Table of Contents for
Mastering Regular Expressions, 3rd Edition
 Mastering Regular Expressions, 3rd Edition
Published by
O'Reilly Media, Inc., 2006
Mastering Regular Expressions, 3rd Edition
Published by
O'Reilly Media, Inc., 2006
- Cover Page
- Programming
- Mastering Regular Expressions
- Title Page
- Copyright Page
- Dedication
- Table of Contents
- Preface
- 1: Introduction to Regular Expressions
- 2: Extended Introductory Examples
- 3: Overview of Regular Expression Features and Flavors
- 4: The Mechanics of Expression Processing
- 5: Practical Regex Techniques
- 6: Crafting an Efficient Expression
- 7: Perl
- Perl Efficiency Issues
- 8: Java
- 9: .NET
- 10: PHP
- Index
- Index
- About the Author
- Colophon
- Footnotes
Chapter 1
† If you have a TiVo, you already know the feeling!
† “Regular expressions are easy!” A somewhat humorous comment about this: as Chapter 3 explains, the term regular expression originally comes from formal algebra. When people ask me what my book is about, the answer “regular expressions” draws a blank face if they are not already familiar with the concept. The Japanese word for regular expression,  , means as little to the average Japanese as its English counterpart, but my reply in Japanese usually draws a bit more than a blank stare. You see, the “regular” part is unfortunately pronounced identically to a much more common word, a medical term for “reproductive organs.” You can only imagine what flashes through their minds until I explain!
, means as little to the average Japanese as its English counterpart, but my reply in Japanese usually draws a bit more than a blank stare. You see, the “regular” part is unfortunately pronounced identically to a much more common word, a medical term for “reproductive organs.” You can only imagine what flashes through their minds until I explain!
† The command shell is the part of the system that accepts your typed commands and actually executes the programs you request. With the shell I use, the single quotes serve to group the command argument, telling the shell not to pay too much attention to what’s inside. If I didn’t use them, the shell might think, for example, a ‘*’ that I intended to be part of the regular expression was really part of a filename pattern that it should interpret. I don’t want that to happen, so I use the quotes to “hide” the metacharacters from the shell. Windows users of COMMAND.COM or CMD.EXE should probably use double quotes instead.
† Once, in fourth grade, I was leading the spelling bee when I was asked to spell “miss.” My answer was “m·i·s·s.” Miss Smith relished in telling me that no, it was “M·i·s·s” with a capital M, that I should have asked for an example sentence, and that I was out. It was a traumatic moment in a young boy’s life. After that, I never liked Miss Smith, and have since been a very poor speler.
† Recall from the typographical conventions on page xxii that “• ” is how I sometimes show a space character so it can be seen easily.
† Recall from the typographical conventions (page xxii) that something like “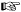 15” is a shorthand for a reference to another page of this book.
15” is a shorthand for a reference to another page of this book.
† If you are not familiar with HTML, never fear. I use these as real-world examples, but I provide all the details needed to understand the points being made. Those familiar with parsing HTML tags will likely recognize important considerations I don’t address at this point in the book.
† Be aware that some versions of egrep, including older versions of popular GNU offering, have a bug with the -i option such that it doesn’t apply to backreferences. Thus, it finds “the the” but not “The the.”
† Most programming languages and tools allow you to escape characters within a character class as well, but most versions of egrep do not, instead treating ‘\’ within a class as a literal backslash to be included in the list of characters.
† You might also come across the decidedly unsightly “regexp.” I’m not sure how one would pronounce that, but those with a lisp might find it a bit easier.
† The definitive book on multiple-byte encodings is Ken Lunde’s CJKV Information Processing, also published by O’Reilly. The CJKV stands for Chinese, Japanese, Korean, and Vietnamese, which are languages that tend to requir e multiple-byte encodings. Ken and Adobe kindly provided many of the special fonts used in this book.
Chapter 2
† Pascal is a traditional programming language originally designed for teaching. Thanks to William F. Maton, and his professor, for the analogy.
† In many situations, the m is optional. This example can also appear as $reply =" /^[0-9]+$/, which some readers with past Perl experience may find to be more natural. Personally, I feel the m is descriptive, so I tend to use it.
† I use the word “string” instead of “line” because, although it’s not really an issue with this particular example, regular expressions can be applied to a string that contains a multiline chunk of text. The caret and dollar anchors (normally) match only at the start and end of the string as a whole (we’ll see a counter example later in this chapter). In any case, the distinction is not vital here because, due to the nature of our algorithm, we know that $line never has more than one logical line.
† In Perl regular expressions and double-quoted strings, most ‘@’ must be escaped ( 77).
† Actually, ⌈$⌋ is often a bit more complex than simply “end of string,” although that’s not important to us for this example. For details, see the discussion of end-of-line anchors on page 129.
† The default variable is $_ (yes, that’s a variable too). It’s used as the default operand for many functions and operators.
‡ This logic assumes that the input file doesn’t have an ASCII escape character itself. If it did, this program could report lines in error.
Chapter 3
† “A logical calculus of the ideas imminent in nervous activity,” first published in Bulletin of Math. Biophysics 5 (1943) and later reprinted in Embodiments of Mind (MIT Press, 1965). The article begins with an interesting summary of how neurons behave (did you know that intra-neuron impulse speeds can range from 1 all the way to 150 meters per second?), and then descends into a pit of formulae that is, literally, all Greek to me.
‡ Robert L. Constable, “The Role of Finite Automata in the Development of Modern Computing Theory,” in The Kleene Symposium, Eds. Barwise, Keisler, and Kunen (North-Holland Publishing Company, 1980), 61–83.
§ Communications of the ACM, Vol.11, No. 6, June 1968.
† Historical trivia: ed (and hence grep) used escaped parentheses rather than unadorned parentheses as delimiters because Ken Thompson felt regular expressions would be used to work primarily with C code, where needing to match raw parentheses would be more common than backreferencing.
† Such as when writing a book about regular expressions—ask me, I know!
† James Gosling would later go on to develop his own language, Java, which includes a standard regular-expressions library as of Version 1.4. Java is covered in depth in Chapter 8.
† My claim to fame is that Larry added the /x modifier after seeing a note from me discussing a long and complex regex. In the note, I had “pretty printed” the regular expression for clarity Upon seeing it, he thought that it would be convenient to do so in Perl code as well, so he added /x.
† PCRE is available for free at ftp://ftp.csx.cam.ac.uk/pub/software/programming/pcre/
† As Ken Thompson (ed’s author) explained it to me, it kept ⌈.* from becoming “too unwieldy.”
† Tcl normally lets its dot match everything, so in one sense it’s more straightforward than other languages. In Tcl regular expressions, newlines are not normally treated specially in any way (neither to dot nor to the line anchors), but by using match modes, they become special. However, since other systems have always done it another way, Tcl could be considered confusing to those used to those other ways.
† If the tool itself is written in C or C++, and converts its regex backslash escapes into C backslash escapes, the resulting value is dependent upon the compiler. In practice, compilers for any particular platform are standardized around newline support, so it’s safe to view these as operating-system dependent. Furthermore, only \n and \r tend to vary across operating systems (and less so as time goes on), so the others can be considered standard across all systems.
† As we’ll see (and is illustrated in the table on page 125), the whole Is/In prefix business is somewhat of a mess. Previous versions of Unicode recommend one thing, while early implementations often did another. During Perl 5.8’s development, I worked with the development group to simplify things for Perl. The rule in Perl now is simply “You don’t need to use ‘Is’ or ‘In’ unless you specifically want a Unicode Block ( 124), in which case you must prepend ‘In’.”
† Actually, in Perl, this particular example could probably be written simply as ⌈\p{Thai}⌋, since in Perl ⌈\p{Thai}⌋ is a script, which never contains unassigned code points. Other differences between the Thai script and block are subtle. It’s beneficial to have the documentation as to what is actually covered by any particular script or block. In this case, the script is actually missing a few special characters that are in the block. See the data files at http://unicode.org for all the details.
‡ In general, this book uses “character class” and “POSIX bracket expression” as synonyms to refer to the entire construct, while “POSIX character class” refers to the special range-like class feature described here.
† The example works with Ruby, but note that Ruby’s (?i) has a bug whereby it sometimes doesn’t work with ⌈|⌋-separated alternatives that are lowercase (but does if they’re uppercase).
† To be pedantic, ⌈(this | that | )⌈ is logically comparable to ⌈( (? : this | that) ?)⌋. The minor difference from ⌈((this | that) ? is that a “nothingness match” is not within the parentheses, a subtle difference important to tools that differentiate between a match of nothing and non-participation in the match.
† In theory, what I say about {0, 0} is correct. In practice, what actually happens is even worse — it’s almost random! In many programs (including GNU awk, GNU grep, and older versions of Perl) it seems that {0,0} means the same as *, while in many others (including most versions of sed that I’ve seen, and some versions of grep) it means the same as ?. Crazy!
Chapter 4
† California has rather strict standards regulating the amount of pollution a car can produce. Because of this, many cars sold in America come in “California” and “non-California” models.
† Actually, as we saw in the previous chapter ( 128), a POSIX collating sequence can match multiple characters, but this is not common. Also, certain Unicode characters can match multiple characters when applied in a case-insensitive manner ( 110), although most implementations do not support this.
† This does not mean that there can’t be some mixing of technologies to try to get the best of both worlds. This is discussed in a sidebar on page 182.
† This example uses capturing as a forum for presenting greediness, so the example itself is appropriate only for NFAs (because only NFAs support capturing). The lessons on greediness, however, apply to all engines, including the non-capturing DFA.
† I suppose I could explain the underlying theory that goes into these names, if I only knew it! As I hinted, the word deterministic is pretty important, but for the most part the theory is not relevant, so long as we understand the practical effects. By the end of this chapter, we will.
† Just for comparison, remember that a DFA doesn’t care much about the form you use to express which matches are possible; the three examples are identical to a DFA.
† With a tool or mode where a dot can match a newline, ⌈.*⌋ applied to strings that contain multiline data matches through all the logical lines to the end of the whole string.
† A smart implementation may be able to make the possessive version a bit more efficient than its atomic-grouping counterpart ( 250).
† lex has trailing context, which is exactly the same thing as zero-width positive lookahead at the end of the regex, but it can’t be generalized and put to use for embedded lookahead.
Chapter 5
† Or maybe not — it depends on what you are used to. In a complex regex, I find ⌈\d⌋ more readable than ⌈[0-9]⌋, but note that on some systems, the two might not be exactly the same. Systems that support Unicode, for example, may have their ⌈\d⌋ match non-ASCII digits as well ( 120).
† The use of ⌈.*⌋ should set off warning alarms. Always pay particular attention to decide whether dot is really what you want to apply star to. Sometimes that is exactly what you need, but ⌈.*⌋ is often used inappropriately.
† The final code for processing the Microsoft style CSV files is presented in Chapter 6 ( 271) after the efficiency issues discussed in that chapter are taken into consideration.
Chapter 6
† The reported time is an estimation based on other benchmarks; I did not actually run the test that long.
† For readers into such things, the number of backtracks done on a string of length n is 2n+1. The number of individual tests is 2n+1+ 2n.
† Some implementations are not as efficient as others, but it’s safe to assume that a class is always faster than the equivalent alternation.
† Actually, in times past, I would use ⌈\b\B⌋ to force one part of a larger expression to fail, during testing. For example, I might insert it at the marked point of ⌈...(this⌋ to guaranteed failure of the first alternative. These days, when I need a “must fail” component, I use ⌈ |this other)...
|this other)...((?!)⌋. You can see an interesting Perl-specific example of this on page 333.
† It’s interesting to note that Perl had this over-optimization bug unnoticed for over 10 years until Perl developer Jeff Pinyan discovered (and fixed) it in early 2002. Apparently, regular expressions like ⌈(. + )X\1⌋ aren’t used often, or the bug would have been discovered sooner.
‡ I say eight characters rather than seven because in many flavors, ⌈$⌋ can match before a string-ending newline ( 129).
† You can see this in action for yourself. The module in question, DBlx::DWlw (available on CPAN), allows very easy access to a MySQL database. Jeremy Zawodny and I developed it at Yahoo!.
† In Perl, if $1 is not filled during the match, it’s given a special “no value” value “undef”. When used in the replacement value, undef is treated as an empty string, so it works as we want. But, if you have Perl warnings turned on (as every good programmer should), the use of an undef value in this way causes a warning to be printed. To avoid this, you can use the ‘no warnings;’ pragma before the regular expression is used, or use this special Perl form of the substitute operator:
Chapter 7
† This book covers features of Perl as of Version 5.8.8.
† That they’re innumerable doesn’t stop this chapter from trying to cover them all!
† Because modifiers can appear in any order, a large portion of a programmer’s time is spent adjusting the order to achieve maximum cuteness. For example, learn/by/osmosis is valid code (assuming you have a function called learn). The osmosis are the modifiers. Repeating modifiers is allowed, but meaningless (except for the substitution-operator’s /e modifier, discussed later).
† Perl doesn’t allow the use of my with this special variable name, so the comparison is only academic.
† Actually, if the original target is undefined, but the match successful (unlikely, but possible), "$'$&$'" would be an empty string, not undefined. This is the only situation where the two differ.
† This tab-replacement snippet has the limitation that it works only with “traditional” western text. It doesn’t produce correct results with wide characters like 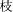 , which is one character but takes up two spaces, nor some Unicode renditions of accented characters like à ( 107).
, which is one character but takes up two spaces, nor some Unicode renditions of accented characters like à ( 107).
† This would work with most other flavors that support ⌈\G⌋, but even so, I would generally not recommend using it, as the optimization gains by having ⌈\G⌋ at the start of the regex usually outweigh the small gain by not testing ⌈\G⌋ an extra time ( 246).
† Actually, there is one side effect remaining from a feature that has been deprecated for many years, but has not actually been removed from the language yet. If split is used in a scalar or void context, it writes its results to the @_ variable (which is also the variable used to pass function arguments, so be careful not to use split in these contexts by accident). use warnings or the -w command-line argument warns you if split is used in either context.
† Normally, I recommend against using the special match variables $', $&, and $', as they can inflict a major efficiency penalty on the entire program ( 356), but they’re fine for temporary debugging.
Chapter 8
† This book covers Java 1.5.0 as of Update 7. The initial release of Java 1.5 had a severe bug related to case-insensitive matches. It was fixed in Update 2, so I recommend upgrading if you’re running a prior version. The Java 1.6 beta information is current as of the second beta release, build 59g.
† Especially when presenting code in a book with a limited page width—ask me, I know!
† Actually, java.util.regex is extremely flexible in that the “string” argument can be any object that implements the CharSequence interface (of which String, StringBuilder, StringBuffer, and CharBuffer are examples).
† The groupCount method can be called at any time, unlike the others in this section, which can be called only after a successful match attempt.
† The regex in the code is ⌈\b[\p{Lu}\p{Lt}]+\bj⌋ You’ll recall from Chapter 3 ( 123) that \p{Lu} matches the full range of Unicode uppercase letters, while \p{Lt} matches titlecase characters. The ASCII version of this regex is ⌈\b [A-Z] +\bj⌋.
† There’s an exception as of Java 1.5 Update 7 due to an obscure bug I’ve reported to Sun. A Pattern.MULTILINE version of ⌈^⌋, (which can be considered a looking construct in the context of a non-default region) can match at the start of the region if there’s a line terminator just before the start of the region, even though anchoring bounds have been turned off and opaque bounds are on.
† As this book goes to press, Sun tells me that this bug should be fixed in “5.0u9,” which means Java 1.5 Update 9. (You’ll recall from the footnote on page 365 that the version of Java 1.5 covered by this book is Update 7.) And again, it’s already fixed in the Java 1.6 beta.
† “All images must have size attributes!” was a mantra at Yahoo!, even in its early days. Remarkably, there are still plenty of major web sites today sending out high-traffic pages with sizeless <img> tags.
† The undocumented recursive construct ⌈(?1)⌋, unofficially available in Java 1.4.2, is no longer included as of Java 1.5.0. It’s similar to the same construct in PCRE ( 476), but being undocumented in Java, it is relegated here to a footnote.
Chapter 9
† This book covers .NET Framework Version 2.0 (which is shipped with “Visual Studio 2005”).
† ECMA stands for “European Computer Manufacturers Association,” a group formed in 1960 to standardize aspects of the growing field of computers.
Chapter 10
† While researching for this chapter with the versions of PHP and PCRE that were available at the time, I discovered a number of bugs that are now fixed in PHP 4.4.3 and 5.1.4, the versions covered by this book. Some of the examples in this chapter may not work with earlier versions.
† If you expect a NULL value instead of an empty string, see the sidebar on page 454.
† Apparently, the web is full of lazy programmers, as my brother’s “No Dashes Or Spaces” Hall of Shame sadly attests to. You can see it at http://www.unixwiz.net/ndos-shame.html.
† Strictly speaking, ⌈(?num )⌋ need not be a recursive reference, that is, the ⌈(?num )⌋ construct itself need not necessarily be part of the subexpression contained within the numth set of capturing parentheses. In such cases, the reference can be considered more of a “subroutine call.”
† Really, a very little extra time. For very long and complex regexes on an average CPU, the extra time taken by the S pattern modifier is less than a hundred-thousandths of a second.