Table of Contents for
Security for Web Developers
 Security for Web Developers
Published by
O'Reilly Media, Inc., 2015
Security for Web Developers
Published by
O'Reilly Media, Inc., 2015
- nav
- Cover
- Security for Web Developers
- Security for Web Developers
- Dedication
- Preface
- I. Developing a Security Plan
- 1. Defining the Application Environment
- 2. Embracing User Needs and Expectations
- 3. Getting Third-Party Assistance
- II. Applying Successful Coding Practices
- 4. Developing Successful Interfaces
- 5. Building Reliable Code
- 6. Incorporating Libraries
- 7. Using APIs with Care
- 8. Considering the Use of Microservices
- III. Creating Useful and Efficient Testing Strategies
- 9. Thinking Like a Hacker
- 10. Creating an API Safety Zone
- 11. Checking Libraries and APIs for Holes
- 12. Using Third-Party Testing
- IV. Implementing a Maintenance Cycle
- 13. Clearly Defining Upgrade Cycles
- 14. Considering Update Options
- 15. Considering the Need for Reports
- V. Locating Security Resources
- 16. Tracking Current Security Threats
- 17. Getting Required Training
- Index
- About the Author
- Colophon
Chapter 8. Considering the Use of Microservices
Microservices are a relatively new technology that breaks huge monolithic applications into small components. Each of these small components acts independently and performs just one task well. Because of the technologies that microservices rely on and the way in which they’re employed, microservices tend to provide better security than some of the other technologies described so far in the book. However, just like any other technology, microservices do present opportunities for hackers to cause problems. It’s important to remember that any technology has gaps that hackers will exploit to accomplish tasks. The goal of the developer is to minimize these gaps and then ensure as many safeguards as possible are in place to help in the monitoring process.
Because microservices are so new, the chapter begins by spending a little more than the usual time explaining them. This book doesn’t provide you with a complete look at microservices, but you should have enough information to understand the security implications of using microservices, rather than older technologies you used in the past. In addition, it’s important to consider the role that people will play in this case. A hostile attitude toward microservice deployment can actually cause security issues that you need to consider during the development stage.
The chapter discusses how you might create a microservice of your own (but doesn’t actually provide source code because this is a book about security and not about writing microservices). The example focuses on a combination of Node.js and Seneca to create a simple microservice, and then access that microservice from a page. The point of the example is to discuss how microservices work so that you can better understand the security information that follows in the next section. The reason for using the combination of Node.js and Seneca is that these applications run on the Mac, Windows, and Linux platforms. Other microservice products, such as Docker, only run on Linux systems at present.
The chapter finishes by reviewing the importance of having multiple paths for microservice access. One of the advantages of using microservices is that you can employ multiple copies of the same microservice to reduce the risk of an application failing. In short, microservices can be both more secure and more reliable than the monolithic applications they replace.
Note
The best way to work with the examples described in this chapter is to use the downloadable source, rather than type it in by hand. Using the downloadable source reduces potential errors. You can find the source code examples for this chapter in the \S4WD\Chapter08 folder of the downloadable source.
Defining Microservices
Applications that work on a single platform will eventually go away for most users. Yes, they’ll continue to exist for special needs, but the common applications that most users rely on every day won’t worry about platform, programming language requirements, or any of the other things that applications need to consider today. Microservices work well in today’s programming environment because they define a new way of looking at code. Instead of worrying how to create the code, where to put it, or what language to use, the developer instead thinks of just one task that the code needs to perform. That task might not necessarily even fit in the application at the moment—it may simply represent something interesting that the application may need to do when working with the data. In the new world of application development, applications will run anywhere at any time because of technologies such as microservices. The following sections provide you with a good overview of precisely what microservices are and why you should care about them.
Specifying Microservice Characteristics
Many developers are used to dealing with monolithic designs that rely heavily on object-oriented programming (OOP) techniques. Creating any application begins by defining all sorts of objects and considering all sorts of issues. Current application design techniques require a lot of up front time just to get started and they’re tied to specific platforms. Microservices are different. Instead of a huge chunk of code, you write extremely small pieces of code and make many decisions as you go along, rather than at the beginning of the process. Microservices have these characteristics:
- Small
- Each microservice performs just one task.
- Language independent
- Every microservice relies on the language that best suits the task it performs without any consideration for the needs of any other microservice.
- Data transfer independence
- Although most microservices currently rely on JavaScript Object Notation (JSON) to transfer data, you can use any method of data transfer that works best for the microservice.
- Queued messages
- Communication typically occurs using an asynchronous messaging system so that no one microservice can cause delays in the application as a whole.
- Dumb pipe
- A problem with many methods of communication today is that the intelligence resides in the pipe. Microservices rely on a dumb pipe and intelligent services. Most microservices rely on Representational State Transfer (REST) for communication purposes.
- Decentralized
- Each microservice is separate from every other microservice and from the application as a whole. A failure of one microservice typically won’t affect application operation. Each microservice receives separate monitoring.
- Platform independence
- Any application can make use of any microservice no matter what platform the application is running on and regardless of which platform the microservice uses.
You might wonder about the size of microservices—what performing just one task well really means. Think about a string for a second. When working with a monolithic application, you have a single object that can capitalize, reverse, and turn the string into a number. When working with a microservice, you create a single microservice to perform each task. For example, one microservice would capitalize the string, another reverse it, and still another turn it into a number. When you think about microservices, think focused and small.
From a developer perspective, microservices represent the ultimate in flexibility and modularity. It’s possible to work on a single function at a time without disturbing any other part of the configuration. In addition, because updates are so small, it’s not like an API where you have a huge investment in time and effort. When you make a mistake, correcting it is a much smaller problem.
Differentiating Microservices and Libraries
It’s important to realize that microservices don’t execute in-process like libraries do. A microservice executes on a server like an API. This means that you don’t have the security risks with microservices that you do with libraries. It’s possible to separate your application code from the microservice completely.
The calling syntax for a microservice also differs from a library in that you create a JSON request and send it to the server. The response is also in JSON format. The use of JSON makes it possible to work with data in a rich way without resorting to XML. Working with JSON is much easier than working with XML because JSON is native to JavaScript and it provides a more lightweight syntax. You see how this works later in the chapter. For now, just know that microservices work differently than library calls do for the most part.
From a security perspective, microservices tend to be safer than libraries because they don’t execute in-process and you can guard against most forms of errant data input using best practices approaches to working with JSON. Of course, hackers can thwart any effort to make things more secure and microservices are no exception.
Differentiating Microservices and APIs
APIs often require that you create an object and then execute calls against that object. Requests can take a number of forms such as REST, HTML request headers, or XML. Responses could involve direct manipulation of objects on the page (as in the case of the Google Maps API example shown in Chapter 7). The process is cumbersome because you’re working with a large chunk of monolithic code that could contain all sorts of inconsistencies.
Like APIs, microservices do execute out of process. However, unlike APIs, microservices aren’t huge chunks of monolithic code. Each microservice is small and could execute in its own process, making it possible to isolate one function from another with complete assurance. Data exchanges occur using just one approach, JSON, which is likely the best approach to use today because it’s simpler than working with XML.
Considering Microservice Politics
Now you know that microservices have a lot to offer the developer, IT in general, and the organization as a whole. Using microservices makes sense because the technology makes it possible to create applications that work on any device in any location without causing hardship on the developer. Unfortunately, monolithic application development scenarios tend to create fiefdoms where a hierarchy of managers rule their own particular set of resources. Because microservices are small, easily used for all sorts of purposes, and tend not to care about where needed data comes from, they break down the walls between organizational groups—upsetting the fiefdoms that ruled in the past. As in any situation of this sort, some level of fighting and even sabotage is bound to happen.
The sabotage part of the equation is what you need to consider as a developer. It’s unlikely that anyone will purposely spend time trying to kill a microservices project, but the subtle reluctance to get tasks done or to do them correctly can kill it just as easily. All organizations have a “we’ve never done it that way here before” attitude when it comes to new technologies—inertia has a role to play in every human endeavor, so it shouldn’t surprise you to find that you have to overcome inertia before you can start your first project.
From a security perspective, flaws induced in the project during this early stage leave openings that hackers are fully aware of and will almost certainly exploit if your organization becomes a target (or sometimes by pure random chance). With all this in mind, it often helps to follow a process when incorporating microservice strategies into your programming toolbox (you won’t always follow these steps in precisely the order listed, but they do help you overcome some of the reluctance involved in working with microservices):
-
Form a development team that is responsible for microservices development that’s separate from the team that currently maintains the monolithic application.
-
Create a few coarse-grained microservices for new application features to start.
-
Develop microservices that provide self-contained business features at the outset so that you don’t have to worry about interactions as much.
-
Provide enough time for existing teams to discover how to use microservices and begin incorporating them into existing applications. However, don’t move existing applications completely to microservices until you have enough successes so that everyone agrees that making the move is a good idea.
-
As development progresses with the initial microservices and you can see where changes need to be made, create finer-grained microservices to produce better results.
-
Standardize service templates so that it’s possible to create microservices with a minimum of chatter between groups. A standardized template also tends to reduce security issues because no one has to make any assumptions.
-
Create enough fine-grained microservices to develop a complete application, but don’t focus on the needs of an existing application—consider creating a new application instead.
-
Obtain the tools required to perform granular monitoring, log aggregation, application metrics, automated deployment, and status dashboards for data such as system status and log reporting.
-
Build a small application based solely on microservice development techniques. The idea is to create a complete application that demonstrates microservices really can do the job. Developing a small application tends to reduce the potential for failure for a development group that is just learning the ropes.
-
Slowly cross-train individuals so that the sharp divisions between skill sets diminishes.
-
Break down the silos between various groups. Start creating microservices that make code, resources, and data from every group available to every other group without consideration of the group that originated the item.
-
Slide development from the existing monolithic application to one designed around microservices.
-
Beginning with a small monolithic project, move the monolithic project entirely to a microservices environment if possible. Perform the task slowly and use metrics after the addition of each microservice to ensure that the application truly does work faster, run more reliably, and stay more secure.
-
Prune older microservices from the system as you replace them with finer-grained and more functional replacements.
Making Microservice Calls Using JavaScript
The previous section helped you understand what a microservice is, but it doesn’t show you how a microservice works. The following sections provide you with a simple example of how you might put a microservice together and use it in an application. Of course, you need a lot of microservices to create a fully functional application, but this example is a good way to get started.
Understanding the Role of REST in Communication
Microservices rely on REST, which is an architectural style of communication, because it’s more lightweight than protocols such as the Simple Object Access Protocol (SOAP). Using SOAP does have advantages in some situations, but it presents problems in Internet scenarios such as significant use of bandwidth and the need for a more formal level of communication between client and server. Applications that rely on REST for communication are called RESTful applications. Using REST for microservices provides the following advantages:
-
Decouples consumers from producers
-
Provides stateless communication
-
Allows use of a cache
-
Allows use of a layered system
-
Provides a uniform interface
You have a number of options for using REST with microservices. However, the easiest method (and the method used for the example) is to rely on a specially formatted URL. For example, http://localhost:10101/act?say=hello is the URL used for the example. In this case, you contact the localhost using a special port, 10101. You send a message using act. The message is interpreted as a JSON name/value pair, {say:"hello"}. The example demonstrates how this all works, but the idea is that you send a request and then get back a JSON response. Using REST for communication makes things simple.
Transmitting Data Using JSON
Microservices rely on JSON for transferring both requests and responses. Yes, you can also send data using REST, but the information ultimately ends up in JSON format. There are three main reasons that you want to use JSON to transfer data:
- Clean data
- The data format for JSON is straightforward. The data appears in two forms: name/value pairs or as a list of values. Because the data format is so strict and simple, there is less chance for error when transferring data and therefore, fewer reliability and security issues.
- Efficiency
- Because JSON avoids the whole tagged appearance of both HTML and XML, it tends to be smaller than other sorts of data transfers. The information is still in text form, but the format itself is quite efficient, which means you waste fewer resources transferring the data.
- Scalability
- The strict data format used by JSON means that data transfers are standardized, which makes it easier to expand your application as needed. Using a single data structure means that you can plug in your code anywhere that you need it.
JSON typically uses five distinct data forms. Unlike XML, you don’t create complex data hierarchies that can follow just about any form imaginable. Here are the five forms that you rely on to transmit data:
- Object
- An object is a name/value pair. The pair appears within curly braces (
{}) and is separated by a colon (:). You can create complex objects by separating several name/value pairs using a comma. For example,{say:"hello"}is a name/value pair. - Array
- An array consists of one or more values contained within square brackets (
[]). For example,["One", "Two", "Three"]is an array containing three string values. - Value
- A value is a single item. JSON recognizes string, number, object, array,
true,false, andnullas values. - String
- A series of characters within quotes (most texts say you should use double quotes). JSON recognizes control characters preceded by the backslash (
\). These characters are: backspace (\b), formfeed (\f), newline (\n), carriage return (\r), and horizontal tab (\t). You can also specify Unicode characters using\uand a four-digit hexadecimal value. For example,\u00BCis the one quarter (¼) symbol. - Number
- A number is an unquoted series of numeric characters with or without a decimal point. The plus and minus signs show positive and negative values. You can also specify numbers using scientific notation by adding an
eor anE. For example,-123e20is a perfectly acceptable presentation of a value.
Creating a Microservice Using Node.js and Seneca
You can find a number of examples for using Node.js and Seneca to create a microservice online. Unfortunately, most of them are convoluted and difficult to use. Some are simply outdated. The best example appears at http://senecajs.org/. The source for the server works precisely as shown. However, an even simpler example is the one found in service.js, as shown here:
require('seneca')()
.add(
{ say:"hello"},
function( message, done )
{
done( null, {message:'hello'} )
})
.listen()
In this example, require('seneca') loads the Seneca library into memory. The code then adds a match pattern of { say:"hello"} as a JSON object. The function() associated with the match pattern outputs another JSON object, {message:'hello'}. The example purposely uses both single and double quotes when creating JSON objects to show that it is possible, even if the official specifications don’t seem to say so. The final step is to tell the service to listen(). You can add a port number to the listen() function. If you don’t provide a port number, the service listens at the default port of 10101. To start the service, you type node server.js and press Enter at the command prompt. You see startup messages like the ones shown in Figure 8-1.
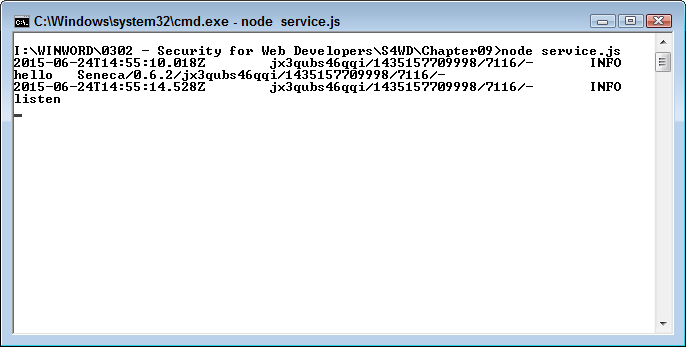
Figure 8-1. The microservice is listening for requests
The startup process logs two steps. The first is the initialization process for Seneca (where Seneca says “hello” on the third line of the output in Figure 8-1). The second is placing the microservice in listen mode (as shown on the fifth line). Whenever the microservice makes a call or performs some other task (other than simple output), you see one or more log entries added to the window. From a security perspective, this makes it possible for you to track the microservice functionality and detect whether anyone is attempting to do something unwanted with it.
Of course, you’ll want to test the microservice. Open your browser window and type http://localhost:10101/act?say=hello as an address. The microservice outputs a simple JSON object, as shown in Figure 8-2.
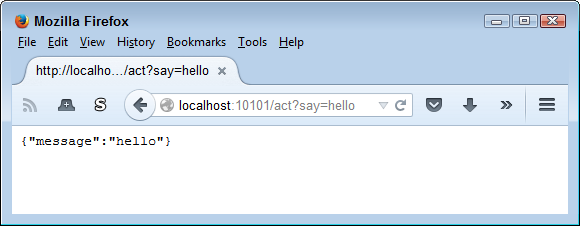
Figure 8-2. This simple example outputs a JSON object
When you look back at the console window, you don’t see anything. That’s because the function outputs a simple JSON object and didn’t make any calls outside the environment. However, try typing http://localhost:10101/act?say=goodbye as a request. Now you see some activity in the console window, as shown in Figure 8-3.
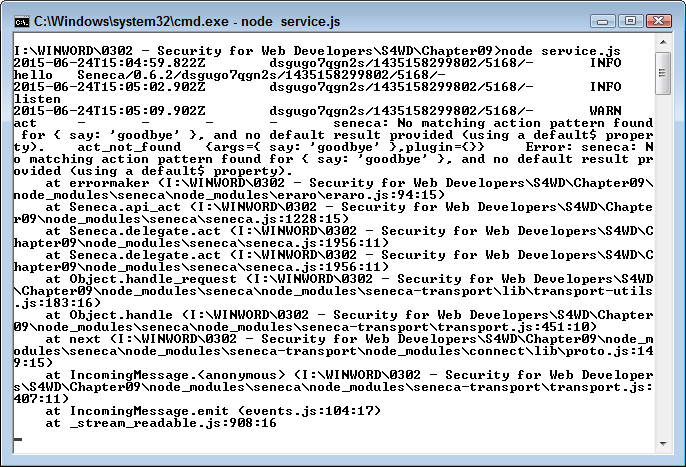
Figure 8-3. Errors produce copious output text
The output includes a stack trace, which you can ignore in this case, but could prove helpful when working with complex microservices. The most important information appears at the top in this case. You see a warning that there is no matching pattern for { say: 'goodbye' }. Notice that the REST request is translated into a JSON object. The error output tells you precisely what happened, so it’s harder for someone to get by with an invalid request.
This is actually a good example for experimentation because you can see the results of trying to fool the REST communication part of the microservice functionality without worrying about other elements covering up the results. When you finish working with the example, press Ctrl–C or Ctrl–Break to stop the service. The service will stop and you’ll see the command prompt reappear.
Defining the Security Threats Posed by Microservices
In many respects, microservices mirror APIs when it comes to security concerns. For example, it’s possible that a microservice could suffer from a man-in-the-middle attack. The ability of a hacker to truly benefit from such an attack is less than with an API because a microservice is small, self-contained, and only performs one task. However, the threat is still there and a hacker really only needs one avenue of attack to ruin your day. Although you may see all sorts of articles telling you about the natural security that microservices provide, they do have security issues and you need to know about them too. The following sections provide a mix of benefits and problems that you need to consider when it comes to microservice security.
Lack of Consistency
The biggest potential threat posed by microservices is the lack of consistency that appears to haunt just about every library and API ever created. The library and API developers begin with the simple idea of creating an easy-to-use and consistent interface, but over time the library or API becomes a mishmash of conflicting strategies that makes a Gordian knot easy to untangle by comparison. Trying to fix either code base is incredibly difficult because developers use libraries and APIs as a single piece of code. These inconsistencies cause security issues because developers using the code bases think the calls should work one way when they really work another. The result is that a mismatch occurs between the code base and the application that relies on it. Hackers seize such errors as a means for gaining access to the application, its data, or the system it runs on.
Microservices can also suffer from a lack of consistency. It’s essential that you create a template for describing precisely how to call microservices as early as possible in the development process. Just like libraries and APIs, hackers could use inconsistencies as a means for overcoming any security you have in place. Unlike libraries and APIs, the inconsistency would affect just one microservice, rather than the entire code base. Fixing the microservice would also prove easier because you’re looking at just one call, rather than an entire API. Publishing a new microservice is also easier than publishing an entirely new library or API. Consequently, overcoming a microservice inconsistency is relatively easy.
Considering the Role of the Virtual Machine
Each microservice typically runs in its own virtual machine (VM) environment. This means that one microservice can’t typically corrupt another. Even if a hacker does gain access to one microservice, the amount of damage the hacker can do is typically minimal. However, it’s quite possible to run multiple microservices in the same virtual machine—at which point it would become possible for a hacker to try various techniques to obtain access to the entire API. To maximize security, you want to avoid stacking microservices as shown by the service2.js example here (to access this example, you must use port 999, such as http://localhost:999/act?say=goodbye):
require('seneca')()
.add(
{ say:"hello"},
function( message, done )
{
done( null, {message:'hello'} )
})
.add(
{ say:"goodbye"},
function( message, done )
{
done( null, {message:'goodbye'} )
})
.listen(999)
Best practice is to run each service in a separate virtual machine to ensure each service has its own address space and process. Separating each microservice presents fewer opportunities for error and also for issues resulting from code tricks hackers could employ.
Using JSON for Data Transfers
There are no perfect data transfer methodologies. Yes, JSON is lightweight, easy to use, and less susceptible to security issues than other technologies such as XML. However, hackers still have a number of methods for causing problems with JSON. The following sections describe the more prevalent issues.
Considering the dangers of eval()
It’s possible that someone could send a response to the client that contains a <script> tag with a script that could do just about anything (in some cases, you don’t even need the tag—passing just the script instead). Fortunately, most browsers now detect such attempts and refuse to transfer the information. For example, try http://localhost:999/act?<script>alert(‘Hello’);</script>=goodbye and you may see something like the output shown in Figure 8-4. In addition, the microservice itself refused to process the request. However, this particular script is simplistic in nature—a more advanced attempt could succeed.
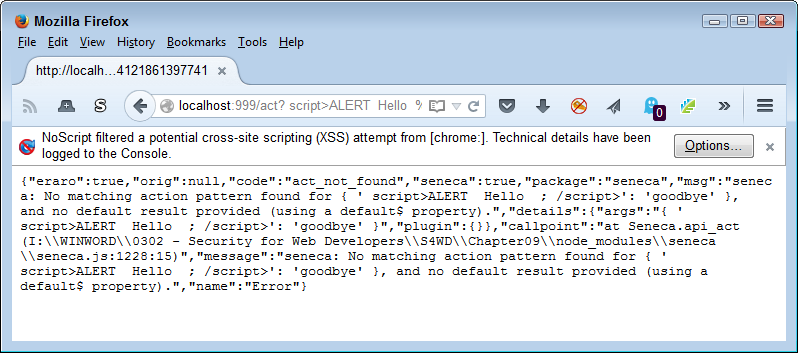
Figure 8-4. Scripting issues can plague microservices just as they do APIs
Defending against cross-site request forgery
A cross-site request forgery (CSRF or XSRF) is an attempt by an attacker to get a user to execute code unwittingly or unknowingly. The code executes at the user’s privilege level and under the user’s credentials, so it appears that the user has executed the code, rather than someone else. In most cases, this particular attack works against microservices when the following series of events occur:
-
A user logs in to an application that relies on microservices.
-
The user performs various tasks, each of which relies on REST for communication in the background.
-
An attacker sends the user an URL that is specially formatted to look just like the other REST messages, but does something the attacker wants the user to do. The URL could appear as part of an email message or some other communication, or even as a link on a website.
-
The user initiates the request by sending the URL to the microservice just like normal.
-
The malicious request executes and the user may not even realize it has happened.
Note
A real-world example of this exploit occurred in 2008 as a μTorrent exploit. The reason this particular exploit is so important to microservice developers is that it works on a system where a web server runs in the background. When the exploit occurs, it compromises the entire system, which is why you want to keep those microservices separated in their own VMs. You can read about it at http://xs-sniper.com/blog/2008/04/21/csrf-pwns-your-box/.
Because of the way in which this exploit works, what you really need to do is ensure that the application automatically logs the user out after a period of inactivity. In addition, you need to look for odd usage patterns and set limits on what a user can do without approval. For example, a user can transfer $1,000 at a bank, but transferring $10,000 requires a manager’s approval. Using multistep workflows, where an attacker would need to interact more with the user to make the exploit work, can sometimes prevent this sort of exploit as well, but then you face the user’s wrath for having to perform more steps to accomplish a given task.
Defining Transport Layer Security
The Achilles’ heel of both microservices and APIs is that both function by sending messages back and forth, rather than performing processing on a single machine. The cornerstone of developing a fix for this issue is Transport Layer Security (TLS). It’s essential to ensure the transport layer between client and server remains secure throughout the messaging process. This means using technologies such as HTTPS and REST to ensure that the communications remain as secure as possible.
An issue with wrapping absolutely every call and response in HTTPS and REST is that the application can slow to a crawl. The best method of overcoming this problem is to rely on load balancing to terminate client communications, while also keeping a channel open to backend processing needs. Keeping the backend processing channel open reduces overhead and helps reduce the effects of using HTTPS and REST.
Note
One of the issues with using HTTPS with public-facing networks is that you must have a certificate from a Certificate Authority (CA)—an expensive proposition that may keep some organizations from using HTTPS. When you control both ends of the communication channel, it’s possible to create your own certificate to achieve the same goal at a significantly reduced cost.
The use of HTTPS and bidirectional TLS ensures that both client and server establish each other’s identity during each request/response cycle. Authentication reduces the chance that someone can successfully implement a man-in-the-middle attack to obtain unauthorized access to data. Most communication today takes place using unidirectional TLS where the client verifies the server’s identity, but the server just assumes the client isn’t compromised. Given the nature of microservice communication, you really do need to implement bidirectional TLS to verify the identity of both client and server.
Creating Alternate Microservice Paths
Something that many developers will have a problem understanding is the decentralized nature of microservices. Each microservice is separate. You don’t have to think about the platform a microservice needs, what language it uses, or where it resides physically. It’s possible to have two microservices written in two different languages residing on two different platforms in two different locations perform the same task. Because the environments used by the two microservices are so different, it’s unlikely that an issue that affects one microservice will also affect the other microservice. Consequently, it’s a good idea to keep both of them around so that you can switch between them as needed to keep your application running. That’s what this section is all about—considering the implications of having multiple paths to access multiple microservices.
When thinking about microservices and the paths they employ, also consider things like ports. You can create microservices that work on different ports. Normally, you might rely on the microservice on port 999 to perform the work required by an application. However, if the microservice on port 999 becomes overloaded, compromised, or simply doesn’t work, you can switch to the same microservice on a different port. Your code remains the same—only the port changes. Using this approach gives your application resilience, reliability, and flexibility. It also means that you have options should something like a distributed denial-of-service (DDOS) attack occur.