
Before we jump into creating bots and fancy natural language models, we will take a quick detour into natural language understanding (NLU) and some of its machine learning (ML) underpinnings. We will be implementing some of these NLU concepts using Microsoft’s Language Understanding Intelligence Service (LUIS) in the following chapter. Some other concepts are available for you to explore using other services (for instance, Microsoft’s Cognitive Services) or Python/R ML tools. This chapter is meant to equip you with a quick-and-dirty introduction into the ML space as it pertains to natural language tasks. If you are familiar with these concepts, by all means, skip ahead to Chapter 3. Otherwise, we hope to impart a base-level understanding of the roots of NLU and how it can be applied to the field of bots. There is a great plethora of content on the Internet that goes into depth about all of these topics; we provide the appropriate references if you feel adventurous!
If we choose to develop an NLU-integrated chat bot, our day-to-day engineering will involve continuous interactions with systems that can make sense of what the user is saying. This is a nontrivial task. Consider using brute-force coding to understand free-text user input as related to our natural language controller thermostat. We introduced this use case in Chapter 1. We had four intents: PowerOn, PowerOff, SetMode, and SetTemperature. Let’s consider the SetTemperature intent. How would you encode a system that understands that the user intends to set a temperature and which part of the user input represents the temperature?
We could use a regular expression that tries to match sentences like “set temperature to {temperature},” “set to {temperature},” and “set {temperature}.” You test it out. You feel pretty good, and a tester comes along and says, “I want it to be 80 degrees.” OK, no biggie. We add “I want it to be {temperature}.” The next day someone comes along and says, “lower temperature by 2 degrees.” We could add “lower temperature by {diff}” and “increase temperature by {diff}.” But now we need to detect the word lower and increase. And how do we even account for variations of those words? And don’t get us started on multiple commands such as “set to 68 during the day and 64 at night.” Come to think of it, what temperature units are we talking about?
As we think through the interactions we want to support on the chat bot, we quickly notice that using the brute-force approach would result in quite a tedious system that, in the end, would not perform well given the fascinating and annoying inconsistencies of natural language communication. If we wanted to utilize a brute-force approach, the closest we can get, and still get some pretty good performance, is to use regular expressions. The Bot Framework supports this, as we will see in Chapter 5. If we use such an approach, assuming you are not a regular expression junkie, our interaction model would need to stay simple for maintenance reasons.
Natural language understanding (NLU) is a subset of the complex field of natural language processing (NLP) concerned with the machine comprehension of human language. NLU and NLP are inextricably tied to our understanding of AI, likely because we often correlate intelligence to communication skills. There is probably an underlying psychological nature to it as well; we think the bot is smarter if it understands what we are saying, regardless of our intelligence level and the complexity of our speech. In fact, we would probably be happiest with the kind of AI that could just understand what we are thinking, not what we say. But I digress.
Under that assumption, a command line is not intelligent because it requires commands to be in a specific format. Would we consider it intelligent if we could launch a Node.js script by asking the command line to “launch node…I’m not sure which file, though; can you help me out?.” Using modern NLU techniques, we can build models that seem knowledgeable about certain specializations or tasks. Subsequently, on the face of it, a bot may seem somewhat intelligent. Is it?
The truth is that we have not yet developed the computational power and techniques to create an NLU system that matches human intelligence. A problem is said to be “AI hard” if it could be solved only if we could make computers as smart as humans. A proper NLU system that behaves and understands natural language input like a human is not yet within our grasp; but we can create narrow and clever systems that can understand a few things well enough to create a reasonable conversational experience.
Considering the hype surrounding ML and AI these days, it is important for us to set those expectations right from the beginning. One of the first things I always address with clients in our initial conversations about conversational intelligence is that there is a gap between expectations and reality. I like to say that anyone in the room will easily be able to defeat the bot by phrasing things in a way that a human may understand but the bot won’t. There are limits to this technology, and there are limits in what it can do within the available budgets and timelines. That’s OK. As long as we create a chat bot focused on certain tasks that make the lives on our users better, we’re on the right path. And if we can delight our users by building some NLU into the chat bot, great!
Natural Language Machine Learning Background
The beginnings of the NLP field can be traced back to Alan Turing and, specifically, the Turing test,1 a test to determine whether a machine can behave intelligently. In the test, an evaluator can ask questions of two participants. Responding as one of the participants is a human; a computer is the second participant. Based on the answers the evaluator receives from the two participants, if the evaluator cannot determine which participant is a human and which one is a computer, then it is said that the computer has passed the Turing test. Some systems have claimed to be able to pass the Turing test, but these announcements have been judged as premature.2 There’s a criticism that scripting a bot to try to trick a human to believe that it is human and understanding human input are two very different things. We are quite a few years from getting to passing the Turing test.

Sample interaction with JavaScript version of Eliza
The NLU engines were generally rule based; they were encoded with structured representations of knowledge for the systems to use when processing user input. Around the 1980s, the field of machine learning started gaining ground. Machine learning is the process of having computers learn without being coded for the task—something seemingly closer to intelligence than the rule-based approach. For example, we briefly explored building a brute-force NLU engine and the tedious work of encoding with the various rules. Using machine learning, our system would not need to know anything about our domain and intent classifications ahead of time, though we can certainly start with a pretrained model. Instead, we would create an engine that we show sample inputs labeled with certain intent names. This is called the training data set . Based on the inputs and labeled intents, we train a model to identify the inputs as the presented labels. Once trained, a model is able to receive inputs it has not yet seen and assign scores to each intent. The more examples we train our model with, the better its performance. This is where the AI comes in: the net effect of training the model with high-quality data is that by using statistical models, the system can start making label predictions of inputs it has not yet encountered.
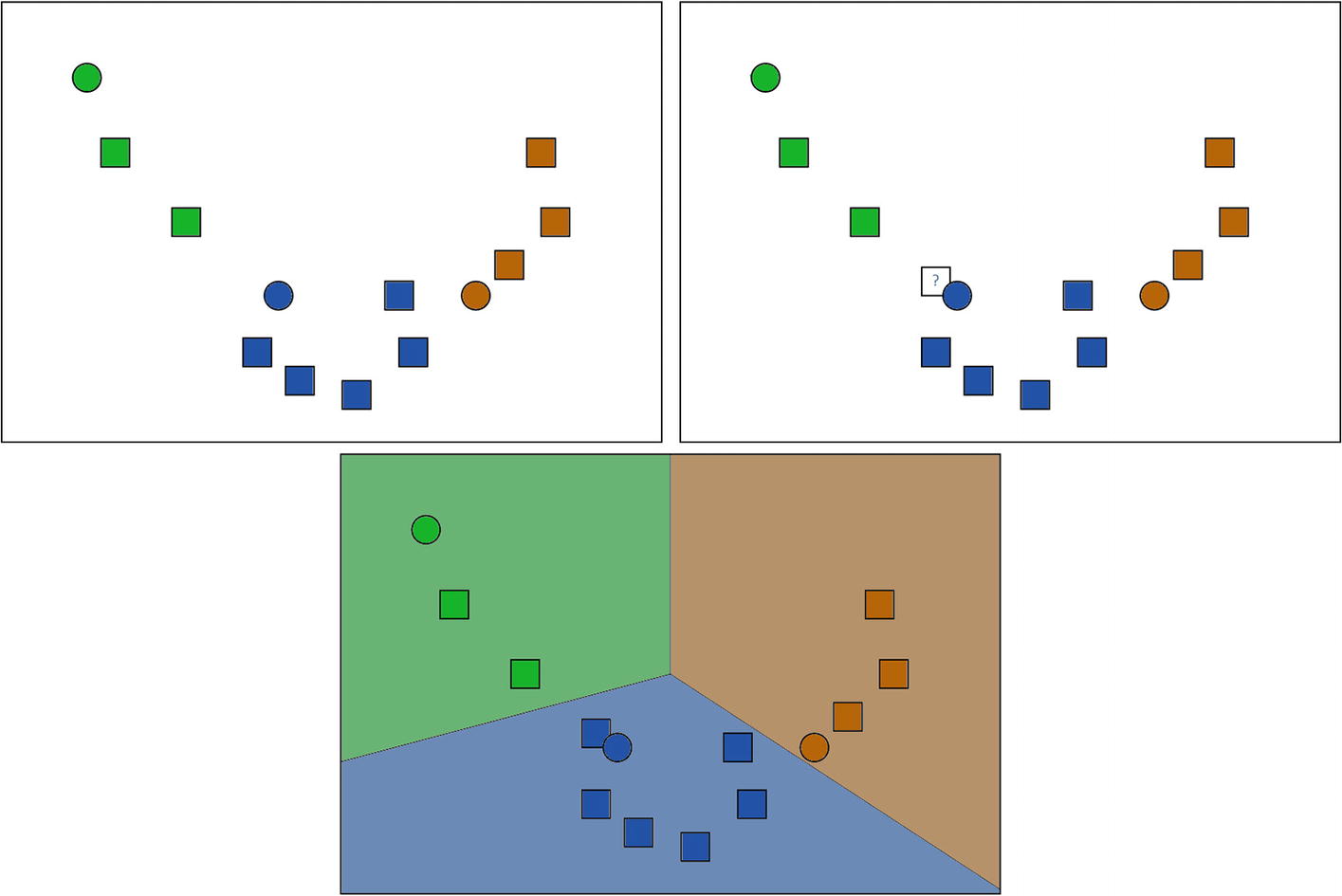
A supervised learning example. Figure 2-2 is our training data, and we would like to ask the system to categorize the data point with the question mark in Figure 2-3. The classification algorithm will utilize the data points to figure out the boundaries based on the labeled data and then predict the label for the input data point (Figure 2-4).
Regression is similar but is concerned with predicting continuous values. For example, say we have a data set of some weather features across airports. Maybe we have data for temperature, humidity, cloud cover, wind speed, rain quantity, and the number of flights canceled for that day for JFK in New York, San Francisco International, and O’Hare in Chicago. We could feed this data into a regression model and use it to estimate the number of cancellations given some hypothetical weather in New York, San Francisco, and Chicago.
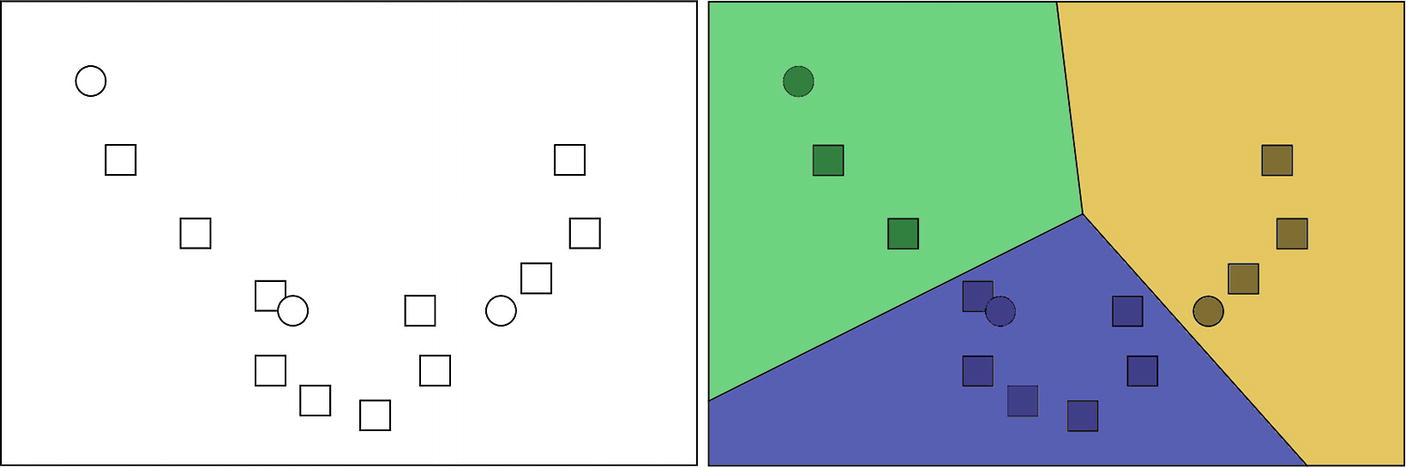
Unsupervised learning in which an algorithm identifies three clusters of data
Semisupervised learning is the idea of training a model with some labeled data and some unlabeled data. Reinforcement learning is the idea of a system learning by making observations and, based on said observations, making a decision that maximizes some reward function. If the decision yields a better reward, it is reinforced. Otherwise, the decision is penalized. More information about the different types of learning can be found elsewhere.5
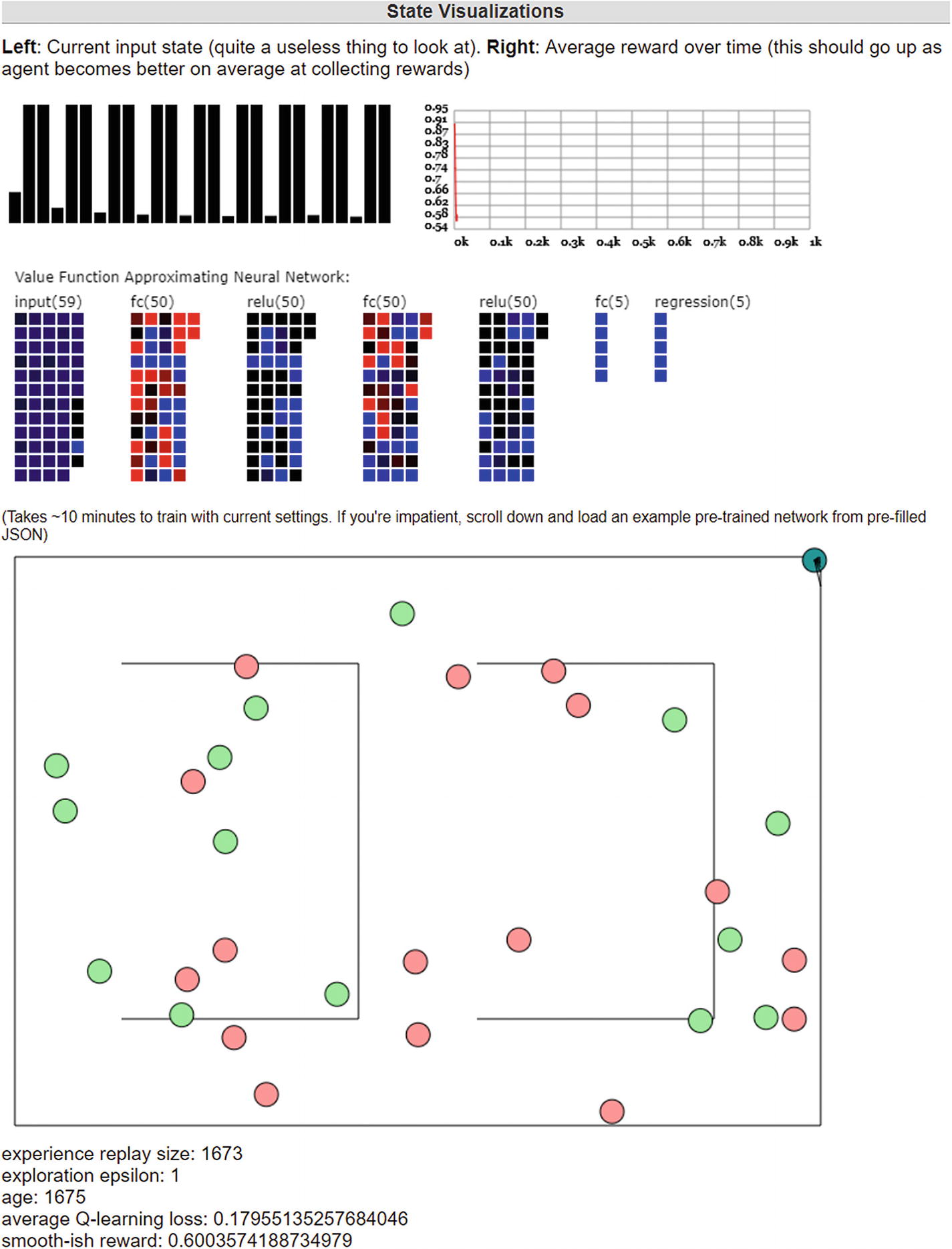
A visualization of a deep reinforcement learning algorithm
An interesting point to highlight is that the general popular bot applications of NLU and NLP are quite superficial. In fact, there has been criticism to calling what Watson did on Jeopardy or what bots do NLU. As a Wall Street Journal article by Ray Kurzweil stated, Watson doesn’t know it won Jeopardy. Understanding and classifying/extracting information are two different tasks. This is a fair criticism, but a well-built intent and entity model can prove useful when it comes to understanding human language in specific narrow contexts, which is exactly what chat bots do.
Aside from the intent classification problem, NLP concerns itself with tasks such as speech tagging, semantic analysis, translation, named entity recognition, automatic summarization, natural language generation, sentiment analysis, and many others. We will look into translation in Chapter 10 in the context of a multilingual bot.
In the 1980s, interest in artificial neural network (ANN) research was increasing. In the following decades, further research in the area yielded fascinating results. A simplistic view of a neuron in an ANN is to think of it as a simple function with N weights/inputs and one output. An ANN is a set of interconnected neurons. The neural network, as a unit, accepts a set of inputs and produces an output. The process of training a neural network is the process of setting the values of the weights on the neurons. Researchers have focused on analysis of many different types of neural networks. Deep learning is the process of training deep neutral networks, which are ANNs with many hidden layers between the input and output (Figure 2-8).
Google’s Translate, AlphaGo, and Microsoft’s Speech Recognition have all experienced positive results by utilizing deep neural networks. Deep learning’s success is a result of research into the various connectivity architectures within the hidden layers. Some of the more popular architectures are convolutional neural networks (CNNs)7 and recurrent neural networks (RNNs).8 Applications related to bots may include translation, text summarization, and language generation. There are many other resources for you to explore if you would like to go down the rabbit hole of how ANNs can be applied to natural language tasks.9
What is happening within the many ANN layers as the data goes back and forth between the neurons? It seems that no one is quite sure. Google’s Translate, for example, has been observed creating an intermediate representation of language. Facebook’s project to create AI that could negotiate with either other bots or human resulted in the AI creating its own shorthand and even lying. This has been written about as some indication that AI is taking over the world when, in reality, although these are fascinating and discussion-worthy behaviors, they are side effects of the training process. In the future, some of these side effects may become creepier and scarier as the complexity of the networks produce more unintended emergent behavior. For now, we are safe from an AI takeover.
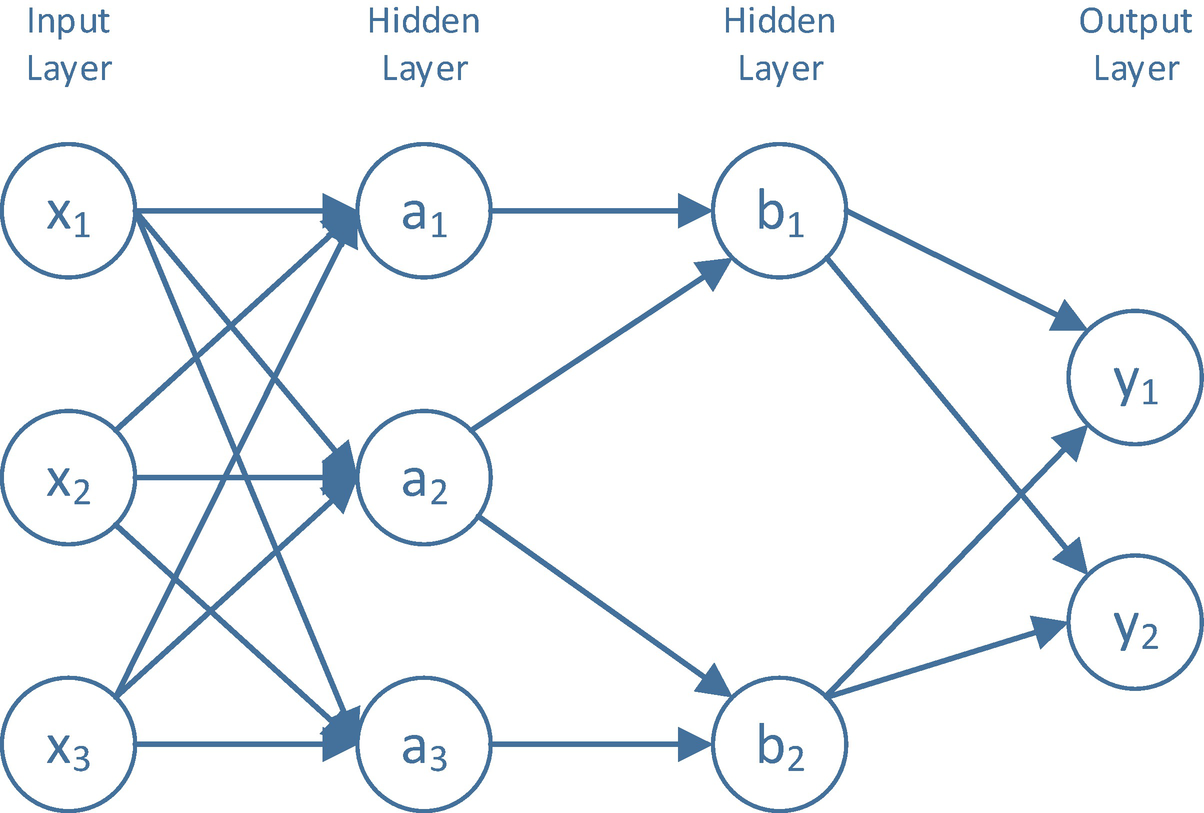
An ANN
Deep learning techniques are being utilized quite successfully in natural language processing tasks. In particular, speech recognition and translation have benefitted substantially from the introduction of deep learning. In fact, Microsoft Research has created speech recognition software “that recognizes conversations as well as professional human transcribers,”12 and Google has decreased its translation algorithm’s error rate by between 55 to 85 percent for certain language pairs by taking advantage of deep learning.13 However, effectiveness in NLU tasks such as intent classification is not as strong as the deep learning hype may want it to be. The key insight here is that deep learning is another tool in the ML toolkit, not a silver bullet.
Common NLP Tasks
In general, NLP deals with a whole multitude of problems, a subset of which are what we would consider NLU tasks. At a high level, the topics can be related to language syntax, semantics, and discourse analysis. Not every NLP task is immediately relevant to chat bot development; some of them are foundational to the more relevant higher-order features such as intent classification and entity extraction.
Syntax
Syntax tasks generally deal with issues corresponding to taking text input and breaking it up into its constituent parts. Many of these tasks are foundational and will not be directly used by a bot. Segmenting input into smaller units of speech, called morphemes, and building structures representing the speech in some grammar are two examples of this. Part of speech tagging, the process of tagging every word in user input with its part of speech (e.g., noun, verb, pronoun), could be used to refine user queries.
Semantics
Named entity extraction: Given some text, determine which words map to names and what the type of name is (e.g., location, person). This is directly applicable to what we want chat bots to do.
Sentiment analysis: Identify whether the contents of some text are overall positive, negative, or neutral. This can be utilized for determining user sentiment to bot responses, redirecting to a human agent, or in bot analytics understanding where users are tripping up and not reacting well to the bot.
Topic segmentation: Given some text, break it into segments related to topics and extract those topics.
Relationship extraction: This extracts the relationship between objects in text.
Discourse Analysis
Discourse analysis is the process of looking at larger natural language structures and making sense of them as a unit. In this area, we are interested in deriving meaning from context in a body of text. Automatic summarization is used to summarize a large body of content such as corporate financial statements. More relevant to chat bots is the concept of co-reference resolution. Co-reference resolution is the idea of determining what entity multiple words refer to. In the following input, the I refers to Szymon:
Common Bot NLU Tasks
Multilanguage support: The support of multiple languages in an NLU implementation speaks volumes about a serious undertaking of an NLU platform. Experience with optimizations for different languages can be a good indicator of the team’s overall experience with NLU.
Ability to include prebuilt models: A head start is always appreciated, and many systems will include many prebuilt intents and entities associated with a specific domain for you to start using.
Prebuilt entities: There are many types of entities we would expect an existing system to be able to easily pull out for us, for example, numbers and date/time objects.
Entity types: There should be an ability to specify different types of entities (lists versus nonlists come to mind).
Synonyms: The system should accept the ability to show assign synonyms to entities.
Ongoing training via Active Learning: The system should support the ability to utilize real user input as training data for the NLU models.
API Although these tools will implement some sort of user interface for you to utilize to train the models, there should an API you can utilize to do so.
Export/Import: The tool should allow you to import/export models, preferably in an open text format like JSON.
An alternative approach to utilizing preexisting services would be to write your own. This is an advanced topic. If you are reading this book, chances are you do not possess the experience and knowledge to make it work. There are easy-to-use ML packages such as scikit-learn that may give the impression that creating something like this is easy, but the effort requires substantial optimizations, tuning, testing, and operationalization. Getting the right type of performance out of these general-purpose NLU systems takes a lot of time, effort, and expertise. If you are interested in how the technologies work, there are plenty of materials online for you to educate yourself.14
Cloud-Based NLU Systems
The great news from the space of cloud computing and the investment that the big technology firms are making into the ML as a service space is that the basic functionality for the tasks that we need for our bots are available as services. From a practical perspective, there are many benefits here: developers don’t have to be concerned with selecting the best algorithms for our classification problem, there is no need to scale the implementation, there are existing efficient user interfaces and upgrades, and optimizations are seamless. If you are creating a chat bot and need the basic classification and entity extractions features, using a cloud-based service is the best option.
Microsoft’s Language Understanding Intelligence Service (LUIS): This is the purest example of an LU system because it is completely independent from a conversation engine. LUIS allows the developer to add intents and entities, version the LUIS application, test the application before publishing, and finally publish to a test or production endpoint. In addition, it includes some very interesting active learning features.
Google’s Dialogflow (Api.ai) : Dialogflow, previously known as Api.ai, has been around for a while. It allows the developer to create NLU models and define conversions flows and calls to webhooks or cloud functions when certain conditions are met. The conversation is accessible via an API or via integrations to many messaging channels.
Amazon’s Lex : Amazon’s Alexa has long allowed users to create intent classification and entity extraction models. With the introduction of Lex, Amazon brings a better user interface to NLU with bot development. Lex has a few channel integrations at the time of this writing and can be accessed via an API. Like Dialogflow, Lex allows developers to use an API to talk to the bot.
IBM Watson Conversation : Yet another similar system, Watson Conversation allows the user to define intents, entities, and a cloud-based dialog. The conversation is accessible via an API. At the time of this writing, there are no prebuilt channel connectors; a broker must be written by the bot developer though samples exist.
Facebook’s Wit.ai : Wit.ai has been around for a while and includes an interface to define intents and entities. As of July 2017, it is refocusing on NLU and removing the bot engine pieces. Wit.ai is also being more closely integrated with the Facebook Messenger ecosystem.
For our NLU deep dive in the following chapter, we will utilize LUIS. Being a pure NLU system, LUIS has a significant advantage, especially when it comes to Bot Framework integration. Although there are not many benchmarks in the NLU space at this time, LUIS ranks among the top-performing NLU systems in the market.15
Enterprise Space
There are many other options in the enterprise space—really, too many to list. Some of the bigger company and product names you may run into are IPsoft’s Amelia and Nuance’s Nina. Products in this space are generally advanced and contain years of enterprise-level investment. Some companies focus on IT or other process automation. Some companies focus on internal use cases. Some companies focus on specific verticals. And yet other companies focus entirely on prebuilt NLU models around specific use cases. In some products, we will write bot implementations via a proprietary language versus an open language.
In the end, the decision for enterprises is a classic buy versus build dilemma. Niche solutions may stay around for a while, but it is reasonable to assume that with the amount of investment IBM, Amazon, Microsoft, Google, and Facebook are throwing into this space, companies with less financial backing might be handicapped. Niche players that don’t solve the general bot problem may certainly thrive, and I think we will find more companies creating and innovating in specialized NLU and bot solutions that are powered by the big tech company offerings.
Conclusion
We are truly seeing the democratization of AI in the NLU space. Years ago, bot developers would have to pick up the existing NLU and ML libraries to create a system that could be trained and used as readily and easily as the cloud options we have available these days. Now, it is incredibly easy to create a bot that integrates NLU, sentiment analysis, and coreferences. The firms’ effort behind these systems isn’t something to scoff at either; the largest technology companies are digging into this space to provide the tooling for their users to build conversational experiences for their own platforms. For you as a bot developer, this is great. It means competition will keep pushing for innovation in the space, and as research in the field progresses, improvements in classification, entity extraction and active learning will improve NLU systems’ performance. Bot developers stand to gain from the increased pace of research and improved performance of all these NLP services.