Table of Contents for
Seven Databases in Seven Weeks, 2nd Edition
 Seven Databases in Seven Weeks, 2nd Edition
Published by
Pragmatic Bookshelf, 2018
Seven Databases in Seven Weeks, 2nd Edition
Published by
Pragmatic Bookshelf, 2018
- Title Page
- Seven Databases in Seven Weeks, Second Edition
- Seven Databases in Seven Weeks, Second Edition
- Seven Databases in Seven Weeks, Second Edition
- Seven Databases in Seven Weeks, Second Edition
- Acknowledgments
- Preface
- Why a NoSQL Book
- Why Seven Databases
- What’s in This Book
- What This Book Is Not
- Code Examples and Conventions
- Credits
- Online Resources
- 1. Introduction
- It Starts with a Question
- The Genres
- Onward and Upward
- 2. PostgreSQL
- That’s Post-greS-Q-L
- Day 1: Relations, CRUD, and Joins
- Day 2: Advanced Queries, Code, and Rules
- Day 3: Full Text and Multidimensions
- Wrap-Up
- 3. HBase
- Introducing HBase
- Day 1: CRUD and Table Administration
- Day 2: Working with Big Data
- Day 3: Taking It to the Cloud
- Wrap-Up
- 4. MongoDB
- Hu(mongo)us
- Day 1: CRUD and Nesting
- Day 2: Indexing, Aggregating, Mapreduce
- Day 3: Replica Sets, Sharding, GeoSpatial, and GridFS
- Wrap-Up
- 5. CouchDB
- Relaxing on the Couch
- Day 1: CRUD, Fauxton, and cURL Redux
- Day 2: Creating and Querying Views
- Day 3: Advanced Views, Changes API, and Replicating Data
- Wrap-Up
- 6. Neo4J
- Neo4j Is Whiteboard Friendly
- Day 1: Graphs, Cypher, and CRUD
- Day 2: REST, Indexes, and Algorithms
- Day 3: Distributed High Availability
- Wrap-Up
- 7. DynamoDB
- DynamoDB: The “Big Easy” of NoSQL
- Day 1: Let’s Go Shopping!
- Day 2: Building a Streaming Data Pipeline
- Day 3: Building an “Internet of Things” System Around DynamoDB
- Wrap-Up
- 8. Redis
- Data Structure Server Store
- Day 1: CRUD and Datatypes
- Day 2: Advanced Usage, Distribution
- Day 3: Playing with Other Databases
- Wrap-Up
- 9. Wrapping Up
- Genres Redux
- Making a Choice
- Where Do We Go from Here?
- A1. Database Overview Tables
- A2. The CAP Theorem
- Eventual Consistency
- CAP in the Wild
- The Latency Trade-Off
- Bibliography
- Seven Databases in Seven Weeks, Second Edition
Hu(mongo)us
Mongo hits a sweet spot between the powerful queryability of a relational database and the distributed nature of other databases, like HBase. Project founder Dwight Merriman has said that MongoDB is the database he wishes he’d had at DoubleClick, where as the CTO he had to house large-scale data while still being able to satisfy ad hoc queries.
Mongo is a JSON document database (though technically data is stored in a binary form of JSON known as BSON). A Mongo document can be likened to a relational table row without a schema, whose values can nest to an arbitrary depth. To get an idea of what a JSON document is, check this out:
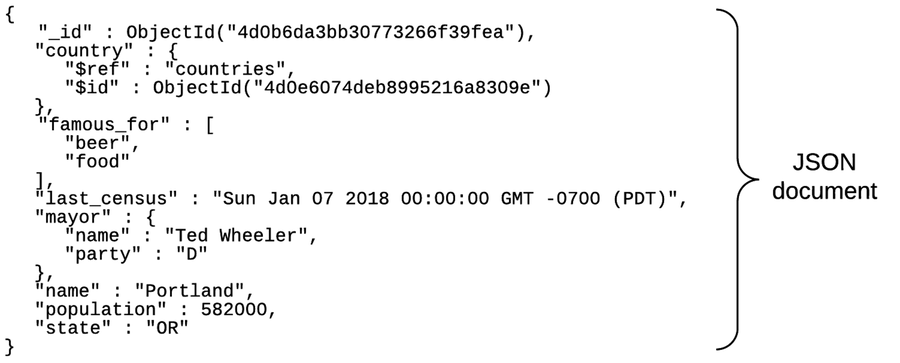
In some ways, document databases have an opposite workflow compared to relational databases. Relational databases such as PostgreSQL assume you know what data you wish to store without necessarily knowing how you want to use it; what’s important is how you store it. The cost of query flexibility is paid upfront on storage. Document databases require you to make some assumptions on how you wish to use your data, but few assumptions on what exactly you wish to store. You can make fundamental “schema” changes on-the-fly, but you may have to pay for your design decisions later on.
Mongo is an excellent choice for an ever-growing class of web projects with large-scale data storage requirements but very little budget to buy big-iron hardware. Thanks to its lack of structured schema, Mongo can grow and change along with your data model. If you’re in a web startup with dreams of enormity or are already large with the need to scale servers horizontally, consider MongoDB.

I was on the fence about using a document database until I actually spent time on teams using document stores in production. Coming from the relational database world, I found Mongo to be an easy transition with its ad hoc queries, and its ability to scale out mirrored my own web-scale dreams in ways that many relational stores couldn’t. But beyond the structure, I trusted Mongo’s development team. They readily admitted that Mongo wasn’t perfect, but their clear plans (and general adherence to those plans) were based on general web infrastructure use cases, rather than idyllic debates on scalability and replication. This pragmatic focus on usability should shine as you use MongoDB. A trade-off of this evolutionary behavior is that there are several paths to performing any given function in Mongo.