Table of Contents for
Hands-On Unsupervised Learning Using Python
 Hands-On Unsupervised Learning Using Python
Published by
O'Reilly Media, Inc., 2019
Hands-On Unsupervised Learning Using Python
Published by
O'Reilly Media, Inc., 2019
- Cover
- nav
- Hands-on Unsupervised Learning Using Python
- Hands-On Unsupervised Learning Using Python
- Preface
- I. Fundamentals of Unsupervised Learning
- 1. Unsupervised Learning in the Machine Learning Ecosystem
- 2. End-to-End Machine Learning Project
- II. Unsupervised Learning Using Scikit-Learn
- 3. Dimensionality Reduction
- 4. Anomaly Detection
- 5. Clustering
- 6. Group Segmentation
- III. Unsupervised Learning using TensorFlow and Keras
- 7. Autoencoders
- 8. Hands-On Autoencoder
- 9. Semi-Supervised Learning
- IV. Deep Unsupervised Learning using TensorFlow and Keras
- 10. Recommender Systems Using Restricted Boltzmann Machines
- 11. Feature Detection Using Deep Belief Networks
- 12. Generative Adversarial Networks
- 13. Time Series Clustering
- 14. Conclusion
- Index
- About the Author
Chapter 12. Generative Adversarial Networks
We have already explored two types of generative models - RBMs and DBNs.
In this chapter, we will explore generative adversarial networks (GANs), one of the latest and most promising areas of unsupervised learning and generative modeling.
GANs, the Concept
GANs were introduced by Ian Goodfellow and his fellow researchers at the University of Montreal in 2014. In GANs, we have two neural networks. One network known as the generator generates data based on a model it has created using samples of real data it has received as input. The other network known as the discriminator discriminates between the data created by the generator and data from the true distribution.
As a simple analogy, the generator is the counterfeiter, and the discriminator is the police trying to identify the forgery. The two networks are locked in a zero-sum game. The generator is trying to fool the discriminator into thinking the synthetic data comes from the true distribution, and the discriminator is trying to call out the synthetic data as fake.
GANs are unsupervised learning algorithms because the generator can learn the underlying structure of the true distribution even when there are no labels. The generator learns the underlying structure by using a number of parameters significantly smaller than the amount of data it has trained on - a core concept of unsupervised learning that we have explored many times in previous chapters. This constraint forces the generator to efficiently capture the most salient aspects of the true data distribution.
This is similar to the representation learning that occurs in deep learning. Each hidden layer in the neutral network of a generator captures a representation of the underlying data—starting very simply—and subsequent layers pick up more complicated representations by building on the simpler preceding layers.
Using all these layers together, the generator learns the underlying structure of the data and attempts to create synthetic data that is nearly identical to the true data. If the generator has captured the essence of the true data, the synthetic data will appear real.
The Power of GANs
In Chapter 11, we explored the ability to use synthetic data from an unsupervised learning model - such as a deep belief network - to improve the performance of a supervised learning model. Like DBNs, GANs are very good at generating synthetic data.
If the objective is to generate a lot of new training examples to help supplement existing training data—for example, to improve accuracy on an image recognition task—we can use the generator to create a lot of synthetic data, add the new synthetic data to the original training data, and then run a supervised machine learning model on the now much larger data set.
GANs can also excel at anomaly detection. If the objective is to identify anomalies—for example, to detect fraud, hacking, or other suspicious behavior—we can use the discriminator to score each instance in the real data. The instances that the discriminator ranks as “likely synthetic” will be the most anomalous instances and also the ones most likely to represent malicious behavior.
Deep Convolutional GANs (DCGANs)
In this chapter, we will return to the MNIST dataset we have used in previous chapters, and we will apply a version of GANs to generate synthetic data to supplement the existing MNIST dataset. We will then apply a supervised learning model to perform image classification. This is yet another version of semi-supervised learning.
Note
As a side note, you should now have a much deeper appreciation for semi-supervised learning. Because much of the world’s data is unlabeled, the ability of unsupervised learning to efficiently help label data by itself is very powerful. As part of such semi-supervised machine learning systems, unsupervised learning enhances the potential of all successful commercial applications of supervised learning to date.
Even outside of applications in semi-supervised systems, unsupervised learning has potential on a standalone basis because it learns from data without any labels and is one of the fields of AI that has the greatest potential to help the machine learning community move from narrow AI to more general AI applications.
The version of GANs we will use is called deep convolutional generative adversarial networks (DCGANs), which were first introduced in late 2015 by Alec Radford, Luke Metz, and Soumith Chintala.1
DCGANs are an unsupervised learning form of convolution neural networks (CNNs), which are commonly used - and with great success - in supervised learning systems for computer vision and image classification. Before we delve into DCGANs, let’s explore CNNs first, especially how they are used for image classification in supervised learning systems.
Convolutional Neural Networks (CNNs)
Compared to numerical and text data, images and video are considerably more computationally expensive to work with. For instance, a 4K Ultra HD image has dimensions of 4096 x 2160 x 3 (26,542,080) in total. To train a neural network on images of this resolution directly would require tens of millions of neurons and result in very long training times.
Instead of building a neural network directly on the raw images, we can take advantage of certain properties of images, namely that pixels are related to other pixels that are close by but not usually related to other pixels that are far away.
Convolution - from which convolutional neural networks derive their name - is the process of filtering the image to decrease the size of the image without losing the relationships among pixels.2
On the original image, we apply several filters of a certain size, known as the kernel size, and move these filters with a small step, known as the stride, to derive the new reduced pixel output.
After the convolution, we reduce the size of the representation further by taking the max of the pixels in the reduced pixel output, one small area at a time. This is known as max pooling.
We perform this convolution and max pooling several times to reduce the complexity of the images. Then, we flatten the images and use a normal fully connected layer to perform image classification.
Let’s now build a CNN and use it to perform image classification on the MNIST dataset.
First, we will load the necessary libraries.
'''Main'''importnumpyasnpimportpandasaspdimportos,time,reimportpickle,gzip,datetime'''Data Viz'''importmatplotlib.pyplotaspltimportseabornassnscolor=sns.color_palette()importmatplotlibasmplfrommpl_toolkits.axes_grid1importGrid%matplotlibinline'''Data Prep and Model Evaluation'''fromsklearnimportpreprocessingasppfromsklearn.model_selectionimporttrain_test_splitfromsklearn.model_selectionimportStratifiedKFoldfromsklearn.metricsimportlog_loss,accuracy_scorefromsklearn.metricsimportprecision_recall_curve,average_precision_scorefromsklearn.metricsimportroc_curve,auc,roc_auc_score,mean_squared_error'''Algos'''importlightgbmaslgb'''TensorFlow and Keras'''importtensorflowastfimportkerasfromkerasimportbackendasKfromkeras.modelsimportSequential,Modelfromkeras.layersimportActivation,Dense,Dropout,Flatten,Conv2D,MaxPool2Dfromkeras.layersimportLeakyReLU,Reshape,UpSampling2D,Conv2DTransposefromkeras.layersimportBatchNormalization,Input,Lambdafromkeras.layersimportEmbedding,Flatten,dotfromkerasimportregularizersfromkeras.lossesimportmse,binary_crossentropyfromIPython.displayimportSVGfromkeras.utils.vis_utilsimportmodel_to_dotfromkeras.optimizersimportAdam,RMSpropfromtensorflow.examples.tutorials.mnistimportinput_data
Next, we will load the MNIST datasets and store the image data in a 4D tensor since Keras requires image data in this format. We will also create one-hot vectors from the labels using the to_categorical function in Keras.
For use later, we will create Pandas DataFrames from the data, too. And, let’s re-use the view_digit function from earlier in the book to view the images.
# Load the datasetscurrent_path=os.getcwd()file='\\datasets\\mnist_data\\mnist.pkl.gz'f=gzip.open(current_path+file,'rb')train_set,validation_set,test_set=pickle.load(f,encoding='latin1')f.close()X_train,y_train=train_set[0],train_set[1]X_validation,y_validation=validation_set[0],validation_set[1]X_test,y_test=test_set[0],test_set[1]X_train_keras=X_train.reshape(50000,28,28,1)X_validation_keras=X_validation.reshape(10000,28,28,1)X_test_keras=X_test.reshape(10000,28,28,1)y_train_keras=to_categorical(y_train)y_validation_keras=to_categorical(y_validation)y_test_keras=to_categorical(y_test)# Create Pandas DataFrames from the datasetstrain_index=range(0,len(X_train))validation_index=range(len(X_train),len(X_train)+len(X_validation))test_index=range(len(X_train)+len(X_validation),len(X_train)+\len(X_validation)+len(X_test))X_train=pd.DataFrame(data=X_train,index=train_index)y_train=pd.Series(data=y_train,index=train_index)X_validation=pd.DataFrame(data=X_validation,index=validation_index)y_validation=pd.Series(data=y_validation,index=validation_index)X_test=pd.DataFrame(data=X_test,index=test_index)y_test=pd.Series(data=y_test,index=test_index)defview_digit(X,y,example):label=y.loc[example]image=X.loc[example,:].values.reshape([28,28])plt.title('Example:%dLabel:%d'%(example,label))plt.imshow(image,cmap=plt.get_cmap('gray'))plt.show()
Now let’s build the convolutional neural network.
We will call Sequential() in Keras to begin the model creation. Then, we will add two convolution layers, each with 32 filters of a kernel size of 5x5, a default stride of 1, and a rectified linear unit (ReLU) activation. Then, we perform max pooling with a pooling window of 2x2 and a stride of 1. And, we perform dropout, which you may recall is a form of regularization to reduce overfitting of the neural network. Specifically, we will drop 25% of the input units.
In the next stage, we add two convolution layers again, this time with 64 filters of a kernel size of 3x3. Then, we perform max pooling with a pooling window of 2x2 and a stride of 2. And, we follow this up with a dropout layer, with a dropout percentage of 25%.
Finally, we flatten the images, add a regular neural network with 256 hidden units, perform dropout with a dropout percentage of 50%, and perform 10-class classification using the softmax function.
model=Sequential()model.add(Conv2D(filters=32,kernel_size=(5,5),padding='Same',activation='relu',input_shape=(28,28,1)))model.add(Conv2D(filters=32,kernel_size=(5,5),padding='Same',activation='relu'))model.add(MaxPooling2D(pool_size=(2,2)))model.add(Dropout(0.25))model.add(Conv2D(filters=64,kernel_size=(3,3),padding='Same',activation='relu'))model.add(Conv2D(filters=64,kernel_size=(3,3),padding='Same',activation='relu'))model.add(MaxPooling2D(pool_size=(2,2),strides=(2,2)))model.add(Dropout(0.25))model.add(Flatten())model.add(Dense(256,activation="relu"))model.add(Dropout(0.5))model.add(Dense(10,activation="softmax"))
For this CNN training, we will use the Adam optimizer and minimize the cross entropy. We will also store the accuracy of the image classification as the evaluation metric.
Now, let’s train the model for one hundred epochs and evaluate the results on the validation set.
# Train CNNmodel.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])model.fit(X_train_keras,y_train_keras,validation_data=(X_validation_keras,y_validation_keras),\epochs=100)
Figure 12-1 displays the final accuracy and the accuracy over the one hundred epochs of training.
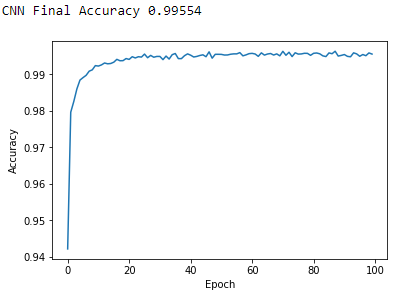
Figure 12-1. CNN results
As you can see, the CNN we just trained has a final accuracy of 99.55%, better than any of the MNIST image classification solutions we have trained so far throughout this book.
DCGANs Revisited
Let’s now turn back to deep convolutional generative adversarial networks once again. We will build a generative model to produce synthetic MNIST images that are very similar to the original MNIST images.
To produce near-realistic yet synthetic images, we need to train a generator that generates new images from the original MNIST images and a discriminator that judges whether those images are believably similar to the original ones or not (essentially performing a bullshit test).
Here is another way to think about this. The original MNIST dataset represents the original data distribution. The generator learns from this original distribution and generates new images based off what it has learned, and the discriminator attempts to determine whether the newly generated images are virtually indistinguishable from the original distribution or not.
For the generator, we will use the architecture presented in the Radford, Metz, and Chintala paper presented at the ICLR 2016 conference, which we referenced earlier (see Figure 12-2).
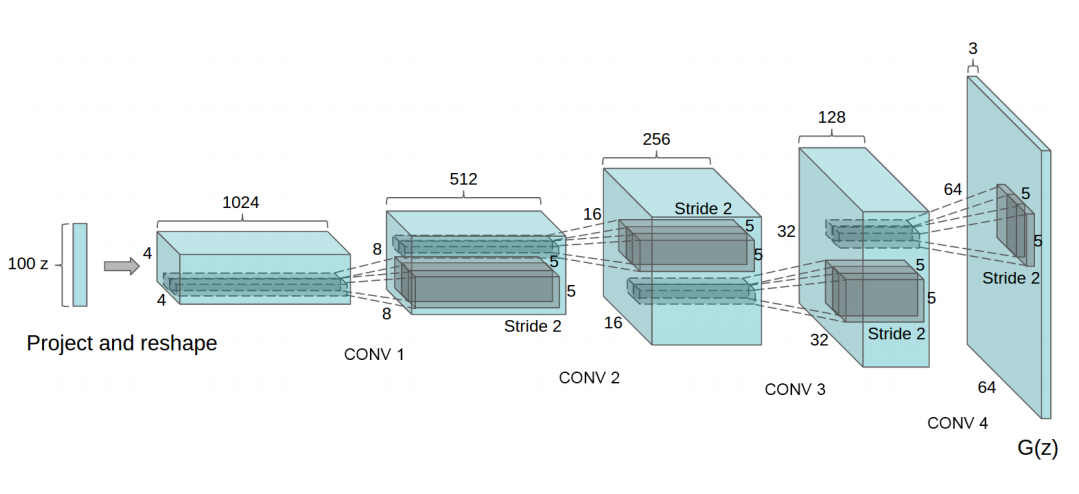
Figure 12-2. DCGAN generator
The genetor takes in an initial noise vector, shown as a 100x1 noise vector here denoted as z, and then projects and reshapes it into a 1024x4x4 tensor. This project and reshape action is the opposite of convolution and is known as tranposed convolution (or deconvolution in some cases). In transposed convolution, the original process of convolution is reversed, mapping a reduced tensor to a larger one.3
After the initial transposed convolution, the generator applies four additional deconvolution layers to map to a final 64x3x3 tensor.
Here are the various stages.
100x1 → 1024x4x4 → 512x8x8 → 256x16x16 → 128x32x32 → 64x64x3
We will apply a similar (but not exact) architecture when designing a DCGAN on the MNIST dataset.
Generator of the DCGAN
For the DCGAN we design, we will leverage work done by Rowel Atienza and build on top of it.4
We will first create a class called DCGAN, which we will use to build the generator, discriminator, discriminator model, and adversarial model.
Let’s start with the generator. We will set several parameters for the generator, including the dropout percentage (default value of 0.3), the depth of the tensor (default value of 256), and the other dimensions (default value of 7x7). We will also use batch normalization with a default momentum value of 0.8. The initial input dimensions are one hundred, and the final output dimensions are 28x28x1.
Recall that both dropout and batch normalization are regularizers to help the neural network we design from overfitting.
To build the generator, we call the Sequential() function from Keras. Then, we will add a dense, fully-connected neural network layer by calling the Dense() function. This will have an input dimension of 100 and an output dimension of 7x7x256. We will perform batch normalization, use the ReLU activation function, and perform dropout.
defgenerator(self,depth=256,dim=7,dropout=0.3,momentum=0.8,\window=5,input_dim=100,output_depth=1):ifself.G:returnself.Gself.G=Sequential()self.G.add(Dense(dim*dim*depth,input_dim=input_dim))self.G.add(BatchNormalization(momentum=momentum))self.G.add(Activation('relu'))self.G.add(Reshape((dim,dim,depth)))self.G.add(Dropout(dropout))
Next, we will perform upsampling and transposed convolution three times. Each time, we will halve the depth of the output space from 256 to 128 to 64 to 32 while increasing the other dimensions. We will maintain a convolution window of 5x5 and the default stride of one. During each transposed convolution, we will perform batch normalization and use the ReLU activation function.
Here is what this looks like.
100 → 7x7x256 → 14x14x128 → 28x28x64 → 28x28x32 → 28x28x1
self.G.add(UpSampling2D())self.G.add(Conv2DTranspose(int(depth/2),window,padding='same'))self.G.add(BatchNormalization(momentum=momentum))self.G.add(Activation('relu'))self.G.add(UpSampling2D())self.G.add(Conv2DTranspose(int(depth/4),window,padding='same'))self.G.add(BatchNormalization(momentum=momentum))self.G.add(Activation('relu'))self.G.add(Conv2DTranspose(int(depth/8),window,padding='same'))self.G.add(BatchNormalization(momentum=momentum))self.G.add(Activation('relu'))
Finally, the generator will output a 28x28 image, which has the same dimensions as the original MNIST images.
self.G.add(Conv2DTranspose(output_depth,window,padding='same'))self.G.add(Activation('sigmoid'))self.G.summary()returnself.G
Discriminator of the DCGAN
For the discriminator, we will set the default dropout percentage to 0.3, the depth as 64, and the alpha for the LeakyReLU function as 0.3.5 is an advanced activation function that is similar to the normal ReLU but allows a small gradient when the unit is not active. It is becoming a preferred activation function for image machine learning problems.]
First, we will load a 28x28x1 image and perform convolution using 64 channels, a filter of 5x5, and a stride of two. We will use LeakyReLU as the activation function and perform dropout.
We will continue this process three more times, doubling the depth of the output space each time while decreasing the other dimensions. For each convolution, we will use the LeakyReLU activation function and dropout.
Finally, we will flatten the images and use the sigmoid function to output a probability. This probability designates the discriminator’s confidence in calling the input image as a fake (where 0.0 is fake and 1.0 is real).
Here is what this looks like.
28x28x1 → 14x14x64 → 7x7x128 → 4x4x256 → 4x4x512 → 1
defdiscriminator(self,depth=64,dropout=0.3,alpha=0.3):ifself.D:returnself.Dself.D=Sequential()input_shape=(self.img_rows,self.img_cols,self.channel)self.D.add(Conv2D(depth*1,5,strides=2,input_shape=input_shape,padding='same'))self.D.add(LeakyReLU(alpha=alpha))self.D.add(Dropout(dropout))self.D.add(Conv2D(depth*2,5,strides=2,padding='same'))self.D.add(LeakyReLU(alpha=alpha))self.D.add(Dropout(dropout))self.D.add(Conv2D(depth*4,5,strides=2,padding='same'))self.D.add(LeakyReLU(alpha=alpha))self.D.add(Dropout(dropout))self.D.add(Conv2D(depth*8,5,strides=1,padding='same'))self.D.add(LeakyReLU(alpha=alpha))self.D.add(Dropout(dropout))self.D.add(Flatten())self.D.add(Dense(1))self.D.add(Activation('sigmoid'))self.D.summary()returnself.D
Discriminator and Adversarial Models
Next, let’s define the discriminator model (i.e., the police detecting the fakes) and the adversarial model (i.e., the counterfeiter learning from the police).
For both the adversarial and the discriminator model, we will use the RMSprop optimizer, define the loss function as binary cross entropy, and use accuracy as our reported metric.
For the adversarial model, we use the generator and discriminator networks we defined earlier. For the discriminator model, we use just the discriminator network.
defdiscriminator_model(self):ifself.DM:returnself.DMoptimizer=RMSprop(lr=0.0002,decay=6e-8)self.DM=Sequential()self.DM.add(self.discriminator())self.DM.compile(loss='binary_crossentropy',\optimizer=optimizer,metrics=['accuracy'])returnself.DMdefadversarial_model(self):ifself.AM:returnself.AMoptimizer=RMSprop(lr=0.0001,decay=3e-8)self.AM=Sequential()self.AM.add(self.generator())self.AM.add(self.discriminator())self.AM.compile(loss='binary_crossentropy',\optimizer=optimizer,metrics=['accuracy'])returnself.AM
DCGAN for the MNIST Dataset
Now let’s define the DCGAN for the MNIST dataset. First, we will initialize the MNIST_DCGAN class for the 28x28x1 MNIST images and use the generator, discriminator model, and adversarial model from earlier.
classMNIST_DCGAN(object):def__init__(self,x_train):self.img_rows=28self.img_cols=28self.channel=1self.x_train=x_trainself.DCGAN=DCGAN()self.discriminator=self.DCGAN.discriminator_model()self.adversarial=self.DCGAN.adversarial_model()self.generator=self.DCGAN.generator()
The train function will train for a default 2,000 training epochs and use a batch size of 256. In this function, we will feed batches of images into the DCGAN architecture we just defined. The generator will generate images, the discriminator will call out images as real or fake. As the generator and discriminator duke it out in this adversarial model, the synthetic images become more and more similar to the original MNIST images.
deftrain(self,train_steps=2000,batch_size=256,save_interval=0):noise_input=Noneifsave_interval>0:noise_input=np.random.uniform(-1.0,1.0,size=[16,100])foriinrange(train_steps):images_train=self.x_train[np.random.randint(0,self.x_train.shape[0],size=batch_size),:,:,:]noise=np.random.uniform(-1.0,1.0,size=[batch_size,100])images_fake=self.generator.predict(noise)x=np.concatenate((images_train,images_fake))y=np.ones([2*batch_size,1])y[batch_size:,:]=0d_loss=self.discriminator.train_on_batch(x,y)y=np.ones([batch_size,1])noise=np.random.uniform(-1.0,1.0,size=[batch_size,100])a_loss=self.adversarial.train_on_batch(noise,y)log_mesg="%d: [D loss:%f, acc:%f]"%(i,d_loss[0],d_loss[1])log_mesg="%s[A loss:%f, acc:%f]"%(log_mesg,a_loss[0],\a_loss[1])(log_mesg)ifsave_interval>0:if(i+1)%save_interval==0:self.plot_images(save2file=True,\samples=noise_input.shape[0],\noise=noise_input,step=(i+1))
Let’s also define a function to plot the images generated by this DCGAN model.
defplot_images(self,save2file=False,fake=True,samples=16,\noise=None,step=0):filename='mnist.png'iffake:ifnoiseisNone:noise=np.random.uniform(-1.0,1.0,size=[samples,100])else:filename="mnist_%d.png"%stepimages=self.generator.predict(noise)else:i=np.random.randint(0,self.x_train.shape[0],samples)images=self.x_train[i,:,:,:]plt.figure(figsize=(10,10))foriinrange(images.shape[0]):plt.subplot(4,4,i+1)image=images[i,:,:,:]image=np.reshape(image,[self.img_rows,self.img_cols])plt.imshow(image,cmap='gray')plt.axis('off')plt.tight_layout()ifsave2file:plt.savefig(filename)plt.close('all')else:plt.show()
MNIST DCGAN in Action
Now that we have defined the MNIST_DCGAN call, let’s call it and begin the training process. We will train for 10,000 epochs with a batch size of 256.
# Initialize MNIST_DCGAN and trainmnist_dcgan=MNIST_DCGAN(X_train_keras)timer=ElapsedTimer()mnist_dcgan.train(train_steps=10000,batch_size=256,save_interval=500)
Figure 12-3 displays the loss and the accuracy of the discriminator and the adversarial model.

Figure 12-3. Initial loss of the MNIST DCGAN
The initial loss of the discriminator fluctuates wildly but remains considerably above 0.50. In other words, the discriminator is initially very good at catching the poorly constructured counterfeits from the generator. Then, as the generator becomes better at creating counterfeits, the discriminator struggles; its accuracy drops close to 0.50 (see Figure 12-4).
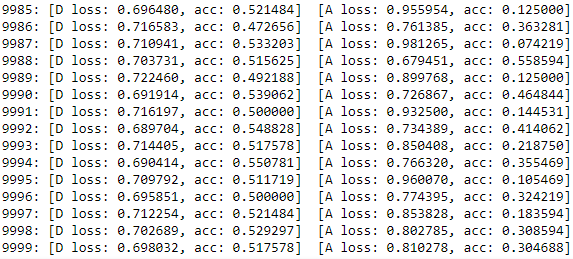
Figure 12-4. Final loss of the MNIST DCGAN
Synthetic Image Generation
Now that the MNIST DCGAN has been trained, let’s use it to generate a sample of synthetic images (see Figure 12-5).

Figure 12-5. Synthetic images generated by the MNIST DCGAN
These synthetic images - while not entirely indistinguishable from the real MNIST dataset - are eeriely similar to real digits. With more training time, the MNIST DCGAN should be capable of generating synthetic images that more closely resemble those of the real MNIST dataset and could be used to supplement the size of that dataset.
While our solution is reasonably good, there are many ways to make the MNIST DCGAN perform better. Here is a paper and the accomanying code that delves into more advanced methods to improve GAN performance.
Conclusion
In this chapter, we explored deep convolutional generative adversarial networks, a specialized form of generative adversarial networks that perform well on image and computer vision datasets.
GANs are a generative model with two neural networks locked in a zero-sum game. One of the networks, the generator (i.e., the counterfeiter), is generating synthetic data from real data, while the other network, the discriminator (i.e, the police), is calling the counterfeits as fake or real.6
This zero-sum game in which the generator learns from the discriminator leads to an overall generative model that generates pretty realistic synthetic data and generally gets better over time (i.e., as we train for more training epochs).
GANs are relatively new - they were first introduced by Ian Goodfellow et al. in 2014.7. GANs are currently mainly used to perform anomaly detection and generate synthetic data, but they could have many other applications in the near future. The machine learning community is barely scratching the surface with what is possible, and, if you decide to use GANs in applied machine learning systems, be ready to experiment a lot.8
In Chapter 13, we will explore our last and final concept called temporal clustering, which are a form of unsupervised learning for use with time series data.
1 For more on DCGANs, please visit the official paper on DCGANs.
2 For more on convolution layers, please visit this post.
3 For more on convolution layers, please visit this post, also referenced earlier in the chapter.
4 For the original code base, please visit Rowel Atienza’s GitHub page.
5 LeakyReLU[https://keras.io/layers/advanced-activations/
6 For more on generative models.
7 For more, please visit the seminal paper.
8 For some tips and tricks, please visit this post on how to how to refine GANs and improve performance.