Table of Contents for
Rapid Cybersecurity Ops
 Rapid Cybersecurity Ops
Published by
O'Reilly Media, Inc., 2019
Rapid Cybersecurity Ops
Published by
O'Reilly Media, Inc., 2019
Chapter 5. Data Processing
In the previous chapter you gathered lots of data. Likely that data is in a variety of formats including free-form text, comma separated values (CSV), and Extensible Markup Language (XML). In this chapter we show you how to parse and manipulate that data so you can extract key elements for analysis.
Commands in Use
We introduce awk, join, sed, tail, and tr to prepare data for analysis.
awk
Awk is not just a command, but actually a programming language designed for processing text. There are entire books dedicated to this subject. Awk will be explained in more detail throughout this book, but here we provide just a brief example of its usage.
Common Command Options
- -f
-
Read in the
awkprogram from a specified file
Command Example
Take the file awkusers.txt:
Example 5-1. awkusers.txt
Mike Jones John Smith Kathy Jones Jane Kennedy Tim Scott
You can use awk to print each line where the user’s last name is Jones.
$ awk '$2 == "Jones" {print $0}' awkusers.txt
Mike Jones
Kathy Jones
Awk will iterate through each line of the input file reading in each word (separated by whitespace by default) into fields. Field $0 represents the entire line, $1 the first word, $2 the second word, etc.
An awk program consists of patterns and corresponding code to be executed when that pattern is matched.
In this example there is only one pattern. We test $2 to see if that field is equal to Jones. If it is, awk will run the code in the braces which, in this case, will print the entire line.
Note
If we left off the explicit comparison and instead wrote awk ' /Jones/ {print $0}' then the string inside the slashes is a regular expression to match anywhere in the input line. It would print all the names as before, but it would also find lines where Jones might be the first name or part of a longer name (such as “Jonestown”).
join
Join combines the lines of two files that share a common field. In order for join to function properly the input files must be sorted.
Common Command Options
- -j
-
Join using the specified field number. Fields start at 1.
- -t
-
Specify the character to use as the field separator. Space is the default field separator.
- --header
-
Use the first line of each file as a header.
Command Example
Take the following files:
Example 5-2. usernames.txt
1,jdoe 2,puser 3,jsmith
Example 5-3. accesstime.txt
0745,file1.txt,1 0830,file4.txt,2 0830,file5.txt,3
Both files share a common field of data, which is the user ID. In accesstime.txt the user ID is in the third column. In usernames.txt the user ID is in the first column. You can merge these two files using join as follows:
$ join -1 3 -2 1 -t, accesstime.txt usernames.txt 1,0745,file1.txt,jdoe 2,0830,file4.txt,puser 3,0830,file5.txt,jsmith
The -1 3 option tells join to use the third column in the first file (accesstime.txt), and -2 1 specifies the first column in the second file (usernames.txt) for use when merging the files. The -t, option specifies the comma character as the field delimiter.
sed
Sed allows you to perform edits, such as replacing characters, on a stream of data.
Common Command Options
- -i
-
Edit the specified file and overwrite in place
Command Example
The sed command is quite powerful and can be used for a variety of functions, however, replacing characters or sequences of characters is one of the most common. Take the file ips.txt:
Example 5-4. ips.txt
ip,OS 10.0.4.2,Windows 8 10.0.4.35,Ubuntu 16 10.0.4.107,macOS 10.0.4.145,macOS
You can use sed to replace all of the instances of the 10.0.4.35 IP address with 10.0.4.27.
$ sed 's/10\.0\.4\.35/10.0.4.27/g' ips.txt ip,OS 10.0.4.2,Windows 8 10.0.4.27,Ubuntu 16 10.0.4.107,macOS 10.0.4.145,macOS
In this example, sed uses the following format with each component separated by a forward slash:
s/<regular expression>/<replace with>/<flags/
The first part of the command (s) tells sed to substitute. The second part of the command (10\.0\.4\.35) is a regular expression pattern. The third part (10.0.4.27) is the value to use to replace the regex pattern matches. The forth part is optional flags, which in this case (g, for global) tells sed to replace all instances on a line (not just the first) that match the regex pattern.
tail
The tail command is used to output the last lines of a file. By default tail will output the last 10 lines of a file.
Common Command Options
- -f
-
Continuously monitor the file and output lines as they are added
- -n
-
Output the number lines specified
Command Example
To output the last line in the somefile.txt file:
$ tail -n 1 somefile.txt 12/30/2017 192.168.10.185 login.html
tr
The tr command is used to translate or map from one character to another. It is also often used to delete unwanted or extraneous characters. It only reads from stdin and writes to stdout so you typically see it with redirects for the input and output files.
Common Command Options
- -d
-
delete the specified characters from the input stream
- -s
-
squeeze, that is, replace repeated instances of a character with a single instance
Command Example
You can translate all the backslashes into forward slashes and all the colons to vertical bars with the tr command:
tr'\\:''/|'< infile.txt > outfile.txt
If the contents of infile.txt looked like this:
drive:path\name c:\Users\Default\file.txt
then after running the tr command, outfile.txt would contain this:
drive|path/name c|/Users/Default/file.txt
The characters from the first argument are mapped to the corresponding characters in the second argument. Two backslashes are needed to specify a single backslash character because the backslash has a special meaning to tr; it is used to indicate special characters line newline \n or return \r or tab \t. You use the single quotes around the arguments to avoid any special interpretation by bash.
Tip
Files from Windows systems often come with both a Carriage Return and a Line Feed (CR & LF) character at the end of each line. Linux and macOS systems will have only the newline character to end a line. If you transfer a file to Linux and want to get rid of those extra return characters, here is how you might do that with the tr command:
tr -d '\r' < fileWind.txt > fileFixed.txt
Conversely, you can convert Linux line endings to Windows line endings using sed:
$ sed -i 's/$/\r/' fileLinux.txt
The -i option makes the changes in place and writes them back to the input file.
Processing Delimited Files
Many of the files you will collect and process are likely to contain text, which makes the ability to manipulate text from the command line a critical skill. Text files are often broken into fields using a delimiter such as a space, tab, or comma. One of the more common formats is known as Comma Separated Values (CSV). As the name indicates, CSV files are delimited using commas, and fields may or may not be surrounded in double quotes ("). The first line of a CSV file is often the field headers. Here is an example:
Example 5-5. csvex.txt
"name","username","phone","password hash" "John Smith","jsmith","555-555-1212",5f4dcc3b5aa765d61d8327deb882cf99 "Jane Smith","jnsmith","555-555-1234",e10adc3949ba59abbe56e057f20f883e "Bill Jones","bjones","555-555-6789",d8578edf8458ce06fbc5bb76a58c5ca4
To extract just the name from the file you can use cut by specifying the field delimiter as a comma and the field number you would like returned.
$ cut -d',' -f1 csvex.txt "name" "John Smith" "Jane Smith" "Bill Jones"
Note that the field values are still enclosed in double quotations. This may not be desirable for certain applications. To remove the quotations you can simply pipe the output into tr with its -d option.
$ cut -d',' -f1 csvex.txt | tr -d '"' name John Smith Jane Smith Bill Jones
You can further process the data by removing the field header using the tail command’s -n option.
$ cut -d',' -f1 csvex.txt | tr -d '"' | tail -n +2 John Smith Jane Smith Bill Jones
The -n +2 option tells tail to output the contents of the file starting at line number 2, thus removing the field header.
Tip
You can also give cut a list of fields to extract, such as -f1-3 to extract fields 1 through 3, or a list such as -f1,4 to extract fields 1 and 4.
Iterating Through Delimited Data
While you can use cut to extract entire columns of data, there are instances where you will want to process the file and extract fields line-by-line; in this case you are better off using awk.
Let’s suppose you want to check each user’s password hash in csvex.txt against the dictionary file of known passwords passwords.txt.
Example 5-6. csvex.txt
"name","username","phone","password hash" "John Smith","jsmith","555-555-1212",5f4dcc3b5aa765d61d8327deb882cf99 "Jane Smith","jnsmith","555-555-1234",e10adc3949ba59abbe56e057f20f883e "Bill Jones","bjones","555-555-6789",d8578edf8458ce06fbc5bb76a58c5ca4
Example 5-7. passwords.txt
password,md5hash 123456,e10adc3949ba59abbe56e057f20f883e password,5f4dcc3b5aa765d61d8327deb882cf99 welcome,40be4e59b9a2a2b5dffb918c0e86b3d7 ninja,3899dcbab79f92af727c2190bbd8abc5 abc123,e99a18c428cb38d5f260853678922e03 123456789,25f9e794323b453885f5181f1b624d0b 12345678,25d55ad283aa400af464c76d713c07ad sunshine,0571749e2ac330a7455809c6b0e7af90 princess,8afa847f50a716e64932d995c8e7435a qwerty,d8578edf8458ce06fbc5bb76a58c5c
You can extract each user’s hash from csvex.txt using awk as follows:
$ awk -F "," '{print $4}' csvex.txt
"password hash"
5f4dcc3b5aa765d61d8327deb882cf99
e10adc3949ba59abbe56e057f20f883e
d8578edf8458ce06fbc5bb76a58c5ca4
By default awk uses the space character as a field delimiter, so the -F option is used to identify a custom field delimiter (,) and then print out the forth field ($4) which is the password hash. You can then use grep to take the output from awk one line at a time and search for it in the passwords.txt dictionary file, outputting any matches.
$ grep "$(awk -F "," '{print $4}' csvex.txt)" passwords.txt
123456,e10adc3949ba59abbe56e057f20f883e
password,5f4dcc3b5aa765d61d8327deb882cf99
qwerty,d8578edf8458ce06fbc5bb76a58c5ca4
Processing by Character Position
If a file has fixed-width field sizes you can use the cut command’s -c option to extract data by character position. In csvex.txt the (U.S. 10-digit) phone number is an example of a fixed-width field.
$ cut -d',' -f3 csvex.txt | cut -c2-13 | tail -n +2 555-555-1212 555-555-1234 555-555-6789
Here you first use cut in delimited mode to extract the phone number at field 3. Since each phone number is the same number of characters you can use the cut character position option (-c) to extract the characters in between the quotations. Finally, tail is used to remove the file header.
Processing XML
Extensible Markup Language (XML) allows you to arbitrarily create tags and elements that describe data. Below is an example XML document.
Example 5-8. book.xml
<booktitle="Rapid Cybersecurity Ops"edition="1"><author><firstName>Paul</firstName><lastName>Troncone</lastName></author><author><firstName>Carl</firstName><lastName>Albing</lastName></author></book>
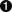
This is a start tag that contains two attributes, also known as name/value pairs. Attribute values must always be quoted.
This is a start tag.

This is an element that has content.

This is an end tag.
For useful processing, you must be able to search through the XML and extract data from within the tags, which can be done using grep. Lets find all of the firstName elements. The -o option is used so only the text that matches the regex pattern will be returned, rather than the entire line.
$ grep -o '<firstName>.*<\/firstName>' book.xml <firstName>Paul</firstName> <firstName>Carl</firstName>
Note that the regex pattern above will only find the XML element if the start and end tags are on the same line. To find the pattern across multiple lines you need to make use of two special features. First, add the -z option to grep, which treats newlines like any ordinary character in its searching and adds a null (ASCII 0) at the end of each string it finds. Then add the -P option and (?s) to the regex pattern, which is a Perl-specific pattern match modifier. It modifies the . metacharacter to also match on the newline character.
$ grep -Pzo '(?s)<author>.*?<\/author>' book.xml <author> <firstName>Paul</firstName> <lastName>Troncone</lastName> </author><author> <firstName>Carl</firstName> <lastName>Albing</lastName> </author>
Warning
The -P option is not available for all versions of grep including those included with macOS.
To strip the XML start and end tags and extract the content you can pipe your output into sed.
$ grep -Po '<firstName>.*?<\/firstName>' book.xml | sed 's/<[^>]*>//g' Paul Carl
The sed expression can be described as s/expr/other/ to replace (or substitute) some expression (expr) with something else (other). The expression can be just literal characters or a more complex regex. If an expression has no “other” portion, such as s/expr// then it replaces anything that matches the regular expression with nothing, essentially removing it. The regex pattern we use in the above example, namely the <[^>]*> expression, is a little confusing, so lets break it down.
< - The pattern begins with a literal less-than character <
[^>]* - Zero or more (indicated by the asterisk) characters from the set of characters inside the brackets; the first character is a ^ which means “not” any of the remaining characters listed. Here that’s just the solitary greater-than character, so [^>] matches any character that is not >
> - The pattern ends with a literal >
This should match a single XML tag, from its opening less-than to its closing greater-than character, but not more than that.
Processing JSON
JavaScript Object Notation (JSON) is another popular file format, particularly for exchanging data through Application Programming Interfaces (APIs). JSON is a simple format that consists of objects, arrays, and name/value pairs. Here is a sample JSON file:
Example 5-9. book.json
{"title":"Rapid Cybersecurity Ops","edition":1,"authors":[{"firstName":"Paul","lastName":"Troncone"},{"firstName":"Carl","lastName":"Albing"}]}
This is an object. Objects begin with
{and end with}.This is a name/value pair. Values can be a string, number, array, boolean, or null.
This is an array. Arrays begin with
[and end with].
Tip
For more information on the JSON format visit http://json.org/
When processing JSON you are likely going to want to extract key/value pairs. To do that you can use grep. Lets extract the firstName key/value pair from book.json.
$ grep -o '"firstName": ".*"' book.json "firstName": "Paul" "firstName": "Carl"
Again, the -o option is used to return only the characters that match the pattern rather than the entire line of the file.
If you want to remove the key and only display the value you can do so by piping the output into cut, extracting the second field, and removing the quotations with tr.
$ grep -o '"firstName": ".*"' book.json | cut -d " " -f2 | tr -d '\"' Paul Carl
We will perform more advanced processing of JSON in a later chapter.
Aggregating Data
Data is often collected from a variety of sources, and in a variety of files and formats. Before you can analyze the data you must get it all into the same place and in a format that is conducive to analysis.
Suppose you want to search a treasure trove of data files for any system named ProductionWebServer. Recall that in previous scripts we wrapped our collected data in XML tags with the following format: '<systeminfo host="">. During collection we also named our files using the host name. You can now use either of those attributes to find and aggregate the data into a single location.
find /data -type f -exec grep '{}' -e 'ProductionWebServer' \;
-exec cat '{}' >> ProductionWebServerAgg.txt \;
The command find /data -type f lists all of the files in the /data directory and its subdirectories. For each file found, it runs grep looking for the string ProductionWebServer. If found, the file is appended (>>) to the file ProductionWebServerAgg.txt. Replace the cat command with cp and a directory location if you would rather copy all of the files to a single location rather than to a single file.
You can also use the join command to take data that is spread across two files and aggregate it into one. Take the two files seen in Example 5-10 and Example 5-11.
Example 5-10. ips.txt
ip,OS 10.0.4.2,Windows 8 10.0.4.35,Ubuntu 16 10.0.4.107,macOS 10.0.4.145,macOS
Example 5-11. user.txt
user,ip jdoe,10.0.4.2 jsmith,10.0.4.35 msmith,10.0.4.107 tjones,10.0.4.145
The files share a common column of data, which is the IP addresses. Because of that the files can be merged using join.
$ join -t, -2 2 ips.txt user.txt ip,OS,user 10.0.4.2,Windows 8,jdoe 10.0.4.35,Ubuntu 16,jsmith 10.0.4.107,macOS,msmith 10.0.4.145,macOS,tjones
The -t, option tells join that the columns are delimited using a comma, by default it uses a space character.
The -2 2 option tells join to use the second column of data in the second file (user.txt) as the key to perform the merge. By default join uses the first field as the key, which is appropriate for the first file (ips.txt). If you needed to join using a different field in ips.txt you would just add the option -1 n where n is replaced by the appropriate column number.
Warning
In order to use join both files must already be sorted by the column you will use to perform the merge. To do this you can use the sort command which is covered in Chapter 6.
Summary
In this chapter we explored ways to process common data formats including delimited, positional, JSON, and XML. The vast majority of data you collect and process will be in one of those formats.
In the next chapter we will look at how data can be analyzed and transformed into information that will provide insights into system status and drive decision making.
Exercises
-
Given the file tasks.txt below, use the
cutcommand to extract columns 1 (Image Name), 2 (PID), and 5 (Mem Usage).Image Name;PID;Session Name;Session#;Mem Usage System Idle Process;0;Services;0;4 K System;4;Services;0;2,140 K smss.exe;340;Services;0;1,060 K csrss.exe;528;Services;0;4,756 K
-
Given the file procowner.txt below, use the
joincommand to merge the file with tasks.txt.Process Owner;PID jdoe;0 tjones;4 jsmith;340 msmith;528
-
Use the
trcommand to replace all of the semicolon characters in tasks.txt with the tab character and print it to the screen. -
Write a command that extracts the first and last names of all of the authors in book.json.