Table of Contents for
Python for Secret Agents
 Python for Secret Agents
Published by
Packt Publishing, 2014
Python for Secret Agents
Published by
Packt Publishing, 2014
- Cover
- Table of Contents
- Python for Secret Agents
- Python for Secret Agents
- Credits
- About the Author
- About the Reviewers
- www.PacktPub.com
- Preface
- What you need for this book
- Who this book is for
- Conventions
- Reader feedback
- Customer support
- 1. Our Espionage Toolkit
- Getting more tools – a text editor
- Confirming our tools
- Background briefing – math and numbers
- Handling text and strings
- Organizing our software
- Working with files and folders
- Solving problems – recovering a lost password
- Summary
- 2. Acquiring Intelligence Data
- Using a REST API in Python
- Organizing collections of data
- Solving problems – currency conversion rates
- Summary
- 3. Encoding Secret Messages with Steganography
- Using the Pillow library
- Some approaches to steganography
- Detecting and preventing tampering
- Solving problems – encrypting a message
- Summary
- 4. Drops, Hideouts, Meetups, and Lairs
- Finding out where we are with geocoding services
- How close? What direction?
- Compressing data to make grid codes
- Decoding a GeoRef code
- Creating natural area codes
- Solving problems – closest good restaurant
- Summary
- 5. A Spymaster's More Sensitive Analyses
- Creating Python modules and applications
- Creating our own classes of objects
- Comparisons and correlations
- Writing high-quality software
- Solving problems – analyzing some interesting datasets
- Summary
- Index
Most of our previous espionage missions focused on bulk data collection and processing. HQ doesn't always want details. Sometimes it needs summaries and assessments. This means calculating central tendencies, summaries, trends, and correlations, which means we need to write more sophisticated algorithms.
We will skirt the borders of some very heavy-duty statistical algorithms. Once we cross the frontier, we will need more powerful tools. For additional tools to support sophisticated numeric processing, check http://www.numpy.org. For some analyses, we may be more successful using the SciPy package (http://www.scipy.org). A good book to refer is Learning SciPy for Numerical and Scientific Computing, Francisco J. Blanco-Silva, Packt Publishing (http://www.packtpub.com/learning-scipy-for-numerical-and-scientific-computing/book).
Another direction we could be pulled in includes the analysis of natural language documents. Reports, speeches, books, and articles are sometimes as important as basic facts and figures. If we want to work with words and language, we need to use the Natural Language Toolkit (NLTK). More information on this can be found at http://www.nltk.org.
In this chapter, we'll look at several more advanced topics that secret agents need to master, such as:
- Computing central tendency—mean, median, and mode—of the data we've gathered.
- Interrogating CSV files to extract information.
- More tips and techniques to use Python generator functions.
- Designing higher-level constructs such as Python modules, libraries, and applications.
- A quick introduction to class definitions.
- Computations of standard deviation, standardized scores, and the coefficient of correlation. This kind of analysis adds value to intelligence assets. Any secret agent can ferret out the raw data. It takes real skill to provide useful summaries.
- How to use doctest to assure that these more sophisticated algorithms really work. Presence of a software bug raises serious questions about the overall quality of the data being reported.
Being a secret agent isn't all car chases and confusing cocktail recipes in posh restaurants. Shaken? Stirred? Who can remember?
Sometimes, we need to tackle some rather complex analysis questions that HQ has assigned us. How can we work with per capita cheese consumption, accidental suffocation and strangulation in bed, and the number of doctorates in civil engineering? What Python components should we apply to this problem?
One essential kind of statistical summary is the measure of central tendency. There are several variations on this theme; mean, mode, and median, which are explained as follows:
- The mean, also known as the average, combines all of the values into a single value
- The median is the middlemost value—the data must be sorted to locate the one in the middle
- The mode is the most common value
None of these is perfect to describe a set of data. Data that is truly random can often be summarized by the mean. Data that isn't random, however, can be better summarized by the median. With continuous data, each value might differ slightly from another. Every measurement in a small set of samples may be unique, making a mode meaningless.
As a consequence, we'll need algorithms to compute all three of these essential summaries. First, we need some data to work with.
In Chapter 2, Acquiring Intelligence Data, HQ asked us to gather cheese consumption data. We used the URL http://www.ers.usda.gov/datafiles/Dairy_Data/chezcon_1_.xls.
Sadly, the data was in a format that we can't easily automate, forcing us to copy and paste the annual cheese consumption data. This is what we got. Hopefully, there aren't many errors introduced by copying and pasting. The following is the data that we gathered:
year_cheese = [(2000, 29.87), (2001, 30.12), (2002, 30.6), (2003, 30.66),
(2004, 31.33), (2005, 32.62), (2006, 32.73), (2007, 33.5),
(2008, 32.84), (2009, 33.02), (2010, 32.92), (2011, 33.27),
(2012, 33.51)]This will serve as a handy dataset that we can use.
Note that we can type this on multiple lines at the >>> prompt. Python needs to see a matching pair of [ and ] to consider the statement complete. The matching [] rule allows the users to enter long statements comfortably.
We've been given the cause of death using ICD code W75 as accidental suffocation and strangulation in bed. It's not perfectly clear what HQ thinks this data means. However, it has somehow become important. We went to the http://wonder.cdc.gov website to get the summary of cause of death by year.
We wound up with a file that starts out like this:
"Notes" "Cause of death" "Cause of death Code" "Year" "Year Code" Deaths Population Crude Rate "Accidental suffocation and strangulation in bed" "W75" "2000" "2000" 327 281421906 0.1 "Accidental suffocation and strangulation in bed" "W75" "2001" "2001" 456 284968955 0.2 … etc. …
This is a bit painful to process. It's almost—but not quite—in CSV notation. It's true that there aren't many commas, but there are tab characters encoded as \t in Python. These characters are sufficient to make a CSV file, where the tab takes the role of a comma.
We can read this file using Python's csv module with a \t delimiter:
import csv
with open( "Cause of Death by Year.txt" ) as source:
rdr= csv.DictReader( source, delimiter="\t" )
for row in rdr:
if row['Notes'] == "---": break
print(row)This snippet will create a csv.DictReader object using the \t delimiter instead of the default value of ,. Once we have a reader that uses \t characters, we can iterate through the rows in the document. Each row will appear as a dictionary. The column title, found in the first row, will be the key for the items in the dictionary.
We used the expression row['Notes'] to get the value from the Notes column of each row. If the notes are equal to ---, this is the beginning of the footnotes for the data. What follows is a great deal of metadata.
The resulting dataset can be summarized easily. First, we'll create a generator function to parse our data:
def deaths():
with open( "Cause of Death by Year.txt" ) as source:
rdr= csv.DictReader( source, delimiter="\t" )
for row in rdr:
if row['Notes'] == "Total": break
yield int(row['Year']), int(row['Deaths'])We replaced the print() function with the yield statement. We also replaced --- with Total to prune the totals off the data. We can compute our own totals. Finally, we converted the year and deaths to integer values so that we can calculate with them.
This function will iterate through the various rows of data producing two-tuples of the year and the number of deaths.
Once we have this generator function, we can collect the summary like this:
year_deaths = list( deaths() )
We get this as a result:
[(2000, 327), (2001, 456), (2002, 509), (2003, 497), (2004, 596), (2005, 573), (2006, 661), (2007, 741), (2008, 809), (2009, 717), (2010, 684)]
This seems to be the data they're looking for. It gives us more data to work with.
The mean is defined using a daunting formula which looks like 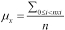 . While the formula looks complex, the various parts are first-class built-in functions of Python.
. While the formula looks complex, the various parts are first-class built-in functions of Python.
The big sigma 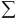 is math-speak for the Python
is math-speak for the Python sum() function.
Given a list of values, the mean is this:
def mean( values ):
return sum(values)/len(values)Our two sets of data are provided as two-tuples with year and amount. We need to reel in the years, stowing away the time for later use. We can use a simple generator function for this. We can use the expression cheese for year, cheese in year_cheese to separate the cheese portion of each two-tuple.
Here's what happens when we use a generator with our mean() function:
>>> mean( cheese for year, cheese in year_cheese ) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 2, in mean TypeError: object of type 'generator' has no len()
Wait. What?
How can the simple generator not work?
Actually, it does work. It just doesn't do what we assume.
There are three important rules that apply to Python generators:
- Many—but not all—functions will work with generator objects. Some functions, however, will not work well with generators; they require a sequence object.
- The objects yielded by a generator aren't created until absolutely necessary. We can describe a generator as being lazy. A list, for example, actually contains objects. A generator expression can operate similarly to a list, but the objects aren't really created until needed.
- Generator functions can only be used once. A list can be reused indefinitely.
The first restriction applies in particular to the len() function. This function works for lists, tuples, and sets. However, it doesn't work for generators. There's no way to know how many items will eventually be created by a generator, so len() can't return the size.
The second restriction is mostly relevant when we try to print the results of a generator. We'll see something such as <generator object <genexpr> at 0x1007b4460>, until we actually evaluate the generator and create the objects.
The third restriction is less obvious. We will to need an example. Let's try to work around the len() problem by defining a count() function that counts items yielded by a generator function:
def count( values ):
return sum( 1 for x in values )This will add up a sequence of 1s instead of the sequence of actual values.
We can test it like this:
>>> count( cheese for year, cheese in year_cheese ) 13
This seems to work, right? Based on this one experiment, we can try to rewrite the mean() function like this:
def mean2( values ):
return sum(values)/count(values)We used count(), which works with a generator expression, instead of len().
When we use it, we get a ZeroDivisionError: float division by zero error. Why didn't count() work in the context of mean()?
This reveals the one-use-only rule. The sum() function consumed the generator expression. When the time to evaluate the count() function came, there was no data left. The generator was empty, sum( 1 for x in [] ) was zero.
What can we do?
We have three choices, as follows:
- We can write our own more sophisticated
sum()that produces both sum and count from one pass through the generator. - Alternatively, we can use the
itertoolslibrary to put a tee fitting into the generator pipeline so that we have two copies of the iterable. This is actually a very efficient solution, but it's also a bit advanced for field agents. - More simply, we can create an actual list object from the generator. We can use the
list()function or wrap the generator expression in[].
The first two choices are too complex for our purposes. The third is really simple. We can use this:
>>> mean( [cheese for year, cheese in year_cheese] ) 32.076153846153844 >>> mean( [death for year, death in year_deaths] ) 597.2727272727273
By including [], we created a list object from the generator. We can get both sum() and len() from the list object. This approach works very nicely.
It points out the importance of writing docstrings in our functions. We really need to do this:
def mean(values):
"""Mean of a sequence (doesn't work with an iterable)"""
return sum(values)/len(values)We put a reminder here that the function works with an object that is a sequence, but it doesn't work with a generator expression or other objects that are merely iterable. When we use help(mean), we'll see the reminder we left in the docstring.
There's a hierarchy of concepts here. Being iterable is a very general feature of many kinds of Python objects. A sequence is one of many kinds of iterable Python objects.
The median value is in the middle of a sorted collection of values. In order to find the median, we need to sort the data.
Here's an easy function to compute the median of a sequence:
def median(values):
s = sorted(values)
if len(s) % 2 == 1: # Odd
return s[len(s)//2]
else:
mid= len(s)//2
return (s[mid-1]+s[mid])/2This includes the common technique of averaging the two middlemost values when there's an even number of samples.
We used len(s)%2 to determine if the sequence length is odd. In two separate places, we compute len(s)//2; seems like we might be able to simplify things using the divmod() function.
We can use this:
mid, odd = divmod(len(s), 2)
This change removes a little bit of the duplicated code that computes len(s)//2, but is it really more clear?
Two potential issues here are the overheads associated with sorting:
- First, sorting means a lot of comparisons between items. As the size of the list grows, the number of items compared grows more quickly. Also, the
sorted()function produces a copy of the sequence, potentially wasting memory when processing a very large list. - The alternative is a clever variation on the quickselect algorithm. For field agents, this level of sophistication isn't necessary. More information is available at http://en.wikipedia.org/wiki/Quickselect.
The modal value is the single most popular value in the collection. We can compute this using the Counter class in the collections module.
Here's a mode function:
from collections import Counter
def mode(values):
c = Counter( values )
mode_value, count = c.most_common(1)[0]
return mode_valueThe most_common() method of a Counter class returns a sequence of two-tuples. Each tuple has the value and the number of times it occurred. For our purposes, we only wanted the value, so we had to take the first element from the sequence of two-tuples. Then, we had to break the pair down into the value and the counter.
The problem with a demonstration is that our datasets are really small and don't have a proper mode. Here's a contrived example:
>>> mode( [1, 2, 3, 3, 4] ) 3
This demonstrates that the
mode function works, even though it doesn't make sense for our cheese consumption and death rate data.