Table of Contents for
Python Algorithms: Mastering Basic Algorithms in the Python Language, Second Edition
 Python Algorithms: Mastering Basic Algorithms in the Python Language, Second Edition
Published by
Apress, 2015
Python Algorithms: Mastering Basic Algorithms in the Python Language, Second Edition
Published by
Apress, 2015
- Cover
- Title
- Copyright
- Dedication
- Contents at a Glance
- Contents
- About the Author
- About the Technical Reviewer
- Acknowledgments
- Preface
- Chapter 1: Introduction
- Chapter 2: The Basics
- Chapter 3: Counting 101
- Chapter 4: Induction and Recursion … and Reduction
- Chapter 5: Traversal: The Skeleton Key of Algorithmics
- Chapter 6: Divide, Combine, and Conquer
- Chapter 7: Greed Is Good? Prove It!
- Chapter 8: Tangled Dependencies and Memoization
- Chapter 9: From A to B with Edsger and Friends
- Chapter 10: Matchings, Cuts, and Flows
- Chapter 11: Hard Problems and (Limited) Sloppiness
- Appendix A: Pedal to the Metal: Accelerating Python
- Appendix B: List of Problems and Algorithms
- Appendix C: Graph Terminology
- Appendix D: Hints for Exercises
- Index

Tangled Dependencies and Memoization
Twice, adv. Once too often.
— Ambrose Bierce, The Devil’s Dictionary
Many of you may know the year 1957 as the birth year of programming languages.1 For algorists, a possibly even more significant event took place this year: Richard Bellman published his groundbreaking book Dynamic Programming. Although Bellman’s book is mostly mathematical in nature, not really aimed at programmers at all (perhaps understandable, given the timing), the core ideas behind his techniques have laid the foundation for a host of very powerful algorithms, and they form a solid design method that any algorithm designer needs to master.
The term dynamic programming (or simply DP) can be a bit confusing to newcomers. Both of the words are used in a different way than most might expect. Programming here refers to making a set of choices (as in “linear programming”) and thus has more in common with the way the term is used in, say, television, than in writing computer programs. Dynamic simply means that things change over time—in this case, that each choice depends on the previous one. In other words, this “dynamicism” has little to do with the program you’ll write and is just a description of the problem class. In Bellman’s own words, “I thought dynamic programming was a good name. It was something not even a Congressman could object to. So I used it as an umbrella for my activities.”2
The core technique of DP, when applied to algorithm design, is caching. You decompose your problem recursively/inductively just like before—but you allow overlap between the subproblems. This means that a plain recursive solution could easily reach each base case an exponential number of times; however, by caching these results, this exponential waste can be trimmed away, and the result is usually both an impressively efficient algorithm and a greater insight into the problem.
Commonly, DP algorithms turn the recursive formulation upside down, making it iterative and filling out some data structure (such as a multidimensional array) step by step. Another option—one I think is particularly suited to high-level languages such as Python—is to implement the recursive formulation directly but to cache the return values. If a call is made more than once with the same arguments, the result is simply returned directly from the cache. This is known as memoization.
 Note Although I think memoization makes the underlying principles of DP clear, I do consistently rewrite the memoized versions to iterative programs throughout the chapter. While memoization is a great first step, one that gives you increased insight as well as a prototype solution, there are factors (such as limited stack depth and function call overhead) that may make an iterative solution preferable in some cases.
Note Although I think memoization makes the underlying principles of DP clear, I do consistently rewrite the memoized versions to iterative programs throughout the chapter. While memoization is a great first step, one that gives you increased insight as well as a prototype solution, there are factors (such as limited stack depth and function call overhead) that may make an iterative solution preferable in some cases.
The basic ideas of DP are quite simple, but they can take a bit getting used to. According to Eric V. Denardo, another authority on the subject, “Most beginners find all of them strange and alien.” I’ll be trying my best to stick to the core ideas and not get lost in formalism. Also, by placing the main emphasis on recursive decomposition and memoization, rather than iterative DP, I hope the link to all the work we’ve done so far in the book should be pretty clear.
Before diving into the chapter, here’s a little puzzle: Say you have a sequence of numbers, and you want to find its longest increasing (or, rather nondecreasing) subsequence—or one of them, if there are more. A subsequence consists of a subset of the elements in their original order. So, for example, in the sequence [3, 1, 0, 2, 4], one solution would be [1, 2, 4]. In Listing 8-1 you can see a reasonably compact solution to this problem. It uses efficient, built-in functions such as combinations from itertools and sorted to do its job, so the overhead should be pretty low. The algorithm, however, is a plain brute-force solution: Generate every subsequence and check them individually to see whether they’re already sorted. In the worst case, the running time here is clearly exponential.
Writing a brute-force solution can be useful in understanding the problem and perhaps even in getting some ideas for better algorithms; I wouldn’t be surprised if you could find several ways of improving naive_lis. However, a substantial improvement can be a bit challenging. Can you, for example, find a quadratic algorithm (somewhat challenging)? What about a loglinear one (pretty hard)? I’ll show you how in a minute.
Listing 8-1. A Naïve Solution to the Longest Increasing Subsequence Problem
from itertools import combinations
def naive_lis(seq):
for length in range(len(seq), 0, -1): # n, n-1, ... , 1
for sub in combinations(seq, length): # Subsequences of given length
if list(sub) == sorted(sub): # An increasing subsequence?
return sub # Return it!
Don’t Repeat Yourself
You may have heard of the DRY principle: Don’t repeat yourself. It’s mainly used about your code, meaning that you should avoid writing the same (or almost the same) piece of code more than once, relying instead of various forms of abstraction to avoid cut-and-paste coding. It is certainly one of the most important basic principles of programming, but it’s not what I’m talking about here. The basic idea of this chapter is to avoid having your algorithm repeat itself. The principle is so simple, and even quite easy to implement (at least in Python), but the mojo here is really deep, as you’ll see as we progress.
But let’s start with a couple of classics: Fibonacci numbers and Pascal’s triangle. You may well have run into these before, but the reason that “everyone” uses them is that they can be pretty instructive. And fear not—I’ll put a Pythonic twist on the solutions here, which I hope will be new to most of you.
The Fibonacci series of numbers is defined recursively as starting with two ones, with every subsequent number being the sum of the two previous. This is easily implemented as a Python function3:
>>> def fib(i):
... if i < 2: return 1
... return fib(i-1) + fib(i-2)
Let’s try it out:
>>> fib(10)
89
Seems correct. Let’s be a bit bolder:
>>> fib(100)
Uh-oh. It seems to hang. Something is clearly wrong. I’m going to give you a solution that is absolutely overkill for this particular problem but that you can actually use for all the problems in this chapter. It’s the neat little memo function in Listing 8-2. This implementation uses nested scopes to give the wrapped function memory—if you’d like, you could easily use a class with cache and func attributes instead.
Note There is actually an equivalent decorator in the functools module of the Python standard library, called lru_cache (available since Python 3.2, or in the package functools32 for Python 2.74). If you set its maxsize argument to None, it will work as a full memoizing decorator. It also provides a cache_clear method, which you could call between uses of your algorithm.
Listing 8-2. A Memoizing Decorator
from functools import wraps
def memo(func):
cache = {} # Stored subproblem solutions
@wraps(func) # Make wrap look like func
def wrap(*args): # The memoized wrapper
if args not in cache: # Not already computed?
cache[args] = func(*args) # Compute & cache the solution
return cache[args] # Return the cached solution
return wrap # Return the wrapper
Before getting into what memo actually does, let’s just try to use it:
>>> fib = memo(fib)
>>> fib(100)
573147844013817084101
Hey, it worked! But … why?
The idea of a memoized function5 is that it caches its return values. If you call it a second time with the same parameters, it will simply return the cached value. You can certainly put this sort of caching logic inside your function, but the memo function is a more reusable solution. It’s even designed to be used as a decorator6:
>>> @memo
... def fib(i):
... if i < 2: return 1
... return fib(i-1) + fib(i-2)
...
>>> fib(100)
573147844013817084101
As you can see, simply tagging fib with @memo can somehow reduce the running time drastically. And I still haven’t really explained how or why.
The thing is, the recursive formulation of the Fibonacci sequence has two subproblems, and it sort of looks like a divide-and-conquer thing. The main difference is that the subproblems have tangled dependencies. Or, to put it in another way, we’re faced with overlapping subproblems. This is perhaps even clearer in this rather silly relative of the Fibonacci numbers: a recursive formulation of the powers of two:
>>> def two_pow(i):
... if i == 0: return 1
... return two_pow(i-1) + two_pow(i-1)
...
>>> two_pow(10)
1024
>>> two_pow(100)
Still horrible. Try adding @memo, and you’ll get the answer instantly. Or, you could try to make the following change, which is actually equivalent:
>>> def two_pow(i):
... if i == 0: return 1
... return 2*two_pow(i-1)
...
>>> print(two_pow(10))
1024
>>> print(two_pow(100))
1267650600228229401496703205376
I’ve reduced the number of recursive calls from two to one, going from an exponential running time to a linear one (corresponding to recurrences 3 and 1, respectively, from Table 3-1). The magic part is that this is equivalent to what the memoized version does. The first recursive call would be performed as normal, going all the way to the bottom (i == 0). Any call after that, though, would go straight to the cache, giving only a constant amount of extra work. Figure 8-1 illustrates the difference. As you can see, when there are overlapping subproblems (that is, nodes with the same number) on multiple levels, the redundant computation quickly becomes exponential.
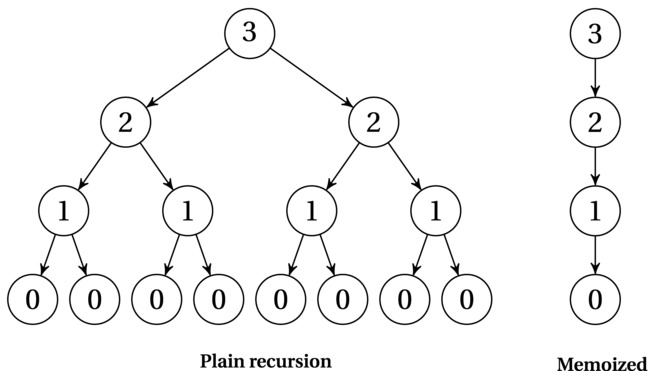
Figure 8-1. Recursion trees showing the impact of memoization. Node labels are subproblem parameters
Let’s solve a slightly more useful problem7: calculating binomial coefficients (see Chapter 3). The combinatorial meaning of C(n,k) is the number of k-sized subsets you can get from a set of size n. The first step, as almost always, is to look for some form of reduction or recursive decomposition. In this case, we can use an idea that you’ll see several times when working with dynamic programming8: We decompose the problem by conditioning on whether some element is included. That is, we get one recursive call if an element is included and another if it isn’t. (Do you see how two_pow could be interpreted in this way? See Exercise 8-2.)
For this to work, we often think of the elements in order so that a single evaluation of C(n,k) would only worry about whether element number n should be included. If it is included, we have to count the k-1-sized subsets of the remaining n-1 elements, which is simply C(n-1,k-1). If it is not included, we have to look for subsets of size k, or C(n-1,k). In other words:
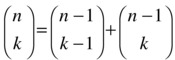
In addition, we have the following base cases: C(n,0) = 1 for the single empty subset, and C(0,k) = 0, k > 0, for nonempty subsets of an empty set.
This recursive formulation corresponds to what is often called Pascal’s triangle (after one if its discoverers, Blaise Pascal), although it was first published in 1303 by the great Chinese mathematician Zhu Shijie, who claimed it was discovered early in the second millennium ce. Figure 8-2 shows how the binomial coefficients can be placed in a triangular pattern so that each number is the sum of the two above it. This means that the row (counting from zero) corresponds to n, and the column (the number of the cell, counting from zero at the left in its row) corresponds to k. For example, the value 6 corresponds to C(4,2) and can be calculated as C(3,1) + C(3,2) = 3 + 3 = 6.
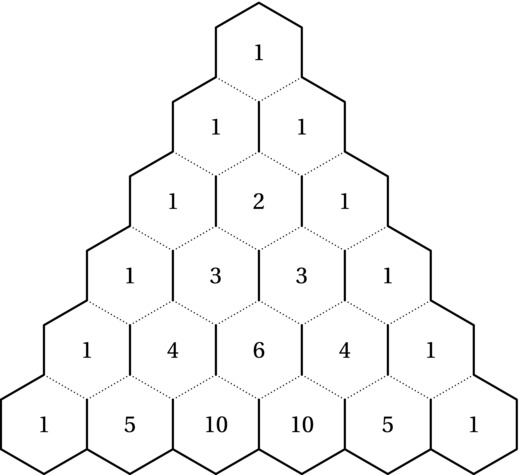
Figure 8-2. Pascal’s triangle
Another way of interpreting the pattern (as hinted at by the figure) is path counting. How many paths are there, if you go only downward, past the dotted lines, from the top cell to each of the others? This leads us to the same recurrence—we can come either from the cell above to the left or from the one above to the right. The number of paths is therefore the sum of the two. This means that the numbers are proportional to the probability of passing each of them if you make each left/right choice randomly on your way down. This is exactly what happens in games like the Japanese game Pachinko or in Plinko on The Price Is Right. There, a ball is dropped at the top and falls down between pins placed in some regular grid (such as the intersections of the hexagonal grid in Figure 8-2). I’ll get back to this path counting in the next section—it’s actually more important than it might seem at the moment.
The code for C(n,k) is trivial:
>>> @memo
>>> def C(n,k):
... if k == 0: return 1
... if n == 0: return 0
... return C(n-1,k-1) + C(n-1,k)
>>> C(4,2)
6
>>> C(10,7)
120
>>> C(100,50)
100891344545564193334812497256
You should try it both with and without the @memo, though, to convince yourself of the enormous difference between the two versions. Usually, we associate caching with some constant-factor speedup, but this is another ballpark entirely. For most of the problems we’ll consider, the memoization will mean the difference between exponential and polynomial running time.
Note Some of the memoized algorithms in this chapter (notably the one for the knapsack problem, as well as the ones in this section) are pseudopolynomial because we get a polynomial running time as a function of one of the numbers in the input, not only its size. Remember, the ranges of these numbers are exponential in their encoding size (that is, the number of bits used to encode them).
In most presentations of dynamic programming, memoized functions are, in fact, not used. The recursive decomposition is an important step of the algorithm design, but it is usually treated as just a mathematical tool, whereas the actual implementation is “upside down”—an iterative version. As you can see, with a simple aid such as the @memo decorator, memoized solutions can be really straightforward, and I don’t think you should shy away from them. They’ll help you get rid of nasty exponential explosions, without getting in the way of your pretty, recursive design.
However, as discussed before (in Chapter 4), you may at times want to rewrite your code to make it iterative. This can make it faster, and you avoid exhausting the stack if the recursion depth gets excessive. There’s another reason, too: The iterative versions are often based on a specially constructed cache, rather than the generic “dict keyed by parameter tuples” used in my @memo. This means that you can sometimes use more efficient structures, such as the multidimensional arrays of NumPy, perhaps combined with Cython (see Appendix A), or even just nested lists. This custom cache design makes it possible to do use DP in more low-level languages, where general, abstract solutions such as our @memo decorator are often not feasible. Note that even though these two techniques often go hand in hand, you are certainly free to use an iterative solution with a more generic cache or a recursive one with a tailored structure for your subproblem solutions.
Let’s reverse our algorithm, filling out Pascal’s triangle directly. To keep things simple, I’ll use a defaultdict as the cache; feel free to use nested lists, for example. (See also Exercise 8-4.)
>>> from collections import defaultdict
>>> n, k = 10, 7
>>> C = defaultdict(int)
>>> for row in range(n+1):
... C[row,0] = 1
... for col in range(1,k+1):
... C[row,col] = C[row-1,col-1] + C[row-1,col]
...
>>> C[n,k]
120
Basically the same thing is going on. The main difference is that we need to figure out which cells in the cache need to be filled out, and we need to find a safe order to do it in so that when we’re about to calculate C[row,col], the cells C[row-1,col-1] and C[row-1,col] are already calculated. With the memoized function, we needn’t worry about either issue: It will calculate whatever it needs recursively.
Tip One useful way to visualize dynamic programming algorithms with one or two subproblem parameters (such as n and k, here) is to use a (real or imagined) spreadsheet. For example, try calculating binomial coefficients in a spreadsheet by filling the first column with ones and filling in the rest of the first row with zeros. Put the formula =A1+B1 into cell B2, and copy it to the remaining cells.
Shortest Paths in Directed Acyclic Graphs
At the core of dynamic programming lies the idea of sequential decision problems. Each choice you make leads to a new situation, and you need to find the best sequence of choices that gets you to the situation you want. This is similar to how greedy algorithms work—it’s just that they rely on which choice looks best right now, while in general, you have to be less myopic and take future effects into consideration.
The prototypical sequential decision problem is finding your way from one node to another in a directed, acyclic graph. We represent the possible states of our decision process as individual nodes. The out-edges represent the possible choices we can make in each state. The edges have weights, and finding an optimal set of choices is equivalent to finding a shortest path. Figure 8-3 gives an example of a DAG where the shortest path from node a to node f has been highlighted. How should we go about finding this path?
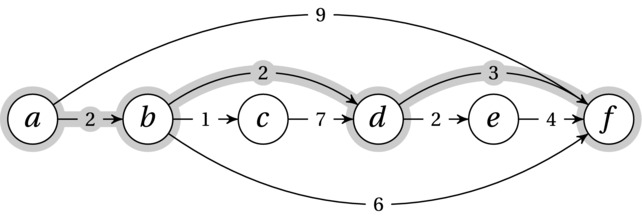
Figure 8-3. A topologically sorted DAG. Edges are labeled with weights, and the shortest path from a to f has been highlighted
It should be clear how this is a sequential decision process. You start in node a, and you have a choice between following the edge to b or the edge to f. On the one hand, the edge to b looks promising because it’s so cheap, while the one to f is tempting because it goes straight for the goal. We can’t go with simple strategies like this, however. For example, the graph has been constructed so that following the shortest edge from each node we visit, we’ll follow the longest path.
As in previous chapters, we need to think inductively. Let’s assume that we already know the answer for all the nodes we can move to. Let’s say the distance from a node v to our end node is d(v). Let the edge weight of edge (u,v) be w(u,v). Then, if we’re in node u, we already (by inductive hypothesis) know d(v) for each neighbor v, so we just have to follow the edge to the neighbor v that minimizes the expression w(u,v) + d(v). In other words, we minimize the sum of the first step and the shortest path from there.
Of course, we don’t really know the value of d(v) for all our neighbors, but as for any inductive design, that’ll take care of itself through the magic of recursion. The only problem is the overlapping subproblems. For example, in Figure 8-3, finding the distance from b to f requires finding the shortest path from, for example, d to f. But so does finding the shortest path from c to f. We have exactly the same situation as for the Fibonacci numbers, two_pow, or Pascal’s triangle. Some subproblems will be solved an exponential number of times if we implement the recursive solution directly. And just as for those problems, the magic of memoization removes all the redundancy, and we end up with a linear-time algorithm (that is, for n nodes and m edges, the running time is Θ(n + m)).
A direct implementation (using something like a dict of dicts representation of the edge weight function) can be found in Listing 8-3. If you remove @memo from the code, you end up with an exponential algorithm (which may still work well for relatively small graphs with few edges).
Listing 8-3. Recursive, Memoized DAG Shortest Path
def rec_dag_sp(W, s, t): # Shortest path from s to t
@memo # Memoize f
def d(u): # Distance from u to t
if u == t: return 0 # We're there!
return min(W[u][v]+d(v) for v in W[u]) # Best of every first step
return d(s) # Apply f to actual start node
In my opinion, the implementation in Listing 8-3 is quite elegant. It directly expresses the inductive idea of the algorithm, while abstracting away the memoization. However, this is not the classical way of expressing this algorithm. What is customarily done here, as in so many other DP algorithms, is to turn the algorithm “upside down” and make it iterative.
The iterative version of the DAG shortest path algorithm works by propagating partial solutions step by step, using the relaxation idea introduced in Chapter 4.9 Because of the way we represent graphs (that is, we usually access nodes by out-edges, rather than in-edges), it can be useful to reverse the inductive design: Instead of thinking about where we want to go, we think about where we want to come from. Then we want to make sure that once we reach a node v, we have already propagated correct answers from all v’s predecessors. That is, we have already relaxed its in-edges. This raises the question—how can we be sure we’ve done that?
The way to know is to sort the nodes topologically, as they are in Figure 8-3. The neat thing about the recursive version (in Listing 8-3) is that no separate topological sorting is needed. The recursion implicitly performs a DFS and does all updates in topologically sorted order automatically. For our iterative solution, though, we need to perform a separate topological sorting. If you want to get away from the recursion entirely, you can use topsort from Listing 4-10; if you don’t mind, you could use dfs_topsort from Listing 5-7 (although then you’re already quite close to the memoized recursive solution). The function dag_sp in Listing 8-4 shows you this more common, iterative solution.
Listing 8-4. DAG Shortest Path
def dag_sp(W, s, t): # Shortest path from s to t
d = {u:float('inf') for u in W} # Distance estimates
d[s] = 0 # Start node: Zero distance
for u in topsort(W): # In top-sorted order...
if u == t: break # Have we arrived?
for v in W[u]: # For each out-edge ...
d[v] = min(d[v], d[u] + W[u][v]) # Relax the edge
return d[t] # Distance to t (from s)
The idea of the iterative algorithm is that as long as we have relaxed each edge out from each of your possible predecessors (that is, those earlier in topologically sorted order), we must necessarily have relaxed all the in-edges to you. Using this, we can show inductively that each node receives a correct distance estimate at the time we get to it in the outer for loop. This means that once we get to the target node, we will have found the correct distance.
Finding the actual path corresponding to this distance isn’t all that hard either (see Exercise 8-5). You could even build the entire shortest path tree from the start node, just like the traversal trees in Chapter 5. (You’d have to remove the break statement, though, and keep going till the end.) Note that some nodes, including those earlier than the start node in topologically sorted order, may not be reached at all and will keep their infinite distances.
Note In most of this chapter, I focus on finding the optimal value of a solution, without the extra bookkeeping needed to reconstruct the solution that gives rise to that value. This approach makes the presentation simpler but may not be what you want in practice. Some of the exercises ask you to extend algorithms to find the actual solutions; you can find an example of how to do this at the end of the section about the knapsack problem.
VARIETIES OF DAG SHORTEST PATH
Although the basic algorithm is the same, there are many ways of finding the shortest path in a DAG and, by extension, solving most DP problems. You could do it recursively, with memoization, or you could do it iteratively, with relaxation. For the recursion, you could start at the first node, try various “next steps,” and then recurse on the remainder, or if your graph representation permits, you could look at the last node and try “previous steps” and recurse on the initial part. The former is usually much more natural, while the latter corresponds more closely to what happens in the iterative version.
Now, if you use the iterative version, you also have two choices: You can relax the edges out of each node (in topologically sorted order), or you can relax all edges into each node. The latter more obviously yields a correct result but requires access to nodes by following edges backward. This isn’t as far-fetched as it seems when you’re working with an implicit DAG in some non-graph problem. (For example, in the longest increasing subsequence problem, discussed later in this chapter, looking at all backward “edges” can be a useful perspective.)
Outward relaxation, called reaching, is exactly equivalent when you relax all edges. As explained, once you get to a node, all its in-edges will have been relaxed anyway. However, with reaching, you can do something that’s hard in the recursive version (or relaxing in-edges): pruning. If, for example, you’re interested only in finding all nodes that are within a distance r, you can skip any node that has distance estimate greater than r. You will still need to visit every node, but you can potentially ignore lots of edges during the relaxation. This won’t affect the asymptotic running time, though (Exercise 8-6).
Note that finding the shortest paths in a DAG is surprisingly similar to, for example, finding the longest path, or even counting the number of paths between two nodes in a DAG. The latter problem is just what we did with Pascal’s triangle earlier; the same approach would work for an arbitrary DAG. These things aren’t quite as easy for general graphs, though. Finding shortest paths in a general graph is a bit harder (in fact, Chapter 9 is devoted to this topic), while finding the longest path is an unsolved problem (see Chapter 11 for more on this).
Longest Increasing Subsequence
Although finding the shortest path in a DAG is the canonical DP problem, a lot—perhaps the majority—of the DP problems you’ll come across won’t have anything to do with (explicit) graphs. In these cases, you’ll have to sniff out the DAG or sequential decision process yourself. Or perhaps it’ll be easier to think of it in terms of recursive decomposition and ignore the whole DAG structure. In this section, I’ll follow both approaches with the problem introduced at the beginning of this chapter: finding the longest nondecreasing subsequence. (The problem is normally called “longest increasing subsequence,” but I’ll allow multiple identical values in the result here.)
Let’s go straight for the induction, and we can think more in graph terms later. To do the induction (or recursive decomposition), we need to define our subproblems—one of the main challenges of many DP problems. In many sequence-related problems, it can be useful to think in terms of prefixes—that we’ve figured out all we need to know about a prefix and that the inductive step is to figure things out for another element. In this case, that might mean that we’d found the longest increasing subsequence for each prefix, but that’s not informative enough. We need to strengthen our induction hypothesis so we can actually implement the inductive step. Let’s try, instead, to find the longest increasing subsequence that ends at each given position.
If we’ve already know how to find this for the first k positions, how can we find it for position k + 1? Once we’ve gotten this far, the answer is pretty straightforward: We just look at the previous positions and look at those whose elements are smaller than the current one. Among those, we choose the one that is at the end of the longest subsequence. Direct recursive implementation will give us exponential running time, but once again, memoization gets rid of the exponential redundancy, as shown in Listing 8-5. Once again, I’ve focused on finding the length of the solution; extending the code to find the actual subsequence isn’t all that hard (Exercise 8-10).
Listing 8-5. A Memoized Recursive Solution to the Longest Increasing Subsequence Problem
def rec_lis(seq): # Longest increasing subseq.
@memo
def L(cur): # Longest ending at seq[cur]
res = 1 # Length is at least 1
for pre in range(cur): # Potential predecessors
if seq[pre] <= seq[cur]: # A valid (smaller) predec.
res = max(res, 1 + L(pre)) # Can we improve the solution?
return res
return max(L(i) for i in range(len(seq))) # The longest of them all
Let’s make an iterative version as well. In this case, the difference is really rather slight—quite reminiscent of the mirror illustration in Figure 4-3. Because of how recursion works, rec_lis will solve the problem for each position in order (0, 1, 2 …). All we need to do in the iterative version is to switch out the recursive call with a lookup and wrap the whole thing in a loop. See Listing 8-6 for an implementation.
Listing 8-6. A Basic Iterative Solution to the Longest Increasing Subsequence Problem
def basic_lis(seq):
L = [1] * len(seq)
for cur, val in enumerate(seq):
for pre in range(cur):
if seq[pre] <= val:
L[cur] = max(L[cur], 1 + L[pre])
return max(L)
I hope you see the resemblance to the recursive version. In this case, the iterative version might be just as easy to understand as the recursive one.
Now, think of this as a DAG: Each sequence element is a node, and there is an implicit edge from each element to each following element that is larger—that is, to any element that is a permissible successor in an increasing subsequence (see Figure 8-4). Voilà! We’re now solving the DAG longest path problem. That’s actually pretty clear in the basic_lis function. We don’t have the edges explicitly represented, so it has to look at each previous element to see whether it’s a valid predecessor, but if it is, it simply relaxes the in-edge (that’s what the line with the max expression does, really). Can we improve the solution at the current position by using this “previous step” in the decision process (that is, this in-edge or this valid predecessor)?10
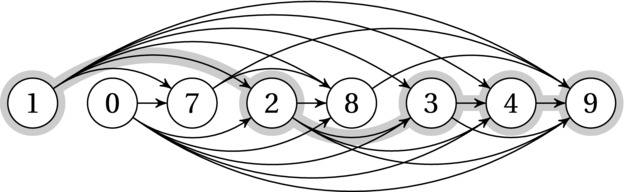
Figure 8-4. A number sequence and the implicit DAG where each path is an increasing subsequence. One of the longest increasing subsequences has been highlighted
As you can see, there is more than one way to view most DP problems. Sometimes you want to focus on the recursive decomposition and induction; sometimes you’d rather try to sniff out some DAG structure; sometimes, yet again, it can pay to look at what’s right there in front of you. In this case, that would be the sequence. The algorithm is still quadratic, and as you may have noticed, I called it basic_lis … that’s because I have another trick up my sleeve.
The main time sink in the algorithm is looking over the previous elements to find the best among those that are valid predecessors. You’ll find that this is the case in some DP algorithms—that the inner loop is devoted to a linear search. If this is the case, it might be worth trying to replace it with a binary search. It’s not at all obvious how that would be possible in this case, but simply knowing what we’re looking for—what we’re trying to do—can sometimes be of help. We’re trying to do some form of bookkeeping that will let us perform a bisection when looking for the optimal predecessor.
A crucial insight is that if more than one predecessor terminate subsequences of length m, it doesn’t matter which one of them we use—they’ll all give us an optimal answer. Say, we want to keep only one of them around; which one should we keep? The only safe choice would be to keep the smallest of them, because that wouldn’t wrongly preclude any later elements from building on it. So let’s say, inductively, that at a certain point we have a sequence end of endpoints, where end[idx] is the smallest among the endpoints we’ve seen for increasing subsequences of length idx+1 (we’re indexing from 0). Because we’re iterating over the sequence, these will all have occurred earlier than our current value, val. All we need now is an inductive step for extending end, finding out how to add val to it. If we can do that, at the end of the algorithm len(end) will give us the final answer—the length of the longest increasing subsequence.
The end sequence will necessarily be nondecreasing (Exercise 8-8). We want to find the largest idx such that end[idx-1] <= val. This would give us the longest sequence that val could contribute to, so adding val at end[idx] will either improve the current result (if we need to append it) or reduce the current end-point value at that position. After this addition, the end sequence still has the properties it had before, so the induction is safe. And the good thing is—we can find idx using the (super-fast) bisect function!11 You can find the final code in Listing 8-7. If you wanted, you could get rid of some of the calls to bisect (Exercise 8-9). If you want to extract the actual sequence, and not just the length, you’ll need to add some extra bookkeeping (Exercise 8-10).
Listing 8-7. Longest Increasing Subsequence
from bisect import bisect
def lis(seq): # Longest increasing subseq.
end = [] # End-values for all lengths
for val in seq: # Try every value, in order
idx = bisect(end, val) # Can we build on an end val?
if idx == len(end): end.append(val) # Longest seq. extended
else: end[idx] = val # Prev. endpoint reduced
return len(end) # The longest we found
That’s it for the longest increasing subsequence problem. Before we dive into some well-known examples of dynamic programming, here’s a recap of what we’ve seen so far. When solving problems using DP, you still use recursive decomposition or inductive thinking. You still need to show that an optimal or correct global solution depends on optimal or correct solutions to your subproblems (optimal substructure, or the principle of optimality). The main difference from, say, divide and conquer is just that you’re allowed to have overlapping subproblems. In fact, that overlap is the raison d’être of DP. You might even say that you should look for a decomposition with overlap, because eliminating that overlap (with memoization) is what will give you an efficient solution. In addition to the perspective of “recursive decomposition with overlap,” you can often see DP problems as sequential decision problems or as looking for special (for example, shortest or longest) paths in a DAG. These perspectives are all equivalent, but they can fit various problems differently.
Sequence Comparison
Comparing sequences for similarity is a crucial problem in much of molecular biology and bioinformatics, where the sequences involved are generally DNA, RNA, or protein sequences. It is used, among other things, to construct phylogenetic (that is, evolutionary) trees—which species have descended from which? It can also be used to find genes that are shared by people who have a given illness or who are receptive to a specific drug. Different kinds of sequence or string comparison is also relevant for many kinds of information retrieval. For example, you may search for “The Color Out of Space” and expect to find “The Colour Out of Space”—and for that to happen, the search technology you’re using needs to somehow know that the two sequences are sufficiently similar.
There are several ways of comparing sequences, many of which are more similar than one might think. For example, consider the problem of finding the longest common subsequence (LCS) between two sequences and finding the edit distance between them. The LCS problem is similar to the longest increasing subsequence problem—except that we’re no longer looking for increasing subsequence. We’re looking for subsequences that also occur in a second sequence. (For example, the LCS of Starwalker12 and Starbuck is Stark.) The edit distance (also known as Levenshtein distance) is the minimum number of editing operations (insertions, deletions, or replacements) needed to turn one sequence into another. (For example, the edit distance between enterprise and deuteroprism is 4.) If we disallow replacements, the two are actually equivalent. The longest common subsequence is the part that stays the same when editing one sequence into the other with as few edits as possible. Every other character in either sequence must be inserted or deleted. Thus, if the length of the sequences are m and n and the length of the longest common subsequence is k, the edit distance without replacements is m+n-2k.
I’ll focus on LCS here, leaving edit distance for an exercise (Exercise 8-11). Also, as before, I’ll restrict myself to the cost of the solution (that is, the length of the LCS). Adding some extra bookkeeping to let you find the underlying structure follows the standard pattern (Exercise 8-12). For some related sequence comparison problems, see the “If You’re Curious …” section near the end of this chapter.
Although dreaming up a polynomial algorithm to find the longest common subsequence can be really tough if you haven’t been exposed to any of the techniques in this book, it’s surprisingly simple using the tools I’ve been discussing in this chapter. As for all DP problems, the key is to design a set of subproblems that we can relate to each other (that is, a recursive decomposition with tangled dependencies). It can often help to think of the set of subproblems as being parametrized by a set of indexes or the like. These will then be our induction variables.13 In this case, we can work with prefixes of the sequences (just like we worked with prefixes of a single sequence in the longest increasing subsequence problem). Any pair of prefixes (identified by their lengths) gives rise to a subproblem, and we want to relate them in a subproblem graph (that is, a dependency DAG).
Let’s say our sequences are a and b. As with inductive thinking in general, we start with two arbitrary prefixes, identified by their lengths i and j. What we need to do is relate the solution to this problem to some other problems, where at least one of the prefixes is smaller. Intuitively, we’d like to temporarily chop off some elements from the end of either sequence, solve the resulting problem by our inductive hypothesis, and stick the elements back on. If we stick with weak induction (reduction by one) along either sequence, we get three cases: Chop the last element from a, from b, or from both. If we remove an element from just one sequence, it’s excluded from the LCS. If we drop the last from both, however, what happens depends on whether the two elements are equal or not. If they are, we can use them to extend the LCS by one! (If not, they’re of no use to us.)
This, in fact, gives us the entire algorithm (except for a couple of details). We can express the length of the LCS of a and b as a function of prefix lengths i and j as follows:
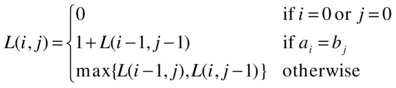
In other words, if either prefix is empty, the LCS is empty. If the last elements are equal, that element is the last element of the LCS, and we find the length of the rest (that is, the earlier part) recursively. If the last elements aren’t equal, we have only two options: Chop on element off either a or b. Because we can choose freely, we take the best of the two results. Listing 8-8 gives a simple memoized implementation of this recursive solution.
Listing 8-8. A Memoized Recursive Solution to the LCS Problem
def rec_lcs(a,b): # Longest common subsequence
@memo # L is memoized
def L(i,j): # Prefixes a[:i] and b[:j]
if min(i,j) < 0: return 0 # One prefix is empty
if a[i] == b[j]: return 1 + L(i-1,j-1) # Match! Move diagonally
return max(L(i-1,j), L(i,j-1)) # Chop off either a[i] or b[j]
return L(len(a)-1,len(b)-1) # Run L on entire sequences
This recursive decomposition can easily be seen as a dynamic decision process (do we chop off an element from the first sequence, from the second, or from both?), which can be represented as a DAG (see Figure 8-5). We start in the node represented by the full sequences, and we try to find the longest path back to the node representing two empty prefixes. It’s important to be clear about what the “longest path” is here, though—that is, what the edge weights are. The only time we can extend the LCS (which is our goal) is when we chop off two identical elements, represented by the DAG edges that are diagonal when the nodes are placed in a grid, as in Figure 8-5. These edges, then, have a weight of one, while the other edges have a weight of zero.
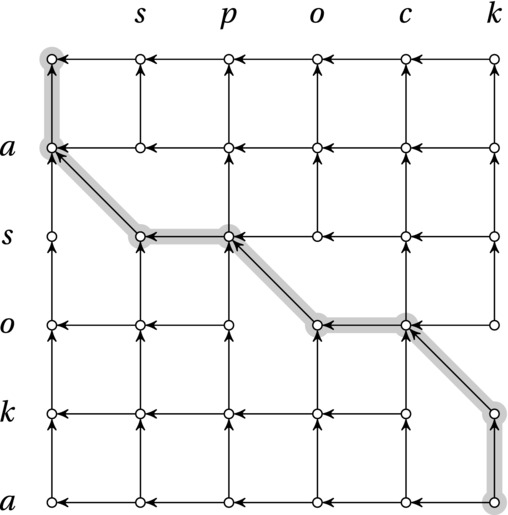
Figure 8-5. The underlying DAG of the LCS problem, where horizontal and vertical edges have zero cost. The longest path (that is, the one with the most diagonals) from corner to corner, where the diagonals represent the LCS, is highlighted
For the usual reasons, you may want to reverse the solution and make it iterative. Listing 8-9 gives you a version that saves memory by keeping only the current and the previous row of the DP matrix. (You could save a bit more, though; see Exercise 8-13.) Note that cur[i-1] corresponds to L(i-1,j) in the recursive version, while pre[i] and pre[i-1] correspond to L(i,j-1) and L(i-1,j-1), respectively.
Listing 8-9. An Iterative Solution to the Longest Common Subsequence (LCS)
def lcs(a,b):
n, m = len(a), len(b)
pre, cur = [0]*(n+1), [0]*(n+1) # Previous/current row
for j in range(1,m+1): # Iterate over b
pre, cur = cur, pre # Keep prev., overwrite cur.
for i in range(1,n+1): # Iterate over a
if a[i-1] == b[j-1]: # Last elts. of pref. equal?
cur[i] = pre[i-1] + 1 # L(i,j) = L(i-1,j-1) + 1
else: # Otherwise...
cur[i] = max(pre[i], cur[i-1]) # max(L(i,j-1),L(i-1,j))
return cur[n] # L(n,m)
In Chapter 7, I promised to give you a solution to the integer knapsack problem, both in bounded and unbounded versions. It’s time to make good on that promise.
Recall that the knapsack problem involves a set of objects, each of which has a weight and a value. Our knapsack also has a capacity. We want to stuff the knapsack with objects such that (1) the total weight is less than or equal to the capacity, and (2) the total value is maximized. Let’s say that object i has weight w[i] and value v[i]. Let’s do the unbounded one first—it’s a bit easier. This means that each object can be used as many times as you want.
I hope you’re starting to see a pattern emerging from the examples in this chapter. This problem fits the pattern just fine: We need to somehow define the subproblems, relate them to each other recursively, and then make sure we compute each subproblem only once (by using memoization, implicitly or explicitly). The “unboundedness” of the problem means that it’s a bit hard to restrict the objects we can use, using the common “in or out” idea (although we’ll use that in the bounded version). Instead, we can simply parametrize our subproblems using—that is, use induction over—the knapsack capacity.
If we say that m(r) is the maximum value we can get with a (remaining) capacity r, each value of r gives us a subproblem. The recursive decomposition is based on either using or not using the last unit of the capacity. If we don’t use it, we have m(r) = m(r-1). If we do use it, we have to choose the right object to use. If we choose object i (provided it will fit in the remaining capacity), we would have m(r) = v[i] + m(r-w[i]), because we’d add the value of i, but we’d also have used up a portion of the remaining capacity equal to its weight.
We can (once again) think of this as a decision process: We can choose whether to use the last capacity unit, and if we do use it, we can choose which object to add. Because we can choose any way we want, we simply take the maximum over all possibilities. The memoization takes care of the exponential redundancy in this recursive definition, as shown in Listing 8-10.
Listing 8-10. A Memoized Recursive Solution to the Unbounded Integer Knapsack Problem
def rec_unbounded_knapsack(w, v, c): # Weights, values and capacity
@memo # m is memoized
def m(r): # Max val. w/remaining cap. r
if r == 0: return 0 # No capacity? No value
val = m(r-1) # Ignore the last cap. unit?
for i, wi in enumerate(w): # Try every object
if wi > r: continue # Too heavy? Ignore it
val = max(val, v[i] + m(r-wi)) # Add value, remove weight
return val # Max over all last objects
return m(c) # Full capacity available
The running time here depends on the capacity and the number of objects. Each memoized call m(r) is computed only once, which means that for a capacity c, we have Θ(c) calls. Each call goes through all the n objects, so the resulting running time is Θ(cn). (This will, perhaps, be easier to see in the equivalent iterative version, coming up next. See also Exercise 8-14 for a way of improving the constant factor in the running time.) Note that this is not a polynomial running time because c can grow exponentially with the actual problem size (the number of bits). As mentioned earlier, this sort of running time is called pseudopolynomial, and for reasonably sized capacities, the solution is actually quite efficient.
Listing 8-11 shows an iterative version of the algorithm. As you can see, the two implementations are virtually identical, except that the recursion is replaced with a for loop, and the cache is now a list.14
Listing 8-11. An Iterative Solution to the Unbounded Integer Knapsack Problem
def unbounded_knapsack(w, v, c):
m = [0]
for r in range(1,c+1):
val = m[r-1]
for i, wi in enumerate(w):
if wi > r: continue
val = max(val, v[i] + m[r-wi])
m.append(val)
return m[c]
Now let’s get to the perhaps more well-known knapsack version—the 0-1 knapsack problem. Here, each object can be used at most once. (You could easily extend this to more than once, either by adjusting the algorithm a bit or by just including the same object more than once in the problem instance.) This is a problem that occurs a lot in practical situations, as discussed in Chapter 7. If you’ve ever played a computer game with an inventory system, I’m sure you know how frustrating it can be. You’ve just slain some mighty monster and find a bunch of loot. You try to pick it up but see that you’re overencumbered. What now? Which objects should you keep, and which should you leave behind?
This version of the problem is quite similar to the unbounded one. The main difference is that we now add another parameter to the subproblems: In addition to restricting the capacity, we add the “in or out” idea and restrict how many of the objects we’re allowed to use. Or, rather, we specify which object (in order) is “currently under consideration,” and we use strong induction, assuming that all subproblems where we either consider an earlier object, have a lower capacity, or both, can be solved recursively.
Now we need to relate these subproblems to each other and build a solution from subsolutions. Let m(k,r) be the maximum value we can have with the first k objects and a remaining capacity r. Then, clearly, if k = 0 or r = 0, we will have m(k,r) = 0. For other cases, we once again have to look at what our decision is. For this problem, the decision is simpler than in the unbounded one; we need consider only whether we want to include the last object, i = k-1. If we don’t, we will have m(k,r) = m(k-1,r). In effect, we’re just “inheriting” the optimum from the case where we hadn’t considered i yet. Note that if w[i] > r, we have no choice but to drop the object.
If the object is small enough, though, we can include it, meaning that m(k,r) = v[i] + m(k-1,r-w[i]), which is quite similar to the unbounded case, except for the extra parameter (k).15 Because we can choose freely whether to include the object, we try both alternatives and use the maximum of the two resulting values. Again, the memoization removes the exponential redundancy, and we end up with code like the one in Listing 8-12.
Listing 8-12. A Memoized Recursive Solution to the 0-1 Knapsack Problem
def rec_knapsack(w, v, c): # Weights, values and capacity
@memo # m is memoized
def m(k, r): # Max val., k objs and cap r
if k == 0 or r == 0: return 0 # No objects/no capacity
i = k-1 # Object under consideration
drop = m(k-1, r) # What if we drop the object?
if w[i] > r: return drop # Too heavy: Must drop it
return max(drop, v[i] + m(k-1, r-w[i])) # Include it? Max of in/out
return m(len(w), c) # All objects, all capacity
In a problem such as LCS, simply finding the value of a solution can be useful. For LCS, the length of the longest common subsequence gives us an idea of how similar two sequences are. In many cases, though, you’d like to find the actual solution giving rise to the optimal cost. The iterative knapsack version in Listing 8-13 constructs an extra table, called P because it works a bit like the predecessor tables used in traversal (Chapter 5) and shortest path algorithms (Chapter 9). Both versions of the 0-1 knapsack solutions have the same (pseudopolynomial) running time as the unbounded ones, that is, Θ(cn).
Listing 8-13. An Iterative Solution to the 0-1 Knapsack Problem
def knapsack(w, v, c): # Returns solution matrices
n = len(w) # Number of available items
m = [[0]*(c+1) for i in range(n+1)] # Empty max-value matrix
P = [[False]*(c+1) for i in range(n+1)] # Empty keep/drop matrix
for k in range(1,n+1): # We can use k first objects
i = k-1 # Object under consideration
for r in range(1,c+1): # Every positive capacity
m[k][r] = drop = m[k-1][r] # By default: drop the object
if w[i] > r: continue # Too heavy? Ignore it
keep = v[i] + m[k-1][r-w[i]] # Value of keeping it
m[k][r] = max(drop, keep) # Best of dropping and keeping
P[k][r] = keep > drop # Did we keep it?
return m, P # Return full results
Now that the knapsack function returns more information, we can use it to extract the set of objects actually included in the optimal solution. For example, you could do something like this:
>>> m, P = knapsack(w, v, c)
>>> k, r, items = len(w), c, set()
>>> while k > 0 and r > 0:
... i = k-1
... if P[k][r]:
... items.add(i)
... r -= w[i]
... k -= 1
In other words, by simply keeping some information about the choices made (in this case, keeping or dropping the element under consideration), we can gradually trace ourselves back from the final state to the initial conditions. In this case, I start with the last object and check P[k][r] to see whether it was included. If it was, I subtract its weight from r; if it wasn’t, I leave r alone (as we still have the full capacity available). In either case, I decrement k because we’re done looking at the last element and now want to have a look at the next-to-last element (with the updated capacity). You might want to convince yourself that this backtracking operation has a linear running time.
The same basic idea can be used in all the examples in this chapter. In addition to the core algorithms presented (which generally compute only the optimal value), you can keep track of what choice was made at each step and then backtrack once the optimum has been found.
Before concluding this chapter, let’s take a look at another typical kind of DP problem, where some sequence is recursively partitioned in some manner. You could think of this as adding parentheses to the sequence, so that we go from, for example, ABCDE to ((AB)((CD)E)). This has several applications, such as the following:
- Matrix chain multiplication: We have a sequence of matrices, and we want to multiply them all together into a single matrix. We can’t swap them around (matrix multiplication isn’t commutative), but we can place the parentheses where we want, and this can affect the number of operations needed. Our goal is to find the parenthesization (phew!) that gives the lowest number of operations.
- Parsing arbitrary context-free languages:16 The grammar for any context-free language can be rewritten to Chomsky normal form, where each production rule produces either a terminal, the empty string, or a pair AB of nonterminals A and B. Parsing a string then is basically equivalent to setting the parentheses just like in the matrix example. Each parenthesized group then represents a nonterminal.
- Optimal search trees: This is a tougher version of the Huffman problem. The goal is the same—minimize expected traversal depth—but because it’s a search tree, we can’t change the order of the leaves, and the greedy algorithm no longer works. Again, what we need is a parenthesization, corresponding to the tree structure.17
These three applications are quite different, but the problem is essentially the same: We want to segment the sequence hierarchically so that each segment contains two others, and we want to find such a partitioning that optimizes some cost or value (in the parsing case, the value is simply “valid”/“invalid”). The recursive decomposition works just like with a divide-and-conquer algorithm, as illustrated in Figure 8-6. A split point is chosen within the current interval, giving rise to two subintervals, which are partitioned recursively. If we were to create a balanced binary search tree based on a sorted sequence, that would be all there was to it. Use the middle element (or one of the two middle ones, for even-length intervals) as the split point (that is, root) and create the balanced left and right subtrees recursively.
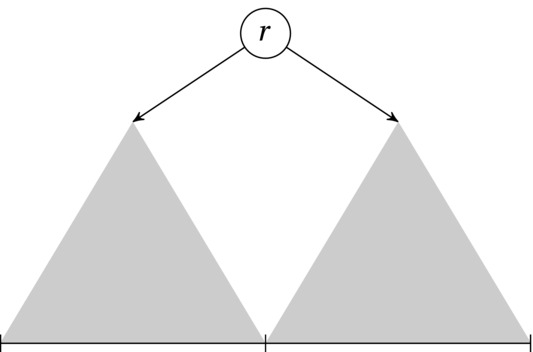
Figure 8-6. Recursive sequence partitioning as it applies to optimal search trees. Each root in the interval gives rise to two subtrees corresponding to the optimal partitioning of the left and right subintervals
Now we’re going to have to step our game up, though, because the split point isn’t given, like for the balanced divide-and-conquer example. No, now we need to try multiple split points, choosing the best one. In fact, in the general case, we need to try every possible split point. This is a typical DP problem—in some ways just as prototypical as finding shortest paths in DAGs. The DAG shortest path problem encapsulates the sequential decision perspective of DP; this sequence decomposition problem embodies the “recursive decomposition with overlap” perspective. The subproblems are the various intervals, and unless we memoize our recursion, they will be solved an exponential number of times. Also note that we’ve got optimal substructure: If we split the sequence at the optimal (or correct) point initially, the two new segments must be partitioned optimally for us to get an optimal (correct) solution.18
As a concrete example, let’s go with optimal search trees.19 As when we were building Huffman trees in Chapter 7, each element has a frequency, and we want to minimize the expected traversal depth (or search time) for a binary search tree. In this case, though, the input is sorted, and we cannot change its ordering. For simplicity, let’s assume that every query is for an element that is actually in the tree. (See Exercise 8-19 for a way around this.) Thinking inductively, we only need to find the right root node, and the two subtrees (over the smaller intervals) will take care of themselves (see Figure 8-6). Once again, to keep things simple, let’s just worry about computing the optimal cost. If you want to extract the actual tree, you need to remember which subtree roots gave rise to the optimal subtree costs (for example, storing it in root[i,j]).
Now we need to figure out the recursive relationships; how do we calculate the cost for a given root, assuming that we know the costs for the subtrees? The contribution of a single node is similar to that in Huffman trees. There, however, we dealt only with leaves, and the cost was the expected depth. For optimal search trees, we can end up with any node. Also, so as not to give the root a cost of zero, let’s count the expected number of nodes visited (that is, expected depth + 1). The contribution of node v is then p(v) × (d(v) + 1), where p(v) is its relative frequency and d(v) its depth, and we sum over all the nodes to get the total cost. (This is just 1 + sum of p(v) × d(v), because the p(v) sums to 1.)
Let e(i,j) be the expected search cost for the interval [i:j]. If we choose r as our root, we can decompose the cost into e(i,j) = e(i,r) + e(r+1,j) + something. The two recursive calls to e represent the expected costs of continuing the search in each subtree. What’s the missing something, though? We’ll have to add p[r], the probability of looking for the root, because that would be its expected cost. But how do we account for the extra edges down to our two subtrees? These edges will increase the depth of each node in the subtrees, meaning that each probability p[v] for every node v except the root must be added to the result. But, hey—as discussed, we’ll be adding p[r] as well! In other words, we will need to add the probabilities for all the nodes in the interval. A relatively straightforward recursive expression for a given root r might then be as follows:
e(i,j) = e(i,r) + e(r+1,j) + sum(p[v] for v in range(i, j))
Of course, in the final solution, we’d try all r in range(i, j) and choose the maximum. There’s a still more room for improvement, though: The sum part of the expression will be summing a quadratic number of overlapping intervals (one for every possible i and j), and each sum has linear running time. In the spirit of DP, we seek out the overlap: We introduce the memoized function s(i,j) representing the sum, as shown in Listing 8-14. As you can see, s is calculated in constant time, assuming the recursive call has already been cached (which means that a constant amount of time is spent calculating each sum s(i,j)). The rest of the code follows directly from the previous discussion.
Listing 8-14. Memoized Recursive Function for Expected Optimal Search Cost
def rec_opt_tree(p):
@memo
def s(i,j):
if i == j: return 0
return s(i,j-1) + p[j-1]
@memo
def e(i,j):
if i == j: return 0
sub = min(e(i,r) + e(r+1,j) for r in range(i,j))
return sub + s(i,j)
return e(0,len(p))
All in all, the running time of this algorithm is cubic. The asymptotic upper bound is straightforward: There is a quadratic number of subproblems (that is, intervals), and we have a linear scan for the best root inside each of them. In fact, the lower bound is also cubic (this is a bit trickier to show), so the running time is Θ(n3).
As for the previous DP algorithms, the iterative version (Listing 8-15) is similar in many ways to the memoized one. To solve the problems in a safe (that is, topologically sorted) order, it solves all intervals of a certain length k before going on to the larger ones. To keep things simple, I’m using a dict (or, more specifically, a defaultdict, which automatically supplies the zeros). You could easily rewrite the implementation to use, say, a list of lists instead. (Note, though, that only a triangular half-matrix is needed—not the full n by n.)
Listing 8-15. An Iterative Solution to the Optimal Search Tree Problem
from collections import defaultdict
def opt_tree(p):
n = len(p)
s, e = defaultdict(int), defaultdict(int)
for k in range(1,n+1):
for i in range(n-k+1):
j = i + k
s[i,j] = s[i,j-1] + p[j-1]
e[i,j] = min(e[i,r] + e[r+1,j] for r in range(i,j))
e[i,j] += s[i,j]
return e[0,n]
Summary
This chapter deals with a technique known as dynamic programming, or DP, which is used when the subproblem dependencies get tangled (that is, we have overlapping subproblems) and a straight divide-and-conquer solution would give an exponential running time. The term dynamic programming was originally applied to a class of sequential decision problems but is now used primarily about the solution technique, where some form of caching is performed, so that each subproblem need be computed only once. One way of implementing this is to add caching directly to a recursive function that embodies the recursive decomposition (that is, the induction step) of the algorithm design; this is called memoization. It can often be useful to invert the memoized recursive implementations, though, turning them into iterative ones. Problems solved using DP in this chapter include calculating binomial coefficients, finding shortest paths in DAGs, finding the longest increasing subsequence of a given sequence, finding the longest common subsequence of two given sequences, getting the most out of your knapsack with limited and unlimited supplies of indivisible items, and building binary search trees that minimize the expected lookup time.
If You’re Curious …
Curious? About dynamic programming? You’re in luck—there’s a lot of rad stuff available about DP. A web search should turn up loads of coolness, including competition problems, for example. If you’re into speech processing, or hidden Markov models in general, you could look for the Viterbi algorithm, which is a nice mental model for many kinds of DP. In the area of image processing, deformable contours (also known as snakes) are a nifty example.
If you think sequence comparison sounds cool, you could check out the books by Gusfield and Smyth (see the references). For a brief introduction to dynamic time warping and weighted edit distance—two important variations not discussed in this chapter—as well as the concept of alignment, you could have a look at the excellent tutorial “Sequence comparison,” by Christian Charras and Thierry Lecroq.20 For some sequence comparison goodness in the Python standard library, check out the difflib module. If you have Sage installed, you could have a look at its knapsack module (http://sage.numerical.knapsack).
For more about how the ideas of dynamic programming appeared initially, take a look at Stuart Dreyfus’s paper “Richard Bellman on the Birth of Dynamic Programming.” For examples of DP problems, you can’t really beat Lew and Mauch; their book on the subject discusses about 50. (Most of their book is rather heavy on the theory side, though.)
Exercises
8-1. Rewrite @memo so that you reduce the number of dict lookups by one.
8-2. How can two_pow be seen as using the “in or out” idea? What would the “in or out” correspond to?
8-3. Write iterative versions of fib and two_pow. This should allow you to use a constant amount of memory, while retaining the pseudolinear time (that is, time linear in the parameter n).
8-4. The code for computing Pascal’s triangle in this chapter actually fills out an rectangle, where the irrelevant parts are simply zeros. Rewrite the code to avoid this redundancy.
8-5. Extend either the recursive or iterative code for finding the length of the shortest path in a DAG so that it returns an actual optimal path.
8-6. Why won’t the pruning discussed in the sidebar “Varieties of DAG Shortest Path” have any effect on the asymptotic running time, even in the best case?
8-7. In the object-oriented observer pattern, several observers may register with an observable object. These observers are then notified when the observable changes. How could this idea be used to implement the DP solution to the DAG shortest path problem? How would it be similar to or different from the approaches discussed in this chapter?
8-8. In the lis function, how do we know that end is nondecreasing?
8-9. How would you reduce the number of calls to bisect in lis?
8-10. Extend either the recursive or one of the iterative solutions to the longest increasing subsequence problem so that it returns the actual subsequence.
8-11. Implement a function that computes the edit distance between two sequences, either using memoization or using iterative DP.
8-12. How would you find the underlying structure for LCS (that is, the actual shared subsequence) or edit distance (the sequence of edit operations)?
8-13. If the two sequences compared in lcs have different lengths, how could you exploit that to reduce the function’s memory use?
8-14. How could you modify w and c to (potentially) reduce the running time of the unbounded knapsack problem?
8-15. The knapsack solution in Listing 8-13 lets you find the actual elements included in the optimal solution. Extend one of the other knapsack solutions in a similar way.
8-16. How can it be that we have developed efficient solutions to the integer knapsack problems, when they are regarded as hard, unsolved problems (see Chapter 11)?
8-17. The subset sum problem is one you’ll also see in Chapter 11. Briefly, it asks you to pick a subset of a set of integers so that the sum of the subset is equal to a given constant, k. Implement a solution to this problem based on dynamic programming.
8-18. A problem closely related to finding optimal binary search trees is the matrix chain multiplication problem, briefly mentioned in the text. If matrices A and B have dimensions n×m and m×p, respectively, their product AB will have dimensions n×p, and we approximate the cost of this multiplication by the product nmp (the number of element multiplications). Design and implement an algorithm that finds a parenthetization of a sequence of matrices so that performing all the matrix multiplications has as low total cost as possible.
8-19. The optimal search trees we construct are based only on the frequencies of the elements. We might also want to take into account the frequencies of various queries that are not in the search tree. For example, we could have the frequencies for all words in a language available but store only some of the words in the tree. How could you take this information into consideration?
References
Bather, J. (2000). Decision Theory: An Introduction to Dynamic Programming and Sequential Decisions. John Wiley & Sons, Ltd.
Bellman, R. (2003). Dynamic Programming. Dover Publications, Inc.
Denardo, E. V. (2003). Dynamic Programming: Models and Applications. Dover Publications, Inc.
Dreyfus, S. (2002). Richard Bellman on the birth of dynamic programming. Operations Research, 50(1):48-51.
Fredman, M. L. (1975). On computing the length of longest increasing subsequences. Discrete Mathematics, 11(1):29-35.
Gusfield, D. (1997). Algorithms on Strings, Trees and Sequences: Computer Science and Computational Biology. Cambridge University Press.
Lew, A. and Mauch, H. (2007). Dynamic Programming: A Computational Tool. Springer.
Smyth, B. (2003). Computing Patterns in Strings. Addison-Wesley.
___________________________
1This was the year the first FORTRAN compiler was released by John Backus’s group. Many consider this the first complete compiler, although the first compiler ever was written in 1942, by Grace Hopper.
2See Richard Bellman on the Birth of Dynamic Programming in the references.
3Some definitions start with zero and one. If you want that, just use return i instead of return 1. The only difference is to shift the sequence indices by one.
4https://pypi.python.org/pypi/functools32/3.2.3
5That is memo-ized, not memorized.
6The use of the wraps decorator from the functools module doesn’t affect the functionality. It just lets the decorated function (such as fib) retain its properties (such as its name) after wrapping. See the Python docs for details.
7This is still just an example for illustrating the basic principles.
8For example, this “In or not?” approach is used in solving the knapsack problem, later in this chapter.
9This approach is also closely related to Prim’s and Dijkstra’s algorithms, as well as the Bellman-Ford algorithm (see Chapters 7 and 9).
10Actually, for the longest increasing subsequence problem, we’re looking for the longest of all the paths, rather just the longest between any two given points.
11This devilishly clever little algorithm was first was first described by Michael L. Fredman in 1975.
12Using Skywalker here gives the slightly less interesting LCS Sar.
13Normally, of course, induction works on only one integer variable, such as problem size. The technique can easily be extended to multiple variables, though, where the induction hypothesis applies wherever at least one of the variables is smaller.
14You could preallocate the list, with m = [0]*(c+1), if you prefer, and then use m[r] = val instead of the append.
15The object index i = k-1 is just a convenience. We might just as well write m(k,r) = v[k-1] + m(k-1,r-w[k-1]).
16If parsing is completely foreign to you, feel free to skip this bullet point. Or perhaps look into it?
17You can find more information about optimal search trees both in Section 15.5 in Introduction to Algorithms by Cormen et al., and in Section 6.2.2 of The Art of Computer Programming, volume 3, “Sorting and Searching,” by Donald E. Knuth (see the “References” section of Chapter 1).
18You could certainly design some sort of cost function so this wasn’t the case, but then we couldn’t use dynamic programming (or, indeed, recursive decomposition) anymore. The induction wouldn’t work.
19You should have a whack at the matrix chains yourself (Exercise 8-18), and perhaps even the parsing, if you’re so inclined.
20www-igm.univ-mlv.fr/~lecroq/seqcomp