Table of Contents for
Implementing SSL/TLS Using Cryptography and PKI
 Implementing SSL/TLS Using Cryptography and PKI
Published by
John Wiley & Sons, 2011
Implementing SSL/TLS Using Cryptography and PKI
Published by
John Wiley & Sons, 2011
- Cover Page
- Title Page
- Copyright
- Dedication
- About the Author
- About the Technical Editor
- Credits
- Acknowledgments
- Contents at a Glance
- Contents
- Introduction
- CHAPTER 1: Understanding Internet Security
- CHAPTER 2: Protecting Against Eavesdroppers with Symmetric Cryptography
- CHAPTER 3: Secure Key Exchange over an Insecure Medium with Public Key Cryptography
- CHAPTER 4: Authenticating Communications Using Digital Signatures
- CHAPTER 5: Creating a Network of Trust Using X.509 Certificates
- CHAPTER 6: A Usable, Secure Communications Protocol: Client-Side TLS
- CHAPTER 7: Adding Server-Side TLS 1.0 Support
- CHAPTER 8: Advanced SSL Topics
- CHAPTER 9: Adding TLS 1.2 Support to Your TLS Library
- CHAPTER 10: Other Applications of SSL
- APPENDIX A: Binary Representation of Integers: A Primer
- APPENDIX B: Installing TCPDump and OpenSSL
- APPENDIX C: Understanding the Pitfalls of SSLv2
- Index
CHAPTER 5
Creating a Network of Trust Using X.509 Certificates
Chapters 3 and 4 discussed public and private keypairs and reviewed their importance to secure communications over insecure channels. Until now, where these keys come from and how they're exchanged has been mostly glossed over. Where the keys come from is the topic of this chapter. This chapter also includes some further discussion on authentication.
You're probably familiar with the term certificate, even if you're fuzzy on the details. You've undoubtedly visited web sites that have reported errors such as "this website's certificate is no longer valid" or "this website's host name does not match its certificate's host name" or "this certificate was not signed by a trusted CA." If you're like most Internet users, you generally ignore these warnings, although in some cases they can indicate something important.
Fundamentally, the certificate is a holder for a public key. Although it contains a lot more information about the subject of the public key — in the case of web sites, that would be the DNS name of the site which has the corresponding private key—the primary purpose of the certificate is to present the user agent with a public key that should then be used to encrypt a symmetric key that is subsequently used to protect the remainder of the connection's traffic.
At this point, you may have at least a hazy idea of how most of the concepts of the past three chapters can be put together to establish a secure communications link: First, a symmetric algorithm and key is chosen, and then the key is exchanged using public-key techniques. Finally, everything is encrypted using the secret symmetric key and authenticated using an HMAC with another secret key. However, the digital signatures examined in Chapter 4 haven't come into play yet. How are these used and why are they important? Digital signatures are how certificates are authenticated and how you can determine whether or not to trust a certificate. This is examined in much greater detail later in this chapter.
Putting It Together: The Secure Channel Protocol
Armed with symmetric encryption and some method of secure key exchange, such as public key encryption of the symmetric encryption key, you have enough to implement a secure channel against passive eavesdroppers. Assuming that an attacker can see, but not modify, your data, you could adopt the simple secure channel protocol shown in Figure 5-1.
Figure 5-1: Naïve secure channel protocol
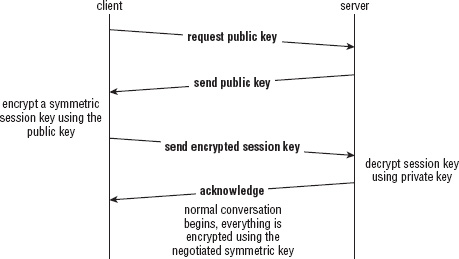
Even if an attacker can view all packets exchanged, all he sees is that the public key was requested and what the public key was — which, by definition, is not a secret. From that point forward, everything is encrypted and, assuming the encryption method is unbreakable, the remainder of the session is secure.
However, a more dangerous form of attack is called a man-in-the middle attack and is carried out by an adversary who can not only view traffic, but also can intercept and modify it. Consider the scenario shown in Figure 5-2.
The problem here is that the client implicitly trusts that the public key belongs to the server. Solving this trust issue surrounds most of the complexity associated with SSL/TLS. The remainder of this book is spent looking at how to get around this problem.
The solution adopted by SSL requires the use of a trusted intermediary. This trusted intermediary digitally signs the public key of the server—using the algorithms discussed in Chapter 4—and the client must verify this signature. Such a signed public key is called a certificate, and a trusted intermediary responsible for signing certificates is called a certificate authority (CA). The client must have access to the public key of the CA so that it can authenticate the signature before accepting the key as genuine. Web browsers have a list of trusted CAs with their public keys built in for just this purpose.
Figure 5-2: Man-in-the-middle attack
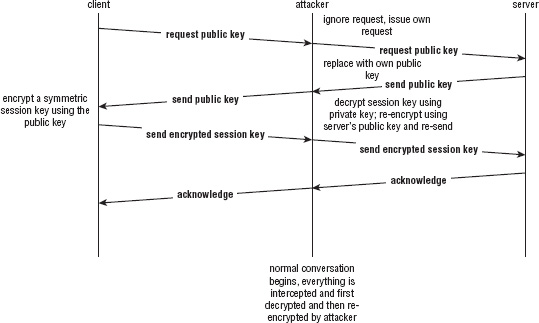
This buys a bit of security against a man-in-the-middle attack, but not much. After all, if the server can get a certificate signed by the trusted CA, you must assume that the attacker, if sufficiently motivated, could do so too. He could present himself to the CA as a legitimate business, for example. This makes his job a bit more difficult, but hardly insurmountable.
What you really need is some way to associate the public key with the server you're connecting to. Thus, a properly formatted certificate needs to have not only the public key of the server included, but also the domain name of the server that the public key belongs to, all signed by the trusted intermediary.
This foils the man-in-the-middle attack. The client requests a certificate from the server, and the man in the middle replaces it with his own. The client then validates the attacker's certificate as legitimate—it's signed by a trusted CA—but observes that the domain doesn't match that of www.server.com, as expected. Nor can the attacker forge a certificate with the domain name www.server.com—this is protected by the digital signature. If he obtains a digitally signed certificate from the CA, with the domain name www.attacker.com, and then changes his own domain in the certificate to www.server.com, the hash code in the signature won't match the hash code of the contents of the certificate, and the client rejects it on this basis.
So, at a bare minimum, in order to protect yourself against man-in-the-middle attacks, you need a trusted CA and a certificate format that includes the domain name, the public key and a digital signature issued by the CA. Now, imagine that a few years go by, and the administrator of the server figures that it's time to reissue the certificate. After all, technology changes, and certificate security holes are found from time to time. And who knows? Some hacker could have broken into the system and stolen the private key without the administrator's knowledge.
Unfortunately, the administrator can't reissue the certificate. Assuming that there's a problem with the certificate—the private key has been compromised or the certificate technology is outdated and includes a security flaw—and the server installs a new certificate, the man in the middle strikes again. When the client tries to connect, the attacker substitutes the old, and presumably weaker, certificate for the new one. The client has no way to authenticate this certificate; the domain is correct, and so is the issuer's digital signature.
To partially guard against this, certificates also include a validity period: a not before date and a not after date. It's the responsibility of the client to check that the certificate's not after date does not fall in the past. If the date is in the past, the client should not connect to the server.
As you can imagine, this is really only half a solution. Imagine that the private key has been compromised and the server administrator knows that the private key been compromised. He should immediately stop allowing use of the compromised certificate. The validity period guarantees that clients stop using the certificate at some point in the future, but you really want a way to accelerate that date. Again, that can't be forced, because a man in the middle can just replace any new certificate with an old one, right up until the end of the validity period.
To fight against this, CAs are responsible for keeping a list of revoked certificates that is called a certificate revocation list (CRL). The client periodically checks this list. But wait—checks it for what? How can you uniquely identify a certificate? As they've been specified so far, you can't; you need one more field in the certificate format, the serial ID. This is a number, unique within a CA, assigned to each certificate. When a certificate is known or believed to be compromised, its serial number is added to the CRL. If the man in the middle tries to replace a new certificate with an old one, the client recognizes that the serial number has been revoked and rejects the connection.
Finally, it's unlikely that everybody on the Internet will use a single CA. That means that the client, when presented with a certificate, needs some way to know whose public key to use to verify the signature. As such, each certificate also includes an issuer that uniquely identifies the CA. The client decides whether or not to trust the issuer dynamically.
Encoding with ASN.1
Certificates need to be precisely defined. Although this sort of structured data is now usually represented and defined in XML, certificates have been around for quite a while, longer than XML. They're specified instead using a syntax referred to as Abstract Syntax Notation (ASN), or ASN.1 (the .1 being the version of Abstract Syntax Notation). ASN serves the same purpose as a DTD or an XSD might serve in an XML context; it describes how elements are nested within one another, what order they must occur in, and what type each is. Official ASN.1 looks quite a bit like a C struct definition, although the differences are significant enough that you can't map directly from one to another.
The certificate format that SSL/TLS uses is defined and maintained by the International Telecommunication Union (ITU) in a series of documents they just refer to as the X series. The documents themselves can be found at http://www.itu.int/rec/T-REC-X/en. Each one has a number, and the corresponding document/standard is referred to as X.nnn where nnn is a number. So, for instance, if you want to see the official standard for X.509, you look under http://www.itu.int/rec/T-REC-X.509/en. I'll refer to several of these specifications by number throughout this chapter.
You may notice that the specifications presented here aren't always specific to SSL/TLS. They were developed independently and adopted later by the Internet consortium. As such, the specifications contain quite a few elements that aren't necessarily relevant to the subject matter of this book itself; I'll mention some of these elements here but refer the interested reader to other sources for details.
Understanding Signed Certificate Structure
ASN.1 is used to describe the structure of an X.509 certificate, which is the official standard for public-key certificates and the format on which TLS 1.0 relies. X.509 has been through three revisions; the current, at the time of this writing, revision of X.509 is 3. The top-level structure of an X.509v3 certificate is shown in Listing 5-1.
Listing 5-1: X.509 Certificate structure declaration
SEQUENCE {
version [0] EXPLICIT Version DEFAULT v1,
serialNumber CertificateSerialNumber,
signature AlgorithmIdentifier,
issuer Name,
validity Validity,
subject Name,
subjectPublicKeyInfo SubjectPublicKeyInfo,
issuerUniqueID [1] IMPLICIT UniqueIdentifier OPTIONAL,
-- If present, version shall be v2 or v3
subjectUniqueID [2] IMPLICIT UniqueIdentifier OPTIONAL, -- If present, version shall be v2 or v3 extensions [3] EXPLICIT Extensions OPTIONAL -- If present, version shall be v3 }
Excerpted fromhttp://www.ietf.org/rfc/rfc2459.txt
The syntax is given in ASN.1. ASN.1 syntax isn't covered completely here; however, you have to understand a fair bit of it to analyze X.509 because X.509 makes use of most of ASN.1. See http://luca.ntop.org/Teaching/Appunti/asn1.html for a complete overview of ASN.1 syntax.
The first line here in the top-level structure of the X.509v3 certificate is SEQUENCE. An ASN.1 SEQUENCE is analogous to a C struct, which may be confusing to a C programmer because sequence sounds more like an array. An ASN.1 sequence groups other elements. As you can see, this sequence contains 10 subelements. The most important of these, of course, is the seventh, subjectPublicKeyInfo, because the primary purpose of a certificate is to transmit a public key.
Each subelement is presented with a name followed by a type—just like a C struct, but inverted. Each of these is examined in detail in the following sections. I'll go over the meaning of each at a high-level, and then come back and show you how to parse a real certificate; if some of this seems a bit abstract, the code samples at the end of this chapter should clear up the intent behind all of these elements.
Version
version [0] EXPLICIT Version DEFAULT v1
The version is an integer between 0 and 2, with 0 representing version 1, 1 representing version 2, 2 representing version 3, and so on. The version number indicates how to parse the remaining structures. For example, the comments at the bottom that indicate issuerUniqueId, subjectUniqueId, and extensions cannot be present if the version is less than 2. However, the original X.509 specification didn't include a version number, so it's necessary for the parser to first check to see if a version number is present. If no version number is present, the parser should assume that the version number is 0 (that is, v1). That's the meaning of the EXPLICIT DEFAULT v1 in the declaration.
The type Version itself is defined in the specification as
Version ::= INTEGER { v1(0), v2(1), v3(2) }
This tells you that the version field is an integer and that it can take on three discrete values.
serialNumber
As discussed in the section "Putting It Together: The Secure Channel Protocol" earlier in this chapter, certificates are signed by CAs. The process of signing a certificate is often referred to as issuing a certificate, and the signer is referred to as the issuer, although this terminology is a bit misleading. Each signer is required to assign a unique serial number to each certificate issued. The serial number is not necessarily globally unique, but it can safely be assumed that VeriSign (a popular CA), for example, never reuses a serial number. Two different CAs may issue two certificates with identical serial numbers, but the same CA never will. The CertificateSerialNumber is defined as an INTEGER.
signature
signature AlgorithmIdentifier,
An X.509 certificate must have been signed by a CA. Whether that CA is trusted or not is a matter for the client to decide. In fact, for testing purposes, it's often useful to create self-signed certificates, in which case the certificate is digitally signed by the private key corresponding to the public key that it contains.
Whoever signed the certificate, the signature algorithm used must be identified by this field. The declaration for an algorithm identifier is
AlgorithmIdentifier ::= SEQUENCE {
algorithm OBJECT IDENTIFIER,
parameters ANY DEFINED BY algorithm OPTIONAL }
Here you see a new type you haven't come across before: the object identifier (OID). OIDs are used quite a bit in the X.509 standard and anything else that's based on ASN.1. OIDs are actually murderously complex and describe a hierarchy of just about anything you can think of. Fortunately, you don't really need to fully understand OIDs. You can treat them simply as byte arrays and keep track of the mappings of these byte arrays and their meanings.
Recall from the Chapter 4 that digitally signing a sequence of bytes involves first securely hashing those bytes using a secure hash algorithm such as MD5 or SHA and then encrypting the bytes using a private key. Thus, a digital signature algorithm identifier must identify both the secure hashing algorithm applied as well as the encrypting algorithm. Given MD5 and SHA for secure hashing algorithms and RSA and DSS for private-key encryption algorithms, you end up with four separate algorithm identifiers. However, because MD5 is not specified for use with DSS, there are only three algorithm identifiers, which are shown in Table 5-1.
Table 5-1: Signing Algorithm OIDs

See X.690 and RFC 2313 for more details on how these values are determined. All you particularly care about is that the third field of the certificate (or the second, if the version number was not supplied) is equal to one of these three-byte sequences. You use this value as a switch to validate the signature of the certificate.
NOTE You may be wondering: "What about ECDSA?" Well, that's sort of complicated. The topic of elliptic-curve cryptography (ECC) in X.509 is revisited in Chapter 9. In general, ECC is not explicitly supported by any version of TLS < 1.2, and supporting it in any version can get a bit hairy.
If you read any of the ITU X series specification documents, you'll notice that the OIDs are not given in hexadecimal form as they are in Table 5-1. Instead, they're given in a dotted-decimal form such as 1.2.840.113549.1.1.4. However, in order to be used, they must be converted to the hexadecimal forms shown in this book. The X.690 specification details this conversion authoritatively. You don't actually need to know how to convert from these dotted-decimal numbers to the normalized hexadecimal forms in order to use them. I've converted all of the ones you need to know but if you're curious, read on.
An OID in X.509 is a leaf in a very, very large tree structure. For example, the OID for the MD5withRSA signature algorithm is 1.2.840.113549.1.1.4. Each number in this very long digit string identifies an element in a large hierarchy. 1 represents iso; 1.2 represents iso/memberBody; 1.2.840 represents iso/member-body/usa and so on. All in all, the OID in this example represents iso/memberBody/usa/rsadsi/pkcs/pkcs1/MD5. Each number only has meaning relative to what came before it. The RSA corporation controls the 1.2.840.113549 namespace and they use 1.1.4 to identify rsa with pkcs #1 padding md5.
So how do you get from 1.2.840.113549.1.1.4 to 2A 86 48 86 F7 0D 01 01 04? Well, the 01 01 04 part is pretty obvious: This is the byte representation of the digits 1.1.4. But as you can see, even the third numeral, 840, is too large to fit into a single byte. Rather than include separators, they adopted a variable-length encoding scheme (The X.500 family of specifications, which includes X.509, is big on variable-length encoding schemes). The 86 48 represents 840, and the 86 F7 0D represents 113549. The encoding scheme used here is this: If the high-order bit is 1 then the other seven bits in this byte should be concatenated with the next byte. If the high-order bit is 0 then this is the last byte in the identifier. So 840, in binary, is 1101001000. This is longer than seven bits, so break it up into chunks of seven or less:
110 1001000
Now, add the high-order bits (and pad the first one):
10000110 01001000
Or hexadecimal 86 48.
The decoder then sees the first byte, recognizes that the high-order bit is 1, continues on to the next byte, sees that the high-order bit is zero, and concatenates the seven lower-order bits of the two constituent bytes back into the value 1101001000, or decimal 840. Likewise, 113549 encodes to 11011101110001101 in binary. This requires 20 bits to encode, so you use three bytes (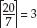 ), with the high-order bits of the first two being set to 1, which tells the decoder that this should be concatenated with the next byte:
), with the high-order bits of the first two being set to 1, which tells the decoder that this should be concatenated with the next byte:
10000110 11110111 00001101
Or 86 F7 0D in hexadecimal.
Is your head spinning yet? Actually, it gets worse. Notice that the hex encoding of the "1.2" on the very beginning of the OID is a single byte: 2A. To save space, X.690 dictates that the first byte encodes two numeric elements according to the algebraic equation Z = 40X + Y. So, 1.2 is 40 * 1 + 2 = 42 (0x2A). On the unpacking side, it's safe to assume that if the byte is in the range 0–40, the decoded value should be 0.(byte); if it's in the range of 41–80, it should be 1.(byte – 40); if it is in the range of 81–120, it should be 2.(byte – 80); and so on. Obviously, this limits the range of values that can be encoded by the first byte.
Fortunately, I've done all of the conversion for you, so you don't have to understand any of this to code around it. All you need to know is that the unique byte sequence 2A 86 48 86 F7 0D 01 01 04 represents the MD5withRSA signature algorithm.
There is also an optional section for parameters. DSS includes a few parameters, so you re-examine this when DSA is covered. Notice that the ANY DEFINED BY algorithm indicates that if the object identifier is one of the two RSA algorithms, the parameters field is not present.
issuer
issuer Name
If you found the subject of OIDs slightly complicated, hold on to your hat as you examine X.509 distinguished names. You've likely seen a distinguished name written out at some point in long form, such as
CN=Joshua Davies,OU=Architecture,O=Travelocity,L=Southlake,ST=Texas,C=USA
You may even be familiar with the meanings of the terse one- and two-letter codes shown in the example, but in case you aren't, they expand to the long names shown in Table 5-2.
Table 5-2: An Expanded X.509 Distinguished Name
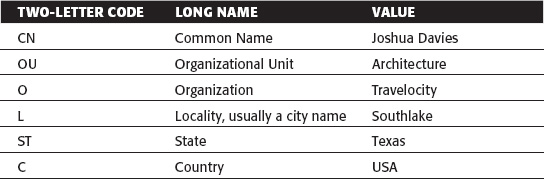
As you can see, this identifies, fairly uniquely, an individual person. In the case of an X.509 certificate, a distinguished name is used to identify the issuer. Here's an example issuer name:
CN = VeriSign Class 3 Extended Validation SSL SGC CA, OU = Terms of use at https://www.verisign.com/rpa (c)06, OU = VeriSign Trust Network, O = VeriSign, Inc., C = US
This is the issuer string on the certificate that identifies the Travelocity.com web site at the time of this writing. As you can see, the CN (common name) doesn't actually identify a person; it identifies an entity. The OU field appears twice and is used to transmit data not actually related to the organizational unit. However, it identifies an issuer well enough for the receiver to decide if it wants to trust it or not. However, see the discussion later in this chapter about the issuerUniqueId field for more on this topic.
You can see this yourself. As way of example, follow these steps:
In FireFox:
- Navigate to a secure page.
- Double-click the lock icon, and click the View button. The Issued By section details the contents of the "issuer" field in the X.509 certificate that the server presented to negotiate the secure connection in the first place.
Using Microsoft's Internet Explorer 8:
- Navigate to a secure page.
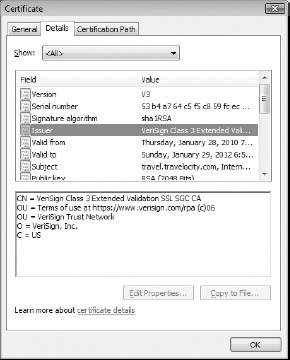
- Click the lock icon on the URL bar, select View Certificates. The Certificate dialog appears as shown in Figure 5-3.
- Click the Details tab, and click Issuer.
One thing you may notice about the two distinguished name examples I've given is that not every field appears in each distinguished name because at least some of them are optional. In fact, technically speaking, all of them are optional. If you look at the declaration of the Name type, which issuer is, you see that it's defined generically:
Name ::= CHOICE { RDNSequence } RDNSequence ::= SEQUENCE OF RelativeDistinguishedName RelativeDistinguishedName ::= SET OF AttributeTypeAndValue AttributeTypeAndValue ::= SEQUENCE { type AttributeType, value AttributeValue } AttributeType ::= OBJECT IDENTIFIER AttributeValue ::= ANY DEFINED BY AttributeType
Figure 5-3: Example of an Issuer field
A name is an RDNSequence, which is a SEQUENCE OF another type, the RelativeDistinguishedName. Remember earlier when SEQUENCE was compared to a C struct, which may be confusing because SEQUENCE sounds like a repeating field? Well, SET OF, which RelativeDistinguishedName is defined as, is a repeating field.
What this all means is that a name is a variable-length array of AttributeTypeAndValue structures. The attribute type is an OID, and the attribute value can be any type, depending on its OID. Again, you don't need to care much about the encoding structure of OIDs; you just need to care about their values and what they map to. As you can probably guess, CN, O, OU, L, ST, and C each have their own OID values. They're not represented as string values anywhere in the certificate. These OIDs are shown in Table 5-3.
Table 5-3: DistinguishedName OIDs
Although the actual type of the attribute value of each depends on the OID, all of the OIDs you typically see (within the distinguished name, at least) have attribute values whose types are strings. Notice also that these OIDs are only three bytes long, whereas the OIDs of the algorithm identifiers shown earlier are each nine bytes long. See X.520 for more detail on the attribute type OIDs (as well as many, many more attribute types—distinguished names are permitted to be very detailed, although they're usually relatively simple).
For now, you just have to identify an issuer well enough to make a trust decision, or provide this same information to the user and let the user make this decision. If you've ever come across the error message "The certificate is signed by an unrecognized CA or one you have chosen not to trust" while browsing the web, your browser is telling you that you should take a look at the "issued by" field.
validity
validity Validity
Recall the purpose and concept of validity period—the validity period represents a time window outside of which the certificate should be considered suspect. You've likely come across the error message "The web site's certificate has expired" while browsing. This is actually a much less serious condition than an untrusted issuer. You know that the certificate was valid at some point in the past; it's just due to be resissued. If it's not terribly old, you can probably trust it.
TRACKING CERTIFICATE VALIDITY PERIODS
Keeping track of validity periods and expiration dates, and ensuring that certificates get reissued before their expiration date, can be an onerous responsibility for a website administrator. Expired certificates are a user annoyance when a web server presents one—the user is presented with an ominous error message and given the option to continue or abort. However, in automated communications, such as secured web services, where a program is making a secure connection to another program, certificate expiration can be fatal.
One day your web services are connecting to one another as they should be; the next day they're failing for no apparent reason with a "certificate expired" error message buried in a log file somewhere. No certificate-based library I'm aware of gives you any warning that a certificate is about to expire (as nice as that would be).
One way to get around this is to have all certificates that protect program-to-program services expire on the same day—for instance, you can have all the test environment certificates expire on Feb. 1, and all the production environment certificates expire on Mar. 1. This way, you'll get some warning and when your test environment certificates start expiring and you'll know it's time to start reissuing your production environment certificates.
How is validity represented in X.509, then?
Validity ::= SEQUENCE {
notBefore Time,
notAfter Time }
Time ::= CHOICE {
utcTime UTCTime,
generalTime GeneralizedTime }
There are two Time values, each of which can either be a UTCTime or a GeneralizedTime. Each is a year, followed by a month, a day, an hour, a minute, a second, and the letter Z. The only difference between the two is that generalized time uses a four-digit year and UTCTime a two-digit year. A UTCTime is 13 bytes long; a GeneralizedTime is 15. Lengths are discussed later in the chapter, when representations are covered.
So, with a two-digit year, the client has to do a bit of detective work to figure out if 35 expired a very, very long time ago, or if it will expire in 25 years. Because no X.509 certificates were issued in 1935, it's safe to assume that a year of 35 means 2035. In fact, the specification mandates that all certificates issued before 2050 must use UTCTime, so if the year is less than 50, it's in the 21st century. After the year 2050, CA's are supposed to begin using GeneralizedTime, with a four-digit year. However, having lived through the Y2K "crisis," I have faith that computer programmers will not actually fix this two-digit year problem until a few years before it actually does become a problem—sometime around the year 2080.
subject
subject Name
The subject, like the issuer, is a relative distinguished name. It includes an optional number of identifying fields, hopefully enough to identify the subject of the certificate. But, now that you mention it, who is the subject? If I have a certificate that identifies me, personally, the subject name (the CN field) should be my name, but if I'm connecting to a web site named www.whizbang.com, the subject field should identify that web site somehow.
As it turns out, this is actually poorly specified. The compromise here has been to insert the domain name into the CN field of the subject name and allow the client to compare the domain name it thinks it's connecting to against the domain name listed in the CN field of the certificate's subject. However, this is imperfect. Consider an e-commerce site that controls three different domains: shop.whizbang.com, purchase.whizbang.com and orders.whizbang.com. SSL certificates are expensive to obtain—at least, those issued by reputable CAs—and something of a hassle to maintain. The site administrator has to keep track of expiration dates and ensure that the certificates get reissued within a reasonable timeframe. As the administrator of whizbang.com, you'd really want one certificate that authenticates all of the site's servers. After all, www.whizbang.com almost certainly identifies multiple physical IP addresses.
As a result, it's acceptable for the certificate's subject's CN field to include a wildcard, such as *.whizbang.com. This actually creates other problems. If you can convince a CA to register you a certificate with a subject name including CN=*.com, you can masquerade as any site on the Internet, and the browser has no way of differentiating your certificate from the legitimate owner of the site. Although authorities are smart enough to check for this, security researcher Moxie Marlinspike, in his paper "Null Prefix Attacks Against SSL Certificates," detailed an interesting vulnerability not in the protocol itself but in most implementations of it. An attacker requests a certificate whose common name was *\0.badguy.com. Note the insertion of the null-terminator \0 in the domain name. Because he owns the top-level domain name badguy.com, the CA issues the certificate. However, a C-based client implementation almost certainly loads the common name into a string field and does a strcmp to determine equality—reading the common name as * or "any website". This is something that implementers of the TLS protocol need to be aware of; the length of the string needs to be checked, and null terminators before the actual end of the string should be removed. If you're lucky, the CA checks for this as well. You shouldn't rely on luck, though; as the implementer, make sure you protect your users against lazy CA's.
RFC 2247 extends the X.509 subject name to explicitly include domain-name components, split out according to the DNS hierarchy, so that www.whizbang.com becomes DC=www,DC=whizbang,DC=com. This new DC (domain-name component) attribute has OID 0.9.2342.19200300.100.1.25 and is not particularly common; most sites still instead use the CN field to identify their domain names. This is part of a chicken-and-egg problem; some older clients don't recognize the DC component, so to interoperate with them, sites identify themselves using the CN field. Because so few sites advertise DC components, there's little incentive for clients to recognize it. At the time of this writing, neither Firefox 3.6.3 nor Internet Explorer 8 properly recognize the DC field in the subject name, although RFC 3280 states that recognizing it is mandatory. If the DC field correctly identifies the domain name, but the CN does not (or is missing), a security exception is still reported. The DC field is more common in LDAP-based certificates; perhaps someday in the future, web browsers will make use of it.
A recent Internet-wide security analysis by Qualys Research found "22 million SSL servers with certificates that are completely invalid because they do not match the domain name on which they reside" (see http://www.esecurityplanet.com/features/article.php/3890171/SSL-Certificates-In-Use-Today-Arent-All-Valid.htm), although some of this is likely caused by virtual hosting rather than truly invalid SSL certificates.
subjectPublicKeyInfo
subjectPublicKeyInfo SubjectPublicKeyInfo
Here is the heart of the certificate—the public key that it presents. On the client side, when the certificate is received, you use the issuer, validity period, and the subject field to decide whether you trust the public key well enough to use it to perform a key exchange. If the subject matches the host you think you're connecting to, the certificate hasn't expired, and the issuer is one you trust, you have reasonable assurance that there's no man in the middle and you can go forward with the key exchange and, presumably, trade sensitive information over the now-secured channel.
The definition for SubjectPublicKeyInfo is
SubjectPublicKeyInfo ::= SEQUENCE {
algorithm AlgorithmIdentifier,
subjectPublicKey BIT STRING }
The AlgorithmIdentifier, it should come as no surprise, includes an OID. Two possible values of interest are shown in Table 5-4.
Table 5-4: Public-Key Algorithm OIDs
| ALGORITHM IDENTIFIER | OID |
| RSA | 2A 86 48 86 F7 0D 01 01 01 |
| Diffie-Hellman | 2A 86 48 CE 3E 02 01 |
NOTE Elliptic-curve Diffie-Hellman support in X.509 certificates is examined in Chapter 9.
The public key itself is defined here as a simple bit string. Recall from Chapter 4, though, that you need some pretty specific information in a pretty specific format to do key exchanges, For RSA, for example, you need the modulus n and the public exponent e. So, as it turns out, the BIT STRING here actually encodes another ASN.1 formatted value, whose contents vary depending on the value of the algorithm identifier. For RSA, this is
RSAPublicKey ::= SEQUENCE {
modulus INTEGER, -- n
publicExponent INTEGER -- e -- }
So, after decoding the OID, you then need to ASN.1 decode the bit string as yet another ASN.1 value to extract the actual public key.
If you recall, regular (e.g. non-elliptic-curve) Diffie-Hellman key exchange doesn't involve a public key the way RSA does. There were two parameters needed, though: the generator g and the field parameter p. The contents of the public key field, in this case, is simply:
DHPublicKey ::= INTEGER -- public key, y = g^x mod p
Of course, the public y value is useless to the client without g and p. You might expect to see them in the public key structure, as you see with n in the RSAPublicKey, but instead the Diffie-Hellman generator and group are passed as algorithm parameters. Notice in the declaration of algorithm in SubjectPublicKeyInfo that the type is actually AlgorithmIdentifier. This includes an OID identifying the algorithm, but allows optional parameters to be included:
AlgorithmIdentifier ::= SEQUENCE {
algorithm OBJECT IDENTIFIER,
parameters ANY DEFINED BY algorithm OPTIONAL }
The parameters field is empty for RSA, but for DH, it's defined as
DomainParameters ::= SEQUENCE {
p INTEGER, -- odd prime, p=jq +1
g INTEGER, -- generator, g
q INTEGER, -- factor of p-1
j INTEGER OPTIONAL, -- subgroup factor
validationParms ValidationParms OPTIONAL }
ValidationParms ::= SEQUENCE {
seed BIT STRING,
pgenCounter INTEGER }
HOW TO AVOID A SMALL SUBGROUP ATTACK USING THE DIFFIE-HELLMAN KEY
If you recall the discussion of Diffie-Hellman key exchange in Chapter 3, you may remember that p and g are the only two parameters that you need in order to perform a key exchange. Each side chooses a random secret number a or b, sends the other side y = ga%p, and the receiving side computes yb%p to complete the key agreement (refer back to Chapter 3 if this is still a bit fuzzy). So—you may wonder—what are those extra parameters, q, j, and validationParms for? Well, when p and g are fixed parameters—used over and over for multiple key exchanges—a poorly chosen p value can open the user to an attack called the small subgroup attack, described by Chae Hoon Lim and Pil Joon Lee in their paper, "A Key Recovery Attack on Discrete Log-based Schemes Using a Prime Order Subgroup." The attack itself is mathematically complex, and I won't go into the details here. As it turns out, SSL/TLS ordinarily uses Diffie-Hellman key exchange in such a way that guarding against the small subgroup attack is unnecessary; this will be examined in more detail in Chapter 8. If you're curious, and would like to see more detail on how these parameters may be used to guard against small subgroup attacks, you may refer to RFC 2631.
extensions
extensions [3] EXPLICIT Extensions OPTIONAL
-- If present, version shall be v3
Finally, there is the generic extensions field introduced in X.509v3—in fact, this was the only addition to X.509v3. Certificate extensions, if present—which they almost always are these days—are appended here. extensions is a nested SEQUENCE of object identifiers, optionally followed by data (depending on the object identifier).
This book doesn't go through all the available certificate extensions. RFC 5280, section 4.2 lists all of the standard ones, but be aware that two entities can agree on non-standard extensions as well. There are, however, a handful of particularly important ones.
The extensions type is defined as
Extensions ::= SEQUENCE SIZE (1..MAX) OF Extension
and the extension type itself is defined as
Extension ::= SEQUENCE {
extnID OBJECT IDENTIFIER,
critical BOOLEAN DEFAULT FALSE,
extnValue OCTET STRING }
Each extension has a unique object identifier; this object identifier determines how the extnValue is parsed, or if it's even present. Additionally, there's a critical field. If an extension is marked critical, and the reader doesn't recognize it, it must reject the entire certificate; otherwise, unrecognized extensions can be ignored. Most extensions are not marked critical.
The Subject Alternative Name extension (OID 55 1D 11) is a useful, but not widely used, extension. This extension offers a place to specifically identify a server's domain name; it also supports e-mail addresses, IP addresses, other directory names, and so on. Because the domain name is explicit, the common-name field no longer needs to be assumed to be the domain name. Unfortunately, this extension has failed to catch on, chiefly for the same reason the DC component in the subject name failed to catch on; to support older clients, servers must continue to set the common name to be the same as domain name. (In fact, it's unclear what, if anything, ought to be in the CN component of a certificate's subject when the certificate identifies a web site, if not the domain name.)
There are additional certificate extensions throughout the remainder of this chapter. Each one is encoded according to the Extension structure defined above, and is identified uniquely by an OID. Incidentally, all of the extension OIDs start with 55 1D.
Signed Certificates
Now, as you browse over the list of fields described in the certificate structure from Listing 5-1, you may have noticed that although a signing algorithm is included, a signature isn't. As you recall from Chapter 4, a signature is generated when a byte sequence is hashed and the hash is encrypted using a private key. So, one thing that must be agreed upon before a signature can be generated is exactly which bytes are hashed. In this case, it's the bytes of the certificate structure—technically, the certificate's DER encoding (described later). So, there's another outer structure defined, which includes the certificate, the signature algorithm (again), and the signature value itself, as shown in Listing 5-2.
Listing 5-2: X.509 signed certificate declaration
Certificate ::= SEQUENCE {
tbsCertificate TBSCertificate,
signatureAlgorithm AlgorithmIdentifier,
signatureValue BIT STRING }
The certificate structure defined here is properly referred to as the TBSCertificate. TBS stands for To Be Signed, although the ones examined here have already been signed. If you think about the overall lifecycle of a certificate, this nomenclature makes sense. First, the certificate requester (e.g. the website owner) generates a public/private keypair and wraps up that information in a To-be-signed certificate structure. This is sent off to the CA, which signs it (after verifying it) and returns the whole certificate back, complete with its digital signature.
The signature algorithm is—in fact, must be—the exact same as the OID given in the TBSCertificate itself. The signature, of course, is a bit string. The use of a bit string—the ASN.1 equivalent of a void pointer—runs into the same definitional problem with subjectPublicKeyInfo; the precise contents vary depending on the signature algorithm itself. Therefore, again, the BIT STRING itself is another ASN.1-defined structure, depending on the algorithm identifier.
NOTE A certificate can legally be signed by the private key corresponding to the public key contained within it. This sort of certificate is called a self-signed certificate. After all, my certificate is signed by a CA, but who signs their certificates? As a result, all top-level certificates are self-signed this way. How the client decides which self-signed top-level certificates to trust is not defined by the SSL specification. In the context of a web browser, for example, there's always a list of trusted CAs that can be updated by the user.
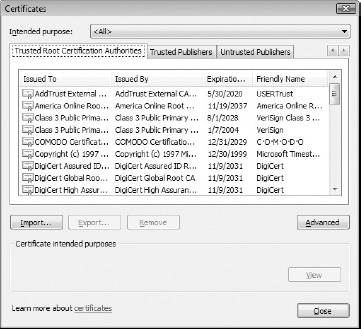
You can see which CAs your browser trusts. If you're using Internet Explorer 8, for instance, go to Tools  Internet Options Publishers, and click the Trusted Root Certification Authorities tab, as shown in Figure 5-4:
Internet Options Publishers, and click the Trusted Root Certification Authorities tab, as shown in Figure 5-4:
Figure 5-4: Sample of trusted root authorities in IE 8
X.509 is designed to allow delegation of signing authority. A top-level CA can issue and sign a certificate to, for instance, a "west coast" authority and an "east coast" authority. These authorities can sign certificates on behalf of the top-level CA. The receiver first verifies that the lowest-level certificate is valid according to the delegated authority's certificate. Then it checks the signature of the delegated authority against that of the root-level authority as illustrated in Figure 5-5.
Figure 5-5: Certificate authority delegation
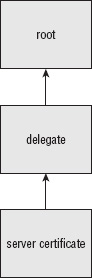
This way, the verifier—for example, the web client—only needs to keep track of a small number of root CAs. A handful of trusted root authorities can certify other authorities, and the client only has to be aware of a dozen or so root authorities. You can extend this scheme to any level of sub-delegates; the client just goes on checking signatures until it finds a signature issued by an authority it already trusts.
Unfortunately, this system was put in place and used for a while before somebody identified a fatal flaw. The problem is that every certificate includes a public key, and any public key can sign another certificate. Therefore, there's nothing stopping an unscrupulous site administrator from using a regular server certificate to sign another certificate, as shown in Figure 5-6, for example.
Figure 5-6: Illegitimate delegation
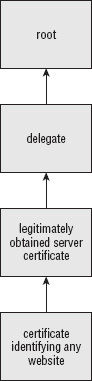
As a result, almost all clients are designed to require that each certificate be signed by a trusted authority and to reject delegated signatures.
The Key Usage certificate extension—OID 55 1D 0F—was introduced to allow this sort of delegated signature scheme in a safe way; this (critical) extension encodes a bit string, each of whose eight bits is either set or unset to identify that the public-key contained in this certificate may or may not be used for a particular purpose. Of course, there's nothing stopping an unscrupulous user from using the key for a nonspecified purpose anyway, but the receiver can check the key usage bit and determine whether to allow the sender to do so. The most important bit is bit 5, which, if set, identifies this certificate as a legitimate signing authority. Presumably, the issuing CA only allows this bit to be set if it trusts the requester to be responsible and sign other certificates on behalf of the CA itself.
Summary of X.509 Certificates
I've covered a lot of ground in this section, and it's easy to get lost in all of the details. To summarize: when your browser warns you about certificate errors, it's referring to an X.509 certificate that was presented by the target web site to identify itself. Such a certificate must be presented in order to guard against man-in-the-middle attacks. An X.509 certificate itself is a mapping of an entity name (e.g. a person or a website) to a public key. This mapping has a validity period and is vouched for by a trusted entity called a certificate authority. As long as all of these elements are present, you have a legitimate certificate. The X.509 specification takes it a step further and tells you what order they should be stored in and what form they should take.
Transmitting Certificates with ASN.1 Distinguished Encoding Rules (DER)
Quite a bit has been said so far about the abstract structure of a certificate without discussing how one is actually represented in byte form. The translation of primitive (ASN.1) types to byte representation is described according to a set of rules. Technically, these rules are independent of ASN.1 itself. I mentioned earlier that a certificate is the sort of thing that would probably be represented in XML these days—there is, in fact, a set of rules to encode ASN.1 in XML format! However, by far the most common encoding, and the one that SSL relies on, is called the Distinguished Encoding Rules (DER). The distinguished differentiates the rules from another set called the basic encoding rules. Fundamentally, the distinguished rules are more restrictive than the basic rules. For example, the basic rules allow the encoder to use more bytes than necessary to specify lengths (if the encoder wants all lengths to be encoded in a fixed set of bytes, for example). For the most part, the differences are superficial, and the basic encoding rules (BER) won't be specifically covered here.
The DER describes how to format integers, strings, dates, object identifiers, bit strings, sequences and sets—as well as several others, but these are the ones that are pertinent to the present discussion about X.509 certificates. See X.690 for a complete listing of DER encoding rules.
Encoded Values
Every encoded value is represented as a type, followed by the value's length, followed by the actual contents of the value itself; the representation of the value depends on the type. So, for example, the type integer is byte 02. DER allows for multi-byte types as well—and has complex rules on how to encode and recognize them—but X.509 doesn't need to make use of them and sticks with single-byte types. Therefore, the integer value 5 is encoded, according to DER, as
02 01 05
That's type 2 (integer), one byte in length, value 5. The integer value 65535 is encoded as
02 02 FF FF
That's type 2, two bytes, value 0xFFFF equals 65535. The length byte tells you when to stop reading the value and start looking for another tag.
So far, so good. It's pretty simple. OID's are just as simple to encode. They're stored just like integers, but they have a type of 6 instead of 2. Otherwise, they're encoded the same way: type, length, value. The OID common name (in the subject and issuer distinguished name fields) of 55 04 03 is represented as
06 03 55 04 03
The length byte tells you that there are three bytes of OID.
Strings and Dates
Strings and dates are both encoded similarly. The type code for a date is either 23 or 24; 23 is a generalized—four-digit year—time. 24 is a UTC—two-digit year—time. Although the type actually includes enough information to infer the length—you know that generalized times are 15 digits, and UTC times are 13—for consistency's sake the lengths are included as well. After that, the year, month, day, hour, minute, second and Z are included in ASCII format. So the date Feb. 23, 2010, 6:50:13 is encoded in UTC time as

and is encoded in generalized time as
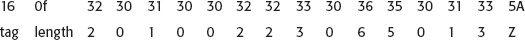
Strings are also coded this way. However, there are quite a few different string types to account for different byte encodings (among other things). The official specification is actually not proscriptive about which type of string should be used, and you actually see different kinds. However, the most common are IA5Strings (type 22) and printable strings (type 19), which you can treat interchangeably. Given, for example, the country code "US" in a name field, the encoding would be
13 02 55 53
which is the ASCII representation of the string "US."
Bit Strings
So far, DER is pretty straightforward, and everything except bit strings, sequences and sets has been covered. Bit strings are just like strings, with one minor difference. Their type is 3 to distinguish them from printable strings, but the encoding is exactly the same: tag, length, contents. The only difference between bit strings and character strings is that bit strings don't necessarily have to end on an eight-bit boundary, so they have an extra byte to indicate how much padding was included. In practice, this is always 0 because all useful bit patterns are eight-bit aligned anyway.
However, as you recall from the discussion of public key algorithms and signature values, bit strings contain nested ASN.1 structures. All the examples of DER-encoded values examined so far have been able to get away with representing their length with a single byte, but a nested ASN.1 structure is bound to be larger than this. So how are lengths greater than 255 represented?
Actually, a single-length byte can only represent 127 byte values. The high-order bit is reserved. If it's 1, then the low order seven bits represent not the length of the value, but the length of the length—that is, how many of the bytes following encode the length of the subsequently following value. So, if a bit string is 512 bytes long, the DER-encoded representation looks like Table 5-5:
Table 5-5: ASN.1 Encoding of Long Values

Technically, a value doesn't have to be a bit string to have a length greater than 127; integers, strings, and OIDs could, at least in theory. In practice, though, this never happens.
Sequences and Sets: Grouping and Nesting ASN.1 Values
So, you're almost ready to start encoding an entire X.509 certificate. There are two missing pieces, though. Notice that there are several sequences nested inside other sequences, and sets nested inside sequences (and sequences nested inside sets...). Sets and sequences are what ASN.1 calls a constructed type—that is, a type containing other types. Technically, they're encoded the same way other values are. They start with a tag, are followed by a variable number of length bytes, and are then followed by their contents. However, for constructed types, the contents themselves are further ASN.1-encoded tags. Sequences are identified by tag 0x30, and sets are identified by tag 0x31. Any tag value whose sixth bit is 1 is a constructed tag and the parser must recognize that it contains additional ASN.1-encoded data.
ASN.1 Explicit Tags
Finally, turn back and look at the definition of the tbsCertificate. Notice that the first field is an optional version number, and the second field is a required serialNumber, and they're both numeric. When parsing a certificate, then, you know for certain that the first value you come across is a number, but you have to check the value of the first value to determine how to interpret the first value! Clearly this is not an optimal way to go about parsing certificates.
To get around this, ASN.1 also allows for explicit tags. Notice in the definition of the tbsCertificate that Version is listed as [0] EXPLICIT.
SEQUENCE {
version [0] EXPLICIT Version DEFAULT v1,
serialNumber CertificateSerialNumber,
So far, tags have been presented as randomly distributed identifiers. Actually, the first two bits of a tag identify its tag class. In X.509 you come across two types of tag classes: universal (00) and context-specific (10). (The other two are application and private and are not used in X.509 certificates.) Context-specific tags are explicit tags. So, to create an explicit tag 0, OR 0 with 1000 0000 (0x80). This is also a constructed tag—its contents are the actual version number—so the sixth bit is set to 1 (OR 0x20).
A Real-World Certificate Example
An example might help clear up any remaining confusion here. To see an actual certificate, you can download one from any SSL-enabled site, or create a new one. The latest version of IE makes it a bit difficult to directly download a certificate, but it's still fairly straightforward with Firefox:
- Navigate to a secure site.
- Click the lock icon.
- Select Security View Certificate.
- Click the Details tab, shown in figure 5-7, and then click the Export button.
Using OpenSSL to Generate an RSA KeyPair and Certificate
To keep the first example simple, go ahead and just create a new certificate. OpenSSL has a req option that enables you to generate a self-signed certificate. Do so and then examine its contents.
jdavies@home:ssl$ openssl req -x509 -newkey rsa:512 -keyout key.der -keyform der \ -out cert.der -outform der Generating a 512 bit RSA private key .....++++++++++++ ........++++++++++++
writing new private key to 'key.der' Enter PEM pass phrase: Verifying - Enter PEM pass phrase: ---- You are about to be asked to enter information that will be incorporated into your certificate request. What you are about to enter is what is called a Distinguished Name or a DN. There are quite a few fields but you can leave some blank For some fields there will be a default value, If you enter '.', the field will be left blank. ---- Country Name (2 letter code) [AU]:US State or Province Name (full name) [Some-State]:TX Locality Name (eg, city) []:Southlake Organization Name (eg, company) [Internet Widgits Pty Ltd]:Travelocity Organizational Unit Name (eg, section) []:Architecture Common Name (eg, YOUR name) []:Joshua Davies Email Address []:joshua.davies@travelocity.com
Figure 5-7: Downloading/exporting a certificate in Firefox
Notice that it created two output files: a key file, containing the encrypted private key, and a cert file, containing the certificate. It doesn't make much sense to generate a new public key without a private key to go with it. The structure of this key file is revisited later.
Also, notice the parameters: -keyform and -outform. There are two options here, der and pem. der is, unsurprisingly, the ASN.1 DER-encoded representation of the certificate or key file. pem, which stands for Privacy Enhanced Mail, is a Base-64 encoded representation of the DER-encoded certificate with a header and a footer. A pem-encoded certificate file looks like this:
-----BEGIN CERTIFICATE---- MIIDUjCCAvygAwIBAgIJAMdcnerewaJQMA0GCSqGSIb3DQEBBQUAMIGkMQswCQYD VQQGEwJVUzEOMAwGA1UECBMFVGV4YXMxEjAQBgNVBAcTCVNvdXRobGFrZTEUMBIG ... AwEB/zANBgkqhkiG9w0BAQUFAANBAKf3QiQgbre9DSq4aeED9v0nonEHXPRsU79j l3q/IUMlhmtuZ4SIlNAPvRdZ6DUIvWqVVJbtl5Bm7MKo7KCMarc= -----END CERTIFICATE-----
And a pem-encoded key file looks like this:
-----BEGIN RSA PRIVATE KEY----- Proc-Type: 4,ENCRYPTED DEK-Info: DES-EDE3-CBC,DF6F51939AF51B22 +cvob7sZl6Ew8/iBqNUF1Q40B14mYzw43cS08/xpzbqtkczYfiQeYN8N4dl8h3tp VzoeCoRKsBKtl89NtpzTJocv33vgcaTFHt1BXBnOPxrQALhyV1x4ADIoW5e7rvsW ... RmyqjA8BH9JeCPzvJlmir55OYB9aCQBTR3+mAlvVrnx5eng1f0YCw/tneXJor3jT IgYBcTpEvug5qeGVl27UA2cI/lcCuNQ0Cjdfztlhhmo= -----END RSA PRIVATE KEY-----
These structures are more amenable to being transmitted in e-mail than DER-encoded files. SSL always deals in DER-encoded files, though.
NOTE You'll encounter the term PEM every once in a while as you read through the official Internet documentation on certificates. Privacy-Enhanced Mail was the first attempt to apply X.509 certificates in an Internet context, so some of the terminology stuck.
The cert.der file is 845 bytes long. If you did this yourself and used your own name, location, and e-mail information, it might be slightly longer or shorter, but should be in this same neighborhood. The contents of this file are
jdavies@home:ssl$ od -t x1 cert.der 0000000 30 82 03 49 30 82 02 f3 a0 03 02 01 02 02 09 00 0000020 ca 30 e1 8f 77 8d a2 81 30 0d 06 09 2a 86 48 86 0000040 f7 0d 01 01 05 05 00 30 81 a1 31 0b 30 09 06 03 0000060 55 04 06 13 02 55 53 31 0b 30 09 06 03 55 04 08 0000100 13 02 54 58 31 12 30 10 06 03 55 04 07 13 09 53 0000120 6f 75 74 68 6c 61 6b 65 31 14 30 12 06 03 55 04 0000140 0a 13 0b 54 72 61 76 65 6c 6f 63 69 74 79 31 15 0000160 30 13 06 03 55 04 0b 13 0c 41 72 63 68 69 74 65 0000200 63 74 75 72 65 31 16 30 14 06 03 55 04 03 13 0d
0000220 4a 6f 73 68 75 61 20 44 61 76 69 65 73 31 2c 30 0000240 2a 06 09 2a 86 48 86 f7 0d 01 09 01 16 1d 6a 6f 0000260 73 68 75 61 2e 64 61 76 69 65 73 40 74 72 61 76 0000300 65 6c 6f 63 69 74 79 2e 63 6f 6d 30 1e 17 0d 31 0000320 30 30 33 30 32 32 32 34 36 32 33 5a 17 0d 31 30 0000340 30 34 30 31 32 32 34 36 32 33 5a 30 81 a1 31 0b 0000360 30 09 06 03 55 04 06 13 02 55 53 31 0b 30 09 06 0000400 03 55 04 08 13 02 54 58 31 12 30 10 06 03 55 04 0000420 07 13 09 53 6f 75 74 68 6c 61 6b 65 31 14 30 12 0000440 06 03 55 04 0a 13 0b 54 72 61 76 65 6c 6f 63 69 0000460 74 79 31 15 30 13 06 03 55 04 0b 13 0c 41 72 63 0000500 68 69 74 65 63 74 75 72 65 31 16 30 14 06 03 55 0000520 04 03 13 0d 4a 6f 73 68 75 61 20 44 61 76 69 65 0000540 73 31 2c 30 2a 06 09 2a 86 48 86 f7 0d 01 09 01 0000560 16 1d 6a 6f 73 68 75 61 2e 64 61 76 69 65 73 40 0000600 74 72 61 76 65 6c 6f 63 69 74 79 2e 63 6f 6d 30 0000620 5c 30 0d 06 09 2a 86 48 86 f7 0d 01 01 01 05 00 0000640 03 4b 00 30 48 02 41 00 e0 13 38 0f 83 b6 ef 06 0000660 70 f5 5b aa 3a 2b cf 8e 95 ff 91 b1 90 03 52 51 0000700 69 73 de a7 fa 97 fb 56 0d b9 e9 0f e8 30 22 8c 0000720 5e f0 1f 07 f0 dc cc 61 b8 01 0e b1 b0 58 ef b5 0000740 b4 54 16 70 eb 59 b4 bf 02 03 01 00 01 a3 82 01 0000760 0a 30 82 01 06 30 1d 06 03 55 1d 0e 04 16 04 14 0001000 2d f1 04 e4 46 1d 72 ef bb a7 ce 05 58 4c 31 f1 0001020 ff 8e 4e 2e 30 81 d6 06 03 55 1d 23 04 81 ce 30 0001040 81 cb 80 14 2d f1 04 e4 46 1d 72 ef bb a7 ce 05 0001060 58 4c 31 f1 ff 8e 4e 2e a1 81 a7 a4 81 a4 30 81 0001100 a1 31 0b 30 09 06 03 55 04 06 13 02 55 53 31 0b 0001120 30 09 06 03 55 04 08 13 02 54 58 31 12 30 10 06 0001140 03 55 04 07 13 09 53 6f 75 74 68 6c 61 6b 65 31 0001160 14 30 12 06 03 55 04 0a 13 0b 54 72 61 76 65 6c 0001200 6f 63 69 74 79 31 15 30 13 06 03 55 04 0b 13 0c 0001220 41 72 63 68 69 74 65 63 74 75 72 65 31 16 30 14 0001240 06 03 55 04 03 13 0d 4a 6f 73 68 75 61 20 44 61 0001260 76 69 65 73 31 2c 30 2a 06 09 2a 86 48 86 f7 0d 0001300 01 09 01 16 1d 6a 6f 73 68 75 61 2e 64 61 76 69 0001320 65 73 40 74 72 61 76 65 6c 6f 63 69 74 79 2e 63 0001340 6f 6d 82 09 00 ca 30 e1 8f 77 8d a2 81 30 0c 06 0001360 03 55 1d 13 04 05 30 03 01 01 ff 30 0d 06 09 2a 0001400 86 48 86 f7 0d 01 01 05 05 00 03 41 00 1b 63 7b 0001420 f5 13 ef 2e 3d 56 22 3d a2 4c d5 0e 31 8d 0c 25 0001440 bb 24 30 fd a3 20 f5 a3 b5 7d 1b cb 1e a8 bd b0 0001460 ce 78 8b e7 5e 7a ac 66 2c 6d 06 06 e8 e3 06 24 0001500 ca d5 ce 0d 99 1a 7c 37 53 4d d3 be 83
It's worth taking the time to break this file down into its constituent parts. As discussed above, the first byte is a tag. 0x30 is a sequence, as you would expect—this should be a signed certificate sequence. This tag is followed by its length. Because the high-order bit of the length byte (0x82) is 1, this indicates that the next two bytes are the length of the sequence. These bytes are 0x0349, or decimal 841. This looks right—four bytes of the 845-byte file are the sequence and length tag, the remaining 841 are its content. The next byte is another sequence (0x30). Remember that the first element of a signed certificate is a tbsCertificate, which is itself a sequence. Again, the length takes up two bytes of the input stream, and is 0x02F3, or decimal 755. That leaves 86 bytes, toward the end, to contain the signature. Recall from Chapter 4 that this is about the right length for a 512-bit RSA signature value.
Table 5-6 presents an annotated breakdown of this certificate.
Table 5-6: Disassembled Certificate
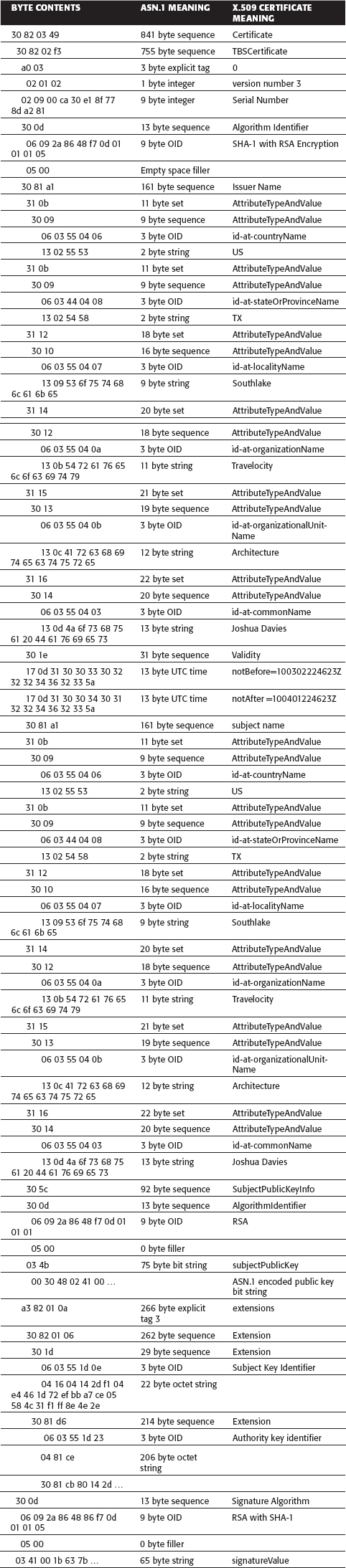
Note that the interpretation of the second column is automatic and requires no context. However, the interpretation of the third column—the actual certificate contents—requires that you keep close track of the sequences, sets, and so on and match them against the definition. One frustrating thing about ASN.1 DER-encoded strings is that they don't carry any identifying information with them. You can often recognize a DER-encoded file by the 30 byte that (usually) starts it, but if you don't have some external information indicating what type of file it is, you'll never be able to figure out what sort of file you're looking at.
Using OpenSSL to Generate a DSA KeyPair and Certificate
The example certificate in the previous section included an RSA public key. Although this is by far the most common certificate form, OpenSSL allows you to generate certificates that include DSA keys as well. (It does not, at the time of this writing, allow the creation of a certificate with Diffie-Hellman parameters as discussed earlier). The process is slightly more involved, though. First, you must create a set of DSA parameters (p, q, and g):
[jdavies@localhost ssl]$ openssl dsaparam 512 -out dsaparam.cer Generating DSA parameters, 512 bit long prime This could take some time ..+................+.....+++++++++++++++++++++++++++++++++++++++++++++++++++* .......+..+...........+........................................+.....+..+...... ... ........+..+.....+......................+............+....+.+....+............. ... .+.+........+.........................................+....+..+.+.....+..+..+.. ... .+...........+...+..........+.........................+.............+.......... ... +.......+...+............+....+....++++++++++++++++++++++++++++++++++++++++++++ +++ ++++*
You pass this in to your certificate request:
[jdavies@localhost ssl]$ openssl req -x509 -newkey dsa:dsaparam.cer -keyout \ dsakey.der -keyform der -out dsacert.der -outform der Generating a 512 bit DSA private key writing new private key to 'dsakey.der' Enter PEM pass phrase: Verifying - Enter PEM pass phrase: ----- You are about to be asked to enter information that will be incorporated into your certificate request. What you are about to enter is what is called a Distinguished Name or a DN. There are quite a few fields but you can leave some blank For some fields there will be a default value, If you enter '.', the field will be left blank. ----- Country Name (2 letter code) [GB]:US State or Province Name (full name) [Berkshire]:Texas Locality Name (eg, city) [Newbury]:Southlake Organization Name (eg, company) [My Company Ltd]:Travelocity Organizational Unit Name (eg, section) []:Architecture Common Name (eg, your name or your server's hostname) []:Joshua Davies Email Address []:joshua.davies@travelocity.com
Developing an ASN.1 Parser
By now, you're probably itching to see some code. You develop code to parse an X.509 certificate in two parts; first, deconstruct the DER-encoded ASN.1 structure into its constituent parts and then interpret these parts as an X.509 certificate. ASN.1-encoded values can be represented naturally as nodes of the form shown in Listing 5-3.
Listing 5-3: "asn1.h" asn1struct definition
struct asn1struct
{
int constructed; // bit 6 of the identifier byte
int tag_class; // bits 7-8 of the identifier byte
int tag; // bits 1-5 of the identifier byte
int length;
const unsigned char *data;
struct asn1struct *children;
struct asn1struct *next;
};
Converting a Byte Stream into an ASN.1 Structure
The first five elements ought to be relatively straightforward if you understood the description of ASN.1 DER in the previous section. The last two are used to navigate the hierarchy. Each asn1struct is part of a linked list of other asn1struct structures, and each one optionally points to the head of another linked list that is its child. So, after parsing, the first part of the certificate is represented in memory as shown in Figure 5-8.
Figure 5-8: Partial illustration of a certificate structure
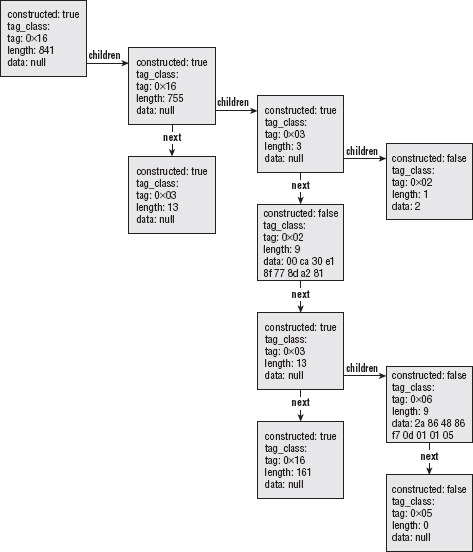
As you can see, locating a node is a matter of starting at the root, and traversing any number of children or nexts until you reach the one you're looking for. The tree structure is preserved by the use of the children pointers. Define a handful of constants to clarify the code as shown in Listing 5-4.
Listing 5-4: "asn1.h" constants
#define ASN1_CLASS_UNIVERSAL 0 #define ASN1_CLASS_APPLICATION 1 #define ASN1_CONTEXT_SPECIFIC 2 #define ASN1_PRIVATE 3 #define ASN1_BER 0 #define ASN1_BOOLEAN 1 #define ASN1_INTEGER 2 #define ASN1_BIT_STRING 3 #define ASN1_OCTET_STRING 4 #define ASN1_NULL 5 #define ASN1_OBJECT_IDENTIFIER 6 #define ASN1_OBJECT_DESCRIPTOR 7 #define ASN1_INSTANCE_OF_EXTERNAL 8 #define ASN1_REAL 9 #define ASN1_ENUMERATED 10 #define ASN1_EMBEDDED_PPV 11 #define ASN1_UTF8_STRING 12 #define ASN1_RELATIVE_OID 13 // 14 & 15 undefined #define ASN1_SEQUENCE 16 #define ASN1_SET 17 #define ASN1_NUMERIC_STRING 18 #define ASN1_PRINTABLE_STRING 19 #define ASN1_TELETEX_STRING 20 #define ASN1_T61_STRING 20 #define ASN1_VIDEOTEX_STRING 21 #define ASN1_IA5_STRING 22 #define ASN1_UTC_TIME 23 #define ASN1_GENERALIZED_TIME 24 #define ASN1_GRAPHIC_STRING 25 #define ASN1_VISIBLE_STRING 26 #define ASN1_ISO64_STRING 26 #define ASN1_GENERAL_STRING 27 #define ASN1_UNIVERSAL_STRING 28 #define ASN1_CHARACTER_STRING 29 #define ASN1_BMP_STRING 30
The recursive ASN.1 parser routine itself is surprisingly simple (see Listing 5-5).
Listing 5-5: "asn1.c" asn1parse
int asn1parse( const unsigned char *buffer,
int length,
struct asn1struct *top_level_token )
{
unsigned int tag;
unsigned char tag_length_byte;
unsigned long tag_length;
const unsigned char *ptr;
const unsigned char *ptr_begin; struct asn1struct *token; ptr = buffer; token = top_level_token; while ( length ) { ptr_begin = ptr; tag = *ptr; ptr++; length--; // High tag # form (bits 5-1 all == "1"), to encode tags > 31. Not used // in X.509 if ( ( tag & 0x1F ) == 0x1F ) { tag = 0; while ( *ptr & 0x80 ) { tag <<= 8; tag |= *ptr & 0x7F; } } tag_length_byte = *ptr; ptr++; length--; // TODO this doesn't handle indefinite-length encodings (according to // ITU-T X.690, this never occurs in DER, only in BER, which X.509 doesn't // use) if ( tag_length_byte & 0x80 ) { const unsigned char *len_ptr = ptr; tag_length = 0; while ( ( len_ptr - ptr ) < ( tag_length_byte & 0x7F ) ) { tag_length <<= 8; tag_length |= *(len_ptr++); length--; } ptr = len_ptr; } else { tag_length = tag_length_byte; } // TODO deal with "high tag numbers" token->constructed = tag & 0x20;
token->tag_class = ( tag & 0xC0 ) >> 6; token->tag = tag & 0x1F; token->length = tag_length; token->data = ptr; token->children = NULL; token->next = NULL; if ( tag & 0x20 ) { token->length = tag_length + ( ptr - ptr_begin ); token->data = ptr_begin; // Append a child to this tag and recurse into it token->children = ( struct asn1struct * ) malloc( sizeof( struct asn1struct ) ); asn1parse( ptr, tag_length, token->children ); } ptr += tag_length; length -= tag_length; // At this point, we're pointed at the tag for the next token in the buffer. if ( length ) { token->next = ( struct asn1struct * ) malloc( sizeof( struct asn1struct ) ); token = token->next; } } return 0; }
This routine is passed a complete certificate structure, so the whole thing must be resident in memory before this routine is called; this approach might need to be revisited in, say, a handheld device where memory is constrained. It reads through the whole buffer, recognizing ASN.1 structures, and allocating asn1struct instances to represent them.
- Check to see if this is a multi-byte tag:
if ( ( tag & 0x1F ) == 0x1F ) { tag = 0; while ( *ptr & 0x80 ) { tag <<= 8;X.509 doesn't define any of these, but you ought to recognize them for completeness—if for no other reason than to be able to safely ignore them if you happen to come across one.
- Parse out the length of the structure itself; this is always present. If the first byte is a multi-length byte, the processing is a bit complex in part because of the endian-ness issue.
if ( tag_length_byte & 0x80 ) { const unsigned char *len_ptr = ptr; tag_length = 0; while ( ( len_ptr - ptr ) < ( tag_length_byte & 0x7F ) ) { tag_length <<= 8; tag_length |= *(len_ptr++); length--; } ptr = len_ptr; } else { tag_length = tag_length_byte; } - Now that you know the type of tag and the length of its contents—whether they are data or other ASN.1 structures—you can start filling out the asn1struct instance:
token->constructed = tag & 0x20; token->tag_class = ( tag & 0xC0 ) >> 6; token->tag = tag & 0x1F; token->length = tag_length; token->data = ptr; token->children = NULL; token->next = NULL;
- Now the tricky part—if this is a constructed tag, its contents are more ASN.1 structures, which must be appended to the children list. If it is then allocate a new structure to store the children and recursively call this routine:
if ( tag & 0x20 ) { token->length = tag_length + ( ptr - ptr_begin ); - When it returns, or if it wasn't called because the tag was a non-constructed tag, you're either at the end of the data or you're pointing at the next element relative to the one that was just parsed.
if ( length ) { token->next = ( struct asn1struct * ) malloc( sizeof( struct asn1struct ) ); token = token->next; } - If there is another element to parse, allocate space for it, update the target token pointer, and loop back around to process this element. When you're finished the supplied top_level_token structure points to the root of a fully parsed ASN.1 tree.
- Finally, because a lot of memory is allocated by the ASN.1 parsing process, define a function to recursively go through and clean it all up as shown in Listing 5-6.
Listing 5-6: "asn1.c" asn1free
/**
* Recurse through the given node and free all of the memory that was allocated
* by asn1parse. Don't free the "data" pointers, since that points to memory
* that was not allocated by asn1parse.
*/
void asn1free( struct asn1struct *node )
{
if ( !node )
{
return;
}
asn1free( node->children );
free( node->children );
asn1free( node->next );
free( node->next );
}
As you can see, the recursive definition of the asn1struct structure makes cleanup and traversal very straightforward.
The asn1parse Code in Action
To see this code in action, put together a sample main routine as in Listing 5-7 that takes as input a certificate file (or any other ASN.1 DER-encoded file) and output the ASN.1 structure elements.
Listing 5-7: "asn1.c" test routine
#ifdef TEST_ASN1
int main( int argc, char *argv[ ] )
{
int certificate_file;
struct stat certificate_file_stat;
unsigned char *buffer, *bufptr;
int buffer_size;
int bytes_read;
struct asn1struct certificate;
if ( argc < 2 )
{
fprintf( stderr, "Usage: %s <certificate file>\n", argv[ 0 ] );
exit( 0 );
}
if ( ( certificate_file = open( argv[ 1 ], O_RDONLY ) ) == −1 )
{
perror( "Unable to open certificate file" );
return 1;
}
// Slurp the whole thing into memory
if ( fstat( certificate_file, &certificate_file_stat ) )
{
perror( "Unable to stat certificate file" );
return 2;
}
buffer_size = certificate_file_stat.st_size;
buffer = ( char * ) malloc( buffer_size );
if ( !buffer ) { perror( "Not enough memory" ); return 3; } bufptr = buffer; while ( bytes_read = read( certificate_file, ( void * ) buffer, certificate_file_stat.st_size ) ) { bufptr += bytes_read; } asn1parse( buffer, buffer_size, &certificate ); asn1show( 0, &certificate ); asn1free( &certificate ); return 0; } #endif
This invokes the asn1show routine in Listing 5-8.
Listing 5-8: "asn1.c" asn1show
static char *tag_names[] = {
"BER", // 0
"BOOLEAN", // 1
"INTEGER", // 2
"BIT STRING", // 3
"OCTET STRING", // 4
"NULL", // 5
"OBJECT IDENTIFIER", // 6
"ObjectDescriptor", // 7
"INSTANCE OF, EXTERNAL", // 8
"REAL", // 9
"ENUMERATED", // 10
"EMBEDDED PPV", // 11
"UTF8String", // 12
"RELATIVE-OID", // 13
"undefined(14)", // 14
"undefined(15)", // 15
"SEQUENCE, SEQUENCE OF", // 16
"SET, SET OF", // 17
"NumericString", // 18
"PrintableString", // 19
"TeletexString, T61String", // 20
"VideotexString", // 21 "IA5String", // 22 "UTCTime", // 23 "GeneralizedTime", // 24 "GraphicString", // 25 "VisibleString, ISO64String", // 26 "GeneralString", // 27 "UniversalString", // 28 "CHARACTER STRING", // 29 "BMPString" // 30 }; void asn1show( int depth, struct asn1struct *certificate ) { struct asn1struct *token; int i; token = certificate; while ( token ) { for ( i = 0; i < depth; i++ ) { printf( " " ); } switch ( token->tag_class ) { case ASN1_CLASS_UNIVERSAL: printf( "%s", tag_names[ token->tag ] ); break; case ASN1_CLASS_APPLICATION: printf( "application" ); break; case ASN1_CONTEXT_SPECIFIC: printf( "context" ); break; case ASN1_PRIVATE: printf( "private" ); break; } printf( " (%d:%d) ", token->tag, token->length ); if ( token->tag_class == ASN1_CLASS_UNIVERSAL ) { switch ( token->tag ) { case ASN1_INTEGER: break;
case ASN1_BIT_STRING: case ASN1_OCTET_STRING: case ASN1_OBJECT_IDENTIFIER: { int i; for ( i = 0; i < token->length; i++ ) { printf( "%.02x ", token->data[ i ] ); } } break; case ASN1_NUMERIC_STRING: case ASN1_PRINTABLE_STRING: case ASN1_TELETEX_STRING: case ASN1_VIDEOTEX_STRING: case ASN1_IA5_STRING: case ASN1_UTC_TIME: case ASN1_GENERALIZED_TIME: case ASN1_GRAPHIC_STRING: case ASN1_VISIBLE_STRING: case ASN1_GENERAL_STRING: case ASN1_UNIVERSAL_STRING: case ASN1_CHARACTER_STRING: case ASN1_BMP_STRING: case ASN1_UTF8_STRING: { char *str_val = ( char * ) malloc( token->length + 1 ); strncpy( str_val, ( char * ) token->data, token->length ); str_val[ token->length ] = 0; printf( " %s", str_val ); free( str_val ); } break; default: break; } } printf( "\n" ); if ( token->children ) { asn1show( depth + 1, token->children ); } token = token->next; } }
If you run this on a DER-encoded certificate file, you get an output similar to Table 5-6 (this was, in fact, how that table was generated). However, when most software saves certificate files, it doesn't do it in DER form; it uses PEM form instead. To use this parsing routine to see the contents of a PEM-encoded file, you can call the base64decode routine from Chapter 1 to convert PEM to DER as in Listing 5-9.
Listing 5-9: "asn1.c" pem_decode
int pem_decode( unsigned char *pem_buffer, unsigned char *der_buffer )
{
unsigned char *pem_buffer_end, *pem_buffer_begin;
unsigned char *bufptr = der_buffer;
int buffer_size;
// Skip first line, which is always "-----BEGIN CERTIFICATE-----".
if ( strncmp( pem_buffer, "-----BEGIN", 10 ) )
{
fprintf( stderr,
"This does not appear to be a PEM-encoded certificate file\n" );
exit( 0 );
}
pem_buffer_begin = pem_buffer;
pem_buffer= pem_buffer_end = strchr( pem_buffer, '\n' ) + 1;
while ( strncmp( pem_buffer, "-----END", 8 ) )
{
// Find end of line
pem_buffer_end = strchr( pem_buffer, '\n' );
// Decode one line out of pem_buffer into buffer
bufptr += base64_decode( pem_buffer,
( pem_buffer_end - pem_buffer ) -
( ( *( pem_buffer_end - 1 ) == '\r' ) ? 1 : 0 ),
bufptr );
pem_buffer = pem_buffer_end + 1;
}
buffer_size = bufptr - der_buffer;
return buffer_size;
}
Change the test main routine to accept either PEM or DER form:
if ( argc < 3 )
{
fprintf( stderr, "Usage: %s [-der|-pem] <certificate file>\n", argv[ 0 ] );
exit( 0 );
}
if ( ( certificate_file = open( argv[ 2 ], O_RDONLY ) ) == −1 )
{
...
}
if ( !( strcmp( argv[ 1 ], "-pem" ) ) ) { // XXX this overallocates a bit, since it sets aside space for markers, etc. unsigned char *pem_buffer = buffer; buffer = (unsigned char * ) malloc( buffer_size ); buffer_size = pem_decode( pem_buffer, buffer ); free( pem_buffer ); } asn1parse( buffer, buffer_size, &certificate );
You now have a working ASN.1 parser that can be used to read and interpret X.509 certificates. You could stop here, and write code like this:
root->next->next->children->next->children->next->data
to look up the values of specific elements in the tree, but to make your code have any semblance of readability, you should really continue to parse this ASN.1 tree into a proper X.509 structure.
Turning a Parsed ASN.1 Structure into X.509 Certificate Components
The X.509 structure is decidedly more complex than the ASN.1 structure; define it to mirror the ASN.1 definition. To keep the implementation easy to digest, the code is presented for RSA certificates—by far the most common case—and then extended to support DSA and Diffie-Hellman. The structure definitions are shown in Listing 5-10.
Listing 5-10: "x509.h" structure definitions
typedef enum
{
rsa,
dh
}
algorithmIdentifier;
typedef enum
{
md5WithRSAEncryption,
shaWithRSAEncryption
}
signatureAlgorithmIdentifier;
/**
* A name (or "distinguishedName") is a list of attribute-value pairs.
* Instead of keeping track of all of them, just keep track of
* the most interesting ones.
*/
typedef struct
{ char *idAtCountryName; char *idAtStateOrProvinceName; char *idAtLocalityName; char *idAtOrganizationName; char *idAtOrganizationalUnitName; char *idAtCommonName; } name; typedef struct { // TODO deal with the "utcTime" or "GeneralizedTime" choice. time_t notBefore; time_t notAfter; } validity_period; typedef huge uniqueIdentifier; typedef struct { algorithmIdentifier algorithm; rsa_key rsa_public_key; } public_key_info; typedef huge objectIdentifier; typedef struct { int version; huge serialNumber; // This can be much longer than a 4-byte long allows signatureAlgorithmIdentifier signature; name issuer; validity_period validity; name subject; public_key_info subjectPublicKeyInfo; uniqueIdentifier issuerUniqueId; uniqueIdentifier subjectUniqueId; int certificate_authority; // 1 if this is a CA, 0 if not } x509_certificate; typedef struct { x509_certificate tbsCertificate; signatureAlgorithmIdentifier algorithm; huge signature_value; } signed_x509_certificate;
Compare the x509_certificate structure in Listing 5-10 with the official ITU definition shown in Listing 5-1 and signed_x509_certificate with Listing 5-2. The goal of the certificate parsing process is to take a "blob" of unstructured bytes and turn it into a signed_x509_certificate instance. As you can see above, there's quite a bit of unallocated memory in this structure definition, so the first thing you need is an initializer function, as shown in Listing 5-11.
Listing 5-11: "x509.c" init_x509_certificate
void init_x509_certificate( signed_x509_certificate *certificate )
{
set_huge( &certificate->tbsCertificate.serialNumber, 1 );
memset( &certificate->tbsCertificate.issuer, 0, sizeof( name ) );
memset( &certificate->tbsCertificate.subject, 0, sizeof( name ) );
certificate->tbsCertificate.subjectPublicKeyInfo.rsa_public_key.modulus =
malloc( sizeof( huge ) );
certificate->tbsCertificate.subjectPublicKeyInfo.rsa_public_key.exponent =
malloc( sizeof( huge ) );
set_huge(
certificate->tbsCertificate.subjectPublicKeyInfo.rsa_public_key.modulus,
0 );
set_huge(
certificate->tbsCertificate.subjectPublicKeyInfo.rsa_public_key.exponent,
0 );
set_huge( &certificate->signature_value, 0 );
certificate->tbsCertificate.certificate_authority = 0;
}
You also need, of course, a companion "free" function as shown in Listing 5-12.
Listing 5-12: "x509.c" free_x509_certificate
static void free_x500_name( name *x500_name )
{
if ( x500_name->idAtCountryName ) { free( x500_name->idAtCountryName ); }
if ( x500_name->idAtStateOrProvinceName ) { free( x500_name-
>idAtStateOrProvinceName ); }
if ( x500_name->idAtLocalityName ) { free( x500_name->idAtLocalityName ); }
if ( x500_name->idAtOrganizationName ) { free( x500_name->idAtOrganizationName
); }
if ( x500_name->idAtOrganizationalUnitName ) { free( x500_name-
>idAtOrganizationalUnitName ); }
if ( x500_name->idAtCommonName ) { free( x500_name->idAtCommonName
); }
}
void free_x509_certificate( signed_x509_certificate *certificate )
{
free_huge( &certificate->tbsCertificate.serialNumber );
free_x500_name( &certificate->tbsCertificate.issuer );
free_x500_name( &certificate->tbsCertificate.subject ); free_huge( certificate->tbsCertificate.subjectPublicKeyInfo.rsa_public_key.modulus ); free_huge( certificate->tbsCertificate.subjectPublicKeyInfo.rsa_public_key.exponent ); free( certificate->tbsCertificate.subjectPublicKeyInfo.rsa_public_key.modulus ); free( certificate->tbsCertificate.subjectPublicKeyInfo.rsa_public_key.exponent ); free_huge( &certificate->signature_value ); }
After the signed_x509_certificate structure has been properly initialized, parsing it involves invoking the parse_asn1_certificate function shown previously and then selectively copying data values from the asn1struct nodes into the appropriate locations in the signed_x509_certificate target. The top-level function that controls this whole process is in Listing 5-13.
Listing 5-13: "x509.c" parse_x509_certificate
int parse_x509_certificate( const unsigned char *buffer,
const unsigned int certificate_length,
signed_x509_certificate *parsed_certificate )
{
struct asn1struct certificate;
struct asn1struct *tbsCertificate;
struct asn1struct *algorithmIdentifier;
struct asn1struct *signatureValue;
// First, read the whole thing into a traversable ASN.1 structure
asn1parse( buffer, certificate_length, &certificate );
tbsCertificate = ( struct asn1struct * ) certificate.children;
algorithmIdentifier = ( struct asn1struct * ) tbsCertificate->next;
signatureValue = ( struct asn1struct * ) algorithmIdentifier->next;
if ( parse_tbs_certificate( &parsed_certificate->tbsCertificate,
tbsCertificate ) )
{
fprintf( stderr, "Error trying to parse TBS certificate\n" );
return 42;
}
if ( parse_algorithm_identifier( &parsed_certificate->algorithm,
algorithmIdentifier ) )
{
return 42;
}
if ( parse_signature_value( parsed_certificate, signatureValue ) )
{
return 42;
Joining the X.509 Components into a Completed X.509 Certificate Structure
According to the ITU specification, the top level node should be a structure containing three child nodes—the TBS certificate, the signature algorithm identifier, and the signature value itself. First, parse the tbsCertificate in Listing 5-14, which is where the most interesting information is anyway. Afterward, the algorithm identifier and signature values are parsed, as was shown in Listing 5-13.
Listing 5-14: "x509.c" parse_tbs_certificate
static int parse_tbs_certificate( x509_certificate *target,
struct asn1struct *source )
{
struct asn1struct *version;
struct asn1struct *serialNumber;
struct asn1struct *signatureAlgorithmIdentifier;
struct asn1struct *issuer;
struct asn1struct *validity;
struct asn1struct *subject;
struct asn1struct *publicKeyInfo;
struct asn1struct *extensions;
// Figure out if there's an explicit version or not; if there is, then
// everything else "shifts down" one spot.
version = ( struct asn1struct * ) source->children;
if ( version->tag == 0 && version->tag_class == ASN1_CONTEXT_SPECIFIC )
{
struct asn1struct *versionNumber =
( struct asn1struct * ) version->children;
// This will only ever be one byte; safe
target->version = ( *versionNumber->data ) + 1;
serialNumber = ( struct asn1struct * ) version->next;
}
else
{
target->version = 1; // default if not provided
serialNumber = ( struct asn1struct * ) version;
}
signatureAlgorithmIdentifier = ( struct asn1struct * ) serialNumber->next;
issuer = ( struct asn1struct * ) signatureAlgorithmIdentifier->next; validity = ( struct asn1struct * ) issuer->next; subject = ( struct asn1struct * ) validity->next; publicKeyInfo = ( struct asn1struct * ) subject->next; extensions = ( struct asn1struct * ) publicKeyInfo->next; if ( parse_huge( &target->serialNumber, serialNumber ) ) { return 2; } if ( parse_algorithm_identifier( &target->signature, signatureAlgorithmIdentifier ) ) { return 3; } if ( parse_name( &target->issuer, issuer ) ) { return 4; } if ( parse_validity( &target->validity, validity ) ) { return 5; } if ( parse_name( &target->subject, subject ) ) { return 6; } if ( parse_public_key_info( &target->subjectPublicKeyInfo, publicKeyInfo ) ) { return 7; } if ( extensions ) { if ( parse_extensions( target, extensions ) ) { return 8; } } return 0; }
The only thing that makes the tbsCertificate structure tricky to parse is the version number. The original designers of the X.509 structure didn't see fit to include a version number in it, so the version was added later on, necessitating an explicit tag as discussed previously. So, if the tag class of the first node is context-specific and the tag is explicit tag 0, it must be the version number and the serial number follows as the next element. Otherwise, the version of the certificate is 1 and the serial number is the first element. To mix things up just a bit more, the version number, if present, is contained within the explicit tag, so you need to look for the first child of the explicit tag. Almost all certificates you find on the public Internet these days include a version tag, but you must be prepared to deal with a very, very old one.
Also, version 1 is identified by the number 0, version 2 by the number 1, and version 3 by the number 2. I think they're just messing with your head.
Whether a version number was supplied or not, the next element is the serial number. Go ahead and parse this into a huge structure as shown in Listing 5-15, although it is just treated as a byte array; you won't be performing any huge math on it.
Listing 5-15: "x509.c" parse_huge
static int parse_huge( huge *target, struct asn1struct *source )
{
target->sign = 0;
target->size = source->length;
target->rep = ( char * ) malloc( target->size );
Parsing Object Identifiers (OIDs)
Following the serial number is the algorithm identifier of the signature. This is an OID and can take on several possible values; each value is unique and identifies a digest algorithm/digital signature algorithm pair. For now, only support two: MD5 with RSA and SHA-1 with RSA, as shown in Listing 5-16.
Listing 5-16: "x509.c" parse_algorithm_identifier
static const unsigned char OID_md5WithRSA[] =
{ 0x2A, 0x86, 0x48, 0x86, 0xF7, 0x0D, 0x01, 0x01, 0x04 };
static const unsigned char OID_sha1WithRSA[] =
{ 0x2A, 0x86, 0x48, 0x86, 0xF7, 0x0D, 0x01, 0x01, 0x05 };
static int parse_algorithm_identifier( signatureAlgorithmIdentifier *target,
struct asn1struct *source )
{
struct asn1struct *oid = ( struct asn1struct * ) source->children;
if ( !memcmp( oid->data, OID_md5WithRSA, oid->length ) )
{
*target = md5WithRSAEncryption;
}
else if ( !memcmp( oid->data, OID_sha1WithRSA, oid->length ) )
{
*target = shaWithRSAEncryption;
}
else
{
int i;
fprintf( stderr, "Unsupported or unrecognized algorithm identifier OID " );
for ( i = 0; i < oid->length; i++ )
{
fprintf( stderr, "%.02x ", oid->data[ i ] );
}
fprintf( stderr, "\n" );
return 2;
}
return 0;
}
Remember that OIDs are being hardcoded in expanded form so that you can just do a memcmp to identify them.
Parsing Distinguished Names
Following the signature algorithm identifier is the issuer name. Name parsing is by far the most involved part of X.509 certificate management. Recall that an X.509 distinguished name is a list of components such as CN, O, OU, each of which is identified by its own OID and may or may not be present. None of them is required, and any of them can appear more than once. However, for all practical purposes, the names you'll be looking at have exactly one each of a country name, a state/province name, a city/locality name, an organization name, an organizational unit name and, most importantly, a common name. As such the structure for the name only contains pointers for this data and throws away any additional information; a more robust implementation than the one shown in Listing 5-17 would be much more complex.
Listing 5-17: "x509.c" parse_name
static unsigned char OID_idAtCommonName[] = { 0x55, 0x04, 0x03 };
static unsigned char OID_idAtCountryName[] = { 0x55, 0x04, 0x06 };
static unsigned char OID_idAtLocalityName[] = { 0x55, 0x04, 0x07 };
static unsigned char OID_idAtStateOrProvinceName[] = { 0x55, 0x04, 0x08 };
static unsigned char OID_idAtOrganizationName[] = { 0x55, 0x04, 0x0A };
static unsigned char OID_idAtOrganizationalUnitName[] = { 0x55, 0x04, 0x0B };
/**
* Name parsing is a bit different. Loop through all of the
* children of the source, each of which is going to be a struct containing
* an OID and a value. If the OID is recognized, copy its contents
* to the correct spot in "target". Otherwise, ignore it.
*/
static int parse_name( name *target, struct asn1struct *source )
{
struct asn1struct *typeValuePair;
struct asn1struct *typeValuePairSequence;
struct asn1struct *type;
struct asn1struct *value;
target->idAtCountryName = NULL;
target->idAtStateOrProvinceName = NULL;
target->idAtLocalityName = NULL;
target->idAtOrganizationName = NULL;
target->idAtOrganizationalUnitName = NULL;
target->idAtCommonName = NULL;
typeValuePair = source->children;
while ( typeValuePair )
{
typeValuePairSequence = ( struct asn1struct * ) typeValuePair->children;
type = ( struct asn1struct * ) typeValuePairSequence->children;
value = ( struct asn1struct * ) type->next; if ( !memcmp( type->data, OID_idAtCountryName, type->length ) ) { target->idAtCountryName = ( char * ) malloc( value->length + 1 ); memcpy( target->idAtCountryName, value->data, value->length ); target->idAtCountryName[ value->length ] = 0; } else if ( !memcmp( type->data, OID_idAtStateOrProvinceName, type->length ) ) { target->idAtStateOrProvinceName = ( char * ) malloc( value->length + 1 ); memcpy( target->idAtStateOrProvinceName, value->data, value->length ); target->idAtStateOrProvinceName[ value->length ] = 0; } else if ( !memcmp( type->data, OID_idAtLocalityName, type->length ) ) { target->idAtLocalityName = ( char * ) malloc( value->length + 1 ); memcpy( target->idAtLocalityName, value->data, value->length ); target->idAtLocalityName[ value->length ] = 0; } else if ( !memcmp( type->data, OID_idAtOrganizationName, type->length ) ) { target->idAtOrganizationName = ( char * ) malloc( value->length + 1 ); memcpy( target->idAtOrganizationName, value->data, value->length ); target->idAtOrganizationName[ value->length ] = 0; } else if ( !memcmp( type->data, OID_idAtOrganizationalUnitName, type->length ) ) { target->idAtOrganizationalUnitName = ( char * ) malloc( value->length + 1 ); memcpy( target->idAtOrganizationalUnitName, value->data, value->length ); target->idAtOrganizationalUnitName[ value->length ] = 0; } else if ( !memcmp( type->data, OID_idAtCommonName, type->length ) ) { target->idAtCommonName = ( char * ) malloc( value->length + 1 ); memcpy( target->idAtCommonName, value->data, value->length ); target->idAtCommonName[ value->length ] = 0; } else { int i; // This is just advisory - NOT a problem printf( "Skipping unrecognized or unsupported name token OID of " ); for ( i = 0; i < type->length; i++ ) { printf( "%.02x ", type->data[ i ] ); } printf( "\n" ); }
As you can see, after you've decided how to represent a distinguished name, parsing it isn't complex, although it is a bit tedious.
Following the issuer name is the validity structure that tells the user between which dates the certificate is valid. It is parsed in Listing 5-18.
Listing 5-18: "parse_validity"
static int parse_validity( validity_period *target, struct asn1struct *source )
{
struct asn1struct *not_before;
struct asn1struct *not_after;
struct tm not_before_tm;
struct tm not_after_tm;
not_before = source->children;
not_after = not_before->next;
// Convert time instances into time_t
if ( sscanf( ( char * ) not_before->data, "%2d%2d%2d%2d%2d%2d",
¬_before_tm.tm_year, ¬_before_tm.tm_mon, ¬_before_tm.tm_mday,
¬_before_tm.tm_hour, ¬_before_tm.tm_min, ¬_before_tm.tm_sec ) < 6 )
{
fprintf( stderr, "Error parsing not before; malformed date." );
return 6;
}
if ( sscanf( ( char * ) not_after->data, "%2d%2d%2d%2d%2d%2d",
¬_after_tm.tm_year, ¬_after_tm.tm_mon, ¬_after_tm.tm_mday,
¬_after_tm.tm_hour, ¬_after_tm.tm_min, ¬_after_tm.tm_sec ) < 6 )
{
fprintf( stderr, "Error parsing not after; malformed date." );
return 7;
}
not_before_tm.tm_year += 100;
not_after_tm.tm_year += 100;
not_before_tm.tm_mon -= 1;
not_after_tm.tm_mon -= 1;
// TODO account for TZ information on end
target->notBefore = mktime( ¬_before_tm );
target->notAfter = mktime( ¬_after_tm );
return 0;
}
Following the validity period is the subject name; this is parsed using the same routine as the issuer name.
Finally, it's time to parse the element you've been waiting this whole time to see—the public key itself, which is the one piece of information that you can't complete a secure key exchange without. Because the designers of the X.509 structure wanted to leave room for arbitrary public encryption algorithms, the structure is a bit more complex than you might expect; the public key node starts with an OID that indicates what to do with the rest. For now, to keep things relatively simple, just look at the RSA specification.
The element following the algorithm identifier OID is a bit string. This bit string is itself an ASN.1 DER-encoded value and must be parsed. Its contents vary depending on the algorithm. For RSA, the contents are a single sequence containing two integers—the first is the public exponent and the second is the modulus (of course, the private exponent is not included).
RSA public key info parsing is shown in Listing 5-19.
Listing 5-19: "x509.c" parse_public_key_info
static const unsigned char OID_RSA[] =
{ 0x2A, 0x86, 0x48, 0x86, 0xF7, 0x0D, 0x01, 0x01, 0x01 };
static int parse_public_key_info( public_key_info *target,
struct asn1struct *source )
{
struct asn1struct *oid;
struct asn1struct *public_key;
struct asn1struct public_key_value;
oid = source->children->children;
public_key = source->children->next;
// The public key is a bit string encoding yet another ASN.1 DER-encoded
// value - need to parse *that* here
// Skip over the "0" byte in the public key.
if ( asn1parse( public_key->data + 1,
public_key->length - 1,
&public_key_value ) )
{
fprintf( stderr,
"Error; public key node is malformed (not ASN.1 DER-encoded)\n" );
return 5;
}
if ( !memcmp( oid->data, &OID_RSA, sizeof( OID_RSA ) ) )
{
target->algorithm = rsa;
parse_huge( target->rsa_public_key.modulus, public_key_value.children );
parse_huge( target->rsa_public_key.exponent, public_key_value.children->next ); // This is important. Most times, the response includes a trailing 0 byte // to stop implementations from interpreting it as a twos-complement // negative number. However, in this implementation, this causes the // results to be the wrong size, so they need to be contracted. contract( target->rsa_public_key.modulus ); contract( target->rsa_public_key.exponent ); } else { fprintf( stderr, "Error; unsupported OID in public key info.\n" ); return 7; } asn1free( &public_key_value ); return 0; }
The only potential surprise in this routine is the "skip over the 0 byte" part. What's the 0 byte? Well, the subject public key is declared as an ASN.1 bit string. The DER encoding of a bit string starts with a length—just like any other ASN.1 value—but a bit string can be any length; it doesn't necessarily need to be a multiple of eight bits. Because DER encoding requires that the result be normalized to eight-bit octets, the first byte of any bit string following the length is the amount of padding bits that were added to the bit string to pad it up to a multiple of eight. In the case of an RSA public key, the result is always a multiple of eight, so this byte is always 0.
NOTE Technically, you really ought to verify that this is the case, but, practically speaking, you never see a public key value that's not a multiple of eight bits. If you actually find an example "in the wild" that contradicts this code, I'd like to know about it.
Parsing Certificate Extensions
Optionally, and only if the version of the certificate is greater than or equal to three, the public key information can be followed by a sequence of extensions. Practically speaking, all certificates that you come across on today's Internet include extensions; RFC 2459 dedicates 19 pages to describing a subset of the available X.509 certificate extensions. Although many of them are important, I'm just showing you how to deal with extensions in general and focus on one—perhaps the most important one: the key usage extension that enables the receiver to determine if the certificate is allowed to sign other certificates or not.
First, if extensions are present, loop through them as in Listing 5-20.
Listing 5-20: "x509.c" parse_extensions
static int parse_extensions( x509_certificate *certificate, struct asn1struct *source ) { // Parse each extension; if one is recognized, update the certificate // in some way source = source->children->children; while ( source ) { if ( parse_extension( certificate, source ) ) { return 1; } source = source->next; } return 0; }
An extension consists of an OID, an optional critical marker, and another optional data section whose interpretation varies depending on the OID. Parsing of the actual extension is shown in Listing 5-21.
Listing 5-21: "x509.c" parse_extension
static int parse_extension( x509_certificate *certificate,
struct asn1struct *source )
{
struct asn1struct *oid;
struct asn1struct *critical;
struct asn1struct *data;
oid = ( struct asn1struct * ) source->children;
critical = ( struct asn1struct * ) oid->next;
if ( critical->tag == ASN1_BOOLEAN )
{
data = ( struct asn1struct * ) critical->next;
}
else
{
// critical defaults to false
data = critical;
critical = NULL;
}
// TODO recognize and parse extensions – there are several
return 0;
}
The first tag is always an OID; the second can be a boolean value, in which case it indicates whether the extension should be considered critical or not. Because the default of this optional value is false, for all intents and purposes if it's present then the extension is critical.
What differentiates a critical from a non-critical extension? According to the specification, if an implementation does not recognize an extension that is marked critical, it should reject the whole certificate. Otherwise, the extension can be safely ignored. Note that the implementation presented here is not compliant, for this reason.
How the data field is interpreted depends on the OID. It's always declared as an OCTET STRING; for all defined extensions, this is an string of bytes whose contents must in turn be parsed as an ASN.1 DER-encoded structure (the X.509 people clearly weren't really aiming for optimal efficiency).
This book doesn't have enough space to cover all, or even most, X.509 extensions. One worth examining is the key usage extension, though. If the OID is 2.5.29.15 then the extension describes key usage, and the final field is a bit field. The bits are interpreted in big-endian order, and the most important is bit 5. If bit 5 is set then the certificate is a CA and can legitimately sign other certificates. Presumably, the signing CA checked that this was truly the case before signing the certificate. Processing the key usage bit is shown in Listing 5-22.
Listing 5-22: "x509.c" parse_extension with key usage recognition
static const unsigned char OID_keyUsage[] = { 0x55, 0x1D, 0x0F };
#define BIT_CERT_SIGNER 5
...
}
if ( !memcmp( oid->data, OID_keyUsage, oid->length ) )
{
struct asn1struct key_usage_bit_string;
asn1parse( data->data, data->length, &key_usage_bit_string );
if ( asn1_get_bit( key_usage_bit_string.length,
key_usage_bit_string.data,
BIT_CERT_SIGNER ) )
{
certificate->certificate_authority = 1;
}
asn1free( &key_usage_bit_string );
}
// TODO recognize and parse other extensions – there are several
As you can see, the data node is itself another ASN.1-encoded structure, which must be parsed when the key usage OID is encountered. In the case of key usage, the contents of this ASN.1 structure are a single-bit string. Bit strings can be a tad complex because they're permitted by ASN.1 to be of arbitrary length. The first byte of the data field is the number of padding bits that were added to pad up to an eight-bit boundary. Implement a handling function as shown in Listing 5-23 to retrieve the value of a single bit from an ASN.1 bit string.
Listing 5-23: "asn1.c" asn1_get_bit
int asn1_get_bit( const int length, const unsigned char *bit_string, const int bit ) { if ( bit > ( ( length - 1 ) * 8 ) ) { return 0; } else { return bit_string[ 1 + ( bit / 8 ) ] & ( 0x80 >> ( bit % 8 ) ); } }
Another potentially useful extension is the subjectAltName extension 2.5.29.17. Look over the definition of the subjectName. It specifies a country, a state, a city, an organizational unit. This is a pretty good qualifier for a person, but fairly irrelevant for a web site. Or an e-mail address. Or an IP address. Or any of a dozen other entities that you might want to identify with a certificate. Therefore, the subjectAltName extension allows the certificate to simply identify, for instance, a domain name. If the subjectAltName extension is present, the subjectName can actually be empty. However, the subjectAltName extension is pretty rare, so in general the subjectName's CN field identifies the domain name of the bearer site. Of course, there's also an IssuerAltName (OID 2.5.29.18), which serves the same purpose and is equally rare.
The last extension examined here has to do with certificate validation. The entire trust model outlined in this chapter hinges on how accurately CAs vet certificate requests. The CertificatePolicies extension 2.5.29.32 provides a way for the CA to indicate how it goes about verifying that the requester of a certificate is, in fact, the entity it purports to be. Recently, the CA/Browser forum began compiling a list of CAs that perform what is called extended validation. Extended validation just indicates that a CA has made extraordinary efforts to ensure that it is signing a certificate on behalf of the true owner of the identity in question. Recent browsers have begun displaying a green bar in addition to the traditional padlock icon to tell the user that the certificate is not only valid, but that it has been signed by an extended validation CA.
A complete X.509 implementation should recognize all of the extensions listed in RFC 5280.
The extensions mark the end of the TBSCertificate. There are two fields left in the signed certificate structure: the signature algorithm and the signature itself. The signature algorithm is an OID, and must match the signature algorithm listed in the tbsCertificate. The signature, of course, is a bit string whose interpretation varies depending on the signature algorithm. For RSA, it's simply a large integer, parsed in Listing 5-24.
Listing 5-24: "x509.c" parse_signature_value
static int parse_signature_value( signed_x509_certificate *target, struct asn1struct *source ) { parse_huge( &target->signature_value, source ); contract( &target->signature_value ); return 0; }
Signature Verification
You're not quite done yet. Remember that you also have to be able to verify this signature; just ensuring that it's there isn't enough. You must also check that it is a proper digital signature of the hash of the tbsCertificate bytes. So, after parsing the entire certificate, you must hash it and store the hash for later inspection. Extend parse_x509_certificate to do so as shown in Listing 5-25.
Listing 5-25: "x509.c" parse_x509_certificate with stored hash
typedef struct
{
x509_certificate tbsCertificate;
unsigned int *hash; // hash code of tbsCertificate
int hash_len;
signatureAlgorithmIdentifier algorithm;
huge signature_value;
}
signed_x509_certificate;
int parse_x509_certificate( const unsigned char *buffer,
const unsigned int certificate_length,
signed_x509_certificate *parsed_certificate )
{
struct asn1struct certificate;
struct asn1struct *tbsCertificate;
struct asn1struct *algorithmIdentifier;
struct asn1struct *signatureValue;
digest_ctx digest;
...
switch ( parsed_certificate->algorithm )
{
case md5WithRSAEncryption:
new_md5_digest( &digest );
break;
case shaWithRSAEncryption:
new_sha1_digest( &digest );
break;
default:
break; } update_digest( &digest, tbsCertificate->data, tbsCertificate->length ); finalize_digest( &digest ); parsed_certificate->hash = digest.hash; parsed_certificate->hash_len = digest.hash_len; asn1free( &certificate ); ...
Notice that, although tbsCertificate is a structure type, the data itself is still made available by the ASN.1 parsing routine (Listing 5-5), which means that you can easily write code to securely hash the DER-encoded representation of the tbsCertificate.
Validating PKCS #7-Formatted RSA Signatures
Validating a certificate involves finding the public key of the issuer, using it to run the digital signature algorithm on the computed hash, and then verifying that it matches the signature included in the certificate itself. When the RSA algorithm is used for signing a certificate, the hash value itself is concatenated onto the OID representing the signing algorithm and stored in an ASN.1 sequence. This is then DER encoded, and the whole thing is encrypted with the private key. This is called PKCS #7, which is officially documented by RSA labs at http://www.rsa.com/rsalabs/node.asp?id=2129. The code to unwrap the signed hash code and compare it to the previously computed one is shown in Listing 5-26.
Listing 5-26: "x509.c" validate_certificate_rsa
/** * An RSA signature is an ASN.1 DER-encoded PKCS-7 structure including * the OID of the signature algorithm (again), and the signature value. */ static int validate_certificate_rsa( signed_x509_certificate *certificate, rsa_key *public_key ) { unsigned char *pkcs7_signature_decrypted; int pkcs7_signature_len; struct asn1struct pkcs7_signature; struct asn1struct *hash_value; int valid = 0; pkcs7_signature_len = rsa_decrypt( certificate->signature_value.rep, certificate->signature_value.size, &pkcs7_signature_decrypted, public_key ); if ( pkcs7_signature_len == −1 )
{ fprintf( stderr, "Unable to decode signature value.\n" ); return valid; } if ( asn1parse( pkcs7_signature_decrypted, pkcs7_signature_len, &pkcs7_signature ) ) { fprintf( stderr, "Unable to parse signature\n" ); return valid; } hash_value = pkcs7_signature.children->next; if ( memcmp( hash_value->data, certificate->hash, certificate->hash_len ) ) { valid = 0; } else { valid = 1; } asn1free( &pkcs7_signature ); return valid; }
Verifying a Self-Signed Certificate
How to map issuers to public keys is outside the scope of the implementation; browsers ship with a (long) list of trusted root CAs and their known public keys, which are compared to the issuer each time a certificate is received. To illustrate the concept, though, you can go ahead and write code to verify a self-signed certificate in Listing 5-27, such as those that are distributed by the CAs to the browsers to begin with. Like the ASN.1 test routine, this routine expects a DER- or PEM-encoded certificate file and outputs the contents of the file. This time, though, it does a lot more interpretation and actually produces useful, meaningful content.
Listing 5-27: "x509.c" main routine
#ifdef TEST_X509
int main( int argc, char *argv[ ] )
{
int certificate_file;
struct stat certificate_file_stat;
char *buffer, *bufptr;
int buffer_size;
int bytes_read;
int error_code; signed_x509_certificate certificate; if ( argc < 3 ) { fprintf( stderr, "Usage: x509 [-pem|-der] [certificate file]\n" ); exit( 0 ); } if ( ( certificate_file = open( argv[ 2 ], O_RDONLY ) ) == −1 ) { perror( "Unable to open certificate file" ); return 1; } // Slurp the whole thing into memory if ( fstat( certificate_file, &certificate_file_stat ) ) { perror( "Unable to stat certificate file" ); return 2; } buffer_size = certificate_file_stat.st_size; buffer = ( char * ) malloc( buffer_size ); if ( !buffer ) { perror( "Not enough memory" ); return 3; } bufptr = buffer; while ( ( bytes_read = read( certificate_file, ( void * ) buffer, buffer_size ) ) ) { bufptr += bytes_read; } if ( !strcmp( argv[ 1 ], "-pem" ) ) { // XXX this overallocates a bit, since it sets aside space for markers, etc. unsigned char *pem_buffer = buffer; buffer = (unsigned char * ) malloc( buffer_size ); buffer_size = pem_decode( pem_buffer, buffer ); free( pem_buffer ); } // now parse it init_x509_certificate( &certificate ); if ( !( error_code = parse_x509_certificate( buffer, buffer_size, &certificate ) ) )
{ printf( "X509 Certificate:\n" ); display_x509_certificate( &certificate ); // Assume it's a self-signed certificate and try to validate it that switch ( certificate.algorithm ) { case md5WithRSAEncryption: case shaWithRSAEncryption: if ( validate_certificate_rsa( &certificate, &certificate.tbsCertificate.subjectPublicKeyInfo.rsa_public_key ) ) { printf( "Certificate is a valid self-signed certificate.\n" ); } else { printf( "Certificate is corrupt or not self-signed.\n" ); } break; } } else { printf( "error parsing certificate: %d\n", error_code ); } free_x509_certificate( &certificate ); free( buffer ); return 0; } #endif
This invokes the companion display_x509_certificate function in Listing 5-28.
Listing 5-28: "x509.c" display_x509_certificate
static void output_x500_name( name *x500_name )
{
printf( "C=%s/ST=%s/L=%s/O=%s/OU=%s/CN=%s\n",
( x500_name->idAtCountryName ? x500_name->idAtCountryName : "?" ),
( x500_name->idAtStateOrProvinceName ? x500_name->idAtStateOrProvinceName :
"?" ),
( x500_name->idAtLocalityName ? x500_name->idAtLocalityName : "?" ),
( x500_name->idAtOrganizationName ? x500_name->idAtOrganizationName : "?" ),
( x500_name->idAtOrganizationalUnitName ? x500_name-
>idAtOrganizationalUnitName : "?" ),
( x500_name->idAtCommonName ? x500_name->idAtCommonName : "?" ) );
}
static void print_huge( huge *h )
{
show_hex( h->rep, h->size ); } static void display_x509_certificate( signed_x509_certificate *certificate ) { printf( "Certificate details:\n" ); printf( "Version: %d\n", certificate->tbsCertificate.version ); printf( "Serial number: " ); print_huge( &certificate->tbsCertificate.serialNumber ); printf( "issuer: " ); output_x500_name( &certificate->tbsCertificate.issuer ); printf( "subject: " ); output_x500_name( &certificate->tbsCertificate.subject ); printf( "not before: %s", asctime( gmtime( &certificate->tbsCertificate.validity.notBefore ) ) ); printf( "not after: %s", asctime( gmtime( &certificate->tbsCertificate.validity.notAfter ) ) ); printf( "Public key algorithm: " ); switch ( certificate->tbsCertificate.subjectPublicKeyInfo.algorithm ) { case rsa: printf( "RSA\n" ); printf( "modulus: " ); print_huge( certificate->tbsCertificate.subjectPublicKeyInfo.rsa_public_key.modulus ); printf( "exponent: " ); print_huge( certificate->tbsCertificate.subjectPublicKeyInfo.rsa_public_key.exponent ); break; case dh: printf( "DH\n" ); break; default: printf( "?\n" ); break; } printf( "Signature algorithm: " ); switch ( certificate->algorithm ) { case md5WithRSAEncryption: printf( "MD5 with RSA Encryption\n" ); break; case shaWithRSAEncryption: printf( "SHA-1 with RSA Encryption\n" ); break; }
printf( "Signature value: " ); switch ( certificate->algorithm ) { case md5WithRSAEncryption: case shaWithRSAEncryption: print_huge( &certificate->signature_value ); break; } printf( "\n" ); if ( certificate->tbsCertificate.certificate_authority ) { printf( "is a CA\n" ); } else { printf( "is not a CA\n" ); } }
Now, you can parse the test certificate you generated.
[jdavies@localhost ssl]$ ./x509 -der cert.der Skipping unrecognized or unsupported name token OID of 2a 86 48 86 f7 0d 01 09 01 Skipping unrecognized or unsupported name token OID of 2a 86 48 86 f7 0d 01 09 01 X509 Certificate: Certificate details: Version: 3 Serial number: 0ca30e18f778da281 issuer: C=US/ST=TX/L=Southlake/O=Travelocity/OU=Architecture/CN=Joshua Davies subject: C=US/ST=TX/L=Southlake/O=Travelocity/OU=Architecture/CN=Joshua Davies not before: Wed Mar 3 04:46:23 2010 not after: Fri Apr 2 03:46:23 2010 Public key algorithm: RSA modulus: e013380f83b6ef0670f55baa3a2bcf8e95ff91b1900352516973dea7fa97fb560db9e90f e830228c5ef01f07f0dccc61b8010eb1b058efb5b4541670eb59b4bf exponent: 10001 Signature algorithm: SHA-1 with RSA Encryption Signature value: 1b637bf513ef2e3d56223da24cd50e318d0c25bb2430fda320f5a3b57d1bcb1e a8bdb0ce788be75e7aac662c6d0606e8e30624cad5ce0d991a7c37534dd3be83 Certificate hash (fingerprint): ac7d5752 30586fb4 3c106b90 60af5eb5 939147f1 certificate is not a CA. 01 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff 00 30 21 30 09 06 05 2b 0e 03 02 1a 05 00 04 14 52 57 7d ac b4 6f 58 30 90 6b 10 3c b5 5e af 60 f1 47 91 93 00 Certificate is a valid self-signed certificate.
Adding DSA Support to the Certificate Parser
Go ahead and add support for DSA as well. This is mostly academic because DSA-signed certificates are extremely rare "in the wild," at least for SSL. Because servers present certificates primarily to prepare for key exchange, and DSA can't be used for this purpose, there's not much point in presenting a certificate with a DSA public key to an SSL client. A CA, on the other hand, could use DSA; the purpose of a root certificate is to sign other certificates, and this is the one thing DSA can do. However, at the time of this writing no CA does—at least none of those implicitly trusted by major browser vendors.
However, it's worthwhile to see how it's done so that you can see how different signature algorithms change the parsing semantics. In addition, common or not, support for DSA certificates is required by TLS. First of all, the structure definitions change slightly as shown in Listing 5-29.
Listing 5-29: "x509.h" with DSA support
typedef enum
{
rsa,
dsa,
dh
}
algorithmIdentifier;
typedef enum
{
md5WithRSAEncryption,
shaWithRSAEncryption,
shaWithDSA
}
signatureAlgorithmIdentifier;
...
typedef struct
{
algorithmIdentifier algorithm;
// RSA parameters, only if algorithm == rsa
rsa_key rsa_public_key;
// DSA or DH parameters, only if algorithm == dsa
dsa_params dsa_parameters;
// DSA parameters, only if algorithm == dsa
huge dsa_public_key;
}
public_key_info;
...
typedef struct
{
x509_certificate tbsCertificate;
unsigned int *hash; // hash code of tbsCertificate int hash_len; signatureAlgorithmIdentifier algorithm; huge rsa_signature_value; dsa_signature dsa_signature_value; } signed_x509_certificate;
Notice that no attempt was made to have the DSA and RSA public keys or signatures share the same memory space. An RSA public key is two distinct numbers e and n, whereas a DSA public key is a single number y. DSA also defines parameters whereas RSA does not. Conversely, a DSA signature is two distinct numbers r and s, whereas an RSA signature is a single number. There's just no commonality there. If you want to be a stickler for space optimization, you could force the declarations of these structures to include a single signature and public key element, but the code that interpreted them would be such a mess it would hardly be worth it. Here, one or the other is left empty, and it is up to the invoker to check the algorithm value to determine which to ignore.
Of course, you need to modify the parse_algorithm_identifier routine to recognize DSA; there's no MD5 with DSA, so there's only one new algorithm to identify in Listing 5-30.
Listing 5-30: "x509.c" parse_algorithm_identifier with DSA support
static const unsigned char OID_sha1WithRSA[] =
{ 0x2A, 0x86, 0x48, 0x86, 0xF7, 0x0D, 0x01, 0x01, 0x05 };
static const unsigned char OID_sha1WithDSA[] =
{ 0x2A, 0x86, 0x48, 0xCE, 0x38, 0x04, 0x03 };
static int parse_algorithm_identifier( signatureAlgorithmIdentifier *target,
struct asn1struct *source )
{
...
}
else if ( !memcmp( oid->data, OID_sha1WithDSA, oid->length ) )
{
*target = shaWithDSA;
}
else
{
The top-level parse_x509_certificate function must likewise invoke a different routine to parse the signature value depending on the signature algorithm as shown in Listing 5-31.
Listing 5-31: "x509.c" parse_x509_certificate with DSA support
int parse_x509_certificate( const unsigned char *buffer,
const unsigned int certificate_length,
signed_x509_certificate *parsed_certificate ) { ... switch ( parsed_certificate->algorithm ) { case md5WithRSAEncryption: case shaWithRSAEncryption: if ( parse_rsa_signature_value( parsed_certificate, signatureValue ) ) { return 42; } break; case shaWithDSA: if ( parse_dsa_signature_value( parsed_certificate, signatureValue ) ) { return 42; } ... switch ( parsed_certificate->algorithm ) { case md5WithRSAEncryption: new_md5_digest( &digest ); break; case shaWithRSAEncryption: case shaWithDSA: new_sha1_digest( &digest ); break; default: break; } ...
Note that the parse_signature_value routine is now named parse_rsa_signature_value. The new parse_dsa_signature_value shown in Listing 5-32 is pretty much like the parse_rsa_signature_value routine except that it expects two values.
Listing 5-32: "x509.c" parse_dsa_signature_value
static int parse_dsa_signature_value( signed_x509_certificate *target,
struct asn1struct *source )
{
struct asn1struct dsa_signature;
if ( asn1parse( source->data + 1, source->length - 1, &dsa_signature ) )
{
fprintf( stderr, "Unable to parse ASN.1 DER-encoded signature.\n" );
return 1;
}
parse_huge( &target->dsa_signature_value.r, dsa_signature.children );
parse_huge( &target->dsa_signature_value.s, dsa_signature.children->next ); asn1free( &dsa_signature ); return 0; }
Most of the complexity in dealing with DSA certificates is in parsing the public key information. An RSA public key is simply two numbers. A DSA public key is a single number, but the algorithm also requires parameters. For no clear reason, the X.509 designers split the parameters and the public key into two separate ASN.1 sequences, with different parent elements, so the parsing code gets a bit involved in Listing 5-33.
Listing 5-33: "x509.c" public key info parsing with DSA support
static const unsigned char OID_RSA[] =
{ 0x2A, 0x86, 0x48, 0x86, 0xF7, 0x0D, 0x01, 0x01, 0x01 };
static const unsigned char OID_DSA[] =
{ 0x2A, 0x86, 0x48, 0xCE, 0x38, 0x04, 0x01 };
...
static int parse_public_key_info( public_key_info *target,
struct asn1struct *source )
{
...
if ( !memcmp( oid->data, &OID_RSA, sizeof( OID_RSA ) ) )
{
...
}
else if ( !memcmp( oid->data, &OID_DSA, sizeof( OID_DSA ) ) )
{
struct asn1struct *params;
target->algorithm = dsa;
parse_huge( &target->dsa_public_key, &public_key_value );
params = oid->next;
parse_dsa_params( target, params );
}
Finally, parsing the DSA params themselves in Listing 5-34 is simple after you've identified the node.
Listing 5-34: "tls.c" parse_dsa_params
static int parse_dsa_params( public_key_info *target, struct asn1struct *source )
{
struct asn1struct *p;
struct asn1struct *q;
struct asn1struct *g;
p = source->children; q = p->next; g = q->next; parse_huge( &target->dsa_parameters.p, p ); parse_huge( &target->dsa_parameters.q, q ); parse_huge( &target->dsa_parameters.g, g ); return 0; }
To test this, you have to generate your own DSA certificate; this was shown in the section "Using OpenSSL to Generate a DSA KeyPair and Certificate" earlier. Extend the certificate display routine just a bit as shown in Listing 5-35, and you can output the details of this certificate:
Listing 5-35: "x509.c" display_x509_certificate
static void display_x509_certificate( signed_x509_certificate *certificate )
{
...
printf( "Public key algorithm: " );
switch ( certificate->tbsCertificate.subjectPublicKeyInfo.algorithm )
{
...
case dsa:
printf( "DSA\n" );
printf( "y: " );
print_huge(
&certificate->tbsCertificate.subjectPublicKeyInfo.dsa_public_key );
printf( "p: " );
print_huge(
&certificate->tbsCertificate.subjectPublicKeyInfo.dsa_parameters.p );
printf( "q: " );
print_huge(
&certificate->tbsCertificate.subjectPublicKeyInfo.dsa_parameters.q );
printf( "g: " );
print_huge(
&certificate->tbsCertificate.subjectPublicKeyInfo.dsa_parameters.g );
break;
...
switch ( certificate->algorithm )
{
...
case shaWithDSA:
printf( "SHA-1 with DSA\n" );
break;
}
...
printf( "Signature value: " );
switch ( certificate->algorithm ) { ... case shaWithDSA: printf( "\n\tr:" ); print_huge( &certificate->dsa_signature_value.r ); printf( "\ts:" ); print_huge( &certificate->dsa_signature_value.s ); break; }
Finally, extend the test main routine in Listing 5-36 to attempt a self-signature validation if the signature algorithm is DSA.
Listing 5-36: "x509.c" main routine
int main( int argc, char *argv[ ] )
{
...
switch ( certificate.algorithm )
{
...
case shaWithDSA:
if ( validate_certificate_dsa( &certificate ) )
{
printf( "Certificate is a valid self-signed certificate.\n" );
}
else
{
printf( "Certificate is corrupt or not self-signed.\n" );
}
DSA certificate validation is actually simpler than RSA certificate validation because the signature value is not an encrypted ASN.1 DER-encoded structure like RSA's; the DSA signature algorithm doesn't allow this. It also doesn't allow the algorithm OID to be embedded in the signature value the way RSA does, though. The validation is shown in Listing 5-37.
Listing 5-37: "x509.c" validate_certificate_dsa
static int validate_certificate_dsa( signed_x509_certificate *certificate )
{
return dsa_verify(
&certificate->tbsCertificate.subjectPublicKeyInfo.dsa_parameters,
&certificate->tbsCertificate.subjectPublicKeyInfo.dsa_public_key,
certificate->hash,
certificate->hash_len * 4,
&certificate->dsa_signature_value );
}
This covers RSA and DSA signature validation and RSA key exchange. What about Diffie-Hellman? X.509 does define a certificate structure that includes the Diffie-Hellman parameters; however, this is even rarer in practice than the nonexistent DSA certificate. You can't even use OpenSSL to generate such a certificate. I won't cover it here; if you're so inclined, though, it wouldn't be hard to add support for it.
There's one big, big problem with all of the X.509 parsing code presented in this chapter. You probably noticed it while you were reading it: There's no error checking. At each step, the code assumes that there is, for instance, a children.next.next.children.next structure as required by the X.509 definition. The code should include a lot more error checking to validate that the parsed ASN.1 structure correctly conforms to the expected X.509 structure. As is the technical book author's prerogative, though, I'll leave that as an exercise for the reader (or you could just download the code from the companion website at www.wiley.com/go/ImplementingSSL, which does include the aforementioned error checking).
Managing Certificates
The primary purpose of a certificate is to communicate a public key. The additional data—the subject name, the issuer name, the signature, the extensions, and so on—are present to allow the receiver of the certificate to verify that the bearer is legitimately in possession of the private key that corresponds with the included public key. Overall, this is referred to as a public key infrastructure (PKI). Public-key cryptography itself was originally developed to permit a secure key exchange to occur over an insecure medium with no prior off-line communication; however, PKI requires that the identities—that is, the public keys—of the trusted CAs be set up before secure communications can be established. How this is done is outside the scope of SSL/TLS. Browsers come preconfigured with a list of trusted CAs, for instance, with an option to allow the user to import new ones. It's up to the user to verify that new public keys are correct and trustworthy, and to keep track of the trustworthiness of the top-level CAs. Although this is not part of the SSL/TLS flow, there is a set of best practices that has grown around PKI and certificate management.
How Authorities Handle Certificate Signing Requests (CSRs)
The CA is vouching for the legitimacy of a certificate. In the context of the world-wide web, CAs are typically for-profit businesses; their reputation, and business viability, depends on how accurately they vet certificates prior to signing them and thus providing their seal of approval. However, it's perfectly acceptable, in a corporate intranet environment, to establish a local CA and let it sign certificates that are only trusted within the local network. An entity wishing to act as a CA must simply create a new key pair, generate a certificate that contains the public key, sign the certificate with the private key, and publish the self-signed certificate.
How the receivers decide which authorities to trust is not part of the PKI specification, but how a would-be certificate holder gets a signature is. First, of course, the hopeful certificate holder must generate his own keypair. The public key and the subject's name are wrapped up into a PKCS #10 certificate signing request (CSR). The whole certificate signing request itself is signed with the private key, but the private key isn't shared with the CA. Signing the request with the private key prevents a malicious man in the middle from intercepting the CSR, substituting his own public key in the request itself, and obtaining a signed certificate in somebody else's name. In essence, the signature proves that whoever generated the request has access to the private key that corresponds with the public key, without ever revealing the actual private key.
The CA should, of course, verify the signature with the public key, but should also verify, in some unspecified offline manner, that the requester is actually the correct holder of the name in the CN field of the subject name. If the certificate identifies an individual, perhaps the CA would request that the individual appear in person and present a driver's license with a name that matches the CN field and a state that matches the ST field. If the certificate identifies a web site, the CA might perform a WHOIS query against the ARIN database for the domain in question to determine who the registered owner is and demand a driver's license in that name.
After the identity of the requester has been verified, the CA creates an X.509 certificate that includes the public key and subject name, as well as the serial number, validity period, issuer's name as well as any extra attributes that may be appropriate, such as key usage, and, of course, the signature using the CA's private key. The final certificate can safely be returned over a cleartext channel with no further authentication. This certificate is now public data and by design contains no sensitive information.
The PKCS #10 format won't be examined in detail here. The official specification can be downloaded from http://www.rsa.com/rsalabs/node.asp?id=2132, and the OpenSSL req command can be used to generate a new CSR.
Correlating Public and Private Keys Using PKCS #12 Formatting
Notice that the private key itself doesn't appear anywhere in the certificate format, nor the CSR format. (This a good thing!) As you can imagine, when dealing with several certificates, it can become difficult to keep track of which private keys correspond to which public keys; some certificates expire, some need to be revoked due to a key compromise, some domains have their own certificates for security purposes, and so on. If you lose track of which private key goes with which certificate, you're pretty much out of luck; it would be nice to store them together so you can always go back to the source.
Storing the keys, of course, must be done in a secure way. The private key may be the most sensitive bit of information in the entire system. The PKCS #12 format was designed as a standardized way to transmit any arbitrary bit of data securely—by encrypting it in a standardized way—but in practice it is generally used to store certificates and their corresponding private keys. The PKCS #12 format was standardized from an older, de facto standard named PFX. As such, many applications that generate PKCS #12 files give them the extension .pfx. If you export a certificate and private key from Internet Explorer, for instance, you get a .pfx file.
The PKCS #12 format is actually extremely general—a bit too general, in fact. The top-level structure consists of a version number, a sequence of bit strings, and a MAC over the whole thing. It's up to the reader of the file to interpret the bit strings to figure out if they're encrypted and what they contain.
Blacklisting Compromised Certificates Using Certificate Revocation Lists (CRLs)
After a CA has applied its signature to a certificate, that signature can never be revoked, ever. The signature is a mathematical operation performed over the certificate data; if it's valid today, it will be valid a million years from now. So what can the holder of a certificate do if, for whatever reason, its private key is compromised?
Depending on the usage pattern of the certificate, this could be very bad news for the rightful owner of the certificate. Of course, if the certificate holder knows about the compromise, the certificate can be taken out of use and a new one generated. However, the key thief can use the old certificate and private key to sign any document he likes, masquerading as the rightful certificate holder.
Every certificate has an expiration date to guard against this. Even if the rightful holder is unaware of the breach, the certificate eventually expires and a new certificate, with a new public key (one would hope) is generated. However, if the certificate holder is aware of a breach, it is irresponsible not to notify the users of the certificate that it should be revoked prior to its expiration date.
CAs came up with half a solution with certificate revocation lists (CRLs). The CA maintains a list of the serial numbers of certificates that have been identified by their owners as no longer applicable. The users of the certificates are responsible for checking this list on a periodic basis and comparing the serial number of each received certificate against the list of revoked serial numbers. The format for a CRL is, of course, an ASN.1 syntax; it starts with a header identifying the CA, the date it was published, and a list of serial numbers and revocation dates.
VeriSign's current CRL, as an example, is 125K and includes more than 3600 certificates, some of which were revoked more than two years ago. The idea behind CRLs is that a user downloads each trusted CA's CRL on a periodic basis. However, there's no real upper bound on how large a CRL may grow. It might be reasonable to try to keep a handle on the size of the file by removing a certificate from the CRL after its validity period had passed, but an actual compromised certificate is a far greater security risk than one that is simply expired. A compromised certificate should never be used, under any circumstances; an expired certificate may be used, if the receiver trusts the certificate holder. As a result, it's necessary for the CA to keep a certificate on its CRL list for a fairly long period of time. To keep the size of the download somewhat manageable, the specification allows the CA to distribute "delta" CRL's that only include newly revoked certificates. This is still problematic, as the user of the CRL has no way of knowing when it's safe to stop keeping track of an expired certificate, whereas the CA knows, for instance, that a certificate expired six years ago and can probably be safely removed from the list. The downloader only knows the serial number of the certificate; he has no way of knowing whether it was revoked 10 years ago or last Tuesday.
You may be wondering where to go to find the CRL associated with a CA. It would seem reasonable that the location of the CRL would be set up when the CA itself was listed as trusted, but this doesn't allow a CA to move its CRL location, ever. The X.509 certificate form has an extension that allows the CA to indicate where the CRL ought to be downloaded from. This does introduce one potential confusion, though: The extension doesn't permit the CA to indicate the date that the CRL distribution point changed. Remember that the CRL is associated with the CA that signed the certificate. If the client downloads two certificates signed by the same CA, but with two different CRL URLs, which one should be used? There are no clear guidelines in the specifications. This isn't a problem if you don't mind downloading the entire CRL each time you want to validate a certificate, but it can be a problem if you're trying to use deltas or if the CRL distribution point is temporarily unreachable.
How does the legitimate holder of a certificate inform a CA that a certificate is compromised and should be revoked? The CSR format described earlier includes an optional attributes section in which the requester can provide a challenge password that must be supplied at any later time in order to perform subsequent certificate management, including revocation.
Keeping Certificate Blacklists Up-to-Date with the Online Certificate Status Protocol (OCSP)
As detailed in the previous section, there are quite a few problems with using CRLs as a means of notifying consumers of the revocation of certificates. In addition to some of the management/ambiguity problems, there's also the problem of freshness. If a private key has been compromised, the potential users of that certificate probably want to know about it right away. To accomplish this, the client has to download the entire CRL, or at least a delta (if the CA supports them) every time a new certificate is encountered. The Online Certificate Status Protocol (OCSP) was developed to enable the client to look up the status of a certificate by serial ID.
The details can be found in RFC 2560 and aren't covered in depth here. The user supplies the serial number of the certificate along with a hash of the issuer's distinguished name as well as its public key. The issuer name and public key are included so that a single OCSP can report on multiple CAs. The OCSP server returns, at a minimum, a status of "good" or "revoked."
Of course, this all works only if the OCSP server itself is online. If the server is not available, the user has a decision to make: abandon the connection attempt, or go ahead with a potentially revoked certificate? Ideally, the client should have a CRL handy to verify in case the OCSP server is unavailable.
Other Problems with Certificates
Whenever a flaw is found in SSL, it's almost always related to certificates.
Even when certificates are implemented "perfectly" human behavior often renders them moot. All browsers, at the time of this writing, allow a user to ignore a mismatched domain name or a certificate past its validity period. Users are presented with cryptic warning messages and allowed to continue, which most of them do—even the ones who ought to know better. Still, PKI is what we have to guard against man-in-the-middle attacks. At a bare minimum, an implementation of TLS must be prepared to parse certificates to extract the server's public key.