Table of Contents for
sed & awk, 2nd Edition
 sed & awk, 2nd Edition
Published by
O'Reilly Media, Inc., 1997
sed & awk, 2nd Edition
Published by
O'Reilly Media, Inc., 1997
- sed & awk, 2nd Edition
- Cover
- sed & awk, 2nd Edition
- A Note Regarding Supplemental Files
- Dedication
- Preface
- Scope of This Handbook
- Availability of sed and awk
- Obtaining Example Source Code
- Conventions Used in This Handbook
- About the Second Edition
- Acknowledgments from the First Edition
- Comments and Questions
- 1. Power Tools for Editing
- 1.1. May You Solve Interesting Problems
- 1.2. A Stream Editor
- 1.3. A Pattern-Matching Programming Language
- 1.4. Four Hurdles to Mastering sed and awk
- 2. Understanding Basic Operations
- 2.1. Awk, by Sed and Grep, out of Ed
- 2.2. Command-Line Syntax
- 2.3. Using sed
- 2.4. Using awk
- 2.5. Using sed and awk Together
- 3. Understanding Regular Expression Syntax
- 3.1. That’s an Expression
- 3.2. A Line-Up of Characters
- 3.3. I Never Metacharacter I Didn’t Like
- 4. Writing sed Scripts
- 4.1. Applying Commands in a Script
- 4.2. A Global Perspective on Addressing
- 4.3. Testing and Saving Output
- 4.4. Four Types of sed Scripts
- 4.5. Getting to the PromiSed Land
- 5. Basic sed Commands
- 5.1. About the Syntax of sed Commands
- 5.2. Comment
- 5.3. Substitution
- 5.4. Delete
- 5.5. Append, Insert, and Change
- 5.6. List
- 5.7. Transform
- 5.8. Print
- 5.9. Print Line Number
- 5.10. Next
- 5.11. Reading and Writing Files
- 5.12. Quit
- 6. Advanced sed Commands
- 6.1. Multiline Pattern Space
- 6.2. A Case for Study
- 6.3. Hold That Line
- 6.4. Advanced Flow Control Commands
- 6.5. To Join a Phrase
- 7. Writing Scripts for awk
- 7.1. Playing the Game
- 7.2. Hello, World
- 7.3. Awk’s Programming Model
- 7.4. Pattern Matching
- 7.5. Records and Fields
- 7.6. Expressions
- 7.7. System Variables
- 7.8. Relational and Boolean Operators
- 7.9. Formatted Printing
- 7.10. Passing Parameters Into a Script
- 7.11. Information Retrieval
- 8. Conditionals, Loops, and Arrays
- 8.1. Conditional Statements
- 8.2. Looping
- 8.3. Other Statements That Affect Flow Control
- 8.4. Arrays
- 8.5. An Acronym Processor
- 8.6. System Variables That Are Arrays
- 9. Functions
- 9.1. Arithmetic Functions
- 9.2. String Functions
- 9.3. Writing Your Own Functions
- 10. The Bottom Drawer
- 10.1. The getline Function
- 10.2. The close( ) Function
- 10.3. The system( ) Function
- 10.4. A Menu-Based Command Generator
- 10.5. Directing Output to Files and Pipes
- 10.6. Generating Columnar Reports
- 10.7. Debugging
- 10.8. Limitations
- 10.9. Invoking awk Using the #! Syntax
- 11. A Flock of awks
- 11.1. Original awk
- 11.2. Freely Available awks
- 11.3. Commercial awks
- 11.4. Epilogue
- 12. Full-Featured Applications
- 12.1. An Interactive Spelling Checker
- 12.2. Generating a Formatted Index
- 12.3. Spare Details of the masterindex Program
- 13. A Miscellany of Scripts
- 13.1. uutot.awk—Report UUCP Statistics
- 13.2. phonebill—Track Phone Usage
- 13.3. combine—Extract Multipart uuencoded Binaries
- 13.4. mailavg—Check Size of Mailboxes
- 13.5. adj—Adjust Lines for Text Files
- 13.6. readsource—Format Program Source Files for troff
- 13.7. gent—Get a termcap Entry
- 13.8. plpr—lpr Preprocessor
- 13.9. transpose—Perform a Matrix Transposition
- 13.10. m1—Simple Macro Processor
- A. Quick Reference for sed
- A.1. Command-Line Syntax
- A.2. Syntax of sed Commands
- A.3. Command Summary for sed
- B. Quick Reference for awk
- B.1. Command-Line Syntax
- B.2. Language Summary for awk
- B.3. Command Summary for awk
- C. Supplement for Chapter 12
- C.1. Full Listing of spellcheck.awk
- C.2. Listing of masterindex Shell Script
- C.3. Documentation for masterindex
- masterindex
- C.3.1. Background Details
- C.3.2. Coding Index Entries
- C.3.3. Output Format
- C.3.4. Compiling a Master Index
- Index
- About the Authors
- Colophon
- Copyright
Applying Commands in a Script
Combining a series of edits in a script can have unexpected results. You might not think of the consequences one edit can have on another. New users typically think that sed applies an individual editing command to all lines of input before applying the next editing command. But the opposite is true. Sed applies the entire script to the first input line before reading the second input line and applying the editing script to it. Because sed is always working with the latest version of the original line, any edit that is made changes the line for subsequent commands. Sed doesn’t retain the original. This means that a pattern that might have matched the original input line may no longer match the line after an edit has been made.
Let’s look at an example that uses the substitute command. Suppose someone quickly wrote the following script to change “pig” to “cow” and “cow” to “horse”:
s/pig/cow/g s/cow/horse/g
What do you think happened? Try it on a sample file. We’ll discuss what happened later, after we look at how sed works.
The Pattern Space
Sed maintains a pattern space, a workspace or temporary buffer where a single line of input is held while the editing commands are applied.[1] The transformation of the pattern space by a two-line script is shown in Figure 4.1. It changes “The Unix System” to “The UNIX Operating System.”
Initially, the pattern space contains a copy of a single input line. In Figure 4.1, that line is “The Unix System.” The normal flow through the script is to execute each command on that line until the end of the script is reached. The first command in the script is applied to that line, changing “Unix” to “UNIX.” Then the second command is applied, changing “UNIX System” to “UNIX Operating System.”[2] Note that the pattern for the second substitute command does not match the original input line; it matches the current line as it has changed in the pattern space.
When all the instructions have been applied, the current line is output and the next line of input is read into the pattern space. Then all the commands in the script are applied to that line.
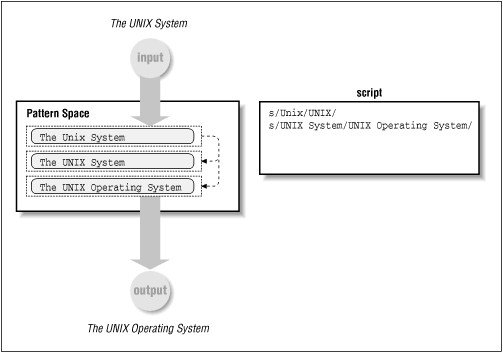
As a consequence, any sed command might change the contents of the pattern space for the next command. The contents of the pattern space are dynamic and do not always match the original input line. That was the problem with the sample script at the beginning of this chapter. The first command would change “pig” to “cow” as expected. However, when the second command changed “cow” to “horse” on the same line, it also changed the “cow” that had been a “pig.” So, where the input file contained pigs and cows, the output file has only horses!
This mistake is simply a problem of the order of the commands in the script. Reversing the order of the commands—changing “cow” into “horse” before changing “pig” into “cow”—does the trick.
s/cow/horse/g s/pig/cow/g
Some sed commands change the flow through the script, as we will see in subsequent chapters. For example, the N command reads another line into the pattern space without removing the current line, so you can test for patterns across multiple lines. Other commands tell sed to exit before reaching the bottom of the script or to go to a labeled command. Sed also maintains a second temporary buffer called the hold space. You can copy the contents of the pattern space to the hold space and retrieve them later. The commands that make use of the hold space are discussed in Chapter 6.
[1] One advantage of the one-line-at-a-time design is that sed can read very large files without any problems. Screen editors that have to read the entire file into memory, or some large portion of it, can run out of memory or be extremely slow to use in dealing with large files.
[2] Yes, we could have changed “Unix System” to “UNIX Operating System” in one step. However, the input file might have instances of “UNIX System” as well as “Unix System.” So by changing “Unix” to “UNIX” we make both instances consistent before changing them to “UNIX Operating System.”