Table of Contents for
Modern Java Recipes
 Modern Java Recipes
Published by
O'Reilly Media, Inc., 2017
Modern Java Recipes
Published by
O'Reilly Media, Inc., 2017
- nav
- Cover
- Modern Java Recipes
- Modern Java Recipes
- Dedication
- Foreword
- Preface
- The Basics
- The java.util.function Package
- Streams
- Comparators and Collectors
- Issues with Streams, Lambdas, and Method References
- The Optional Type
- File I/O
- The java.time Package
- Parallelism and Concurrency
- Java 9 Additions
- Generics and Java 8
- Index
- About the Author
- Colophon
Chapter 3. Streams
Java 8 introduces a new streaming metaphor to support functional programming. A stream is a sequence of elements that does not save the elements or modify the original source. Functional programming in Java often involves generating a stream from some source of data, passing the elements through a series of intermediate operations (called a pipeline), and completing the process with a terminal expression.
Streams can only be used once. After a stream has passed through zero or more intermediate operations and reached a terminal operation, it is finished. To process the values again, you need to make a new stream.
Streams are also lazy. A stream will only process as much data as is necessary to reach the terminal condition. Recipe 3.13 shows this in action.
The recipes in this chapter demonstrate various typical stream operations.
3.1 Creating Streams
Solution
Use the static factory methods in the Stream interface, or the stream methods on Iterable or Arrays.
Discussion
The new java.util.stream.Stream interface in Java 8 provides several static methods for creating streams. Specifically, you can use the static methods Stream.of, Stream.iterate, and Stream.generate.
The Stream.of method takes a variable argument list of elements:
static<T>Stream<T>of(T...values)
The implementation of the of method in the standard library actually delegates to the stream method in the Arrays class, shown in Example 3-1.
Example 3-1. Reference implementation of Stream.of
@SafeVarargspublicstatic<T>Stream<T>of(T...values){returnArrays.stream(values);}
Tip
The @SafeVarargs annotation is part of Java generics. It comes up when you have an array as an argument, because it is possible to assign a typed array to an Object array and then violate type safety with an added element. The @SafeVarargs annotation tells the compiler that the developer promises not to do that. See Appendix A for additional details.
As a trivial example, see Example 3-2.
Note
Since streams do not process any data until a terminal expression is reached, each of the examples in this recipe will add a terminal method like collect or forEach at the end.
Example 3-2. Creating a stream using Stream.of
Stringnames=Stream.of("Gomez","Morticia","Wednesday","Pugsley").collect(Collectors.joining(","));System.out.println(names);// prints Gomez,Morticia,Wednesday,Pugsley
The API also includes an overloaded of method that takes a single element T t. This method returns a singleton sequential stream containing a single element.
Speaking of the Arrays.stream method, Example 3-3 shows an example.
Example 3-3. Creating a stream using Arrays.stream
String[]munsters={"Herman","Lily","Eddie","Marilyn","Grandpa"};names=Arrays.stream(munsters).collect(Collectors.joining(","));System.out.println(names);// prints Herman,Lily,Eddie,Marilyn,Grandpa
Since you have to create an array ahead of time, this approach is less convenient, but works well for variable argument lists. The API includes overloads of Arrays.stream for arrays of int, long, and double, as well as the generic type used here.
Another static factory method in the Stream interface is iterate. The signature of the iterate method is:
static<T>Stream<T>iterate(Tseed,UnaryOperator<T>f)
According to the Javadocs, this method “returns an infinite (emphasis added) sequential ordered Stream produced by iterative application of a function f to an initial element seed.” Recall that a UnaryOperator is a function whose single input and output types are the same (discussed in Recipe 2.4). This is useful when you have a way to produce the next value of the stream from the current value, as in Example 3-4.
Example 3-4. Creating a stream using Stream.iterate
List<BigDecimal>nums=Stream.iterate(BigDecimal.ONE,n->n.add(BigDecimal.ONE)).limit(10).collect(Collectors.toList());System.out.println(nums);// prints [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]Stream.iterate(LocalDate.now(),ld->ld.plusDays(1L)).limit(10).forEach(System.out::println)// prints 10 days starting from today
The first example counts from one using BigDecimal instances. The second uses the new LocalDate class in java.time and adds one day to it repeatedly. Since the resulting streams are both unbounded, the intermediate operation limit is needed.
The other factory method in the Stream class is generate, whose signature is:
static<T>Stream<T>generate(Supplier<T>s)
This method produces a sequential, unordered stream by repeatedly invoking the Supplier. A simple example of a Supplier in the standard library (a method that takes no arguments but produces a return value) is the Math.random method, which is used in Example 3-5.
Example 3-5. Creating a stream of random doubles
longcount=Stream.generate(Math::random).limit(10).forEach(System.out::println)
If you already have a collection, you can take advantage of the default method stream that has been added to the Collection interface, as in Example 3-6.1
Example 3-6. Creating a stream from a collection
List<String>bradyBunch=Arrays.asList("Greg","Marcia","Peter","Jan","Bobby","Cindy");names=bradyBunch.stream().collect(Collectors.joining(","));System.out.println(names);// prints Greg,Marcia,Peter,Jan,Bobby,Cindy
There are three child interfaces of Stream specifically for working with primitives: IntStream, LongStream, and DoubleStream. IntStream and LongStream each have two additional factory methods for creating streams, range and rangeClosed. The methods from IntStream and LongStream are:
staticIntStreamrange(intstartInclusive,intendExclusive)staticIntStreamrangeClosed(intstartInclusive,intendInclusive)staticLongStreamrange(longstartInclusive,longendExclusive)staticLongStreamrangeClosed(longstartInclusive,longendInclusive)
The arguments show the difference between the two: rangeClosed includes the end value, and range doesn’t. Each returns a sequential, ordered stream that starts at the first argument and increments by one after that. An example of each is shown in Example 3-7.
Example 3-7. The range and rangeClosed methods
List<Integer>ints=IntStream.range(10,15).boxed().collect(Collectors.toList());System.out.println(ints);// prints [10, 11, 12, 13, 14]List<Long>longs=LongStream.rangeClosed(10,15).boxed().collect(Collectors.toList());System.out.println(longs);// prints [10, 11, 12, 13, 14, 15]
Necessary for
Collectorsto convert primitives toList<T>
The only quirk in that example is the use of the boxed method to convert the int values to Integer instances, which is discussed further in Recipe 3.2.
To summarize, here are the methods to create streams:
-
Stream.of(T... values)andStream.of(T t) -
Arrays.stream(T[] array), with overloads forint[],double[], andlong[] -
Stream.iterate(T seed, UnaryOperator<T> f) -
Stream.generate(Supplier<T> s) -
Collection.stream() -
Using
rangeandrangeClosed:-
IntStream.range(int startInclusive, int endExclusive) -
IntStream.rangeClosed(int startInclusive, int endInclusive) -
LongStream.range(long startInclusive, long endExclusive) -
LongStream.rangeClosed(long startInclusive, long endInclusive)
-
See Also
Streams are used throughout this book. The process of converting streams of primitives to wrapper instances is discussed in Recipe 3.2.
3.2 Boxed Streams
Solution
Use the boxed method on Stream to wrap the elements. Alternatively, map the values using the appropriate wrapper class, or use the three-argument form of the collect method.
Discussion
When dealing with streams of objects, you can convert from a stream to a collection using one of the static methods in the Collectors class. For example, given a stream of strings, you can create a List<String> using the code in Example 3-8.
Example 3-8. Converting a stream of strings to a list
List<String>strings=Stream.of("this","is","a","list","of","strings").collect(Collectors.toList());
The same process doesn’t work on streams of primitives, however. The code in Example 3-9 does not compile.
Example 3-9. Converting a stream of int to a list of Integer (DOES NOT COMPILE)
IntStream.of(3,1,4,1,5,9).collect(Collectors.toList());// does not compile
You have three alternatives available as workarounds. First, use the boxed method on Stream to convert the IntStream to a Stream<Integer>, as shown in Example 3-10.
Example 3-10. Using the boxed method
List<Integer>ints=IntStream.of(3,1,4,1,5,9).boxed().collect(Collectors.toList());
Converts
inttoInteger
One alternative is to use the mapToObj method to convert each element from a primitive to an instance of the wrapper class, as in Example 3-11.
Example 3-11. Using the mapToObj method
List<Integer>ints=IntStream.of(3,1,4,1,5,9).mapToObj(Integer::valueOf).collect(Collectors.toList())
Just as mapToInt, mapToLong, and mapToDouble parse streams of objects into the associated primitives, the mapToObj method from IntStream, LongStream, and DoubleStream converts primitives to instances of the associated wrapper classes. The argument to mapToObj in this example uses the static valueOf method from the Integer class.
Warning
In JDK 9, the Integer(int val) constructor is deprecated for performance reasons. The recommendation is to use Integer.valueOf(int) instead.
Another alternative is to use the three-argument version of collect, whose signature is:
<R>Rcollect(Supplier<R>supplier,ObjIntConsumer<R>accumulator,BiConsumer<R,R>combiner)
Example 3-12 shows how to use this method.
Example 3-12. Using the three-argument version of collect
List<Integer>ints=IntStream.of(3,1,4,1,5,9).collect(ArrayList<Integer>::new,ArrayList::add,ArrayList::addAll);
In this version of collect, the Supplier is the constructor for ArrayList<Integer>, the accumulator is the add method, which represents how to add a single element to a list, and the combiner (which is only used during parallel operations) is addAll, which combines two lists into one. Using the three-argument version of collect is not very common, but understanding how it works is a useful skill.
Any of these approaches work, so the choice is just a matter of style.
Incidentally, if you want to convert to an array rather than a list, then the toArray method works just as well if not better. See Example 3-13.
Example 3-13. Convert an IntStream to an int array
int[]intArray=IntStream.of(3,1,4,1,5,9).toArray();
The fact that any of these approaches is necessary is yet another consequence of the original decision in Java to treat primitives differently from objects, complicated by the introduction of generics. Still, using boxed or mapToObj is easy enough once you know to look for them.
See Also
Collectors are discussed in Chapter 4. Constructor references are covered in Recipe 1.3.
3.3 Reduction Operations Using Reduce
Solution
Use the reduce method to accumulate calculations on each element.
Discussion
The functional paradigm in Java often uses a process known as map-filter-reduce. The map operation transforms a stream of one type (like a String) into another (like an int, by invoking the length method). Then a filter is applied to produce a new stream with only the desired elements in it (e.g., strings with length below a certain threshold). Finally, you may wish to provide a terminal operation that generates a single value from the stream (like a sum or average of the lengths).
Built-in reduction operations
The primitive streams IntStream, LongStream, and DoubleStream have several reduction operations built into the API.
For example, Table 3-1 shows the reduction operations from the IntStream class.
| Method | Return type |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Reduction operations like sum, count, max, min, and average do what you would expect. The only interesting part is that some of them return Optionals, because if there are no elements in the stream (perhaps after a filtering operation) the result is undefined or null.
For example, consider reduction operations involving the lengths of a collection of strings, as in Example 3-14.
Example 3-14. Reduction operations on IntStream
String[]strings="this is an array of strings".split(" ");longcount=Arrays.stream(strings).map(String::length).count();System.out.println("There are "+count+" strings");inttotalLength=Arrays.stream(strings).mapToInt(String::length).sum();System.out.println("The total length is "+totalLength);OptionalDoubleave=Arrays.stream(strings).mapToInt(String::length).average();System.out.println("The average length is "+ave);OptionalIntmax=Arrays.stream(strings).mapToInt(String::length).max();OptionalIntmin=Arrays.stream(strings).mapToInt(String::length).min();System.out.println("The max and min lengths are "+max+" and "+min);
countis aStreammethod, so no need to map toIntStream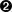
sumandaverageare on the primitive streams only
maxandminwithoutComparatoronly on primitive streams
The program prints:
There are 6 strings The total length is 22 The average length is OptionalDouble[3.6666666666666665] The max and min lengths are OptionalInt[7] and OptionalInt[2]
Note how the average, max, and min methods return Optionals, because in principle you could have applied a filter that removed all the elements from the stream.
The count method is actually quite interesting, and is discussed in Recipe 3.7.
The Stream interface has max(Comparator) and min(Comparator), where the comparators are used to determine the max or min element. In IntStream, there are overloaded versions of both methods that do not need an argument, because the comparison is done using the natural order of integers.
The summaryStatistics method is discussed in Recipe 3.8.
The last two operations in the table, collect and reduce, bear further discussion. The collect method is used throughout this book to convert a stream into a collection, usually in combination with one of the static helper methods in the Collectors class, like toList or toSet. That version of collect does not exist on the primitive streams. The three-argument version shown here takes a collection to populate, a way to add a single element to that collection, and a way to add multiple elements to the collection. An example is shown in Recipe 3.2.
Basic reduce implementations
The behavior of the reduce method, however, is not necessarily intuitive until you’ve seen it in action.
There are two overloaded versions of the reduce method in IntStream:
OptionalInt reduce(IntBinaryOperator op) int reduce(int identity, IntBinaryOperator op)
The first takes an IntBinaryOperator and returns an OptionalInt. The second asks you to supply an int called identity along with an IntBinaryOperator.
Recall that a java.util.function.BiFunction takes two arguments and returns a single value, all three of which can be of different types. If both input types and the return type are all the same, the function is a BinaryOperator (think, for example, Math.max). An IntBinaryOperator is a BinaryOperator where the both inputs and the output type are all ints.
Pretend, for the moment, that you didn’t think to use sum. One way to sum a series of integers would be to use the reduce method shown in Example 3-15.
Example 3-15. Summing numbers using reduce
intsum=IntStream.rangeClosed(1,10).reduce((x,y)->x+y).orElse(0);
The value of
sumis 55
Note
Normally stream pipelines are written vertically, an approach based on a fluent API where the result of one method becomes the target of the next. In this case, the reduce method returns something other than a stream, so orElse is written on the same line rather than below because it’s not part of the pipeline. That’s just a convenience—use any formatting approach that works for you.
The IntBinaryOperator here is supplied by a lambda expression that takes two ints and returns their sum. Since it is conceivable that the stream could be empty if we had added a filter, the result is an OptionalInt. Chaining the orElse method to it indicates that if there are no elements in the stream, the return value should be zero.
In the lambda expression, you can think of the first argument of the binary operator as an accumulator, and the second argument as the value of each element in the stream. This is made clear if you print each one as it goes by, as shown in Example 3-16.
Example 3-16. Printing the values of x and y
intsum=IntStream.rangeClosed(1,10).reduce((x,y)->{System.out.printf("x=%d, y=%d%n",x,y);returnx+y;}).orElse(0);
The output is shown in Example 3-17.
Example 3-17. The output of printing each value as it passes
x=1, y=2 x=3, y=3 x=6, y=4 x=10, y=5 x=15, y=6 x=21, y=7 x=28, y=8 x=36, y=9 x=45, y=10 sum=55
As the output shows, the initial values of x and y are the first two values of the range. The value returned by the binary operator becomes the value of x (i.e., the accumulator) on the next iteration, while y takes on each value in the stream.
This is fine, but what if you wanted to process each number before summing them? Say, for example, you wanted to double all the numbers before summing them.2 A naïve approach would be simply to try the code shown in Example 3-18.
Example 3-18. Doubling the values during the sum (NOTE: NOT CORRECT)
intdoubleSum=IntStream.rangeClosed(1,10).reduce((x,y)->x+2*y).orElse(0);
The value of
doubleSumis 109 (oops! off by one!)
Since the sum of the integers from 1 to 10 is 55, the resulting sum should be 110, but this calculation produces 109. The reason is that in the lambda expression in the reduce method, the initial values of x and y are 1 and 2 (the first two values of the stream), so that first value of the stream doesn’t get doubled.
That’s why there’s an overloaded version of reduce that takes an initial value for the accumulator. The resulting code is shown in Example 3-19.
Example 3-19. Doubling the values during the sum (WORKS)
intdoubleSum=IntStream.rangeClosed(1,10).reduce(0,(x,y)->x+2*y);
The value of
doubleSumis 110, as it should be
By providing the initial value of zero for the accumulator x, the value of y is assigned to each of the elements in the stream, doubling them all. The values of x and y during each iteration are shown in Example 3-20.
Example 3-20. The values of the lambda parameters during each iteration
Acc=0, n=1 Acc=2, n=2 Acc=6, n=3 Acc=12, n=4 Acc=20, n=5 Acc=30, n=6 Acc=42, n=7 Acc=56, n=8 Acc=72, n=9 Acc=90, n=10 sum=110
Note also that when you use the version of reduce with an initial value for the accumulator, the return type is int rather than OptionalInt.
The standard library provides many reduction methods, but if none of them directly apply to your problem, the two forms of the reduce method shown here can be very helpful.
Binary operators in the library
A few methods have been added to the standard library that make reduction operations particularly simple. For example, Integer, Long, and Double all have a sum method that does exactly what you would expect. The implementation of the sum method in Integer is:
publicstaticintsum(inta,intb){returna+b;}
Why bother creating a method just to add two integers, as done here? The sum method is a BinaryOperator (more specifically, an IntBinaryOperator) and can therefore be used easily in a reduce operation, as in Example 3-21.
Example 3-21. Performing a reduce with a binary operator
intsum=Stream.of(1,2,3,4,5,6,7,8,9,10).reduce(0,Integer::sum);System.out.println(sum);
This time you don’t even need an IntStream, but the result is the same. Likewise the Integer class now has a max and a min method, both of which are also binary operators and can be used the same way, as in Example 3-22.
Example 3-22. Finding the max using reduce
Integermax=Stream.of(3,1,4,1,5,9).reduce(Integer.MIN_VALUE,Integer::max);System.out.println("The max value is "+max);
The identity for
maxis the minimum integer
Another interesting example is the concat method in String, which doesn’t actually look like a BinaryOperator because the method only takes a single argument:
Stringconcat(Stringstr)
You can use this in a reduce operation anyway, as shown in Example 3-23.
Example 3-23. Concatenating strings from a stream using reduce
Strings=Stream.of("this","is","a","list").reduce("",String::concat);System.out.println(s);
Prints
thisisalist
The reason this works is that when you use a method reference via the class name (as in String::concat), the first parameter becomes the target of the concat method and the second parameter is the argument to concat. Since the result returns a String, the target, parameter, and return type are all of the same type and once again you can treat this as a binary operator for the reduce method.
This technique can greatly reduce3 the size of your code, so keep that in mind when you’re browsing the API.
The most general form of reduce
The third form of the reduce method is:
<U>Ureduce(Uidentity,BiFunction<U,?superT,U>accumulator,BinaryOperator<U>combiner)
This is a bit more complicated, and there are normally easier ways to accomplish the same goal, but an example of how to use it might be useful.
Consider a Book class with simply an integer ID and a string title, as in Example 3-27.
Example 3-27. A simple Book class
publicclassBook{privateIntegerid;privateStringtitle;// ... constructors, getters and setters, toString, equals, hashCode ...}
Say you have a list of books and you want to add them to a Map, where the keys are the IDs and the values are the books themselves.
Warning
The example shown here can be solved much more easily using the Collectors.toMap method, which is demonstrated in Recipe 4.3. It is used here because its simplicity will hopefully make it easier to focus on the more complex version of reduce.
One way to accomplish that is shown in Example 3-28.
Example 3-28. Accumulating Books into a Map
HashMap<Integer,Book>bookMap=books.stream().reduce(newHashMap<Integer,Book>(),(map,book)->{map.put(book.getId(),book);returnmap;},(map1,map2)->{map1.putAll(map2);returnmap1;});bookMap.forEach((k,v)->System.out.println(k+": "+v));
Identity value for
putAllAccumulate a single book into
MapusingputCombine multiple
Maps usingputAll
It’s easiest to examine the arguments to the reduce method in reverse order.
The last argument is a combiner, which is required to be a BinaryOperator. In this case, the provided lambda expression takes two maps and copies all the keys from the second map into the first one and returns it. The lambda expression would be simpler if the putAll method returned the map, but no such luck. The combiner is only relevant if the reduce operation is done in parallel, because then you need to combine maps produced from each portion of the range.
The second argument is a function that adds a single book to a Map. This too would be simpler if the put method on Map returned the Map after the new entry was added.
The first argument to the reduce method is the identity value for the combiner function. In this case, the identity value is an empty Map, because that combined with any other Map returns the other Map.
The output from this program is:
1: Book{id=1, title='Modern Java Recipes'}
2: Book{id=2, title='Making Java Groovy'}
3: Book{id=3, title='Gradle Recipes for Android'}
Reduction operations are fundamental to the functional programming idiom. In many common cases, the Stream interfaces provide a built-in method for you, like sum or collect(Collectors.joining(','). If you need to write your own, however, this recipe shows how to use the reduce operation directly.
The best news is that once you understand how to use reduce in Java 8, you know how to use the same operation in other languages, even if it goes by different names (like inject in Groovy or fold in Scala). They all work the same way.
See Also
A much simpler way to turn a list of POJOs into a Map is shown in Recipe 4.3. Summary statistics are discussed in Recipe 3.8. Collectors are discussed in Chapter 4.
3.4 Check Sorting Using Reduce
Solution
Use the reduce method to check each pair of elements.
Discussion
The reduce method on Stream takes a BinaryOperator as an argument:
Optional<T>reduce(BinaryOperator<T>accumulator)
A BinaryOperator is a Function where both input types and the output type are all the same. As shown in Recipe 3.3, the first element in the BinaryOperator is normally an accumulator, while the second element takes each value of the stream, as in Example 3-29.
Example 3-29. Summing BigDecimals with reduce
BigDecimaltotal=Stream.iterate(BigDecimal.ONE,n->n.add(BigDecimal.ONE)).limit(10).reduce(BigDecimal.ZERO,(acc,val)->acc.add(val));System.out.println("The total is "+total);
Using the
addmethod inBigDecimalas aBinaryOperator
As usual, whatever is returned by the lambda expression becomes the value of the acc variable on the next iteration. In this way, the calculation accumulates the values of the first 10 BigDecimal instances.
This is the most typical way of using the reduce method, but just because acc here is used as an accumulator doesn’t mean it has to be thought of as such. Consider sorting strings instead, using the approach discussed in Recipe 4.1. The code snippet shown in Example 3-30 sorts strings by length.
Example 3-30. Sorting strings by length
List<String>strings=Arrays.asList("this","is","a","list","of","strings");List<String>sorted=strings.stream().sorted(Comparator.comparingInt(String::length)).collect(toList());
Result is
["a", "is", "of", "this", "list", "strings"]
The question is, how do you test this? Each adjacent pair of strings has to be compared by length to make sure the first is equal to or shorter than the second. The reduce method here works well, however, as Example 3-31 shows (part of a JUnit test case).
Example 3-31. Testing that strings are sorted properly
strings.stream().reduce((prev,curr)->{assertTrue(prev.length()<=curr.length());returncurr;});
Check each pair is sorted properly
currbecomes the next value ofprev
For each consecutive pair, the previous and current parameters are assigned to variables prev and curr. The assertion tests that the previous length is less than or equal to the current length. The important part is that the argument to reduce returns the value of the current string, curr, which becomes the value of prev on the next iteration.
The only thing required to make this work is for the stream to be sequential and ordered, as here.
See Also
The reduce method is discussed in Recipe 3.3. Sorting is discussed in Recipe 4.1.
3.5 Debugging Streams with peek
Discussion
Stream processing consists of a series of zero or more intermediate operations followed by a terminal operation. Each intermediate operation returns a new stream. The terminal operation returns something other than a stream.
Newcomers to Java 8 sometimes find the sequence of intermediate operations on a stream pipeline confusing, because they have trouble visualizing the stream values as they are processed.
Consider a simple method that accepts a start and end range for a stream of integers, doubles each number, and then sums up only the resulting values divisible by 3, as shown in Example 3-32.
Example 3-32. Doubling integers, filtering, and summing
publicintsumDoublesDivisibleBy3(intstart,intend){returnIntStream.rangeClosed(start,end).map(n->n*2).filter(n->n%3==0).sum();}
A simple test could prove that this is working properly:
@TestpublicvoidsumDoublesDivisibleBy3()throwsException{assertEquals(1554,demo.sumDoublesDivisibleBy3(100,120));}
That’s helpful, but doesn’t deliver a lot of insight. If the code wasn’t working, it would be very difficult to figure out where the problem lay.
Imagine that you added a map operation to the pipeline that took each value, printed it, and then returned the value again, as in Example 3-33.
Example 3-33. Adding an identity map for printing
publicintsumDoublesDivisibleBy3(intstart,intend){returnIntStream.rangeClosed(start,end).map(n->{System.out.println(n);returnn;}).map(n->n*2).filter(n->n%3==0).sum();}
Identity map that prints each element before returning it
The result prints the numbers from start to end, inclusive, with one number per line. While you might not want this in production code, it gives you a look inside the stream processing without interfering with it.
This behavior is exactly how the peek method in Stream works. The declaration of the peek method is:
Stream<T>peek(Consumer<?superT>action)
According to the Javadocs, the peek method “returns a stream consisting of the elements of this stream, additionally performing the provided action on each element as they are consumed from the resulting stream.” Recall that a Consumer takes a single input but returns nothing, so any provided Consumer will not corrupt each value as it streams by.
Since peek is an intermediate operation, the peek method can be added multiple times if you wish, as in Example 3-34.
Example 3-34. Using multiple peek methods
publicintsumDoublesDivisibleBy3(intstart,intend){returnIntStream.rangeClosed(start,end).peek(n->System.out.printf("original: %d%n",n)).map(n->n*2).peek(n->System.out.printf("doubled : %d%n",n)).filter(n->n%3==0).peek(n->System.out.printf("filtered: %d%n",n)).sum();}
Print value before doubling
Print value after doubling but before filtering
Print value after filtering but before summing
The result will show each element in its original form, then after it has been doubled, and finally only if it passes the filter. The output is:
original: 100 doubled : 200 original: 101 doubled : 202 original: 102 doubled : 204 filtered: 204 ... original: 119 doubled : 238 original: 120 doubled : 240 filtered: 240
Unfortunately, there’s no easy way to make the peek code optional, so this is a convenient step to use for debugging but should be removed in production code.
3.6 Converting Strings to Streams and Back
Solution
Use the default methods chars and codePoints from the java.lang.CharSequence interface to convert a String into an IntStream. To convert back to a String, use the overload of the collect method on IntStream that takes a Supplier, a BiConsumer representing an accumulator, and a BiConsumer representing a combiner.
Discussion
Strings are collections of characters, so in principle it should be as easy to convert a string into a stream as it is any other collection or array. Unfortunately, String is not part of the Collections framework, and therefore does not implement Iterable, so there is no stream factory method to convert one into a Stream. The other option would be the static stream methods in the java.util.Arrays class, but while there are versions of Arrays.stream for int[], long[], double[], and even T[], there isn’t one for char[]. It’s almost as if the designers of the API didn’t want you to process a String using stream techniques.
Still, there is an approach that works. The String class implements the CharSequence interface, and that interface contains two new methods that produce an IntStream. Both methods are default methods in the interface, so they have an implementation available. The signatures are in Example 3-35.
Example 3-35. Stream methods in java.lang.CharSequence
defaultIntStreamchars()defaultIntStreamcodePoints()
The difference between the two methods has to do with how Java handles UTF-16-encoded characters as opposed to the full Unicode set of code points. If you’re interested, the differences are explained in the Javadocs for java.lang.Character. For the methods shown here, the difference is only in the type of integers returned. The former returns a IntStream consisting of char values from this sequence, while the latter returns an IntStream of Unicode code points.
The opposite question is how to convert a stream of characters back into a String. The Stream.collect method is used to perform a mutable reduction on the elements of a stream to produce a collection. The version of collect that takes a Collector is most commonly used, because the Collectors utility class provides many static methods (like toList, toSet, toMap, joining, and many others discussed in this book) that produce the desired Collector.
Conspicuous by its absence, however, is a Collector that will take a stream of characters and assemble it into a String. Fortunately, that code isn’t difficult to write, using the other overload of collect, which takes a Supplier and two BiConsumer arguments, one as an accumulator and one as a combiner.
This all sounds a lot more complicated than it is in practice. Consider writing a method to check if a string is a palindrome. Palindromes are not case sensitive, and they remove all punctuation before checking whether the resulting string is the same forward as backward. In Java 7 or earlier, Example 3-36 shows one way to write a method that tests strings.
Example 3-36. Checking for palindromes in Java 7 or earlier
publicbooleanisPalindrome(Strings){StringBuildersb=newStringBuilder();for(charc:s.toCharArray()){if(Character.isLetterOrDigit(c)){sb.append(c);}}Stringforward=sb.toString().toLowerCase();Stringbackward=sb.reverse().toString().toLowerCase();returnforward.equals(backward);}
As is typical in code written in a nonfunctional style, the method declares a separate object with mutable state (the StringBuilder instance), then iterates over a collection (the char[] returned by the toCharArray method in String), using an if condition to decide whether to append a value to the buffer. The StringBuilder class also has a reverse method to make checking for palindromes easier, while the String class does not. This combination of mutable state, iteration, and decision statements cries out for an alternative stream-based approach.
That stream-based alternative is shown in Example 3-37.
Example 3-37. Checking for palindromes using Java 8 streams
publicbooleanisPalindrome(Strings){Stringforward=s.toLowerCase().codePoints().filter(Character::isLetterOrDigit).collect(StringBuilder::new,StringBuilder::appendCodePoint,StringBuilder::append).toString();Stringbackward=newStringBuilder(forward).reverse().toString();returnforward.equals(backward);}
Returns an
IntStream
The codePoints method returns an IntStream, which can then be filtered using the same condition as in Example 3-37. The interesting part is in the collect method, whose signature is:
<R>Rcollect(Supplier<R>supplier,BiConsumer<R,?superT>accumulator,BiConsumer<R,R>combiner)
The arguments are:
-
A
Supplier, which produces the resulting reduced object, in this case aStringBuilder. -
A
BiConsumerused to accumulate each element of the stream into the resulting data structure; this example uses theappendCodePointmethod. -
A
BiConsumerrepresenting a combiner, which is a “non-interfering, stateless function” for combining two values that must be compatible with the accumulator; in this case, theappendmethod. Note that the combiner is only used if the operation is done in parallel.
That sounds like a lot, but the advantage in this case is that the code doesn’t have to make a distinction between characters and integers, which is often an issue when working with elements of strings.
Example 3-38 shows a simple test of the method.
Example 3-38. Testing the palindrome checker
privatePalindromeEvaluatordemo=newPalindromeEvaluator();@TestpublicvoidisPalindrome()throwsException{assertTrue(Stream.of("Madam, in Eden, I'm Adam","Go hang a salami; I'm a lasagna hog","Flee to me, remote elf!","A Santa pets rats as Pat taps a star step at NASA").allMatch(demo::isPalindrome));assertFalse(demo.isPalindrome("This is NOT a palindrome"));}
Viewing strings as arrays of characters doesn’t quite fit the functional idioms in Java 8, but the mechanisms in this recipe hopefully show how they can be made to work.
See Also
Collectors are discussed further in Chapter 4, with the case of implementing your own collector the subject of Recipe 4.9. The allMatch method is discussed in Recipe 3.10.
3.7 Counting Elements
Solution
Use either the Stream.count or Collectors.counting methods.
Discussion
This recipe is almost too easy, but does serve to demonstrate a technique that will be revisited later in Recipe 4.6.
The Stream interface has a default method called count that returns a long, which is demonstrated in Example 3-39.
Example 3-39. Counting elements in a stream
longcount=Stream.of(3,1,4,1,5,9,2,6,5).count();System.out.printf("There are %d elements in the stream%n",count);
Prints
There are 9 elements in the stream
One interesting feature of the count method is that the Javadocs show how it is implemented. The docs say, “this is a special case of a reduction and is equivalent to”:
returnmapToLong(e->1L).sum();
First every element in the stream is mapped to 1 as a long. Then the mapToLong method produces a LongStream, which has a sum method. In other words, map all the elements to ones and add them up. Nice and simple.
An alternative is to notice that the Collectors class has a similar method, called counting, shown in Example 3-40.
Example 3-40. Counting the elements using Collectors.counting
count=Stream.of(3,1,4,1,5,9,2,6,5).collect(Collectors.counting());System.out.printf("There are %d elements in the stream%n",count);
The result is the same. The question is, why do this? Why not use the count method on Stream instead?
You can, of course, and arguably should. Where this becomes useful, however, is as a downstream collector, discussed more extensively in Recipe 4.6. As a spoiler, consider Example 3-41.
Example 3-41. Counting string partitioned by length
Map<Boolean,Long>numberLengthMap=strings.stream().collect(Collectors.partitioningBy(s->s.length()%2==0,Collectors.counting()));numberLengthMap.forEach((k,v)->System.out.printf("%5s: %d%n",k,v));//// false: 4// true: 8
Predicate
Downstream collector
The first argument to partitioningBy is a Predicate, used to separate the strings into two categories: those that satisfy the predicate, and those that do not. If that was the only argument to partitioningBy, the result would be a Map<Boolean, List<String>>, where the keys would be the values true and false, and the values would be lists of even- and odd-length strings.
The two-argument overload of partitioningBy used here takes a Predicate followed by a Collector, called a downstream collector, which postprocesses each list of strings returned. This is the use case for the Collectors.counting method. The output now is a Map<Boolean, Long> where the values are the number of even- and odd-length strings in the stream.
Several other methods in Stream have analogs in Collectors methods, which are discussed in that section. In each case, if you are working directly with a stream, use the Stream methods. The Collectors methods are intended for downstream post-processing of a partitioningBy or groupingBy operation.
See Also
Downstream collectors are discussed in Recipe 4.6. Collectors in general are discussed in several recipes included in Chapter 4. Counting is a built-in reduction operation, as discussed in Recipe 3.3.
3.8 Summary Statistics
Discussion
The primitive streams IntStream, DoubleStream, and LongStream add methods to the Stream interface that work for primitive types. One of those methods is summaryStatistics, shown in Example 3-42.
Example 3-42. SummaryStatistics
DoubleSummaryStatisticsstats=DoubleStream.generate(Math::random).limit(1_000_000).summaryStatistics();System.out.println(stats);System.out.println("count: "+stats.getCount());System.out.println("min : "+stats.getMin());System.out.println("max : "+stats.getMax());System.out.println("sum : "+stats.getSum());System.out.println("ave : "+stats.getAverage());
Print using the
toStringmethod
Tip
Java 7 added the capability to use underscores in numerical literals, as in 1_000_000.
A typical run yields:
DoubleSummaryStatistics{count=1000000, sum=499608.317465, min=0.000001,
average=0.499608, max=0.999999}
count: 1000000
min : 1.3938598313334438E-6
max : 0.9999988915490642
sum : 499608.31746475823
ave : 0.49960831746475826
The toString implementation of DoubleSummaryStatistics shows all the values, but the class also has getter methods for the individual quantities: getCount, getSum, getMax, getMin, and getAverage. With one million doubles, it’s not surprising that the minimum is close to zero, the maximum is close to 1, the sum is approximately 500,000, and the average is nearly 0.5.
There are two other interesting methods in the DoubleSummaryStatistics class:
voidaccept(doublevalue)voidcombine(DoubleSummaryStatisticsother)
The accept method records another value into the summary information. The combine method combines two DoubleSummaryStatistics objects into one. They are used when adding data to an instance of the class before computing the results.
As an example, the website Spotrac keeps track of payroll statistics for various sports teams. In the source code for this book you will find a file holding the team salary payroll for all 30 teams in Major League Baseball for the 2017 season, taken from this site.4
The source code in Example 3-43 defines a class called Team that contains an id, a team name, and a total salary.
Example 3-43. Team class contains id, name, and salary
publicclassTeam{privatestaticfinalNumberFormatnf=NumberFormat.getCurrencyInstance();privateintid;privateStringname;privatedoublesalary;// ... constructors, getters and setters ...@OverridepublicStringtoString(){return"Team{"+"id="+id+", name='"+name+'\''+", salary="+nf.format(salary)+'}';}}
After parsing the team salary file, the results are:
Team{id=1, name='Los Angeles Dodgers', salary=$245,269,535.00}
Team{id=2, name='Boston Red Sox', salary=$202,135,939.00}
Team{id=3, name='New York Yankees', salary=$202,095,552.00}
...
Team{id=28, name='San Diego Padres', salary=$73,754,027.00}
Team{id=29, name='Tampa Bay Rays', salary=$73,102,766.00}
Team{id=30, name='Milwaukee Brewers', salary=$62,094,433.00}
There are now two ways to compute the summary statistics on the collection of teams. The first is to use the three-argument collect method as in Example 3-44.
Example 3-44. Collect with a Supplier, accumulator, and combiner
DoubleSummaryStatisticsteamStats=teams.stream().mapToDouble(Team::getSalary).collect(DoubleSummaryStatistics::new,DoubleSummaryStatistics::accept,DoubleSummaryStatistics::combine);
This version of the collect method is discussed in Recipe 4.9. Here it relies on a constructor reference to supply an instance of DoubleSummaryStatistics, the accept method to add another value to an existing DoubleSummaryStatistics object, and the combine method to combine two separate DoubleSummaryStatistics objects into one.
The results are (formatted for easy reading):
30 teams sum = $4,232,271,100.00 min = $62,094,433.00 max = $245,269,535.00 ave = $141,075,703.33
The recipe on downstream collectors (Recipe 4.6) shows an alternative way to compute the same data. In this case, the summary is computed as in Example 3-45.
Example 3-45. Collect using summarizingDouble
teamStats=teams.stream().collect(Collectors.summarizingDouble(Team::getSalary));
The argument to the Collectors.summarizingDouble method is the salary for each team. Either way, the result is the same.
The summary statistics classes are essentially a “poor developer’s” approach to statistics. They’re limited to only the properties shown (count, max, min, sum, and average), but if those are all you need, it’s nice to know the library provides them automatically.5
See Also
Summary statistics is a special form of a reduction operation. Others appear in Recipe 3.3. Downstream collectors are covered in Recipe 4.6. The multi-argument collect method is discussed in Recipe 4.9.
3.9 Finding the First Element in a Stream
Solution
Use the findFirst or findAny method after applying a filter.
Discussion
The findFirst and findAny methods in java.util.stream.Stream return an Optional describing the first element of a stream. Neither takes an argument, implying that any mapping or filtering operations have already been done.
For example, given a list of integers, to find the first even number, apply an even-number filter and then use findFirst, as in Example 3-46.
Example 3-46. Finding the first even integer
Optional<Integer>firstEven=Stream.of(3,1,4,1,5,9,2,6,5).filter(n->n%2==0).findFirst();System.out.println(firstEven);
Prints
Optional[4]
If the stream is empty, the return value is an empty Optional (see Example 3-47).
Example 3-47. Using findFirst on an empty stream
Optional<Integer> firstEvenGT10 = Stream.of(3, 1, 4, 1, 5, 9, 2, 6, 5)
.filter(n -> n > 10)
.filter(n -> n % 2 == 0)
.findFirst();
System.out.println(firstEvenGT10);
Prints
Optional.empty
Since the code returns the first element after applying the filter, you might think that it involves a lot of wasted work. Why apply a modulus operation to all the elements and then pick just the first one? Stream elements are actually processed one by one, so this isn’t a problem. This is discussed in Recipe 3.13.
If the stream has no encounter order, then any element may be returned. In the current example, the stream does have an encounter order, so the “first” even number (in the original example) is always 4, whether we do the search using a sequential or a parallel stream. See Example 3-48.
Example 3-48. Using firstEven in parallel
firstEven=Stream.of(3,1,4,1,5,9,2,6,5).parallel().filter(n->n%2==0).findFirst();System.out.println(firstEven);
Always prints
Optional[4]
That feels bizarre at first. Why would you get the same value back even though several numbers are being processed at the same time? The answer lies in the notion of encounter order.
The API defines encounter order as the order in which the source of data makes its elements available. A List and an array both have an encounter order, but a Set does not.
There is also a method called unordered in BaseStream (which Stream extends) that (optionally!) returns an unordered stream as an intermediate operation, though it may not.
The findAny method returns an Optional describing some element of the stream, or an empty Optional if the stream is empty. In this case, the behavior of the operation is explicitly nondeterministic, meaning it is free to select any element of the stream. This allows optimization in parallel operations.
To demonstrate this, consider returning any element from an unordered, parallel stream of integers. Example 3-49 introduces an artificial delay by mapping each element to itself after a random delay of up to 100 milliseconds.
Example 3-49. Using findAny in parallel after a random delay
publicIntegerdelay(Integern){try{Thread.sleep((long)(Math.random()*100));}catch(InterruptedExceptionignored){}returnn;}// ...Optional<Integer>any=Stream.of(3,1,4,1,5,9,2,6,5).unordered().parallel().map(this::delay).findAny();System.out.println("Any: "+any);
The only exception in Java that it is OK to catch and ignore7
We don’t care about order
Use the common fork-join pool in parallel

Introduce a random delay

Return the first element, regardless of encounter order
The output now could be any of the given numbers, depending on which thread gets there first.
Both findFirst and findAny are short-circuiting, terminal operations. A short-circuiting operation may produce a finite stream when presented with an infinite one. A terminal operation is short-circuiting if it may terminate in finite time even when presented with infinite input.
Note that the examples used in this recipe demonstrate that sometimes parallelization can hurt rather than help performance. Streams are lazy, meaning they will only process as many elements as are necessary to satisfy the pipeline. In this case, since the requirement is simply to return the first element, firing up a fork-join pool is overkill. See Example 3-50.
Example 3-50. Using findAny on sequential and parallel streams
Optional<Integer>any=Stream.of(3,1,4,1,5,9,2,6,5).unordered().map(this::delay).findAny();System.out.println("Sequential Any: "+any);any=Stream.of(3,1,4,1,5,9,2,6,5).unordered().parallel().map(this::delay).findAny();System.out.println("Parallel Any: "+any);
Sequential stream (by default)
Parallel stream
Typical output looks like the following (on an eight-core machine, which therefore uses a fork-join pool with eight threads by default).8
For sequential processing:
main // sequential, so only one thread Sequential Any: Optional[3]
For parallel processing:
ForkJoinPool.commonPool-worker-1 ForkJoinPool.commonPool-worker-5 ForkJoinPool.commonPool-worker-3 ForkJoinPool.commonPool-worker-6 ForkJoinPool.commonPool-worker-7 main ForkJoinPool.commonPool-worker-2 ForkJoinPool.commonPool-worker-4 Parallel Any: Optional[1]
The sequential stream only needs to access one element, which it then returns, short-circuiting the process. The parallel stream fires up eight different threads, finds one element, and shuts them all down. The parallel stream therefore accesses many values it doesn’t need.
Again, the key concept is that of encounter order with streams. If the stream has an encounter order, then findFirst will always return the same value. The findAny method is allowed to return any element, making it more appropriate for parallel operations.
See Also
Lazy streams are discussed in Recipe 3.13. Parallel streams are in Chapter 9.
3.10 Using anyMatch, allMatch, and noneMatch
Discussion
The signatures of the anyMatch, allMatch, and noneMatch methods on Stream are:
booleananyMatch(Predicate<?superT>predicate)booleanallMatch(Predicate<?superT>predicate)booleannoneMatch(Predicate<?superT>predicate)
Each does exactly what it sounds like. As an example, consider a prime number calculator. A number is prime if none of the integers from 2 up to the value minus 1 evenly divide into it.
A trivial way to check if a number is prime is to compute the modulus of the number from every number from 2 up to its square root, rounded up, as in Example 3-51.
Example 3-51. Prime number check
publicbooleanisPrime(intnum){intlimit=(int)(Math.sqrt(num)+1);returnnum==2||num>1&&IntStream.range(2,limit).noneMatch(divisor->num%divisor==0);}
Upper limit for check
Using
noneMatch
The noneMatch method makes the calculation particularly simple.
Two ways to test the calculation are shown in Example 3-52.
Example 3-52. Tests for the prime calculation
privatePrimescalculator=newPrimes();@TestpublicvoidtestIsPrimeUsingAllMatch()throwsException{assertTrue(IntStream.of(2,3,5,7,11,13,17,19).allMatch(calculator::isPrime));}@TestpublicvoidtestIsPrimeWithComposites()throwsException{assertFalse(Stream.of(4,6,8,9,10,12,14,15,16,18,20).anyMatch(calculator::isPrime));}
Use
allMatchfor simplicityTest with composites
The first test invokes the allMatch method, whose argument is a Predicate, on a stream of known primes and returns true only if all the values are prime.
The second test uses anyMatch with a collection of composite (nonprime) numbers, and asserts that none of them satisfy the predicate.
The anyMatch, allMatch, and noneMatch methods are convenient ways to check a stream of values against a particular condition.
You need to be aware of one problematic edge condition. The anyMatch, allMatch, and noneMatch methods don’t necessarily behave intuitively on empty streams, as the tests in Example 3-53 show.
Example 3-53. Testing empty streams
@TestpublicvoidemptyStreamsDanger()throwsException{assertTrue(Stream.empty().allMatch(e->false));assertTrue(Stream.empty().noneMatch(e->true));assertFalse(Stream.empty().anyMatch(e->true));}
For both allMatch and noneMatch, the Javadocs say, “if the stream is empty then true is returned and the predicate is not evaluated,” so in both of these cases the predicate can be anything. For anyMatch, the method returns false on an empty stream. That can lead to very difficult-to-diagnose errors, so be careful.
See Also
Predicates are discussed in Recipe 2.3.
3.11 Stream flatMap Versus map
Solution
Use map if each element is transformed into a single value. Use flatMap if each element will be transformed to multiple values and the resulting stream needs to be “flattened.”
Discussion
Both the map and the flatMap methods on Stream take a Function as an argument. The signature for map is:
<R>Stream<R>map(Function<?superT,?extendsR>mapper)
A Function takes a single input and transforms it into a single output. In the case of map, a single input of type T is transformed into a single output of type R.
Consider a Customer class, where a customer has a name and a collection of Order. To keep things simple, the Order class just has an integer ID. Both classes are shown in Example 3-54.
Example 3-54. A one-to-many relationship
publicclassCustomer{privateStringname;privateList<Order>orders=newArrayList<>();publicCustomer(Stringname){this.name=name;}publicStringgetName(){returnname;}publicList<Order>getOrders(){returnorders;}publicCustomeraddOrder(Orderorder){orders.add(order);returnthis;}}publicclassOrder{privateintid;publicOrder(intid){this.id=id;}publicintgetId(){returnid;}}
Now create a few customers and add some orders, as in Example 3-55.
Example 3-55. Sample customers with orders
Customersheridan=newCustomer("Sheridan");Customerivanova=newCustomer("Ivanova");Customergaribaldi=newCustomer("Garibaldi");sheridan.addOrder(newOrder(1)).addOrder(newOrder(2)).addOrder(newOrder(3));ivanova.addOrder(newOrder(4)).addOrder(newOrder(5));List<Customer>customers=Arrays.asList(sheridan,ivanova,garibaldi);
A map operation is done when there is a one-to-one relationship between the input parameter and the output type. In this case, you can map the customers to names and print them, as in Example 3-56.
Example 3-56. Using map on Customer to name
customers.stream().map(Customer::getName).forEach(System.out::println);
Stream<Customer>Stream<String>Sheridan, Ivanova, Garibaldi
If instead of mapping customers to name, you map them to orders, you get a collection of collections, as in Example 3-57.
Example 3-57. Using map on Customer to orders
customers.stream().map(Customer::getOrders).forEach(System.out::println);customers.stream().map(customer->customer.getOrders().stream()).forEach(System.out::println);
Stream<List<Order>>[Order{id=1}, Order{id=2}, Order{id=3}], [Order{id=4}, Order{id=5}], []Stream<Stream<Order>>
The mapping operation results in a Stream<List<Order>>, where the last list is empty. If you invoke the stream method on the lists of orders, you get a Stream<Stream<Order>>, where the last inner stream is an empty stream.
This is where the flatMap method comes in. The flatMap method has the following signature:
<R>Stream<R>flatMap(Function<?superT,?extendsStream<?extendsR>>mapper)
For each generic argument T, the function produces a Stream<R> rather than just an R. The flatMap method then “flattens” the resulting stream by removing each element from the individual streams and adding them to the output.
Tip
The Function argument to flatMap takes a generic input argument, but produces a Stream of output types.
The code in Example 3-58 demonstrates flatMap.
Example 3-58. Using flatMap on Customer orders
customers.stream().flatMap(customer->customer.getOrders().stream()).forEach(System.out::println);
Stream<Customer>Stream<Order>Order{id=1}, Order{id=2}, Order{id=3}, Order{id=4}, Order{id=5}
The result of the flatMap operation is to produce a Stream<Order>, which has been flattened so you don’t need to worry about the nested streams any more.
The two key concepts for flatMap are:
-
The
Functionargument toflatMapproduces aStreamof output values. -
The resulting stream of streams is flattened into a single stream of results.
If you keep those ideas in mind, you should find the flatMap method quite helpful.
As a final note, the Optional class also has a map method and a flatMap method. See Recipes 6.4 and 6.5 for details.
See Also
The flatMap method is also demonstrated in Recipe 6.5. flatMap in Optional is discussed in Recipe 6.4.
3.12 Concatenating Streams
Discussion
Say you acquire data from several locations, and you want to process every element in all of them using streams. One mechanism you can use is the concat method in Stream, whose signature is:
static<T>Stream<T>concat(Stream<?extendsT>a,Stream<?extendsT>b)
This method creates a lazily concatenated stream that accesses all the elements of the first stream, followed by all the elements of the second stream. As the Javadocs say, the resulting stream is ordered if the input streams are ordered, and the resulting stream is parallel if either of the input streams are parallel. Closing the returned stream also closes the underlying input streams.
Note
Both input streams must hold elements of the same type.
As a simple example of concatenating streams, see Example 3-59.
Example 3-59. Concatenating two streams
@Testpublicvoidconcat()throwsException{Stream<String>first=Stream.of("a","b","c").parallel();Stream<String>second=Stream.of("X","Y","Z");List<String>strings=Stream.concat(first,second).collect(Collectors.toList());List<String>stringList=Arrays.asList("a","b","c","X","Y","Z");assertEquals(stringList,strings);}
First elements followed by second elements
If you want to add a third stream to the mix, you can nest the concatenations, Example 3-60.
Example 3-60. Concatenating multiple streams
@TestpublicvoidconcatThree()throwsException{Stream<String>first=Stream.of("a","b","c").parallel();Stream<String>second=Stream.of("X","Y","Z");Stream<String>third=Stream.of("alpha","beta","gamma");List<String>strings=Stream.concat(Stream.concat(first,second),third).collect(Collectors.toList());List<String>stringList=Arrays.asList("a","b","c","X","Y","Z","alpha","beta","gamma");assertEquals(stringList,strings);}
This nesting approach works, but the Javadocs contain a note about this:
Use caution when constructing streams from repeated concatenation. Accessing an element of a deeply concatenated stream can result in deep call chains, or even
StackOverflowException
The idea is that the concat method essentially builds a binary tree of streams, which can grow unwieldy if too many are used.
An alternative approach is to use the reduce method to perform multiple concatenations, as in Example 3-61.
Example 3-61. Concatenating with reduce
@Testpublicvoidreduce()throwsException{Stream<String>first=Stream.of("a","b","c").parallel();Stream<String>second=Stream.of("X","Y","Z");Stream<String>third=Stream.of("alpha","beta","gamma");Stream<String>fourth=Stream.empty();List<String>strings=Stream.of(first,second,third,fourth).reduce(Stream.empty(),Stream::concat).collect(Collectors.toList());List<String>stringList=Arrays.asList("a","b","c","X","Y","Z","alpha","beta","gamma");assertEquals(stringList,strings);}
Using
reducewith an empty stream and a binary operator
This works because the concat method when used as a method reference is a binary operator. Note this is simpler code, but doesn’t fix the potential stack overflow problem.
Instead, when combining streams, the flatMap method is a natural solution, as in Example 3-62.
Example 3-62. Using flatMap to concatenate streams
@TestpublicvoidflatMap()throwsException{Stream<String>first=Stream.of("a","b","c").parallel();Stream<String>second=Stream.of("X","Y","Z");Stream<String>third=Stream.of("alpha","beta","gamma");Stream<String>fourth=Stream.empty();List<String>strings=Stream.of(first,second,third,fourth).flatMap(Function.identity()).collect(Collectors.toList());List<String>stringList=Arrays.asList("a","b","c","X","Y","Z","alpha","beta","gamma");assertEquals(stringList,strings);}
This approach works, but also has its quirks. Using concat creates a parallel stream if any of the input streams are parallel, but flatMap does not (Example 3-63).
Example 3-63. Parallel or not?
@TestpublicvoidconcatParallel()throwsException{Stream<String>first=Stream.of("a","b","c").parallel();Stream<String>second=Stream.of("X","Y","Z");Stream<String>third=Stream.of("alpha","beta","gamma");Stream<String>total=Stream.concat(Stream.concat(first,second),third);assertTrue(total.isParallel());}@TestpublicvoidflatMapNotParallel()throwsException{Stream<String>first=Stream.of("a","b","c").parallel();Stream<String>second=Stream.of("X","Y","Z");Stream<String>third=Stream.of("alpha","beta","gamma");Stream<String>fourth=Stream.empty();Stream<String>total=Stream.of(first,second,third,fourth).flatMap(Function.identity());assertFalse(total.isParallel());}
Still, you can always make the stream parallel if you want by calling the parallel method, as long as you have not yet processed the data (Example 3-64).
Example 3-64. Making a flatMap stream parallel
@TestpublicvoidflatMapParallel()throwsException{Stream<String>first=Stream.of("a","b","c").parallel();Stream<String>second=Stream.of("X","Y","Z");Stream<String>third=Stream.of("alpha","beta","gamma");Stream<String>fourth=Stream.empty();Stream<String>total=Stream.of(first,second,third,fourth).flatMap(Function.identity());assertFalse(total.isParallel());total=total.parallel();assertTrue(total.isParallel());}
Since flatMap is an intermediate operation, the stream can still be modified using the parallel method, as shown.
In short, the concat method is effective for two streams, and can be used as part of a general reduction operation, but flatMap is a natural alternative.
See Also
See the excellent blog post online at http://bit.ly/efficient-multistream-concatentation for details, performance considerations, and more.
The flatMap method on Stream is discussed in Recipe 3.11.
3.13 Lazy Streams
Discussion
When you first encounter stream processing, it’s tempting to think that much more effort is being expended than necessary. For example, consider taking a range of numbers between 100 and 200, doubling each of them, and then finding the first value that is evenly divisible by three, as in Example 3-65.9
Example 3-65. First double between 200 and 400 divisible by 3
OptionalIntfirstEvenDoubleDivBy3=IntStream.range(100,200).map(n->n*2).filter(n->n%3==0).findFirst();System.out.println(firstEvenDoubleDivBy3);
Prints
Optional[204]
If you didn’t know better, you might think a lot of wasted effort was expended:
-
The range of numbers from 100 to 199 is created (100 operations)
-
Each number is doubled (100 operations)
-
Each number is checked for divisibility (100 operations)
-
The first element of the resulting stream is returned (1 operation)
Since the first value that satisfies the stream requirements is 204, why process all the other numbers?
Fortunately, stream processing doesn’t work that way. Streams are lazy, in that no work is done until the terminal condition is reached, and then each element is processed through the pipeline individually. To demonstrate this, Example 3-66 shows the same code, but refactored to show each element as it passes through the pipeline.
Example 3-66. Explicit processing of each stream element
publicintmultByTwo(intn){System.out.printf("Inside multByTwo with arg %d%n",n);returnn*2;}publicbooleandivByThree(intn){System.out.printf("Inside divByThree with arg %d%n",n);returnn%3==0;}// ...firstEvenDoubleDivBy3=IntStream.range(100,200).map(this::multByTwo).filter(this::divByThree).findFirst();
Method reference for multiply by two, with print
Method reference for modulus 3, with print
The output this time is:
Inside multByTwo with arg 100 Inside divByThree with arg 200 Inside multByTwo with arg 101 Inside divByThree with arg 202 Inside multByTwo with arg 102 Inside divByThree with arg 204 First even divisible by 3 is Optional[204]
The value 100 goes through the map to produce 200, but does not pass the filter, so the stream moves to the value 101. That is mapped to 202, which also doesn’t pass the filter. Then the next value, 102, is mapped to 204, but that is divisible by 3, so it passes. The stream processing terminates after processing only three values, using six operations.
This is one of the great advantages of stream processing over working with collections directly. With a collection, all of the operations would have to be performed before moving to the next step. With streams, the intermediate operations form a pipeline, but nothing happens until the terminal operation is reached. Then the stream processes only as many values as are necessary.
This isn’t always relevant—if any of the operations are stateful, like sorting or adding them all together, then all the values are going to have to be processed anyway. But when you have stateless operations followed by a short-circuiting, terminal operation, the advantage is clear.
See Also
The differences between findFirst and findAny are discussed in Recipe 3.9.
1 Hopefully it doesn’t destroy my credibility entirely to admit that I was able to recall the names of all six Brady Bunch kids without looking them up. Believe me, I’m as horrified as you are.
2 There are many ways to solve this problem, including just doubling the value returned by the sum method. The approach taken here illustrates how to use the two-argument form of reduce.
3 Sorry about the pun.
4 Source: http://www.spotrac.com/mlb/payroll/, where you can specify a year or other information.
5 Of course, another lesson of this recipe is that if you can find a way to play Major League Baseball, you probably ought to consider it, even if only for a short time. Java will still be here when you’re done.
6 Thanks to Stuart Marks for this explanation.
7 To be serious for a moment, it’s not a good idea to catch and ignore any exception. It’s just fairly common to do so with InterruptedException. That doesn’t make it a great idea, though.
8 This demo assumes that the delay method has been modified to print the name of the current thread along with the value it is processing.
9 Thanks to the inimitable Venkat Subramaniam for the basis of this example.