Table of Contents for
Seven Databases in Seven Weeks, 2nd Edition
 Seven Databases in Seven Weeks, 2nd Edition
Published by
Pragmatic Bookshelf, 2018
Seven Databases in Seven Weeks, 2nd Edition
Published by
Pragmatic Bookshelf, 2018
- Title Page
- Seven Databases in Seven Weeks, Second Edition
- Seven Databases in Seven Weeks, Second Edition
- Seven Databases in Seven Weeks, Second Edition
- Seven Databases in Seven Weeks, Second Edition
- Acknowledgments
- Preface
- Why a NoSQL Book
- Why Seven Databases
- What’s in This Book
- What This Book Is Not
- Code Examples and Conventions
- Credits
- Online Resources
- 1. Introduction
- It Starts with a Question
- The Genres
- Onward and Upward
- 2. PostgreSQL
- That’s Post-greS-Q-L
- Day 1: Relations, CRUD, and Joins
- Day 2: Advanced Queries, Code, and Rules
- Day 3: Full Text and Multidimensions
- Wrap-Up
- 3. HBase
- Introducing HBase
- Day 1: CRUD and Table Administration
- Day 2: Working with Big Data
- Day 3: Taking It to the Cloud
- Wrap-Up
- 4. MongoDB
- Hu(mongo)us
- Day 1: CRUD and Nesting
- Day 2: Indexing, Aggregating, Mapreduce
- Day 3: Replica Sets, Sharding, GeoSpatial, and GridFS
- Wrap-Up
- 5. CouchDB
- Relaxing on the Couch
- Day 1: CRUD, Fauxton, and cURL Redux
- Day 2: Creating and Querying Views
- Day 3: Advanced Views, Changes API, and Replicating Data
- Wrap-Up
- 6. Neo4J
- Neo4j Is Whiteboard Friendly
- Day 1: Graphs, Cypher, and CRUD
- Day 2: REST, Indexes, and Algorithms
- Day 3: Distributed High Availability
- Wrap-Up
- 7. DynamoDB
- DynamoDB: The “Big Easy” of NoSQL
- Day 1: Let’s Go Shopping!
- Day 2: Building a Streaming Data Pipeline
- Day 3: Building an “Internet of Things” System Around DynamoDB
- Wrap-Up
- 8. Redis
- Data Structure Server Store
- Day 1: CRUD and Datatypes
- Day 2: Advanced Usage, Distribution
- Day 3: Playing with Other Databases
- Wrap-Up
- 9. Wrapping Up
- Genres Redux
- Making a Choice
- Where Do We Go from Here?
- A1. Database Overview Tables
- A2. The CAP Theorem
- Eventual Consistency
- CAP in the Wild
- The Latency Trade-Off
- Bibliography
- Seven Databases in Seven Weeks, Second Edition
Neo4j Is Whiteboard Friendly
Imagine you need to create a wine suggestion engine in which wines are categorized by different varieties, regions, wineries, vintages, and designations. Imagine that you also need to keep track of things like articles describing those wines written by various authors and to enable users to track their favorite wines.
If you were using a relational model, you might create a category table and a many-to-many relationship between a single winery’s wine and some combination of categories and other data. But this isn’t quite how humans mentally model data. In the following figure, compare this wine suggestion schema in relational UML:
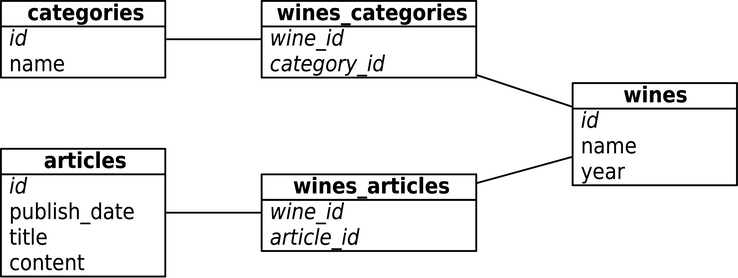
to this wine suggestion data on a whiteboard:
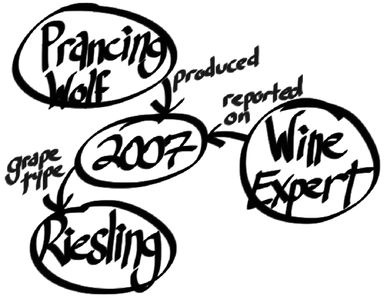
There’s an old saying in the relational database world: on a long enough timeline, all fields become optional. Neo4j handles this implicitly by providing values and structure only where necessary. If a wine blend has no vintage, add a bottle year and point the vintages to the blend node instead. In graph databases such as Neo4j there is simply no schema to adjust.
Over the next three days you’ll learn how to interact with Neo4j through a web console, using a querying language called Cypher, then via a REST interface, and finally through search indexes. You’ll work with some simple graphs as well as some larger graphs with graph algorithms. Finally, on Day 3, you’ll take a peek at the enterprise tools that Neo4j provides for mission-critical applications, from full ACID-compliant transactions to high-availability clustering and incremental backups.
In this chapter, we’ll use the Neo4j 3.1.4 Enterprise Edition. Most of the actions you perform on Days 1 and 2 can actually use the GPL Community edition, but we’ll require some enterprise functionality for Day 3: Distributed High Availability. You can download a free trial version of the Enterprise Edition from the Neo4j website.