightforward, as is moving subtrees around to different parents.
What isn’t easy are tree-centric operations, like counting all of the nodes in a subtree, or computing the depth of a specific node (often used for output formatting). You can do limited traversals (like finding a grand-parent) by joining the tree table to itself multiple times, but you cannot write a single query that can compute an answer to these types of questions on a tree of arbitrary size. The only choice is to write application routines that loop over different levels in the tree, computing the answers you seek.
Overall, the adjacency model is easy to understand, and the trees are easy to modify. The model is based on foreign keys, and can take full advantage of the database’s built-in referential integrity. The major disadvantage is that many types of common data queries require the application code to loop over several individual database queries and assist in calculating answers.
Nested set
As the name implies, the nested set representation depends on nesting groups of nodes inside other groups. Rather than representing some type of parent-child relationship, each node holds bounding data about the full subtree underneath it. With some clever math, this allows us to query all kinds of information about a node.
A nested set table might look like this:
CREATE TABLE nest (
name TEXT,
lower INTEGER NOT NULL UNIQUE,
upper INTEGER NOT NULL UNIQUE,
CHECK ( lower < upper ) );The nested set can be visualized by converting the tree structure into a parenthetical representation. We then count the parentheses and record the upper and lower bound of each nested set. The index numbers can also be calculated with a depth-first tree traversal, where the lower bound is a pre-visit count and the upper bound is a post-visit count.
A( A.1( A.1.a( ) ), A.2( A.2.a( ), A.2.b( ) ), A.3( ) ) 1 2 3 4 5 6 7 8 9 10 11 12 13 14
INSERT INTO nest VALUES ( 'A', 1, 14 ); INSERT INTO nest VALUES ( 'A.1', 2, 5 ); INSERT INTO nest VALUES ( 'A.1.a', 3, 4 ); INSERT INTO nest VALUES ( 'A.2', 6, 11 ); INSERT INTO nest VALUES ( 'A.2.a', 7, 8 ); INSERT INTO nest VALUES ( 'A.2.b', 9, 10 ); INSERT INTO nest VALUES ( 'A.3', 12, 13 );
This might not look that useful, but it allows a number of different queries. For example, if you want to find all the leaf nodes (nodes without children) just look for nodes that have an upper and lower value that are next to each other:
SELECT name FROM nest WHERE lower + 1 = upper;
You can find the depth of a node by counting all of its ancestors:
sqlite>SELECT n.name AS name, count(*) AS depth...>FROM nest AS n JOIN nest AS p...>ON p.lower <= n.lower AND p.upper >= n.upper...>GROUP BY n.name;name depth ---------- ---------- A 1 A.1 2 A.1.a 3 A.2 2 A.2.a 3 A.2.b 3 A.3 2
There are many other queries that match patterns or differences in the upper and lower bounds.
Nested sets are very efficient at calculating many types of queries, but they are expensive to change. For the math to work correctly, there can’t be any gaps in the numbering sequence. This means that any insert or delete requires renumbering a significant number of entries in the table. This isn’t bad for something with a few dozen nodes, but it can quickly prove impractical for a tree with hundreds of nodes.
Additionally, because nested sets aren’t based off any kind of key reference, the database can’t help enforce the correctness of the tree structure. This leaves database integrity and correctness in the hands of the application—something that is normally avoided.
More information
This is just a brief overview of how to represent tree relationships. If you need to implement a tree, I suggest you do a few web searches on adjacency model or nested set. Many of the larger SQL books mentioned in Wrap-up also have sections on tree and hierarchies.