Table of Contents for
Graph Algorithms
 Graph Algorithms
Published by
O'Reilly Media, Inc., 2019
Graph Algorithms
Published by
O'Reilly Media, Inc., 2019
- Cover
- nav
- Graph Algorithms
- Graph Algorithms
- Preface
- 1. Introduction
- 2. Graph Theory and Concepts
- 3. Graph Platforms and Processing
- 4. Pathfinding and Graph Search Algorithms
- 5. Centrality Algorithms
- 6. Community Detection Algorithms
- 7. Graph Algorithms in Practice
- 8. Using Graph Algorithms to Enhance Machine Learning
- About the Authors
Chapter 3. Graph Platforms and Processing
In this chapter, we’ll quickly cover different methods for graph processing and the most common platform approaches. We’ll look closer at the two platforms, Apache Spark and Neo4j, used in this book and when they may be appropriate for different requirements. Platform installation guidelines are included to prepare us for the next several chapters.
Graph Platform and Processing Considerations
Graph analytical processing has unique qualities such as computation that is structure-driven, globally focused, and difficult to parse. In this section we’ll look at the general considerations for graph platforms and processing.
Platform Considerations
There’s a debate as to whether it’s better to scale up or scale out graph processing. Should you use powerful multicore, large-memory machines and focus on efficient data-structures and multithreaded algorithms? Or are investments in distributed processing frameworks and related algorithms worthwhile?
A useful approach is the Configuration that Outperforms a Single Thread (COST) as described in the research paper, “Scalability! But at what COST?”1. The concept is that a well configured system using an optimized algorithm and data-structure can outperform current general-purpose scale-out solutions. COST provides us with a way to compare a system’s scalability with the overhead the system introduces. It’s a method for measuring performance gains without rewarding systems that mask inefficiencies through parallelization. Separating the ideas of scalability and efficient use of resources will help build a platform configured explicitly for our needs.
Some approaches to graph platforms include highly integrated solutions that optimize algorithms, processing, and memory retrieval to work in tighter coordination.
Processing Considerations
There are different approaches for expressing data processing; for example, stream or batch processing or the map-reduce paradigm for records-based data. However, for graph data, there also exist approaches which incorporate the data-dependencies inherent in graph structures into their processing.
-
A node-centric approach uses nodes as processing units having them accumulate and compute state and communicate state changes via messages to their neighbors. This model uses the provided transformation functions for more straightforward implementations of each algorithm.
-
A relationship-centric approach has similiarities with the node-centric model but may perform better for subgraph and sequential analysis.
-
Graph-centric models process nodes within a subgraph independently of other subgraphs while (mimimal) communication to other subgraphs happens via messaging.
-
Traversal-centric models use the accumulation of data by the traverser while navigating the graph as their means of computation.
-
Algorithm-centric approaches use various methods to optimize implementations per algorithm. This is a hybrid of previous models.
Most of these graph specific approaches require the presence of the entire graph for efficient cross-topological operations. This is because separating and distributing the graph data leads to extensive data transfers and reshuffling between worker instances. This can be difficult for the many algorithms that need to iteratively process the global graph structure.
Representative Platforms
To address the requirements of graph processing several platforms have emerged. Traditionally there was a separation between graph compute engines and graph databases, that required users to move their data depending on their process needs.
Graph compute engines are read-only, non-transactional engines that focus on efficient execution of iterative graph analytics and queries of the whole graph. Graph compute engines support different definition and processing paradigms for graph algorithms, like vertex-centric (Pregel, Gather-Apply-Scatter) or map-reduce based approaches (PACT). Examples of such engines are Giraph, GraphLab, Graph-Engine, and Apache Spark.
Graph databases come from a transactional background focussing on fast writes and reads using smaller queries that generally touch only a small fraction of a graph. Their strengths are in operational robustness and high concurrent scalability for many users.
Selecting Our Platform
Choosing a production platform has many considersations such as the type of analysis to be run, performance needs, the existing environment, and team preferences. We use Apache Spark and Neo4j to showcase graph algorithms in this book because they both offer unique advantages.
Spark is an example of scale-out and node-centric graph compute engine. Its popular computing framework and libraries suppport a variety of data science workflows. Spark may be the right platform when our:
-
Algorithms are fundamentally parallelizable or partitionable.
-
Algorithm workflows needs “multi-lingual” operations in multiple tools and languages.
-
Analysis can be run off-line in batch mode.
-
Graph analysis is on data not transformed into a graph format.
-
Team has the expertise to code and implement new algorithms.
-
Team uses graph algorithms infrequently.
-
Team prefers to keep all data and analysis within the Hadoop ecosystem.
The Neo4j Graph Platform is an example of a tightly integrated graph database and algorithm-centric processing, optimized for graphs. Its popular for building graph-based applications and includes a graph algorithms library tuned for the native graph database. Neo4j may be the right platform when our:
-
Algorithms are more iterative and require good memory locality.
-
Algorithms and results are performance sensitive.
-
Graph analysis is on complex graph data and / or requires deep path traversal.
-
Analysis / Results are tightly integrated with transactional workloads.
-
Results are used to enrich an existing graph.
-
Team needs to integrate with graph-based visualization tools.
-
Team prefers prepackaged and supported algorithms.
Finally, some organizations select both Neo4j and Spark for graph processing. Using Spark for the high-level filtering and pre-processing of massive datasets and data integration and then the leveraging Neo4j for more specific processing and integration with graph-based applications.
Apache Spark
Apache Spark (henceforth just Spark) is a analytics engine for large-scale data processing. It uses a table abstraction called a DataFrame to represent and process data in rows of named and typed columns. The platform integrates diverse data sources and supports several languages such as Scala, Python, and R.
Spark supports a variety of analytics libraries as shown in Figure 3-1. It’s memory-based system uses efficiently distributed compute graphs for it’s operations.
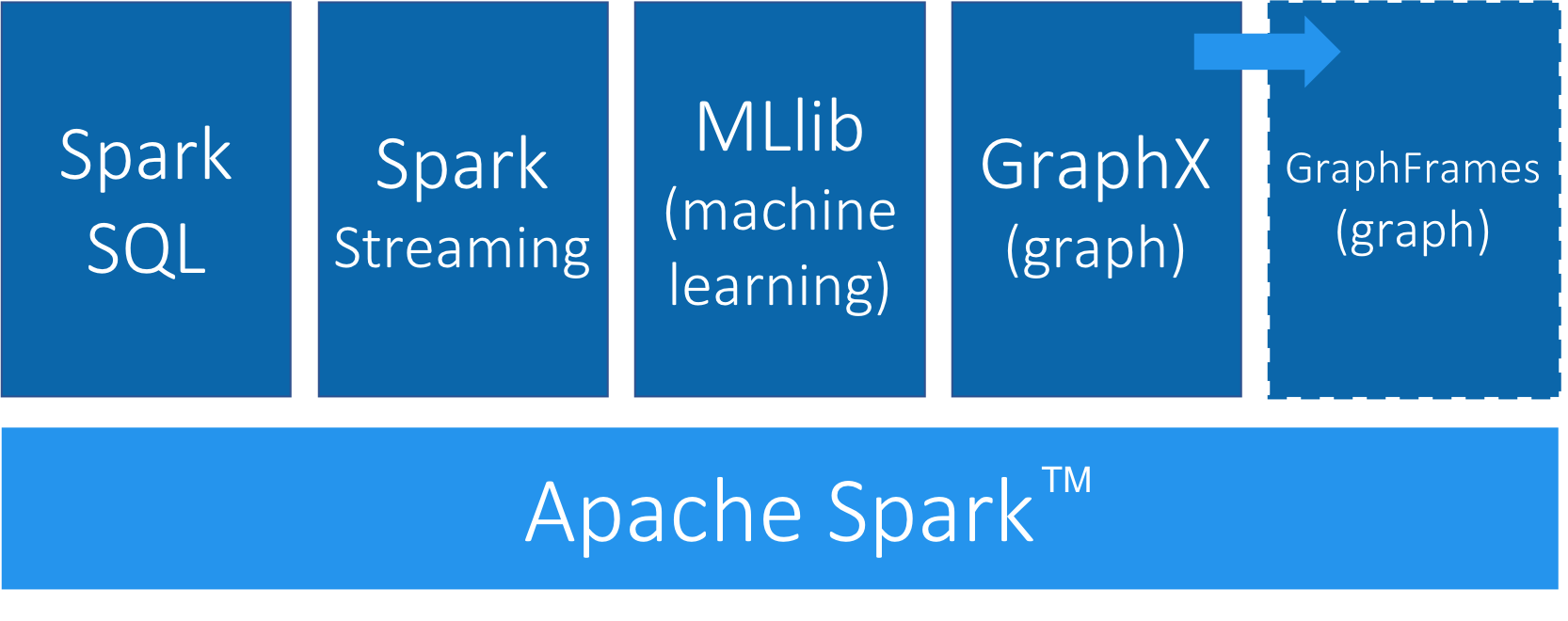
Figure 3-1. Apache Spark is an open-source distributed and general purpose cluster-computing framework. It includes several modules for various workloads.
GraphFrames is a graph processing library for Spark that succeeded GraphX in 2016, although it is still separate from the core Apache Spark. GraphFrames is based on GraphX, but uses DataFrames as its underlying data structure. GraphFrames has support for the Java, Scala, and Python programming languages. In this book our examples will be based on the Python API (PySpark).
Nodes and relationships are represented as DataFrames with a unique ID for each node and a source and destination node for each relationship.
We can see an example of a nodes DataFrame in Table 3-1 and a relationships DataFrame in Table 3-2.
A GraphFrame based on these DataFrames would have two nodes: JFK and SEA, and one relationship from JFK to SEA.
| id | city | state |
|---|---|---|
JFK |
New York |
NY |
SEA |
Seattle |
WA |
| src | dst | delay | tripId |
|---|---|---|---|
JFK |
SEA |
45 |
1058923 |
The nodes DataFrame must have an id column-the value in this column is used to uniquely identify that node.
The relationships DataFrame must have src and dst columns-the values in these columns describe which nodes are connected and should refer to entries that appear in the id column of the nodes DataFrame.
The nodes and relationships DataFrames can be loaded using any of the DataFrame data sources3, including Parquet, JSON, and CSV. Queries are described using a combination of the PySpark API and Spark SQL.
GraphFrames also provides users with an extension point4 to implement algorithms that aren’t available out of the box.
Installing Spark
We can download Spark from the Apache Spark website5. Once we’ve downloaded Spark we need to install the following libraries to execute Spark jobs from Python:
pip install pyspark
pip install git+https://github.com/munro/graphframes.git@release-0.5.0#egg=graphframes
Once we’ve done that we can launch the pyspark REPL by executing the following command:
exportSPARK_VERSION="spark-2.4.0-bin-hadoop2.7"./${SPARK_VERSION}/bin/pyspark\--driver-memory 2g\--executor-memory 6g\--packages graphframes:graphframes:0.5.0-spark2.1-s_2.11
At the time of writing the latest released version of Spark is spark-2.4.0-bin-hadoop2.7 but that may have changed by the time you read this so be sure to change the SPARK_VERSION environment variable appropriately.
We’re now ready to learn how to run graph algorithms on Spark.
Neo4j Graph Platform
The Neo4j Graph Platform provides transactional processing and analytical processing of graph data. It includes graph storage and compute with data management and analytics tooling. The set of integrated tools sits on top of a common protocol, API, and query language (Cypher) to provide effective access for different uses as shown in Figure 3-2.
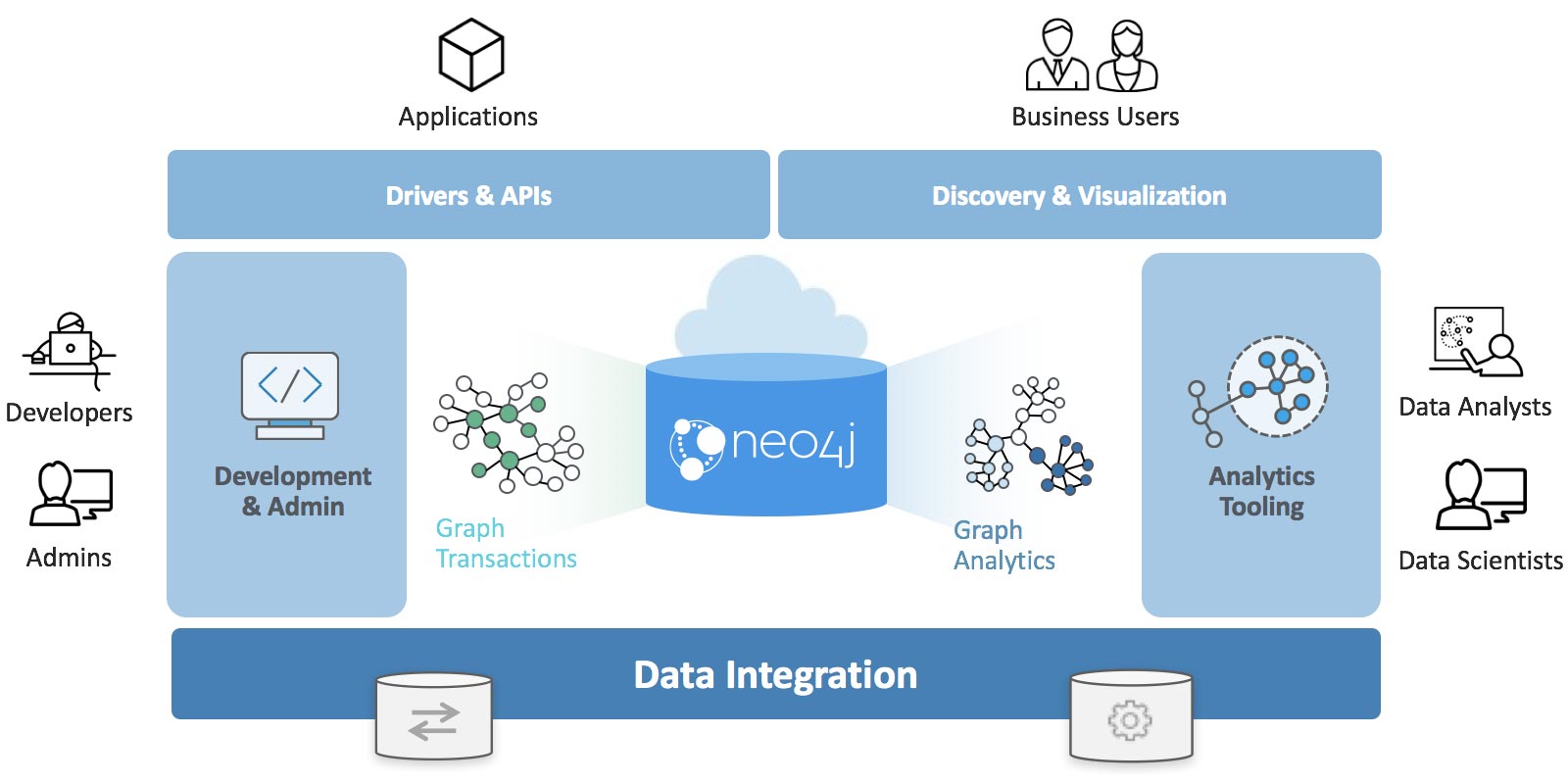
Figure 3-2. The Neo4j Graph Platform is built around a native graph database that supports transactional applications and graph analytics.
In this book we’ll be using the Neo4j Graph Algorithms library7, which was released in July 2017. The library can be installed as a plugin alongside the database, and provides a set of user defined procedures8 that can be executed via the Cypher query language.
The graph algorithm library includes parallel versions of algorithms supporting graph-analytics and machine-learning workflows. The algorithms are executed on top of a task based parallel computation framework and are optimized for the Neo4j platform. For different graph sizes there are internal implementations that scale up to tens of billions of nodes and relationships.
Results can be streamed to the client as a tuples stream and tabular results can be used as a driving table for further processing. Results can also be optionally written back to the database efficiently as node-properties or relationship types.
Note
In this book, we’ll also be using the Neo4j APOC (Awesome Procedures On Cypher) library 9. APOC consists of more than 450 procedures and functions to help with common tasks such as data integration, data conversion, and model refactoring.
Installing Neo4j
We can download the Neo4j desktop from the Neo4j website10. The Graph Algorithms and APOC libraries can be installed as plugins once we’ve installed and launched the Neo4j desktop.
Once we’ve created a project we need to select it on the left menu and click Manage on the database where we want to install the plugins.
Under the Plugins tab we’ll see options for several plugins and we need to click the Install button for Graph Algorithms and APOC.
See Figure 3-3 and Figure 3-4.
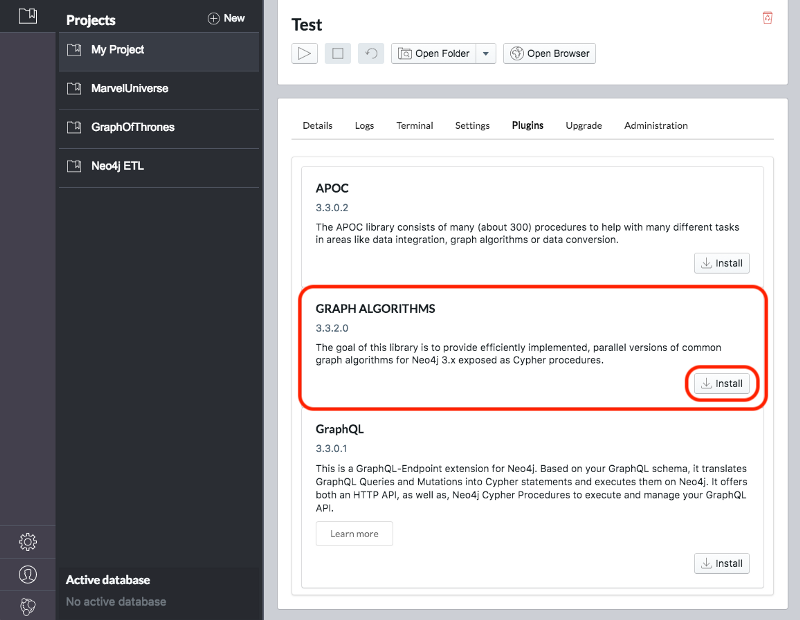
Figure 3-3. Installing Graph Algorithms
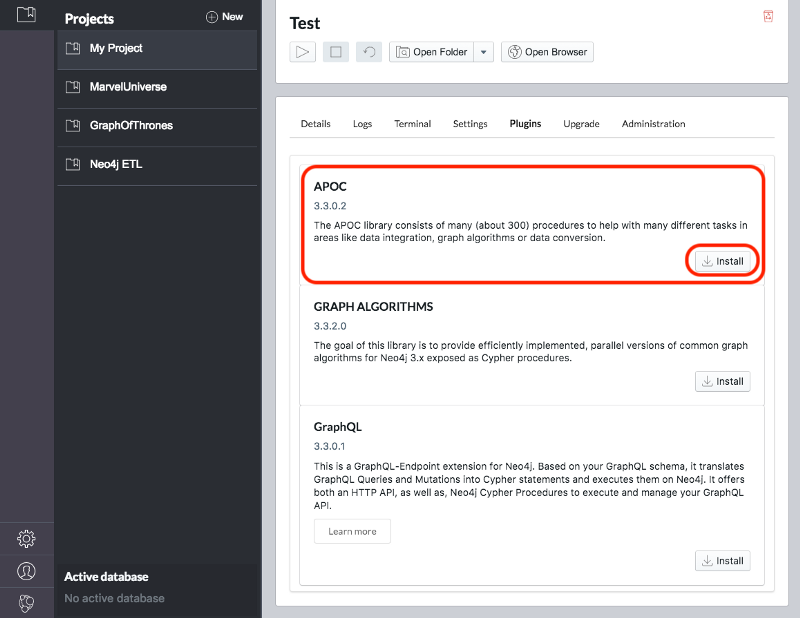
Figure 3-4. Installing APOC
Jennifer Reif explains the installation process in more detail in her blog post “Explore New Worlds—Adding Plugins to Neo4j” 11. We’re now ready to learn how to run graph algorithms on Neo4j.
Summary
The last few chapters we’ve described why graph analytics is important to studying real-work networks and looked at fundamental graph concepts, processing, and analysis. This puts us on solid footing for understanding how to apply graph algorithms. In the next chapters we’ll discover how to run graph algorithms with examples in Apache Spark and Neo4j.
1 https://www.usenix.org/system/files/conference/hotos15/hotos15-paper-mcsherry.pdf
2 https://kowshik.github.io/JPregel/pregel_paper.pdf
3 http://spark.apache.org/docs/latest/sql-programming-guide.html#data-sources
4 https://graphframes.github.io/user-guide.html#message-passing-via-aggregatemessages
5 http://spark.apache.org/downloads.html
6 http://shop.oreilly.com/product/0636920034957.do
7 https://neo4j.com/docs/graph-algorithms/current/
8 https://neo4j.com/docs/developer-manual/current/extending-neo4j/procedures/
9 https://github.com/neo4j-contrib/neo4j-apoc-procedures
10 https://neo4j.com/download/
11 https://medium.com/neo4j/explore-new-worlds-adding-plugins-to-neo4j-26e6a8e5d37e