Table of Contents for
A Tour of C++
 A Tour of C++
Published by
Addison-Wesley Professional, 2018
A Tour of C++
Published by
Addison-Wesley Professional, 2018
- Contents
- Cover
- About This eBook
- A Tour of C++
- Title Page
- Copyright Page
- Contents
- Preface
- 1 The Basics
- 2 User-Defined Types
- 3 Modularity
- 4 Classes
- 5 Essential Operations
- 6 Templates
- 7 Concepts and Generic Programming
- 8 Library Overview
- 9 Strings and Regular Expressions
- 10 Input and Output
- 11 Containers
- 12 Algorithms
- 13 Utilities
- 14 Numerics
- 15 Concurrency
- 16 History and Compatibility
- Index
- A Tour of C++
- Code Snippets
- Code Snippets
- Code Snippets
- Code Snippets
- Code Snippets
- Code Snippets
- Code Snippets
- Code Snippets
- Code Snippets
- Code Snippets
- Code Snippets
- Code Snippets
- Code Snippets
- Code Snippets
- Code Snippets
- Code Snippets
5
Essential Operations
When someone says I want a programming language in which I need only say what I wish done, give him a lollipop.
– Alan Perlis
-
Comparisons; Container Operations; Input and Output Operators; User-Defined Literals;
swap();hash<>
5.1 Introduction
Some operations, such as initialization, assignment, copy, and move, are fundamental in the sense that language rules make assumptions about them. Other operations, such as == and <<, have conventional meanings that are perilous to ignore.
5.1.1 Essential Operations
Construction of objects plays a key role in many designs. This wide variety of uses is reflected in the range and flexibility of the language features supporting initialization.
Constructors, destructors, and copy and move operations for a type are not logically separate. We must define them as a matched set or suffer logical or performance problems. If a class X has a destructor that performs a nontrivial task, such as free-store deallocation or lock release, the class is likely to need the full complement of functions:
class X {
public:
X(Sometype); // "ordinary constructor": create an object
X(); // default constructor
X(const X&); // copy constructor
X(X&&); // move constructor
X& operator=(const X&); // copy assignment: clean up target and copy
X& operator=(X&&); // move assignment: clean up target and move
~X(); // destructor: clean up
// ...
};
There are five situations in which an object can be copied or moved:
As the source of an assignment
As an object initializer
As a function argument
As a function return value
As an exception
An assignment uses a copy or move assignment operator. In principle, the other cases use a copy or move constructor. However, a copy or move constructor invocation is often optimized away by constructing the object used to initialize right in the target object. For example:
X make(Sometype); X x = make(value);
Here, a compiler will typically construct the X from make() directly in x; thus eliminating (“eliding”) a copy.
In addition to the initialization of named objects and of objects on the free store, constructors are used to initialize temporary objects and to implement explicit type conversion.
Except for the “ordinary constructor,” these special member functions will be generated by the compiler as needed. If you want to be explicit about generating default implementations, you can:
class Y {
public:
Y(Sometype);
Y(const Y&) = default; // I really do want the default copy constructor
Y(Y&&) = default; // and the default move constructor
// ...
};
If you are explicit about some defaults, other default definitions will not be generated.
When a class has a pointer member, it is usually a good idea to be explicit about copy and move operations. The reason is that a pointer may point to something that the class needs to delete, in which case the default memberwise copy would be wrong. Alternatively, it might point to something that the class must not delete. In either case, a reader of the code would like to know. For an example, see §5.2.1.
A good rule of thumb (sometimes called the rule of zero) is to either define all of the essential operations or none (using the default for all). For example:
struct Z {
Vector v;
string s;
};
Z z1; // default initialize z1.v and z1.s
Z z2 = z1; // default copy z1.v and z1.s
Here, the compiler will synthesize memberwise default construction, copy, move, and destructor as needed, and all with the correct semantics.
To complement =default, we have =delete to indicate that an operation is not to be generated. A base class in a class hierarchy is the classical example where we don’t want to allow a memberwise copy. For example:
class Shape {
public:
Shape(const Shape&) =delete; // no copy operations
Shape& operator=(const Shape&) =delete;
// ...
};
void copy(Shape& s1, const Shape& s2)
{
s1 = s2; // error: Shape copy is deleted
}
A =delete makes an attempted use of the deleted function a compile-time error; =delete can be used to suppress any function, not just essential member functions.
5.1.2 Conversions
A constructor taking a single argument defines a conversion from its argument type. For example, complex (§4.2.1) provides a constructor from a double:
complex z1 = 3.14; // z1 becomes {3.14,0.0}
complex z2 = z1*2; // z2 becomes z1*{2.0,0} == {6.28,0.0}
This implicit conversion is sometimes ideal, but not always. For example, Vector (§4.2.2) provides a constructor from an int:
Vector v1 = 7; // OK: v1 has 7 elements
This is typically considered unfortunate, and the standard-library vector does not allow this int-to-vector “conversion.”
The way to avoid this problem is to say that only explicit “conversion” is allowed; that is, we can define the constructor like this:
class Vector {
public:
explicit Vector(int s); // no implicit conversion from int to Vector
// ...
};
That gives us:
Vector v1(7); // OK: v1 has 7 elements Vector v2 = 7; // error: no implicit conversion from int to Vector
When it comes to conversions, more types are like Vector than are like complex, so use explicit for constructors that take a single argument unless there is a good reason not to.
5.1.3 Member Initializers
When a data member of a class is defined, we can supply a default initializer called a default member initializer. Consider a revision of complex (§4.2.1):
class complex {
double re = 0;
double im = 0; // representation: two doubles with default value 0.0
public:
complex(double r, double i) :re{r}, im{i} {} // construct complex from two scalars: {r,i}
complex(double r) :re{r} {} // construct complex from one scalar: {r,0}
complex() {} // default complex: {0,0}
// ...
}
The default value is used whenever a constructor doesn’t provide a value. This simplifies code and helps us to avoid accidentally leaving a member uninitialized.
5.2 Copy and Move
By default, objects can be copied. This is true for objects of user-defined types as well as for built-in types. The default meaning of copy is memberwise copy: copy each member. For example, using complex from §4.2.1:
void test(complex z1)
{
complex z2 {z1}; // copy initialization
complex z3;
z3 = z2; // copy assignment
// ...
}
Now z1, z2, and z3 have the same value because both the assignment and the initialization copied both members.
When we design a class, we must always consider if and how an object might be copied. For simple concrete types, memberwise copy is often exactly the right semantics for copy. For some sophisticated concrete types, such as Vector, memberwise copy is not the right semantics for copy; for abstract types it almost never is.
5.2.1 Copying Containers
When a class is a resource handle – that is, when the class is responsible for an object accessed through a pointer – the default memberwise copy is typically a disaster. Memberwise copy would violate the resource handle’s invariant (§3.5.2). For example, the default copy would leave a copy of a Vector referring to the same elements as the original:
void bad_copy(Vector v1)
{
Vector v2 = v1; // copy v1's representation into v2
v1[0] = 2; // v2[0] is now also 2!
v2[1] = 3; // v1[1] is now also 3!
}
Assuming that v1 has four elements, the result can be represented graphically like this:
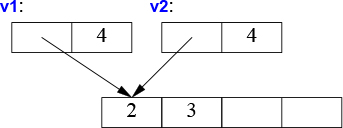
Fortunately, the fact that Vector has a destructor is a strong hint that the default (memberwise) copy semantics is wrong and the compiler should at least warn against this example. We need to define better copy semantics.
Copying of an object of a class is defined by two members: a copy constructor and a copy assignment:
class Vector {
private:
double* elem; // elem points to an array of sz doubles
int sz;
public:
Vector(int s); // constructor: establish invariant, acquire resources
~Vector() { delete[] elem; } // destructor: release resources
Vector(const Vector& a); // copy constructor
Vector& operator=(const Vector& a); // copy assignment
double& operator[](int i);
const double& operator[](int i) const;
int size() const;
};
A suitable definition of a copy constructor for Vector allocates the space for the required number of elements and then copies the elements into it so that after a copy each Vector has its own copy of the elements:
Vector::Vector(const Vector& a) // copy constructor
:elem{new double[a.sz]}, // allocate space for elements
sz{a.sz}
{
for (int i=0; i!=sz; ++i) // copy elements
elem[i] = a.elem[i];
}
The result of the v2=v1 example can now be presented as:
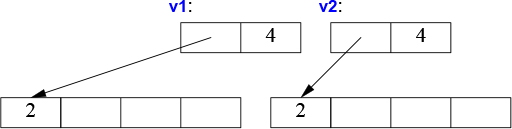
Of course, we need a copy assignment in addition to the copy constructor:
Vector& Vector::operator=(const Vector& a) // copy assignment
{
double* p = new double[a.sz];
for (int i=0; i!=a.sz; ++i)
p[i] = a.elem[i];
delete[] elem; // delete old elements
elem = p;
sz = a.sz;
return *this;
}
The name this is predefined in a member function and points to the object for which the member function is called.
5.2.2 Moving Containers
We can control copying by defining a copy constructor and a copy assignment, but copying can be costly for large containers. We avoid the cost of copying when we pass objects to a function by using references, but we can’t return a reference to a local object as the result (the local object would be destroyed by the time the caller got a chance to look at it). Consider:
Vector operator+(const Vector& a, const Vector& b)
{
if (a.size()!=b.size())
throw Vector_size_mismatch{};
Vector res(a.size());
for (int i=0; i!=a.size(); ++i)
res[i]=a[i]+b[i];
return res;
}
Returning from a + involves copying the result out of the local variable res and into some place where the caller can access it. We might use this + like this:
void f(const Vector& x, const Vector& y, const Vector& z)
{
Vector r;
// ...
r = x+y+z;
// ...
}
That would be copying a Vector at least twice (one for each use of the + operator). If a Vector is large, say, 10,000 doubles, that could be embarrassing. The most embarrassing part is that res in operator+() is never used again after the copy. We didn’t really want a copy; we just wanted to get the result out of a function: we wanted to move a Vector rather than copy it. Fortunately, we can state that intent:
class Vector {
// ...
Vector(const Vector& a); // copy constructor
Vector& operator=(const Vector& a); // copy assignment
Vector(Vector&& a); // move constructor
Vector& operator=(Vector&& a); // move assignment
};
Given that definition, the compiler will choose the move constructor to implement the transfer of the return value out of the function. This means that r=x+y+z will involve no copying of Vectors. Instead, Vectors are just moved.
As is typical, Vector’s move constructor is trivial to define:
Vector::Vector(Vector&& a)
:elem{a.elem}, // "grab the elements" from a
sz{a.sz}
{
a.elem = nullptr; // now a has no elements
a.sz = 0;
}
The && means “rvalue reference” and is a reference to which we can bind an rvalue. The word “rvalue” is intended to complement “lvalue,” which roughly means “something that can appear on the left-hand side of an assignment.” So an rvalue is – to a first approximation – a value that you can’t assign to, such as an integer returned by a function call. Thus, an rvalue reference is a reference to something that nobody else can assign to, so we can safely “steal” its value. The res local variable in operator+() for Vectors is an example.
A move constructor does not take a const argument: after all, a move constructor is supposed to remove the value from its argument. A move assignment is defined similarly.
A move operation is applied when an rvalue reference is used as an initializer or as the right-hand side of an assignment.
After a move, a moved-from object should be in a state that allows a destructor to be run. Typically, we also allow assignment to a moved-from object. The standard-library algorithms (Chapter 12) assumes that. Our Vector does that.
Where the programmer knows that a value will not be used again, but the compiler can’t be expected to be smart enough to figure that out, the programmer can be specific:
Vector f()
{
Vector x(1000);
Vector y(2000);
Vector z(3000);
z = x; // we get a copy (x might be used later in f())
y = std::move(x); // we get a move (move assignment)
// ... better not use x here ...
return z; // we get a move
}
The standard-library function move() doesn’t actually move anything. Instead, it returns a reference to its argument from which we may move – an rvalue reference; it is a kind of cast (§4.2.3).
Just before the return we have:
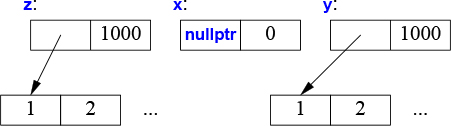
When we return from f(), z is destroyed after its elements has been moved out of f() by the return. However, y’s destructor will delete[] its elements.
The compiler is obliged (by the C++ standard) to eliminate most copies associated with initialization, so move constructors are not invoked as often as you might imagine. This copy elision eliminates even the very minor overhead of a move. On the other hand, it is typically not possible to implicitly eliminate copy or move operations from assignments, so move assignments can be critical for performance.
5.3 Resource Management
By defining constructors, copy operations, move operations, and a destructor, a programmer can provide complete control of the lifetime of a contained resource (such as the elements of a container). Furthermore, a move constructor allows an object to move simply and cheaply from one scope to another. That way, objects that we cannot or would not want to copy out of a scope can be simply and cheaply moved out instead. Consider a standard-library thread representing a concurrent activity (§15.2) and a Vector of a million doubles. We can’t copy the former and don’t want to copy the latter.
std::vector<thread> my_threads;
Vector init(int n)
{
thread t {heartbeat}; // run heartbeat concurrently (in a separate thread)
my_threads.push_back(std::move(t)); // move t into my_threads (§13.2.2)
// ... more initialization ...
Vector vec(n);
for (int i=0; i!=vec.size(); ++i)
vec[i] = 777;
return vec; // move vec out of init()
}
auto v = init(1'000'000); // start heartbeat and initialize v
Resource handles, such as Vector and thread, are superior alternatives to direct use of built-in pointers in many cases. In fact, the standard-library “smart pointers,” such as unique_ptr, are themselves resource handles (§13.2.1).
I used the standard-library vector to hold the threads because we don’t get to parameterize our simple Vector with an element type until §6.2.
In very much the same way that new and delete disappear from application code, we can make pointers disappear into resource handles. In both cases, the result is simpler and more maintainable code, without added overhead. In particular, we can achieve strong resource safety; that is, we can eliminate resource leaks for a general notion of a resource. Examples are vectors holding memory, threads holding system threads, and fstreams holding file handles.
In many languages, resource management is primarily delegated to a garbage collector. C++ also offers a garbage collection interface so that you can plug in a garbage collector. However, I consider garbage collection the last choice after cleaner, more general, and better localized alternatives to resource management have been exhausted. My ideal is not to create any garbage, thus eliminating the need for a garbage collector: Do not litter!
Garbage collection is fundamentally a global memory management scheme. Clever implementations can compensate, but as systems are getting more distributed (think caches, multicores, and clusters), locality is more important than ever.
Also, memory is not the only resource. A resource is anything that has to be acquired and (explicitly or implicitly) released after use. Examples are memory, locks, sockets, file handles, and thread handles. Unsurprisingly, a resource that is not just memory is called a non-memory resource. A good resource management system handles all kinds of resources. Leaks must be avoided in any long-running system, but excessive resource retention can be almost as bad as a leak. For example, if a system holds on to memory, locks, files, etc. for twice as long, the system needs to be provisioned with potentially twice as many resources.
Before resorting to garbage collection, systematically use resource handles: let each resource have an owner in some scope and by default be released at the end of its owners scope. In C++, this is known as RAII (Resource Acquisition Is Initialization) and is integrated with error handling in the form of exceptions. Resources can be moved from scope to scope using move semantics or “smart pointers,” and shared ownership can be represented by “shared pointers” (§13.2.1).
In the C++ standard library, RAII is pervasive: for example, memory (string, vector, map, unordered_map, etc.), files (ifstream, ofstream, etc.), threads (thread), locks (lock_guard, unique_lock, etc.), and general objects (through unique_ptr and shared_ptr). The result is implicit resource management that is invisible in common use and leads to low resource retention durations.
5.4 Conventional Operations
Some operations have conventional meanings when defined for a type. These conventional meanings are often assumed by programmers and libraries (notably, the standard library), so it is wise to conform to them when designing new types for which the operations make sense.
Comparisons:
==,!=,<,<=,>, and>=(§5.4.1)Container operations:
size(),begin(), andend()(§5.4.2)Input and output operations:
>>and<<(§5.4.3)User-defined literals (§5.4.4)
swap()(§5.4.5)Hash functions:
hash<>(§5.4.6)
5.4.1 Comparisons
The meaning of the equality comparisons (== and !=) is closely related to copying. After a copy, the copies should compare equal:
X a = something; X b = a; assert(a==b); // if a!=b here, something is very odd (§3.5.4).
When defining ==, also define != and make sure that a!=b means !(a==b).
Similarly, if you define <, also define <=, >, >=, and make sure that the usual equivalences hold:
a<=bmeans(a<b)||(a==b)and!(b<a).a>bmeansb<a.a>=bmeans(a>b)||(a==b)and!(a<b).
To give identical treatment to both operands of a binary operator, such as ==, it is best defined as a free-standing function in the namespace of its class. For example:
namespace NX {
class X {
// ...
};
bool operator==(const X&, const X&);
// ...
};
5.4.2 Container Operations
Unless there is a really good reason not to, design containers in the style of the standard-library containers (Chapter 11). In particular, make the container resource safe by implementing it as a handle with appropriate essential operations (§5.1.1, §5.2).
The standard-library containers all know their number of elements and we can obtain it by calling size(). For example:
for (size_t i = 0; i<c.size(); ++i) // size_t is the name of the type returned by a standard-library size()
c[i] = 0;
However, rather than traversing containers using indices from 0 to size(), the standard algorithms (Chapter 12) rely on the notion of sequences delimited by pairs of iterators:
for (auto p = c.begin(); p!=c.end(); ++p)
*p = 0;
Here, c.begin() is an iterator pointing to the first element of c and c.end() points one-beyond-the-last element of c. Like pointers, iterators support ++ to move to the next element and * to access the value of the element pointed to. This iterator model (§12.3) allows for great generality and efficiency. Iterators are used to pass sequences to standard-library algorithms. For example:
sort(v.begin(),v.end());
For details and more container operations, see Chapter 11 and Chapter 12.
Another way of using the number of elements implicitly is a range-for loop:
for (auto& x : c)
x = 0;
This uses c.begin() and c.end() implicitly and is roughly equivalent to the more explicit loop.
5.4.3 Input and Output Operations
For pairs of integers, << means left-shift and >> means right-shift. However, for iostreams, they are the output and input operator, respectively (§1.8, Chapter 10). For details and more I/O operations, see Chapter 10.
5.4.4 User-Defined Literals
One purpose of classes was to enable the programmer to design and implement types to closely mimic built-in types. Constructors provide initialization that equals or exceeds the flexibility and efficiency of built-in type initialization, but for built-in types, we have literals:
123is anint.0xFF00uis anunsigned int.123.456is adouble."Surprise!"is aconst char[10].
It can be useful to provide such literals for a user-defined type also. This is done by defining the meaning of a suitable suffix to a literal, so we can get
"Surprise!"sis astd::string.123sisseconds.12.7iisimaginaryso that12.7i+47is acomplex number(i.e.,{47,12.7}).
In particular, we can get these examples from the standard library by using suitable headers and namespaces:
Standard-Library Suffixes for Literals |
||
|
|
|
|
|
|
|
|
|
|
|
|
Unsurprisingly, literals with user-defined suffixes are called user-defined literals or UDLs. Such literals are defined using literal operators. A literal operator converts a literal of its argument type, followed by a subscript, into its return type. For example, the i for imaginary suffix might be implemented like this:
constexpr complex<double> operator""i(long double arg) // imaginary literal
{
return {0,arg};
}
Here
The
operator""indicates that we are defining a literal operator.The
iafter the “literal indicator”""is the suffix to which the operator gives a meaning.The argument type,
long double, indicates that the suffix (i) is being defined for a floating-point literal.The return type,
complex<double>, specifies the type of the resulting literal.
Given that, we can write
complex<double> z = 2.7182818+6.283185i;
5.4.5 swap()
Many algorithms, most notably sort(), use a swap() function that exchanges the values of two objects. Such algorithms generally assume that swap() is very fast and doesn’t throw an exception. The standard-library provides a std::swap(a,b) implemented as three move operations: (tmp=a, a=b, b=tmp). If you design a type that is expensive to copy and could plausibly be swapped (e.g., by a sort function), then give it move operations or a swap() or both. Note that the standard-library containers (Chapter 11) and string (§9.2.1) have fast move operations.
5.4.6 hash<>
The standard-library unordered_map<K,V> is a hash table with K as the key type and V as the value type (§11.5). To use a type X as a key, we must define hash<X>. The standard library does that for us for common types, such as std::string.
5.5 Advice
[1] Control construction, copy, move, and destruction of objects; §5.1.1; [CG: R.1].
[2] Design constructors, assignments, and the destructor as a matched set of operations; §5.1.1; [CG: C.22].
[3] Define all essential operations or none; §5.1.1; [CG: C.21].
[4] If a default constructor, assignment, or destructor is appropriate, let the compiler generate it (don’t rewrite it yourself); §5.1.1; [CG: C.20].
[5] If a class has a pointer member, it probably needs a user-defined or deleted destructor, copy and move; §5.1.1; [CG: C.32] [CG: C.33].
[6] If a class has a destructor, it probably needs user-defined or deleted copy and move; §5.2.1.
[7] By default, declare single-argument constructors explicit; §5.1.1; [CG: C.46].
[8] If a class member has a reasonable default value, provide it as a data member initializer; §5.1.3; [CG: C.48].
[9] Redefine or prohibit copying if the default is not appropriate for a type; §5.2.1, §4.6.5; [CG: C.61].
[10] Return containers by value (relying on move for efficiency); §5.2.2; [CG: F.20].
[11] For large operands, use const reference argument types; §5.2.2; [CG: F.16].
[12] Provide strong resource safety; that is, never leak anything that you think of as a resource; §5.3; [CG: R.1].
[13] If a class is a resource handle, it needs a user-defined constructor, a destructor, and non-default copy operations; §5.3; [CG: R.1].
[14] Overload operations to mimic conventional usage; §5.4; [CG: C.160].
[15] Follow the standard-library container design; §5.4.2; [CG: C.100].