
In the previous eight chapters, you learned about the scalar floating-point, packed floating-point, and packed integer capabilities of AVX and AVX2. In this chapter, you’ll learn about Advance Vector Extensions 512 (AVX-512). AVX-512 is undoubtedly the largest and perhaps the most consequential extension of the x86 platform to date. It doubles the number of available SIMD registers and broadens the width of each register from 256 to 512 bits. AVX-512 also extends the instruction syntax of AVX and AVX2 to support additional capabilities not available in the earlier extensions, including conditional execution and merging, embedded broadcasts, and instruction-level rounding control for floating-point operations.
The content of this chapter is organized as follows. The first section presents a brief overview of AVX-512, which includes information about AVX-512’s various instruction set extensions. This is followed by an examination of the AVX-512 execution environment, including its register sets, data types, instruction syntaxes, and enhanced computational features. The chapter concludes with a synopsis of the AVX-512 instruction set extensions that are included in recently marketed processors for server and workstation platforms.
AVX-512 Overview
Overview of AVX-512 Instruction Set Extensions
CPUID Flag | Description |
|---|---|
AVX512F | Foundation instructions |
AVX512ER | Exponential and reciprocal instructions |
AVX512PF | Prefetch instructions |
AVX512CD | Conflict detect instructions |
AVX512DQ | Doubleword and quadword instructions |
AVX512BW | Byte and word instructions |
AVX512VL | 128-bit and 256-bit vector instructions |
AVX512_IFMA | Integer fused-multiply-add |
AVX512_VBMI | Additional vector byte instructions |
AVX512_4FMAPS | Packed single-precision FMA (4 iterations) |
AVX512_4VNNI | Vector neural network instructions (4 iterations) |
AVX512_VPOPCNTDQ | vpopcnt[d|q] instructions |
AVX512_VNNI | Vector neural net instructions |
AVX512_VBMI2 | New vector byte, word, doubleword, and quadword instructions |
AVX512_BITALG | vpopcnt[b|w] and vpshufbitqmb instructions |
The discussions in this chapter and the source code examples of Chapters 13 and 14 primarily focus on the AVX-512 instruction set extensions that are incorporated in Intel’s Skylake Server microarchitecture, which was launched during 2017. This microarchitecture is used in Intel’s Xeon Scalable (servers), Xeon W (workstations), and Core i7-7800X and i9-7900X series (high-end desktop) CPUs. Processors based on the Skylake Server microarchitecture contain the following AVX-512 instruction set extensions: AVX512F, AVX512CD, AVX512BW, AVX512DQ, and AVX512VL. Future mainstream processors from both AMD and Intel are expected to include these same AVX-512 extensions. Chapter 16 explains how to use the cupid instruction to detect the AVX-512 instructions set extensions that are shown in Table 12-1.
AVX-512 Execution Environment
AVX-512 augments the execution environment of the x86 platform with the addition of new registers and data types. It also extends the assembly language instruction syntax of AVX and AVX2 to support enhanced operations such as conditional executions and merging, embedded broadcasts, and instruction level rounding control. This section discusses these enhancements in greater detail.
Register Sets
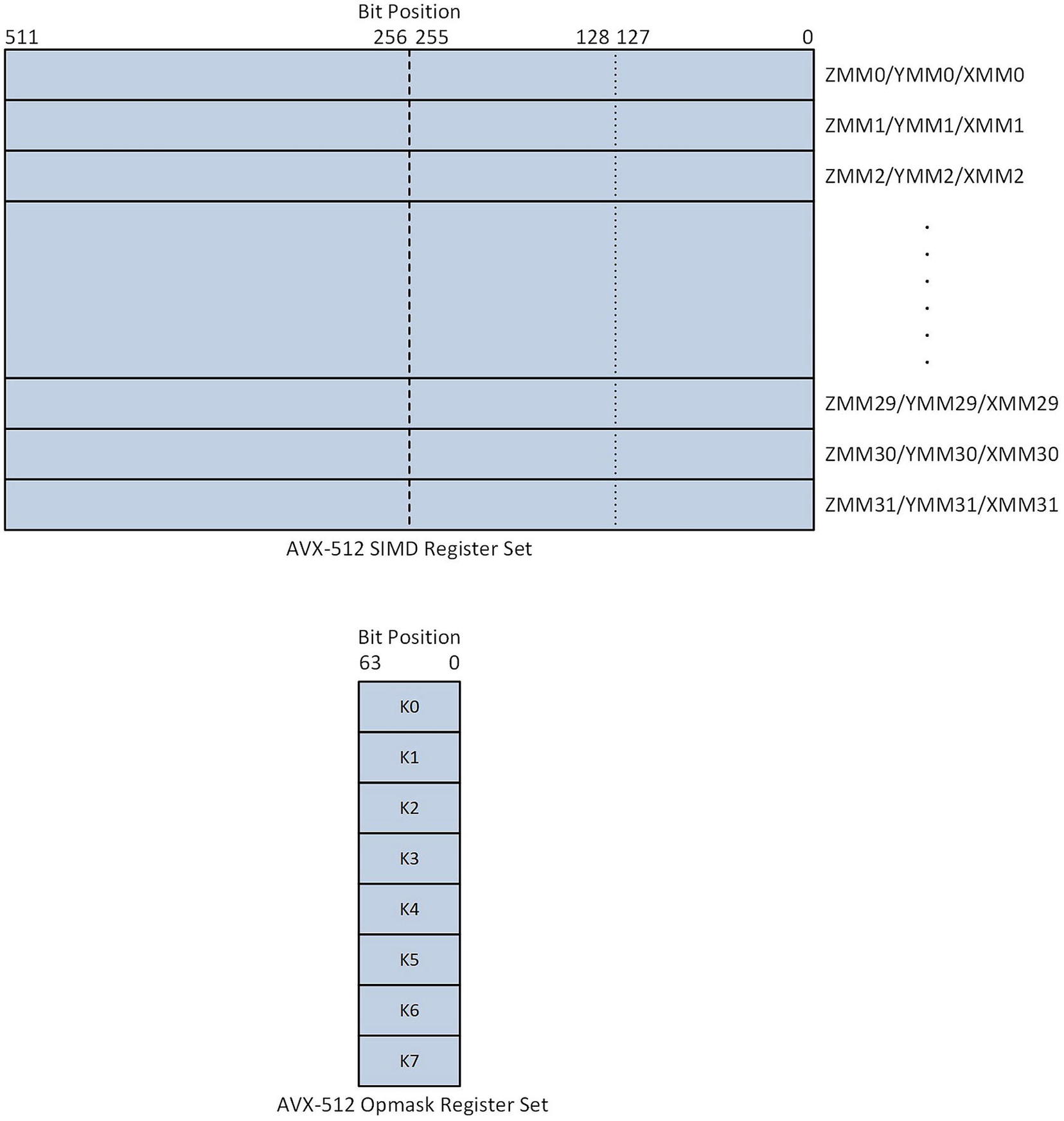
AVX-512 register sets
Data Types
Maximum Number of Elements for AVX-512 Register Operands
Data Type | ZMM | YMM | XMM |
|---|---|---|---|
Integer byte | 64 | 32 | 16 |
Integer word | 32 | 16 | 8 |
Integer doubleword | 16 | 8 | 4 |
Integer quadword | 8 | 4 | 2 |
Single-precision floating-point | 16 | 8 | 4 |
Double-precision floating-point | 8 | 4 | 2 |
The alignment requirements for 512-bit wide operands in memory are similar to other x86 SIMD operands. Except for instructions that explicitly specify an aligned operand (e.g., vmovdqa[32|64], vmovap[d|s], etc.), proper alignment of a 512-bit wide operand in memory is not mandatory. However, 512-bit wide operands should always be aligned on a 64-byte boundary whenever possible to avoid processing delays that can occur if the processor is forced to access an unaligned operand in memory. AVX-512 instructions that access 256-bit or 128-bit wide operands in memory should also ensure that these types of operands are properly aligned on their respective natural boundaries.
Instruction Syntax
AVX-512 extends the instruction syntax of AVX and AVX2. Most AVX-512 instructions can use the same three-operand instruction syntax as AVX and AVX2 instructions, which consists of two non-destructive source operands and one destination operand. AVX-512 instructions can also exploit several new optional operands. These operands facilitate conditional executions and merging, embedded broadcast operations, and floating-point rounding control. The next few sections discuss AVX-512’s optional instruction operands in greater detail.
Conditional Execution and Merging
Most AVX-512 instructions support conditional execution and merging. A conditional execution and merge operation uses the bits of an opmask register as a predicate mask to control instruction execution and destination operand updates on a per-element basis. Figure 12-2 illustrates this concept in greater detail. In this figure, registers ZMM0, ZMM1, and ZMM2 each contain 16 single-precision floating-point values. The 16 low-order bits of opmask register K1 constitute the predicate mask. When an opmask register is used in this manner, each bit controls how the result of corresponding element position in the destination operand is calculated and updated.
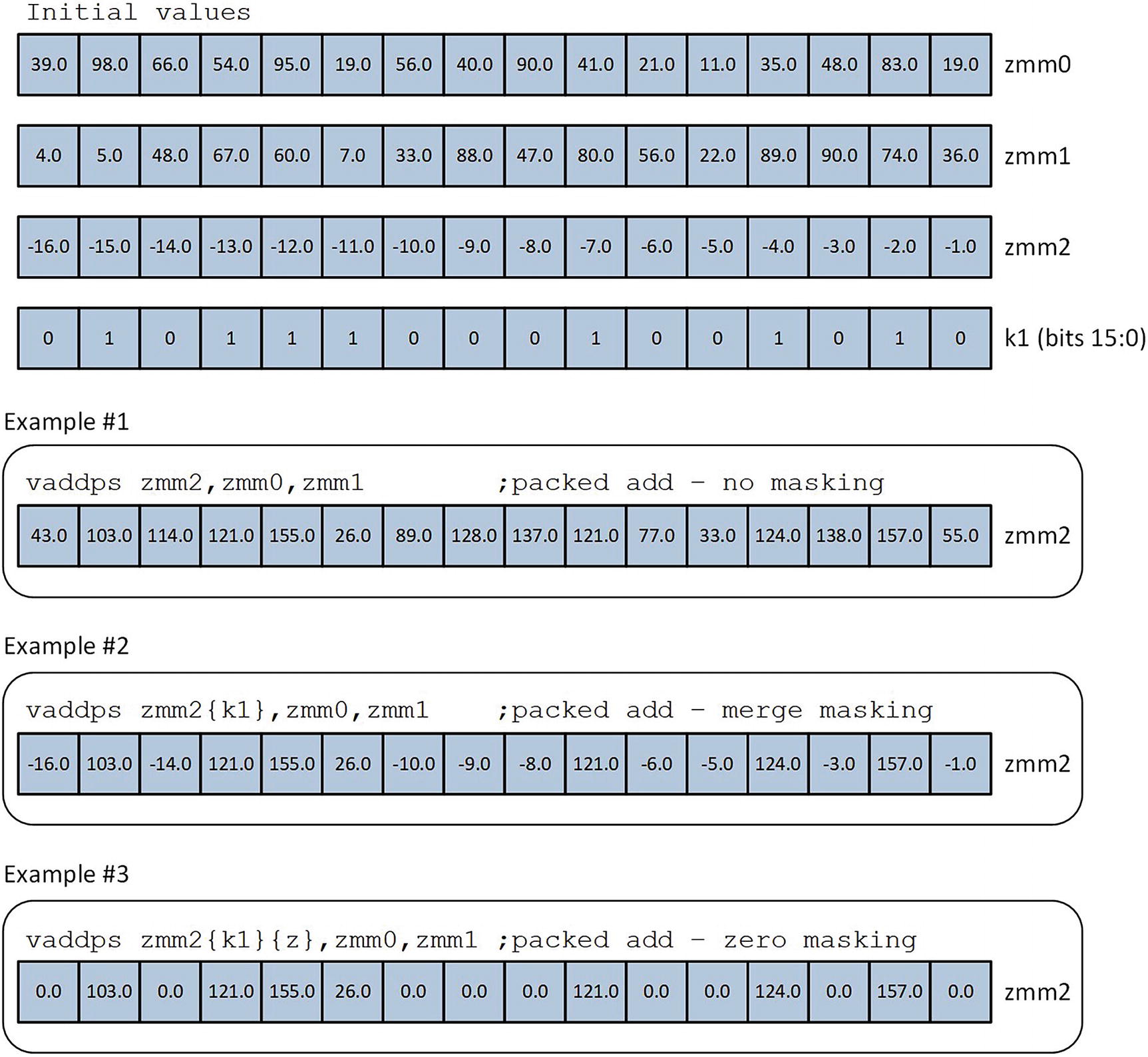
Execution examples of the vaddps instruction using no masking, merge masking, and zero masking
At this point a few words about the opmask registers are warranted. The eight opmask registers are somewhat like the general-purpose registers. On processors that support AVX-512, each opmask register is 64-bits wide. However, when employed as a predicate mask, only the low-order bits are used during instruction execution. The exact number of used low-order bits varies depending on the number of vector elements. In Figure 12-2, bits 0–15 of opmask register K1 form the predicate mask since the vaddps instruction employs ZMM register operands that contain 16 single-precision floating-point values.
AVX-512 includes several new instructions that can be used to read values from and write values to an opmask register and perform Boolean operations. You’ll learn about these instructions later in this chapter. An opmask register can also be used as destination operand with instructions that generate a vector mask result such as vcmpp[d|s] and vpcmp[b|w|d|q]. The source code examples in Chapters 13 and 14 illustrate how to use these instructions with an opmask register. AVX-512 instructions can use opmask registers K1–K7 as a predicate mask. Opmask register K0 cannot be employed as a predicate mask operand but it can be used in any instruction that requires a source or destination operand opmask register. If an AVX-512 instruction attempts to use K0 as a predicate mask, the processor substitutes an implicit operand of all 1s, which disables all conditional execution and masking operations.
Embedded Broadcast
Many AVX-512 instructions can carry out a SIMD computation using an embedded broadcast operand. An embedded broadcast operand is a memory-based scalar value that is replicated N times into a temporary packed value, where N represents the number of vector elements referenced by the instruction. This temporary packed value is then used as an operand in a SIMD calculation.
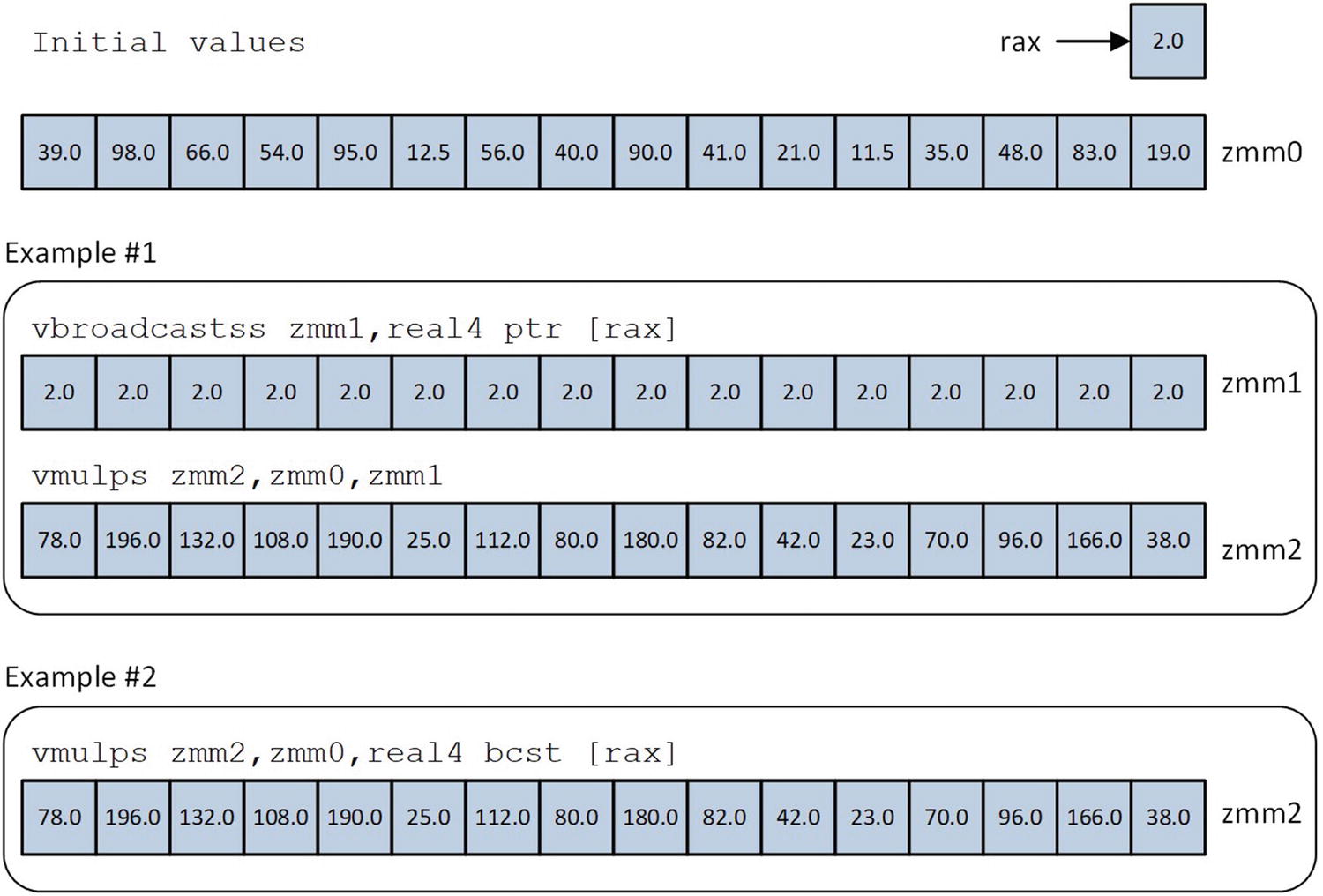
Packed single-precision floating-point multiplication using the vbroadcastss and vmulps instructions versus a vmulps instruction with an embedded broadcast operand
AVX-512 supports embedded broadcast operations using 32-bit and 64-bit wide elements. Embedded broadcasts cannot be performed using 8-bit and 16-bit wide elements.
Instruction Level Rounding
AVX-512 Instruction-Level Static Rounding Mode Operands
Rounding Mode Operand | Description |
|---|---|
{rn-sae} | Round to nearest |
{rd-sae} | Round down (toward −∞) |
{ru-sae} | Round up (toward +∞) |
{rz-sae} | Round toward zero (truncate) |
Static rounding mode operands can be used with many (but not all) AVX-512 instructions that perform floating-point operations using 512-bit wide packed operands; 256-bit and 128-bit wide packed operands are not supported. Static rounding mode operands can also be used with instructions that perform scalar floating-point operations. In both use cases, all instruction operands must be registers. For example, the instructions vmulps zmm2,zmm0,zmm1 {rz-sae} and vmulss xmm2,xmm0,xmm1 {rz-sae} are valid, whereas vmulps zmm2,zmm0,zmmword ptr [rax] {rz-sae} and vmulss xmm2,xmm0,real4 ptr [rax] {rz-sae} are invalid. Some AVX-512 floating-point instructions do not support the specification of a static rounding mode operand, but these instructions still can use the operand {sae} to suppress all exceptions.
Instruction Set Overview
This section presents an overview of the following AVX-512 instruction set extensions: AVX512F, AVX512CD, AVX512BW, and AVX512DQ. It also includes a summary of the opmask register instructions. The tables in this section only include instructions that are new to AVX-512. They do not include instructions that are a simple promotion of an existing AVX or AVX2 instruction. Most of the instructions in these tables can be used with 512-bit wide operands; 256-bit and 128-bit wide operands can be used on processors that support AVX512VL.
AVX512F
AVX512F Instruction Set Overview
Mnemonic | Description |
|---|---|
valign[d|q] | Align doubleword | quadword vectors |
vblendmp[d|s] | Blend floating-point vectors using opmask control |
vbroadcastf[32x4|64x4] | Broadcast floating-point tuples |
vbroadcasti[32x4|64x4] | Broadcast integer tuples |
vcompressp[d|s] | Store sparse packed floating-point values |
vcvtp[d|s]2udq | Convert packed floating-point to packed unsigned doubleword integers |
vcvts[d|s]2usi | Convert scalar floating-point to unsigned doubleword integer |
vcvttp[d|s]2udq | Convert packed floating-point to packed unsigned doubleword integers with truncation |
vcvtts[d|s]2usi | Convert scalar floating-point to unsigned doubleword integer with truncation |
vcvtudq2p[d|s] | Convert packed unsigned doubleword integers to packed floating-point |
vcvtusi2s[d|s] | Convert unsigned doubleword integer to floating-point |
vexpandp[d|s] | Load sparse packed floating-point values |
vextractf[32x4|64x4] | Extract packed floating-point values |
vextracti[32x4|64x4] | Extract packed integer values |
vfixupimmp[d|s] | Fix up special packed floating-point values |
vfixupimms[d|s] | Fix up special scalar floating-point values |
vgetexpp[d|s] | Convert exponents of packed floating-point values |
vgetexps[d|s] | Convert exponents of scalar floating-point values |
vgetmantp[d|s] | Get normalized mantissas from packed floating-point values |
vgetmants[d|s] | Get normalized mantissas from scalar floating-point value |
vinsertf[32x4|64x4] | Insert packed floating-point values |
vinserti[32x4|64x4] | Insert packed integer values |
vmovdqa[32|64] | Move aligned packed integers |
vmovdqu[32|64] | Move unaligned packed integers |
vpblendm[d|q] | Blend packed integers using opmask control |
vpbroadcast[d|q] | Broadcast integer from general-purpose register |
vpcmp[d|q] | Compare packed signed integers |
vpcmpu[d|q] | Compare packed unsigned integers |
vpcompress[d|q] | Store sparse packed integers |
vpermi2[d|q|ps|pd] | Permute from two tables overwriting the index |
vpermt2[d|q|ps|pd] | Permute from two tables overwriting one table |
vpmov[db|sdb|usdb] | Down convert packed doublewords to packed bytes |
vpexpand[d|q] | Load sparse packed integers |
vpmax[s|u]q | Calculated packed quadword maximums |
vpmin[s|u]q | Calculate packed quadword minimums |
vpmov[db|sdb|usdb] | Down convert packed doublewords to packed bytes |
vpmov[dw|sdw|usdw] | Down convert packed doublewords to packed words |
vpmov[qb|sqb|usqb] | Down convert packed quadwords to packed bytes |
vpmov[qd|sqd|usqd] | Down convert packed quadwords to packed doublewords |
vpmov[qw|sqw|usqw] | Down convert packed quadwords to packed words |
vprol[d|q] | Rotate left packed integers using constant count |
vprolv[d|q] | Rotate left pack integers using variable counts |
vpror[d|q] | Rotate right packed integers using constant count |
vprorv[d|q] | Rotate right packed integers using variable counts |
vpscatterd[d|q] | Scatter packed integers using doubleword indices |
vpscatterq[d|q] | Scatter packed integers using quadword indices |
vpsraq | Shift right arithmetic packed quadword integers using constant count |
vpsravq | Shift right arithmetic packed quadword integers using variable counts |
vpternlog[d|q] | Bitwise ternary logic |
vptestm[d|q] | Packed integer bitwise AND and set mask |
vptestnm[d|q] | Packed integer bitwise NAND and set mask |
vrcp14p[d|s] | Compute approximate reciprocals of packed floating-point values |
vrcp14s[d|s] | Compute approximate reciprocals of scalar floating-point value |
vreducep[d|s] | Perform reduction transformation on packed floating-point values |
vreduces[d|s] | Perform reduction transformation on scalar floating-point value |
vrndscalep[d|s] | Round packed floating-point values to number of fractional bits |
vrndscales[d|s] | Round floating-point value to number of fractional bits |
vrsqrt14p[d|s] | Compute approximate reciprocals of packed floating-point square roots |
vrsqrt14s[d|s] | Compute approximate reciprocals of scalar floating-point square root |
vscalefp[d|s] | Scale packed floating-point values |
vscalefs[d|s] | Scale scalar floating-point value |
vscatterdp[d|s] | Scatter packed floating-point values using doubleword indices |
vscatterqp[d|s] | Scatter packed floating-point values using quadword indices |
vshuff[32x4|64x2] | Shuffle packed floating-point values |
vshufi[32x4|64x2] | Shuffle packed integer values |
AVX512CD
AVX512CD Instruction Set Overview
Mnemonic | Description |
|---|---|
vpbroadcastm[b2q|w2d] | Broadcast mask to vector register |
vpconflict[d|q] | Detect conflicts within packed integers |
vplzcnt[d|q] | Count number of leading zeros in packed integers |
AVX512BW
AVX512BW Instruction Set Overview
Mnemonic | Description |
|---|---|
vdbpsadbw | Double block packed sum-absolute-differences using unsigned bytes |
vmovdq[u8|u16] | Move unaligned packed integers |
vpblendm[b|w] | Blend packed integers using opmask control |
vpbroadcast[b|w] | Broadcast integer from general-purpose register |
vpcmp[b|w] | Compare packed signed integers |
vpcmpu[b|w] | Compare packed unsigned integers |
vpermw | Permute packed words |
vpermi2w | Permute word integers from two tables overwriting the index |
vpermt2w | Permute word integers from two tables overwriting one table |
vpmov[b|w]2m | Convert vector register to mask register |
vpmovm2[b|w] | Convert mask register to vector register |
vpmovw[b|sb|usb] | Down convert packed words to packed bytes |
vpsllvw | Packed word shift left logical using variable bit counts |
vpsravw | Packed word shift right arithmetic using variable bit counts |
vpsrlvw | Packed word shift right logical using variable bit counts |
vptestm[b|w] | Packed integer bitwise AND and set mask |
vptestnm[b|w] | Packed integer bitwise NAND and set mask |
AVX512DQ
AVX512DQ Instruction Set Overview
Mnemonic | Description |
|---|---|
vcvtp[d|s]2qq | Convert packed floating-point to signed quadword integers |
vcvtp[d|s]2uqq | Convert packed floating-point to unsigned quadword integers |
vcvttp[d|s]2qq | Convert packed floating-point to signed quadword integers with truncation |
vcvttp[d|s]2uqq | Convert packed floating-point to unsigned quadword integers with truncation |
vcvtuqq2p[d|s] | Convert packed unsigned quadword integers to floating-point |
vextractf64x2 | Extract packed double-precision floating-point values |
vextracti64x2 | Extract packed quadword values |
vfpclass[pd|ps] | Test packed floating-point class |
vfpclass[sd|ss] | Test scalar floating-point class |
vinsertf64x2 | Insert packed double-precision floating-point values |
vinserti64x2 | Insert packed quadword values |
vpmov[d|q]2m | Convert vector register to mask register |
vpmovm2[d|q] | Convert mask register to vector register |
vpmullq | Multiply packed quadword integers and store low result |
vrangep[d|s] | Range restriction calculation for packed floating-point |
vranges[d|s] | Range restriction calculation for scalar floating-point |
vreducep[d|s] | Perform reduction on packed floating-point values |
vreduces[d|s] | Perform reduction on scalar floating-point values |
Opmask Registers
Opmask Register Instruction Set Overview
Mnemonic | Description |
|---|---|
kadd[b|w|d|q] | Add mask values |
kand[b|w|d|q] | Bitwise AND |
kandn[b|w|d|q] | Bitwise AND NOT |
kmov[b|w|d|q] | Move value to/from opmask register |
knot[b|w|d|q] | Bitwise NOT |
kor[b|w|d|q] | Bitwise inclusive OR |
kortest[b|w|d|q] | Bitwise inclusive OR; update RFLAGS.ZF and RFLAGS.CF |
kshiftl[b|w|d|q] | Shift left |
kshiftr[b|w|d|q] | Shift right |
ktest[b|w|d|q] | Bitwise AND and ANDN; update RFLAGS.ZF and RFLAGS.CF |
kunpck[bw|wd|dq] | Unpack |
kxnor[b|w|d|q] | Bitwise exclusive NOR |
kxor[b|w|d|q] | Bitwise exclusive OR |
Summary
All AVX-512 conforming processors support the AVX512F instruction set extension. Inclusion of additional AVX-512 instruction set extensions varies depending on the processor’s target market.
The AVX-512 register set includes 32 512-bit wide registers named ZMM0–ZMM31. The low-order 256 and 128 bits are aliased to registers YMM0–YMM31 and XMM0–XMM31, respectively.
The AVX-512 register set also includes eight opmask registers named K0–K7. Opmask registers K1–K7 can be used to perform instruction-level conditional executions with merge masking or zero masking.
Many AVX-512 instructions that require a packed operand of constant values can use an embedded broadcast operand instead of a separate broadcast instruction.
A static rounding mode operand can be specified with many AVX-512 instructions that perform floating-point operations using 512-bit wide packed or scalar floating-point register operands.