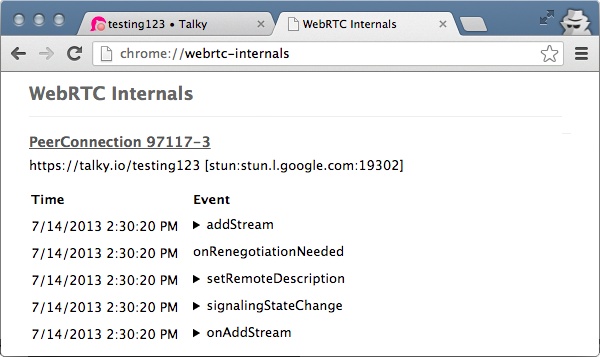
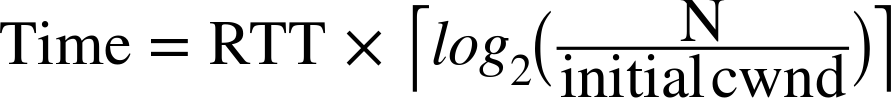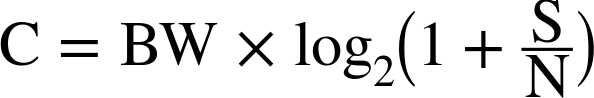“Good developers know how things work. Great developers know why things work.”
We all resonate with this adage. We want to be that person who understands and can explain the underpinning of the systems we depend on. And yet, if you’re a web developer, you might be moving in the opposite direction.
Web development is becoming more and more specialized. What kind of web developer are you? Frontend? Backend? Ops? Big data analytics? UI/UX? Storage? Video? Messaging? I would add “Performance Engineer” making that list of possible specializations even longer.
It’s hard to balance studying the foundations of the technology stack with the need to keep up with the latest innovations. And yet, if we don’t understand the foundation our knowledge is hollow, shallow. Knowing how to use the topmost layers of the technology stack isn’t enough. When the complex problems need to be solved, when the inexplicable happens, the person who understands the foundation leads the way.
That’s why High Performance Browser Networking is an important book. If you’re a web developer, the foundation of your technology stack is the Web and the myriad of networking protocols it rides on: TCP, TLS, UDP, HTTP, and many others. Each of these protocols has its own performance characteristics and optimizations, and to build high performance applications you need to understand why the network behaves the way it does.
Thank goodness you’ve found your way to this book. I wish I had this book when I started web programming. I was able to move forward by listening to people who understood the why of networking and read specifications to fill in the gaps. High Performance Browser Networking combines the expertise of a networking guru, Ilya Grigorik, with the necessary information from the many relevant specifications, all woven together in one place.
In High Performance Browser Networking, Ilya explains many whys of networking: Why latency is the performance bottleneck. Why TCP isn’t always the best transport mechanism and UDP might be your better choice. Why reusing connections is a critical optimization. He then goes even further by providing specific actions for improving networking performance. Want to reduce latency? Terminate sessions at a server closer to the client. Want to increase connection reuse? Enable connection keep-alive. The combination of understanding what to do and why it matters turns this knowledge into action.
Ilya explains the foundation of networking and builds on that to introduce the latest advances in protocols and browsers. The benefits of HTTP/2 are explained. XHR is reviewed and its limitations motivate the introduction of Cross-Origin Resource Sharing. Server-Sent Events, WebSockets, and WebRTC are also covered, bringing us up to date on the latest in browser networking.
Viewing the foundation and latest advances in networking from the perspective of performance is what ties the book together. Performance is the context that helps us see the why of networking and translate that into how it affects our website and our users. It transforms abstract specifications into tools that we can wield to optimize our websites and create the best user experience possible. That’s important. That’s why you should read this book.
The web browser is the most widespread deployment platform available to developers today: it is installed on every smartphone, tablet, laptop, desktop, and every other form factor in between. In fact, current cumulative industry growth projections put us on track for 20 billion connected devices by 2020—each with a browser, and at the very least, WiFi or a cellular connection. The type of platform, manufacturer of the device, or the version of the operating system do not matter—each and every device will have a web browser, which by itself is getting more feature rich each day.
The browser of yesterday looks nothing like what we now have access to, thanks to all the recent innovations: HTML and CSS form the presentation layer, JavaScript is the new assembly language of the Web, and new HTML5 APIs are continuing to improve and expose new platform capabilities for delivering engaging, high-performance applications. There is simply no other technology, or platform, that has ever had the reach or the distribution that is made available to us today when we develop for the browser. And where there is big opportunity, innovation always follows.
In fact, there is no better example of the rapid progress and innovation than the networking infrastructure within the browser. Historically, we have been restricted to simple HTTP request-response interactions, and today we have mechanisms for efficient streaming, bidirectional and real-time communication, ability to deliver custom application protocols, and even peer-to-peer videoconferencing and data delivery directly between the peers—all with a few dozen lines of JavaScript.
The net result? Billions of connected devices, a swelling userbase for existing and new online services, and high demand for high-performance web applications. Speed is a feature, and in fact, for some applications it is the feature, and delivering a high-performance web application requires a solid foundation in how the browser and the network interact. That is the subject of this book.
Our goal is to cover what every developer should know about the network: what protocols are being used and their inherent limitations, how to best optimize your applications for the underlying network, and what networking capabilities the browser offers and when to use them.
In the process, we will look at the internals of TCP, UDP, and TLS protocols, and how to optimize our applications and infrastructure for each one. Then we’ll take a deep dive into how the wireless and mobile networks work under the hood—this radio thing, it’s very different—and discuss its implications for how we design and architect our applications. Finally, we will dissect how the HTTP protocol works under the hood and investigate the many new and exciting networking capabilities in the browser:
Understanding how the individual bits are delivered, and the properties of each transport and protocol in use are essential knowledge for delivering high-performance applications. After all, if our applications are blocked waiting on the network, then no amount of rendering, JavaScript, or any other form of optimization will help! Our goal is to eliminate this wait time by getting the best possible performance from the network.
High-Performance Browser Networking will be of interest to anyone interested in optimizing the delivery and performance of her applications, and more generally, curious minds that are not satisfied with a simple checklist but want to know how the browser and the underlying protocols actually work under the hood. The “how” and the “why” go hand in hand: we’ll cover practical advice about configuration and architecture, and we’ll also explore the trade-offs and the underlying reasons for each optimization.
Our primary focus is on the protocols and their properties with respect to applications running in the browser. However, all the discussions on TCP, UDP, TLS, HTTP, and just about every other protocol we will cover are also directly applicable to native applications, regardless of the platform.
The following typographical conventions are used in this book:
Constant width
Constant width bold
Constant width italic
This icon signifies a tip, suggestion, or general note.
This icon indicates a warning or caution.
Safari Books Online is an on-demand digital library that delivers expert content in both book and video form from the world’s leading authors in technology and business.
Technology professionals, software developers, web designers, and business and creative professionals use Safari Books Online as their primary resource for research, problem solving, learning, and certification training.
Safari Books Online offers a range of product mixes and pricing programs for organizations, government agencies, and individuals. Subscribers have access to thousands of books, training videos, and prepublication manuscripts in one fully searchable database from publishers like O’Reilly Media, Prentice Hall Professional, Addison-Wesley Professional, Microsoft Press, Sams, Que, Peachpit Press, Focal Press, Cisco Press, John Wiley & Sons, Syngress, Morgan Kaufmann, IBM Redbooks, Packt, Adobe Press, FT Press, Apress, Manning, New Riders, McGraw-Hill, Jones & Bartlett, Course Technology, and dozens more. For more information about Safari Books Online, please visit us online.
Please address comments and questions concerning this book to the publisher:
| O’Reilly Media, Inc. |
| 1005 Gravenstein Highway North |
| Sebastopol, CA 95472 |
| 800-998-9938 (in the United States or Canada) |
| 707-829-0515 (international or local) |
| 707-829-0104 (fax) |
We have a web page for this book, where we list errata, examples, and any additional information. You can access this page at http://oreil.ly/high-performance-browser.
To comment or ask technical questions about this book, send email to bookquestions@oreilly.com.
For more information about our books, courses, conferences, and news, see our website at http://www.oreilly.com.
Find us on Facebook: http://facebook.com/oreilly
Follow us on Twitter: http://twitter.com/oreillymedia
Watch us on YouTube: http://www.youtube.com/oreillymedia
The emergence and the fast growth of the web performance optimization (WPO) industry within the past few years is a telltale sign of the growing importance and demand for speed and faster user experiences by the users. And this is not simply a psychological need for speed in our ever accelerating and connected world, but a requirement driven by empirical results, as measured with respect to the bottom-line performance of the many online businesses:
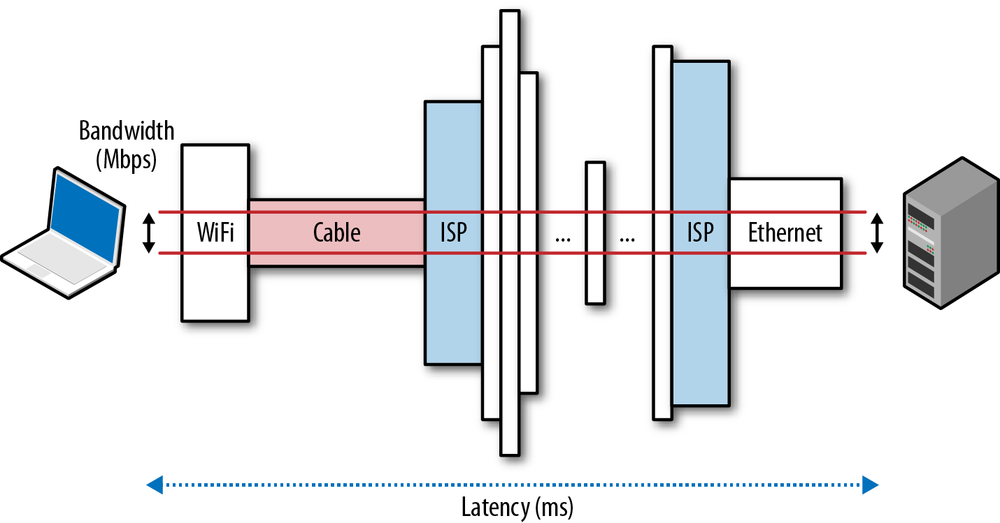
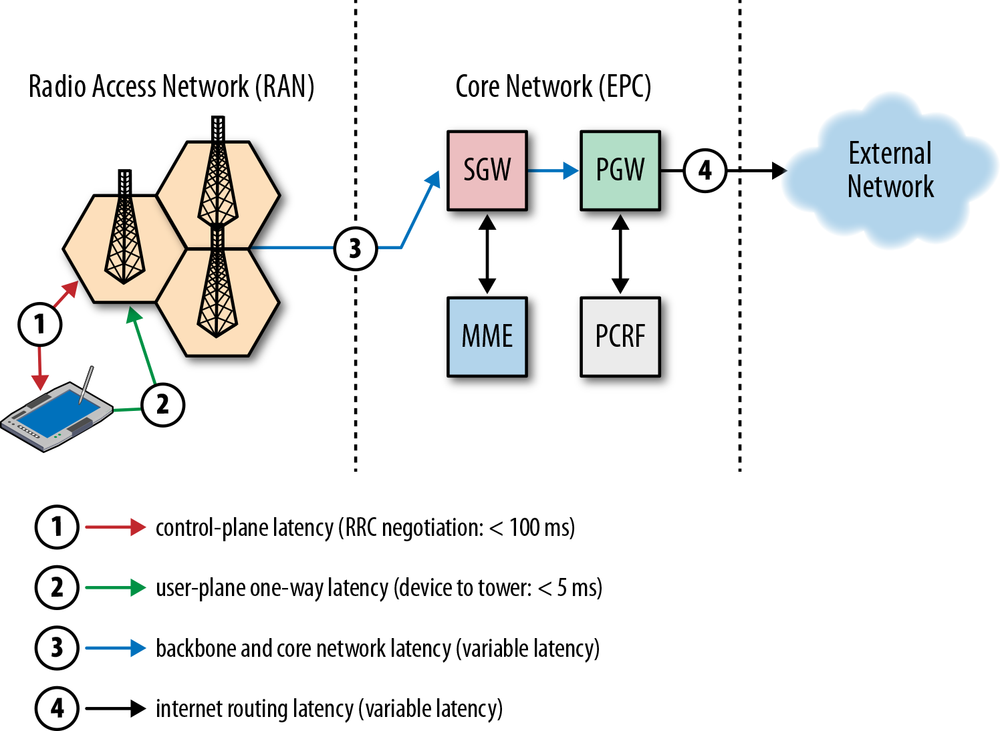
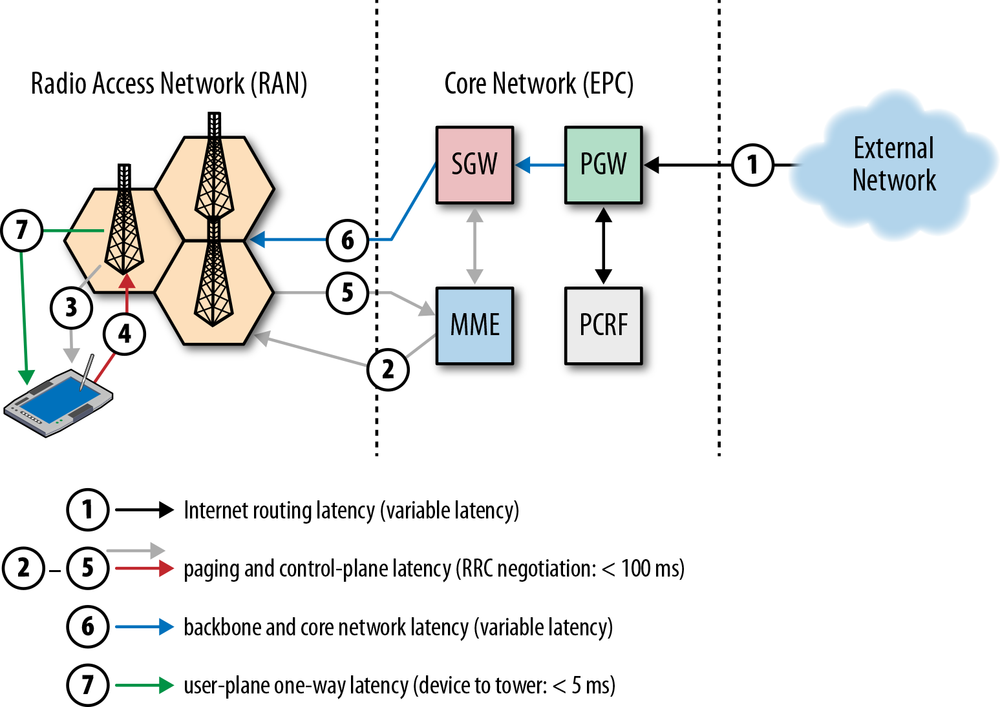
Simply put, speed is a feature. And to deliver it, we need to understand the many factors and fundamental limitations that are at play. In this chapter, we will focus on the two critical components that dictate the performance of all network traffic: latency and bandwidth (Figure 1-1).
Armed with a better understanding of how bandwidth and latency work together, we will then have the tools to dive deeper into the internals and performance characteristics of TCP, UDP, and all application protocols above them.
Latency is the time it takes for a message, or a packet, to travel from its point of origin to the point of destination. That is a simple and useful definition, but it often hides a lot of useful information—every system contains multiple sources, or components, contributing to the overall time it takes for a message to be delivered, and it is important to understand what these components are and what dictates their performance.
Let’s take a closer look at some common contributing components for a typical router on the Internet, which is responsible for relaying a message between the client and the server:
The total latency between the client and the server is the sum of all the delays just listed. Propagation time is dictated by the distance and the medium through which the signal travels—as we will see, the propagation speed is usually within a small constant factor of the speed of light. On the other hand, transmission delay is dictated by the available data rate of the transmitting link and has nothing to do with the distance between the client and the server. As an example, let’s assume we want to transmit a 10 Mb file over two links: 1 Mbps and 100 Mbps. It will take 10 seconds to put the entire file on the “wire” over the 1 Mbps link and only 0.1 seconds over the 100 Mbps link.
Next, once the packet arrives at the router, the router must examine the packet header to determine the outgoing route and may run other checks on the data—this takes time as well. Much of this logic is now often done in hardware, so the delays are very small, but they do exist. And, finally, if the packets are arriving at a faster rate than the router is capable of processing, then the packets are queued inside an incoming buffer. The time data spends queued inside the buffer is, not surprisingly, known as queuing delay.
Each packet traveling over the network will incur many instances of each of these delays. The farther the distance between the source and destination, the more time it will take to propagate. The more intermediate routers we encounter along the way, the higher the processing and transmission delays for each packet. Finally, the higher the load of traffic along the path, the higher the likelihood of our packet being delayed inside an incoming buffer.
As Einstein outlined in his theory of special relativity, the speed of light is the maximum speed at which all energy, matter, and information can travel. This observation places a hard limit, and a governor, on the propagation time of any network packet.
The good news is the speed of light is high: 299,792,458 meters per second, or 186,282 miles per second. However, and there is always a however, that is the speed of light in a vacuum. Instead, our packets travel through a medium such as a copper wire or a fiber-optic cable, which will slow down the signal (Table 1-1). This ratio of the speed of light and the speed with which the packet travels in a material is known as the refractive index of the material. The larger the value, the slower light travels in that medium.
The typical refractive index value of an optical fiber, through which most of our packets travel for long-distance hops, can vary between 1.4 to 1.6—slowly but surely we are making improvements in the quality of the materials and are able to lower the refractive index. But to keep it simple, the rule of thumb is to assume that the speed of light in fiber is around 200,000,000 meters per second, which corresponds to a refractive index of ~1.5. The remarkable part about this is that we are already within a small constant factor of the maximum speed! An amazing engineering achievement in its own right.
| Route | Distance | Time, light in vacuum | Time, light in fiber | Round-trip time (RTT) in fiber |
New York to San Francisco | 4,148 km | 14 ms | 21 ms | 42 ms |
New York to London | 5,585 km | 19 ms | 28 ms | 56 ms |
New York to Sydney | 15,993 km | 53 ms | 80 ms | 160 ms |
Equatorial circumference | 40,075 km | 133.7 ms | 200 ms | 200 ms |
The speed of light is fast, but it nonetheless takes 160 milliseconds to make the round-trip (RTT) from New York to Sydney. In fact, the numbers in Table 1-1 are also optimistic in that they assume that the packet travels over a fiber-optic cable along the great-circle path (the shortest distance between two points on the globe) between the cities. In practice, no such cable is available, and the packet would take a much longer route between New York and Sydney. Each hop along this route will introduce additional routing, processing, queuing, and transmission delays. As a result, the actual RTT between New York and Sydney, over our existing networks, works out to be in the 200–300 millisecond range. All things considered, that still seems pretty fast, right?
We are not accustomed to measuring our everyday encounters in milliseconds, but studies have shown that most of us will reliably report perceptible “lag” once a delay of over 100–200 milliseconds is introduced into the system. Once the 300 millisecond delay threshold is exceeded, the interaction is often reported as “sluggish,” and at the 1,000 milliseconds (1 second) barrier, many users have already performed a mental context switch while waiting for the response—anything from a daydream to thinking about the next urgent task.
The conclusion is simple: to deliver the best experience and to keep our users engaged in the task at hand, we need our applications to respond within hundreds of milliseconds. That doesn’t leave us, and especially the network, with much room for error. To succeed, network latency has to be carefully managed and be an explicit design criteria at all stages of development.
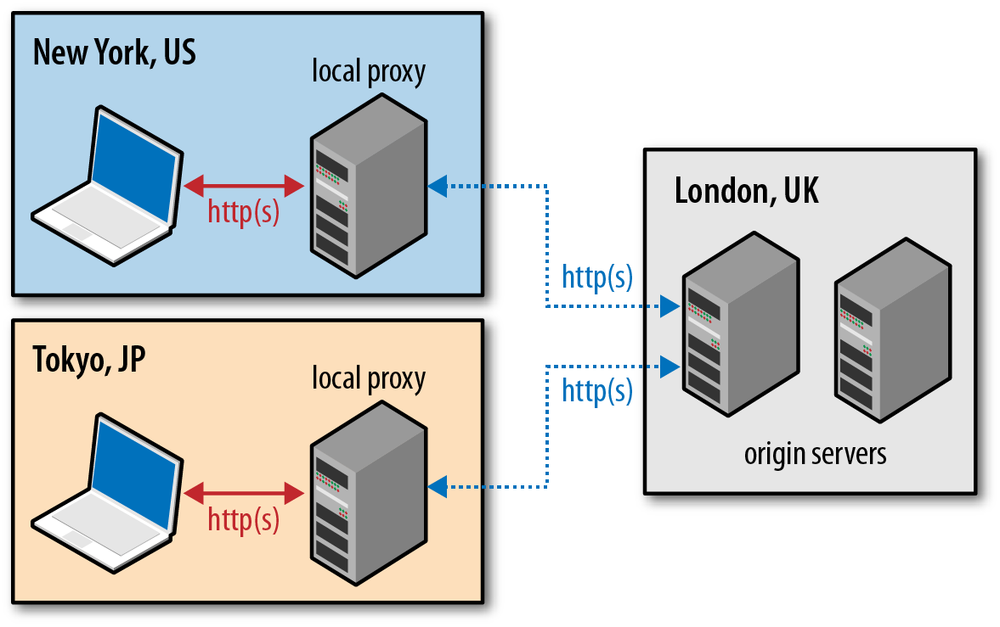
Content delivery network (CDN) services provide many benefits, but chief among them is the simple observation that distributing the content around the globe, and serving that content from a nearby location to the client, will allow us to significantly reduce the propagation time of all the data packets.
We may not be able to make the packets travel faster, but we can reduce the distance by strategically positioning our servers closer to the users! Leveraging a CDN to serve your data can offer significant performance benefits.
Ironically, it is often the last few miles, not the crossing of oceans or continents, where significant latency is introduced: the infamous last-mile problem. To connect your home or office to the Internet, your local ISP needs to route the cables throughout the neighborhood, aggregate the signal, and forward it to a local routing node. In practice, depending on the type of connectivity, routing methodology, and deployed technology, these first few hops can take tens of milliseconds just to get to your ISP’s main routers! According to the “Measuring Broadband America” report conducted by the Federal Communications Commission in early 2013, during peak hours:
Fiber-to-the-home, on average, has the best performance in terms of latency, with 18 ms average during the peak period, with cable having 26 ms latency and DSL 44 ms latency.
— FCC February 2013
This translates into 18–44 ms of latency just to the closest measuring node within the ISP’s core network, before the packet is even routed to its destination! The FCC report is focused on the United States, but last-mile latency is a challenge for all Internet providers, regardless of geography. For the curious, a simple traceroute can often tell you volumes about the topology and performance of your Internet provider.
$> traceroute google.comtraceroute to google.com (74.125.224.102), 64 hops max, 52 byte packets 1 10.1.10.1 (10.1.10.1) 7.120 ms 8.925 ms 1.199 ms2 96.157.100.1 (96.157.100.1) 20.894 ms 32.138 ms 28.928 ms 3 x.santaclara.xxxx.com (68.85.191.29) 9.953 ms 11.359 ms 9.686 ms 4 x.oakland.xxx.com (68.86.143.98) 24.013 ms 21.423 ms 19.594 ms 5 68.86.91.205 (68.86.91.205) 16.578 ms 71.938 ms 36.496 ms 6 x.sanjose.ca.xxx.com (68.86.85.78) 17.135 ms 17.978 ms 22.870 ms 7 x.529bryant.xxx.com (68.86.87.142) 25.568 ms 22.865 ms 23.392 ms 8 66.208.228.226 (66.208.228.226) 40.582 ms 16.058 ms 15.629 ms 9 72.14.232.136 (72.14.232.136) 20.149 ms 20.210 ms 18.020 ms 10 64.233.174.109 (64.233.174.109) 63.946 ms 18.995 ms 18.150 ms 11 x.1e100.net (74.125.224.102) 18.467 ms 17.839 ms 17.958 ms
In the previous example, the packet started in the city of Sunnyvale, bounced to Santa Clara, then Oakland, returned to San Jose, got routed to the “529 Bryant” datacenter, at which point it was routed toward Google and arrived at its destination on the 11th hop. This entire process took, on average, 18 milliseconds. Not bad, all things considered, but in the same time the packet could have traveled across most of the continental USA!
The last-mile latency can vary wildly based on your provider, the deployed technology, topology of the network, and even the time of day. As an end user, if you are looking to improve your web browsing speeds, low latency is worth optimizing for when picking a local ISP.
Latency, not bandwidth, is the performance bottleneck for most websites! To understand why, we need to understand the mechanics of TCP and HTTP protocols—subjects we’ll be covering in subsequent chapters. However, if you are curious, feel free to skip ahead to More Bandwidth Doesn’t Matter (Much).
An optical fiber acts as a simple “light pipe,” slightly thicker than a human hair, designed to transmit light between the two ends of the cable. Metal wires are also used but are subject to higher signal loss, electromagnetic interference, and higher lifetime maintenance costs. Chances are, your packets will travel over both types of cable, but for any long-distance hops, they will be transmitted over a fiber-optic link.
Optical fibers have a distinct advantage when it comes to bandwidth because each fiber can carry many different wavelengths (channels) of light through a process known as wavelength-division multiplexing (WDM). Hence, the total bandwidth of a fiber link is the multiple of per-channel data rate and the number of multiplexed channels.
As of early 2010, researchers have been able to multiplex over 400 wavelengths with the peak capacity of 171 Gbit/s per channel, which translates to over 70 Tbit/s of total bandwidth for a single fiber link! We would need thousands of copper wire (electrical) links to match this throughput. Not surprisingly, most long-distance hops, such as subsea data transmission between continents, is now done over fiber-optic links. Each cable carries several strands of fiber (four strands is a common number), which translates into bandwidth capacity in hundreds of terabits per second for each cable.
The backbones, or the fiber links, that form the core data paths of the Internet are capable of moving hundreds of terabits per second. However, the available capacity at the edges of the network is much, much less, and varies wildly based on deployed technology: dial-up, DSL, cable, a host of wireless technologies, fiber-to-the-home, and even the performance of the local router. The available bandwidth to the user is a function of the lowest capacity link between the client and the destination server (Figure 1-1).
Akamai Technologies operates a global CDN, with servers positioned around the globe, and provides free quarterly reports at Akamai’s website on average broadband speeds, as seen by their servers. Table 1-2 captures the macro bandwidth trends as of Q1 2013.
| Rank | Country | Average Mbps | Year-over-year change |
- | Global | 3.1 | 17% |
1 | South Korea | 14.2 | -10% |
2 | Japan | 11.7 | 6.8% |
3 | Hong Kong | 10.9 | 16% |
4 | Switzerland | 10.1 | 24% |
5 | Netherlands | 9.9 | 12% |
… | |||
9 | United States | 8.6 | 27% |
The preceding data excludes traffic from mobile carriers, a topic we will come back to later to examine in closer detail. For now, it should suffice to say that mobile speeds are highly variable and generally slower. However, even with that in mind, the average global broadband bandwidth in early 2013 was just 3.1 Mbps! South Korea led the world with a 14.2 Mbps average throughput, and United States came in 9th place with 8.6 Mbps.
As a reference point, streaming an HD video can require anywhere from 2 to 10 Mbps depending on resolution and the codec. So an average user can stream a lower-resolution video stream at the network edge, but doing so would consume much of their link capacity—not a very promising story for a household with multiple users.
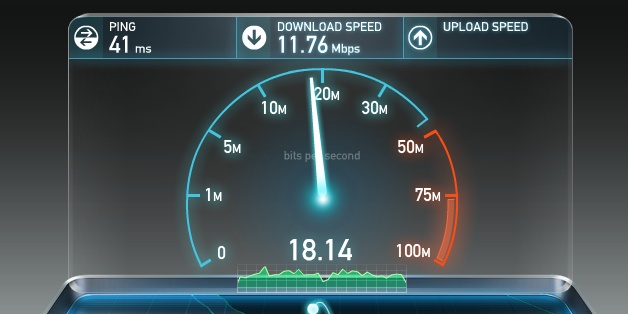
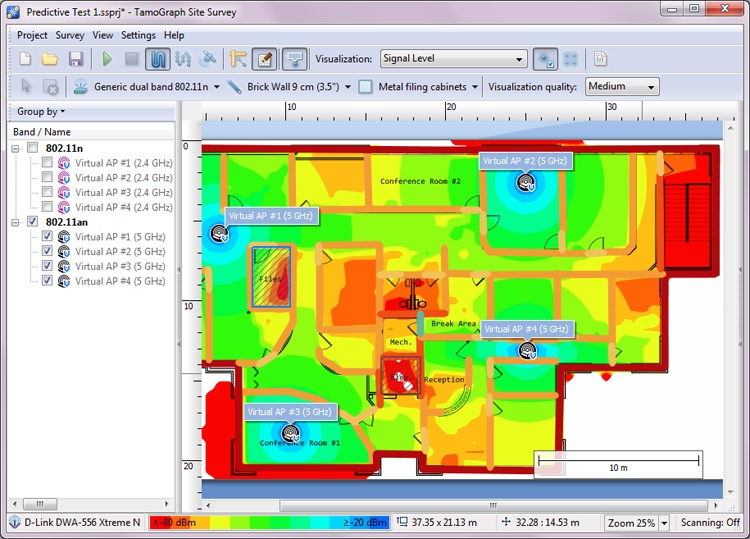
Figuring out where the bandwidth bottleneck is for any given user is often a nontrivial but important exercise. Once again, for the curious, there are a number of online services, such as speedtest.net operated by Ookla (Figure 1-2), which provide upstream and downstream tests to some local server—we will see why picking a local server is important in our discussion on TCP. Running a test on one of these services is a good way to check that your connection meets the advertised speeds of your local ISP.
However, while a high-bandwidth link to your ISP is desirable, it is also not a guarantee of stable end-to-end performance. The network could be congested at any intermediate node at some point in time due to high demand, hardware failures, a concentrated network attack, or a host of other reasons. High variability of throughput and latency performance is an inherent property of our data networks—predicting, managing, and adapting to the continuously changing “network weather” is a complex task.
Our demand for higher bandwidth is growing fast, in large part due to the rising popularity of streaming video, which is now responsible for well over half of all Internet traffic. The good news is, while it may not be cheap, there are multiple strategies available for us to grow the available capacity: we can add more fibers into our fiber-optic links, we can deploy more links across the congested routes, or we can improve the WDM techniques to transfer more data through existing links.
TeleGeography, a telecommunications market research and consulting firm, estimates that as of 2011, we are using, on average, just 20% of the available capacity of the deployed subsea fiber links. Even more importantly, between 2007 and 2011, more than half of all the added capacity of the trans-Pacific cables was due to WDM upgrades: same fiber links, better technology on both ends to multiplex the data. Of course, we cannot expect these advances to go on indefinitely, as every medium reaches a point of diminishing returns. Nonetheless, as long as economics of the enterprise permit, there is no fundamental reason why bandwidth throughput cannot be increased over time—if all else fails, we can add more fiber links.
Improving latency, on the other hand, is a very different story. The quality of the fiber links could be improved to get us a little closer to the speed of light: better materials with lower refractive index and faster routers along the way. However, given that our current speeds are within ~1.5 of the speed of light, the most we can expect from this strategy is just a modest 30% improvement. Unfortunately, there is simply no way around the laws of physics: the speed of light places a hard limit on the minimum latency.
Alternatively, since we can’t make light travel faster, we can make the distance shorter—the shortest distance between any two points on the globe is defined by the great-circle path between them. However, laying new cables is also not always possible due to the constraints imposed by the physical terrain, social and political reasons, and of course, the associated costs.
As a result, to improve performance of our applications, we need to architect and optimize our protocols and networking code with explicit awareness of the limitations of available bandwidth and the speed of light: we need to reduce round trips, move the data closer to the client, and build applications that can hide the latency through caching, pre-fetching, and a variety of similar techniques, as explained in subsequent chapters.
At the heart of the Internet are two protocols, IP and TCP. The IP, or Internet Protocol, is what provides the host-to-host routing and addressing, and TCP, or Transmission Control Protocol, is what provides the abstraction of a reliable network running over an unreliable channel. TCP/IP is also commonly referred to as the Internet Protocol Suite and was first proposed by Vint Cerf and Bob Kahn in their 1974 paper titled “A Protocol for Packet Network Intercommunication.”
The original proposal (RFC 675) was revised several times, and in 1981 the v4 specification of TCP/IP was published not as one, but as two separate RFCs:
Since then, there have been a number of enhancements proposed and made to TCP, but the core operation has not changed significantly. TCP quickly replaced previous protocols and is now the protocol of choice for many of the most popular applications: World Wide Web, email, file transfers, and many others.
TCP provides an effective abstraction of a reliable network running over an unreliable channel, hiding most of the complexity of network communication from our applications: retransmission of lost data, in-order delivery, congestion control and avoidance, data integrity, and more. When you work with a TCP stream, you are guaranteed that all bytes sent will be identical with bytes received and that they will arrive in the same order to the client. As such, TCP is optimized for accurate delivery, rather than a timely one. This, as it turns out, also creates some challenges when it comes to optimizing for web performance in the browser.
The HTTP standard does not specify TCP as the only transport protocol. If we wanted, we could deliver HTTP via a datagram socket (User Datagram Protocol or UDP), or any other transport protocol of our choice, but in practice all HTTP traffic on the Internet today is delivered via TCP due to the many great features it provides out of the box.
Because of this, understanding some of the core mechanisms of TCP is essential knowledge for building an optimized web experience. Chances are you won’t be working with TCP sockets directly in your application, but the design choices you make at the application layer will dictate the performance of TCP and the underlying network over which your application is delivered.
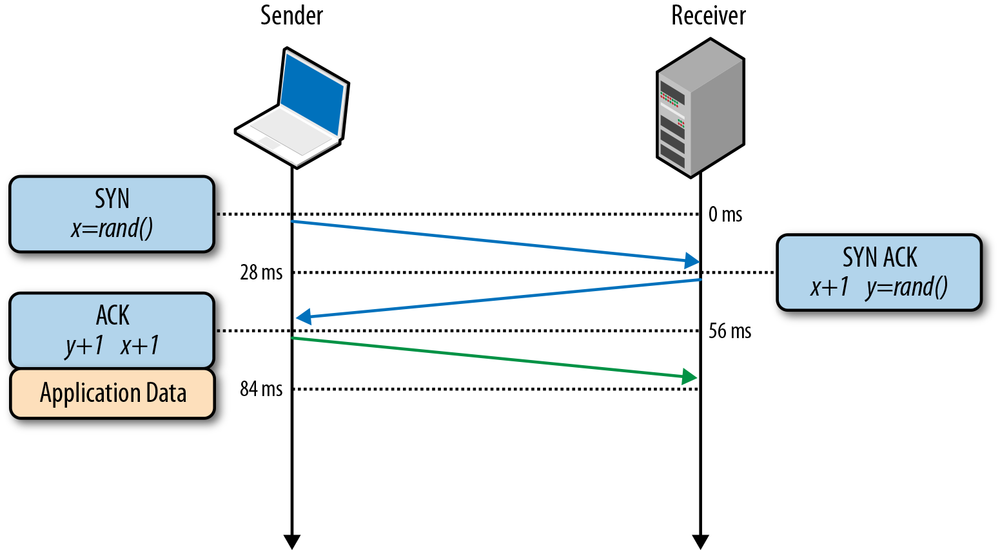
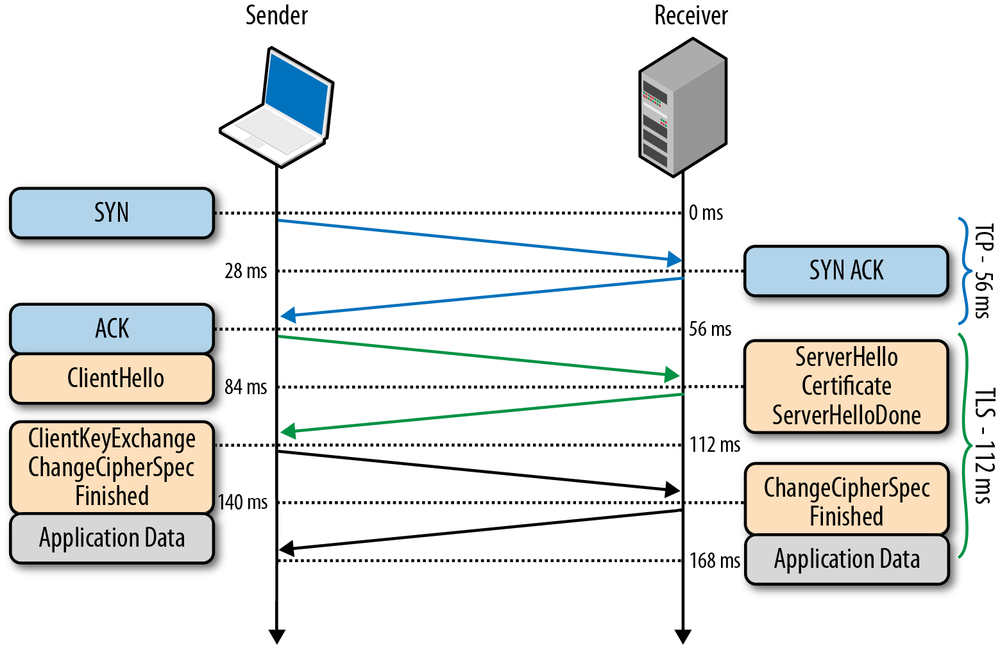
All TCP connections begin with a three-way handshake (Figure 2-1). Before the client or the server can exchange any application data, they must agree on starting packet sequence numbers, as well as a number of other connection specific variables, from both sides. The sequence numbers are picked randomly from both sides for security reasons.
x and sends a SYN packet, which may also include additional TCP flags and options.
x by one, picks own random sequence number y, appends its own set of flags and options, and dispatches the response.
x and y by one and completes the handshake by dispatching the last ACK packet in the handshake.
Once the three-way handshake is complete, the application data can begin to flow between the client and the server. The client can send a data packet immediately after the ACK packet, and the server must wait for the ACK before it can dispatch any data. This startup process applies to every TCP connection and carries an important implication for performance of all network applications using TCP: each new connection will have a full roundtrip of latency before any application data can be transferred.
For example, if our client is in New York, the server is in London, and we are starting a new TCP connection over a fiber link, then the three-way handshake will take a minimum of 56 milliseconds (Table 1-1): 28 milliseconds to propagate the packet in one direction, after which it must return back to New York. Note that bandwidth of the connection plays no role here. Instead, the delay is governed by the latency between the client and the server, which in turn is dominated by the propagation time between New York and London.
The delay imposed by the three-way handshake makes new TCP connections expensive to create, and is one of the big reasons why connection reuse is a critical optimization for any application running over TCP.
In early 1984, John Nagle documented a condition known as “congestion collapse,” which could affect any network with asymmetric bandwidth capacity between the nodes:
Congestion control is a recognized problem in complex networks. We have discovered that the Department of Defense’s Internet Protocol (IP), a pure datagram protocol, and Transmission Control Protocol (TCP), a transport layer protocol, when used together, are subject to unusual congestion problems caused by interactions between the transport and datagram layers. In particular, IP gateways are vulnerable to a phenomenon we call “congestion collapse”, especially when such gateways connect networks of widely different bandwidth…
Should the roundtrip time exceed the maximum retransmission interval for any host, that host will begin to introduce more and more copies of the same datagrams into the net. The network is now in serious trouble. Eventually all available buffers in the switching nodes will be full and packets must be dropped. The roundtrip time for packets that are delivered is now at its maximum. Hosts are sending each packet several times, and eventually some copy of each packet arrives at its destination. This is congestion collapse.
This condition is stable. Once the saturation point has been reached, if the algorithm for selecting packets to be dropped is fair, the network will continue to operate in a degraded condition.
— John Nagle RFC 896
The report concluded that congestion collapse had not yet become a problem for ARPANET because most nodes had uniform bandwidth, and the backbone had substantial excess capacity. However, neither of these assertions held true for long. In 1986, as the number (5,000+) and the variety of nodes on the network grew, a series of congestion collapse incidents swept throughout the network—in some cases the capacity dropped by a factor of 1,000 and the network became unusable.
To address these issues, multiple mechanisms were implemented in TCP to govern the rate with which the data can be sent in both directions: flow control, congestion control, and congestion avoidance.
Advanced Research Projects Agency Network (ARPANET) was the precursor to the modern Internet and the world’s first operational packet-switched network. The project was officially launched in 1969, and in 1983 the TCP/IP protocols replaced the earlier NCP (Network Control Program) as the principal communication protocols. The rest, as they say, is history.
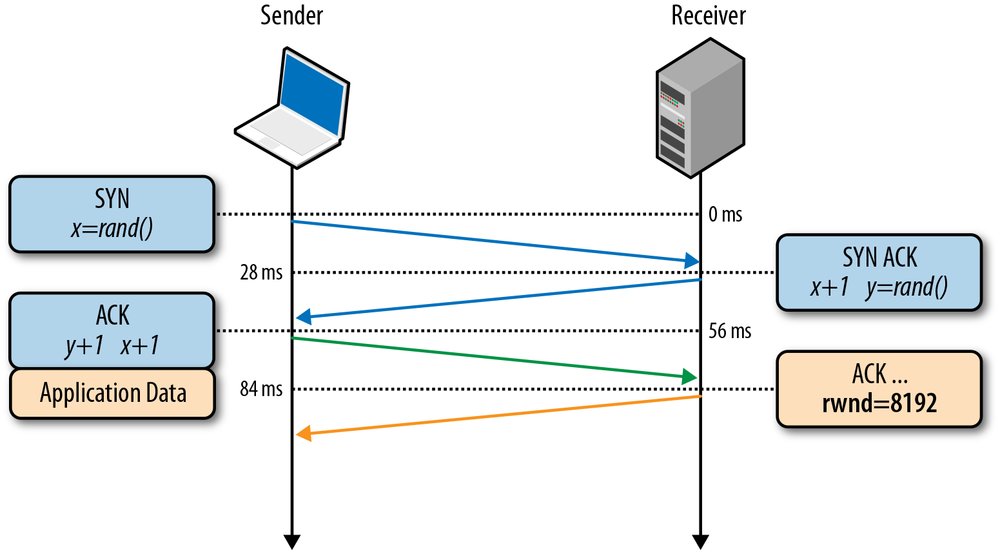
Flow control is a mechanism to prevent the sender from overwhelming the receiver with data it may not be able to process—the receiver may be busy, under heavy load, or may only be willing to allocate a fixed amount of buffer space. To address this, each side of the TCP connection advertises (Figure 2-2) its own receive window (rwnd), which communicates the size of the available buffer space to hold the incoming data.
When the connection is first established, both sides initiate their rwnd values by using their system default settings. A typical web page will stream the majority of the data from the server to the client, making the client’s window the likely bottleneck. However, if a client is streaming large amounts of data to the server, such as in the case of an image or a video upload, then the server receive window may become the limiting factor.
If, for any reason, one of the sides is not able to keep up, then it can advertise a smaller window to the sender. If the window reaches zero, then it is treated as a signal that no more data should be sent until the existing data in the buffer has been cleared by the application layer. This workflow continues throughout the lifetime of every TCP connection: each ACK packet carries the latest rwnd value for each side, allowing both sides to dynamically adjust the data flow rate to the capacity and processing speed of the sender and receiver.
Despite the presence of flow control in TCP, network congestion collapse became a real issue in the mid to late 1980s. The problem was that flow control prevented the sender from overwhelming the receiver, but there was no mechanism to prevent either side from overwhelming the underlying network: neither the sender nor the receiver knows the available bandwidth at the beginning of a new connection, and hence need a mechanism to estimate it and also to adapt their speeds to the continuously changing conditions within the network.
To illustrate one example where such an adaptation is beneficial, imagine you are at home and streaming a large video from a remote server that managed to saturate your downlink to deliver the maximum quality experience. Then another user on your home network opens a new connection to download some software updates. All of the sudden, the amount of available downlink bandwidth to the video stream is much less, and the video server must adjust its data rate—otherwise, if it continues at the same rate, the data will simply pile up at some intermediate gateway and packets will be dropped, leading to inefficient use of the network.
In 1988, Van Jacobson and Michael J. Karels documented several algorithms to address these problems: slow-start, congestion avoidance, fast retransmit, and fast recovery. All four quickly became a mandatory part of the TCP specification. In fact, it is widely held that it was these updates to TCP that prevented an Internet meltdown in the ’80s and the early ’90s as the traffic continued to grow at an exponential rate.
To understand slow-start, it is best to see it in action. So, once again, let us come back to our client, who is located in New York, attempting to retrieve a file from a server in London. First, the three-way handshake is performed, during which both sides advertise their respective receive window (rwnd) sizes within the ACK packets (Figure 2-2). Once the final ACK packet is put on the wire, we can start exchanging application data.
The only way to estimate the available capacity between the client and the server is to measure it by exchanging data, and this is precisely what slow-start is designed to do. To start, the server initializes a new congestion window (cwnd) variable per TCP connection and sets its initial value to a conservative, system-specified value (initcwnd on Linux).
The cwnd variable is not advertised or exchanged between the sender and receiver—in this case, it will be a private variable maintained by the server in London. Further, a new rule is introduced: the maximum amount of data in flight (not ACKed) between the client and the server is the minimum of the rwnd and cwnd variables. So far so good, but how do the server and the client determine optimal values for their congestion window sizes? After all, network conditions vary all the time, even between the same two network nodes, as we saw in the earlier example, and it would be great if we could use the algorithm without having to hand-tune the window sizes for each connection.
The solution is to start slow and to grow the window size as the packets are acknowledged: slow-start! Originally, the cwnd start value was set to 1 network segment; RFC 2581 updated this value to a maximum of 4 segments in April 1999, and most recently the value was increased once more to 10 segments by RFC 6928 in April 2013.
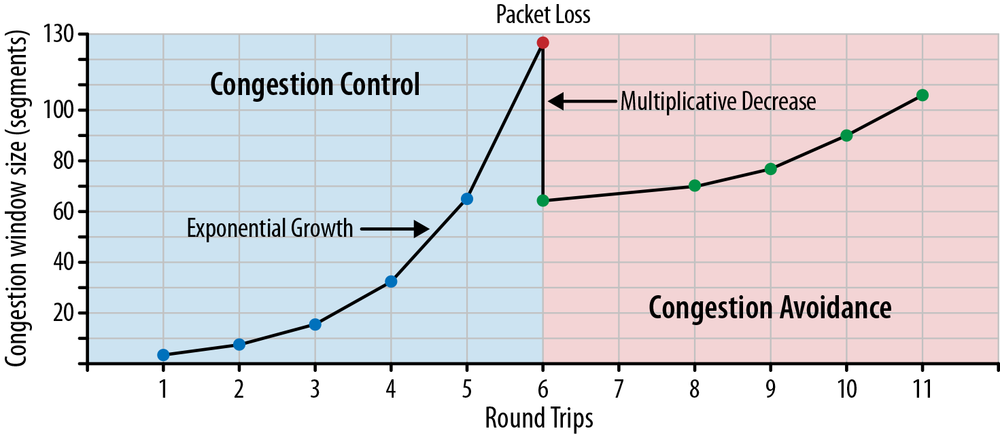
The maximum amount of data in flight for a new TCP connection is the minimum of the rwnd and cwnd values; hence the server can send up to four network segments to the client, at which point it must stop and wait for an acknowledgment. Then, for every received ACK, the slow-start algorithm indicates that the server can increment its cwnd window size by one segment—for every ACKed packet, two new packets can be sent. This phase of the TCP connection is commonly known as the “exponential growth” algorithm (Figure 2-3), as the client and the server are trying to quickly converge on the available bandwidth on the network path between them.
So why is slow-start an important factor to keep in mind when we are building applications for the browser? Well, HTTP and many other application protocols run over TCP, and no matter the available bandwidth, every TCP connection must go through the slow-start phase—we cannot use the full capacity of the link immediately!
Instead, we start with a small congestion window and double it for every roundtrip—i.e., exponential growth. As a result, the time required to reach a specific throughput target is a function (Equation 2-1) of both the roundtrip time between the client and server and the initial congestion window size.
For a hands-on example of slow-start impact, let’s assume the following scenario:
We will be using the old (RFC 2581) value of four network segments for the initial congestion window in this and the following examples, as it is still the most common value for most servers. Except, you won’t make this mistake—right? The following examples should serve as good motivation for why you should update your servers!
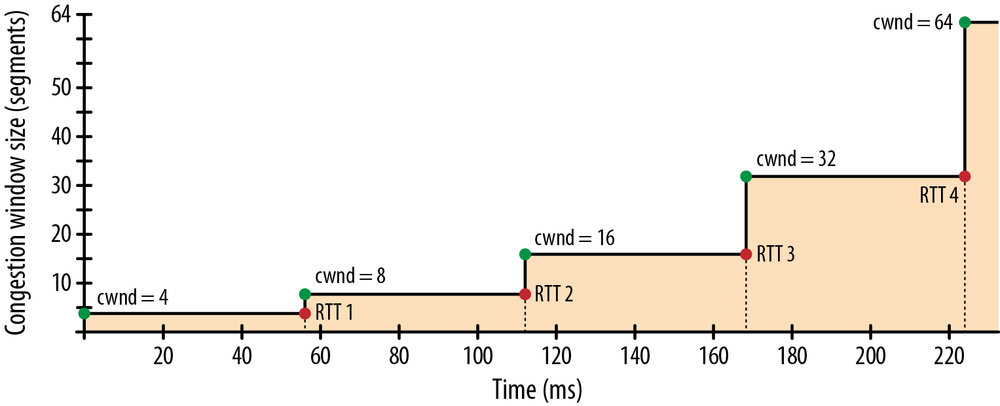
Despite the 64 KB receive window size, the throughput of a new TCP connection is initially limited by the size of the congestion window. In fact, to reach the 64 KB limit, we will need to grow the congestion window size to 45 segments, which will take 224 milliseconds:
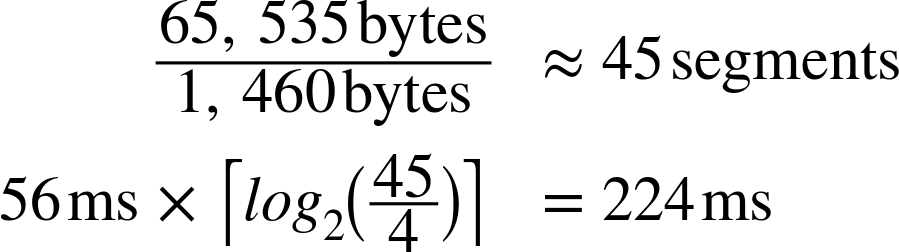
That’s four roundtrips (Figure 2-4), and hundreds of milliseconds of latency, to reach 64 KB of throughput between the client and server! The fact that the client and server may be capable of transferring at Mbps+ data rates has no effect—that’s slow-start.
To decrease the amount of time it takes to grow the congestion window, we can decrease the roundtrip time between the client and server—e.g., move the server geographically closer to the client. Or we can increase the initial congestion window size to the new RFC 6928 value of 10 segments.
Slow-start is not as big of an issue for large, streaming downloads, as the client and the server will arrive at their maximum window sizes after a few hundred milliseconds and continue to transmit at near maximum speeds—the cost of the slow-start phase is amortized over the lifetime of the larger transfer.
However, for many HTTP connections, which are often short and bursty, it is not unusual for the request to terminate before the maximum window size is reached. As a result, the performance of many web applications is often limited by the roundtrip time between server and client: slow-start limits the available bandwidth throughput, which has an adverse effect on the performance of small transfers.
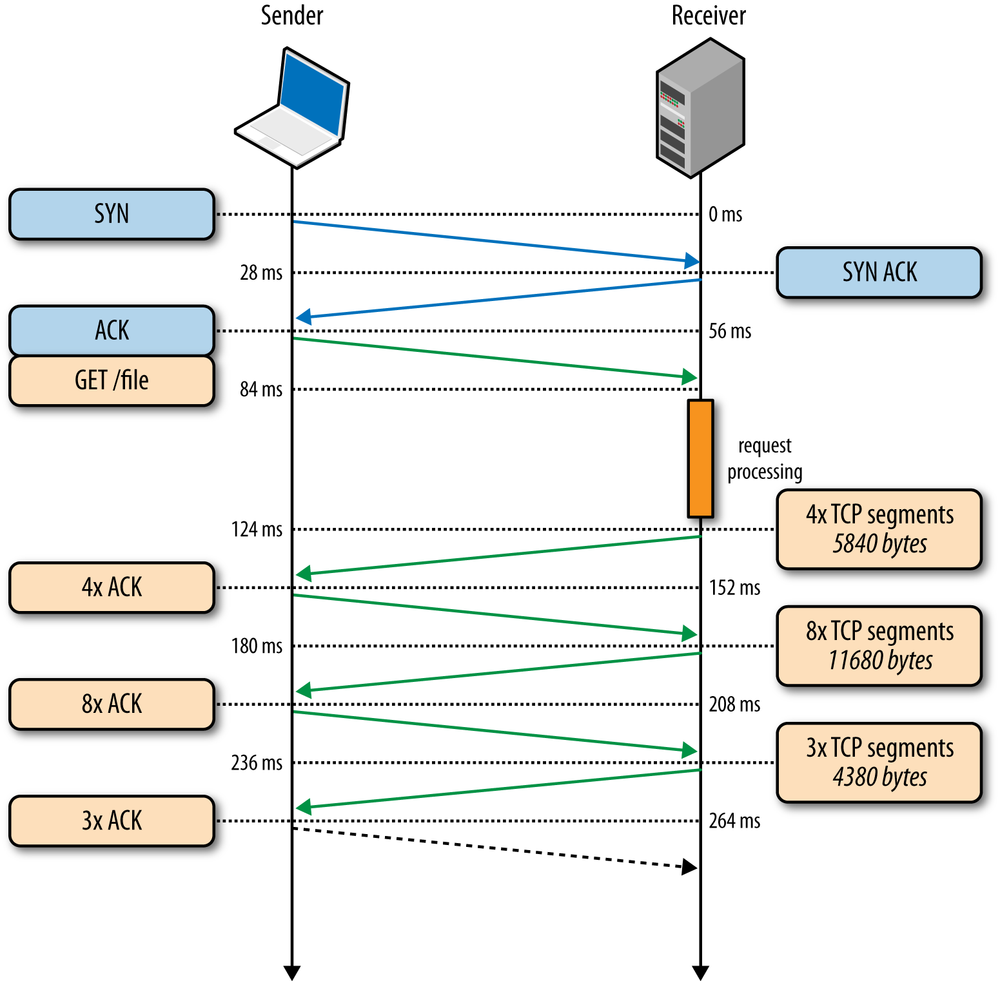
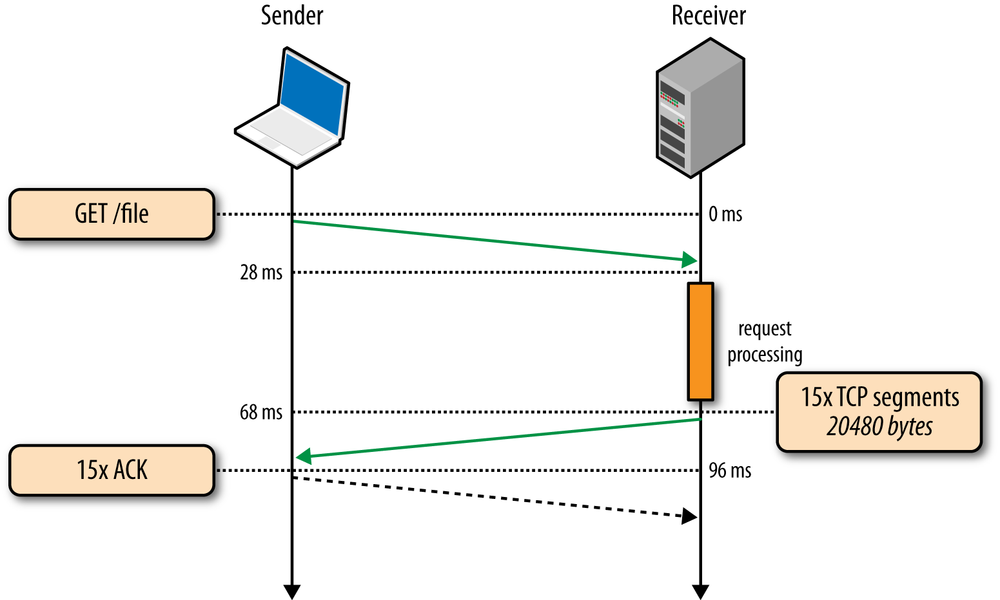
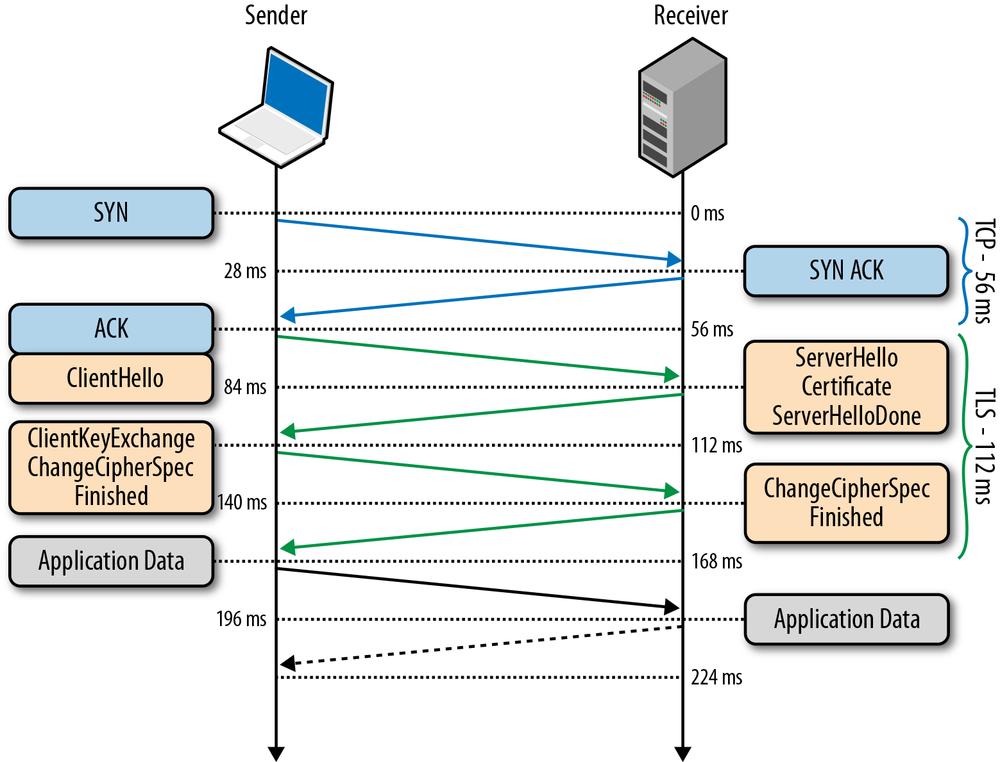
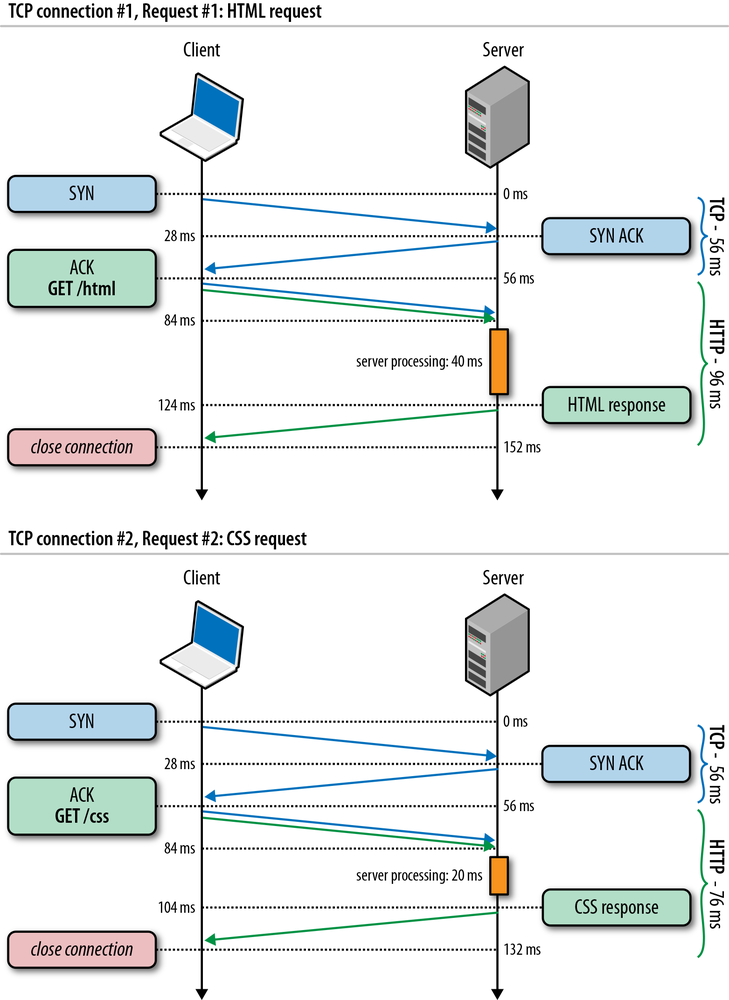
To illustrate the impact of the three-way handshake and the slow-start phase on a simple HTTP transfer, let’s assume that our client in New York requests a 20 KB file from the server in London over a new TCP connection (Figure 2-5), and the following connection parameters are in place:
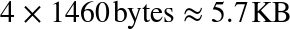 )
)
|
|
Client begins the TCP handshake with the SYN packet. |
|
|
Server replies with SYN-ACK and specifies its rwnd size. |
|
|
Client ACKs the SYN-ACK, specifies its rwnd size, and immediately sends the HTTP GET request. |
|
|
Server receives the HTTP request. |
|
|
Server completes generating the 20 KB response and sends 4 TCP segments before pausing for an ACK (initial cwnd size is 4). |
|
|
Client receives four segments and ACKs each one. |
|
|
Server increments its cwnd for each ACK and sends eight segments. |
|
|
Client receives eight segments and ACKs each one. |
|
|
Server increments its cwnd for each ACK and sends remaining segments. |
|
|
Client receives remaining segments, ACKs each one. |
As an exercise, run through Figure 2-5 with cwnd value set to 10 network segments instead of 4. You should see a full roundtrip of network latency disappear—a 22% improvement in performance!
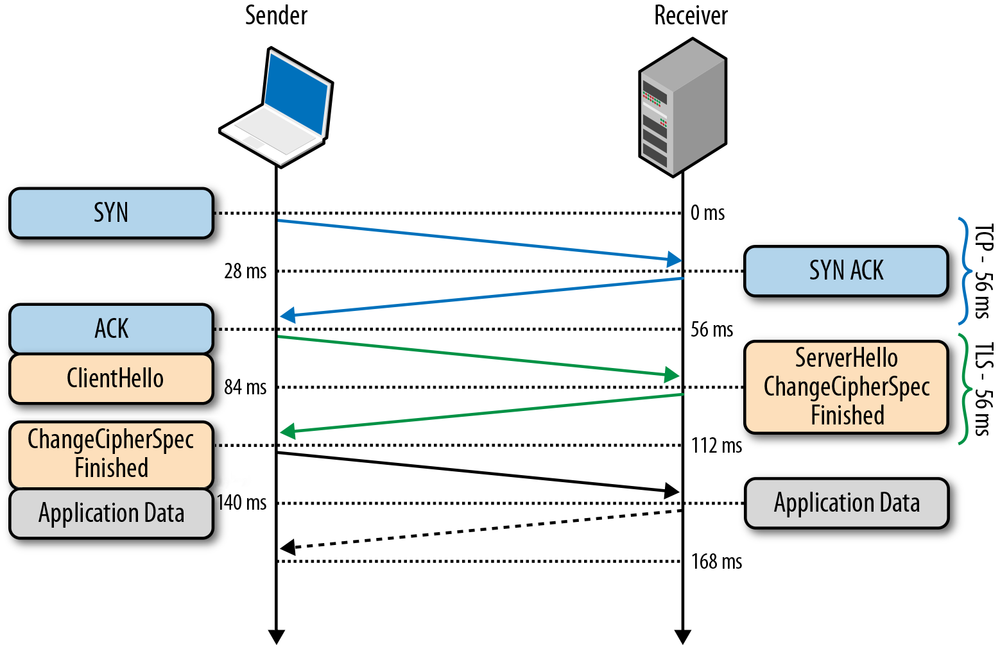
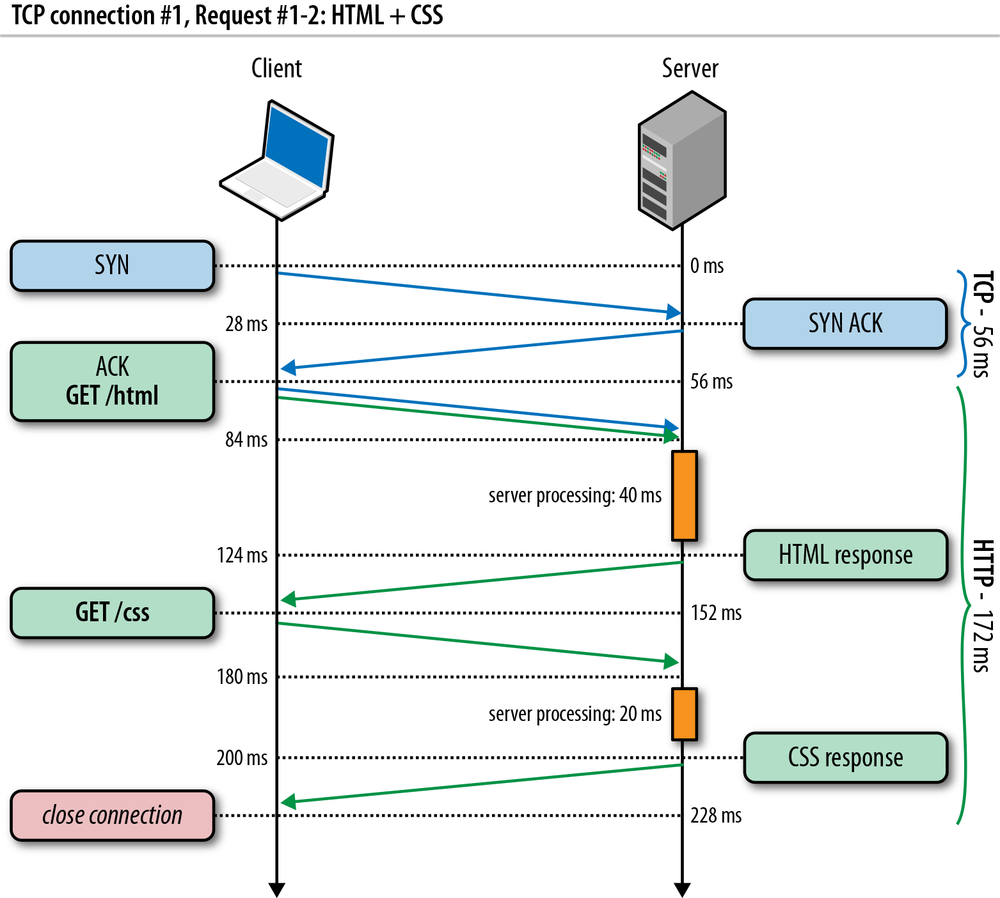
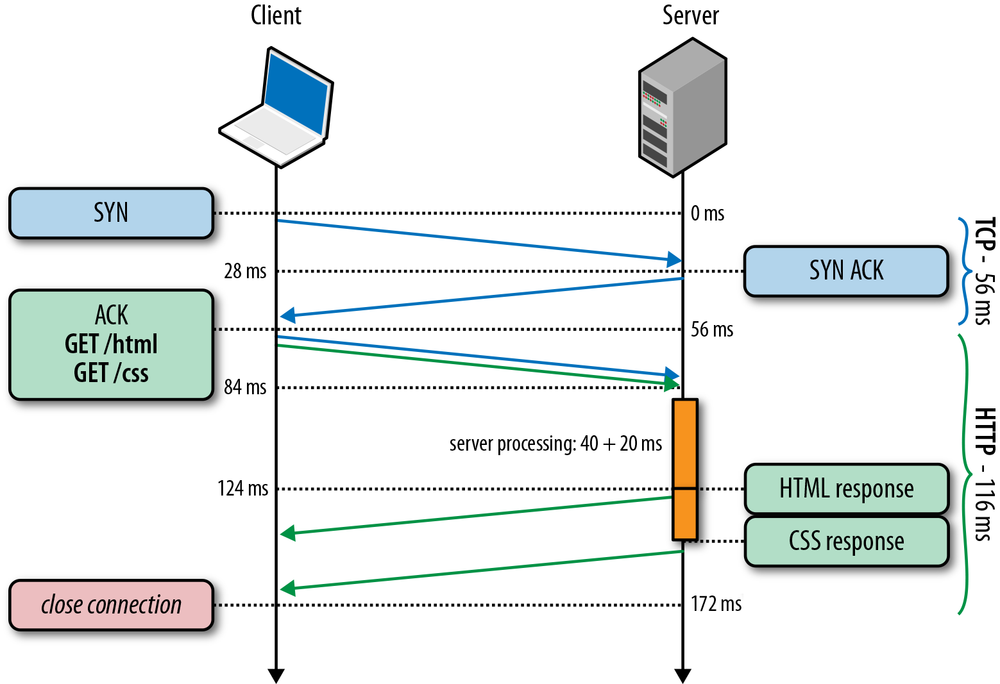
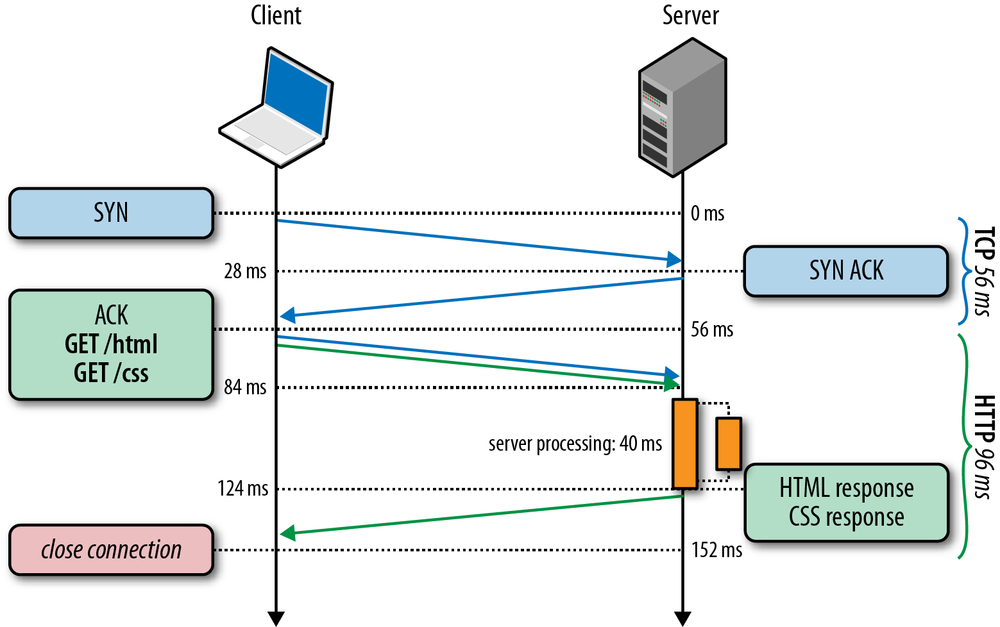
264 ms to transfer the 20 KB file on a new TCP connection with 56 ms roundtrip time between the client and server! By comparison, let’s now assume that the client is able to reuse the same TCP connection (Figure 2-6) and issues the same request once more.
|
|
Client sends the HTTP request. |
|
|
Server receives the HTTP request. |
|
|
Server completes generating the 20 KB response, but the cwnd value is already greater than the 15 segments required to send the file; hence it dispatches all the segments in one burst. |
|
|
Client receives all 15 segments, ACKs each one. |
The same request made on the same connection, but without the cost of the three-way handshake and the penalty of the slow-start phase, now took 96 milliseconds, which translates into a 275% improvement in performance!
In both cases, the fact that both the server and the client have access to 5 Mbps of upstream bandwidth had no impact during the startup phase of the TCP connection. Instead, the latency and the congestion window sizes were the limiting factors.
In fact, the performance gap between the first and the second request dispatched over an existing connection will only widen if we increase the roundtrip time; as an exercise, try it with a few different values. Once you develop an intuition for the mechanics of TCP congestion control, dozens of optimizations such as keepalive, pipelining, and multiplexing will require little further motivation.
It is important to recognize that TCP is specifically designed to use packet loss as a feedback mechanism to help regulate its performance. In other words, it is not a question of if, but rather of when the packet loss will occur. Slow-start initializes the connection with a conservative window and, for every roundtrip, doubles the amount of data in flight until it exceeds the receiver’s flow-control window, a system-configured congestion threshold (ssthresh) window, or until a packet is lost, at which point the congestion avoidance algorithm (Figure 2-3) takes over.
The implicit assumption in congestion avoidance is that packet loss is indicative of network congestion: somewhere along the path we have encountered a congested link or a router, which was forced to drop the packet, and hence we need to adjust our window to avoid inducing more packet loss to avoid overwhelming the network.
Once the congestion window is reset, congestion avoidance specifies its own algorithms for how to grow the window to minimize further loss. At a certain point, another packet loss event will occur, and the process will repeat once over. If you have ever looked at a throughput trace of a TCP connection and observed a sawtooth pattern within it, now you know why it looks as such: it is the congestion control and avoidance algorithms adjusting the congestion window size to account for packet loss in the network.
Finally, it is worth noting that improving congestion control and avoidance is an active area both for academic research and commercial products: there are adaptations for different network types, different types of data transfers, and so on. Today, depending on your platform, you will likely run one of the many variants: TCP Tahoe and Reno (original implementations), TCP Vegas, TCP New Reno, TCP BIC, TCP CUBIC (default on Linux), or Compound TCP (default on Windows), among many others. However, regardless of the flavor, the core performance implications of congestion control and avoidance hold for all.
The built-in congestion control and congestion avoidance mechanisms in TCP carry another important performance implication: the optimal sender and receiver window sizes must vary based on the roundtrip time and the target data rate between them.
To understand why this is the case, first recall that the maximum amount of unacknowledged, in-flight data between the sender and receiver is defined as the minimum of the receive (rwnd) and congestion (cwnd) window sizes: the current receive windows are communicated in every ACK, and the congestion window is dynamically adjusted by the sender based on the congestion control and avoidance algorithms.
If either the sender or receiver exceeds the maximum amount of unacknowledged data, then it must stop and wait for the other end to ACK some of the packets before proceeding. How long would it have to wait? That’s dictated by the roundtrip time between the two!
If either the sender or receiver are frequently forced to stop and wait for ACKs for previous packets, then this would create gaps in the data flow (Figure 2-7), which would consequently limit the maximum throughput of the connection. To address this problem, the window sizes should be made just big enough, such that either side can continue sending data until an ACK arrives back from the client for an earlier packet—no gaps, maximum throughput. Consequently, the optimal window size depends on the roundtrip time! Pick a low window size, and you will limit your connection throughput, regardless of the available or advertised bandwidth between the peers.
So how big do the flow control (rwnd) and congestion control (cwnd) window values need to be? The actual calculation is a simple one. First, let us assume that the minimum of the cwnd and rwnd window sizes is 16 KB, and the roundtrip time is 100 ms:

Regardless of the available bandwidth between the sender and receiver, this TCP connection will not exceed a 1.31 Mbps data rate! To achieve higher throughput we need to raise the minimum window size or lower the roundtrip time.
Similarly, we can compute the optimal window size if we know the roundtrip time and the available bandwidth on both ends. In this scenario, let’s assume that the roundtrip time stays the same (100 ms), but the sender has 10 Mbps of available bandwidth, and the receiver is on a high-throughput 100 Mbps+ link. Assuming there is no network congestion between them, our goal is to saturate the 10 Mbps link available to the client:
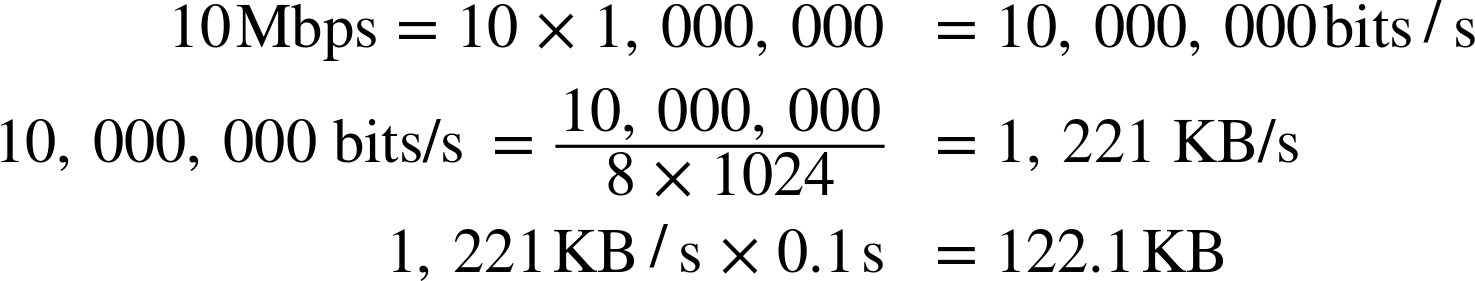
The window size needs to be at least 122.1 KB to saturate the 10 Mbps link. Recall that the maximum receive window size in TCP is 64 KB unless window scaling—see Window Scaling (RFC 1323)—is present: double-check your client and server settings!
The good news is that the window size negotiation and tuning is managed automatically by the network stack and should adjust accordingly. The bad news is sometimes it will still be the limiting factor on TCP performance. If you have ever wondered why your connection is transmitting at a fraction of the available bandwidth, even when you know that both the client and the server are capable of higher rates, then it is likely due to a small window size: a saturated peer advertising low receive window, bad network weather and high packet loss resetting the congestion window, or explicit traffic shaping that could have been applied to limit throughput of your connection.
TCP provides the abstraction of a reliable network running over an unreliable channel, which includes basic packet error checking and correction, in-order delivery, retransmission of lost packets, as well as flow control, congestion control, and congestion avoidance designed to operate the network at the point of greatest efficiency. Combined, these features make TCP the preferred transport for most applications.
However, while TCP is a popular choice, it is not the only, nor necessarily the best choice for every occasion. Specifically, some of the features, such as in-order and reliable packet delivery, are not always necessary and can introduce unnecessary delays and negative performance implications.
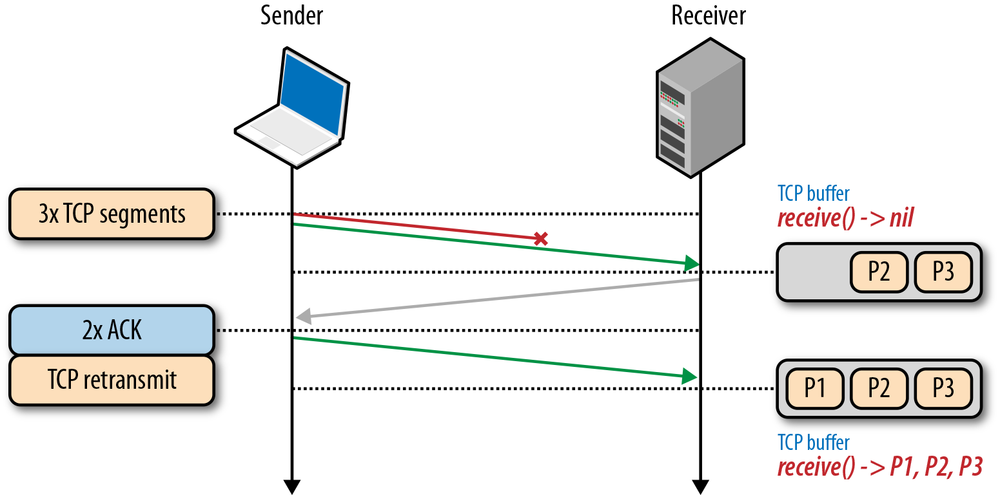
To understand why that is the case, recall that every TCP packet carries a unique sequence number when put on the wire, and the data must be passed to the receiver in-order (Figure 2-8). If one of the packets is lost en route to the receiver, then all subsequent packets must be held in the receiver’s TCP buffer until the lost packet is retransmitted and arrives at the receiver. Because this work is done within the TCP layer, our application has no visibility into the TCP retransmissions or the queued packet buffers, and must wait for the full sequence before it is able to access the data. Instead, it simply sees a delivery delay when it tries to read the data from the socket. This effect is known as TCP head-of-line (HOL) blocking.
The delay imposed by head-of-line blocking allows our applications to avoid having to deal with packet reordering and reassembly, which makes our application code much simpler. However, this is done at the cost of introducing unpredictable latency variation in the packet arrival times, commonly referred to as jitter, which can negatively impact the performance of the application.
Further, some applications may not even need either reliable delivery or in-order delivery: if every packet is a standalone message, then in-order delivery is strictly unnecessary, and if every message overrides all previous messages, then the requirement for reliable delivery can be removed entirely. Unfortunately, TCP does not provide such configuration—all packets are sequenced and delivered in order.
Applications that can deal with out-of-order delivery or packet loss and that are latency or jitter sensitive are likely better served with an alternate transport, such as UDP.
TCP is an adaptive protocol designed to be fair to all network peers and to make the most efficient use of the underlying network. Thus, the best way to optimize TCP is to tune how TCP senses the current network conditions and adapts its behavior based on the type and the requirements of the layers below and above it: wireless networks may need different congestion algorithms, and some applications may need custom quality of service (QoS) semantics to deliver the best experience.
The close interplay of the varying application requirements, and the many knobs in every TCP algorithm, make TCP tuning and optimization an inexhaustible area of academic and commercial research. In this chapter, we have only scratched the surface of the many factors that govern TCP performance. Additional mechanisms, such as selective acknowledgments (SACK), delayed acknowledgments, and fast retransmit, among many others, make each TCP session much more complicated (or interesting, depending on your perspective) to understand, analyze, and tune.
Having said that, while the specific details of each algorithm and feedback mechanism will continue to evolve, the core principles and their implications remain unchanged:
As a result, the rate with which a TCP connection can transfer data in modern high-speed networks is often limited by the roundtrip time between the receiver and sender. Further, while bandwidth continues to increase, latency is bounded by the speed of light and is already within a small constant factor of its maximum value. In most cases, latency, not bandwidth, is the bottleneck for TCP—e.g., see Figure 2-5.
As a starting point, prior to tuning any specific values for each buffer and timeout variable in TCP, of which there are dozens, you are much better off simply upgrading your hosts to their latest system versions. TCP best practices and underlying algorithms that govern its performance continue to evolve, and most of these changes are only available only in the latest kernels. In short, keep your servers up to date to ensure the optimal interaction between the sender’s and receiver’s TCP stacks.
On the surface, upgrading server kernel versions seems like trivial advice. However, in practice, it is often met with significant resistance: many existing servers are tuned for specific kernel versions, and system administrators are reluctant to perform the upgrade.
To be fair, every upgrade brings its risks, but to get the best TCP performance, it is also likely the single best investment you can make.
With the latest kernel in place, it is good practice to ensure that your server is configured to use the following best practices:
The combination of the preceding settings and the latest kernel will enable the best performance—lower latency and higher throughput—for individual TCP connections.
Depending on your application, you may also need to tune other TCP settings on the server to optimize for high connection rates, memory consumption, or similar criteria. However, these configuration settings are dependent on the platform, application, and hardware—consult your platform documentation as required.
Tuning performance of TCP allows the server and client to deliver the best throughput and latency for an individual connection. However, how an application uses each new, or established, TCP connection can have an even greater impact:
Eliminating unnecessary data transfers is, of course, the single best optimization—e.g., eliminating unnecessary resources or ensuring that the minimum number of bits is transferred by applying the appropriate compression algorithm. Following that, locating the bits closer to the client, by geo-distributing servers around the world—e.g., using a CDN—will help reduce latency of network roundtrips and significantly improve TCP performance. Finally, where possible, existing TCP connections should be reused to minimize overhead imposed by slow-start and other congestion mechanisms.
Optimizing TCP performance pays high dividends, regardless of the type of application, for every new connection to your servers. A short list to put on the agenda:
User Datagram Protocol, or UDP, was added to the core network protocol suite in August of 1980 by Jon Postel, well after the original introduction of TCP/IP, but right at the time when the TCP and IP specifications were being split to become two separate RFCs. This timing is important because, as we will see, the primary feature and appeal of UDP is not in what it introduces, but rather in all the features it chooses to omit. UDP is colloquially referred to as a null protocol, and RFC 768, which describes its operation, could indeed fit on a napkin.
The words datagram and packet are often used interchangeably, but there are some nuances. While the term “packet” applies to any formatted block of data, the term “datagram” is often reserved for packets delivered via an unreliable service—no delivery guarantees, no failure notifications. Because of this, you will frequently find the more descriptive term “Unreliable” substituted for the official term “User” in the UDP acronym, to form “Unreliable Datagram Protocol.” That is also why UDP packets are generally, and more correctly, referred to as datagrams.
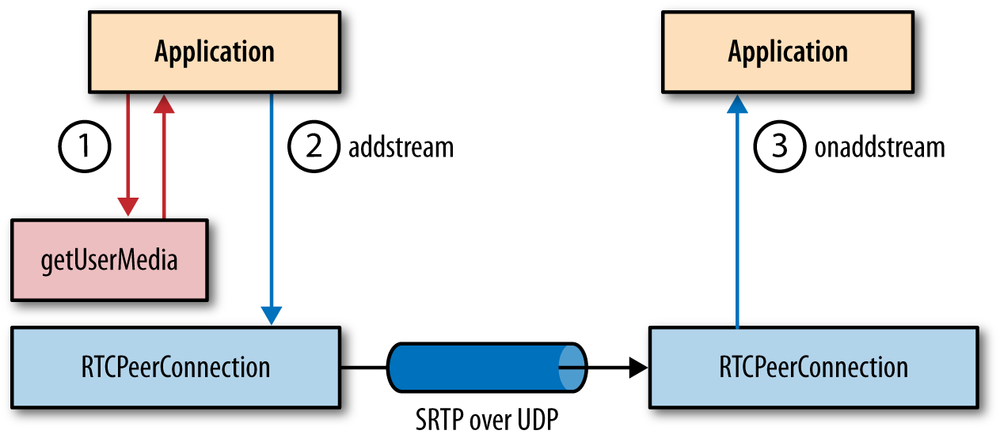
Perhaps the most well-known use of UDP, and one that every browser and Internet application depends on, is the Domain Name System (DNS): given a human-friendly computer hostname, we need to discover its IP address before any data exchange can occur. However, even though the browser itself is dependent on UDP, historically the protocol has never been exposed as a first-class transport for pages and applications running within it. That is, until WebRTC entered into the picture.
The new Web Real-Time Communication (WebRTC) standards, jointly developed by the IETF and W3C working groups, are enabling real-time communication, such as voice and video calling and other forms of peer-to-peer (P2P) communication, natively within the browser via UDP. With WebRTC, UDP is now a first-class browser transport with a client-side API! We will investigate WebRTC in-depth in Chapter 18, but before we get there, let’s first explore the inner workings of the UDP protocol to understand why and where we may want to use it.
To understand UDP and why it is commonly referred to as a “null protocol,” we first need to look at the Internet Protocol (IP), which is located one layer below both TCP and UDP protocols.
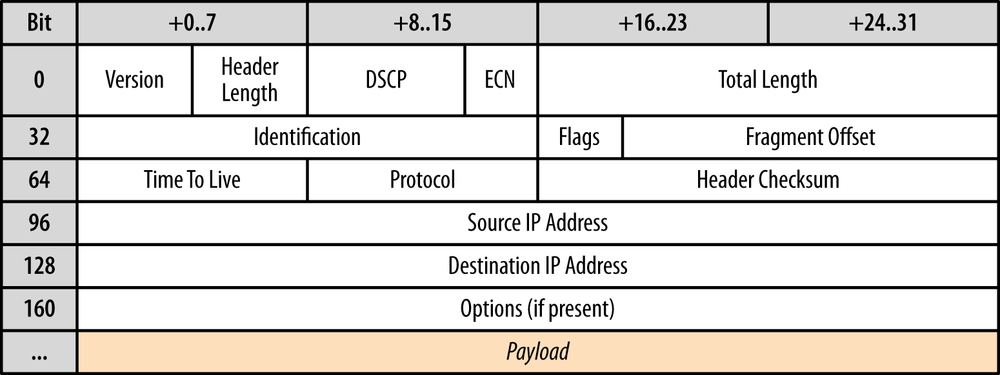
The IP layer has the primary task of delivering datagrams from the source to the destination host based on their addresses. To do so, the messages are encapsulated within an IP packet (Figure 3-1) which identifies the source and the destination addresses, as well as a number of other routing parameters .
Once again, the word “datagram” is an important distinction: the IP layer provides no guarantees about message delivery or notifications of failure and hence directly exposes the unreliability of the underlying network to the layers above it. If a routing node along the way drops the IP packet due to congestion, high load, or for other reasons, then it is the responsibility of a protocol above IP to detect it, recover, and retransmit the data—that is, if that is the desired behavior!
The UDP protocol encapsulates user messages into its own packet structure (Figure 3-2), which adds only four additional fields: source port, destination port, length of packet, and checksum. Thus, when IP delivers the packet to the destination host, the host is able to unwrap the UDP packet, identify the target application by the destination port, and deliver the message. Nothing more, nothing less.
In fact, both the source port and the checksum fields are optional fields in UDP datagrams. The IP packet contains its own header checksum, and the application can choose to omit the UDP checksum, which means that all the error detection and error correction can be delegated to the applications above them. At its core, UDP simply provides “application multiplexing” on top of IP by embedding the source and the target application ports of the communicating hosts. With that in mind, we can now summarize all the UDP non-services:
TCP is a byte-stream oriented protocol capable of transmitting application messages spread across multiple packets without any explicit message boundaries within the packets themselves. To achieve this, connection state is allocated on both ends of the connection, and each packet is sequenced, retransmitted when lost, and delivered in order. UDP datagrams, on the other hand, have definitive boundaries: each datagram is carried in a single IP packet, and each application read yields the full message; datagrams cannot be fragmented.
UDP is a simple, stateless protocol, suitable for bootstrapping other application protocols on top: virtually all of the protocol design decisions are left to the application above it. However, before you run away to implement your own protocol to replace TCP, you should think carefully about complications such as UDP interaction with the many layers of deployed middleboxes (NAT traversal), as well as general network protocol design best practices. Without careful engineering and planning, it is not uncommon to start with a bright idea for a new protocol but end up with a poorly implemented version of TCP. The algorithms and the state machines in TCP have been honed and improved over decades and have taken into account dozens of mechanisms that are anything but easy to replicate well.
Unfortunately, IPv4 addresses are only 32 bits long, which provides a maximum of 4.29 billion unique IP addresses. The IP Network Address Translator (NAT) specification was introduced in mid-1994 (RFC 1631) as an interim solution to resolve the looming IPv4 address depletion problem—as the number of hosts on the Internet began to grow exponentially in the early ’90s, we could not expect to allocate a unique IP to every host.
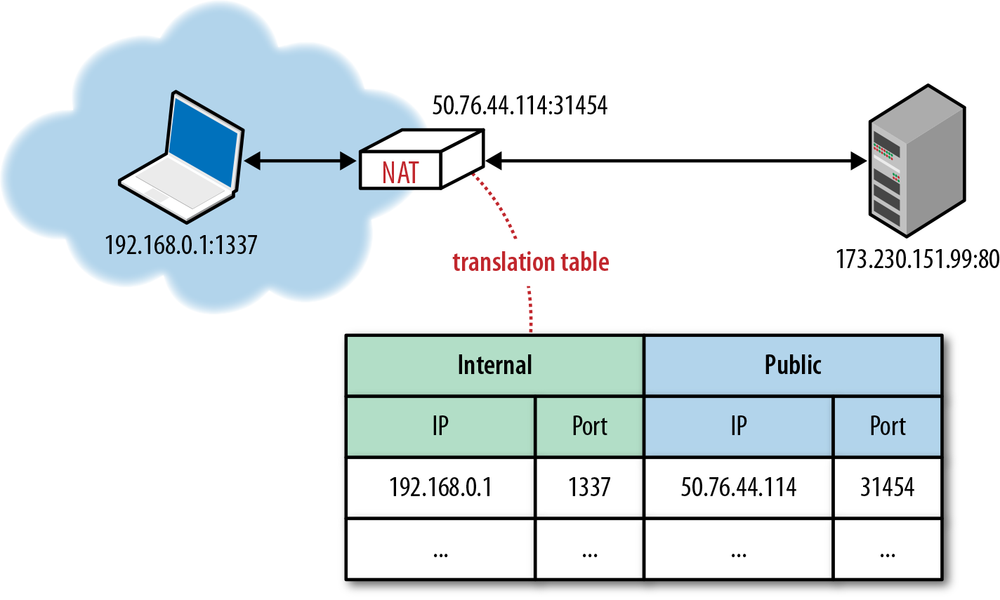
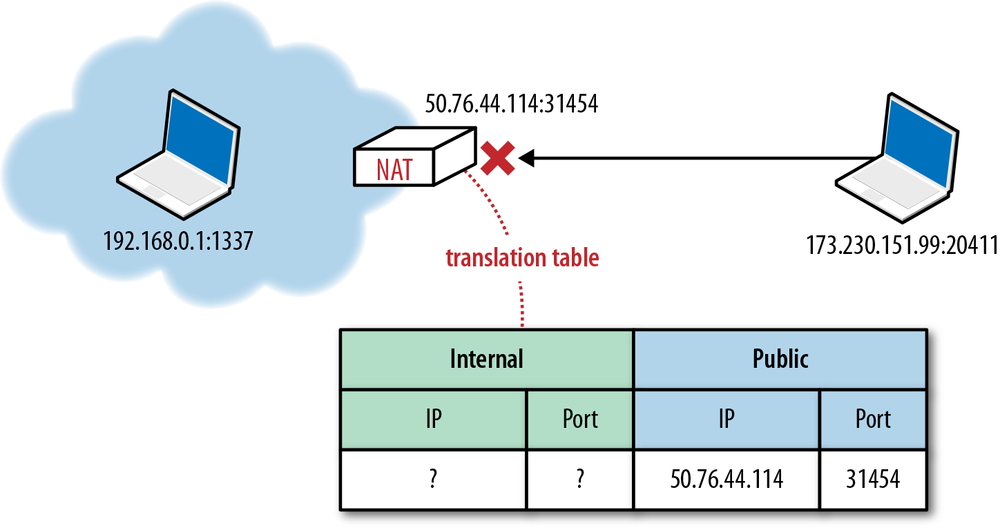
The proposed IP reuse solution was to introduce NAT devices at the edge of the network, each of which would be responsible for maintaining a table mapping of local IP and port tuples to one or more globally unique (public) IP and port tuples (Figure 3-3). The local IP address space behind the translator could then be reused among many different networks, thus solving the address depletion problem.
Unfortunately, as it often happens, there is nothing more permanent than a temporary solution. Not only did the NAT devices resolve the immediate problem, but they also quickly became a ubiquitous component of many corporate and home proxies and routers, security appliances, firewalls, and dozens of other hardware and software devices. NAT middleboxes are no longer a temporary solution; rather, they have become an integral part of the Internet infrastructure.
The issue with NAT translation, at least as far as UDP is concerned, is precisely the routing table that it must maintain to deliver the data. NAT middleboxes rely on connection state, whereas UDP has none. This is a fundamental mismatch and a source of many problems for delivering UDP datagrams. Further, it is now not uncommon for a client to be behind many layers of NATs, which only complicates matters further.
Each TCP connection has a well-defined protocol state machine, which begins with a handshake, followed by application data transfer, and a well-defined exchange to close the connection. Given this flow, each middlebox can observe the state of the connection and create and remove the routing entries as needed. With UDP, there is no handshake or connection termination, and hence there is no connection state machine to monitor.
Delivering outbound UDP traffic does not require any extra work, but routing a reply requires that we have an entry in the translation table, which will tell us the IP and port of the local destination host. Thus, translators have to keep state about each UDP flow, which itself is stateless.
Even worse, the translator is also tasked with figuring out when to drop the translation record, but since UDP has no connection termination sequence, either peer could just stop transmitting datagrams at any point without notice. To address this, UDP routing records are expired on a timer. How often? There is no definitive answer; instead the timeout depends on the vendor, make, version, and configuration of the translator. Consequently, one of the de facto best practices for long-running sessions over UDP is to introduce bidirectional keepalive packets to periodically reset the timers for the translation records in all the NAT devices along the path.
Unpredictable connection state handling is a serious issue created by NATs, but an even larger problem for many applications is the inability to establish a UDP connection at all. This is especially true for P2P applications, such as VoIP, games, and file sharing, which often need to act as both client and server to enable two-way direct communication between the peers.
The first issue is that in the presence of a NAT, the internal client is unaware of its public IP: it knows its internal IP address, and the NAT devices perform the rewriting of the source port and address in every UDP packet, as well as the originating IP address within the IP packet. However, if the client communicates its private IP address as part of its application data with a peer outside of its private network, then the connection will inevitably fail. Hence, the promise of “transparent” translation is no longer true, and the application must first discover its public IP address if it needs to share it with a peer outside its private network.
However, knowing the public IP is also not sufficient to successfully transmit with UDP. Any packet that arrives at the public IP of a NAT device must also have a destination port and an entry in the NAT table that can translate it to an internal destination host IP and port tuple. If this entry does not exist, which is the most likely case if someone simply tries to transmit data from the public network, then the packet is simply dropped (Figure 3-4). The NAT device acts as a simple packet filter since it has no way to automatically determine the internal route, unless explicitly configured by the user through a port-forwarding or similar mechanism.
It is important to note that the preceding behavior is not an issue for client applications, which begin their interaction from the internal network and in the process establish the necessary translation records along the path. However, handling inbound connections (acting as a server) from P2P applications such as VoIP, game consoles, file sharing, and so on, in the presence of a NAT, is where we will immediately run into this problem.
To work around this mismatch in UDP and NATs, various traversal techniques (TURN, STUN, ICE) have to be used to establish end-to-end connectivity between the UDP peers on both sides.
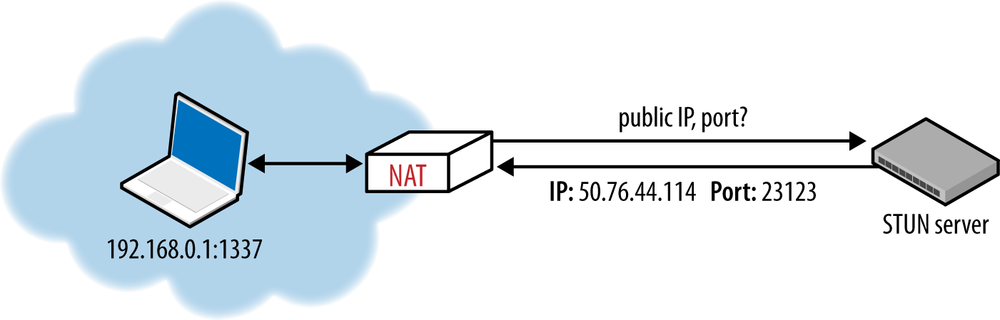
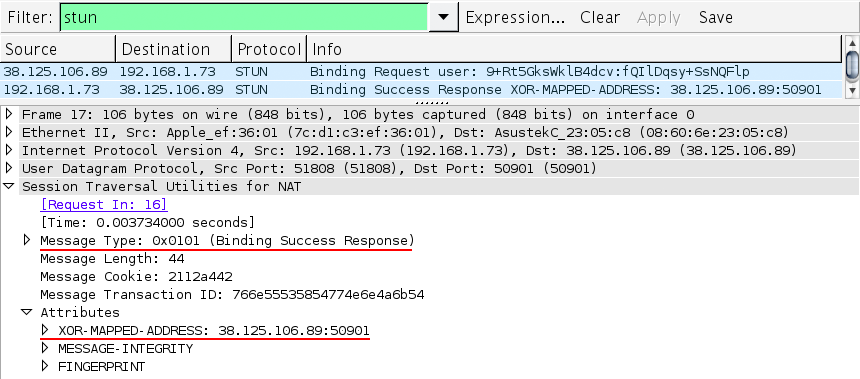
Session Traversal Utilities for NAT (STUN) is a protocol (RFC 5389) that allows the host application to discover the presence of a network address translator on the network, and when present to obtain the allocated public IP and port tuple for the current connection (Figure 3-5). To do so, the protocol requires assistance from a well-known, third-party STUN server that must reside on the public network.
Assuming the IP address of the STUN server is known (through DNS discovery, or through a manually specified address), the application first sends a binding request to the STUN server. In turn, the STUN server replies with a response that contains the public IP address and port of the client as seen from the public network. This simple workflow addresses several problems we encountered in our earlier discussion:
With this mechanism in place, whenever two peers want to talk to each other over UDP, they will first send binding requests to their respective STUN servers, and following a successful response on both sides, they can then use the established public IP and port tuples to exchange data.
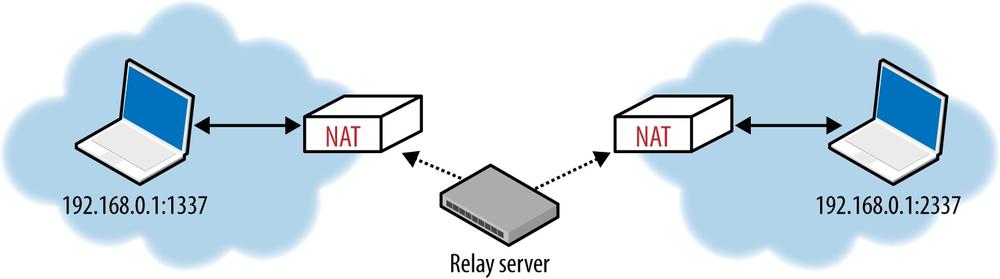
However, in practice, STUN is not sufficient to deal with all NAT topologies and network configurations. Further, unfortunately, in some cases UDP may be blocked altogether by a firewall or some other network appliance—not an uncommon scenario for many enterprise networks. To address this issue, whenever STUN fails, we can use the Traversal Using Relays around NAT (TURN) protocol (RFC 5766) as a fallback, which can run over UDP and switch to TCP if all else fails.
The key word in TURN is, of course, “relays.” The protocol relies on the presence and availability of a public relay (Figure 3-6) to shuttle the data between the peers.
Of course, the obvious downside in this exchange is that it is no longer peer-to-peer! TURN is the most reliable way to provide connectivity between any two peers on any networks, but it carries a very high cost of operating the TURN server—at the very least, the relay must have enough capacity to service all the data flows. As a result, TURN is best used as a last resort fallback for cases where direct connectivity fails.
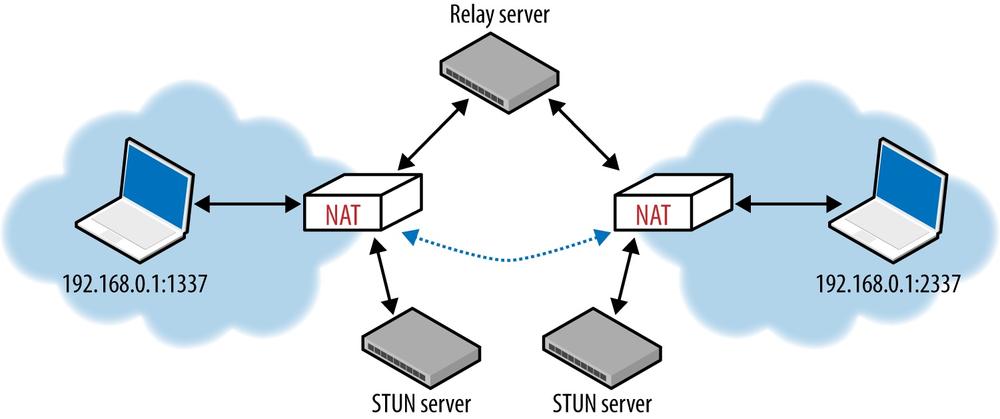
Building an effective NAT traversal solution is not for the faint of heart. Thankfully, we can lean on Interactive Connectivity Establishment (ICE) protocol (RFC 5245) to help with this task. ICE is a protocol, and a set of methods, that seek to establish the most efficient tunnel between the participants (Figure 3-7): direct connection where possible, leveraging STUN negotiation where needed, and finally fallback to TURN if all else fails.
In practice, if you are building a P2P application over UDP, then you most definitely want to leverage an existing platform API, or a third-party library that implements ICE, STUN, and TURN for you. And now that you are familiar with what each of these protocols does, you can navigate your way through the required setup and configuration!
UDP is a simple and a commonly used protocol for bootstrapping new transport protocols. In fact, the primary feature of UDP is all the features it omits: no connection state, handshakes, retransmissions, reassembly, reordering, congestion control, congestion avoidance, flow control, or even optional error checking. However, the flexibility that this minimal message-oriented transport layer affords is also a liability for the implementer. Your application will likely have to reimplement some, or many, of these features from scratch, and each must be designed to play well with other peers and protocols on the network.
Unlike TCP, which ships with built-in flow and congestion control and congestion avoidance, UDP applications must implement these mechanisms on their own. Congestion insensitive UDP applications can easily overwhelm the network, which can lead to degraded network performance and, in severe cases, to network congestion collapse.
If you want to leverage UDP for your own application, make sure to research and read the current best practices and recommendations. One such document is the RFC 5405, which specifically focuses on design guidelines for applications delivered via unicast UDP. Here is a short sample of the recommendations:
Designing a new transport protocol requires a lot of careful thought, planning, and research—do your due diligence. Where possible, leverage an existing library or a framework that has already taken into account NAT traversal, and is able to establish some degree of fairness with other sources of concurrent network traffic.
On that note, good news: WebRTC is just such a framework!
The SSL protocol was originally developed at Netscape to enable ecommerce transaction security on the Web, which required encryption to protect customers’ personal data, as well as authentication and integrity guarantees to ensure a safe transaction. To achieve this, the SSL protocol was implemented at the application layer, directly on top of TCP (Figure 4-1), enabling protocols above it (HTTP, email, instant messaging, and many others) to operate unchanged while providing communication security when communicating across the network.
When SSL is used correctly, a third-party observer can only infer the connection endpoints, type of encryption, as well as the frequency and an approximate amount of data sent, but cannot read or modify any of the actual data.
When the SSL protocol was standardized by the IETF, it was renamed to Transport Layer Security (TLS). Many use the TLS and SSL names interchangeably, but technically, they are different, since each describes a different version of the protocol.
SSL 2.0 was the first publicly released version of the protocol, but it was quickly replaced by SSL 3.0 due to a number of discovered security flaws. Because the SSL protocol was proprietary to Netscape, the IETF formed an effort to standardize the protocol, resulting in RFC 2246, which became known as TLS 1.0 and is effectively an upgrade to SSL 3.0:
The differences between this protocol and SSL 3.0 are not dramatic, but they are significant to preclude interoperability between TLS 1.0 and SSL 3.0.
— The TLS Protocol RFC 2246
Since the publication of TLS 1.0 in January 1999, two new versions have been produced by the IETF working group to address found security flaws, as well as to extend the capabilities of the protocol: TLS 1.1 in April 2006 and TLS 1.2 in August 2008. Internally the SSL 3.0 implementation, as well as all subsequent TLS versions, are very similar, and many clients continue to support SSL 3.0 and TLS 1.0 to this day, although there are very good reasons to upgrade to newer versions to protect users from known attacks!
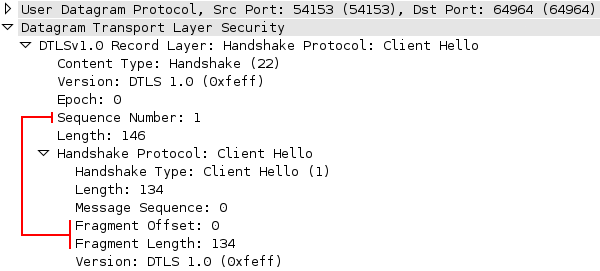
TLS was designed to operate on top of a reliable transport protocol such as TCP. However, it has also been adapted to run over datagram protocols such as UDP. The Datagram Transport Layer Security (DTLS) protocol, defined in RFC 6347, is based on the TLS protocol and is able to provide similar security guarantees while preserving the datagram delivery model.
The TLS protocol is designed to provide three essential services to all applications running above it: encryption, authentication, and data integrity. Technically, you are not required to use all three in every situation. You may decide to accept a certificate without validating its authenticity, but you should be well aware of the security risks and implications of doing so. In practice, a secure web application will leverage all three services.
In order to establish a cryptographically secure data channel, the connection peers must agree on which ciphersuites will be used and the keys used to encrypt the data. The TLS protocol specifies a well-defined handshake sequence to perform this exchange, which we will examine in detail in TLS Handshake. The ingenious part of this handshake, and the reason TLS works in practice, is its use of public key cryptography (also known as asymmetric key cryptography), which allows the peers to negotiate a shared secret key without having to establish any prior knowledge of each other, and to do so over an unencrypted channel.
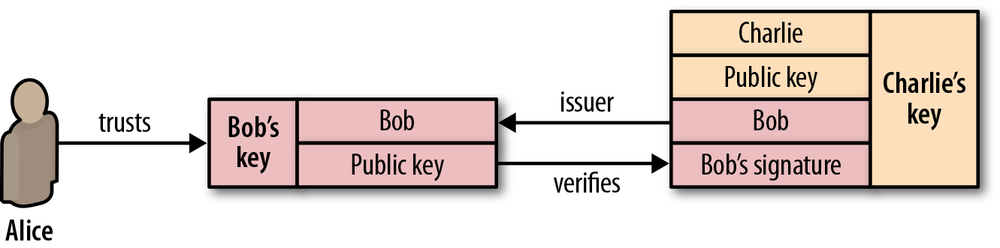
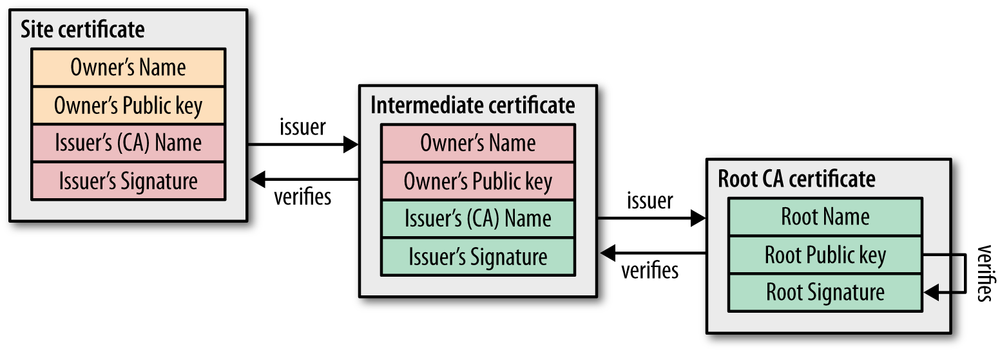
As part of the TLS handshake, the protocol also allows both connection peers to authenticate their identity. When used in the browser, this authentication mechanism allows the client to verify that the server is who it claims to be (e.g., your bank) and not someone simply pretending to be the destination by spoofing its name or IP address. This verification is based on the established chain of trust; see Chain of Trust and Certificate Authorities). In addition, the server can also optionally verify the identity of the client—e.g., a company proxy server can authenticate all employees, each of whom could have his own unique certificate signed by the company.
Finally, with encryption and authentication in place, the TLS protocol also provides its own message framing mechanism and signs each message with a message authentication code (MAC). The MAC algorithm is a one-way cryptographic hash function (effectively a checksum), the keys to which are negotiated by both connection peers. Whenever a TLS record is sent, a MAC value is generated and appended for that message, and the receiver is then able to compute and verify the sent MAC value to ensure message integrity and authenticity.
Combined, all three mechanisms serve as a foundation for secure communication on the Web. All modern web browsers provide support for a variety of ciphersuites, are able to authenticate both the client and server, and transparently perform message integrity checks for every record.
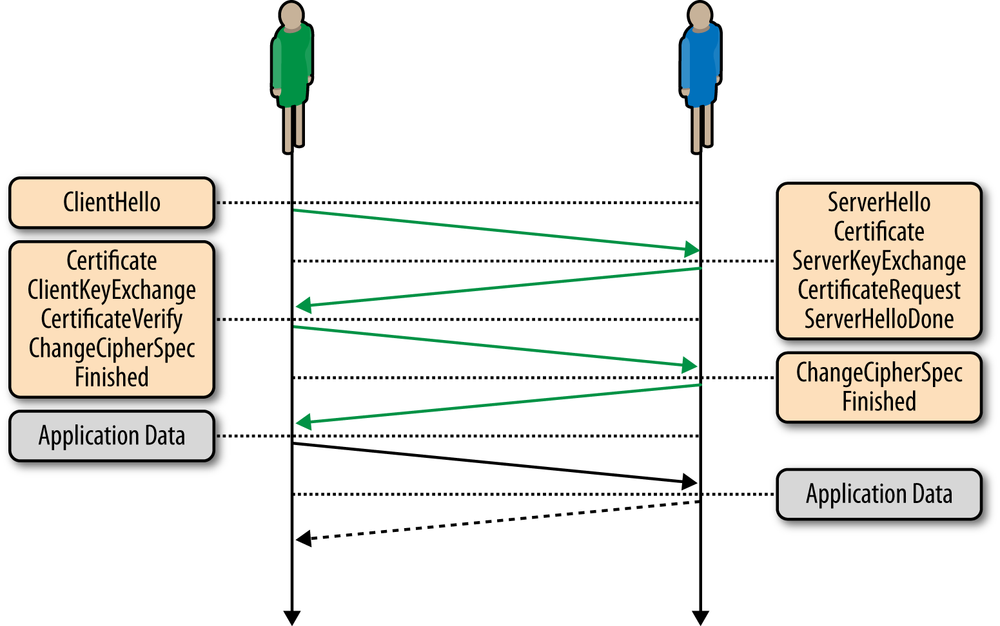
Before the client and the server can begin exchanging application data over TLS, the encrypted tunnel must be negotiated: the client and the server must agree on the version of the TLS protocol, choose the ciphersuite, and verify certificates if necessary. Unfortunately, each of these steps requires new packet roundtrips (Figure 4-2) between the client and the server, which adds startup latency to all TLS connections.
Figure 4-2 assumes the same 28 millisecond one-way “light in fiber” delay between New York and London as used in previous TCP connection establishment examples; see Table 1-1.
|
|
TLS runs over a reliable transport (TCP), which means that we must first complete the TCP three-way handshake, which takes one full roundtrip. |
|
|
With the TCP connection in place, the client sends a number of specifications in plain text, such as the version of the TLS protocol it is running, the list of supported ciphersuites, and other TLS options it may want to use. |
|
|
The server picks the TLS protocol version for further communication, decides on a ciphersuite from the list provided by the client, attaches its certificate, and sends the response back to the client. Optionally, the server can also send a request for the client’s certificate and parameters for other TLS extensions. |
|
|
Assuming both sides are able to negotiate a common version and cipher, and the client is happy with the certificate provided by the server, the client initiates either the RSA or the Diffie-Hellman key exchange, which is used to establish the symmetric key for the ensuing session. |
|
|
The server processes the key exchange parameters sent by the client, checks message integrity by verifying the MAC, and returns an encrypted “Finished” message back to the client. |
|
|
The client decrypts the message with the negotiated symmetric key, verifies the MAC, and if all is well, then the tunnel is established and application data can now be sent. |
Negotiating a secure TLS tunnel is a complicated process, and there are many ways to get it wrong. The good news is all the work just shown will be done for us by the server and the browser, and all we need to do is provide and configure the certificates.
Having said that, while our web applications do not have to drive the preceding exchange, it is nonetheless important to realize that every TLS connection will require up to two extra roundtrips on top of the TCP handshake—that’s a long time to wait before any application data can be exchanged! If not managed carefully, delivering application data over TLS can add hundreds, if not thousands of milliseconds of network latency.
Due to a variety of historical and commercial reasons the RSA handshake has been the dominant key exchange mechanism in most TLS deployments: the client generates a symmetric key, encrypts it with the server’s public key, and sends it to the server to use as the symmetric key for the established session. In turn, the server uses its private key to decrypt the sent symmetric key and the key-exchange is complete. From this point forward the client and server use the negotiated symmetric key to encrypt their session.
The RSA handshake works, but has a critical weakness: the same public-private key pair is used both to authenticate the server and to encrypt the symmetric session key sent to the server. As a result, if an attacker gains access to the server’s private key and listens in on the exchange, then they can decrypt the the entire session. Worse, even if an attacker does not currently have access to the private key, they can still record the encrypted session and decrypt it at a later time once they obtain the private key.
By contrast, the Diffie-Hellman key exchange allows the client and server to negotiate a shared secret without explicitly communicating it in the handshake: the server’s private key is used to sign and verify the handshake, but the established symmetric key never leaves the client or server and cannot be intercepted by a passive attacker even if they have access to the private key.
For the curious, the Wikipedia article on Diffie-Hellman key exchange is a great place to learn about the algorithm and its properties.
Best of all, Diffie-Hellman key exchange can be used to reduce the risk of compromise of past communication sessions: we can generate a new “ephemeral” symmetric key as part of each and every key exchange and discard the previous keys. As a result, because the ephemeral keys are never communicated and are actively renegotiated for each the new session, the worst-case scenario is that an attacker could compromise the client or server and access the session keys of the current and future sessions. However, knowing the private key, or the ephemeral key, for those session does not help attacker decrypt any of the previous sessions!
The combination of Diffie-Hellman and the use of ephemeral session keys are what enables “Forward Secrecy”: even if an attacker gains access to the server’s private key they are not able to passively listen in on the active session, nor can they decrypt previously recorded sessions.
Despite the historical dominance of the RSA handshake, it is now being actively phased out to address the weaknesses we saw above: all the popular browsers prefer ciphers that enable forward secrecy (i.e., Diffie-Hellman key exchange), and may only enable certain protocol optimizations when forward secrecy is available. Long story short, consult your server documentation on how to enable forward secrecy.
Two network peers may want to use a custom application protocol to communicate with each other. One way to resolve this is to determine the protocol upfront, assign a well-known port to it (e.g., port 80 for HTTP, port 443 for TLS), and configure all clients and servers to use it. However, in practice, this is a slow and impractical process: each port assignment must be approved and, worse, firewalls and other intermediaries often permit traffic only on ports 80 and 443.
As a result, to enable easy deployment of custom protocols, we must reuse ports 80 or 443 and use an additional mechanism to negotiate the application protocol. Port 80 is reserved for HTTP, and the HTTP specification provides a special Upgrade flow for this very purpose. However, the use of Upgrade can add an extra network roundtrip of latency, and in practice is often unreliable in the presence of many intermediaries; see Proxies, Intermediaries, TLS, and New Protocols on the Web.
For a hands-on example of HTTP Upgrade flow, flip ahead to Upgrading to HTTP/2.
The solution is, you guessed it, to use port 443, which is reserved for secure HTTPS sessions (running over TLS). The use of an end-to-end encrypted tunnel obfuscates the data from intermediate proxies and enables a quick and reliable way to deploy new and arbitrary application protocols. However, while use of TLS addresses reliability, we still need a way to negotiate the protocol!
An HTTPS session could, of course, reuse the HTTP Upgrade mechanism to perform the require negotiation, but this would result in another full roundtrip of latency. What if we could negotiate the protocol as part of the TLS handshake itself?
As the name implies, Application Layer Protocol Negotiation (ALPN) is a TLS extension that introduces support for application protocol negotiation into the TLS handshake (Figure 4-2), thereby eliminating the need for an extra roundtrip required by the HTTP Upgrade workflow. Specifically, the process is as follows:
ProtocolNameList field, containing the list of supported application protocols, into the ClientHello message.
ProtocolNameList field and returns a ProtocolName field indicating the selected protocol as part of the ServerHello message.
The server may respond with only a single protocol name, and if it does not support any that the client requests, then it may choose to abort the connection. As a result, once the TLS handshake is complete, both the secure tunnel is established, and the client and server are in agreement as to which application protocol will be used, they can begin communicating immediately.
ALPN eliminates the need for the HTTP Upgrade exchange, saving an extra roundtrip of latency. However, note that the TLS handshake itself still must be performed; hence ALPN negotiation is not any faster than HTTP Upgrade over an unencrypted channel. Instead, it ensures that application protocol negotiation over TLS is not any slower.
An encrypted TLS tunnel can be established between any two TCP peers: the client only needs to know the IP address of the other peer to make the connection and perform the TLS handshake. However, what if the server wants to host multiple independent sites, each with its own TLS certificate, on the same IP address—how does that work? Trick question; it doesn’t.
To address the preceding problem, the Server Name Indication (SNI) extension was introduced to the TLS protocol, which allows the client to indicate the hostname the client is attempting to connect to at the start of the handshake. As a result, a web server can inspect the SNI hostname, select the appropriate certificate, and continue the handshake.
The extra latency and computational costs of the full TLS handshake impose a serious performance penalty on all applications that require secure communication. To help mitigate some of the costs, TLS provides an ability to resume or share the same negotiated secret key data between multiple connections.
The first Session Identifiers (RFC 5246) resumption mechanism was introduced in SSL 2.0, which allowed the server to create and send a 32-byte session identifier as part of its “ServerHello” message during the full TLS negotiation we saw earlier.
Internally, the server could then maintain a cache of session IDs and the negotiated session parameters for each peer. In turn, the client could then also store the session ID information and include the ID in the “ClientHello” message for a subsequent session, which serves as an indication to the server that the client still remembers the negotiated cipher suite and keys from previous handshake and is able to reuse them. Assuming both the client and the server are able to find the shared session ID parameters in their respective caches, then an abbreviated handshake (Figure 4-3) can take place. Otherwise, a full new session negotiation is required, which will generate a new session ID.
Leveraging session identifiers allows us to remove a full roundtrip, as well as the overhead of public key cryptography, which is used to negotiate the shared secret key. This allows a secure connection to be established quickly and with no loss of security, since we are reusing the previously negotiated session data.
In practice, most web applications attempt to establish multiple connections to the same host to fetch resources in parallel, which makes session resumption a must-have optimization to reduce latency and computational costs for both sides.
Most modern browsers intentionally wait for the first TLS connection to complete before opening new connections to the same server: subsequent TLS connections can reuse the SSL session parameters to avoid the costly handshake.
However, one of the practical limitations of the Session Identifiers mechanism is the requirement for the server to create and maintain a session cache for every client. This results in several problems on the server, which may see tens of thousands or even millions of unique connections every day: consumed memory for every open TLS connection, a requirement for session ID cache and eviction policies, and nontrivial deployment challenges for popular sites with many servers, which should, ideally, use a shared TLS session cache for best performance.
None of the preceding problems are impossible to solve, and many high-traffic sites are using session identifiers successfully today. But for any multiserver deployment, session identifiers will require some careful thinking and systems architecture to ensure a well operating session cache.
To address this concern for server-side deployment of TLS session caches, the “Session Ticket” (RFC 5077) replacement mechanism was introduced, which removes the requirement for the server to keep per-client session state. Instead, if the client indicated that it supports Session Tickets, in the last exchange of the full TLS handshake, the server can include a New Session Ticket record, which includes all of the session data encrypted with a secret key known only by the server.
This session ticket is then stored by the client and can be included in the SessionTicket extension within the ClientHello message of a subsequent session. Thus, all session data is stored only on the client, but the ticket is still safe because it is encrypted with a key known only by the server.
The session identifiers and session ticket mechanisms are respectively commonly referred to as session caching and stateless resumption mechanisms. The main improvement of stateless resumption is the removal of the server-side session cache, which simplifies deployment by requiring that the client provide the session ticket on every new connection to the server—that is, until the ticket has expired.
In practice, deploying session tickets across a set of load-balanced servers also requires some careful thinking and systems architecture: all servers must be initialized with the same session key, and an additional mechanism may be needed to periodically rotate the shared key across all servers.
Authentication is an integral part of establishing every TLS connection. After all, it is possible to carry out a conversation over an encrypted tunnel with any peer, including an attacker, and unless we can be sure that the computer we are speaking to is the one we trust, then all the encryption work could be for nothing. To understand how we can verify the peer’s identity, let’s examine a simple authentication workflow between Alice and Bob:
Trust is a key component of the preceding exchange. Specifically, public key encryption allows us to use the public key of the sender to verify that the message was signed with the right private key, but the decision to approve the sender is still one that is based on trust. In the exchange just shown, Alice and Bob could have exchanged their public keys when they met in person, and because they know each other well, they are certain that their exchange was not compromised by an impostor—perhaps they even verified their identities through another, secret (physical) handshake they had established earlier!
Next, Alice receives a message from Charlie, whom she has never met, but who claims to be a friend of Bob’s. In fact, to prove that he is friends with Bob, Charlie asked Bob to sign his own public key with Bob’s private key and attached this signature with his message (Figure 4-4). In this case, Alice first checks Bob’s signature of Charlie’s key. She knows Bob’s public key and is thus able to verify that Bob did indeed sign Charlie’s key. Because she trusts Bob’s decision to verify Charlie, she accepts the message and performs a similar integrity check on Charlie’s message to ensure that it is, indeed, from Charlie.
What we have just done is established a chain of trust: Alice trusts Bob, Bob trusts Charlie, and by transitive trust, Alice decides to trust Charlie. As long as nobody in the chain gets compromised, this allows us to build and grow the list of trusted parties.
Authentication on the Web and in your browser follows the exact same process as shown. Which means that at this point you should be asking: whom does your browser trust, and whom do you trust when you use the browser? There are at least three answers to this question:
In practice, it would be impractical to store and manually verify each and every key for every website (although you can, if you are so inclined). Hence, the most common solution is to use certificate authorities (CAs) to do this job for us (Figure 4-5): the browser specifies which CAs to trust (root CAs), and the burden is then on the CAs to verify each site they sign, and to audit and verify that these certificates are not misused or compromised. If the security of any site with the CA’s certificate is breached, then it is also the responsibility of that CA to revoke the compromised certificate.
Every browser allows you to inspect the chain of trust of your secure connection (Figure 4-6), usually accessible by clicking on the lock icon beside the URL.
The “trust anchor” for the entire chain is the root certificate authority, which in the case just shown, is the StartCom Certification Authority. Every browser ships with a pre-initialized list of trusted certificate authorities (“roots”), and in this case, the browser trusts and is able to verify the StartCom root certificate. Hence, through a transitive chain of trust in the browser, the browser vendor, and the StartCom certificate authority, we extend the trust to our destination site.
Every operating system vendor and every browser provide a public listing of all the certificate authorities they trust by default. Use your favorite search engine to find and investigate these lists.
In practice, there are hundreds of well-known and trusted certificate authorities, which is also a common complaint against the system. The large number of CAs creates a potentially large attack surface area against the chain of trust in your browser.
Occasionally the issuer of a certificate will need to revoke or invalidate the certificate due to a number of possible reasons: the private key of the certificate has been compromised, the certificate authority itself has been compromised, or due to a variety of more benign reasons such as a superseding certificate, change in affiliation, and so on. To address this, the certificates themselves contain instructions (Figure 4-7) on how to check if they have been revoked. Hence, to ensure that the chain of trust is not compromised, each peer can check the status of each certificate by following the embedded instructions, along with the signatures, as it walks up the certificate chain.
Certificate Revocation List (CRL) is defined by RFC 5280 and specifies a simple mechanism to check the status of every certificate: each certificate authority maintains and periodically publishes a list of revoked certificate serial numbers. Anyone attempting to verify a certificate is then able to download the revocation list and check the presence of the serial number within it—if it is present, then it has been revoked.
The CRL file itself can be published periodically or on every update and can be delivered via HTTP, or any other file transfer protocol. The list is also signed by the CA, and is usually allowed to be cached for a specified interval. In practice, this workflow works quite well, but there are instances where CRL mechanism may be insufficient:
To address some of the limitations of the CRL mechanism, the Online Certificate Status Protocol (OCSP) was introduced by RFC 2560, which provides a mechanism to perform a real-time check for status of the certificate. Unlike the CRL, which contains all the revoked serial numbers, OCSP allows the verifier to query the certificate database directly for just the serial number in question while validating the certificate chain.
As a result, the OCSP mechanism should consume much less bandwidth and is able to provide real-time validation. However, no mechanism is perfect! The requirement to perform real-time OCSP queries creates several problems of its own:
In practice, CRL and OCSP mechanisms are complementary, and most certificates will provide instructions and endpoints for both.
The more important part is the client support and behavior: some browsers distribute their own CRL lists, others fetch and cache the CRL files from the CAs. Similarly, some browsers will perform the real-time OCSP check but will differ in their behavior if the OCSP request fails. If you are curious, check your browser and OS certificate revocation settings!
Not unlike the IP or TCP layers below it, all data exchanged within a TLS session is also framed using a well-defined protocol (Figure 4-8). The TLS Record protocol is responsible for identifying different types of messages (handshake, alert, or data via the “Content Type” field), as well as securing and verifying the integrity of each message.
A typical workflow for delivering application data is as follows:
Once these steps are complete, the encrypted data is passed down to the TCP layer for transport. On the receiving end, the same workflow, but in reverse, is applied by the peer: decrypt data using negotiated cipher, verify MAC, extract and deliver the data to the application above it.
Once again, the good news is all the work just shown is handled by the TLS layer itself and is completely transparent to most applications. However, the record protocol does introduce a few important implications that you should be aware of:
Picking the right record size for your application, if you have the ability to do so, can be an important optimization. Small records incur a larger overhead due to record framing, whereas large records will have to be delivered and reassembled by the TCP layer before they can be processed by the TLS layer and delivered to your application.
Due to the layered architecture of the network protocols, running an application over TLS is no different from communicating directly over TCP. As such, there are no, or at most minimal, application modifications that you will need to make to deliver it over TLS. That is, assuming you have already applied the Optimizing for TCP best practices.
However, what you should investigate are the operational pieces of your TLS deployments: how and where you deploy your servers, size of TLS records and memory buffers, certificate sizes, support for abbreviated handshakes, and so on. Getting these parameters right on your servers can make an enormous positive difference in the user experience, as well as in your operational costs.
Establishing and maintaining an encrypted channel introduces additional computational costs for both peers. Specifically, first there is the asymmetric (public key) encryption used during the TLS handshake (explained in TLS Handshake). Then, once a shared secret is established, it is used as a symmetric key to encrypt all TLS records.
As we noted earlier, public key cryptography is more computationally expensive when compared with symmetric key cryptography, and in the early days of the Web often required additional hardware to perform “SSL offloading.” The good news is this is no longer the case. Modern hardware has made great improvements to help minimize these costs, and what once required additional hardware can now be done directly on the CPU. Large organizations such as Facebook, Twitter, and Google, which offer TLS to hundreds of millions of users, perform all the necessary TLS negotiation and computation in software and on commodity hardware.
In January this year (2010), Gmail switched to using HTTPS for everything by default. Previously it had been introduced as an option, but now all of our users use HTTPS to secure their email between their browsers and Google, all the time. In order to do this we had to deploy no additional machines and no special hardware. On our production frontend machines, SSL/TLS accounts for less than 1% of the CPU load, less than 10 KB of memory per connection and less than 2% of network overhead. Many people believe that SSL/TLS takes a lot of CPU time and we hope the preceding numbers (public for the first time) will help to dispel that.
If you stop reading now you only need to remember one thing: SSL/TLS is not computationally expensive anymore.
— Adam Langley (Google)
We have deployed TLS at a large scale using both hardware and software load balancers. We have found that modern software-based TLS implementations running on commodity CPUs are fast enough to handle heavy HTTPS traffic load without needing to resort to dedicated cryptographic hardware. We serve all of our HTTPS traffic using software running on commodity hardware.
— Doug Beaver (Facebook)
Elliptic Curve Diffie-Hellman (ECDHE) is only a little more expensive than RSA for an equivalent security level… In practical deployment, we found that enabling and prioritizing ECDHE cipher suites actually caused negligible increase in CPU usage. HTTP keepalives and session resumption mean that most requests do not require a full handshake, so handshake operations do not dominate our CPU usage. We find 75% of Twitter’s client requests are sent over connections established using ECDHE. The remaining 25% consists mostly of older clients that don’t yet support the ECDHE cipher suites.
— Jacob Hoffman-Andrews (Twitter)
Previous experiences notwithstanding, techniques such as TLS Session Resumption are still important optimizations, which will help you decrease the computational costs and latency of public key cryptography performed during the TLS handshake. There is no reason to spend CPU cycles on work that you don’t need to do.
Speaking of optimizing CPU cycles, make sure to upgrade your SSL libraries to the latest release, and build your web server or proxy against them! For example, recent versions of OpenSSL have made significant performance improvements, and chances are your system default OpenSSL libraries are outdated.
The connection setup latency imposed on every TLS connection, new or resumed, is an important area of optimization. First, recall that every TCP connection begins with a three-way handshake (explained in Three-Way Handshake), which takes a full roundtrip for the SYN/SYN-ACK packets. Following that, the TLS handshake (explained in TLS Handshake) requires up to two additional roundtrips for the full process, or one roundtrip if an abbreviated handshake (explained in Optimizing TLS handshake with Session Resumption and False Start) can be used.
In the worst case, before any application data can be exchanged, the TCP and TLS connection setup process will take three roundtrips! Following our earlier example of a client in New York and the server in London, with a roundtrip time of 56 milliseconds (Table 1-1), this translates to 168 milliseconds of latency for a full TCP and TLS setup, and 112 milliseconds for a TLS session that is resumed. Even worse, the higher the latency between the peers, the worse the penalty, and 56 milliseconds is definitely an optimistic number.
Because all TLS sessions run over TCP, all the advice for Optimizing for TCP applies here as well. If TCP connection reuse was an important consideration for unencrypted traffic, then it is a critical optimization for all applications running over TLS—if you can avoid doing the handshake, do so. However, if you have to perform the handshake, then you may want to investigate using the “early termination” technique.
As we discussed in Chapter 1, we cannot expect any dramatic improvements in latency in the future, as our packets are already traveling within a small constant factor of the speed of light. However, while we may not be able to make our packets travel faster, we can make them travel a shorter distance. Early termination is a simple technique of placing your servers closer to the user (Figure 4-9) to minimize the latency cost of each roundtrip between the client and the server.
The simplest way to accomplish this is to replicate or cache your data and services on servers around the world instead of forcing every user to traverse across oceans and continental links to the origin servers. Of course, this is precisely the service that many content delivery networks (CDNs) are set up to offer. However, the use case for geo-distributed servers does not stop at optimized delivery of static assets.
A nearby server can also terminate the TLS session, which means that the TCP and TLS handshake roundtrips are much quicker and the total connection setup latency is greatly reduced. In turn, the same nearby server can then establish a pool of long-lived, secure connections to the origin servers and proxy all incoming requests and responses to and from the origin servers.
In a nutshell, move the server closer to the client to accelerate TCP and TLS handshakes! Most CDN providers offer this service, and if you are adventurous, you can also deploy your own infrastructure with minimal costs: spin up cloud servers in a few data centers around the globe, configure a proxy server on each to forward requests to your origin, add geographic DNS load balancing, and you are in business.
Terminating the connection closer to the user is an optimization that will help decrease latency for your users in all cases, but once again, no bit is faster than a bit not sent—send fewer bits. Enabling TLS session caching and stateless resumption will allow you to eliminate an entire roundtrip and reduce computational overhead for repeat visitors.
Session identifiers, on which TLS session caching relies, were introduced in SSL 2.0 and have wide support among most clients and servers. However, if you are configuring TLS on your server, do not assume that session support will be on by default. In fact, it is more common to have it off on most servers by default—but you know better! You should double-check and verify your configuration:
In practice, and for best results, you should configure both session caching and session ticket mechanisms. These mechanisms are not exclusive and can work together to provide best performance coverage both for new and older clients.
Session resumption provides two important benefits: it eliminates an extra handshake roundtrip for returning visitors and reduces the computational cost of the handshake by allowing reuse of previously negotiated session parameters. However, it does not help in cases where the visitor is communicating with the server for the first time, or if the previous session has expired.
To get the best of both worlds—a one roundtrip handshake for new and repeat visitors, and computational savings for repeat visitors—we can use TLS False Start, which is an optional protocol extension that allows the sender to send application data (Figure 4-10) when the handshake is only partially complete.
False Start does not modify the TLS handshake protocol, rather it only affects the protocol timing of when the application data can be sent. Intuitively, once the client has sent the ClientKeyExchange record, it already knows the encryption key and can begin transmitting application data—the rest of the handshake is spent confirming that nobody has tampered with the handshake records, and can be done in parallel. As a result, False Start allows us to keep the TLS handshake at one roundtrip regardless of whether we are performing a full or abbreviated handshake.
All application data delivered via TLS is transported within a record protocol (Figure 4-8). The maximum size of each record is 16 KB, and depending on the chosen cipher, each record will add anywhere from 20 to 40 bytes of overhead for the header, MAC, and optional padding. If the record then fits into a single TCP packet, then we also have to add the IP and TCP overhead: 20-byte header for IP, and 20-byte header for TCP with no options. As a result, there is potential for 60 to 100 bytes of overhead for each record. For a typical maximum transmission unit (MTU) size of 1,500 bytes on the wire, this packet structure translates to a minimum of 6% of framing overhead.
The smaller the record, the higher the framing overhead. However, simply increasing the size of the record to its maximum size (16 KB) is not necessarily a good idea! If the record spans multiple TCP packets, then the TLS layer must wait for all the TCP packets to arrive before it can decrypt the data (Figure 4-11). If any of those TCP packets get lost, reordered, or throttled due to congestion control, then the individual fragments of the TLS record will have to be buffered before they can be decoded, resulting in additional latency. In practice, these delays can create significant bottlenecks for the browser, which prefers to consume data byte by byte and as soon as possible.
Small records incur overhead, large records incur latency, and there is no one value for the “optimal” record size. Instead, for web applications, which are consumed by the browser, the best strategy is to dynamically adjust the record size based on the state of the TCP connection:
If the TCP connection has been idle, and even if Slow-Start Restart is disabled on the server, the best strategy is to decrease the record size when sending a new burst of data: the conditions may have changed since last transmission, and our goal is to minimize the probability of buffering at the application layer due to lost packets, reordering, and retransmissions.
Using a dynamic strategy delivers the best performance for interactive traffic: small record size eliminates unnecessary buffering latency and improves the time-to-first-{HTML byte, …, video frame}, and a larger record size optimizes throughput by minimizing the overhead of TLS for long-lived streams.
To determine the optimal record size for each state let’s start with the initial case of a new or idle TCP connection where we want to avoid TLS records from spanning multiple TCP packets:
Assuming a common 1,500-byte starting MTU, this leaves 1,420 bytes for a TLS record delivered over IPv4, and 1,400 bytes for IPv6. To be future-proof, use the IPv6 size, which leaves us with 1,400 bytes for each TLS record payload—adjust as needed if your MTU is lower.
Next, the decision as to when the record size should be increased and reset if the connection has been idle, can be set based on pre-configured thresholds: increase record size to up to 16 KB after X KB of data have been transferred, and reset the record size after Y milliseconds of idle time.
Typically, configuring the TLS record size is not something we can control at the application layer. Instead, this is a setting and perhaps even a compile-time constant or flag on your TLS server. For details on how to configure these values, check the documentation of your server.
A little-known feature of TLS is built-in support for lossless compression of data transferred within the record protocol: the compression algorithm is negotiated during the TLS handshake, and compression is applied prior to encryption of each record. However, in practice, you should disable TLS compression on your server for several reasons:
Double compression will waste CPU time on both the server and the client, and the security breach implications are quite serious: disable TLS compression. In practice, most browsers disable support for TLS compression, but you should nonetheless also explicitly disable it in the configuration of your server to protect your users.
Verifying the chain of trust requires that the browser traverse the chain, starting from the site certificate, and recursively verifying the certificate of the parent until it reaches a trusted root. Hence, the first optimization you should make is to verify that the server does not forget to include all the intermediate certificates when the handshake is performed. If you forget, many browsers will still work, but they will instead be forced to pause the verification and fetch the intermediate certificate on their own, verify it, and then continue. This will most likely require a new DNS lookup, TCP connection, and an HTTP GET request, adding hundreds of milliseconds to your handshake.
How does the browser know from where to fetch it? The child certificate will usually contain the URL for the parent.
Conversely, make sure you do not include unnecessary certificates in your chain! Or, more generally, you should aim to minimize the size of your certificate chain. Recall that server certificates are sent during the TLS handshake, which is likely running over a new TCP connection that is in the early stages of its slow-start algorithm. If the certificate chain exceeds TCP’s initial congestion window (Figure 4-12), then we will inadvertently add yet another roundtrip to the handshake: certificate length will overflow the congestion window and cause the server to stop and wait for a client ACK before proceeding.
The certificate chain in Figure 4-12 is over 5 KB in size, which will overflow the initial congestion window size of older servers and force another roundtrip of delay into the handshake. One possible solution is to increase the initial congestion window; see Increasing TCP’s Initial Congestion Window. In addition, you should investigate if it is possible to reduce the size of the sent certificates:
Every new TLS connection requires that the browser must verify the signatures of the sent certificate chain. However, there is one more step we can’t forget: the browser also needs to verify that the certificate is not revoked. To do so, it may periodically download and cache the CRL of the certificate authority, but it may also need to dispatch an OCSP request during the verification process for a “real-time” check. Unfortunately, the browser behavior for this process varies wildly:
Unfortunately, it is a complicated space with no single best solution. However, one optimization that can be made for some browsers is OCSP stapling: the server can include (staple) the OCSP response from the CA to its certificate chain, allowing the browser to skip the online check. Moving the OCSP fetch to the server allows the server to cache the signed OCSP response and save the extra request for many clients. However, there are also a few things to watch out for:
Finally, to enable OCSP stapling, you will need a server that supports it. The good news is popular servers such as Nginx, Apache, and IIS meet this criteria. Check the documentation of your own server for support and configuration instructions.
HTTP Strict Transport Security is a security policy mechanism that allows the server to declare access rules to a compliant browser via a simple HTTP header—e.g., Strict-Transport-Security: max-age=31536000. Specifically, it instructs the user-agent to enforce the following rules:
max-age=31536000 is equal to a 365-day cache lifetime).
HSTS converts the origin to an HTTPS-only destination and helps protect the application from a variety of passive and active network attacks against the user. Performance wise, it also helps eliminate unnecessary HTTP-to-HTTPS redirects by shifting this responsibility to the client, which will automatically rewrite all links to HTTPS.
As of early 2013, HSTS is supported by Firefox 4+, Chrome 4+, Opera 12+, and Chrome and Firefox for Android. For the latest status, see caniuse.com/stricttransportsecurity.
As an application developer, you are shielded from virtually all the complexity of TLS. Short of ensuring that you do not mix HTTP and HTTPS content on your pages, your application will run transparently on both. However, the performance of your entire application will be affected by the underlying configuration of your server.
The good news is it is never too late to make these optimizations, and once in place, they will pay high dividends for every new connection to your servers! A short list to put on the agenda:
Finally, to verify and test your configuration, you can use an online service, such as the Qualys SSL Server Test to scan your public server for common configuration and security flaws. Additionally, you should familiarize yourself with the openssl command-line interface, which will help you inspect the entire handshake and configuration of your server locally.
$> openssl s_client -state -CAfile startssl.ca.crt -connect igvita.com:443CONNECTED(00000003) SSL_connect:before/connect initialization SSL_connect:SSLv2/v3 write client hello A SSL_connect:SSLv3 read server hello A depth=2 /C=IL/O=StartCom Ltd./OU=Secure Digital Certificate Signing /CN=StartCom Certification Authority verify return:1 depth=1 /C=IL/O=StartCom Ltd./OU=Secure Digital Certificate Signing /CN=StartCom Class 1 Primary Intermediate Server CA verify return:1 depth=0 /description=ABjQuqt3nPv7ebEG/C=US /CN=www.igvita.com/emailAddress=ilya@igvita.com verify return:1 SSL_connect:SSLv3 read server certificate A SSL_connect:SSLv3 read server done A--- New, TLSv1/SSLv3, Cipher is RC4-SHA Server public key is 2048 bit Secure Renegotiation IS supported Compression: NONE Expansion: NONE SSL-Session: Protocol : TLSv1 Cipher : RC4-SHA Session-ID: 269349C84A4702EFA7 ...
Session-ID-ctx: Master-Key: 1F5F5F33D50BE6228A ... Key-Arg : None Start Time: 1354037095 Timeout : 300 (sec) Verify return code: 0 (ok) ---
In the preceding example, we connect to igvita.com on the default TLS port (443), and perform the TLS handshake. Because the s_client makes no assumptions about known root certificates, we manually specify the path to the root certificate of StartSSL Certificate Authority—this is important. Your browser already has StartSSL’s root certificate and is thus able to verify the chain, but s_client makes no such assumptions. Try omitting the root certificate, and you will see a verification error in the log.
Inspecting the certificate chain shows that the server sent two certificates, which added up to 3,571 bytes, which is very close to the three- to four-segment initial TCP congestion window size. We should be careful not to overflow it or raise the cwnd size on the server. Finally, we can inspect the negotiated SSL session variables—chosen protocol, cipher, key—and we can also see that the server issued a session identifier for the current session, which may be resumed in the future.
One of the most transformative technology trends of the past decade is the availability and growing expectation of ubiquitous connectivity. Whether it is for checking email, carrying a voice conversation, web browsing, or myriad other use cases, we now expect to be able to access these online services regardless of location, time, or circumstance: on the run, while standing in line, at the office, on a subway, while in flight, and everywhere in between. Today, we are still often forced to be proactive about finding connectivity (e.g., looking for a nearby WiFi hotspot) but without a doubt, the future is about ubiquitous connectivity where access to the Internet is omnipresent.
Wireless networks are at the epicenter of this trend. At its broadest, a wireless network refers to any network not connected by cables, which is what enables the desired convenience and mobility for the user. Not surprisingly, given the myriad different use cases and applications, we should also expect to see dozens of different wireless technologies to meet the needs, each with its own performance characteristics and each optimized for a specific task and context. Today, we already have over a dozen widespread wireless technologies in use: WiFi, Bluetooth, ZigBee, NFC, WiMAX, LTE, HSPA, EV-DO, earlier 3G standards, satellite services, and more.
As such, given the diversity, it is not wise to make sweeping generalizations about performance of wireless networks. However, the good news is that most wireless technologies operate on common principles, have common trade-offs, and are subject to common performance criteria and constraints. Once we uncover and understand these fundamental principles of wireless performance, most of the other pieces will begin to automatically fall into place.
Further, while the mechanics of data delivery via radio communication are fundamentally different from the tethered world, the outcome as experienced by the user is, or should be, all the same—same performance, same results. In the long run all applications are and will be delivered over wireless networks; it just may be the case that some will be accessed more frequently over wireless than others. There is no such thing as a wired application, and there is zero demand for such a distinction.
All applications should perform well regardless of underlying connectivity. As a user, you should not care about the underlying technology in use, but as developers we must think ahead and architect our applications to anticipate the differences between the different types of networks. And the good news is every optimization that we apply for wireless networks will translate to a better experience in all other contexts. Let’s dive in.
A network is a group of devices connected to one another. In the case of wireless networks, radio communication is usually the medium of choice. However, even within the radio-powered subset, there are dozens of different technologies designed for use at different scales, topologies, and for dramatically different use cases. One way to illustrate this difference is to partition the use cases based on their “geographic range”:
| Type | Range | Applications | Standards | |
Personal area network (PAN) | Within reach of a person | Cable replacement for peripherals | Bluetooth, ZigBee, NFC | |
Local area network (LAN) | Within a building or campus | Wireless extension of wired network | IEEE 802.11 (WiFi) | |
Metropolitan area network (MAN) | Within a city | Wireless inter-network connectivity | IEEE 802.15 (WiMAX) | |
Wide area network (WAN) | Worldwide | Wireless network access | Cellular (UMTS, LTE, etc.) |
The preceding classification is neither complete nor entirely accurate. Many technologies and standards start within a specific use case, such as Bluetooth for PAN applications and cable replacement, and with time acquire more capabilities, reach, and throughput. In fact, the latest drafts of Bluetooth now provide seamless interoperability with 802.11 (WiFi) for high-bandwidth use cases. Similarly, technologies such as WiMAX have their origins as fixed-wireless solutions, but with time acquired additional mobility capabilities, making them a viable alternative to other WAN and cellular technologies.
The point of the classification is not to partition each technology into a separate bin, but to highlight the high-level differences within each use case. Some devices have access to a continuous power source; others must optimize their battery life at all costs. Some require Gbit/s+ data rates; others are built to transfer tens or hundreds of bytes of data (e.g., NFC). Some applications require always-on connectivity, while others are delay and latency tolerant. These and a large number of other criteria are what determine the original characteristics of each type of network. However, once in place, each standard continues to evolve: better battery capacities, faster processors, improved modulation algorithms, and other advancements continue to extend the use cases and performance of each wireless standard.
Each and every type of wireless technology has its own set of constraints and limitations. However, regardless of the specific wireless technology in use, all communication methods have a maximum channel capacity, which is determined by the same underlying principles. In fact, Claude E. Shannon gave us an exact mathematical model (Equation 5-1) to determine channel capacity, regardless of the technology in use.
C is the channel capacity and is measured in bits per second.
BW is the available bandwidth, and is measured in hertz.
S is signal and N is noise, and they are measured in watts.
Although somewhat simplified, the previous formula captures all the essential insights we need to understand the performance of most wireless networks. Regardless of the name, acronym, or the revision number of the specification, the two fundamental constraints on achievable data rates are the amount of available bandwidth and the signal power between the receiver and the sender.
Unlike the tethered world, where a dedicated wire can be run between each network peer, radio communication by its very nature uses a shared medium: radio waves, or if you prefer, electromagnetic radiation. Both the sender and receiver must agree up-front on the specific frequency range over which the communication will occur; a well-defined range allows seamless interoperability between devices. For example, the 802.11b and 802.11g standards both use the 2.4–2.5 GHz band across all WiFi devices.
Who determines the frequency range and its allocation? In short, local government (Figure 5-1). In the United States, this process is governed by the Federal Communications Commission (FCC). In fact, due to different government regulations, some wireless technologies may work in one part of the world, but not in others. Different countries may, and often do, assign different spectrum ranges to the same wireless technology.
Politics aside, besides having a common band for interoperability, the most important performance factor is the size of the assigned frequency range. As Shannon’s model shows, the overall channel bitrate is directly proportional to the assigned range. Hence, all else being equal, a doubling in available frequency range will double the data rate—e.g., going from 20 to 40 MHz of bandwidth can double the channel data rate, which is exactly how 802.11n is improving its performance over earlier WiFi standards!
Finally, it is also worth noting that not all frequency ranges offer the same performance. Low-frequency signals travel farther and cover large areas (macrocells), but at the cost of requiring larger antennas and having more clients competing for access. On the other hand, high-frequency signals can transfer more data but won’t travel as far, resulting in smaller coverage areas (microcells) and a requirement for more infrastructure.
Certain frequency ranges are more valuable than others for some applications. Broadcast-only applications (e.g., broadcast radio) are well suited for low-frequency ranges. On the other hand, two-way communication benefits from use of smaller cells, which provide higher bandwidth and less competition.
Besides bandwidth, the second fundamental limiting factor in all wireless communication is the signal power between the sender and receiver, also known as the signal-power-to-noise-power, S/N ratio, or SNR. In essence, it is a measure that compares the level of desired signal to the level of background noise and interference. The larger the amount of background noise, the stronger the signal has to be to carry the information.
By its very nature, all radio communication is done over a shared medium, which means that other devices may generate unwanted interference. For example, a microwave oven operating at 2.5 GHz may overlap with the frequency range used by WiFi, creating cross-standard interference. However, other WiFi devices, such as your neighbors’ WiFi access point, and even your coworker’s laptop accessing the same WiFi network, also create interference for your transmissions.
In the ideal case, you would be the one and only user within a certain frequency range, with no other background noise or interference. Unfortunately, that’s unlikely. First, bandwidth is scarce, and second, there are simply too many wireless devices to make that work. Instead, to achieve the desired data rate where interference is present, we can either increase the transmit power, thereby increasing the strength of the signal, or decrease the distance between the transmitter and the receiver—or both, of course.
Path loss, or path attenuation, is the reduction in signal power with respect to distance traveled—the exact reduction rate depends on the environment. A full discussion on this is outside the scope of this book, but if you are curious, consult your favorite search engine.
To illustrate the relationship between signal, noise, transmit power, and distance, imagine you are in a small room and talking to someone 20 feet away. If nobody else is present, you can hold a conversation at normal volume. However, now add a few dozen people into the same room, such as at a crowded party, each carrying their own conversations. All of the sudden, it would be impossible for you to hear your peer! Of course, you could start speaking louder, but doing so would raise the amount of “noise” for everyone around you. In turn, they would start speaking louder also and further escalate the amount of noise and interference. Before you know it, everyone in the room is only able to communicate from a few feet away from each other (Figure 5-2). If you have ever lost your voice at a rowdy party, or had to lean in to hear a conversation, then you have firsthand experience with SNR.
In fact, this scenario illustrates two important effects:
One, or more loud speakers beside you can block out weaker signals from farther away—the near-far problem. Similarly, the larger the number of other conversations around you, the higher the interference and the smaller the range from which you can discern a useful signal—cell-breathing. Not surprisingly, these same limitations are present in all forms of radio communication as well, regardless of protocol or underlying technology.
Available bandwidth and SNR are the two primary, physical factors that dictate the capacity of every wireless channel. However, the algorithm by which the signal is encoded can also have a significant effect.
In a nutshell, our digital alphabet (1’s and 0’s), needs to be translated into an analog signal (a radio wave). Modulation is the process of digital-to-analog conversion, and different “modulation alphabets” can be used to encode the digital signal with different efficiency. The combination of the alphabet and the symbol rate is what then determines the final throughput of the channel. As a hands-on example:
The choice of the modulation algorithm depends on the available technology, computing power of both the receiver and sender, as well as the SNR ratio. A higher-order modulation alphabet comes at a cost of reduced robustness to noise and interference—there is no free lunch!
Don’t worry, we are not planning to dive headfirst into the world of signal processing. Rather, it is simply important to understand that the choice of the modulation algorithm does affect the capacity of the wireless channel, but it is also subject to SNR, available processing power, and all other common trade-offs.
Our brief crash course on signal theory can be summed up as follows: the performance of any wireless network, regardless of the name, acronym, or the revision number, is fundamentally limited by a small number of well-known parameters. Specifically, the amount of allocated bandwidth and the signal-to-noise ratio between receiver and sender. Further, all radio-powered communication is:
All wireless technologies advertise a peak, or a maximum data rate. For example, the 802.11g standard is capable of 54 Mbit/s, and the 802.11n standard raises the bar up to 600 Mbit/s. Similarly, some mobile carriers are advertising 100+ MBit/s throughput with LTE. However, the most important part that is often overlooked when analyzing all these numbers is the emphasis on in ideal conditions.
What are ideal conditions? You guessed it: maximum amount of allotted bandwidth, exclusive use of the frequency spectrum, minimum or no background noise, highest-throughput modulation alphabet, and, increasingly, multiple radio streams (multiple-input and multiple-output, or MIMO) transmitting in parallel. Needless to say, what you see on the label and what you experience in the real world might be (read, will be) very different.
Just a few factors that may affect the performance of your wireless network:
In other words, if you want maximum throughput, then try to remove any noise and interference you can control, place your receiver and sender as close as possible, give them all the power they desire, and make sure both select the best modulation method. Or, if you are bent on performance, just run a physical wire between the two! The convenience of wireless communication does have its costs.
Measuring wireless performance is a tricky business. A small change, on the order of a few inches, in the location of the receiver can easily double throughput, and a few instants later the throughput could be halved again because another receiver has just woken up and is now competing for access to the radio channel. By its very nature, wireless performance is highly variable.
Finally, note that all of the previous discussions have been focused exclusively on throughput. Are we omitting latency on purpose? In fact, we have so far, because latency performance in wireless networks is directly tied to the specific technology in use, and that is the subject we turn to next.
WiFi operates in the unlicensed ISM spectrum; it is trivial to deploy by anyone, anywhere; and the required hardware is simple and cheap. Not surprisingly, it has become one of the most widely deployed and popular wireless standards.
The name itself is a trademark of the WiFi Alliance, which is a trade association established to promote wireless LAN technologies, as well as to provide interoperability standards and testing. Technically, a device must be submitted to and certified by the WiFi Alliance to carry the WiFi name and logo, but in practice, the name is used to refer to any product based on the IEEE 802.11 standards.
The first 802.11 protocol was drafted in 1997, more or less as a direct adaptation of the Ethernet standard (IEEE 802.3) to the world of wireless communication. However, it wasn’t until 1999, when the 802.11b standard was introduced, that the market for WiFi devices took off. The relative simplicity of the technology, easy deployment, convenience, and the fact that it operated in the unlicensed 2.4 GHz ISM band allowed anyone to easily provide a “wireless extension” to their existing local area network. Today, most every new desktop, laptop, tablet, smartphone, and just about every other form-factor device is WiFi enabled.
The 802.11 wireless standards were primarily designed as an adaptation and an extension of the existing Ethernet (802.3) standard. Hence, while Ethernet is commonly referred to as the LAN standard, the 802.11 family (Figure 6-1) is correspondingly commonly known as the wireless LAN (WLAN). However, for the history geeks, technically much of the Ethernet protocol was inspired by the ALOHAnet protocol, which was the first public demonstration of a wireless network developed in 1971 at the University of Hawaii. In other words, we have come full circle.
The reason why this distinction is important is due to the mechanics of how the ALOHAnet, and consequently Ethernet and WiFi protocols, schedule all communication. Namely, they all treat the shared medium, regardless of whether it is a wire or the radio waves, as a “random access channel,” which means that there is no central process, or scheduler, that controls who or which device is allowed to transmit data at any point in time. Instead, each device decides on its own, and all devices must work together to guarantee good shared channel performance.
The Ethernet standard has historically relied on a probabilistic carrier sense multiple access (CSMA) protocol, which is a complicated name for a simple “listen before you speak” algorithm. In brief, if you have data to send:
Of course, it takes time to propagate any signal; hence collisions can still occur. For this reason, the Ethernet standard also added collision detection (CSMA/CD): if a collision is detected, then both parties stop transmitting immediately and sleep for a random interval (with exponential backoff). This way, multiple competing senders won’t synchronize and restart their transmissions simultaneously.
WiFi follows a very similar but slightly different model: due to hardware limitations of the radio, it cannot detect collisions while sending data. Hence, WiFi relies on collision avoidance (CSMA/CA), where each sender attempts to avoid collisions by transmitting only when the channel is sensed to be idle, and then sends its full message frame in its entirety. Once the WiFi frame is sent, the sender waits for an explicit acknowledgment from the receiver before proceeding with the next transmission.
There are a few more details, but in a nutshell that’s all there is to it: the combination of these techniques is how both Ethernet and WiFi regulate access to the shared medium. In the case of Ethernet, the medium is a physical wire, and in the case of WiFi, it is the shared radio channel.
In practice, the probabilistic access model works very well for lightly loaded networks. In fact, we won’t show the math here, but we can prove that to get good channel utilization (minimize number of collisions), the channel load must be kept below 10%. If the load is kept low, we can get good throughput without any explicit coordination or scheduling. However, if the load increases, then the number of collisions will quickly rise, leading to unstable performance of the entire network.
If you have ever tried to use a highly loaded WiFi network, with many peers competing for access—say, at a large public event, like a conference hall—then chances are, you have firsthand experience with “unstable WiFi performance.” Of course, the probabilistic scheduling is not the only factor, but it certainly plays a role.
The 802.11b standard launched WiFi into everyday use, but as with any popular technology, the IEEE 802 Standards Committee has not been idle and has actively continued to release new protocols (Table 6-1) with higher throughput, better modulation techniques, multistreaming, and many other new features.
| 802.11 protocol | Release | Freq (GHz) | Bandwidth (MHz) | Data rate per stream (Mbit/s) |
b | Sep 1999 | 2.4 | 20 | 1, 2, 5.5, 11 |
g | Jun 2003 | 2.4 | 20 | 6, 9, 12, 18, 24, 36, 48, 54 |
n | Oct 2009 | 2.4 | 20 | 7.2, 14.4, 21.7, 28.9, 43.3, 57.8, 65, 72.2 |
n | Oct 2009 | 5 | 40 | 15, 30, 45, 60, 90, 120, 135, 150 |
ac | ~2014 | 5 | 20, 40, 80, 160 | up to 866.7 |
Today, the “b” and “g” standards are the most widely deployed and supported. Both utilize the unlicensed 2.4 GHz ISM band, use 20 MHz of bandwidth, and support at most one radio data stream. Depending on your local regulations, the transmit power is also likely fixed at a maximum of 200 mW. Some routers will allow you to adjust this value but will likely override it with a regional maximum.
So how do we increase performance of our future WiFi networks? The “n” and upcoming “ac” standards are doubling the bandwidth from 20 to 40 MHz per channel, using higher-order modulation, and adding multiple radios to transmit multiple streams in parallel—multiple-input and multiple-output (MIMO). All combined, and in ideal conditions, this should enable gigabit-plus throughput with the upcoming “ac” wireless standard.
By this point you should be skeptical of the notion of “ideal conditions,” and for good reason. The wide adoption and popularity of WiFi networks also created one of its biggest performance challenges: inter- and intra-cell interference. The WiFi standard does not have any central scheduler, which also means that there are no guarantees on throughput or latency for any client.
The new WiFi Multimedia (WMM) extension enables basic Quality of Service (QoS) within the radio interface for latency-sensitive applications (e.g., voice, video, best effort), but few routers, and even fewer deployed clients, are aware of it. In the meantime, all traffic both within your own network, and in nearby WiFi networks must compete for access for the same shared radio resource.
Your router may allow you to set some Quality of Service (QoS) policy for clients within your own network (e.g., maximum total data rate per client, or by type of traffic), but you nonetheless have no control over traffic generated by other, nearby WiFi networks. The fact that WiFi networks are so easy to deploy is what made them ubiquitous, but the widespread adoption has also created a lot of performance problems: in practice it is now not unusual to find several dozen different and overlapping WiFi networks (Figure 6-2) in any high-density urban or office environment.
The most widely used 2.4 GHz band provides three non-overlapping 20 MHz radio channels: 1, 6, and 11 (Figure 6-3). Although even this assignment is not consistent among all countries. In some, you may be allowed to use higher channels (13, 14), and in others you may be effectively limited to an even smaller subset. However, regardless of local regulations, what this effectively means is that the moment you have more than two or three nearby WiFi networks, some must overlap and hence compete for the same shared bandwidth in the same frequency ranges.
Your 802.11g client and router may be capable of reaching 54 Mbps, but the moment your neighbor, who is occupying the same WiFi channel, starts streaming an HD video over WiFi, your bandwidth is cut in half, or worse. Your access point has no say in this arrangement, and that is a feature, not a bug!
Unfortunately, latency performance fares no better. There are no guarantees for the latency of the first hop between your client and the WiFi access point. In environments with many overlapping networks, you should not be surprised to see high variability, measured in tens and even hundreds of milliseconds for the first wireless hop. You are competing for access to a shared channel with every other wireless peer.
The good news is, if you are an early adopter, then there is a good chance that you can significantly improve performance of your own WiFi network. The 5 GHz band, used by the new 802.11n and 802.11ac standards, offers both a much wider frequency range and is still largely interference free in most environments. That is, at least for the moment, and assuming you don’t have too many tech-savvy friends nearby, like yourself! A dual-band router, which is capable of transmitting both on the 2.4 GHz and the 5 GHz bands will likely offer the best of both worlds: compatibility with old clients limited to 2.4 GHz, and much better performance for any client on the 5 GHz band.
Putting it all together, what does this tell us about the performance of WiFi?
There is no such thing as “typical” WiFi performance. The operating range will vary based on the standard, location of the user, used devices, and the local radio environment. If you are lucky, and you are the only WiFi user, then you can expect high throughput, low latency, and low variability in both. But once you are competing for access with other peers, or nearby WiFi networks, then all bets are off—expect high variability for latency and bandwidth.
The probabilistic scheduling of WiFi transmissions can result in a high number of collisions between multiple wireless peers in the area. However, even if that is the case, this does not necessarily translate to higher amounts of observed TCP packet loss. The data and physical layer implementations of all WiFi protocols have their own retransmission and error correction mechanisms, which hide these wireless collisions from higher layers of the networking stack.
In other words, while TCP packet loss is definitely a concern for data delivered over WiFi, the absolute rate observed by TCP is often no higher than that of most wired networks. Instead of direct TCP packet loss, you are much more likely to see higher variability in packet arrival times due to the underlying collisions and retransmissions performed by the lower link and physical layers.
The preceding performance characteristics of WiFi may paint an overly stark picture against it. In practice, it seems to work “well enough” in most cases, and the simple convenience that WiFi enables is hard to beat. In fact, you are now more likely to have a device that requires an extra peripheral to get an Ethernet jack for a wired connection than to find a computer, smartphone, or tablet that is not WiFi enabled.
With that in mind, it is worth considering whether your application can benefit from knowing about and optimizing for WiFi networks.
In practice, a WiFi network is usually an extension to a wired LAN, which is in turn connected via DSL, cable, or fiber to the wide area network. For an average user in the U.S., this translates to 8.6 Mbps of edge bandwidth and a 3.1 Mbps global average (Table 1-2). In other words, most WiFi clients are still likely to be limited by the available WAN bandwidth, not by WiFi itself. That is, when the “radio network weather” is nice!
However, bandwidth bottlenecks aside, this also frequently means that a typical WiFi deployment is backed by an unmetered WAN connection—or, at the very least, a connection with much higher data caps and maximum throughput. While many users may be sensitive to large downloads over their 3G or 4G connections due to associated costs and bandwidth caps, frequently this is not as much of a concern when on WiFi.
Of course, the unmetered assumption is not true in all cases (e.g., a WiFi tethered device backed by a 3G or 4G connection), but in practice it holds true more often than not. Consequently, large downloads, updates, and streaming use cases are best done over WiFi when possible. Don’t be afraid to prompt the user to switch to WiFi on such occasions!
As we saw, WiFi provides no bandwidth or latency guarantees. The user’s router may have some application-level QoS policies, which may provide a degree of fairness to multiple peers on the same wireless network. However, the WiFi radio interface itself has very limited support for QoS. Worse, there are no QoS policies between multiple, overlapping WiFi networks.
As a result, the available bandwidth allocation may change dramatically, on a second-to-second basis, based on small changes in location, activity of nearby wireless peers, and the general radio environment.
As an example, an HD video stream may require several megabits per second of bandwidth (Table 6-3), and while most WiFi standards are sufficient in ideal conditions, in practice you should not be surprised to see, and should anticipate, intermittent drops in throughput. In fact, due to the dynamic nature of available bandwidth, you cannot and should not extrapolate past download bitrate too far into the future. Testing for bandwidth rate just at the beginning of the video will likely result in intermittent buffering pauses as the radio conditions change during playback.
| Container | Video resolution | Encoding | Video bitrate (Mbit/s) |
mp4 | 360p | H.264 | 0.5 |
mp4 | 480p | H.264 | 1–1.5 |
mp4 | 720p | H.264 | 2–2.9 |
mp4 | 1080p | H.264 | 3–4.3 |
Instead, while we can’t predict the available bandwidth, we can and should adapt based on continuous measurement through techniques such as adaptive bitrate streaming.
Just as there are no bandwidth guarantees when on WiFi, similarly, there are no guarantees on the latency of the first wireless hop. Further, things get only more unpredictable if multiple wireless hops are needed, such as in the case when a wireless bridge (relay) access point is used.
In the ideal case, when there is minimum interference and the network is not loaded, the wireless hop can take less than one millisecond with very low variability. However, in practice, in high-density urban and office environments the presence of dozens of competing WiFi access points and peers creates a lot of contention for the same radio frequencies. As a result, you should not be surprised to see a 1–10 millisecond median for the first wireless hop, with a long latency tail: expect an occasional 10–50 millisecond delay and, in the worst case, even as high as hundreds of milliseconds.
If your application is latency sensitive, then you may need to think carefully about adapting its behavior when running over a WiFi network. In fact, this may be a good reason to consider WebRTC, which offers the option of an unreliable UDP transport. Of course, switching transports won’t fix the radio network, but it can help lower the protocol and application induced latency overhead.
As of early 2013, there are now an estimated 6.4 billion worldwide cellular connections. For 2012 alone, IDC market intelligence reports show an estimated 1.1 billion shipments for smart connected devices—smartphones, tablets, laptops, PCs, and so on. However, even more remarkable are the hockey stick growth projections for the years to come: the same IDC reports forecast the new device shipment numbers to climb to over 1.8 billion by 2016, and other cumulative forecasts estimate a total of over 20 billion connected devices by 2020.
With an estimated human population of 7 billion in 2012, rising to 7.5 billion by 2020, these trends illustrate our insatiable appetite for smart connected devices: apparently, most of us are not satisfied with just one.
However, the absolute number of connected devices is only one small part of the overall story. Implicit in this growth is also the insatiable demand for high-speed connectivity, ubiquitous wireless broadband access, and the connected services that must power all of these new devices! This is where, and why, we must turn our conversation to the performance of the various cellular technologies, such as GSM, CDMA, HSPA, and LTE. Chances are, most of your users will be using one of these technologies, some exclusively, to access your site or service. The stakes are high, we have to get this right, and mobile networks definitely pose their own set of performance challenges.
Navigating the forest of the various cellular standards, release versions, and the pros and cons of each could occupy not chapters, but entire books. Our goal here is much more humble: we need to develop an intuition for the operating parameters, and their implications, of the major past and future milestones (Table 7-1) of the dominant wireless technologies in the market.
| Generation | Peak data rate | Description |
1G | no data | Analog systems |
2G | Kbit/s | First digital systems as overlays or parallel to analog systems |
3G | Mbit/s | Dedicated digital networks deployed in parallel to analog systems |
4G | Gbit/s | Digital and packet-only networks |
The first important realization is that the underlying standards for each wireless generation are expressed in terms of peak spectral efficiency (bps/Hz), which is then translated to impressive numbers such as Gbit/s+ peak data rates for 4G networks. However, you should now recognize the key word in the previous sentence: peak! Think back to our earlier discussion on Measuring Real-World Wireless Performance—peak data rates are achieved in ideal conditions.
Regardless of the standard, the real performance of every network will vary by provider, their configuration of the network, the number of active users in a given cell, the radio environment in a specific location, the device in use, plus all the other factors that affect wireless performance. With that in mind, while there are no guarantees for data rates in real-world environments, a simple but effective strategy to calibrate your performance expectations (Table 7-2) is to assume much closer to the lower bound for data throughput, and toward the higher bound for packet latency for every generation.
| Generation | Data rate | Latency |
2G | 100–400 Kbit/s | 300–1000 ms |
3G | 0.5–5 Mbit/s | 100–500 ms |
4G | 1–50 Mbit/s | < 100 ms |
To complicate matters further, the classification of any given network as 3G or 4G is definitely too coarse, and correspondingly so is the expected throughput and latency. To understand why this is the case, and where the industry is heading, we first need to take a quick survey of the history of the different technologies and the key players behind their evolution.
The first commercial 1G network was launched in Japan in 1979. It was an analog system and offered no data capabilities. In 1991, the first 2G network was launched in Finland based on the emerging GSM (Global System for Mobile Communications, originally Groupe Spécial Mobile) standard, which introduced digital signaling within the radio network. This enabled first circuit-switched mobile data services, such as text messaging (SMS), and packet delivery at a whopping peak data rate of 9.6 Kbit/s!
It wasn’t until the mid 1990s, when general packet radio service (GPRS) was first introduced to the GSM standard that wireless Internet access became a practical, albeit still very slow, possibility: with GPRS, you could now reach 172 Kbit/s, with typical roundtrip latency hovering in high hundreds of milliseconds. The combination of GPRS and earlier 2G voice technologies is often described as 2.5G. A few years later, these networks were enhanced by EDGE (Enhanced Data rates for GSM Evolution), which increased the peak data rates to 384 Kbit/s. The first EDGE networks (2.75G) were launched in the U.S. in 2003.
At this point, a pause and some reflection is warranted. Wireless communication is many decades old, but practical, consumer-oriented data services over mobile networks are a recent phenomenon! 2.75G networks are barely a decade old, which is recent history, and are also still widely used around the world. Yet, most of us now simply can’t imagine living without high-speed wireless access. The rate of adoption, and the evolution of the wireless technologies, has been nothing short of breathtaking.
Once the consumer demand for wireless data services began to grow, the question of radio network interoperability became a hot issue for everyone involved. For one, the telecom providers must buy and deploy the hardware for the radio access network (RAN), which requires significant capital investments and ongoing maintenance—standard hardware means lower costs. Similarly, without industry-wide standards, the users would be restricted to their home networks, limiting the use cases and convenience of mobile data access.
In response, the European Telecommunication Standards Institute (ETSI) developed the GSM standard in the early 1990’s, which was quickly adopted by many European countries and around the globe. In fact, GSM would go on to become the most widely deployed wireless standard, by some estimates, covering 80%–85% of the market (Figure 7-1). But it wasn’t the only one. In parallel, the IS-95 standard developed by Qualcomm also captured 10%–15% of the market, most notably with many network deployments across North America. As a result, a device designed for the IS-95 radio network cannot operate on the GSM network, and vice versa—an unfortunate property that is familiar to many international travelers.
In 1998, recognizing the need for global evolution of the deployed standards, as well as defining the requirements for the next generation (3G) networks, the participants in GSM and IS-95 standards organizations formed two global partnership projects:
Consequently, the development of both types of standards (Table 7-3) and associated network infrastructure has proceeded in parallel. Perhaps not directly in lockstep, but nonetheless following mostly similar evolution of the underlying technologies.
| Generation | Organization | Release |
2G | 3GPP | GSM |
3GPP2 | IS-95 (cdmaOne) | |
2.5G, 2.75G | 3GPP | GPRS, EDGE (EGPRS) |
3GPP2 | CDMA2000 | |
3G | 3GPP | UMTS |
3GPP2 | CDMA 2000 1x EV-DO Release 0 | |
3.5G, 3.75G, 3.9G | 3GPP | HSPA, HSPA+, LTE |
3GPP2 | EV-DO Revision A, EV-DO Revision B, EV-DO Advanced | |
4G | 3GPP | LTE-Advanced, HSPA+ Revision 11+ |
Chances are, you should see some familiar labels on the list: EV-DO, HSPA, LTE. Many network operators have invested significant marketing resources, and continue to do so, to promote these technologies as their “latest and fastest mobile data networks.” However, our interest and the reason for this historical detour is not for the marketing, but for the macro observations of the evolution of the mobile wireless industry:
There is no one 4G or 3G technology. The International Telecommunication Union (ITU) sets the international standards and performance characteristics, such as data rates and latency, for each wireless generation, and the 3GPP and 3GPP2 organizations then define the standards to meet and exceed these expectations within the context of their respective technologies.
How do you know which network type your carrier is using? Simple. Does your phone have a SIM card? If so, then it is a 3GPP technology that evolved from GSM. To find out more detailed information about the network, check your carrier’s FAQ, or if your phone allows it, check the network information directly on your phone.
For Android users, open your phone dial screen and type in: *#*#4636#*#*. If your phone allows it, it should open a diagnostics screen where you can inspect the status and type of your mobile connection, battery diagnostics, and more.
In the context of 3G networks, we have two dominant and competing standards: UMTS and CDMA-based networks, which are developed by 3GPP and 3GPP2, respectively. However as the earlier table of cellular standards (Table 7-3) shows, each is also split into several transitional milestones: 3.5G, 3.75G, and 3.9G technologies.
Why couldn’t we simply jump to 4G instead? Well, standards take a long time to develop, but even more importantly, there are big financial costs for deploying new network infrastructure. As we will see, 4G requires an entirely different radio interface and parallel infrastructure to 3G. Because of this, and also for the benefit of the many users who have purchased 3G handsets, both 3GPP and 3GPP2 have continued to evolve the existing 3G standards, which also enables the operators to incrementally upgrade their existing networks to deliver better performance to their existing users.
Not surprisingly, the throughput, latency, and other performance characteristics of the various 3G networks have improved, sometimes dramatically, with every new release. In fact, technically, LTE is considered a 3.9G transitional standard! However, before we get to LTE, let’s take a closer look at the various 3GPP and 3GPP2 milestones.
| Release | Date | Summary |
99 | 1999 | First release of the UMTS standard |
4 | 2001 | Introduced an all-IP core network |
5 | 2002 | Introduced High-Speed Packet Downlink Access (HSDPA) |
6 | 2004 | Introduced High-Speed Packet Uplink Access (HSUPA) |
7 | 2007 | Introduced High-Speed Packet Access Evolution (HSPA+) |
8 | 2008 | Introduced new LTE System Architecture Evolution (SAE) |
9 | 2009 | Improvements to SAE and WiMAX interoperability |
10 | 2010 | Introduced 4G LTE-Advanced architecture |
In the case of networks following the 3GPP standards, the combination of HSDPA and HSUPA releases is often known and marketed as a High-Speed Packet Access (HSPA) network. This combination of the two releases enabled low single-digit Mbit/s throughput in real-world deployments, which was a significant step up from the early 3G speeds. HSPA networks are often labeled as 3.5G.
From there, the next upgrade was HSPA+ (3.75G), which offered significantly lower latencies thanks to a simplified core network architecture and data rates in mid to high single-digit Mbit/s throughput in real-world deployments. However, as we will see, release 7, which introduced HSPA+, was not the end of the line for this technology. In fact, the HSPA+ standards have been continuously refined since then and are now competing head to head with LTE and LTE-Advanced!
| Release | Date | Summary |
Rel. 0 | 1999 | First release of the 1x EV-DO standard |
Rev. A | 2001 | Upgrade to peak data-rate, lower latency, and QoS |
Rev. B | 2004 | Introduced multicarrier capabilities to Rev. A |
Rev. C | 2007 | Improved core network efficiency and performance |
The CDMA2000 EV-DO standard developed by 3GPP2 followed a similar network upgrade path. The first release (Rel. 0) enabled low single digit Mbit/s downlink throughput but very low uplink speeds. The uplink performance was addressed with Rev. A, and both uplink and downlink speeds were further improved in Rev. B. Hence, a Rev. B network was able to deliver mid to high single-digit Mbit/s performance to its users, which makes it comparable to HSPA and early HSPA+ networks—aka, 3.5–3.75G.
The Rev. C release is also frequently referred to as EV-DO Advanced and offers significant operational improvements in capacity and performance. However, the adoption of EV-DO Advanced has not been nearly as strong as that of HSPA+. Why? If you paid close attention to the standards generation table (Table 7-3), you may have noticed that 3GPP2 does not have an official and competing 4G standard!
While 3GPP2 could have continued to evolve its CDMA technologies, at some point both the network operators and the network vendors agreed on 3GPP LTE as a common 4G successor to all types of networks. For this reason, many of the CDMA network operators are also some of the first to invest into early LTE infrastructure, in part to be able to compete with ongoing HSPA+ improvements.
In other words, most mobile operators around the world are converging on HSPA+ and LTE as the future mobile wireless standards—that’s the good news. Having said that, don’t hold your breath. Existing 2G and 3–3.75G technologies are still powering the vast majority of deployed mobile radio networks, and even more importantly, will remain operational for at least another decade.
3G is often described as “mobile broadband.” However, broadband is a relative term. Some pin it as a communication bandwidth of at least 256 Kbit/s, others as that exceeding 640 Kbit/s, but the truth is that the value keeps changing based on the experience we are trying to achieve. As the services evolve and demand higher throughput, so does the definition of broadband.
In that light, it might be more useful to think of 3G standards as those targeting and exceeding the Mbit/s bandwidth threshold. How far over the Mbit/s barrier? Well, that depends on the release version of the standard (as we saw earlier), the carrier configuration of the network, and the capabilities of the device in use.
Before we dissect the various 4G technologies, it is important to understand what stands behind the “4G” label. Just as with 3G, there is no one 4G technology. Rather, 4G is a set of requirements (IMT-Advanced) that was developed and published by the ITU back in 2008. Any technology that meets these requirements can be labeled as 4G.
Some example requirements of IMT-Advanced include the following:
The actual list is much, much longer but the preceding captures the highlights important for our discussion: much higher throughput and significantly lower latencies when compared to earlier generations. Armed with these criteria, we now know how to classify a 4G network—right? Not so fast, that would be too easy! The marketing departments also had to have their say.
LTE-Advanced is a standard that was specifically developed to satisfy all the IMT-Advanced criteria. In fact, it was also the first 3GPP standard to do so. However, if you were paying close attention, you would have noticed that LTE (release 8) and LTE-Advanced (release 10) are, in fact, different standards. Technically, LTE should really be considered a 3.9G transitional standard, even though it lays much of the necessary groundwork to meet the 4G requirements—it is almost there, but not quite!
However, this is where the marketing steps in. The 3G and 4G trademarks are held by the ITU, and hence their use should correspond to defined requirements for each generation. Except the carriers won a marketing coup and were able to redefine the “4G” trademark to include a set of technologies that are significantly close to the 4G requirements. For this reason, LTE (release 8) and most HSPA+ networks, which do not meet the actual technical 4G requirements, are nonetheless marketed as “4G.”
What about the real (LTE-Advanced) 4G deployments? Those are coming, but it remains to be seen how these networks will be marketed in light of their earlier predecessors. Regardless, the point is, the “4G” label as it is used today by many carriers is ambiguous, and you should read the fine print to understand the technology behind it.
Despite the continuous evolution of the 3G standards, the increased demand for high data transmission speeds and lower latencies exposed a number of inherent design limitations in the earlier UMTS technologies. To address this, 3GPP set out to redesign both the core and the radio networks, which led to the creation of the aptly named Long Term Evolution (LTE) standard:
Not surprisingly, the preceding list should read similar to the IMT-Advanced requirements we saw earlier. LTE (release 8) laid the groundwork for the new network architecture, and LTE-Advanced (release 10) delivered the necessary improvements to meet the true 4G requirements set by IMT-Advanced.
At this point it is important to note that due to radio and core network implementation differences, LTE networks are not simple upgrades to existing 3G infrastructure. Instead, LTE networks must be deployed in parallel and on separate spectrum from existing 3G infrastructure. However, since LTE is a common successor to both UMTS and CDMA standards, it does provide a way to interoperate with both: an LTE subscriber can be seamlessly handed off to a 3G network and be migrated back where LTE infrastructure is available.
Finally, as the name implies, LTE is definitely the long-term evolution plan for virtually all future mobile networks. The only question is, how distant is this future? A few carriers have already begun investing into LTE infrastructure, and many others are beginning to look for the spectrum, funds, or both, to do so. However, current industry estimates show that this migration will indeed be a long-term one—perhaps over the course of the next decade or so. In the meantime, HSPA+ is set to take the center stage.
Every LTE-capable device must have multiple radios for mandatory MIMO support. However, each device will also need separate radio interfaces for earlier 3G and 2G networks. If you are counting, that translates to three or four radios in every handset! For higher data rates with LTE, you will need 4x MIMO, which brings the total to five or six radios. You were wondering why your battery is drained so quickly?
HSPA+ was first introduced in 3GPP release 7, back in 2007. However, while the popular attention quickly shifted toward LTE, which was first introduced in 3GPP release 8 in 2008, what is often overlooked is that the development of HSPA+ did not cease and continued to coevolve in parallel. In fact, HSPA+ release 10 meets many of the IMT-Advanced criteria. But, you may ask, if we have LTE and everyone is in agreement that it is the standard for future mobile networks, why continue to develop and invest into HSPA+? As usual, the answer is a simple one: cost.
3GPP 3G technologies command the lion’s share of the established wireless market around the world, which translates into huge existing infrastructure investments by the carriers around the globe. Migrating to LTE requires development of new radio networks, which once again translates into significant capital expenditures. By contrast, HSPA+ offers a much more capital efficient route: the carriers can deploy incremental upgrades to their existing networks and get comparable performance.
Cost-effectiveness is the name of the game and the reason why current industry projections (Figure 7-2) show HSPA+ as responsible for the majority of 4G upgrades around the world for years to come. In the meantime, CDMA technologies developed by 3GPP2 will continue to coexist, although their number of subscriptions is projected to start declining slowly, while new LTE deployments will proceed in parallel with different rates in different regions—in part due to cost constraints, and in part due to different regulation and the availability of required radio spectrum.
For a variety of reasons, North America appears to be the leader in LTE adoption: current industry projections show the number of LTE subscribers in U.S. and Canada surpassing that of HSPA by 2016 (Figure 7-3). However, the rate of LTE adoption in North America appears to be significantly more aggressive than in most other countries. Within the global context, HSPA+ is set to be the dominant mobile wireless technology of the current decade.
While many are first surprised by the trends in the HSPA+ vs. LTE adoption, this is not an unexpected outcome. If nothing else, it serves to illustrate an important point: it takes roughly a decade from the first specification of a new wireless standard to its mainstream availability in real-world wireless networks.
By extension, it is a fairly safe bet that we will be talking about LTE-Advanced in earnest by the early 2020s! Unfortunately, deploying new radio infrastructure is a costly and time-consuming proposition.
Crystal ball gazing is a dangerous practice in our industry. However, by this point we have covered enough to make some reasonable predictions about what we can and should expect out of the currently deployed mobile networks, as well as where we might be in a few years’ time.
First, the wireless standards are evolving quickly, but the physical rollout of these networks is both a costly and a time-consuming exercise. Further, once deployed, the network must be maintained for significant amounts of time to recoup the costs and to keep existing customers online. In other words, while there is a lot of hype and marketing around 4G, older-generation networks will continue to operate for at least another decade. When building for the mobile web, plan accordingly.
Ironically, while 4G networks provide significant improvements for IP data delivery, 3G networks are still much more efficient in handling the old-fashioned voice traffic! Voice over LTE (VoLTE) is currently in active development and aims to enable efficient and reliable voice over 4G, but most current 4G deployments still rely on the older, circuit-switched infrastructure for voice delivery.
Consequently, when building applications for mobile networks, we cannot target a single type or generation of network, or worse, hope for specific throughput or latency performance. As we saw, the actual performance of any network is highly variable, based on deployed release, infrastructure, radio conditions, and a dozen other variables. Our applications should adapt to the continuously changing conditions within the network: throughput, latency, and even the availability of the radio connection. When the user is on the go, it is highly likely that he may transition between multiple generations of networks (LTE, HSPA+, HSPA, EV-DO, and even GPRS Edge) based on the available coverage and signal strength. If the application fails to account for this, then the user experience will suffer.
The good news is HSPA+ and LTE adoption is growing very fast, which enables an entirely new class of high-throughput and latency-sensitive applications previously not possible. Both are effectively on par in throughput and latency (Table 7-6): mid to high digit Mbps throughput in real-world environments, and sub-100-millisecond latency, which makes them comparable to many home and office WiFi networks.
| HSPA+ | LTE | LTE-Advanced | |
Peak downlink speed (Mbit/s) | 168 | 300 | 3,000 |
Peak uplink speed (Mbit/s) | 22 | 75 | 1,500 |
Maximum MIMO streams | 2 | 4 | 8 |
Idle to connected latency (ms) | < 100 | < 100 | < 50 |
Dormant to active latency (ms) | < 50 | < 50 | < 10 |
User-plane one-way latency (ms) | < 10 | < 5 | < 5 |
However, while 4G wireless performance is often compared to that of WiFi, or wired broadband, it would be incorrect to assume that we can get away with treating them as the same environments: that they are definitely not.
For example, most users and developers expect an “always on” experience where the device is permanently connected to the Internet and is ready to instantaneously react to user input or an incoming data packet. This assumption holds true in the tethered world but is definitely incorrect for mobile networks. Practical constraints such as battery life and device capabilities mean that we must design our applications with explicit awareness of the constraints of mobile networks. To understand these differences, let’s dig a little deeper.
What is often forgotten is that the deployed radio network is only half of the equation. It goes without saying that devices from different manufacturers and release dates will have very different characteristics: CPU speeds and core counts, amount of available memory, storage capacity, GPU, and more. Each of these factors will affect the overall performance of the device and the applications running on it.
However, even with all of these variables accounted for, when it comes to network performance, there is one more section that is often overlooked: radio capabilities. Specifically, the device that the user is holding in her hands must also be able to take advantage of the deployed radio infrastructure! The carrier may deploy the latest LTE infrastructure, but a device designed for an earlier release may simply not be able to take advantage of it, and vice versa.
Both the 3GPP and 3GPP2 standards continue to evolve and enhance the radio interface requirements: modulation schemes, number of radios, and so on. To get the best performance out of any network, the device must also meet the specified user equipment (UE) category requirements for each type of network. In fact, for each release, there are often multiple UE categories, each of which will offer very different radio performance.
An obvious and important question is, why? Once again, the answer is a simple one: cost. Availability of multiple categories of devices enables device differentiation, various price points for price-sensitive users, and ability to adapt to deployed network infrastructure on the ground.
The HSPA standard alone specifies over 36 possible UE categories! Hence, just saying that you have an “HSPA capable device” (Table 7-7) is not enough—you need to read the fine print. For example, assuming the radio network is capable, to get the 42.2 Mbps/s throughput, you would also need a category 20 (2x MIMO), or category 24 (dual-cell) device. Finally, to confuse matters further, a category 21 device does not automatically guarantee higher throughput over a category 20 handset.
| 3GPP Release | Category | MIMO, Multicell | Peak data rate (Mbit/s) |
5 | 8 | — | 7.2 |
5 | 10 | — | 14.0 |
7 | 14 | — | 21.1 |
8 | 20 | 2x MIMO | 42.2 |
8 | 21 | Dual-cell | 23.4 |
8 | 24 | Dual-cell | 42.2 |
10 | 32 | Quad-cell + MIMO | 168.8 |
Similarly, the LTE standard defines its own set of user equipment categories (Table 7-8): a high-end smartphone is likely to be a category 3–5 device, but it will also likely share the network with a lot of cheaper category 1–2 neighbors. Higher UE categories, which require 4x and even 8x MIMO, are more likely to be found in specialized devices—powering that many radios simultaneously consumes a lot of power, which may not be very practical for something in your pocket!
| 3GPP release | Category | MIMO | Peak downlink (Mbit/s) | Peak uplink (Mbit/s) |
8 | 1 | 1x | 10.3 | 5.2 |
8 | 2 | 2x | 51.0 | 25.5 |
8 | 3 | 2x | 102.0 | 51.0 |
8 | 4 | 2x | 150.8 | 51.0 |
8 | 5 | 4x | 299.6 | 75.4 |
10 | 6 | 2x or 4x | 301.5 | 51.0 |
10 | 7 | 2x or 4x | 301.5 | 102.0 |
10 | 8 | 8x | 2998.6 | 1497.8 |
In practice, most of the early LTE deployments are targeting category 1–3 devices, with early LTE-Advanced networks focusing on category 3 as their primary UE type.
If you own an LTE or an HSPA+ device, do you know its category classification? And once you figure that out, do you know which 3GPP release your network operator is running? To get the best performance, the two must match. Otherwise, you will be limited either by the capabilities of the radio network or the device in use.
Both 3G and 4G networks have a unique feature that is not present in tethered and even WiFi networks. The Radio Resource Controller (RRC) mediates all connection management between the device in use and the radio base station (Figure 7-4). Understanding why it exists, and how it affects the performance of every device on a mobile network, is critical to building high-performance mobile applications. The RRC has direct impact on latency, throughput, and battery life of the device in use.
When using a physical connection, such as an Ethernet cable, your computer has a direct and an always-on network link, which allows either side of this connection to send data packets at any time; this is the best possible case for minimizing latency. As we saw in From Ethernet to a Wireless LAN, the WiFi standard follows a similar model, where each device is able to transmit at any point in time. This too provides minimum latency in the best case, but due to the use of the shared radio medium can also lead to high collision rates and unpredictable performance if there are many active users. Further, because any WiFi peer could start transmitting at any time, all others must also be ready to receive. The radio is always on, which consumes a lot of power.
In practice, keeping the WiFi radio active at all times is simply too expensive, as battery capacity is a limited resource on most devices. Hence, WiFi offers a small power optimization where the access point broadcasts a delivery traffic indication message (DTIM) within a periodic beacon frame to indicate that it will be transmitting data for certain clients immediately after. In turn, the clients can listen for these DTIM frames as hints for when the radio should be ready to receive, and otherwise the radio can sleep until the next DTIM transmission. This lowers battery use but adds extra latency.
The upcoming WiFi Multimedia (WMM) standard will further improve the power efficiency of WiFi devices with the help of the new PowerSave mechanisms such as NoAck and APSD (Automatic Power Save Delivery).
Therein lies the problem for 3G and 4G networks: network efficiency and power. Or rather, lack of power, due to the fact that mobile devices are constrained by their battery capacity and a requirement for high network efficiency among a significantly larger number of active users in the cell. This is why the RRC exists.
As the name implies, the Radio Resource Controller assumes full responsibility over scheduling of who talks when, allocated bandwidth, the signal power used, the power state of each device, and a dozen other variables. Simply put, the RRC is the brains of the radio access network. Want to send data over the wireless channel? You must first ask the RRC to allocate some radio resources for you. Have incoming data from the Internet? The RRC will notify you for when to listen to receive the inbound packets.
The good news is all the RRC management is performed by the network. The bad news is, while you can’t necessarily control the RRC via an API, if you do want to optimize your application for 3G and 4G networks, then you need to be aware of and work within the constraints imposed by the RRC.
The RRC lives within the radio network. In 2G and 3G networks, the RRC lived in the core carrier network, and in 4G the RRC logic has been moved directly to the serving radio tower (eNodeB) to improve performance and reduce coordination latency.
The radio is one of the most power-hungry components of any handset. In fact, the screen is the only component that consumes higher amounts of power when active—emphasis on active. In practice, the screen is off for significant periods of time, whereas the radio must maintain the illusion of an “always-on” experience such that the user is reachable at any point in time.
One way to achieve this goal is to keep the radio active at all times, but even with the latest advances in battery capacity, doing so would drain the battery in a matter of hours. Worse, latest iterations of the 3G and 4G standards require parallel transmissions (MIMO, Multicell, etc.), which is equivalent to powering multiple radios at once. In practice, a balance must be struck between keeping the radio active to service low-latency interactive traffic and cycling into low-power states to enable reasonable battery performance.
How do the different technologies compare, and which is better for battery life? There is no one single answer. With WiFi, each device sets its own transmit power, which is usually in the 30–200 mW range. By comparison, the transmit power of the 3G/4G radio is managed by the network and can consume as low as 15 mW when in an idle state. However, to account for larger range and interference, the same radio can require 1,000–3,500 mW when transmitting in a high-power state!
In practice, when transferring large amounts of data, WiFi is often far more efficient if the signal strength is good. But if the device is mostly idle, then the 3G/4G radio is more effective. For best performance, ideally we would want dynamic switching between the different connection types. However, at least for the moment, no such mechanism exists. This is an active area of research, both in the industry and academia.
So how does the battery and power management affect networking performance? Signal power (explained in Signal Power) is one of the primary levers to achieve higher throughput. However, high transmit power consumes significant amounts of energy and hence may be throttled to achieve better battery life. Similarly, powering down the radio may also tear down the radio link to the radio tower altogether, which means that in the event of a new transmission, a series of control messages must be first exchanged to reestablish the radio context, which can add tens and even hundreds of milliseconds of latency.
Both throughput and latency performance are directly impacted by the power management profile of the device in use. In fact, and this is key, in 3G and 4G networks the radio power management is controlled by the RRC: not only does it tell you when to communicate, but it will also tell you the transmit power and when to cycle into different power states.
The radio state of every LTE device is controlled by the radio tower currently servicing the user. In fact, the 3GPP standard defines a well-specified state machine, which describes the possible power states of each device connected to the network (Figure 7-5). The network operator can make modifications to the parameters that trigger the state transitions, but the state machine itself is the same across all LTE deployments.
The device is either idle, in which case it is only listening to control channel broadcasts, such as paging notifications of inbound traffic, or connected, in which case the network has an established context and resource assignment for the client.
When in an idle state, the device cannot send or receive any data. To do so, it must first synchronize itself to the network by listening to the network broadcasts and then issue a request to the RRC to be moved to the “connected” state. This negotiation can take several roundtrips to establish, and the 3GPP LTE specification allocates a target of 100 milliseconds or less for this state transition. In LTE-Advanced, the target time was further reduced to 50 milliseconds.
Once in a connected state, a network context is established between the radio tower and the LTE device, and data can be transferred. However, once either side completes the intended data transfer, how does the RRC know when to transition the device to a lower power state? Trick question—it doesn’t!
IP traffic is bursty, optimized TCP connections are long-lived, and UDP traffic provides no “end of transmission” indicator by design. As a result, and not unlike the NAT connection-state timeouts solution covered in Connection-State Timeouts, the RRC state machine depends on a collection of timers to trigger the RRC state transitions.
Finally, because the connected state requires such high amounts of power, multiple sub-states are available (Figure 7-5) to allow for more efficient operation:
In the high-power state, the RRC creates a reservation for the device to receive and transmit data over the wireless interface and notifies the device for what these time-slots are, the transmit power that must be used, the modulation scheme, and a dozen other variables. Then, if the device has been idle for a configured period of time, it is transitioned to a Short DRX power state, where the network context is still maintained, but no specific radio resources are assigned. When in Short DRX state, the device only listens to periodic broadcasts from the network, which allows it to preserve the battery—not unlike the DTIM interval in WiFi.
If the radio remains idle long enough, it is then transitioned to the Long DRX state, which is identical to the Short DRX state, except that the device sleeps for longer periods of time between waking up to listen to the broadcasts (Figure 7-6).
What happens if the network or the mobile device must transmit data when the radio is in one of Short or Long DRX (dormant) states? The device and the RRC must first exchange control messages to negotiate when to transmit and when to listen to radio broadcasts. For LTE, this negotiation time (“dormant to connected”) is specified as less than 50 milliseconds, and further tightened to less than 10 milliseconds for LTE-Advanced.
So what does this all mean in practice? Depending on which power state the radio is in, an LTE device may first require anywhere from 10 to 100 milliseconds (Table 7-9) of latency to negotiate the required resources with the RRC. Following that, application data can be transferred over the wireless link, through the carrier’s network, and then out to the public Internet. Planning for these delays, especially when designing latency-sensitive applications, can be all the difference between “unpredictable performance” and an optimized mobile application.
Earlier generation 3GPP networks prior to LTE and LTE-Advanced have a very similar RRC state machine that is also maintained by the radio network. That’s the good news. The bad news is the state machine for earlier generations is a bit more complicated (Figure 7-7), and the latencies are much, much higher. In fact, one reason why LTE offers better performance is precisely due to the simplified architecture and improved performance of the RRC state transitions.
Idle and DCH states are nearly identical to that of idle and connected in LTE. However, the intermediate FACH state is unique to UMTS networks (HSPA, HSPA+) and allows the use of a common channel for small data transfers: slow, steady, and consuming roughly half the power of the DCH state. In practice, this state was designed to handle non-interactive traffic, such as periodic polling and status checks done by many background applications.
Not surprisingly, the transition from DCH to FACH is triggered by a timer. However, once in FACH, what triggers a promotion back to DCH? Each device maintains a buffer of data to be sent, and as long as the buffer does not exceed a network-configured threshold, typically anywhere from 100 to 1,000 bytes, then the device can remain in the intermediate state. Finally, if no data is transferred while in FACH for some period of time, another timer transitions the device down to the idle state.
Unlike LTE, which offers two intermediate states (Short DRX and Long DRX), UMTS devices have just a single intermediate state: FACH. However, even though LTE offers a theoretically higher degree of power control, the radios themselves tend to consume more power in LTE devices; higher throughput comes at a cost of increased battery consumption. Hence, LTE devices still have a much higher power profile than their 3G predecessors.
Individual power states aside, perhaps the biggest difference between the earlier-generation 3G networks and LTE is the latency of the state transitions. Where LTE targets sub-hundred milliseconds for idle to connected states, the same transition from idle to DCH can take up to two seconds and require tens of control messages between the 3G device and the RRC! FACH to DCH is not much better either, requiring up to one and a half seconds for the state transition.
The good news is the latest HSPA+ networks have made significant improvements in this department and are now competitive with LTE (Table 7-6). However, we can’t count on ubiquitous access to 4G or HSPA+ networks; older generation 3G networks will continue to exist for at least another decade. Hence, all mobile applications should plan for multisecond RRC latency delays when accessing the network over a 3G interface.
While 3GPP standards such as HSPA, HSPA+, and LTE are the dominant network standards around the globe, it is important that we don’t forget the 3GPP2 CDMA based networks. The growth curve for EV-DO networks may look comparatively flat, but even so, current industry projections show nearly half a billion CDMA powered wireless subscriptions by 2017.
Not surprisingly, regardless of the differences in the standards, the fundamental limitations are the same in UMTS- and CDMA-based networks: battery power is a constraining resource, radios are expensive to operate, and network efficiency is an important goal. Consequently, CDMA networks also have an RRC state machine (Figure 7-8), which controls the radio state of each device.
This is definitely the simplest RRC state machine out of all the ones we have examined: the device is either in a high-power state, with allocated network resources, or it is idle. Further, all network transfers require a transition to a connected state, the latency for which is similar to that of HSPA networks: hundreds to thousands of milliseconds depending on the revision of the deployed infrastructure. There are no other intermediate states, and transitions back to idle are also controlled via carrier configured timeouts.
An important consequence of the timeout-driven radio state transitions, regardless of the generation or the underlying standard, is that it is very easy to construct network access patterns that can yield both poor user experience for interactive traffic and poor battery performance. In fact, all you have to do is wait long enough for the radio to transition to a lower-power state, and then trigger a network access to force an RRC transition!
To illustrate the problem, let’s assume that the device is on an HSPA+ network, which is configured to move from DCH to FACH state after 10 seconds of radio inactivity. Next, we load an application that schedules an intermittent transfer, such as a real-time analytics beacon, on an 11-second interval. What’s the net result? The device may end up spending hundreds of milliseconds in data transfer and otherwise idle while in a high-power state. Worse, it would transition into the low-power state only to be woken up again a few hundred milliseconds later—worst-case scenario for latency and battery performance.
Every radio transmission, no matter how small, forces a transition to a high-power state. Then, once the transmission is done, the radio will remain in this high-power state until the inactivity timer has expired (Figure 7-9). The size of the actual data transfer does not influence the timer. Further, the device may then also have to cycle through several more intermediate states before it can return back to idle.
The “energy tails” generated by the timer-driven state transitions make periodic transfers a very inefficient network access pattern on mobile networks. First, you have to pay the latency cost of the state transition, then the transfer happens, and finally the radio idles, wasting power, until all the timers fire and the device can return to the low-power state.
Now that we have familiarized ourselves with the RRC and device capabilities, it is useful to zoom out and consider the overall end-to-end architecture of a carrier network. Our goal here is not to become experts in the nomenclature and function of every component, of which there are dozens, but rather to highlight the components that have a direct impact on how the data flows through the carrier network and reasons why it may affect the performance of our applications.
The specific infrastructure and names of various logical and physical components within a carrier network depend on the generation and type of deployed network: EV-DO vs. HSPA vs. LTE, and so on. However, there are also many similarities among all of them, and in this chapter we’ll examine the high-level architecture of an LTE network.
Why LTE? First, it is the most likely architecture for new carrier deployments. Second, and even more importantly, one of the key features of LTE is its simplified architecture: fewer components and fewer dependencies also enable improved performance.
The radio access network (RAN) is the first big logical component of every carrier network (Figure 7-10), whose primary responsibility is to mediate access to the provisioned radio channel and shuttle the data packets to and from the user’s device. In fact, this is the component controlled and mediated by the Radio Resource Controller. In LTE, each radio base station (eNodeB) hosts the RRC, which maintains the RRC state machine and performs all resource assignment for each active user in its cell.
Whenever a user has a stronger signal from a nearby cell, or if his current cell is overloaded, he may be handed off to a neighboring tower. However, while this sounds simple on paper, the hand-off procedure is also the reason for much of the additional complexity within every carrier network. If all users always remained in the same fixed position, and stayed within reach of a single tower, then a static routing topology would suffice. However, as we all know, that is simply not the case: users are mobile and must be migrated from tower to tower, and the migration process should not interrupt any voice or data traffic. Needless to say, this is a nontrivial problem.
First of all, if the user’s device can be associated with any radio tower, how do we know where to route the incoming packets? Of course, there is no magic: the radio access network must communicate with the core network to keep track of the location of every user. Further, to handle the transparent handoff, it must also be able to dynamically update its existing tunnels and routes without interrupting any existing, user-initiated voice and data sessions.
In LTE, a tower-to-tower handoff can be performed within hundreds of milliseconds, which will yield a slight pause in data delivery at the physical layer, but otherwise this procedure is completely transparent to the user and to all applications running on her device. In earlier-generation networks, this same process can take up to several seconds.
However, we’re not done yet. Radio handoffs can be a frequent occurrence, especially in high-density urban and office environments, and requiring the user’s device to continuously perform the cell handoff negotiations, even when the device is idle, would consume a lot of energy on the device. Hence, an additional layer of indirection was added: one or more radio towers are said to form a “tracking area,” which is a logical grouping of towers defined by the carrier network.
The core network must know the location of the user, but frequently it knows only the tracking area and not the specific tower currently servicing the user—as we will see, this has important implications on the latency of inbound data packets. In turn, the device is allowed to migrate between towers within the same tracking area with no overhead: if the device is in idle RRC state, no notifications are emitted by the device or the radio network, which saves energy on the mobile handset.
The core network (Figure 7-11), which is also known as the Evolved Packet Core (EPC) in LTE is responsible for the data routing, accounting, and policy management. Put simply, it is the piece that connects the radio network to the public Internet.
First, we have the packet gateway (PGW), which is the public gateway that connects the mobile carrier to the public Internet. The PGW is the termination point for all external connections, regardless of the protocol. When a mobile device is connected to the carrier network, the IP address of the device is allocated and maintained by the PGW.
Each device within the carrier network has an internal identifier, which is independent of the assigned IP address. In turn, once a packet is received by the PGW, it is encapsulated and tunneled through the EPC to the radio access network. LTE uses Stream Control Transmission Protocol (SCTP) for control-plane traffic and a combination of GPRS Tunneling Protocol (GTP) and UDP for all other data.
The PGW also performs all the common policy enforcement, such as packet filtering and inspection, QoS assignment, DoS protection, and more. The Policy and Charging Rules Function (PCRF) component is responsible for maintaining and evaluating these rules for the packet gateway. PCRF is a logical component, meaning it can be part of the PGW, or it can stand on its own.
Now, let’s say the PGW has received a packet from the public Internet for one of the mobile devices on its network; where does it route the data? The PGW has no knowledge of the actual location of the user, nor the different tracking areas within the radio access network. This next step is the responsibility of the Serving Gateway (SGW) and the Mobility Management Entity (MME).
The PGW routes all of its packets to the SGW. However, to make matters even more complicated, the SGW may not know the exact location of the user either. This function is, in fact, one of the core responsibilities of the MME. The Mobility Management Entity component is effectively a user database, which manages all the state for every user on the network: their location on the network, type of account, billing status, enabled services, plus all other user metadata. Whenever a user’s location within the network changes, the location update is sent to the MME; when the user turns on their phone, the authentication is performed by the MME, and so on.
Hence, when a packet arrives at the SGW, a query to the MME is sent for the location of the user. Then, once the MME returns the answer, which contains the tracking area and the ID of the specific tower serving the target device, the SGW can establish a connection to the tower if none exists and route the user data to the radio access network.
In a nutshell, that is all there is to it. This high-level architecture is effectively the same in all the different generations of mobile data networks. The names of the logical components may differ, but fundamentally all mobile networks are subject to the following workflow:
An important factor in the performance of any carrier network is the provisioned connectivity and capacity between all the logical and physical components. The LTE radio interface may be capable of reaching up to 100 Mbps between the user and the radio tower, but once the signal is received by the radio tower, sufficient capacity must be available to transport all this data through the carrier network and toward its actual destination. Plus, let’s not forget that a single tower should be able to service many active users simultaneously!
Delivering a true 4G experience is not a simple matter of deploying the new radio network. The core network must also be upgraded, sufficient capacity links must be present between the EPC and the radio network, and all the EPC components must be able to process much higher data rates with much lower latencies than in any previous generation network.
In practice, a single radio tower may serve up to three nearby radio cells, which can easily add up to hundreds of active users. With 10+ Mbps data rate requirements per user, each tower needs a dedicated fiber link!
Needless to say, all of these requirements make 4G networks a costly proposition to the carrier: running fiber to all the radio stations, high-performance routers, and so on. In practice, it is now not unusual to find the overall performance of the network being limited not by the radio interface, but by the available backhaul capacity of the carrier network.
These performance bottlenecks are not something we can control as developers of mobile applications, but they do, once again, illustrate an important fact: the architecture of our IP networks is based on a best effort delivery model, which makes no guarantees about end-to-end performance. Once we remove the bottleneck from the first hop, which is the wireless interface, we move the bottleneck to the next slowest link in the network, either within the carrier network or somewhere else on the path toward our destination. In fact, this is nothing new; recall our earlier discussion on Last-Mile Latency in wired networks.
Just because you are connected over a 4G interface doesn’t mean you are guaranteed the maximum throughput offered by the radio interface. Instead, our applications must adapt to the continuously changing network weather over the wireless channel, within the carrier network, and on the public Internet.
One of the primary complaints about designing applications for the mobile web is the high variability in latency. Well, now that we have covered the RRC and the high-level architecture of a mobile network, we can finally connect the dots and see the end-to-end flow of the data packets, which should also explain why this variability exists. Even better, as we will see, much of the variability is actually very much predictable!
To start, let’s assume that the user has already authenticated with a 4G network and the mobile device is idle. Next, the user types in a URL and hits “Go.” What happens next?
First, because the phone is in idle RRC state, the radio must synchronize with the nearby radio tower and send a request for a new radio context to be established (Figure 7-12, step 1)—this negotiation requires several roundtrips between the handset and the radio tower, which may take up to 100 milliseconds. For earlier-generation networks, where the RRC is managed by the serving gateway, this negotiation latency is much higher—up to several seconds.
Once the radio context is established, the device has a resource assignment from the radio tower and is able to transmit data (step 2) at a specified rate and signal power. The time to transmit a packet of data from the user’s radio to the tower is known as the “user-plane one-way latency” and takes up to five milliseconds for 4G networks. Hence, the first packet incurs a much higher delay due to the need to perform the RRC transition, but packets immediately after incur only the constant first-hop latency cost, as long as the radio stays in the high-power state.
However, we are not done yet, as we have only transferred our packets from the device to the radio tower! From here, the packets have to travel through the core network—through the SGW to the PGW (step 3)—and out to the public Internet (step 4). Unfortunately, the 4G standards make no guarantees on latency of this path, and hence this latency will vary from carrier to carrier.
In practice, the end-to-end latency of many deployed 4G networks tends to be in the 30–100 ms range once the device is in a connected state—that is to say, without the control plane latency incurred by the initial packet. Hence, if up to 5 ms of the total time is accounted for on the first wireless hop, then the rest (25–95 ms) is the routing and transit overhead within the core network of the carrier.
Next, let’s say the browser has fetched the requested page and the user is engaging with the content. The radio has been idle for a few dozen seconds, which means that the RRC has likely moved the user into a DRX state (LTE RRC State Machine) to conserve battery power and to free up network resources for other users. At this point, the user decides to navigate to a different destination in the browser and hence triggers a new request. What happens now?
Nearly the same workflow is repeated as we just saw, except that because the device was in a dormant (DRX) state, a slightly quicker negotiation (Figure 7-12, step 1) can take place between the device and the radio tower—up to 50 milliseconds (Table 7-9) for dormant to connected.
In summary, a user initiating a new request incurs several different latencies:
The first two latencies are bounded by the 4G requirements, the core network latency is carrier specific, and the final piece is something you can influence by strategically positioning your servers closer to the user; see the earlier discussion on Speed of Light and Propagation Latency.
Now let’s examine the opposite scenario: the user’s device is idle, but a data packet must be routed from the PGW to the user (Figure 7-13). Once again, recall that all connections are terminated at the PGW, which means that the device can be idle, with its radio off, but the connection the device may have established earlier, such as a long-lived TCP session, can still be active at the PGW.
As we saw earlier, the PGW routes the inbound packet to the SGW (step 1), which in turn queries the MME. However, the MME may not know the exact tower currently servicing the user; recall that a collection of radio towers form a “tracking area.” Whenever a user enters a different tracking area, its location is updated in the MME, but tower handoffs within the same tracking area do not trigger an update to the MME.
Instead, if the device is idle, the MME sends a paging message (step 2) to all the towers in the tracking area, which in turn all broadcast a notification (step 3) on a shared radio channel, indicating that the device should reestablish its radio context to receive the inbound data. The device periodically wakes to listen to the paging messages, and if it finds itself on the paging list, then it initiates the negotiation (step 4) with the radio tower to reestablish the radio context.
Once the radio context is established, the tower that performed the negotiation sends a message back (step 5) to the MME indicating where the user is, the MME returns the answer to the serving gateway, and the gateway finally routes the message (step 6) to the tower, which then delivers (step 7) the message to the device! Phew.
Once the device is in a connected state, a direct tunnel is established between the radio tower and the serving gateway, which means that further incoming packets are routed directly to the tower without the paging overhead, skipping steps 2–5. Once again, the first packet incurs a much higher latency cost on mobile networks! Plan for it.
The preceding packet workflow is transparent to IP and all layers above it, including our applications: the packets are buffered by the PGW, SGW, and the eNodeB at each stage until they can be routed to the device. In practice, this translates to observable latency jitter in packet arrival times, with the first packet incurring the highest delays due to control-plane negotiation.
Existing 4G radio and modulation technologies are already within reach of the theoretical limits of the wireless channel. Hence, the next order of magnitude in wireless performance will not come from improvements in the radio interfaces, but rather from smarter topologies of the wireless networks—specifically, through wide deployment of multilayer heterogeneous networks (HetNets), which will also require many improvements in the intra-cell coordination, handoff, and interference management.
The core idea behind HetNets is a simple one: instead of relying on just the macro coverage of a large geographic area, which creates a lot of competition for all users, we can also cover the area with many small cells (Figure 7-14), each of which can minimize path loss, require lower transmit power, and enable better performance for all users.
A single macrocell can cover up to tens of square miles in low-density wireless environments, but in practice, in high-density urban and office settings, can be limited to anywhere from just 50 to 300 meters! In other words, it can cover a small block, or a few buildings. By comparison, microcells are designed to cover a specific building; picocells can service one or more separate floors, and femtocells can cover a small apartment and leverage your existing broadband service as the wireless backhaul.
However, note that HetNets are not simply replacing the macrocells with many small cells. Instead, HetNets are layering multiple cells on top of one another! By deploying overlapping layers of wireless networks, HetNets can provide much better network capacity and improved coverage for all users. However, the outstanding challenges are in minimizing interference, providing sufficient uplink capacity, and creating and improving protocols for seamless handoff between the various layers of networks.
What does this mean for the developers building mobile applications? Expect the number of handoffs between different cells to increase significantly and adapt accordingly: the latency and throughput performance may vary significantly.
Picocells are often used by mobile carriers to extend coverage to indoor and outdoor areas where signal quality may be poor, or to add network capacity in areas with very dense phone usage—e.g., a large public area, a conference hall, stadium, train station, and so on. Some picocells may be deployed permanently, while others may be put up for a specific occasion: wireless capacity planning and modeling (Figure 7-15) is both an art and a science!
Dedicated modeling software, such as TamoGraph Site Survey shown earlier, is often used to model the physical environment, number of active users, and the wireless technology in use (WiFi in the previous example) to help determine the required number, placement, and configuration of networks.
By this point, one has to wonder whether all the extra protocols, gateways, and negotiation mechanisms within a 3G or 4G network are worth the additional complexity. By comparison, WiFi implementation is much simpler and seems to work well enough, doesn’t it? Answering this question requires a lot of caveats, since as we saw, measuring wireless performance is subject to dozens of environmental and technology considerations. Further, the answer also depends on chosen evaluation criteria:
However, while there are dozens of different stakeholders (users, carriers, and handset manufacturers, just to name a few), each with their own priority lists, early tests of the new 4G networks are showing very promising results. In fact, key metrics such as network latency, throughput, and network capacity are often outperforming WiFi!
As a concrete example, a joint research project between the University of Michigan and AT&T Labs ran a country-wide test (Figure 7-16) within the U.S., comparing 4G, 3G, and WiFi (802.11g, 2.4GHz) performance:
The box-and-whisker plot for each connection type packs a lot of useful information into a small graphic: the whiskers show the range of the entire distribution, the box shows the 25%–75% quantiles of the distribution, and the black horizontal line within the box is the median.
Of course, a single test does not prove a universal rule, especially when it comes to performance, but the results are nonetheless very promising: early LTE networks are showing great network throughput performance, and even more impressively, much more stable RTT and packet jitter latencies when compared with other wireless standards.
In other words, at least with respect to this test, LTE offers comparable and better performance than WiFi, which also shows that improved performance is possible, and all the extra complexity is paying off! The mobile web doesn’t have to be slow. In fact, we have all the reasons to believe that we can and will make it faster.
First off, minimizing latency through keepalive connections, geo-positioning your servers and data closer to the client, optimizing your TLS deployments, and all the other protocol optimizations we have covered are only more important on mobile applications, where both latency and throughput are always at a premium. Similarly, all the web application performance best practices are equally applicable. Feel free to flip ahead to Chapter 10; we’ll wait.
However, mobile networks also pose some new and unique requirements for our performance strategy. Designing applications for the mobile web requires careful planning and consideration of the presentation of the content within the constraints of the form factor of the device, the unique performance properties of the radio interface, and the impact on the battery life. The three are inextricably linked.
Perhaps because it is the easiest to control, the presentation layer, with topics such as responsive design, tends to receive the most attention. However, where most applications fall short, it is often due to the incorrect design assumptions about networking performance: the application protocols are the same, but the differences in the physical delivery layers impose a number of constraints that, if unaccounted for, will lead to slow response times, high latency variability, and ultimately a compromised experience for the user. To add insult to injury, poor networking decisions will also have an outsized negative impact on the battery life of the device.
There is no universal solution for these three constraints. There are best practices for the presentation layer, the networking, and the battery life performance, but frequently they are at odds; it is up to you and your application to find the balance in your requirements. One thing is for sure: simply disregarding any one of them won’t get you far.
With that in mind, we won’t elaborate too much on the presentation layer, as that varies with every platform and type of application—plus, there are plenty of existing books dedicated to this subject. But, regardless of the make or the operating system, the radio and battery constraints imposed by mobile networks are universal, and that is what we will focus on in this chapter.
Throughout this chapter and especially in the following pages, the term “mobile application” is used in its broadest definition: all of our discussions on the performance of mobile networks are equally applicable to native applications, regardless of the platform, and applications running in your browser, regardless of the browser vendor.
When it comes to mobile, conserving power is a critical concern for everyone involved: device manufacturers, carriers, application developers, and the end users of our applications. When in doubt, or wondering why or how certain mobile behaviors were put in place, ask a simple question: how does it impact or improve the battery life? In fact, this is a great question to ask for any and every feature in your application also.
Networking performance on mobile networks is inherently linked to battery performance. In fact, the physical layers of the radio interface are specifically built to optimize the battery life against the following constraints:
With that in mind, mobile applications should aim to minimize their use of the radio interface. To be clear, that is not to say that you should avoid using the radio entirely; after all we are building connected applications that rely on access to the network! However, because keeping the radio active is so expensive in terms of battery life, our applications should maximize the amount of transferred data while the radio is on and then seek to minimize the number of additional data transfers.
Even though WiFi uses a radio interface to transfer data, it is important to realize that the underlying mechanics of WiFi, and consequently the latency, throughput, and power profiles of WiFi, when compared with 2G, 3G, and 4G mobile networks are fundamentally different; see our earlier discussion on 3G, 4G, and WiFi Power Requirements. Consequently, the networking behavior can and often should be different when on WiFi vs. mobile networks.
Despite the high emphasis on optimizing energy use, most platforms currently lack the necessary tools to help developers measure and optimize their applications. Thankfully, there are third-party tools that can help, such as the free Application Resource Optimizer (ARO) toolkit developed by AT&T.
ARO consists of two components: a collector and an analyzer. The collector is an Android application that runs in the background (on a real phone, or within an emulator) and captures the transferred data packets, radio activity, and other interactions with the phone. To capture a trace, load the collector, hit Record, interact with your application, and then copy the trace to your system.
Once a trace is available, you can open it with the analyzer to get insights into radio states, energy consumption, and traffic patterns of your application. One of the great features about the analyzer is that it will also provide recommendations for common performance pitfalls, such as missing compression, redundant data transfers, and more.
Two important things to note: the battery consumption and radio states are generated via a specified model of the device and the type of radio network. In other words, the generated numbers are not exact measurements from the device in use but estimates based on specified parameters in the model. On the upside, this allows you to import different device and network models and compare their energy use—e.g., 3G vs. 4G.
Finally, the collector is Android only, but the ARO analyzer can also accept any regular packet trace (pcap) file produced by tcpdump or a compatible tool; iOS users will have to use the tcpdump method.
To get started with ARO, head to http://hpbn.co/attaro.
The fact that the mobile radio incurs a fixed power cost to cycle into the full power state, regardless of the amount of data to be transferred, tells us that there is no such thing as a “small request” as far as the battery is concerned. Intermittent network access is a performance anti-pattern on mobile networks; see Inefficiency of Periodic Transfers. In fact, extending this same logic yields the following rules:
In general, push delivery is more efficient than polling. However, a high-frequency push stream can be just as, if not more, expensive. Whenever there is a need for real-time updates, you should consider the following questions:
For push delivery, native applications have access to platform-specific push delivery services, which should be used when possible. For web applications, server-sent events (SSEs) and WebSocket delivery can be used to minimize latency and protocol overhead. Avoid polling and costly XHR techniques when possible.
A simple aggregation strategy of bundling multiple notifications into a single push event, based on an adaptive interval, user preference, or even the battery level on the device, can make a significant improvement to the power profile of any application, especially background applications, which often rely on this type of network access pattern.
Intermittent beacon requests such as audience measurement pings and real-time analytics can easily negate all of your careful battery optimizations. These pings are mostly harmless on wired and even WiFi networks but carry an outsized cost on mobile networks. Do these beacons need to happen instantaneously? There is a good chance that you can easily log and defer these requests until next time the radio is active. Piggyback your background pings, and pay close attention to the network access patterns of third-party libraries and snippets in your code.
Finally, while we have so far focused on the battery, intermittent network access required for techniques such as progressive enhancement and incremental loading also carries a large latency cost due to the RRC state transitions! Recall that every state transition incurs a high control-plane latency cost in mobile networks, which may inject hundreds or thousands of extra milliseconds of latency—an especially expensive proposition for user-initiated and interactive traffic.
To illustrate the impact of periodic polling on battery life, let’s do some simple math. The numbers are not exact but are within range of a typical 3G/4G mobile handset:
 )
)
 )
)
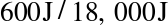 )
)
~3% of available battery capacity per hour for a single application! All it would take is a couple of applications with non-overlapping polling intervals to drain your battery by midday. Although, to be fair, a push application with frequent, unbuffered updates can have an even higher energy consumption profile.
Battery life optimization and frequency of updates are inherently at odds. Consider the requirements of your specific application to determine the optimal strategy: bundling of updates, adaptive update intervals, pull vs. push, and so on. Then, measure the impact with ARO or a similar tool and adjust accordingly.
The connection state and the lifecycle of any TCP or UDP connection is independent of the radio state on the device: the radio can be in a low-power state while the connections are maintained by the carrier network. Then, when a new packet arrives from the external network, the carrier radio network will notify the device, promote its radio to a connected state, and resume the data transfer.
The application does not need to keep the radio “active” to ensure that connections are not dropped. Unnecessary application keepalives can have an enormous negative impact on battery life performance and are often put in place due to simple misunderstanding of how the mobile radio works. Refer to Physical Layer vs. Application Layer Connectivity and Packet Flow in a Mobile Network.
Most mobile carriers set a 5–30 minute NAT connection timeout. Hence, you may need a periodic (5 minute) keepalive to keep an idle connection from being dropped. If you find yourself requiring more frequent keepalives, check your own server, proxy, and load balancer configuration first!
A single HTTP request for a required resource may incur anywhere from hundreds to thousands of milliseconds of network latency overhead in a mobile network. In part, this is due to the high roundtrip latencies, but we also can’t forget the overhead (Figure 8-2) of DNS, TCP, TLS, and control-plane costs!
In the best case, the radio is already in a high-power state, the DNS is pre-resolved, and an existing TCP connection is available: the client may be able to reuse an existing connection and avoid the overhead of establishing a new connection. However, if the connection is busy, or nonexistent, then we must incur a number of additional roundtrips before any application data can be sent.
To illustrate the impact of these extra network roundtrips, let’s assume an optimistic 100 ms roundtrip time for 4G and a 200 ms roundtrip time for 3.5G+ networks:
| 3G | 4G | |
Control plane | 200–2,500 ms | 50–100 ms |
DNS lookup | 200 ms | 100 ms |
TCP handshake | 200 ms | 100 ms |
TLS handshake | 200–400 ms | 100–200 ms |
HTTP request | 200 ms | 100 ms |
Total latency overhead | 200–3500 ms | 100–600 ms |
The RRC control-plane latency alone can add anywhere from hundreds to thousands of milliseconds of overhead to reestablish the radio context on a 3G network! Once the radio is active, we may need to resolve the hostname to an IP address and then perform the TCP handshake—two network roundtrips. Then, if a secure tunnel is required, we may need up to two extra network roundtrips (see TLS Session Resumption). Finally, the HTTP request can be sent, which adds a minimum of another roundtrip.
We have not accounted for the server response time or the size of the response, which may require several roundtrips, and yet we have already incurred up to half a dozen roundtrips. Multiply that by the roundtrip time, and we are looking at entire seconds of latency overhead for 3G, and roughly half a second for 4G networks.
If the mobile device has been idle for more than a few seconds, you should assume and anticipate that the first packet will incur hundreds, or even thousands of milliseconds of extra RRC latency. As a rule of thumb, add 100 ms for 4G, 150–500 ms for 3.5G+, and 500–2,500 ms for 3G networks, as a one-time, control-plane latency cost.
The RRC is specifically designed to help mitigate some of the cost of operating the power-hungry radio. However, what we gain in battery life is offset by increases in latency and lower throughput due to the presence of the various timers, counters, and the consequent overhead of required network negotiation to transition between the different radio states. However, the RRC is also a fact of life on mobile networks–there is no way around it–and if you want to build optimized applications for the mobile web, you must design with the RRC in mind.
A quick summary of what we have learned about the RRC:
We have already covered why preserving battery is such an important goal for mobile applications, and we have also highlighted the inefficiency of intermittent transfers, which are a direct result of the timeout-driven RRC state transitions. However, there is one more thing you need to take away: if the device radio has been idle, then initiating a new data transfer on mobile networks will incur an additional latency delay, which may take anywhere from 100 milliseconds on latest-generation networks to up to several seconds on older 3G and 2G networks.
While the network presents the illusion of an always-on experience to our applications, the physical or the radio layer controlled by the RRC is continuously connecting and disconnecting. On the surface, this is not an issue, but the delays imposed by the RRC are, in fact, often easily noticeable by many users when unaccounted for.
A well-designed application can feel fast by providing instant feedback even if the underlying connection is slow or the request is taking a long time to complete. Do not couple user interactions, user feedback, and network communication. To deliver the best experience, the application should acknowledge user input within hundreds of milliseconds; see Speed, Performance, and Human Perception.
If a network request is required, then initiate it in the background, and provide immediate UI feedback to acknowledge user input. The control plane latency alone will often push your application over the allotted budget for providing instant user feedback. Plan for high latencies—you cannot “fix” the latency imposed by the core network and the RRC—and work with your design team to ensure that they are aware of these limitations when designing the application.
Users dislike slow applications, but broken applications, due to transient network errors, are the worst experience of all. Your mobile application must be robust in the face of common networking failures: unreachable hosts, sudden drops in throughput or increases in latency, or outright loss of connectivity. Unlike the tethered world, you simply cannot assume that once the connection is established, it will remain established. The user may be on the move and may enter an area with high amounts of interference, many active users, or plain poor coverage.
Further, just as you cannot design your pages just for the latest browsers, you cannot design your application just for the latest-generation mobile networks. As we have covered earlier (Building for the Multigeneration Future), even users with the latest handsets will continuously transition between 4G, 3G, and even 2G networks based on the continuously changing conditions of their radio environments. Your application should subscribe to these interface transitions and adjust accordingly.
The application can subscribe to navigator.onLine notifications to monitor connection status. For a good introduction, also see Paul Kinlan’s article on HTML5Rocks: Working Off the Grid with HTML5 Offline.
Change is the only constant in mobile networks. Radio channel quality is always changing based on distance from the tower, congestion from nearby users, ambient interference, and dozens of other factors. With that in mind, while it may be tempting to perform various forms of bandwidth and latency estimation to optimize your mobile application, the results should be treated, at best, as transient data points.
The iPhone 4 “antennagate” serves as a great illustration of the unpredictable nature of radio performance: reception quality was affected by the physical location of your hand in regards to the phone’s antenna, which gave birth to the infamous “You’re holding it wrong.”
Latency and bandwidth estimates on mobile networks are stable on the order of tens to hundreds of milliseconds, at most a second, but not more. Hence, while optimizations such as adaptive bitrate streaming are still useful for long-lived streams, such as video, which is adapted in data chunks spanning a few seconds, these bandwidth estimates should definitely not be cached or used later to make decisions about the available throughput: even on 4G, you may measure your throughput as just a few hundred Kbit/s, and then move your radio a few inches and get Mbit/s+ performance!
End-to-end bandwidth and latency estimation is a hard problem on any network, but doubly so on mobile networks. Avoid it, because you will get it wrong. Instead, use coarse-grained information about the generation of the network, and adjust your code accordingly. To be clear, knowing the generation or type of mobile network does not make any end-to-end performance guarantees, but it does tell you important data about the latency of the first wireless hop and the end-to-end performance of the carrier network; see Latency and Jitter in Mobile Networks and Table 7-6.
Finally, throughput and latency aside, you should plan for loss of connectivity: assume this case is not an exception but the rule. Your application should remain operational, to the extent possible, when the network is unavailable or a transient failure happens and should adapt based on request type and specific error:
Mobile radio interface is optimized for bursty transfers, which is a property you should leverage whenever possible: group your requests together and download as much as possible, as quickly as possible, and then let the radio return to an idle state. This strategy will deliver the best network throughput and maximize battery life of the device.
The only accurate way to estimate the network’s speed is, well, to use it! Latest-generation networks, such as LTE and HSPA+, perform dynamic allocation of resources in one-millisecond intervals and prioritize bursty data flows. To go fast, keep it simple: batch and pre-fetch as much data as you can, and let the network do the rest.
An important corollary is that progressive loading of resources may do more harm than good on mobile networks. By downloading content in small chunks, we expose our applications to higher variability both in throughput and latency, not to mention the much higher energy costs to operate the radio. Instead, anticipate what your users will need next, download the content ahead of time, and let the radio idle:
Current industry estimates show that almost 90% of the worldwide wireless traffic is expected to originate indoors, and frequently in areas with WiFi connectivity within reach. Hence, while the latest 4G networks may compete with WiFi over peak throughput and latency, very frequently they still impose a monthly data cap: mobile access is metered and often expensive to the user. Further, WiFi connections are more battery efficient (see 3G, 4G, and WiFi Power Requirements) for large transfers and do not require an RRC.
Whenever possible, and especially if you are building a data-intensive application, you should leverage WiFi connectivity when available, and if not, then consider prompting the user to enable WiFi on her device to improve experience and minimize costs.
One of the great properties of the layered architecture of our network infrastructure is that it abstracts the physical delivery from the transport layer, and the transport layer abstracts the routing and data delivery from the application protocols. This separation provides great API abstractions, but for best end-to-end performance, we still need to consider the entire stack.
Throughout this chapter, we have focused on the unique properties of the physical layer of mobile networks, such as the presence of the RRC, concerns over the battery life of the device, and incurred routing latencies in mobile networks. However, on top of this physical layer reside the transport and session protocols we have covered in earlier chapters, and all of their optimizations are just as critical, perhaps doubly so:
Minimizing latency by reusing keepalive connections, geo-positioning servers and data closer to the client, optimizing TLS deployments, and all the other optimizations we outlined earlier are even more important on mobile networks, where roundtrip latencies are high and bandwidth is always at a premium.
Of course, our optimization strategy does not stop with transport and session protocols; they are simply the foundation. From there, we must also consider the performance implications of different application protocols (HTTP/1.0, 1.1, and 2), as well as general web application best practices—keep reading, we are not done yet!
The Hypertext Transfer Protocol (HTTP) is one of the most ubiquitous and widely adopted application protocols on the Internet: it is the common language between clients and servers, enabling the modern web. From its simple beginnings as a single keyword and document path, it has become the protocol of choice not just for browsers, but for virtually every Internet-connected software and hardware application.
In this chapter, we will take a brief historical tour of the evolution of the HTTP protocol. A full discussion of the varying HTTP semantics is outside the scope of this book, but an understanding of the key design changes of HTTP, and the motivations behind each, will give us the necessary background for our discussions on HTTP performance, especially in the context of the many upcoming improvements in HTTP/2.
The original HTTP proposal by Tim Berners-Lee was designed with simplicity in mind as to help with the adoption of his other nascent idea: the World Wide Web. The strategy appears to have worked: aspiring protocol designers, take note.
In 1991, Berners-Lee outlined the motivation for the new protocol and listed several high-level design goals: file transfer functionality, ability to request an index search of a hypertext archive, format negotiation, and an ability to refer the client to another server. To prove the theory in action, a simple prototype was built, which implemented a small subset of the proposed functionality:
However, even that sounds a lot more complicated than it really is. What these rules enable is an extremely simple, Telnet-friendly protocol, which some web servers support to this very day:
$> telnet google.com 80
Connected to 74.125.xxx.xxx
GET /about/
(hypertext response)
(connection closed)
The request consists of a single line: GET method and the path of the requested document. The response is a single hypertext document—no headers or any other metadata, just the HTML. It really couldn’t get any simpler. Further, since the previous interaction is a subset of the intended protocol, it unofficially acquired the HTTP 0.9 label. The rest, as they say, is history.
From these humble beginnings in 1991, HTTP took on a life of its own and evolved rapidly over the coming years. Let us quickly recap the features of HTTP 0.9:
Popular web servers, such as Apache and Nginx, still support the HTTP 0.9 protocol—in part, because there is not much to it! If you are curious, open up a Telnet session and try accessing google.com, or your own favorite site, via HTTP 0.9 and inspect the behavior and the limitations of this early protocol.
The period from 1991 to 1995 is one of rapid coevolution of the HTML specification, a new breed of software known as a “web browser,” and the emergence and quick growth of the consumer-oriented public Internet infrastructure.
The growing list of desired capabilities of the nascent Web and their use cases on the public Web quickly exposed many of the fundamental limitations of HTTP 0.9: we needed a protocol that could serve more than just hypertext documents, provide richer metadata about the request and the response, enable content negotiation, and more. In turn, the nascent community of web developers responded by producing a large number of experimental HTTP server and client implementations through an ad hoc process: implement, deploy, and see if other people adopt it.
From this period of rapid experimentation, a set of best practices and common patterns began to emerge, and in May 1996 the HTTP Working Group (HTTP-WG) published RFC 1945, which documented the “common usage” of the many HTTP/1.0 implementations found in the wild. Note that this was only an informational RFC: HTTP/1.0 as we know it is not a formal specification or an Internet standard!
Having said that, an example HTTP/1.0 request should look very familiar:
$> telnet website.org 80Connected to xxx.xxx.xxx.xxx GET /rfc/rfc1945.txt HTTP/1.0
The preceding exchange is not an exhaustive list of HTTP/1.0 capabilities, but it does illustrate some of the key protocol changes:
Both the request and response headers were kept as ASCII encoded, but the response object itself could be of any type: an HTML file, a plain text file, an image, or any other content type. Hence, the “hypertext transfer” part of HTTP became a misnomer not long after its introduction. In reality, HTTP has quickly evolved to become a hypermedia transport, but the original name stuck.
In addition to media type negotiation, the RFC also documented a number of other commonly implemented capabilities: content encoding, character set support, multi-part types, authorization, caching, proxy behaviors, date formats, and more.
Almost every server on the Web today can and will still speak HTTP/1.0. Except that, by now, you should know better! Requiring a new TCP connection per request imposes a significant performance penalty on HTTP/1.0; see Three-Way Handshake, followed by Slow-Start.
The work on turning HTTP into an official IETF Internet standard proceeded in parallel with the documentation effort around HTTP/1.0 and happened over a period of roughly four years: between 1995 and 1999. In fact, the first official HTTP/1.1 standard is defined in RFC 2068, which was officially released in January 1997, roughly six months after the publication of HTTP/1.0. Then, two and a half years later, in June of 1999, a number of improvements and updates were incorporated into the standard and were released as RFC 2616.
The HTTP/1.1 standard resolved a lot of the protocol ambiguities found in earlier versions and introduced a number of critical performance optimizations: keepalive connections, chunked encoding transfers, byte-range requests, additional caching mechanisms, transfer encodings, and request pipelining.
With these capabilities in place, we can now inspect a typical HTTP/1.1 session as performed by any modern HTTP browser and client:
$> telnet website.org 80Connected to xxx.xxx.xxx.xxx GET /index.html HTTP/1.1Host: www.website.org User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4)... (snip) Accept: */* Referer: http://website.org/ Connection: close
Accept-Encoding: gzip,deflate,sdch Accept-Language: en-US,en;q=0.8 Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.3 Cookie: __qca=P0-800083390... (snip) HTTP/1.1 200 OK
Server: nginx/1.0.11 Content-Type: image/x-icon Content-Length: 3638 Connection: close Last-Modified: Thu, 19 Jul 2012 17:51:44 GMT Cache-Control: max-age=315360000 Accept-Ranges: bytes Via: HTTP/1.1 GWA Date: Sat, 21 Jul 2012 21:35:22 GMT Expires: Thu, 31 Dec 2037 23:55:55 GMT Etag: W/PSA-GAu26oXbDi (icon data) (connection closed)
Request for HTML file, with encoding, charset, and cookie metadata
Chunked response for original HTML request
Number of octets in the chunk expressed as an ASCII hexadecimal number (256 bytes)
End of chunked stream response
Request for an icon file made on same TCP connection
Inform server that the connection will not be reused
Icon response, followed by connection close
Phew, there is a lot going on in there! The first and most obvious difference is that we have two object requests, one for an HTML page and one for an image, both delivered over a single connection. This is connection keepalive in action, which allows us to reuse the existing TCP connection for multiple requests to the same host and deliver a much faster end-user experience; see Optimizing for TCP.
To terminate the persistent connection, notice that the second client request sends an explicit close token to the server via the Connection header. Similarly, the server can notify the client of the intent to close the current TCP connection once the response is transferred. Technically, either side can terminate the TCP connection without such signal at any point, but clients and servers should provide it whenever possible to enable better connection reuse strategies on both sides.
HTTP/1.1 changed the semantics of the HTTP protocol to use connection keepalive by default. Meaning, unless told otherwise (via Connection: close header), the server should keep the connection open by default.
However, this same functionality was also backported to HTTP/1.0 and enabled via the Connection: Keep-Alive header. Hence, if you are using HTTP/1.1, technically you don’t need the Connection: Keep-Alive header, but many clients choose to provide it nonetheless.
Additionally, the HTTP/1.1 protocol added content, encoding, character set, and even language negotiation, transfer encoding, caching directives, client cookies, plus a dozen other capabilities that can be negotiated on each request.
We are not going to dwell on the semantics of every HTTP/1.1 feature. This is a subject for a dedicated book, and many great ones have been written already. Instead, the previous example serves as a good illustration of both the quick progress and evolution of HTTP, as well as the intricate and complicated dance of every client-server exchange. There is a lot going on in there!
Since its publication, RFC 2616 has served as a foundation for the unprecedented growth of the Internet: billions of devices of all shapes and sizes, from desktop computers to the tiny web devices in our pockets, speak HTTP every day to deliver news, video, and millions of other web applications we have all come to depend on in our lives.
What began as a simple, one-line protocol for retrieving hypertext quickly evolved into a generic hypermedia transport, and now a decade later can be used to power just about any use case you can imagine. Both the ubiquity of servers that can speak the protocol and the wide availability of clients to consume it means that many applications are now designed and deployed exclusively on top of HTTP.
Need a protocol to control your coffee pot? RFC 2324 has you covered with the Hyper Text Coffee Pot Control Protocol (HTCPCP/1.0)—originally an April Fools’ Day joke by IETF, and increasingly anything but a joke in our new hyper-connected world.
The Hypertext Transfer Protocol (HTTP) is an application-level protocol for distributed, collaborative, hypermedia information systems. It is a generic, stateless, protocol that can be used for many tasks beyond its use for hypertext, such as name servers and distributed object management systems, through extension of its request methods, error codes and headers. A feature of HTTP is the typing and negotiation of data representation, allowing systems to be built independently of the data being transferred.
— RFC 2616: HTTP/1.1 June 1999
The simplicity of the HTTP protocol is what enabled its original adoption and rapid growth. In fact, it is now not unusual to find embedded devices—sensors, actuators, and coffee pots alike—using HTTP as their primary control and data protocols. But under the weight of its own success and as we increasingly continue to migrate our everyday interactions to the Web—social, email, news, and video, and increasingly our entire personal and job workspaces—it has also begun to show signs of stress. Users and web developers alike are now demanding near real-time responsiveness and protocol performance from HTTP/1.1, which it simply cannot meet without some modifications.
To meet these new challenges, HTTP must continue to evolve, and hence the HTTPbis working group announced a new initiative for HTTP/2 in early 2012:
There is emerging implementation experience and interest in a protocol that retains the semantics of HTTP without the legacy of HTTP/1.x message framing and syntax, which have been identified as hampering performance and encouraging misuse of the underlying transport.
The working group will produce a specification of a new expression of HTTP’s current semantics in ordered, bi-directional streams. As with HTTP/1.x, the primary target transport is TCP, but it should be possible to use other transports.
— HTTP/2 charter January 2012
The primary focus of HTTP/2 is on improving transport performance and enabling both lower latency and higher throughput. The major version increment sounds like a big step, which it is and will be as far as performance is concerned, but it is important to note that none of the high-level protocol semantics are affected: all HTTP headers, values, and use cases are the same.
Any existing website or application can and will be delivered over HTTP/2 without modification: you do not need to modify your application markup to take advantage of HTTP/2. The HTTP servers will have to speak HTTP/2, but that should be a transparent upgrade for the majority of users. The only difference if the working group meets its goal, should be that our applications are delivered with lower latency and better utilization of the network link!
Having said that, let’s not get ahead of ourselves. Before we get to the new HTTP/2 protocol features, it is worth taking a step back and examining our existing deployment and performance best practices for HTTP/1.1. The HTTP/2 working group is making fast progress on the new specification, but even if the final standard was already done and ready, we would still have to support older HTTP/1.1 clients for the foreseeable future—realistically, a decade or more.
In any complex system, a large part of the performance optimization process is the untangling of the interactions between the many distinct and separate layers of the system, each with its own set of constraints and limitations. So far, we have examined a number of individual networking components in close detail—different physical delivery methods and transport protocols—and now we can turn our attention to the larger, end-to-end picture of web performance optimization:
Optimizing the interaction among all the different layers is not unlike solving a family of equations, each dependent on the others, but nonetheless yielding many possible solutions. There is no one fixed set of recommendations or best practices, and the individual components continue to evolve: browsers are getting faster, user connectivity profiles change, and web applications continue to grow in their scope, ambition, and complexity.
Hence, before we dive into enumerating and analyzing individual performance best practices, it is important to step back and define what the problem really is: what a modern web application is, what tools we have at our disposal, how we measure web-performance, and which parts of the system are helping and hindering our progress.
The evolution of the Web over the course of the last few decades has given us at least three different classes of experience: the hypertext document, rich media web page, and interactive web application. Admittedly, the line between the latter two may at times be blurry to the user, but from a performance point of view, each requires a very different approach to our conversation, metrics, and the definition of performance.
An HTTP 0.9 session consisted of a single document request, which was perfectly sufficient for delivery of hypertext: single document, one TCP connection, followed by connection close. Consequently, tuning for performance was as simple as optimizing for a single HTTP request over a short-lived TCP connection.
The advent of the web page changed the formula from delivery of a single document to the document plus its dependent resources. Consequently, HTTP/1.0 introduced the notion of HTTP metadata (headers), and HTTP/1.1 enhanced it with a variety of performance-oriented primitives, such as well-defined caching, keepalive, and more. Hence, multiple TCP connections are now potentially at play, and the key performance metric has shifted from document load time to page load time, which is commonly abbreviated as PLT.
The simplest definition of PLT is “the time until the loading spinner stops spinning in the browser.” A more technical definition is time to onload event in the browser, which is an event fired by the browser once the document and all of its dependent resources (JavaScript, images, etc.) have finished loading.
Finally, the web application transformed the simple web page, which used media as an enhancement to the primary content in the markup, into a complex dependency graph: markup defines the basic structure, stylesheets define the layout, and scripts build up the resulting interactive application and respond to user input, potentially modifying both styles and markup in the process.
Consequently, page load time, which has been the de facto metric of the web performance world, is also an increasingly insufficient performance benchmark: we are no longer building pages, we are building dynamic and interactive web applications. Instead of, or in addition to, measuring the time to load each and every resource (PLT), we are now interested in answering application-specific questions:
The success of your performance and optimization strategy is directly correlated to your ability to define and iterate on application-specific benchmarks and criteria. Nothing beats application-specific knowledge and measurements, especially when linked to bottom-line goals and metrics of your business.
What exactly do we mean by “complex dependency graph of scripts, stylesheets, and markup” found in a modern web application? To answer this question, we need to take a quick detour into browser architecture and investigate how the parsing, layout, and scripting pipelines have to come together to paint the pixels to the screen.
The parsing of the HTML document is what constructs the Document Object Model (DOM). In parallel, there is an oft-forgotten cousin, the CSS Object Model (CSSOM), which is constructed from the specified stylesheet rules and resources. The two are then combined to create the “render tree,” at which point the browser has enough information to perform a layout and paint something to the screen. So far, so good.
However, this is where we must, unfortunately, introduce our favorite friend and foe: JavaScript. Script execution can issue a synchronous doc.write and block DOM parsing and construction. Similarly, scripts can query for a computed style of any object, which means that JavaScript can also block on CSS. Consequently, the construction of DOM and CSSOM objects is frequently intertwined: DOM construction cannot proceed until JavaScript is executed, and JavaScript execution cannot proceed until CSSOM is available.
The performance of your application, especially the first load and the “time to render” depends directly on how this dependency graph between markup, stylesheets, and JavaScript is resolved. Incidentally, recall the popular “styles at the top, scripts at the bottom” best practice? Now you know why! Rendering and script execution are blocked on stylesheets; get the CSS down to the user as quickly as you can.
What does a modern web application look like after all? HTTP Archive can help us answer this question. The project tracks how the Web is built by periodically crawling the most popular sites (300,000+ from Alexa Top 1M) and recording and aggregating analytics on the number of used resources, content types, headers, and other metadata for each individual destination.
An average web application, as of early 2013, is composed of the following:
90 requests, fetched from 15 hosts, with 1,311 KB total transfer size
By the time you read this, the preceding numbers have already changed and have grown even larger (Figure 10-2); the upward climb has been a stable and reliable trend with no signs of stopping. However, exact request and kilobyte count aside, it is the order of magnitude of these individual components that warrants some careful contemplation: an average web application is now well over 1 MB in size and is composed of roughly 100 sub-resources delivered from over 15 different hosts!
Unlike their desktop counterparts, web applications do not require a separate installation process: type in the URL, hit Enter, and we are up and running! However, desktop applications pay the installation cost just once, whereas web applications are running the “installation process” on each and every visit—resource downloads, DOM and CSSOM construction, and JavaScript execution. No wonder web performance is such a fast-growing field and a hot topic of discussion! Hundreds of resources, megabytes of data, dozens of different hosts, all of which must come together in hundreds of milliseconds to facilitate the desired instant web experience.
Speed and performance are relative terms. Each application dictates its own set of requirements based on business criteria, context, user expectations, and the complexity of the task that must be performed. Having said that, if the application must react and respond to a user, then we must plan and design for specific, user-centric perceptual processing time constants. Despite the ever-accelerating pace of life, or at least the feeling of it, our reaction times remain constant (Table 10-1), regardless of type of application (online or offline), or medium (laptop, desktop, or mobile device).
| Delay | User perception |
0–100 ms | Instant |
100–300 ms | Small perceptible delay |
300–1000 ms | Machine is working |
1,000+ ms | Likely mental context switch |
10,000+ ms | Task is abandoned |
The preceding table helps explain the unofficial rule of thumb in the web performance community: render pages, or at the very least provide visual feedback, in under 250 milliseconds to keep the user engaged!
For an application to feel instant, a perceptible response to user input must be provided within hundreds of milliseconds. After a second or more, the user’s flow and engagement with the initiated task is broken, and after 10 seconds have passed, unless progress feedback is provided, the task is frequently abandoned.
Now, add up the network latency of a DNS lookup, followed by a TCP handshake, and another few roundtrips for a typical web page request, and much, if not all, of our 100–1,000 millisecond latency budget can be easily spent on just the networking overhead; see Figure 8-2. No wonder so many users, especially when on a mobile or a wireless network, are demanding faster web browsing performance!
Jakob Nielsen’s Usability Engineering and Steven Seow’s Designing and Engineering Time are both excellent resources that every developer and designer should read! Time is measured objectively but perceived subjectively, and experiences can be engineered to improve perceived performance.
No discussion on web performance is complete without a mention of the resource waterfall. In fact, the resource waterfall is likely the single most insightful network performance and diagnostics tool at our disposal. Every browser provides some instrumentation to see the resource waterfall, and there are great online tools, such as WebPageTest, which can render it online for a wide variety of different browsers.
WebPageTest.org is an open-source project and a free web service that provides a system for testing the performance of web pages from multiple locations around the world: the browser runs within a virtual machine and can be configured and scripted with a variety of connection and browser-oriented settings. Following the test, the results are then available through a web interface, which makes WebPageTest an indispensable power tool in your web performance toolkit.
To start, it is important to recognize that every HTTP request is composed of a number of separate stages (Figure 10-3): DNS resolution, TCP connection handshake, TLS negotiation (if required), dispatch of the HTTP request, followed by content download. The visual display of these individual stages may differ slightly within each browser, but to keep things simple, we will use the WebPageTest version in this chapter. Make sure to familiarize yourself with the meaning of each color in your favorite browser.
Close analysis of Figure 10-3 shows that the Yahoo! homepage took 683 ms to download, and over 200 ms of that time was spent waiting on the network, which amounts to 30% of total latency of the request! However, the document request is only the beginning since, as we know, a modern web application also needs a wide variety of resources (Figure 10-4) to produce the final output. To be exact, to load the Yahoo! homepage, the browser will require 52 resources, fetched from 30 different hosts, all adding up to 486 KB in total.
The resource waterfall reveals a number of important insights about the structure of the page and the browser processing pipeline. First off, notice that while the content of the www.yahoo.com document is being fetched, new HTTP requests are being dispatched: HTML parsing is performed incrementally, allowing the browser to discover required resources early and dispatch the necessary requests in parallel. Hence, the scheduling of when the resource is fetched is in large part determined by the structure of the markup. The browser may reprioritize some requests, but the incremental discovery of each resource in the document is what creates the distinct resource “waterfall effect.”
Second, notice that the “Start Render” (green vertical line) occurs well before all the resources are fully loaded, allowing the user to begin interacting with the page while the page is being built. In fact, the “Document Complete” event (blue vertical line), also fires early and well before the remaining assets are loaded. In other words, the browser spinner has stopped spinning, the user is able to continue with his task, but the Yahoo! homepage is progressively filling in additional content, such as advertising and social widgets, in the background.
The difference between the first render time, document complete, and the time to finish fetching the last resource in the preceding example is a great illustration of the necessary context when discussing different web performance metrics. Which of those three metrics is the right one to track? There is no one single answer; each application is different! Yahoo! engineers have chosen to optimize the page to take advantage of incremental loading to allow the user to begin consuming the important content earlier, and in doing so they had to apply application-specific knowledge about which content is critical and which can be filled in later.
Different browsers implement different logic for when, and in which order, the individual resource requests are dispatched. As a result, the performance of the application will vary from browser to browser.
Tip: WebPageTest allows you to select both the location and the make and version of the browser when running the test!
The network waterfall is a power tool that can help reveal the chosen optimizations, or lack thereof, for any page or application. The previous process of analyzing and optimizing the resource waterfall is often referred to as front-end performance analysis and optimization. However, the name may be an unfortunate choice, as it misleads many to believe that all performance bottlenecks are now on the client. In reality, while JavaScript, CSS, and rendering pipelines are critical and resource-intensive steps, the server response times and network latency (“back-end performance”) are no less critical for optimizing the resource waterfall. After all, you can’t parse or execute a resource that is blocked on the network!
To illustrate this in action, we only have to switch from the resource waterfall to the connection view (Figure 10-5) provided by WebPageTest.
Unlike the resource waterfall, where each record represents an individual HTTP request, the connection view shows the life of each TCP connection—all 30 of them in this case—used to fetch the resources for the Yahoo! homepage. Does anything stand out? Notice that the download time, indicated in blue, is but a small fraction of the total latency of each connection: there are 15 DNS lookups, 30 TCP handshakes, and a lot of network latency (indicated in green) while waiting to receive the first byte of each response.
Wondering why some requests are showing the green bar (time to first byte) only? Many responses are very small, and consequently the download time does not register on the diagram. In fact, for many requests, response times are often dominated by the roundtrip latency and server processing times.
Finally, we have saved the best for last. The real surprise to many is found at the bottom of the connection view: examine the bandwidth utilization chart in Figure 10-5. With the exception of a few short data bursts, the utilization of the available connection is very low—it appears that we are not limited by bandwidth of our connection! Is this an anomaly, or worse, a browser bug? Unfortunately, it is neither. Turns out, bandwidth is not the limiting performance factor for most web applications. Instead, the bottleneck is the network roundtrip latency between the client and the server.
The execution of a web program primarily involves three tasks: fetching resources, page layout and rendering, and JavaScript execution. The rendering and scripting steps follow a single-threaded, interleaved model of execution; it is not possible to perform concurrent modifications of the resulting Document Object Model (DOM). Hence, optimizing how the rendering and script execution runtimes work together, as we saw in DOM, CSSOM, and JavaScript, is of critical importance.
However, optimizing JavaScript execution and rendering pipelines also won’t do much good if the browser is blocked on the network, waiting for the resources to arrive. Fast and efficient delivery of network resources is the performance keystone of each and every application running in the browser.
But, one might ask, Internet speeds are getting faster by the day, so won’t this problem solve itself? Yes, our applications are growing larger, but if the global average speed is already at 3.1 Mbps (Bandwidth at the Network Edge) and growing, as evidenced by ubiquitous advertising by every ISP and mobile carrier, why bother, right? Unfortunately, as you might intuit, and as the Yahoo! example shows, if that were the case then you wouldn’t be reading this book. Let’s take a closer look.
For a detailed discussion of the trends and interplay of bandwidth and latency, refer back to the “Primer on Latency and Bandwidth” in Chapter 1.
Hold your horses; of course bandwidth matters! After all, every commercial by our local ISP and mobile carrier continues to remind us of its many benefits: faster downloads, uploads, and streaming, all at up to speeds of [insert latest number here] Mbps!
Access to higher bandwidth data rates is always good, especially for cases that involve bulk data transfers: video and audio streaming or any other type of large data transfer. However, when it comes to everyday web browsing, which requires fetching hundreds of relatively small resources from dozens of different hosts, roundtrip latency is the limiting factor:
Depending on the quality and the encoding of the video you are trying to stream, you may need anywhere from a few hundred Kbps to several Mbps in bandwidth capacity—e.g., 3+ Mbps for an HD 1080p video stream. This data rate is now within reach for many users, which is evidenced by the growing popularity of streaming video services such as Netflix. Why, then, would downloading a much, much smaller web application be such a challenge for a connection capable of streaming an HD movie?
We have already covered all the necessary topics in preceding chapters to make a good qualitative theory as to why latency may be the limiting factor for everyday web browsing. However, a picture is worth a thousand words, so let’s examine the results of a quantitative study performed by Mike Belshe (Figure 10-6), one of the creators of the SPDY protocol, on the impact of varying bandwidth vs. latency on the page load times of some of the most popular destinations on the Web.
This study by Mike Belshe served as a launching point for the development of the SPDY protocol at Google, which later became the foundation of the HTTP/2 protocol.
In the first test, the connection latency is held fixed, and the connection bandwidth is incrementally increased from 1 Mbps up to 10 Mbps. Notice that at first, upgrading the connection from 1 to 2 Mbps nearly halves the page loading time—exactly the result we want to see. However, following that, each incremental improvement in bandwidth yields diminishing returns. By the time the available bandwidth exceeds 5 Mbps, we are looking at single-digit percent improvements, and upgrading from 5 Mbps to 10 Mbps results in a mere 5% improvement in page loading times!
Akamai’s broadband speed report (Bandwidth at the Network Edge) shows that an average consumer in the United States is already accessing the Web with 5 Mbps+ of available bandwidth—a number that many other countries are quickly approaching or have surpassed already. Ergo, we are led to conclude that an average consumer in the United States would not benefit much from upgrading the available bandwidth of her connection if she is interested in improving her web browsing speeds. She may be able to stream or upload larger media files more quickly, but the pages containing those files will not load noticeably faster: bandwidth doesn’t matter, much.
However, the latency experiment tells an entirely different story: for every 20 millisecond improvement in latency, we have a linear improvement in page loading times! Perhaps it is latency we should be optimizing for when deciding on an ISP, and not just bandwidth?
To speed up the Internet at large, we should look for more ways to bring down RTT. What if we could reduce cross-atlantic RTTs from 150 ms to 100 ms? This would have a larger effect on the speed of the internet than increasing a user’s bandwidth from 3.9 Mbps to 10 Mbps or even 1 Gbps.
Another approach to reducing page load times would be to reduce the number of round trips required per page load. Today, web pages require a certain amount of back and forth between the client and server. The number of round trips is largely due to the handshakes to start communicating between client and server (e.g., DNS, TCP, HTTP), and also round trips induced by the communication protocols (e.g., TCP slow start). If we can improve protocols to transfer this data with fewer round trips, we should also be able to improve page load times. This is one of the goals of SPDY.
— Mike Belshe More Bandwidth Doesn’t Matter (Much)
The previous results are a surprise to many, but they really should not be, as they are a direct consequence of the performance characteristics of the underlying protocols: TCP handshakes, flow and congestion control, and head-of-line blocking due to packet loss. Most of the HTTP data flows consist of small, bursty data transfers, whereas TCP is optimized for long-lived connections and bulk data transfers. Network roundtrip time is the limiting factor in TCP throughput and performance in most cases; see Optimizing for TCP. Consequently, latency is also the performance bottleneck for HTTP and most web applications delivered over it.
If we can measure it, we can improve it. The question is, are we measuring the right criteria, and is the process sound? As we noted earlier, measuring the performance of a modern web application is a nontrivial challenge: there is no one single metric that holds true for every application, which means that we must carefully define custom metrics in each case. Then, once the criteria are established, we must gather the performance data, which should be done through a combination of synthetic and real-user performance measurement.
Broadly speaking, synthetic testing refers to any process with a controlled measurement environment: a local build process running through a performance suite, load testing against staging infrastructure, or a set of geo-distributed monitoring servers that periodically perform a set of scripted actions and log the outcomes. Each and every one of these tests may test a different piece of the infrastructure (e.g., application server throughput, database performance, DNS timing, and so on), and serves as a stable baseline to help detect regressions or narrow in on a specific component of the system.
When configured well, synthetic testing provides a controlled and reproducible performance testing environment, which makes it a great fit for identifying and fixing performance regressions before they reach the user. Tip: identify your key performance metrics and set a “budget” for each one as part of your synthetic testing. If the budget is exceeded, raise an alarm!
However, synthetic testing is not sufficient to identify all performance bottlenecks. Specifically, the problem is that the gathered measurements are not representative of the wide diversity of the real-world factors that will determine the final user experience with the application. Some contributing factors to this gap include the following:
The combination of these and similar factors means that in addition to synthetic testing, we must augment our performance strategy with real-user measurement (RUM) to capture actual performance of our application as experienced by the user. The good news is the W3C Web Performance Working Group has made this part of our data-gathering process a simple one by introducing the Navigation Timing API (Figure 10-7), which is now supported across many of the modern desktop and mobile browsers.
As of early 2013, Navigation Timing is supported by IE9+, Chrome 6+, and Firefox 7+ across desktop and mobile platforms. The notable omissions are the Safari and Opera browsers. For the latest status, see caniuse.com/nav-timing.
The real benefit of Navigation Timing is that it exposes a lot of previously inaccessible data, such as DNS and TCP connect times, with high precision (microsecond timestamps), via a standardized performance.timing object in each browser. Hence, the data gathering process is very simple: load the page, grab the timing object from the user’s browser, and beacon it back to your analytics servers! By capturing this data, we can observe real-world performance of our applications as seen by real users, on real hardware, and across a wide variety of different networks.
When analyzing performance data, always look at the underlying distribution of the data: throw away the averages and focus on the histograms, medians, and quantiles. Averages lead to meaningless metrics when analyzing skewed and multimodal distributions. Figure 10-8 shows a hands-on, real-world example of both types of distributions on a single site: skewed distribution for the page load time and a multimodal distribution for the server response time (the two modes are due to cached vs. uncached page generation time by the application server).
Ensure that your analytics tool can provide the right statistical metrics for your performance data. The preceding data was taken from Google Analytics, which provides a histogram view within the standard Site Speed reports. Google Analytics automatically gathers Navigation Timing data when the analytics tracker is installed. Similarly, there are a wide variety of other analytics vendors who offer Navigation Timing data gathering and reporting.
Finally, in addition to Navigation Timing, the W3C Performance Group also standardized two other APIs: User Timing and Resource Timing. Whereas Navigation Timing provides performance timers for root documents only, Resource Timing provides similar performance data for each resource on the page, allowing us to gather the full performance profile of the page. Similarly, User Timing provides a simple JavaScript API to mark and measure application-specific performance metrics with the help of the same high-resolution timers:
function init() {
performance.mark("startTask1");
applicationCode1();
performance.mark("endTask1");
logPerformance();
}
function logPerformance() {
var perfEntries = performance.getEntriesByType("mark");
for (var i = 0; i < perfEntries.length; i++) {
console.log("Name: " + perfEntries[i].name +
" Entry Type: " + perfEntries[i].entryType +
" Start Time: " + perfEntries[i].startTime +
" Duration: " + perfEntries[i].duration + "\n");
}
console.log(performance.timing);
}
The combination of Navigation, Resource, and User timing APIs provides all the necessary tools to instrument and conduct real-user performance measurement for every web application; there is no longer any excuse not to do it right. We optimize what we measure, and RUM and synthetic testing are complementary approaches to help you identify regressions and real-world bottlenecks in the performance and the user experience of your applications.
Custom and application-specific metrics are the key to establishing a sound performance strategy. There is no generic way to measure or define the quality of user experience. Instead, we must define and instrument specific milestones and events in each application, a process that requires collaboration between all the stakeholders in the project: business owners, designers, and developers.
We would be remiss if we didn’t mention that a modern browser is much more than a simple network socket manager. Performance is one of the primary competitive features for each browser vendor, and given that the networking performance is such a critical criteria, it should not surprise you that the browsers are getting smarter every day: pre-resolving likely DNS lookups, pre-connecting to likely destinations, pre-fetching and prioritizing critical resources on the page, and more.
The exact list of performed optimizations will differ by browser vendor, but at their core the optimizations can be grouped into two broad classes:
The good news is all of these optimizations are done automatically on our behalf and often lead to hundreds of milliseconds of saved network latency. Having said that, it is important to understand how and why these optimizations work under the hood, because we can assist the browser and help it do an even better job at accelerating our applications. There are four techniques employed by most browsers:
For a deep dive into how these and other networking optimizations are implemented in Google Chrome, see High Performance Networking in Google Chrome.
From the outside, a modern browser network stack presents itself as simple resource-fetching mechanism, but from the inside, it is an elaborate and a fascinating case study for how to optimize for web performance. So how can we assist the browser in this quest? To start, pay close attention to the structure and the delivery of each page:
Further, aside from optimizing the structure of the page, we can also embed additional hints into the document itself to tip off the browser about additional optimizations it can perform on our behalf:
<link rel="dns-prefetch" href="//hostname_to_resolve.com">
Each of these is a hint for a speculative optimization. The browser does not guarantee that it will act on it, but it may use the hint to optimize its loading strategy. Unfortunately, not all browsers support all hints (Table 10-2), but if they don’t, then the hint is treated as a no-op and is harmless; make use of each of the techniques just shown where possible.
| Browser | dns-prefetch | subresource | prefetch | prerender |
Firefox | 3.5+ | n/a | 3.5+ | n/a |
Chrome | 1.0+ | 1.0+ | 1.0+ | 13+ |
Safari | 5.01+ | n/a | n/a | n/a |
IE | 9+ (prefetch) | n/a | 10+ | 11+ |
Internet Explorer 9 supports DNS pre-fetching, but calls it prefetch. In Internet Explorer 10+, dns-prefetch and prefetch are equivalent, resulting in a DNS pre-fetch in both cases.
To most users and even web developers, the DNS, TCP, and SSL delays are entirely transparent and are negotiated at network layers to which few of us descend. And yet each of these steps is critical to the overall user experience, since each extra network roundtrip can add tens or hundreds of milliseconds of network latency. By helping the browser anticipate these roundtrips, we can remove these bottlenecks and deliver much faster and better web applications.
A discussion on optimization strategies for HTTP/1.0 is a simple one: all HTTP/1.0 deployments should be upgraded to HTTP/1.1; end of story.
Improving performance of HTTP was one the key design goals for the HTTP/1.1 working group, and the standard introduced a large number of critical performance enhancements and features. A few of the best known include the following:
This list is incomplete, and a full discussion of the technical details of each and every HTTP/1.1 enhancement deserves a separate book. Once again, check out HTTP: The Definitive Guide by David Gourley and Brian Totty. Similarly, speaking of good reference books, Steve Souders’ High Performance Web Sites offers great advice in the form of 14 rules, half of which are networking optimizations:
Each of the preceding recommendations has stood the test of time and is as true today as when the book was first published in 2007. That is no coincidence, because all of them highlight two fundamental recommendations: eliminate and reduce unnecessary network latency, and minimize the amount of transferred bytes. Both are evergreen optimizations, which will always ring true for any application.
However, the same can’t be said for all HTTP/1.1 features and best practices. Unfortunately, some HTTP/1.1 features, like request pipelining, have effectively failed due to lack of support, and other protocol limitations, such as head-of-line response blocking, created further cracks in the foundation. In turn, the web developer community—always an inventive lot—has created and popularized a number of homebrew optimizations: domain sharding, concatenation, spriting, and inlining among dozens of others.
For many web developers, all of these are matter-of-fact optimizations: familiar, necessary, and universally accepted. However, in reality, these techniques should be seen for what they really are: stopgap workarounds for existing limitations in the HTTP/1.1 protocol. We shouldn’t have to worry about concatenating files, spriting images, sharding domains, or inlining assets. Unfortunately, “shouldn’t” is not a pragmatic stance to take: these optimizations exist for good reasons, and we have to rely on them until the underlying issues are fixed in the next revision of the protocol.
One of the primary performance improvements of HTTP/1.1 was the introduction of persistent, or keepalive HTTP connections—both names refer to the same feature. We saw keepalive in action in HTTP/1.1: Internet Standard, but let’s illustrate why this feature is such a critical component of our performance strategy.
To keep things simple, let’s restrict ourselves to a maximum of one TCP connection and examine the scenario (Figure 11-1) where we need to fetch just two small (<4 KB each) resources: an HTML document and a supporting CSS file, each taking some arbitrary amount of time on the server (40 and 20 ms, respectively).
Figure 11-1 assumes the same 28 millisecond one-way “light in fiber” delay between New York and London as used in previous TCP connection establishment examples; see Table 1-1.
Each TCP connection begins with a TCP three-way handshake, which takes a full roundtrip of latency between the client and the server. Following that, we will incur a minimum of another roundtrip of latency due to the two-way propagation delay of the HTTP request and response. Finally, we have to add the server processing time to get the total time for every request.
We cannot predict the server processing time, since that will vary by resource and the back-end behind it, but it is worth highlighting that the minimum total time for an HTTP request delivered via a new TCP connection is two network roundtrips: one for the handshake, one for the request-response cycle. This is a fixed cost imposed on all non-persistent HTTP sessions.
The faster your server processing time, the higher the impact of the fixed latency overhead of every network request! To prove this, try changing the roundtrip and server times in the previous example.
Hence, a simple optimization is to reuse the underlying connection! Adding support for HTTP keepalive (Figure 11-2) allows us to eliminate the second TCP three-way handshake, avoid another round of TCP slow-start, and save a full roundtrip of network latency.
In our example with two requests, the total savings is just a single roundtrip of latency, but let’s now consider the general case with a single TCP connection and N HTTP requests:
The total latency savings for N requests is (N–1) × RTT when connection keepalive is enabled. Finally, recall that the average value of N is 90 resources and growing (Anatomy of a Modern Web Application), and we quickly arrive at potential latency savings measured in seconds! Needless to say, persistent HTTP is a critical optimization for every web application.
Persistent HTTP allows us to reuse an existing connection between multiple application requests, but it implies a strict first in, first out (FIFO) queuing order on the client: dispatch request, wait for the full response, dispatch next request from the client queue. HTTP pipelining is a small but important optimization to this workflow, which allows us to relocate the FIFO queue from the client (request queuing) to the server (response queuing).
To understand why this is beneficial, let’s revisit Figure 11-2. First, observe that once the first request is processed by the server, there is an entire roundtrip of latency—response propagation latency, followed by request propagation latency—during which the server is idle. Instead, what if the server could begin processing the second request immediately after it finished the first one? Or, even better, perhaps it could even process both in parallel, on multiple threads, or with the help of multiple workers.
By dispatching our requests early, without blocking on each individual response, we can eliminate another full roundtrip of network latency, taking us from two roundtrips per request with no connection keepalive, down to two network roundtrips (Figure 11-3) of latency overhead for the entire queue of requests!
Eliminating the wait time imposed by response and request propagation latencies is one of the primary benefits of HTTP/1.1 pipelining. However, the ability to process the requests in parallel can have just as big, if not bigger, impact on the performance of your application.
At this point, let’s pause and revisit our performance gains so far. We began with two distinct TCP connections for each request (Figure 11-1), which resulted in 284 milliseconds of total latency. With keepalive enabled (Figure 11-2), we were able to eliminate an extra handshake roundtrip, bringing the total down to 228 milliseconds. Finally, with HTTP pipelining in place, we eliminated another network roundtrip in between requests. Hence, we went from 284 milliseconds down to 172 milliseconds, a 40% reduction in total latency, all through simple protocol optimization.
Further, note that the 40% improvement is not a fixed performance gain. This number is specific to our chosen network latencies and the two requests in our example. As an exercise for the reader, try a few additional scenarios with higher latencies and more requests. You may be surprised to discover that the savings can be much, much larger. In fact, the larger the network latency, and the more requests, the higher the savings. It is worth proving to yourself that this is indeed the case! Ergo, the larger the application, the larger the impact of networking optimization.
However, we are not done yet. The eagle-eyed among you have likely spotted another opportunity for optimization: parallel request processing on the server. In theory, there is no reason why the server could not have processed both pipelined requests (Figure 11-3) in parallel, eliminating another 20 milliseconds of latency.
Unfortunately, this optimization introduces a lot of subtle implications and illustrates an important limitation of the HTTP/1.x protocol: strict serialization of returned responses. Specifically, HTTP/1.x does not allow data from multiple responses to be interleaved (multiplexed) on the same connection, forcing each response to be returned in full before the bytes for the next response can be transferred. To illustrate this in action, let’s consider the case (Figure 11-4) where the server processes both of our requests in parallel.
Figure 11-4 demonstrates the following:
Even though the client issued both requests in parallel, and the CSS resource is available first, the server must wait to send the full HTML response before it can proceed with delivery of the CSS asset. This scenario is commonly known as head-of-line blocking and results in suboptimal delivery: underutilized network links, server buffering costs, and worst of all, unpredictable latency delays for the client. What if the first request hangs indefinitely or simply takes a very long time to generate on the server? With HTTP/1.1, all requests behind it are blocked and have to wait.
We have already encountered head-of-line blocking when discussing TCP: due to the requirement for strict in-order delivery, a lost TCP packet will block all packets with higher sequence numbers until it is retransmitted, inducing extra application latency; see TCP Head-of-Line Blocking.
In practice, due to lack of multiplexing, HTTP pipelining creates many subtle and undocumented implications for HTTP servers, intermediaries, and clients:
Due to these and similar complications, and lack of guidance in the HTTP/1.1 standard for these cases, HTTP pipelining adoption has remained very limited despite its many benefits. Today, some browsers support pipelining, usually as an advanced configuration option, but most have it disabled. In other words, if the web browser is the primary delivery vehicle for your web application, then we can’t count on HTTP pipelining to help with performance.
In absence of multiplexing in HTTP/1.x, the browser could naively queue all HTTP requests on the client, sending one after another over a single, persistent connection. However, in practice, this is too slow. Hence, the browser vendors are left with no other choice than to open multiple TCP sessions in parallel. How many? In practice, most modern browsers, both desktop and mobile, open up to six connections per host.
Before we go any further, it is worth contemplating the implications, both positive and negative, of opening multiple TCP connections in parallel. Let’s consider the maximum case with six independent connections per host:
The maximum request parallelism, in absence of pipelining, is the same as the number of open connections. Further, the TCP congestion window is also effectively multiplied by the number of open connections, allowing the client to circumvent the configured packet limit dictated by TCP slow-start. So far, this seems like a convenient workaround! However, let’s now consider some of the costs:
In practice, the CPU and memory costs are nontrivial, resulting in much higher per-client overhead on both client and server—higher operational costs. Similarly, we raise the implementation complexity on the client—higher development costs. Finally, this approach still delivers only limited benefits as far as application parallelism is concerned. It’s not the right long-term solution. Having said that, there are three valid reasons why we have to use it today:
Both TCP considerations (window scaling and cwnd) are best addressed by a simple upgrade to the latest OS kernel release; see Optimizing for TCP. The cwnd value has been recently raised to 10 packets, and all the latest platforms provide robust support for TCP window scaling. That’s the good news. The bad news is there is no simple workaround for fixing multiplexing in HTTP/1.x.
As long as we need to support HTTP/1.x clients, we are stuck with having to juggle multiple TCP streams. Which brings us to the next obvious question: why and how did the browsers settle on six connections per host? Unfortunately, as you may have guessed, the number is based on a collection of trade-offs: the higher the limit, the higher the client and server overhead, but at the additional benefit of higher request parallelism. Six connections per host is simply a safe middle ground. For some sites, this may provide great results; for many it is insufficient.
A gap in the HTTP/1.X protocol has forced browser vendors to introduce and maintain a connection pool of up to six TCP streams per host. The good news is all of the connection management is handled by the browser itself. As an application developer, you don’t have to modify your application at all. The bad news is six parallel streams may still not be enough for your application.
According to HTTP Archive, an average page is now composed of 90+ individual resources, which if delivered all by the same host would still result in significant queuing delays (Figure 11-5). Hence, why limit ourselves to the same host? Instead of serving all resources from the same origin (e.g., www.example.com), we can manually “shard” them across multiple subdomains: {shard1, shardn}.example.com. Because the hostnames are different, we are implicitly increasing the browser’s connection limit to achieve a higher level of parallelism. The more shards we use, the higher the parallelism!
Of course, there is no free lunch, and domain sharding is not an exception: every new hostname will require an additional DNS lookup, consume additional resources on both sides for each additional socket, and, worst of all, require the site author to manually manage where and how the resources are split.
In practice, it is not uncommon to have multiple hostnames (e.g., shard1.example.com, shard2.example.com) resolve to the same IP address. The shards are CNAME DNS records pointing to the same server, and browser connection limits are enforced with respect to the hostname, not the IP. Alternatively, the shards could point to a CDN or any other reachable server.
What is the formula for the optimal number of shards? Trick question, as there is no such simple equation. The answer depends on the number of resources on the page (which varies per page) and the available bandwidth and latency of the client’s connection (which varies per client). Hence, the best we can do is make an informed guess and use some fixed number of shards. With luck, the added complexity will translate to a net win for most clients.
In practice, domain sharding is often overused, resulting in tens of underutilized TCP streams, many of them never escaping TCP slow-start, and in the worst case, actually slowing down the user experience. Further, the costs are even higher when HTTPS must be used, due to the extra network roundtrips incurred by the TLS handshake. A few considerations to keep in mind:
Domain sharding is a legitimate but also an imperfect optimization. Always begin with the minimum number of shards (none), and then carefully increase the number and measure the impact on your application metrics. In practice, very few sites actually benefit from more than a dozen connections, and if you do find yourself at the top end of that range, then you may see a much larger benefit by reducing the number of resources or consolidating them into fewer requests.
HTTP 0.9 started with a simple, one-line ASCII request to fetch a hypertext document, which incurred minimal overhead. HTTP/1.0 extended the protocol by adding the notion of request and response headers to allow both sides to exchange additional request and response metadata. Finally, HTTP/1.1 made this format a standard: headers are easily extensible by any server or client and are always sent as plain text to remain compatible with previous versions of HTTP.
Today, each browser-initiated HTTP request will carry an additional 500–800 bytes of HTTP metadata: user-agent string, accept and transfer headers that rarely change, caching directives, and so on. Even worse, the 500–800 bytes is optimistic, since it omits the largest offender: HTTP cookies, which are now commonly used for session management, personalization, analytics, and more. Combined, all of this uncompressed HTTP metadata can, and often does, add up to multiple kilobytes of protocol overhead for each and every HTTP request.
RFC 2616 (HTTP/1.1) does not define any limit on the size of the HTTP headers. However, in practice, many servers and proxies will try to enforce either an 8 KB or a 16 KB limit.
The growing list of HTTP headers is not bad in and of itself, as most headers exist for a good reason. However, the fact that all HTTP headers are transferred in plain text (without any compression), can lead to high overhead costs for each and every request, which can be a serious bottleneck for some applications. For example, the rise of API-driven web applications, which frequently communicate with compact serialized messages (e.g., JSON payloads) means that it is now not uncommon to see the HTTP overhead exceed the payload data by an order of magnitude:
$> curl --trace-ascii - -d'{"msg":"hello"}' http://www.igvita.com/api== Info: Connected to www.igvita.com => Send header, 218 bytes
In the preceding example, our brief 15-character JSON message is wrapped in 352 bytes of HTTP headers, all transferred as plain text on the wire—96% protocol byte overhead, and that is the best case without any cookies. Reducing the transferred header data, which is highly repetitive and uncompressed, could save entire roundtrips of network latency and significantly improve the performance of many web applications.
Cookies are a common performance bottleneck for many applications; many developers forget that they add significant overhead to each request. See Eliminate Unnecessary Request Bytes for a full discussion.
The fastest request is a request not made. Reducing the number of total requests is the best performance optimization, regardless of protocol used or application in question. However, if eliminating the request is not an option, then an alternative strategy for HTTP/1.x is to bundle multiple resources into a single network request:
In the case of JavaScript and CSS, we can safely concatenate multiple files without affecting the behavior and the execution of the code as long as the execution order is maintained. Similarly, multiple images can be combined into an “image sprite,” and CSS can then be used to select and position the appropriate parts of the sprite within the browser viewport. The benefits of both of these techniques are twofold:
Both concatenation and spriting techniques are examples of content-aware application layer optimizations, which can yield significant performance improvements by reducing the networking overhead costs. However, these same techniques also introduce extra application complexity by requiring additional preprocessing, deployment considerations, and code (e.g., extra CSS markup for managing sprites). Further, bundling multiple independent resources may also have a significant negative impact on cache performance and execution speed of the page.
To understand why these techniques may hurt performance, consider the not-unusual case of an application with a few dozen individual JavaScript and CSS files, all combined into two requests in a production environment, one for the CSS and one for the JavaScript assets:
In practice, most web applications are not single pages but collections of different views, each with different resource requirements but also with significant overlap: common CSS, JavaScript, and images. Hence, combining all assets into a single bundle often results in loading and processing of unnecessary bytes on the wire—although this can be seen as a form of pre-fetching, but at the cost of slower initial startup.
Updates are an even larger problem for many applications. A single update to an image sprite or a combined JavaScript file may result in hundreds of kilobytes of new data transfers. We sacrifice modularity and cache granularity, which can quickly backfire if there is high churn on the asset, and especially if the bundle is large. If such is the case for your application, consider separating the “stable core,” such as frameworks and libraries, into separate bundles.
Memory use can also become a problem. In the case of image sprites, the browser must decode the entire image and keep it in memory, regardless of the actual size of displayed area. The browser does not magically clip the rest of the bitmap from memory!
All decoded images are stored as memory-backed RGBA bitmaps within the browser. In turn, each RGBA image pixel requires four bytes of memory: one byte each for red, green, and blue channels, and one byte for the alpha (transparency) channel. Hence, the total memory used is simply 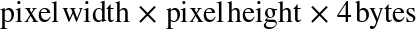 .
.
As an exercise, how much memory will a 800 × 600 pixel bitmap require?
800 × 600 × 4 bytes = 1,920,000 bytes ≈ 1.83 MB
On resource-constrained devices, such as mobile handsets, the memory overhead can quickly become your new bottleneck. This is especially true for image-heavy applications, such as games, which often depend on large numbers of image assets.
Finally, why would the execution speed be affected? Unfortunately, unlike HTML processing, which is parsed incrementally as soon as the bytes arrive on the client, both JavaScript and CSS parsing and execution is held back until the entire file is downloaded—neither JavaScript nor CSS processing models allow incremental execution.
In summary, concatenation and spriting are application-layer optimizations for the limitations of the underlying HTTP/1.x protocol: lack of reliable pipelining support and high request overhead. Both techniques can deliver significant performance improvements when applied correctly, but at the cost of added application complexity and with many additional caveats for caching, update costs, and even speed of execution and rendering of the page. Apply these optimizations carefully, measure the results, and consider the following questions in the context of your own application:
Finding the right balance among all of these criteria is an imperfect science.
Resource inlining is another popular optimization that helps reduce the number of outbound requests by embedding the resource within the document itself: JavaScript and CSS code can be included directly in the page via the appropriate script and style HTML blocks, and other resources, such as images and even audio or PDF files, can be inlined via the data URI scheme (data:[mediatype][;base64],data):
<imgsrc="data:image/gif;base64,R0lGODlhAQABAIAAAAAAAAAAACH5BAAAAAAALAAAAAABAAEAAAICTAEAOw=="alt="1x1 transparent (GIF) pixel"/>
The previous example embeds a 1×1 transparent GIF pixel within the document, but any other MIME type, as long as the browser understands it, could be similarly inlined within the page: PDF, audio, video, etc. However, some browsers enforce a limit on the size of data URIs: IE8 has a maximum limit of 32 KB.
Data URIs are useful for small and ideally unique assets. When a resource is inlined within a page, it is by definition part of the page and cannot be cached individually by the browser, a CDN, or any caching proxy as a standalone resource. Hence, if the same resource is inlined across multiple pages, then the same resource will have to be transferred as part of each and every page, increasing the overall size of each page. Further, if the inlined resource is updated, then all pages on which it previously appeared must be invalidated and refetched by the client.
Finally, while text-based resources such as CSS and JavaScript are easily inlined directly into the page with no extra overhead, base64 encoding must be used for non-text assets, which adds a significant overhead: 33% byte expansion as compared with the original resource!
Base64 encodes any byte stream into an ASCII string via 64 ASCII symbols, plus whitespace. In the process, base64 expands encoded stream by a factor of 4/3, incurring a 33% byte overhead.
In practice, a common rule of thumb is to consider inlining for resources under 1–2 KB, as resources below this threshold often incur higher HTTP overhead than the resource itself. However, if the inlined resource changes frequently, then this may lead to an unnecessarily high cache invalidation rate of host document: inlining is an imperfect science. A few criteria to consider if your application has many small, individual files:
HTTP/2 will make our applications faster, simpler, and more robust—a rare combination—by allowing us to undo many of the HTTP/1.1 workarounds previously done within our applications and address these concerns within the transport layer itself. Even better, it also opens up a number of entirely new opportunities to optimize our applications and improve performance!
The primary goals for HTTP/2 are to reduce latency by enabling full request and response multiplexing, minimize protocol overhead via efficient compression of HTTP header fields, and add support for request prioritization and server push. To implement these requirements, there is a large supporting cast of other protocol enhancements, such as new flow control, error handling, and upgrade mechanisms, but these are the most important features that every web developer should understand and leverage in their applications.
HTTP/2 does not modify the application semantics of HTTP in any way. All the core concepts, such as HTTP methods, status codes, URIs, and header fields, remain in place. Instead, HTTP/2 modifies how the data is formatted (framed) and transported between the client and server, both of whom manage the entire process, and hides all the complexity from our applications within the new framing layer. As a result, all existing applications can be delivered without modification. That’s the good news.
However, we are not just interested in delivering a working application; our goal is to deliver the best performance! HTTP/2 enables a number of new optimizations our applications can leverage, which were previously not possible, and our job is to make the best of them. Let’s take a closer look under the hood.
SPDY was an experimental protocol, developed at Google and announced in mid-2009, whose primary goal was to try to reduce the load latency of web pages by addressing some of the well-known performance limitations of HTTP/1.1. Specifically, the outlined project goals were set as follows:
To achieve the 50% PLT improvement, SPDY aimed to make more efficient use of the underlying TCP connection by introducing a new binary framing layer to enable request and response multiplexing, prioritization, and header compression; see Latency as a Performance Bottleneck.
Not long after the initial announcement, Mike Belshe and Roberto Peon, both software engineers at Google, shared their first results, documentation, and source code for the experimental implementation of the new SPDY protocol:
So far we have only tested SPDY in lab conditions. The initial results are very encouraging: when we download the top 25 websites over simulated home network connections, we see a significant improvement in performance—pages loaded up to 55% faster.
— A 2x Faster Web Chromium Blog
Fast-forward to 2012 and the new experimental protocol was supported in Chrome, Firefox, and Opera, and a rapidly growing number of sites, both large (e.g., Google, Twitter, Facebook) and small, were deploying SPDY within their infrastructure. In effect, SPDY was on track to become a de facto standard through growing industry adoption.
Observing the above trend, the HTTP Working Group (HTTP-WG) kicked off a new effort to take the lessons learned from SPDY, build and improve on them, and deliver an official “HTTP/2” standard: a new charter was drafted, an open call for HTTP/2 proposals was made, and after a lot of discussion within the working group, the SPDY specification was adopted as a starting point for the new HTTP/2 protocol.
Over the next few years SPDY and HTTP/2 would continue to coevolve in parallel, with SPDY acting as an experimental branch that was used to test new features and proposals for the HTTP/2 standard: what looks good on paper may not work in practice, and vice versa, and SPDY offered a route to test and evaluate each proposal before its inclusion in the HTTP/2 standard. In the end, this process spanned three years and resulted in a over a dozen intermediate drafts:
In early 2015 the IESG reviewed and approved the new HTTP/2 standard for publication. Shortly after that, the Google Chrome team announced their schedule to deprecate SPDY and NPN extension for TLS:
HTTP/2’s primary changes from HTTP/1.1 focus on improved performance. Some key features such as multiplexing, header compression, prioritization and protocol negotiation evolved from work done in an earlier open, but non-standard protocol named SPDY. Chrome has supported SPDY since Chrome 6, but since most of the benefits are present in HTTP/2, it’s time to say goodbye. We plan to remove support for SPDY in early 2016, and to also remove support for the TLS extension named NPN in favor of ALPN in Chrome at the same time. Server developers are strongly encouraged to move to HTTP/2 and ALPN.
We’re happy to have contributed to the open standards process that led to HTTP/2, and hope to see wide adoption given the broad industry engagement on standardization and implementation.
— Hello HTTP/2, Goodbye SPDY Chromium Blog
The coevolution of SPDY and HTTP/2 enabled server, browser, and site developers to gain real-world experience with the new protocol as it was being developed. As a result, the HTTP/2 standard is one of the best and most extensively tested standards right out of the gate. By the time HTTP/2 was approved by the IESG, there were dozens of thoroughly tested and production-ready client and server implementations. In fact, just weeks after the final protocol was approved, many users were already enjoying its benefits as several popular browsers (and many sites) deployed full HTTP/2 support.
First versions of the HTTP protocol were intentionally designed for simplicity of implementation: HTTP/0.9 was a one-line protocol to bootstrap the World Wide Web; HTTP/1.0 documented the popular extensions to HTTP/0.9 in an informational standard; HTTP/1.1 introduced an official IETF standard; see Chapter 9. As such, HTTP/0.9-1.x delivered exactly what it set out to do: HTTP is one of the most ubiquitous and widely adopted application protocols on the Internet.
Unfortunately, implementation simplicity also came at a cost of application performance: HTTP/1.x clients need to use multiple connections to achieve concurrency and reduce latency; HTTP/1.x does not compress request and response headers, causing unnecessary network traffic; HTTP/1.x does not allow effective resource prioritization, resulting in poor use of the underlying TCP connection; and so on.
These limitations were not fatal, but as the web applications continued to grow in their scope, complexity, and importance in our everyday lives, they imposed a growing burden on both the developers and users of the web, which is the exact gap that HTTP/2 was designed to address:
HTTP/2 enables a more efficient use of network resources and a reduced perception of latency by introducing header field compression and allowing multiple concurrent exchanges on the same connection… Specifically, it allows interleaving of request and response messages on the same connection and uses an efficient coding for HTTP header fields. It also allows prioritization of requests, letting more important requests complete more quickly, further improving performance.
The resulting protocol is more friendly to the network, because fewer TCP connections can be used in comparison to HTTP/1.x. This means less competition with other flows, and longer-lived connections, which in turn leads to better utilization of available network capacity. Finally, HTTP/2 also enables more efficient processing of messages through use of binary message framing.
— Hypertext Transfer Protocol version 2, Draft 17
It is important to note that HTTP/2 is extending, not replacing, the previous HTTP standards. The application semantics of HTTP are the same, and no changes were made to the offered functionality or core concepts such as HTTP methods, status codes, URIs, and header fields—these changes were explicitly out of scope for the HTTP/2 effort. That said, while the high-level API remains the same, it is important to understand how the low-level changes address the performance limitations of the previous protocols. Let’s take a brief tour of the binary framing layer and its features.
At the core of all performance enhancements of HTTP/2 is the new binary framing layer (Figure 12-1), which dictates how the HTTP messages are encapsulated and transferred between the client and server.
The “layer” refers to a design choice to introduce a new optimized encoding mechanism between the socket interface and the higher HTTP API exposed to our applications: the HTTP semantics, such as verbs, methods, and headers, are unaffected, but the way they are encoded while in transit is what’s different. Unlike the newline delimited plaintext HTTP/1.x protocol, all HTTP/2 communication is split into smaller messages and frames, each of which is encoded in binary format.
As a result, both client and server must use the new binary encoding mechanism to understand each other: an HTTP/1.x client won’t understand an HTTP/2 only server, and vice versa. Thankfully, our applications remain blissfully unaware of all these changes, as the client and server perform all the necessary framing work on our behalf.
The introduction of the new binary framing mechanism changes how the data is exchanged (Figure 12-2) between the client and server. To describe this process, let’s familiarize ourselves with the HTTP/2 terminology:
The smallest unit of communication in HTTP/2, each containing a frame header, which at a minimum identifies the stream to which the frame belongs.
In short, HTTP/2 breaks down the HTTP protocol communication into an exchange of binary-encoded frames, which are then mapped to messages that belong to a particular stream, and all of which are multiplexed within a single TCP connection. This is the foundation that enables all other features and performance optimizations provided by the HTTP/2 protocol.
With HTTP/1.x, if the client wants to make multiple parallel requests to improve performance, then multiple TCP connections must be used; see Using Multiple TCP Connections. This behavior is a direct consequence of the HTTP/1.x delivery model, which ensures that only one response can be delivered at a time (response queuing) per connection. Worse, this also results in head-of-line blocking and inefficient use of the underlying TCP connection.
The new binary framing layer in HTTP/2 removes these limitations, and enables full request and response multiplexing, by allowing the client and server to break down an HTTP message into independent frames (Figure 12-3), interleave them, and then reassemble them on the other end.
The snapshot in Figure 12-3 captures multiple streams in flight within the same connection: the client is transmitting a DATA frame (stream 5) to the server, while the server is transmitting an interleaved sequence of frames to the client for streams 1 and 3. As a result, there are three parallel streams in flight!
The ability to break down an HTTP message into independent frames, interleave them, and then reassemble them on the other end is the single most important enhancement of HTTP/2. In fact, it introduces a ripple effect of numerous performance benefits across the entire stack of all web technologies, enabling us to:
The new binary framing layer in HTTP/2 resolves the head-of-line blocking problem found in HTTP/1.x and eliminates the need for multiple connections to enable parallel processing and delivery of requests and responses. As a result, this makes our applications faster, simpler, and cheaper to deploy.
Once an HTTP message can be split into many individual frames, and we allow for frames from multiple streams to be multiplexed, the order in which the frames are interleaved and delivered both by the client and server becomes a critical performance consideration. To facilitate this, the HTTP/2 standard allows each stream to have an associated weight and dependency:
The combination of stream dependencies and weights allows the client to construct and communicate a “prioritization tree” (Figure 12-4) that expresses how it would prefer to receive the responses. In turn, the server can use this information to prioritize stream processing by controlling the allocation of CPU, memory, and other resources, and once the response data is available, allocation of bandwidth to ensure optimal delivery of high-priority responses to the client.
A stream dependency within HTTP/2 is declared by referencing the unique identifier of another stream as its parent; if omitted the stream is said to be dependent on the “root stream”. Declaring a stream dependency indicates that, if possible, the parent stream should be allocated resources ahead of its dependencies—e.g., please process and deliver response D before response C.
Streams that share the same parent (i.e., sibling streams) should be allocated resources in proportion to their weight. For example, if stream A has a weight of 12 and its one sibling B has a weight of 4, then to determine the proportion of the resources that each of these streams should receive:
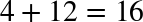
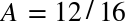 ,
, 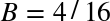
Thus, stream A should receive three-quarters and stream B should receive one-quarter of available resources; stream B should receive one-third of the resources allocated to stream A. Let’s work through a few more hands-on examples in Figure 12-4. From left to right:
As the above examples illustrate, the combination of stream dependencies and weights provides an expressive language for resource prioritization, which is a critical feature for improving browsing performance where we have many resource types with different dependencies and weights. Even better, the HTTP/2 protocol also allows the client to update these preferences at any point, which enables further optimizations in the browser—e.g., we can change dependencies and reallocate weights in response to user interaction and other signals.
Stream dependencies and weights express a transport preference, not a requirement, and as such do not guarantee a particular processing or transmission order. That is, the client cannot force the server to process the stream in particular order using stream prioritization. While this may seem counterintuitive, it is in fact the desired behavior: we do not want to block the server from making progress on a lower priority resource if a higher priority resource is blocked.
With the new binary framing mechanism in place, HTTP/2 no longer needs multiple TCP connections to multiplex streams in parallel; each stream is split into many frames, which can be interleaved and prioritized. As a result, all HTTP/2 connections are persistent, and only one connection per origin is required, which offers numerous performance benefits.
For both SPDY and HTTP/2 the killer feature is arbitrary multiplexing on a single well congestion controlled channel. It amazes me how important this is and how well it works. One great metric around that which I enjoy is the fraction of connections created that carry just a single HTTP transaction (and thus make that transaction bear all the overhead). For HTTP/1 74% of our active connections carry just a single transaction—persistent connections just aren’t as helpful as we all want. But in HTTP/2 that number plummets to 25%. That’s a huge win for overhead reduction.
— HTTP/2 is Live in Firefox Patrick McManus
Most HTTP transfers are short and bursty, whereas TCP is optimized for long-lived, bulk data transfers. By reusing the same connection HTTP/2 is able to both make more efficient use of each TCP connection, and also significantly reduce the overall protocol overhead. Further, the use of fewer connections reduces the memory and processing footprint along the full connection path (i.e., client, intermediaries, and origin servers), which reduces the overall operational costs and improves network utilization and capacity. As a result, the move to HTTP/2 should not only reduce the network latency, but also help improve throughput and reduce the operational costs.
Reduced number of connections is a particularly important feature for improving performance of HTTPS deployments: this translates to fewer expensive TLS handshakes, better session reuse, and an overall reduction in required client and server resources.
Flow control is a mechanism to prevent the sender from overwhelming the receiver with data it may not want or be able to process: the receiver may be busy, under heavy load, or may only be willing to allocate a fixed amount of resources for a particular stream. For example, the client may have requested a large video stream with high priority, but the user has paused the video and the client now wants to pause or throttle its delivery from the server to avoid fetching and buffering unnecessary data. Alternatively, a proxy server may have a fast downstream and slow upstream connections and similarly wants to regulate how quickly the downstream delivers data to match the speed of upstream to control its resource usage; and so on.
Do the above requirements remind you of TCP flow control? They should, as the problem is effectively identical—see Flow Control. However, because the HTTP/2 streams are multiplexed within a single TCP connection, TCP flow control is both not granular enough, and does not provide the necessary application-level APIs to regulate the delivery of individual streams. To address this, HTTP/2 provides a set of simple building blocks that allow the client and server to implement own stream- and connection-level flow control:
DATA frame and incremented via a WINDOW_UPDATE frame sent by the receiver.
SETTINGS frames, which set the flow control window sizes in both directions. The default value of the flow control window is set to 65,535 bytes, but the receiver can set a large maximum window size (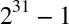 bytes) and maintain it by sending a
bytes) and maintain it by sending a WINDOW_UPDATE frame whenever any data is received.
HTTP/2 does not specify any particular algorithm for implementing flow control. Instead, it provides the simple building blocks and defers the implementation to the client and server, which can use it to implement custom strategies to regulate resource use and allocation, as well as implement new delivery capabilities that may help improve both the real and perceived performance (see Speed, Performance, and Human Perception) of our web applications.
For example, application-layer flow control allows the browser to fetch only a part of a particular resource, put the fetch on hold by reducing the stream flow control window down to zero, and then resume it later—e.g., fetch a preview or first scan of an image, display it and allow other high priority fetches to proceed, and resume the fetch once more critical resources have finished loading.
Another powerful new feature of HTTP/2 is the ability of the server to send multiple responses for a single client request. That is, in addition to the response to the original request, the server can push additional resources to the client (Figure 12-5), without the client having to request each one explicitly!
HTTP/2 breaks away from the strict request-response semantics and enables one-to-many and server-initiated push workflows that open up a world of new interaction possibilities both within and outside the browser. This is an enabling feature that will have important long-term consequences both for how we think about the protocol, and where and how it is used.
Why would we need such a mechanism in a browser? A typical web application consists of dozens of resources, all of which are discovered by the client by examining the document provided by the server. As a result, why not eliminate the extra latency and let the server push the associated resources ahead of time? The server already knows which resources the client will require; that’s server push.
In fact, if you have ever inlined a CSS, JavaScript, or any other asset via a data URI (see Resource Inlining), then you already have hands-on experience with server push! By manually inlining the resource into the document, we are, in effect, pushing that resource to the client, without waiting for the client to request it. With HTTP/2 we can achieve the same results, but with additional performance benefits:
Each pushed resource is a stream that, unlike an inlined resource, allows it to be individually multiplexed, prioritized, and processed by the client. The only security restriction, as enforced by the browser, is that pushed resources must obey the same-origin policy: the server must be authoritative for the provided content.
Each HTTP transfer carries a set of headers that describe the transferred resource and its properties. In HTTP/1.x, this metadata is always sent as plain text and adds anywhere from 500–800 bytes of overhead per transfer, and sometimes kilobytes more if HTTP cookies are being used; see Measuring and Controlling Protocol Overhead. To reduce this overhead and improve performance, HTTP/2 compresses request and response header metadata using the HPACK compression format that uses two simple but powerful techniques:
Huffman coding allows the individual values to be compressed when transferred, and the indexed list of previously transferred values allows us to encode duplicate values (Figure 12-6) by transferring index values that can be used to efficiently look up and reconstruct the full header keys and values.
As one further optimization, the HPACK compression context consists of a static and dynamic tables: the static table is defined in the specification and provides a list of common HTTP header fields that all connections are likely to use (e.g., valid header names); the dynamic table is initially empty and is updated based on exchanged values within a particular connection. As a result, the size of each request is reduced by using static Huffman coding for values that haven’t been seen before, and substitution of indexes for values that are already present in the static or dynamic tables on each side.
The definitions of the request and response header fields in HTTP/2 remain unchanged, with a few minor exceptions: all header field names are lowercase, and the request line is now split into individual :method, :scheme, :authority, and :path pseudo-header fields.
The switch to HTTP/2 cannot happen overnight: millions of servers must be updated to use the new binary framing, and billions of clients must similarly update their networking libraries, browsers, and other applications.
The good news is, all modern browsers have committed to supporting HTTP/2, and most modern browsers use efficient background update mechanisms, which have already enabled HTTP/2 support with minimal intervention for a large proportion of existing users. That said, some users will be stuck on legacy browsers, and servers and intermediaries will also have to be updated to support HTTP/2, which is a much longer (and labor- and capital-intensive) process.
HTTP/1.x will be around for at least another decade, and most servers and clients will have to support both HTTP/1.x and HTTP/2 standards. As a result, an HTTP/2 client and server must be able to discover and negotiate which protocol will be used prior to exchanging application data. To address this, the HTTP/2 protocol defines the following mechanisms:
The HTTP/2 standard does not require use of TLS, but in practice it is the most reliable way to deploy a new protocol in the presence of large number of existing intermediaries; see Proxies, Intermediaries, TLS, and New Protocols on the Web. As a result, the use of TLS and ALPN is the recommended mechanism to deploy and negotiate HTTP/2: the client and server negotiate the desired protocol as part of the TLS handshake without adding any extra latency or roundtrips; see TLS Handshake and Application Layer Protocol Negotiation (ALPN). Further, as an additional constraint, while all popular browsers have committed to supporting HTTP/2 over TLS, some have also indicated that they will only enable HTTP/2 over TLS—e.g., Firefox and Google Chrome. As a result, TLS with ALPN negotiation is a de facto requirement for enabling HTTP/2 in the browser.
Establishing an HTTP/2 connection over a regular, non-encrypted channel is still possible, albeit perhaps not with a popular browser, and with some additional complexity. Because both HTTP/1.x and HTTP/2 run on the same port (80), in absence of any other information about server support for HTTP/2, the client has to use the HTTP Upgrade mechanism to negotiate the appropriate protocol:
GET /page HTTP/1.1 Host: server.example.com Connection: Upgrade, HTTP2-Settings Upgrade: h2c
Using the preceding Upgrade flow, if the server does not support HTTP/2, then it can immediately respond to the request with HTTP/1.1 response. Alternatively, it can confirm the HTTP/2 upgrade by returning the 101 Switching Protocols response in HTTP/1.1 format and then immediately switch to HTTP/2 and return the response using the new binary framing protocol. In either case, no extra roundtrips are incurred.
Finally, if the client chooses to, it may also remember or obtain the information about HTTP/2 support through some other means—e.g., DNS record, manual configuration, and so on—instead of having to rely on the Upgrade workflow. Armed with this knowledge, it may choose to send HTTP/2 frames right from the start, over an unencrypted channel, and hope for the best. In the worst case, the connection will fail, and the client will fall back to Upgrade workflow or switch to a TLS tunnel with ALPN negotiation.
Secure communication between client and server, server to server, and all other permutations, is a security best practice: all in-transit data should be encrypted, authenticated, and checked against tampering. In short, use TLS with ALPN negotiation to deploy HTTP/2.
At the core of all HTTP/2 improvements is the new binary, length-prefixed framing layer. Compared with the newline-delimited plaintext HTTP/1.x protocol, binary framing offers more compact representation that is both more efficient to process and easier to implement correctly.
Once an HTTP/2 connection is established, the client and server communicate by exchanging frames, which serve as the smallest unit of communication within the protocol. All frames share a common 9-byte header (Figure 12-7), which contains the length of the frame, its type, a bit field for flags, and a 31-bit stream identifier.
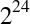 bytes of data.
bytes of data.
Technically, the length field allows payloads of up to 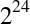 bytes (~16MB) per frame. However, the HTTP/2 standard sets the default maximum payload size of
bytes (~16MB) per frame. However, the HTTP/2 standard sets the default maximum payload size of DATA frames to 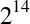 bytes (~16KB) per frame and allows the client and server to negotiate the higher value. Bigger is not always better: smaller frame size enables efficient multiplexing and minimizes head-of-line blocking.
bytes (~16KB) per frame and allows the client and server to negotiate the higher value. Bigger is not always better: smaller frame size enables efficient multiplexing and minimizes head-of-line blocking.
Given this knowledge of the shared HTTP/2 frame header, we can now write a simple parser that can examine any HTTP/2 bytestream and identify different frame types, report their flags, and report the length of each by examining the first nine bytes of every frame. Further, because each frame is length-prefixed, the parser can skip ahead to the beginning of the next frame both quickly and efficiently—a big performance improvement over HTTP/1.x.
Once the frame type is known, the remainder of the frame can be interpreted by the parser. The HTTP/2 standard defines the following types:
|
|
Used to transport HTTP message bodies |
|
|
Used to communicate header fields for a stream |
|
|
Used to communicate sender-advised priority of a stream |
|
|
Used to signal termination of a stream |
|
|
Used to communicate configuration parameters for the connection |
|
|
Used to signal a promise to serve the referenced resource |
|
|
Used to measure the roundtrip time and perform “liveness” checks |
|
|
Used to inform the peer to stop creating streams for current connection |
WINDOW_UPDATE
CONTINUATION
You will need some tooling to inspect the low-level HTTP/2 frame exchange. Your favorite hex viewer is, of course, an option. Or, for a more human-friendly representation, you can use a tool like Wireshark, which understands the HTTP/2 protocol and can capture, decode, and analyze the exchange.
The good news is that the exact semantics of the preceding taxonomy of frames is mostly only relevant to server and client implementers, who will need to worry about the semantics of flow control, error handling, connection termination, and other details. The application layer features and semantics of the HTTP protocol remain unchanged: the client and server take care of the framing, multiplexing, and other details, while the application can enjoy the benefits of faster and more efficient delivery.
Having said that, even though the framing layer is hidden from our applications, it is useful for us to go just one step further and look at the two most common workflows: initiating a new stream and exchanging application data. Having an intuition for how a request, or a response, is translated into individual frames will give you the necessary knowledge to debug and optimize your HTTP/2 deployments. Let’s dig a little deeper.
Before any application data can be sent, a new stream must be created and the appropriate request metadata must be sent: optional stream dependency and weight, optional flags, and the HPACK-encoded HTTP request headers describing the request. The client initiates this process by sending a HEADERS frame (Figure 12-8) with all of the above.
Wireshark decodes and displays the frame fields in the same order as encoded on the wire—e.g., compare the fields in the common frame header to the frame layout in Figure 12-7.
The HEADERS frame is used to declare and communicate metadata about the new request. The application payload, if available, is delivered independently within the DATA frames. This separation allows the protocol to separate processing of “control traffic” from delivery of application data—e.g., flow control is applied only to DATA frames, and non-DATA frames are always processed with high priority.
Once a new stream is created, and the HTTP headers are sent, DATA frames (Figure 12-9) are used to send the application payload if one is present. The payload can be split between multiple DATA frames, with the last frame indicating the end of the message by toggling the END_STREAM flag in the header of the frame.
The “End Stream” flag is set to “false” in Figure 12-9, indicating that the client has not finished transmitting the application payload; more DATA frames are coming.
Aside from the length and flags fields, there really isn’t much more to say about the DATA frame. The application payload may be split between multiple DATA frames to enable efficient multiplexing, but otherwise it is delivered exactly as provided by the application—i.e., the choice of the encoding mechanism (plain text, gzip, or other encoding formats) is deferred to the application.
Armed with knowledge of the different frame types, we can now revisit the diagram (Figure 12-10) we encountered earlier in Request and Response Multiplexing and analyze the HTTP/2 exchange:
DATA frames for stream 1, which carry the application response to the client’s earlier request.
HEADERS and DATA frames for stream 3 between the DATA frames for stream 1—response multiplexing in action!
DATA frame for stream 5, which indicates that a HEADERS frame was transferred earlier.
The above analysis is, of course, based on a simplified representation of an actual HTTP/2 exchange, but it still illustrates many of the strengths and features of the new protocol. By this point, you should have the necessary knowledge to successfully record and analyze a real-world HTTP/2 trace—give it a try!
High-performance browser networking relies on a host of networking technologies (Figure 13-1), and the overall performance of our applications is the sum total of each of their parts.
We cannot control the network weather between the client and server, nor the client hardware or the configuration of their device, but the rest is in our hands: TCP and TLS optimizations on the server, and dozens of application optimizations to account for the peculiarities of the different physical layers, versions of HTTP protocol in use, as well as general application best practices. Granted, getting it all right is not an easy task, but it is a rewarding one! Let’s pull it all together.
The physical properties of the communication channel set hard performance limits on every application: speed of light and distance between client and server dictate the propagation latency, and the choice of medium (wired vs. wireless) determines the processing, transmission, queuing, and other delays incurred by each data packet. In fact, the performance of most web applications is limited by latency, not bandwidth, and while bandwidth speeds will continue to increase, unfortunately the same can’t be said for latency:
As a result, while we cannot make the bits travel any faster, it is crucial that we apply all the possible optimizations at the transport and application layers to eliminate unnecessary roundtrips, requests, and minimize the distance traveled by each packet—i.e., position the servers closer to the client.
Every application can benefit from optimizing for the unique properties of the physical layer in wireless networks, where latencies are high, and bandwidth is always at a premium. At the API layer, the differences between the wired and wireless networks are entirely transparent, but ignoring them is a recipe for poor performance. Simple optimizations in how and when we schedule resource downloads, beacons, and the rest can translate to significant impact on the experienced latency, battery life, and overall user experience of our applications:
Moving up the stack from the physical layer, we must ensure that each and every server is configured to use the latest TCP and TLS best practices. Optimizing the underlying protocols ensures that each client can get the best performance—high throughput and low latency—when communicating with the server:
Finally, we arrive at the application layer. By all accounts and measures, HTTP is an incredibly successful protocol. After all, it is the common language between billions of clients and servers, enabling the modern Web. However, it is also an imperfect protocol, which means that we must take special care in how we architect our applications:
The secret to a successful web performance strategy is simple: invest into monitoring and measurement tools to identify problems and regressions (see Synthetic and Real-User Performance Measurement), link business goals to performance metrics, and optimize from there—i.e., treat performance as a feature.
Regardless of the type of network or the type or version of the networking protocols in use, all applications should always seek to eliminate or reduce unnecessary network latency and minimize the number of transferred bytes. These two simple rules are the foundation for all of the evergreen performance best practices:
By this point, all of these recommendations should require no explanation: latency is the bottleneck, and the fastest byte is a byte not sent. However, HTTP provides some additional mechanisms, such as caching and compression, as well as its set of version-specific performance quirks:
Each of these warrants closer examination. Let’s dive in.
The fastest network request is a request not made. Maintaining a cache of previously downloaded data allows the client to use a local copy of the resource, thereby eliminating the request. For resources delivered over HTTP, make sure the appropriate cache headers are in place:
Whenever possible, you should specify an explicit cache lifetime for each resource, which allows the client to use a local copy, instead of re-requesting the same object all the time. Similarly, specify a validation mechanism to allow the client to check if the expired resource has been updated: if the resource has not changed, we can eliminate the data transfer.
Finally, note that you need to specify both the cache lifetime and the validation method! A common mistake is to provide only one of the two, which results in either redundant transfers of resources that have not changed (i.e., missing validation), or redundant validation checks each time the resource is used (i.e., missing or unnecessarily short cache lifetime).
For hands-on advice on optimizing your caching strategy, see the “HTTP caching” section on Google’s Web Fundamentals.
Leveraging a local cache allows the client to avoid fetching duplicate content on each request. However, if and when the resource must be fetched, either because it has expired, it is new, or it cannot be cached, then it should be transferred with the minimum number of bytes. Always apply the best compression method for each asset.
The size of text-based assets, such as HTML, CSS, and JavaScript, can be reduced by 60%–80% on average when compressed with Gzip. Images, on the other hand, require more nuanced consideration:
Images account for over half of the transferred bytes of an average page, which makes them a high-value optimization target: the simple choice of an optimal image format can yield dramatically improved compression ratios; lossy compression methods can reduce transfer sizes by orders of magnitude; sizing the image to its display width will reduce both the transfer and memory footprints (see Calculating Image Memory Requirements) on the client. Invest into tools and automation to optimize image delivery on your site.
For hands-on advice on reducing the transfer size of text, image, webfont, and other resources, see the “Optimizing Content Efficiency” section on Google’s Web Fundamentals.
HTTP is a stateless protocol, which means that the server is not required to retain any information about the client between different requests. However, many applications require state for session management, personalization, analytics, and more. To enable this functionality, the HTTP State Management Mechanism (RFC 2965) extension allows any website to associate and update “cookie” metadata for its origin: the provided data is saved by the browser and is then automatically appended onto every request to the origin within the Cookie header.
The standard does not specify a maximum limit on the size of a cookie, but in practice most browsers enforce a 4 KB limit. However, the standard also allows the site to associate many cookies per origin. As a result, it is possible to associate tens to hundreds of kilobytes of arbitrary metadata, split across multiple cookies, for each origin!
Needless to say, this can have significant performance implications for your application. Associated cookie data is automatically sent by the browser on each request, which, in the worst case can add entire roundtrips of network latency by exceeding the initial TCP congestion window, regardless of whether HTTP/1.x or HTTP/2 is used:
Cookie size should be monitored judiciously: transfer the minimum amount of required data, such as a secure session token, and leverage a shared session cache on the server to look up other metadata. And even better, eliminate cookies entirely wherever possible—chances are, you do not need client-specific metadata when requesting static assets, such as images, scripts, and stylesheets.
To achieve the fastest response times within your application, all resource requests should be dispatched as soon as possible. However, another important point to consider is how these requests will be processed on the server. After all, if all of our requests are then serially queued by the server, then we are once again incurring unnecessary latency. Here’s how to get the best performance:
Without connection keepalive, a new TCP connection is required for each HTTP request, which incurs significant overhead due to the TCP handshake and slow-start. Make sure to identify and optimize your server and proxy connection timeouts to avoid closing the connection prematurely. With that in place, and to get the best performance, use HTTP/2 to allow the client and server to reuse the same connection for all requests. If HTTP/2 is not an option, use multiple TCP connections to achieve request parallelism with HTTP/1.x.
Identifying the sources of unnecessary client and server latency is both an art and science: examine the client resource waterfall (see Analyzing the Resource Waterfall), as well as your server logs. Common pitfalls often include the following:
The order in which we optimize HTTP/1.x deployments is important: configure servers to deliver the best possible TCP and TLS performance, and then carefully review and apply mobile and evergreen application best practices: measure, iterate.
With the evergreen optimizations in place, and with good performance instrumentation within the application, evaluate whether the application can benefit from applying HTTP/1.x specific optimizations (read, protocol workarounds):
Pipelining has limited support, and each of the remaining optimizations comes with its set of benefits and trade-offs. In fact, it is often overlooked that each of these techniques can hurt performance when applied aggressively, or incorrectly; review Chapter 11 for an in-depth discussion.
HTTP/2 eliminates the need for all of the above HTTP/1.x workarounds, making our applications both simpler and more performant. Which is to say, the best optimization for HTTP/1.x is to deploy HTTP/2.
HTTP/2 enables more efficient use of network resources and reduced latency by enabling request and response multiplexing, header compression, prioritization, and more—see Design and Technical Goals. Getting the best performance out of HTTP/2, especially in light of the one-connection-per-origin model, requires a well-tuned server network stack. Review Optimizing for TCP and Optimizing for TLS for an in-depth discussion and optimization checklists.
Next up—surprise—apply the evergreen application best practices: send fewer bytes, eliminate requests, and adapt resource scheduling for wireless networks. Reducing the amount of data transferred and eliminating unnecessary network latency are the best optimizations for any application, web or native, regardless of the version or type of the application and transport protocols in use.
Finally, undo and unlearn the bad habits of domain sharding, concatenation, and image spriting. With HTTP/2 we are no longer constrained by limited parallelism: requests are cheap, and both requests and responses can be multiplexed efficiently. These workarounds are no longer necessary and omitting them can improve performance.
HTTP/2 achieves the best performance by multiplexing requests over the same TCP connection, which enables effective request and response prioritization, flow control, and header compression. As a result, the optimal number of connections is exactly one and domain sharding is an anti-pattern.
HTTP/2 also provides a TLS connection-coalescing mechanism that allows the client to coalesce requests from different origins and dispatch them over the same connection when the following conditions are satisfied:
For example, if example.com provides a wildcard TLS certificate that is valid for all of its subdomains (i.e., *.example.com) and references an asset on static.example.com that resolves to the same server IP address as example.com, then the HTTP/2 client is allowed to reuse the same TCP connection to fetch resources from example.com and static.example.com.
An interesting side effect of HTTP/2 connection coalescing is that it enables an HTTP/1.x friendly deployment model: some assets can be served from alternate origins, which enables higher parallelism for HTTP/1 clients, and if those same origins satisfy the above criteria then the HTTP/2 clients can coalesce requests and reuse the same connection. Alternatively, the application can be more hands-on and inspect the negotiated protocol and deliver alternate resources for each client: with sharded asset references for HTTP/1.x clients and with same-origin asset references for HTTP/2 clients.
Depending on the architecture of your application you may be able to rely on connection coalescing, you may need to serve alternate markup, or you may use both techniques as necessary to provide the optimal HTTP/1.x and HTTP/2 experience. Alternatively, you might consider focusing on optimizing HTTP/2 performance only; the client adoption is growing rapidly, and the extra complexity of optimizing for both protocols may be unnecessary.
Due to third-party dependencies it may not be possible to fetch all the resources via the same TCP connection—that’s OK. Seek to minimize the number of origins regardless of the protocol and eliminate sharding when HTTP/2 is in use to get the best performance.
Bundling multiple assets into a single response was a critical optimization for HTTP/1.x where limited parallelism and high protocol overhead typically outweighed all other concerns—see Concatenation and Spriting. However, with HTTP/2, multiplexing is no longer an issue, and header compression dramatically reduces the metadata overhead of each HTTP request. As a result, we need to reconsider the use of concatenation and spriting in light of its new pros and cons:
In practice, while HTTP/1.x provides the mechanisms for granular cache management of each resource, the limited parallelism forced us to bundle resources together. The latency penalty of delayed fetches outweighed the costs of decreased effectiveness of caching, more frequent and more expensive invalidations, and delayed execution.
HTTP/2 removes this unfortunate trade-off by providing support for request and response multiplexing, which means that we can now optimize our applications by delivering more granular resources: each resource can have an optimized caching policy (expiry time and revalidation token) and be individually updated without invalidating other resources in the bundle. In short, HTTP/2 enables our applications to make better use of the HTTP cache.
That said, HTTP/2 does not eliminate the utility of concatenation and spriting entirely. A few additional considerations to keep in mind:
There is no single optimal strategy for all applications: delivering a single large bundle is unlikely to yield best results, and issuing hundreds of requests for small resources may not be the optimal strategy either. The right trade-off will depend on the type of content, frequency of updates, access patterns, and other criteria. To get the best results, gather measurement data for your own application and optimize accordingly.
Server push is a powerful new feature of HTTP/2 that enables the server to send multiple responses for a single client request. That said, recall that the use of resource inlining (e.g., embedding an image into an HTML document via a data URI) is, in fact, a form of application-layer server push. As such, while this is not an entirely new capability for web developers, the use of HTTP/2 server push offers many performance benefits over inlining: pushed resources can be cached individually, reused across pages, canceled by the client, and more—see Server Push.
With HTTP/2 there is no longer a reason to inline resources just because they are small; we’re no longer constrained by the lack of parallelism and request overhead is very low. As a result, server push acts as a latency optimization that removes a full request-response roundtrip between the client and server—e.g., if, after sending a particular response, we know that the client will always come back and request a specific subresource, we can eliminate the roundtrip by pushing the subresource to the client.
If the client does not support, or disables the use of server push, it will initiate the request for the same resource on its own—i.e., server push is a safe and transparent latency optimization.
Critical resources that block page construction and rendering (see DOM, CSSOM, and JavaScript) are prime candidates for the use of server push, as they are often known or can be specified upfront. Eliminating a full roundtrip from the critical path can yield savings of tens to hundreds of milliseconds, especially for users on mobile networks where latencies are often both high and highly variable.
Note that even the most naive server push strategy that opts to push assets regardless of their caching policy is, in effect, equivalent to inlining: the resource is duplicated on each page and transferred each time the parent resource is requested. However, even there, server push offers important performance benefits: the pushed response can be prioritized more effectively, it affords more control to the client, and it provides an upgrade path towards implementing much smarter strategies that leverage caching and other mechanisms that can eliminate redundant transfers. In short, if your application is using inlining, then you should consider replacing it with server push.
A naive implementation of an HTTP/2 server, or proxy, may “speak” the protocol, but without well implemented support for features such as flow control and request prioritization, it can easily yield less that optimal performance. For example, it might saturate the user’s bandwidth by sending large low priority resources (such as images), while the browser is blocked from rendering the page until it receives higher priority resources (such as HTML, CSS, or JavaScript).
With HTTP/2 the client places a lot of trust on the server. To get the best performance, an HTTP/2 client has to be “optimistic”: it annotates requests with priority information (see Stream Prioritization) and dispatches them to the server as soon as possible; it relies on the server to use the communicated dependencies and weights to optimize delivery of each response. A well-optimized HTTP server has always been important, but with HTTP/2 the server takes on additional and critical responsibilities that, previously, were out of scope.
Do your due diligence when testing and deploying your HTTP/2 infrastructure. Common benchmarks measuring server throughput and requests per second do not capture these new requirements and may not be representative of the actual experience as seen by your users when loading your application.
A modern browser is a platform specifically designed for fast, efficient, and secure delivery of web applications. In fact, under the hood, a modern browser is an entire operating system with hundreds of components: process management, security sandboxes, layers of optimization caches, JavaScript VMs, graphics rendering and GPU pipelines, storage, sensors, audio and video, networking, and much more.
Not surprisingly, the overall performance of the browser, and any application that it runs, is determined by a number of components: parsing, layout, style calculation of HTML and CSS, JavaScript execution speed, rendering pipelines, and of course the networking stack. Each component plays a critical role, but networking often doubly so, since if the browser is blocked on the network, waiting for the resources to arrive, then all other steps are blocked!
As a result, it is not surprising to discover that the networking stack of a modern browser is much more than a simple socket manager. From the outside, it may present itself as a simple resource-fetching mechanism, but from the inside it is its own platform (Figure 14-1), with its own optimization criteria, APIs, and services.
When designing a web application, we don’t have to worry about the individual TCP or UDP sockets; the browser manages that for us. Further, the network stack takes care of imposing the right connection limits, formatting our requests, sandboxing individual applications from one another, dealing with proxies, caching, and much more. In turn, with all of this complexity removed, our applications can focus on the application logic.
However, out of sight does not mean out of mind! As we saw, understanding the performance characteristics of TCP, HTTP, and mobile networks can help us build faster applications. Similarly, understanding how to optimize for the various browser networking APIs, protocols, and services can make a dramatic difference in performance of any application.
Web applications running in the browser do not manage the lifecycle of individual network sockets, and that’s a good thing. By deferring this work to the browser, we allow it to automate a number of critical performance optimizations, such as socket reuse, request prioritization and late binding, protocol negotiation, enforcing connection limits, and much more. In fact, the browser intentionally separates the request management lifecycle from socket management. This is a subtle but critical distinction.
Sockets are organized in pools (Figure 14-2), which are grouped by origin, and each pool enforces its own connection limits and security constraints. Pending requests are queued, prioritized, and then bound to individual sockets in the pool. Consequently, unless the server intentionally closes the connection, the same socket can be automatically reused across multiple requests!
Automatic socket pooling automates TCP connection reuse, which offers significant performance benefits; see Benefits of Keepalive Connections. However, that’s not all. This architecture also enables a number of additional optimization opportunities:
In short, the browser networking stack is our strategic ally on our quest to deliver high-performance applications. None of the functionality we have covered requires any work on our behalf! However, that’s not to say that we can’t help the browser. Design decisions in our applications that determine the network communication patterns, type and frequency of transfers, choice of protocols, and tuning and optimization of our server stacks play critical roles in the end performance of every application.
Deferring management of individual sockets serves another important purpose: it allows the browser to sandbox and enforce a consistent set of security and policy constraints on untrusted application code. For example, the browser does not permit direct API access to raw network sockets, as that would allow a malicious application to initiate arbitrary connections to any host—e.g., run a port scan, connect to a mail server and start sending unintended messages, and so on.
The previous list is not complete, but it highlights the principle of “least privilege” at work. The browser exposes only the APIs and resources that are necessary for the application code: the application supplies the data and URL, and the browser formats the request and handles the full lifecycle of each connection.
It is worth noting that there is no single “same-origin policy.” Instead, there is a set of related mechanisms that enforce restrictions on DOM access, cookie and session state management, networking, and other components of the browser.
A full discussion on browser security requires its own separate book. If you are curious, Michal Zalewski’s The Tangled Web: A Guide to Securing Modern Web Applications is a fantastic resource.
The best and fastest request is a request not made. Prior to dispatching a request, the browser automatically checks its resource cache, performs the necessary validation checks, and returns a local copy of the resources if the specified constraints are satisfied. Similarly, if a local resource is not available in cache, then a network request is made and the response is automatically placed in cache for subsequent access if permitted.
Managing an efficient and optimized resource cache is hard. Thankfully, the browser takes care of all of the complexity on our behalf, and all we need to do is ensure that our servers are returning the appropriate cache directives; see Cache Resources on the Client. You are providing Cache-Control, ETag, and Last-Modified response headers for all the resources on your pages, right?
Finally, an often-overlooked but critical function of the browser is to provide authentication, session, and cookie management. The browser maintains separate “cookie jars” for each origin, provides necessary application and server APIs to read and write new cookie, session, and authentication data and automatically appends and processes appropriate HTTP headers to automate the entire process on our behalf.
Walking up the ladder of provided network services we finally arrive at the application APIs and protocols. As we saw, the lower layers provide a wide array of critical services: socket and connection management, request and response processing, enforcement of various security policies, caching, and much more. Every time we initiate an HTTP or an XMLHttpRequest, a long-lived Server-Sent Events or WebSocket session, or open a WebRTC connection, we are interacting with some or all of these underlying services.
There is no one best protocol or API. Every nontrivial application will require a mix of different transports based on a variety of requirements: interaction with the browser cache, protocol overhead, message latency, reliability, type of data transfer, and more. Some protocols may offer low-latency delivery (e.g., Server-Sent Events, WebSocket), but may not meet other critical criteria, such as the ability to leverage the browser cache or support efficient binary transfers in all cases.
| XMLHttpRequest | Server-Sent Events | WebSocket | |
Request streaming | no | no | yes |
Response streaming | limited | yes | yes |
Framing mechanism | HTTP | event stream | binary framing |
Binary data transfers | yes | no (base64) | yes |
Compression | yes | yes | limited |
Application transport protocol | HTTP | HTTP | WebSocket |
Network transport protocol | TCP | TCP | TCP |
We are intentionally omitting WebRTC from this comparison, as its peer-to-peer delivery model offers a significant departure from XHR, SSE, and WebSocket protocols.
This comparison of high-level features is incomplete—that’s the subject of the following chapters—but serves as a good illustration of the many differences among each protocol. Understanding the pros, cons, and trade-offs of each, and matching them to the requirements of our applications, can make all the difference between a high-performance application and a consistently poor experience for the user.
XMLHttpRequest (XHR) is a browser-level API that enables the client to script data transfers via JavaScript. XHR made its first debut in Internet Explorer 5, became one of the key technologies behind the Asynchronous JavaScript and XML (AJAX) revolution, and is now a fundamental building block of nearly every modern web application.
XMLHTTP changed everything. It put the “D” in DHTML. It allowed us to asynchronously get data from the server and preserve document state on the client… The Outlook Web Access (OWA) team’s desire to build a rich Win32 like application in a browser pushed the technology into IE that allowed AJAX to become a reality.
— Jim Van Eaton Outlook Web Access: A catalyst for web evolution
Prior to XHR, the web page had to be refreshed to send or fetch any state updates between the client and server. With XHR, this workflow could be done asynchronously and under full control of the application JavaScript code. XHR is what enabled us to make the leap from building pages to building interactive web applications in the browser.
However, the power of XHR is not only that it enabled asynchronous communication within the browser, but also that it made it simple. XHR is an application API provided by the browser, which is to say that the browser automatically takes care of all the low-level connection management, protocol negotiation, formatting of HTTP requests, and much more:
Free from worrying about all the low-level details, our applications can focus on the business logic of initiating requests, managing their progress, and processing returned data from the server. The combination of a simple API and its ubiquitous availability across all the browsers makes XHR the “Swiss Army knife” of networking in the browser.
As a result, nearly every networking use case (scripted downloads, uploads, streaming, and even real-time notifications) can and have been built on top of XHR. Of course, this doesn’t mean that XHR is the most efficient transport in each case—in fact, as we will see, far from it—but it is nonetheless often used as a fallback transport for older clients, which may not have access to newer browser networking APIs. With that in mind, let’s take a closer look at the latest capabilities of XHR, its use cases, and performance do’s and don’ts.
An exhaustive analysis of the full XHR API and its capabilities is outside the scope of our discussion—our focus is on performance! Refer to the official W3C standard for an overview of the XMLHttpRequest API.
Despite its name, XHR was never intended to be tied to XML specifically. The XML prefix is a vestige of a decision to ship the first version of what became known as XHR as part of the MSXML library in Internet Explorer 5:
This was the good-old-days when critical features were crammed in just days before a release…I realized that the MSXML library shipped with IE and I had some good contacts over in the XML team who would probably help out—I got in touch with Jean Paoli who was running that team at the time and we pretty quickly struck a deal to ship the thing as part of the MSXML library. Which is the real explanation of where the name XMLHTTP comes from—the thing is mostly about HTTP and doesn’t have any specific tie to XML other than that was the easiest excuse for shipping it so I needed to cram XML into the name.
— Alex Hopmann The story of XMLHTTP
Mozilla modeled its own implementation of XHR against Microsoft’s and exposed it via the XMLHttpRequest interface. Safari, Opera, and other browsers followed, and XHR became a de facto standard in all major browsers—hence the name and why it stuck. In fact, the official W3C Working Draft specification for XHR was only published in 2006, well after XHR came into widespread use!
However, despite its popularity and key role in the AJAX revolution, the early versions of XHR provided limited capabilities: text-based-only data transfers, restricted support for handling uploads, and inability to handle cross-domain requests. To address these shortcomings, the “XMLHttpRequest Level 2” draft was published in 2008, which added a number of new features:
In 2011, “XMLHttpRequest Level 2” specification was merged with the original XMLHttpRequest working draft. Hence, while you will often find references to XHR version or level 1 and 2, these distinctions are no longer relevant; today, there is only one, unified XHR specification. In fact, all the new XHR2 features and capabilities are offered via the same XMLHttpRequest API: same interface, more features.
New XHR2 features are now supported by all the modern browsers; see caniuse.com/xhr2. Hence, whenever we refer to XHR, we are implicitly referring to the XHR2 standard.
XHR is a browser-level API that automatically handles myriad low-level details such as caching, handling redirects, content negotiation, authentication, and much more. This serves a dual purpose. First, it makes the application APIs much easier to work with, allowing us to focus on the business logic. But, second, it allows the browser to sandbox and enforce a set of security and policy constraints on the application code.
The XHR interface enforces strict HTTP semantics on each request: the application supplies the data and URL, and the browser formats the request and handles the full lifecycle of each connection. Similarly, while the XHR API allows the application to add custom HTTP headers (via the setRequestHeader() method), there are a number of protected headers that are off-limits to application code:
The browser will refuse to override any of the unsafe headers, which guarantees that the application cannot impersonate a fake user-agent, user, or the origin from where the request is being made. In fact, protecting the origin header is especially important, as it is the key piece of the “same-origin policy” applied to all XHR requests.
An “origin” is defined as a triple of application protocol, domain name, and port number—e.g., (http, example.com, 80) and (https, example.com, 443) are considered as different origins. For more details see The Web Origin Concept.
The motivation for the same-origin policy is simple: the browser stores user data, such as authentication tokens, cookies, and other private metadata, which cannot be leaked across different applications—e.g., without the same origin sandbox an arbitrary script on example.com could access and manipulate users’ data on thirdparty.com!
To address this specific problem, early versions of XHR were restricted to same-origin requests only, where the requesting origin had to match the origin of the requested resource: an XHR initiated from example.com could request another resource only from the same example.com origin. Alternatively, if the same origin precondition failed, then the browser would simply refuse to initiate the XHR request and raise an error.
However, while necessary, the same-origin policy also places severe restrictions on the usefulness of XHR: what if the server wants to offer a resource to a script running in a different origin? That’s where “Cross-Origin Resource Sharing” (CORS) comes in! CORS provides a secure opt-in mechanism for client-side cross-origin requests:
// script origin: (http, example.com, 80)
var xhr = new XMLHttpRequest();
xhr.open('GET', '/resource.js');
xhr.onload = function() { ... };
xhr.send();
var cors_xhr = new XMLHttpRequest();
cors_xhr.open('GET', 'http://thirdparty.com/resource.js');
cors_xhr.onload = function() { ... };
cors_xhr.send();
CORS requests use the same XHR API, with the only difference that the URL to the requested resource is associated with a different origin from where the script is being executed: in the previous example, the script is executed from (http, example.com, 80), and the second XHR request is accessing resource.js from (http, thirdparty.com, 80).
The opt-in authentication mechanism for the CORS request is handled at a lower layer: when the request is made, the browser automatically appends the protected Origin HTTP header, which advertises the origin from where the request is being made. In turn, the remote server is then able to examine the Origin header and decide if it should allow the request by returning an Access-Control-Allow-Origin header in its response:
=> Request GET /resource.js HTTP/1.1 Host: thirdparty.com Origin: http://example.com
In the preceding example, thirdparty.com decided to opt into cross-origin resource sharing with example.com by returning an appropriate access control header in its response. Alternatively, if it wanted to disallow access, it could simply omit the Access-Control-Allow-Origin header, and the client’s browser would automatically fail the sent request.
If the third-party server is not CORS aware, then the client request will fail, as the client always verifies the presence of the opt-in header. As a special case, CORS also allows the server to return a wildcard (Access-Control-Allow-Origin: *) to indicate that it allows access from any origin. However, think twice before enabling this policy!
With that, we are all done, right? Turns out, not quite, as CORS takes a number of additional security precautions to ensure that the server is CORS aware:
To enable cookies and HTTP authentication, the client must set an extra property (withCredentials) on the XHR object when making the request, and the server must also respond with an appropriate header (Access-Control-Allow-Credentials) to indicate that it is knowingly allowing the application to include private user data. Similarly, if the client needs to write or read custom HTTP headers or wants to use a “non-simple method” for the request, then it must first ask for permission from the third-party server by issuing a preflight request:
=> Preflight request OPTIONS /resource.js HTTP/1.1
The official W3C CORS specification defines when and where a preflight request must be used: “simple” requests can skip it, but there are a variety of conditions that will trigger it and add a minimum of a full roundtrip of network latency to verify permissions. The good news is, once a preflight request is made, it can be cached by the client to avoid the same verification on each request.
CORS is supported by all modern browsers; see caniuse.com/cors. For a deep dive on various CORS policies and implementation refer to the official W3C standard.
XHR can transfer both text-based and binary data. In fact, the browser offers automatic encoding and decoding for a variety of native data types, which allows the application to pass these types directly to XHR to be properly encoded, and vice versa, for the types to be automatically decoded by the browser:
ArrayBuffer
Blob
Document
JSON
Text
Either the browser can rely on the HTTP content-type negotiation to infer the appropriate data type (e.g., decode an application/json response into a JSON object), or the application can explicitly override the data type when initiating the XHR request:
var xhr = new XMLHttpRequest();
xhr.open('GET', '/images/photo.webp');
xhr.responseType = 'blob';
xhr.onload = function() {
if (this.status == 200) {
var img = document.createElement('img');
img.src = window.URL.createObjectURL(this.response);
img.onload = function() {
window.URL.revokeObjectURL(this.src);
}
document.body.appendChild(img);
}
};
xhr.send();
Note that we are transferring an image asset in its native format, without relying on base64 encoding, and adding an image element to the page without relying on data URIs. There is no network transmission overhead or encoding overhead when handling the received binary data in JavaScript! XHR API allows us to script efficient, dynamic applications, regardless of the data type, right from JavaScript.
The blob interface is part of the HTML5 File API and acts as an opaque reference for an arbitrary chunk of data (binary or text). By itself, a blob reference has limited functionality: you can query its size, MIME type, and split it into smaller blobs. However, its real role is to serve as an efficient interchange mechanism between various JavaScript APIs.
Uploading data via XHR is just as simple and efficient for all data types. In fact, the code is effectively the same, with the only difference that we also pass in a data object when calling send() on the XHR request. The rest is handled by the browser:
var xhr = new XMLHttpRequest();
xhr.open('POST','/upload');
xhr.onload = function() { ... };
xhr.send("text string");
var formData = new FormData();
formData.append('id', 123456);
formData.append('topic', 'performance');
var xhr = new XMLHttpRequest();
xhr.open('POST', '/upload');
xhr.onload = function() { ... };
xhr.send(formData);
var xhr = new XMLHttpRequest();
xhr.open('POST', '/upload');
xhr.onload = function() { ... };
var uInt8Array = new Uint8Array([1, 2, 3]);
xhr.send(uInt8Array.buffer);
The XHR send() method accepts one of DOMString, Document, FormData, Blob, File, or ArrayBuffer objects, automatically performs the appropriate encoding, sets the appropriate HTTP content-type, and dispatches the request. Need to send a binary blob or upload a file provided by the user? Simple: grab a reference to the object and pass it to XHR. In fact, with a little extra work, we can also split a large file into smaller chunks:
var blob = ...;
XHR does not support request streaming, which means that we must provide the full payload when calling send(). However, this example illustrates a simple application workaround: the file is split and uploaded in chunks via multiple XHR requests. This implementation pattern is by no means a replacement for a true request streaming API, but it is nonetheless a viable solution for some applications.
Network connectivity can be intermittent, and latency and bandwidth are highly variable. So how do we know if an XHR request has succeeded, timed out, or failed? The XHR object provides a convenient API for listening to progress events (Table 15-1), which indicate the current status of the request.
| Event type | Description | Times fired |
loadstart | Transfer has begun | once |
progress | Transfer is in progress | zero or more |
error | Transfer has failed | zero or once |
abort | Transfer is terminated | zero or once |
load | Transfer is successful | zero or once |
loadend | Transfer has finished | once |
Each XHR transfer begins with a loadstart and finishes with a loadend event, and in between, one or more additional events are fired to indicate the status of the transfer. Hence, to monitor progress the application can register a set of JavaScript event listeners on the XHR object:
var xhr = new XMLHttpRequest();
xhr.open('GET','/resource');
xhr.timeout = 5000;
xhr.addEventListener('load', function() { ... });
xhr.addEventListener('error', function() { ... });
var onProgressHandler = function(event) {
if(event.lengthComputable) {
var progress = (event.loaded / event.total) * 100;
...
}
}
xhr.upload.addEventListener('progress', onProgressHandler);
xhr.addEventListener('progress', onProgressHandler);
xhr.send();
Either the load or error event will fire once to indicate the final status of the XHR transfer, whereas the progress event can fire any number of times and provides a convenient API for tracking transfer status: we can compare the loaded attribute against total to estimate the amount of transferred data.
To estimate the amount of transferred data, the server must provide a content length in its response: we can’t estimate progress of chunked transfers, since by definition, the total size of the response is unknown.
Also, XHR requests do not have a default timeout, which means that a request can be “in progress” indefinitely. As a best practice, always set a meaningful timeout for your application and handle the error!
In some cases an application may need or want to process a stream of data incrementally: upload the data to the server as it becomes available on the client, or process the downloaded data as it arrives from the server. Unfortunately, while this is an important use case, today there is no simple, efficient, cross-browser API for XHR streaming:
Streaming has never been an official use case within the official XHR specification. As a result, short of manually splitting an upload into smaller, individual XHRs, there is no API for streaming data from client to server. Similarly, while the XHR2 specification does provide some ability to read a partial response from the server, the implementation is inefficient and very limited. That’s the bad news.
The good news is that there is hope on the horizon! Lack of streaming support as a first-class use case for XHR is a well-recognized limitation, and there is work in progress to address the problem:
Web applications should have the ability to acquire and manipulate data in a wide variety of forms, including as a sequence of data made available over time. This specification defines the basic representation for Streams, errors raised by Streams, and programmatic ways to read and create Streams.
— W3C Streams API
The combination of XHR and Streams API will enable efficient XHR streaming in the browser. However, the Streams API is still under active discussion, and is not yet available in any browser. So, with that, we’re stuck, right? Well, not quite. As we noted earlier, streaming uploads with XHR is not an option, but we do have limited support for streaming downloads with XHR:
var xhr = new XMLHttpRequest();
xhr.open('GET', '/stream');
xhr.seenBytes = 0;
xhr.onreadystatechange = function() {
if(xhr.readyState > 2) {
var newData = xhr.responseText.substr(xhr.seenBytes);
// process newData
xhr.seenBytes = xhr.responseText.length;
}
};
xhr.send();
This example will work in most modern browsers. However, performance is not great, and there are a large number of implementation caveats and gotchas:
In short, currently, XHR streaming is neither efficient nor convenient, and to make matters worse, the lack of a common specification also means that the implementations differ from browser to browser. As a result, at least until the Streams API is available, XHR is not a good fit for streaming.
No need to despair! While XHR may not meet the criteria, we do have other transports that are optimized for the streaming use case: Server-Sent Events offers a convenient API for streaming text-based data from server to client, and WebSocket offers efficient, bidirectional streaming for both binary and text-based data.
XHR enables a simple and efficient way to synchronize client updates with the server: whenever necessary, an XHR request is dispatched by the client to update the appropriate data on the server. However, the same problem, but in reverse, is much harder. If data is updated on the server, how does the server notify the client?
HTTP does not provide any way for the server to initiate a new connection to the client. As a result, to receive real-time notifications, the client must either poll the server for updates or leverage a streaming transport to allow the server to push new notifications as they become available. Unfortunately, as we saw in the preceding section, support for XHR streaming is limited, which leaves us with XHR polling.
“Real-time” has different meanings for different applications: some applications demand submillisecond overhead, while others may be just fine with delays measured in minutes. To determine the optimal transport, first define clear latency and overhead targets for your application!
One of the simplest strategies to retrieve updates from the server is to have the client do a periodic check: the client can initiate a background XHR request on a periodic interval (poll the server) to check for updates. If new data is available on the server, then it is returned in the response, and otherwise the response is empty.
Polling is simple to implement but frequently is also very inefficient. The choice of the polling interval is critical: long polling intervals translate to delayed delivery of updates, whereas short intervals result in unnecessary traffic and high overhead both for the client and the server. Let’s consider the simplest possible example:
function checkUpdates(url) {
var xhr = new XMLHttpRequest();
xhr.open('GET', url);
xhr.onload = function() { ... };
xhr.send();
}
setInterval(function() { checkUpdates('/updates') }, 60000);
What is the optimal polling interval? There isn’t one. The frequency depends on the requirements of the application, and there is an inherent trade-off between efficiency and message latency. As a result, polling is a good fit for applications where polling intervals are long, new events are arriving at a predictable rate, and the transferred payloads are large. This combination offsets the extra HTTP overhead and minimizes message delivery delays.
To illustrate the trade-off between latency and overhead of XHR polling, let’s consider a simple email application that is using XHR polling to check for message updates on the server. The implementation is as follows:
An average HTTP 1.x request adds 800 bytes of request and response overhead (see Measuring and Controlling Protocol Overhead). Because the client is logged in, we will also have an extra authentication cookie and the message ID; let’s say this adds another 50 bytes. Hence, a request that returns no new messages will incur 850 bytes! Now imagine we have 10,000 clients, all polling on a 60-second interval:
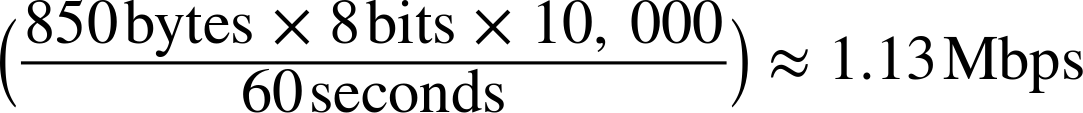
Each client sends 850 bytes of data on each request, which translates to 167 requests per second and a sustained rate of 1.13 Mbps of ingress throughput on the server! And that’s a constant rate without actually delivering any new messages to any of the clients.
Is the 30-second delay too high? We can decrease the polling interval, but in doing so, we would incur higher throughput and overhead: the same 10,000 clients, but on a 1-second interval, would generate over 60 Mbps of throughput! In short, unless the polling intervals are long, polling is expensive.
The challenge with periodic polling is that there is potential for many unnecessary and empty checks. With that in mind, what if we made a slight modification (Figure 15-1) to the polling workflow: instead of returning an empty response when no updates are available, could we keep the connection idle until an update is available?
The technique of leveraging a long-held HTTP request (“a hanging GET”) to allow the server to push data to the browser is commonly known as “Comet.” However, you may also encounter it under other names, such as “reverse AJAX,” “AJAX push,” and “HTTP push.”
By holding the connection open until an update is available (long-polling), data can be sent immediately to the client once it becomes available on the server. As a result, long-polling offers the best-case scenario for message latency, and it also eliminates empty checks, which reduces the number of XHR requests and the overall overhead of polling. Once an update is delivered, the long-poll request is finished and the client can issue another long-poll request and wait for the next available message:
function checkUpdates(url) {
var xhr = new XMLHttpRequest();
xhr.open('GET', url);
xhr.onload = function() {
...
checkUpdates('/updates');
};
xhr.send();
}
checkUpdates('/updates');
With that, is long-polling always a better choice than periodic polling? Unless the message arrival rate is known and constant, long-polling will always deliver better message latency. If that’s the primary criteria, then long-polling is the winner.
On the other hand, the overhead discussion requires a more nuanced view. First, note that each delivered message still incurs the same HTTP overhead; each new message is a standalone HTTP request. However, if the message arrival rate is high, then long-polling will issue more XHR requests than periodic polling!
Long-polling dynamically adapts to the message arrival rate by minimizing message latency, which is a behavior you may or may not want. If there is some tolerance for message latency, then polling may be a more efficient transport—e.g., if the update rate is high, then polling provides a simple “message aggregation” mechanism, which can reduce the number of requests and improve battery life on mobile handsets.
In practice, not all messages have the same priority or latency requirements. As a result, you may want to consider a mix of strategies: aggregate low-priority updates on the server, and trigger immediate delivery for high priority updates; see Nagle and Efficient Server Push.
XMLHttpRequest is what enabled us to make the leap from building pages to building interactive web applications in the browser. First, it enabled asynchronous communication within the browser, but just as importantly, it also made the process simple. Dispatching and controlling a scripted HTTP request takes just a few lines of JavaScript code, and the browser handles all the rest:
As such, XHR is a versatile and a high-performance transport for any transfers that follow the HTTP request-response cycle. Need to fetch a resource that requires authentication, should be compressed while in transfer, and should be cached for future lookups? The browser takes care of all of this and more, allowing us to focus on the application logic!
However, XHR also has its limitations. As we saw, streaming has never been an official use case in the XHR standard, and the support is limited: streaming with XHR is neither efficient nor convenient. Different browsers have different behaviors, and efficient binary streaming is impossible. In short, XHR is not a good fit for streaming.
Similarly, there is no one best strategy for delivering real-time updates with XHR. Periodic polling incurs high overhead and message latency delays. Long-polling delivers low latency but still has the same per-message overhead; each message is its own HTTP request. To have both low latency and low overhead, we need XHR streaming!
As a result, while XHR is a popular mechanism for “real-time” delivery, it may not be the best-performing transport for the job. Modern browsers support both simpler and more efficient options, such as Server-Sent Events and WebSocket. Hence, unless you have a specific reason why XHR polling is required, use them.
Server-Sent Events enables efficient server-to-client streaming of text-based event data—e.g., real-time notifications or updates generated on the server. To meet this goal, SSE introduces two components: a new EventSource interface in the browser, which allows the client to receive push notifications from the server as DOM events, and the “event stream” data format, which is used to deliver the individual updates.
The combination of the EventSource API in the browser and the well-defined event stream data format is what makes SSE both an efficient and an indispensable tool for handling real-time data in the browser:
Under the hood, SSE provides an efficient, cross-browser implementation of XHR streaming; the actual delivery of the messages is done over a single, long-lived HTTP connection. However, unlike dealing XHR streaming on our own, the browser handles all the connection management and message parsing, allowing our applications to focus on the business logic! In short, SSE makes working with real-time data simple and efficient. Let’s take a look under the hood.
The EventSource interface abstracts all the low-level connection establishment and message parsing behind a simple browser API. To get started, we simply need to specify the URL of the SSE event stream resource and register the appropriate JavaScript event listeners on the object:
var source = new EventSource("/path/to/stream-url");
source.onopen = function () { ... };
source.onerror = function () { ... };
source.addEventListener("foo", function (event) {
processFoo(event.data);
});
source.onmessage = function (event) {
log_message(event.id, event.data);
if (event.id == "CLOSE") {
source.close();
}
}
Open new SSE connection to stream endpoint
Optional callback, invoked when connection is established
Optional callback, invoked if the connection fails
Subscribe to event of type “foo”; invoke custom logic
Subscribe to all events without an explicit type
Close SSE connection if server sends a “CLOSE” message ID
EventSource can stream event data from remote origins by leveraging the same CORS permission and opt-in workflow as a regular XHR.
That’s all there is to it for the client API. The implementation logic is handled for us: the connection is negotiated on our behalf, received data is parsed incrementally, message boundaries are identified, and finally a DOM event is fired by the browser. EventSource interface allows the application to focus on the business logic: open new connection, process received event notifications, terminate stream when finished.
SSE provides a memory-efficient implementation of XHR streaming. Unlike a raw XHR connection, which buffers the full received response until the connection is dropped, an SSE connection can discard processed messages without accumulating all of them in memory.
As icing on the cake, the EventSource interface also provides auto-reconnect and tracking of the last seen message: if the connection is dropped, EventSource will automatically reconnect to the server and optionally advertise the ID of the last seen message, such that the stream can be resumed and lost messages can be retransmitted.
How does the browser know the ID, type, and boundary of each message? This is where the event stream protocol comes in. The combination of a simple client API and a well-defined data format is what allows us to offload the bulk of the work to the browser. The two go hand in hand, even though the low-level data protocol is completely transparent to the application in the browser.
An SSE event stream is delivered as a streaming HTTP response: the client initiates a regular HTTP request, the server responds with a custom “text/event-stream” content-type, and then streams the UTF-8 encoded event data. However, even that sounds too complicated, so an example is in order:
=> Request GET /stream HTTP/1.1data: Last message, id "43"
Client connection initiated via EventSource interface
Server response with “text/event-stream” content-type
Server sets client reconnect interval (15s) if the connection drops
Simple text event with no message type
JSON payload with no message type
Simple text event of type “foo”
Multiline event with message ID and type
Simple text event with optional ID
The event-stream protocol is trivial to understand and implement:
On the receiving end, the EventSource interface parses the incoming stream by looking for newline separators, extracts the payload from data fields, checks for optional ID and type, and finally dispatches a DOM event to notify the application. If a type is present, then a custom DOM event is fired, and otherwise the generic “onmessage” callback is invoked; see EventSource API for both cases.
Finally, in addition to automatic event parsing, SSE provides built-in support for reestablishing dropped connections, as well as recovery of messages the client may have missed while disconnected. By default, if the connection is dropped, then the browser will automatically reestablish the connection. The SSE specification recommends a 2–3 second delay, which is a common default for most browsers, but the server can also set a custom interval at any point by sending a retry command to the client.
Similarly, the server can also associate an arbitrary ID string with each message. The browser automatically remembers the last seen ID and will automatically append a “Last-Event-ID” HTTP header with the remembered value when issuing a reconnect request. Here’s an example:
(existing SSE connection) retry: 4500
The client application does not need to provide any extra logic to reestablish the connection or remember the last seen event ID. The entire workflow is handled by the browser, and we rely on the server to handle the recovery. Specifically, depending on the requirements of the application and the data stream, the server can implement several different strategies:
The exact implementation details of how far back the messages are persisted are, of course, specific to the requirements of the application. Further, note that the ID is an optional event stream field. Hence, the server can also choose to checkpoint specific messages or milestones in the delivered event stream. In short, evaluate your requirements, and implement the appropriate logic on the server.
SSE is a high-performance transport for server-to-client streaming of text-based real-time data: messages can be pushed the moment they become available on the server (low latency), there is minimum message overhead (long-lived connection, event-stream protocol, and gzip compression), the browser handles all the message parsing, and there are no unbounded buffers. Add to that a convenient EventSource API with auto-reconnect and message notifications as DOM events, and SSE becomes an indispensable tool for working with real-time data!
There are two key limitations to SSE. First, it is server-to-client only and hence does not address the request streaming use case—e.g., streaming a large upload to the server. Second, the event-stream protocol is specifically designed to transfer UTF-8 data: binary streaming, while possible, is inefficient.
Having said that, the UTF-8 limitation can often be resolved at the application layer: SSE delivers a notification to the application about a new binary asset available on the server, and the application dispatches an XHR request to fetch it. While this incurs an extra roundtrip of latency, it also has the benefit of leveraging the numerous services provided by the XHR: response caching, transfer-encoding (compression), and so on. If an asset is streamed, it cannot be cached by the browser cache.
Real-time push, just as polling, can have a large negative impact on battery life. First, consider batching messages to avoid waking up the radio. Second, eliminate unnecessary keepalives; an SSE connection is not “dropped” while the radio is idle. For more details, see Eliminate Periodic and Inefficient Data Transfers.
WebSocket enables bidirectional, message-oriented streaming of text and binary data between client and server. It is the closest API to a raw network socket in the browser. Except a WebSocket connection is also much more than a network socket, as the browser abstracts all the complexity behind a simple API and provides a number of additional services:
WebSocket is one of the most versatile and flexible transports available in the browser. The simple and minimal API enables us to layer and deliver arbitrary application protocols between client and server—anything from simple JSON payloads to custom binary message formats—in a streaming fashion, where either side can send data at any time.
However, the trade-off with custom protocols is that they are, well, custom. The application must account for missing state management, compression, caching, and other services otherwise provided by the browser. There are always design constraints and performance trade-offs, and leveraging WebSocket is no exception. In short, WebSocket is not a replacement for HTTP, XHR, or SSE, and for best performance it is critical that we leverage the strengths of each transport.
WebSocket is a set of multiple standards: the WebSocket API is defined by the W3C, and the WebSocket protocol (RFC 6455) and its extensions are defined by the HyBi Working Group (IETF).
The WebSocket API provided by the browser is remarkably small and simple. Once again, all the low-level details of connection management and message processing are taken care of by the browser. To initiate a new connection, we need the URL of a WebSocket resource and a few application callbacks:
var ws = new WebSocket('wss://example.com/socket');
ws.onerror = function (error) { ... }
ws.onclose = function () { ... }
ws.onopen = function () {
ws.send("Connection established. Hello server!");
}
ws.onmessage = function(msg) {
if(msg.data instanceof Blob) {
processBlob(msg.data);
} else {
processText(msg.data);
}
}
Open a new secure WebSocket connection (wss)
Optional callback, invoked if a connection error has occurred
Optional callback, invoked when the connection is terminated
Optional callback, invoked when a WebSocket connection is established
Client-initiated message to the server
A callback function invoked for each new message from the server
Invoke binary or text processing logic for the received message
The API speaks for itself. In fact, it should look very similar to the EventSource API we saw in the preceding chapter. This is intentional, as WebSocket offers similar and extended functionality. Having said that, there are a number of important differences as well. Let’s take a look at them one by one.
The WebSocket resource URL uses its own custom scheme: ws for plain-text communication (e.g., ws://example.com/socket), and wss when an encrypted channel (TCP+TLS) is required. Why the custom scheme, instead of the familiar http?
The primary use case for the WebSocket protocol is to provide an optimized, bi-directional communication channel between applications running in the browser and the server. However, the WebSocket wire protocol can be used outside the browser and could be negotiated via a non-HTTP exchange. As a result, the HyBi Working Group chose to adopt a custom URL scheme.
Despite the non-HTTP negotiation option enabled by the custom scheme, in practice there are no existing standards for alternative handshake mechanisms for establishing a WebSocket session.
WebSocket communication consists of messages and application code and does not need to worry about buffering, parsing, and reconstructing received data. For example, if the server sends a 1 MB payload, the application’s onmessage callback will be called only when the entire message is available on the client.
Further, the WebSocket protocol makes no assumptions and places no constraints on the application payload: both text and binary data are fair game. Internally, the protocol tracks only two pieces of information about the message: the length of payload as a variable-length field and the type of payload to distinguish UTF-8 from binary transfers.
When a new message is received by the browser, it is automatically converted to a DOMString object for text-based data, or a Blob object for binary data, and then passed directly to the application. The only other option, which acts as performance hint and optimization for the client, is to tell the browser to convert the received binary data to an ArrayBuffer instead of Blob:
var ws = new WebSocket('wss://example.com/socket');
ws.binaryType = "arraybuffer";
ws.onmessage = function(msg) {
if(msg.data instanceof ArrayBuffer) {
processArrayBuffer(msg.data);
} else {
processText(msg.data);
}
}
User agents can use this as a hint for how to handle incoming binary data: if the attribute is set to “blob”, it is safe to spool it to disk, and if it is set to “arraybuffer”, it is likely more efficient to keep the data in memory. Naturally, user agents are encouraged to use more subtle heuristics to decide whether to keep incoming data in memory or not…
— The WebSocket API W3C Candidate Recommendation
A Blob object represents a file-like object of immutable, raw data. If you do not need to modify the data and do not need to slice it into smaller chunks, then it is the optimal format—e.g., you can pass the entire Blob object to an image tag (see the example in Downloading Data with XHR). On the other hand, if you need to perform additional processing on the binary data, then ArrayBuffer is likely the better fit.
Once a WebSocket connection is established, the client can send and receive UTF-8 and binary messages at will. WebSocket offers a bidirectional communication channel, which allows message delivery in both directions over the same TCP connection:
var ws = new WebSocket('wss://example.com/socket');
ws.onopen = function () {
socket.send("Hello server!");
socket.send(JSON.stringify({'msg': 'payload'}));
var buffer = new ArrayBuffer(128);
socket.send(buffer);
var intview = new Uint32Array(buffer);
socket.send(intview);
var blob = new Blob([buffer]);
socket.send(blob);
}
The WebSocket API accepts a DOMString object, which is encoded as UTF-8 on the wire, or one of ArrayBuffer, ArrayBufferView, or Blob objects for binary transfers. However, note that the latter binary options are simply an API convenience: on the wire, a WebSocket frame is either marked as binary or text via a single bit. Hence, if the application, or the server, need other content-type information about the payload, then they must use an additional mechanism to communicate this data.
The send() method is asynchronous: the provided data is queued by the client, and the function returns immediately. As a result, especially when transferring large payloads, do not mistake the fast return for a signal that the data has been sent! To monitor the amount of data queued by the browser, the application can query the bufferedAmount attribute on the socket:
var ws = new WebSocket('wss://example.com/socket');
ws.onopen = function () {
subscribeToApplicationUpdates(function(evt) {
if (ws.bufferedAmount == 0)
ws.send(evt.data);
});
};
The preceding example attempts to send application updates to the server, but only if the previous messages have been drained from the client’s buffer. Why bother with such checks? All WebSocket messages are delivered in the exact order in which they are queued by the client. As a result, a large backlog of queued messages, or even a single large message, will delay delivery of messages queued behind it—head-of-line blocking!
To work around this problem, the application can split large messages into smaller chunks, monitor the bufferedAmount value carefully to avoid head-of-line blocking, and even implement its own priority queue for pending messages instead of blindly queuing them all on the socket.
WebSocket protocol makes no assumptions about the format of each message: a single bit tracks whether the message contains text or binary data, such that it can be efficiently decoded by the client and server, but otherwise the message contents are opaque.
Further, unlike HTTP or XHR requests, which communicate additional metadata via HTTP headers of each request and response, there is no such equivalent mechanism for a WebSocket message. As a result, if additional metadata about the message is required, then the client and server must agree to implement their own subprotocol to communicate this data:
This list is just a small sample of possible strategies. The flexibility and low overhead of a WebSocket message come at the cost of extra application logic. However, message serialization and management of metadata are only part of the problem! Once we determine the serialization format for our messages, how do we ensure that both client and server understand each other, and how do we keep them in sync?
Thankfully, WebSocket provides a simple and convenient subprotocol negotiation API to address the second problem. The client can advertise which protocols it supports to the server as part of its initial connection handshake:
var ws = new WebSocket('wss://example.com/socket',
['appProtocol', 'appProtocol-v2']);
ws.onopen = function () {
if (ws.protocol == 'appProtocol-v2') {
...
} else {
...
}
}
As the preceding example illustrates, the WebSocket constructor accepts an optional array of subprotocol names, which allows the client to advertise the list of protocols it understands or is willing to use for this connection. The specified list is sent to the server, and the server is allowed to pick one of the protocols advertised by the client.
If the subprotocol negotiation is successful, then the onopen callback is fired on the client, and the application can query the protocol attribute on the WebSocket object to determine the chosen protocol. On the other hand, if the server does not support any of the client protocols advertised by the client, then the WebSocket handshake is incomplete: the onerror callback is invoked, and the connection is terminated.
The WebSocket wire protocol (RFC 6455) developed by the HyBi Working Group consists of two high-level components: the opening HTTP handshake used to negotiate the parameters of the connection and a binary message framing mechanism to allow for low overhead, message-based delivery of both text and binary data.
The WebSocket Protocol attempts to address the goals of existing bidirectional HTTP technologies in the context of the existing HTTP infrastructure; as such, it is designed to work over HTTP ports 80 and 443… However, the design does not limit WebSocket to HTTP, and future implementations could use a simpler handshake over a dedicated port without reinventing the entire protocol.
— WebSocket Protocol RFC 6455
WebSocket protocol is a fully functional, standalone protocol that can be used outside the browser. Having said that, its primary application is as a bidirectional transport for browser-based applications.
Client and server WebSocket applications communicate via a message-oriented API: the sender provides an arbitrary UTF-8 or binary payload, and the receiver is notified of its delivery when the entire message is available. To enable this, WebSocket uses a custom binary framing format (Figure 17-1), which splits each application message into one or more frames, transports them to the destination, reassembles them, and finally notifies the receiver once the entire message has been received.
The decision to fragment an application message into multiple frames is made by the underlying implementation of the client and server framing code. Hence, the applications remain blissfully unaware of the individual WebSocket frames or how the framing is performed. Having said that, it is still useful to understand the highlights of how each WebSocket frame is represented on the wire:
Payload length is represented as a variable-length field:
The payload of all client-initiated frames is masked using the value specified in the frame header: this prevents malicious scripts executing on the client from performing a cache poisoning attack against intermediaries that may not understand the WebSocket protocol. For full details of this attack, refer to “Talking to Yourself for Fun and Profit”, presented at W2SP 2011.
As a result, each server-sent WebSocket frame incurs 2–10 bytes of framing overhead. The client must also send a masking key, which adds an extra 4 bytes to the header, resulting in 6–14 bytes over overhead. No other metadata, such as header fields or other information about the payload, is available: all WebSocket communication is performed by exchanging frames that treat the payload as an opaque blob of application data.
WebSocket specification allows for protocol extensions: the wire format and the semantics of the WebSocket protocol can be extended with new opcodes and data fields. While somewhat unusual, this is a very powerful feature, as it allows the client and server to implement additional functionality on top of the base WebSocket framing layer without requiring any intervention or cooperation from the application code.
What are some examples of WebSocket protocol extensions? The HyBi Working Group, which is responsible for the development of the WebSocket specification, lists two official extensions in development:
As we noted earlier, each WebSocket connection requires a dedicated TCP connection, which is inefficient. Multiplexing extension addresses this problem by extending each WebSocket frame with an additional “channel ID” to allow multiple virtual WebSocket channels to share a single TCP connection.
Similarly, the base WebSocket specification provides no mechanism or provisions for compression of transferred data: each frame carries payload data as provided by the application. As a result, while this may not be a problem for optimized binary data structures, this can result in high byte transfer overhead unless the application implements its own data compression and decompression logic. In effect, compression extension enables an equivalent of transfer-encoding negotiation provided by HTTP.
To enable one or more extensions, the client must advertise them in the initial Upgrade handshake, and the server must select and acknowledge the extensions that will be used for the lifetime of the negotiated connection. For a hands-on example, let’s now take a closer look at the Upgrade sequence.
The WebSocket protocol delivers a lot of powerful features: message-oriented communication, its own binary framing layer, subprotocol negotiation, optional protocol extensions, and more. As a result, before any messages can be exchanged, the client and server must negotiate the appropriate parameters to establish the connection.
Leveraging HTTP to perform the handshake offers several advantages. First, it makes WebSockets compatible with existing HTTP infrastructure: WebSocket servers can run on port 80 and 443, which are frequently the only open ports for the client. Second, it allows us to reuse and extend the HTTP Upgrade flow with custom WebSocket headers to perform the negotiation:
Sec-WebSocket-Version
Sec-WebSocket-Key
Sec-WebSocket-Accept
Sec-WebSocket-Protocol
Sec-WebSocket-Extensions
With that, we now have all the necessary pieces to perform an HTTP Upgrade and negotiate a new WebSocket connection between the client and server:
GET /socket HTTP/1.1 Host: thirdparty.com Origin: http://example.com Connection: Upgrade Upgrade: websocket
Just like any other client-initiated connection in the browser, WebSocket requests are subject to the same-origin policy: the browser automatically appends the Origin header to the upgrade handshake, and the remote server can use CORS to accept or deny the cross origin request; see Cross-Origin Resource Sharing (CORS). To complete the handshake, the server must return a successful “Switching Protocols” response and confirm the selected options advertised by the client:
HTTP/1.1 101 Switching Protocols
All RFC6455-compatible WebSocket servers use the same algorithm to compute the answer to the client challenge: the contents of the Sec-WebSocket-Key are concatenated with a unique GUID string defined in the standard, a SHA1 hash is computed, and the resulting string is base-64 encoded and sent back to the client.
At a minimum, a successful WebSocket handshake must contain the protocol version and an auto-generated challenge value sent by the client, followed by a 101 HTTP response code (Switching Protocols) from the server with a hashed challenge-response to confirm the selected protocol version:
Sec-WebSocket-Version and Sec-WebSocket-Key.
Sec-WebSocket-Accept.
Sec-WebSocket-Protocol.
Sec-WebSocket-Protocol. If the server does not support any, then the connection is aborted.
Sec-WebSocket-Extensions.
Sec-WebSocket-Extensions. If no extensions are provided, then the connection proceeds without them.
Finally, once the preceding handshake is complete, and if the handshake is successful, the connection can now be used as a two-way communication channel for exchanging WebSocket messages. From here on, there is no other explicit HTTP communication between the client and server, and the WebSocket protocol takes over.
WebSocket API provides a simple interface for bidirectional, message-oriented streaming of text and binary data between client and server: pass in a WebSocket URL to the constructor, set up a few JavaScript callback functions, and we are up and running—the rest is handled by the browser. Add to that the WebSocket protocol, which offers binary framing, extensibility, and subprotocol negotiation, and WebSocket becomes a perfect fit for delivering custom application protocols in the browser.
However, just as with any discussion on performance, while the implementation complexity of the WebSocket protocol is hidden from the application, it nonetheless has important performance implications for how and when WebSocket should be used. WebSocket is not a replacement for XHR or SSE, and for best performance it is critical that we leverage the strengths of each transport!
Refer to XHR Use Cases and Performance and SSE Use Cases and Performance for a review of the performance characteristics of each transport.
WebSocket is the only transport that allows bidirectional communication over the same TCP connection (Figure 17-2): the client and server can exchange messages at will. As a result, WebSocket provides low latency delivery of text and binary application data in both directions.
Once a WebSocket connection is established, the client and server exchange data via the WebSocket protocol: application messages are split into one or more frames, each of which adds from 2 to 14 bytes of overhead. Further, because the framing is done via a custom binary format, both UTF-8 and binary application data can be efficiently encoded via the same mechanism. How does that compare with XHR and SSE?
Keep in mind that these overhead numbers do not include the overhead of IP, TCP, and TLS framing, which add 60–100 bytes of combined overhead per message, regardless of the application protocol; see TLS Record Size.
Every XHR request can negotiate the optimal transfer encoding format (e.g., gzip for text-based data), via regular HTTP negotiation. Similarly, because SSE is restricted to UTF-8–only transfers, the event stream data can be efficiently compressed by applying gzip across the entire session.
With WebSocket, the situation is more complex: WebSocket can transfer both text and binary data, and as a result it doesn’t make sense to compress the entire session. The binary payloads may be compressed already! As a result, WebSocket must implement its own compression mechanism and selectively apply it to each message.
The good news is the HyBi working group is developing the per-message compression extension for the WebSocket protocol. However, it is not yet available in any of the browsers. As a result, unless the application implements its own compression logic by carefully optimizing its binary payloads (see Decoding Binary Data with JavaScript) and implementing its own compression logic for text-based messages, it may incur high byte overhead on the transferred data!
Chrome and some WebKit-based browsers support an older revision (per-frame compression) of the compression extension to the WebSocket protocol; see WebSocket Multiplexing and Compression in the Wild.
The browser is optimized for HTTP data transfers: it understands the protocol, and it provides a wide array of services, such as authentication, caching, compression, and much more. As a result, XHR requests inherit all of this functionality for free.
By contrast, streaming allows us to deliver custom protocols between client and server, but at the cost of bypassing many of the services provided by the browser: the initial HTTP handshake may be able to perform some negotiation of the parameters of the connection, but once the session is established, all further data streamed between the client and server is opaque to the browser. As a result, the flexibility of delivering a custom protocol also has its downsides, and the application may have to implement its own logic to fill in the missing gaps: caching, state management, delivery of message metadata, and so on!
HTTP is optimized for short and bursty transfers. As a result, many of the servers, proxies, and other intermediaries are often configured to aggressively timeout idle HTTP connections, which, of course, is exactly what we don’t want to see for long-lived WebSocket sessions. To address this, there are three pieces to consider:
We have no control over the policy of the client’s network. In fact, some networks may block WebSocket traffic entirely, which is why you may need a fallback strategy. Similarly, we don’t have control over the proxies on the external network. However, this is where TLS may help! By tunneling over a secure end-to-end connection, WebSocket traffic can bypass all the intermediate proxies.
Using TLS does not prevent the intermediary from timing out an idle TCP connection. However, in practice, it significantly increases the success rate of negotiating the WebSocket session and often also helps to extend the connection timeout intervals.
Finally, there is the infrastructure that we deploy and manage ourselves, which also often requires attention and tuning. As easy as it is to blame the client or external networks, all too often the problem is close to home. Each load-balancer, router, proxy, and web server in the serving path must be tuned to allow long-lived connections.
For example, Nginx 1.3.13+ can proxy WebSocket traffic, but defaults to aggressive 60-second timeouts! To increase the limit, we must explicitly define the longer timeouts:
location /websocket {
proxy_pass http://backend;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_read_timeout 3600;
proxy_send_timeout 3600;
}
Similarly, it is not uncommon to have a load balancer, such as HAProxy, in front of one or more Nginx servers. Not surprisingly, we need to apply similar explicit configuration here as well—e.g., for HAProxy:
defaults http
timeout connect 30s
timeout client 30s
timeout server 30s
timeout tunnel 1h
The gotcha with the preceding example is the extra “tunnel” timeout. In HAProxy the connect, client, and server timeouts are applied only to the initial HTTP Upgrade handshake, but once the upgrade is complete, the timeout is controlled by the tunnel value.
Nginx and HAProxy are just two of hundreds of different servers, proxies, and load balancers running in our data centers. We can’t enumerate all the configuration possibilities in these pages. The previous examples are just an illustration that most infrastructure requires custom configuration to handle long-lived sessions. Hence, before implementing application keepalives, double-check your infrastructure first.
Long-lived and idle sessions occupy memory and socket resources on all the intermediate servers. Hence, short timeouts are often justified as a security, resource, and operational precaution. Deploying WebSocket, SSE, and HTTP/2, each of which relies on long-lived sessions, brings its own class of new operational challenges.
Deploying a high-performance WebSocket service requires careful tuning and consideration, both on the client and on the server. A short list of criteria to put on the agenda:
Last, but definitely not least, optimize for mobile! Real-time push can be a costly performance anti-pattern on mobile handsets, where battery life is always at a premium. That’s not to say that WebSocket should not be used on mobile. To the contrary, it can be a highly efficient transport, but make sure to account for its requirements:
Web Real-Time Communication (WebRTC) is a collection of standards, protocols, and JavaScript APIs, the combination of which enables peer-to-peer audio, video, and data sharing between browsers (peers). Instead of relying on third-party plug-ins or proprietary software, WebRTC turns real-time communication into a standard feature that any web application can leverage via a simple JavaScript API.
Delivering rich, high-quality, RTC applications such as audio and video teleconferencing and peer-to-peer data exchange requires a lot of new functionality in the browser: audio and video processing capabilities, new application APIs, and support for half a dozen new network protocols. Thankfully, the browser abstracts most of this complexity behind three primary APIs:
All it takes is a dozen lines of JavaScript code, and any web application can enable a rich teleconferencing experience with peer-to-peer data transfers. That’s the promise and the power of WebRTC! However, the listed APIs are also just the tip of the iceberg: signaling, peer discovery, connection negotiation, security, and entire layers of new protocols are just a few components required to bring it all together.
Not surprisingly, the architecture and the protocols powering WebRTC also determine its performance characteristics: connection setup latency, protocol overhead, and delivery semantics, to name a few. In fact, unlike all other browser communication, WebRTC transports its data over UDP. However, UDP is also just a starting point. It takes a lot more than raw UDP to make real-time communication in the browser a reality. Let’s take a closer look.
WebRTC is already enabled for 1B+ users: the latest Chrome and Firefox browsers provide WebRTC support to all of their users! Having said that, WebRTC is also under active construction, both at the browser API level and at the transport and protocol levels. As a result, the specific APIs and protocols discussed in the following chapters may still change in the future.
Enabling real-time communication in the browser is an ambitious undertaking, and arguably, one of the most significant additions to the web platform since its very beginning. WebRTC breaks away from the familiar client-to-server communication model, which results in a full re-engineering of the networking layer in the browser, and also brings a whole new media stack, which is required to enable efficient, real-time processing of audio and video.
As a result, the WebRTC architecture consists of over a dozen different standards, covering both the application and browser APIs, as well as many different protocols and data formats required to make it work:
WebRTC is not a blank-slate standard. While its primary purpose is to enable real-time communication between browsers, it is also designed such that it can be integrated with existing communication systems: voice over IP (VOIP), various SIP clients, and even the public switched telephone network (PSTN), just to name a few. The WebRTC standards do not define any specific interoperability requirements, or APIs, but they do try to reuse the same concepts and protocols where possible.
In other words, WebRTC is not only about bringing real-time communication to the browser, but also about bringing all the capabilities of the Web to the telecommunications world—a $4.7 trillion industry in 2012! Not surprisingly, this is a significant development and one that many existing telecom vendors, businesses, and startups are following closely. WebRTC is much more than just another browser API.
Enabling a rich teleconferencing experience in the browser requires that the browser be able to access the system hardware to capture both audio and video—no third-party plug-ins or custom drivers, just a simple and a consistent API. However, raw audio and video streams are also not sufficient on their own: each stream must be processed to enhance quality, synchronized, and the output bitrate must adjust to the continuously fluctuating bandwidth and latency between the clients.
On the receiving end, the process is reversed, and the client must decode the streams in real-time and be able to adjust to network jitter and latency delays. In short, capturing and processing audio and video is a complex problem. However, the good news is that WebRTC brings fully featured audio and video engines to the browser (Figure 18-1), which take care of all the signal processing, and more, on our behalf.
The full implementation and technical details of the audio and video engines is easily a topic for a dedicated book, and is outside the scope of our discussion. To learn more, head to http://www.webrtc.org.
The acquired audio stream is processed for noise reduction and echo cancellation, then automatically encoded with one of the optimized narrowband or wideband audio codecs. Finally, a special error-concealment algorithm is used to hide the negative effects of network jitter and packet loss—that’s just the highlights! The video engine performs similar processing by optimizing image quality, picking the optimal compression and codec settings, applying jitter and packet-loss concealment, and more.
All of the processing is done directly by the browser, and even more importantly, the browser dynamically adjusts its processing pipeline to account for the continuously changing parameters of the audio and video streams and networking conditions. Once all of this work is done, the web application receives the optimized media stream, which it can then output to the local screen and speakers, forward to its peers, or post-process using one of the HTML5 media APIs!
The Media Capture and Streams W3C specification defines a set of new JavaScript APIs that enable the application to request audio and video streams from the platform, as well as a set of APIs to manipulate and process the acquired media streams. The MediaStream object (Figure 18-2) is the primary interface that enables all of this functionality.
A MediaStream object represents a real-time media stream and allows the application code to acquire data, manipulate individual tracks, and specify outputs. All the audio and video processing, such as noise cancellation, equalization, image enhancement, and more are automatically handled by the audio and video engines.
However, the features of the acquired media stream are constrained by the capabilities of the input source: a microphone can emit only an audio stream, and some webcams can produce higher-resolution video streams than others. As a result, when requesting media streams in the browser, the getUserMedia() API allows us to specify a list of mandatory and optional constraints to match the needs of the application:
<video autoplay></video>
This example illustrates one of the more elaborate scenarios: we are requesting audio and video tracks, and we are specifying both the minimum resolution and type of camera that must be used, as well as a list of optional constraints for 720p HD video! The getUserMedia() API is responsible for requesting access to the microphone and camera from the user, and acquiring the streams that match the specified constraints—that’s the whirlwind tour.
The provided APIs also enable the application to manipulate individual tracks, clone them, modify constraints, and more. Further, once the stream is acquired, we can feed it into a variety of other browser APIs:
To make a long story short, getUserMedia() is a simple API to acquire audio and video streams from the underlying platform. The media is automatically optimized, encoded, and decoded by the WebRTC audio and video engines and is then routed to one or more outputs. With that, we are halfway to building a real-time teleconferencing application—we just need to route the data to a peer!
For a full list of capabilities of the Media Capture and Streams APIs, head to the official W3C standard.
Real-time communication is time-sensitive; that should come as no surprise. As a result, audio and video streaming applications are designed to tolerate intermittent packet loss: the audio and video codecs can fill in small data gaps, often with minimal impact on the output quality. Similarly, applications must implement their own logic to recover from lost or delayed packets carrying other types of application data. Timeliness and low latency can be more important than reliability.
Audio and video streaming in particular have to adapt to the unique properties of our brains. Turns out we are very good at filling in the gaps but highly sensitive to latency delays. Add some variable delays into an audio stream, and “it just won’t feel right,” but drop a few samples in between, and most of us won’t even notice!
The requirement for timeliness over reliability is the primary reason why the UDP protocol is a preferred transport for delivery of real-time data. TCP delivers a reliable, ordered stream of data: if an intermediate packet is lost, then TCP buffers all the packets after it, waits for a retransmission, and then delivers the stream in order to the application. By comparison, UDP offers the following “non-services”:
Before we go any further, you may want to revisit Chapter 3 and in particular the section Null Protocol Services, for a refresher on the inner workings (or lack thereof) of UDP.
UDP offers no promises on reliability or order of the data, and delivers each packet to the application the moment it arrives. In effect, it is a thin wrapper around the best-effort delivery model offered by the IP layer of our network stacks.
WebRTC uses UDP at the transport layer: latency and timeliness are critical. With that, we can just fire off our audio, video, and application UDP packets, and we are good to go, right? Well, not quite. We also need mechanisms to traverse the many layers of NATs and firewalls, negotiate the parameters for each stream, provide encryption of user data, implement congestion and flow control, and more!
UDP is the foundation for real-time communication in the browser, but to meet all the requirements of WebRTC, the browser also needs a large supporting cast (Figure 18-3) of protocols and services above it.
ICE: Interactive Connectivity Establishment (RFC 5245)
ICE, STUN, and TURN are necessary to establish and maintain a peer-to-peer connection over UDP. DTLS is used to secure all data transfers between peers; encryption is a mandatory feature of WebRTC. Finally, SCTP and SRTP are the application protocols used to multiplex the different streams, provide congestion and flow control, and provide partially reliable delivery and other additional services on top of UDP.
Yes, that is a complicated stack, and not surprisingly, before we can talk about the end-to-end performance, we need to understand how each works under the hood. It will be a whirlwind tour, but that’s our focus for the remainder of the chapter. Let’s dive in.
We didn’t forget about SDP! As we will see, SDP is a data format used to negotiate the parameters of the peer-to-peer connection. However, the SDP “offer” and “answer” are communicated out of band, which is why SDP is missing from the protocol diagram.
Despite the many protocols involved in setting up and maintaining a peer-to-peer connection, the application API exposed by the browser is relatively simple. The RTCPeerConnection interface (Figure 18-4) is responsible for managing the full life cycle of each peer-to-peer connection.
In short, RTCPeerConnection encapsulates all the connection setup, management, and state within a single interface. However, before we dive into the details of each configuration option of the RTCPeerConnection API, we need to understand signaling and negotiation, the offer-answer workflow, and ICE traversal. Let’s take it step by step.
Initiating a peer-to-peer connection requires (much) more work than opening an XHR, EventSource, or a new WebSocket session: the latter three rely on a well-defined HTTP handshake mechanism to negotiate the parameters of the connection, and all three implicitly assume that the destination server is reachable by the client—i.e., the server has a publicly routable IP address or the client and server are located on the same internal network.
By contrast, it is likely that the two WebRTC peers are within their own, distinct private networks and behind one or more layers of NATs. As a result, neither peer is directly reachable by the other. To initiate a session, we must first gather the possible IP and port candidates for each peer, traverse the NATs, and then run the connectivity checks to find the ones that work, and even then, there are no guarantees that we will succeed.
Refer to UDP and Network Address Translators and NAT Traversal for an in-depth discussion of the challenges posed by NATs for UDP and peer-to-peer communication in particular.
However, while NAT traversal is an issue we must deal with, we may have gotten ahead of ourselves already. When we open an HTTP connection to a server, there is an implicit assumption that the server is listening for our handshake; it may wish to decline it, but it is nonetheless always listening for new connections. Unfortunately, the same can’t be said about a remote peer: the peer may be offline or unreachable, busy, or simply not interested in initiating a connection with the other party.
As a result, in order to establish a successful peer-to-peer connection, we must first solve several additional problems:
The good news is that WebRTC solves one of the problems on our behalf: the built-in ICE protocol performs the necessary routing and connectivity checks. However, the delivery of notifications (signaling) and initial session negotiation is left to the application.
Before any connectivity checks or session negotiation can occur, we must find out if the other peer is reachable and if it is willing to establish the connection. We must extend an offer, and the peer must return an answer (Figure 18-5). However, now we have a dilemma: if the other peer is not listening for incoming packets, how do we notify it of our intent? At a minimum, we need a shared signaling channel.
WebRTC defers the choice of signaling transport and protocol to the application; the standard intentionally does not provide any recommendations or implementation for the signaling stack. Why? This allows interoperability with a variety of other signaling protocols powering existing communications infrastructure, such as the following:
A “signaling channel” can be as simple as a shout across the room—that is, if your intended peer is within shouting distance! The choice of the signaling medium and the protocol is left to the application.
A WebRTC application can choose to use any of the existing signaling protocols and gateways (Figure 18-6) to negotiate a call or a video conference with an existing communication system—e.g., initiate a “telephone” call with a PSTN client! Alternatively, it can choose to implement its own signaling service with a custom protocol.
The signaling server can act as a gateway to an existing communications network, in which case it is the responsibility of the network to notify the target peer of a connection offer and then route the answer back to the WebRTC client initiating the exchange. Alternatively, the application can also use its own custom signaling channel, which may consist of one or more servers and a custom protocol to communicate the messages: if both peers are connected to the same signaling service, then the service can shuttle messages between them.
Assuming the application implements a shared signaling channel, we can now perform the first steps required to initiate a WebRTC connection:
var signalingChannel = new SignalingChannel();
Initialize the shared signaling channel
Initialize the RTCPeerConnection object
Request audio stream from the browser
Register local audio stream with RTCPeerConnection object
Create SDP (offer) description of the peer connection
Apply generated SDP as local description of peer connection
Send generated SDP offer to remote peer via signaling channel
We will be using unprefixed APIs in our examples, as they are defined by the W3C standard. Until the browser implementations are finalized, you may need to adjust the code for your favorite browser.
WebRTC uses Session Description Protocol (SDP) to describe the parameters of the peer-to-peer connection. SDP does not deliver any media itself; instead it is used to describe the “session profile,” which represents a list of properties of the connection: types of media to be exchanged (audio, video, and application data), network transports, used codecs and their settings, bandwidth information, and other metadata.
In the preceding example, once a local audio stream is registered with the RTCPeerConnection object, we call createOffer() to generate the SDP description of the intended session. What does the generated SDP contain? Let’s take a look:
(... snip ...) m=audio 1 RTP/SAVPF 111 ...
SDP is a simple text-based protocol (RFC 4568) for describing the properties of the intended session; in the previous case, it provides a description of the acquired audio stream. The good news is, WebRTC applications do not have to deal with SDP directly. The JavaScript Session Establishment Protocol (JSEP) abstracts all the inner workings of SDP behind a few simple method calls on the RTCPeerConnection object.
Once the offer is generated, it can be sent to the remote peer via the signaling channel. Once again, how the SDP is encoded is up to the application: the SDP string can be transferred directly as shown earlier (as a simple text blob), or it can be encoded in any other format—e.g., the Jingle protocol provides a mapping from SDP to XMPP (XML) stanzas.
To establish a peer-to-peer connection, both peers must follow a symmetric workflow (Figure 18-7) to exchange SDP descriptions of their respective audio, video, and other data streams.
With that, once the SDP session descriptions have been exchanged via the signaling channel, both parties have now negotiated the type of streams to be exchanged, and their settings. We are almost ready to begin our peer-to-peer communication! Now, there is just one more detail to take care of: connectivity checks and NAT traversal.
In order to establish a peer-to-peer connection, by definition, the peers must be able to route packets to each other. A trivial statement on the surface, but hard to achieve in practice due to the numerous layers of firewalls and NAT devices between most peers; see UDP and Network Address Translators.
First, let’s consider the trivial case, where both peers are located on the same internal network, and there are no firewalls or NATs between them. To establish the connection, each peer can simply query its operating system for its IP address (or multiple, if there are multiple network interfaces), append the provided IP and port tuples to the generated SDP strings, and forward it to the other peer. Once the SDP exchange is complete, both peers can initiate a direct peer-to-peer connection.
The earlier “SDP example” illustrates the preceding scenario: the a=candidate line lists a private (192.168.x.x) IP address for the peer initiating the session; see Reserved Private Network Ranges.
So far, so good. However, what would happen if one or both of the peers were on distinct private networks? We could repeat the preceding workflow, discover and embed the private IP addresses of each peer, but the peer-to-peer connections would obviously fail! What we need is a public routing path between the peers. Thankfully, the WebRTC framework manages most of this complexity on our behalf:
Once a session description (local or remote) is set, local ICE agent automatically begins the process of discovering all the possible candidate IP, port tuples for the local peer:
If you have ever had to answer the “What is my public IP address?” question, then you’ve effectively performed a manual “STUN lookup.” The STUN protocol allows the browser to learn if it’s behind a NAT and to discover its public IP and port; see STUN, TURN, and ICE.
Whenever a new candidate (an IP, port tuple) is discovered, the agent automatically registers it with the RTCPeerConnection object and notifies the application via a callback function (onicecandidate). Once the ICE gathering is complete, the same callback is fired to notify the application. Let’s extend our earlier example to work with ICE:
var ice = {"iceServers": [
{"url": "stun:stun.l.google.com:19302"},
{"url": "turn:turnserver.com", "username": "user", "credential": "pass"}
]};
var signalingChannel = new SignalingChannel();
var pc = new RTCPeerConnection(ice);
navigator.getUserMedia({ "audio": true }, gotStream, logError);
function gotStream(stream) {
pc.addStream(stream);
pc.createOffer(function(offer) {
pc.setLocalDescription(offer);
});
}
pc.onicecandidate = function(evt) {
if (evt.target.iceGatheringState == "complete") {
local.createOffer(function(offer) {
console.log("Offer with ICE candidates: " + offer.sdp);
signalingChannel.send(offer.sdp);
});
}
}
...
// Offer with ICE candidates:
// a=candidate:1862263974 1 udp 2113937151 192.168.1.73 60834 typ host ...
// a=candidate:2565840242 1 udp 1845501695 50.76.44.100 60834 typ srflx ...
STUN server, configured to use Google’s public test server
TURN server for relaying data if peer-to-peer connection fails
Apply local session description: initiates ICE gathering process
Subscribe to ICE events and listen for ICE gathering completion
Regenerate the SDP offer (now with discovered ICE candidates)
Private ICE candidate (192.168.1.73:60834) for the peer
Public ICE candidate (50.76.44.100:69834) returned by the STUN server
The previous example uses Google’s public demo STUN server. Unfortunately, STUN alone may not be sufficient (see STUN and TURN in Practice), and you may also need to provide a TURN server to guarantee connectivity for peers that cannot establish a direct peer-to-peer connection (~8% of users).
As the example illustrates, the ICE agent handles most of the complexity on our behalf: the ICE gathering process is triggered automatically, STUN lookups are performed in the background, and the discovered candidates are registered with the RTCPeerConnection object. Once the process is complete, we can generate the SDP offer and use the signaling channel to deliver it to the other peer.
Then, once the ICE candidates are received by the other peer, we are ready to begin the second phase of establishing a peer-to-peer connection: once the remote session description is set on the RTCPeerConnection object, which now contains a list of candidate IP and port tuples for the other peer, the ICE agent begins connectivity checks (Figure 18-8) to see if it can reach the other party.
The ICE agent sends a message (a STUN binding request), which the other peer must acknowledge with a successful STUN response. If this completes, then we finally have a routing path for a peer-to-peer connection! Conversely, if all candidates fail, then either the RTCPeerConnection is marked as failed, or the connection falls back to a TURN relay server to establish the connection.
The ICE agent automatically ranks and prioritizes the order in which the candidate connection checks are performed: local IP addresses are checked first, then public, and TURN is used as a last resort. Once a connection is established, the ICE agent continues to issue periodic STUN requests to the other peer. This serves as a connection keepalive.
Phew! As we said at the beginning of this section, initiating a peer-to-peer connection requires (much) more work than opening an XHR, EventSource, or a new WebSocket session. The good news is, most of this work is done on our behalf by the browser. However, for performance reasons, it is important to keep in mind that the process may incur multiple roundtrips between the STUN servers and between the individual peers before we can begin transmitting data—that is, assuming ICE negotiation is successful.
The ICE gathering process is anything but instantaneous: retrieving local IP addresses is fast, but querying the STUN server requires a roundtrip to the external server, followed by another round of STUN connectivity checks between the individual peers. Trickle ICE is an extension to the ICE protocol that allows incremental gathering and connectivity checks between the peers. The core idea is very simple:
In short, instead of waiting for the ICE gathering process to complete, we rely on the signaling channel to deliver incremental updates to the other peer, which helps accelerate the process. The WebRTC implementation is also fairly simple:
var ice = {"iceServers": [
{"url": "stun:stun.l.google.com:19302"},
{"url": "turn:turnserver.com", "username": "user", "credential": "pass"}
]};
var pc = new RTCPeerConnection(ice);
navigator.getUserMedia({ "audio": true }, gotStream, logError);
function gotStream(stream) {
pc.addStream(stream);
pc.createOffer(function(offer) {
pc.setLocalDescription(offer);
signalingChannel.send(offer.sdp);
});
}
pc.onicecandidate = function(evt) {
if (evt.candidate) {
signalingChannel.send(evt.candidate);
}
}
signalingChannel.onmessage = function(msg) {
if (msg.candidate) {
pc.addIceCandidate(msg.candidate);
}
}
Trickle ICE generates more traffic over the signaling channel, but it can yield a significant improvement in the time required to initiate the peer-to-peer connection. For this reason, it is also the recommended strategy for all WebRTC applications: send the offer as soon as possible, and then trickle ICE candidates as they are discovered.
The built-in ICE framework manages candidate discovery, connectivity checks, keepalives, and more. If all works well, then all of this work is completely transparent to the application: the only thing we have to do is specify the STUN and TURN servers when initializing the RTCPeerConnection object. However, not all connections will succeed, and it is important to be able to isolate and resolve the problem. To do so, we can query the status of the ICE agent and subscribe to its notifications:
var ice = {"iceServers": [
{"url": "stun:stun.l.google.com:19302"},
{"url": "turn:turnserver.com", "username": "user", "credential": "pass"}
]};
var pc = new RTCPeerConnection(ice);
logStatus("ICE gathering state: " + pc.iceGatheringState);
pc.onicecandidate = function(evt) {
logStatus("ICE gathering state change: " + evt.target.iceGatheringState);
}
logStatus("ICE connection state: " + pc.iceConnectionState);
pc.oniceconnectionstatechange = function(evt) {
logStatus("ICE connection state change: " + evt.target.iceConnectionState);
}
The iceGatheringState attribute, as its name implies, reports the status of the candidate gathering process for the local peer. As a result, it can be in three different states:
|
|
The object was just created and no networking has occurred yet. |
|
|
The ICE agent is in the process of gathering local candidates. |
|
|
The ICE agent has completed the gathering process. |
On the other hand, the iceConnectionState attribute reports the status of the peer-to-peer connection (Figure 18-9), which can be in one of seven possible states:
new
checking
connected
completed
failed
disconnected
closed
A WebRTC session may require multiple streams for delivering audio, video, and application data. As a result, a successful connection is one that is able to establish connectivity for all the requested streams. Further, due to the unreliable nature of peer-to-peer connectivity, there are no guarantees that once the connection is established that it will stay that way: the connection may periodically flip between connected and disconnected states while the ICE agent attempts to find the best possible path to re-establish connectivity.
The first and primary goal for the ICE agent is to identify a viable routing path between the peers. However, it doesn’t stop there. Even once connected, the ICE agent may periodically try other candidates to see if it can deliver better performance via an alternate route.
Google Chrome provides a simple and very useful tool to investigate the entire workflow and state of any WebRTC connection: open a new tab and load chrome://webrtc-internals. There, you can inspect (Figure 18-10) all of the open peer-to-peer connections, inspect the exchanged SDP descriptions, and more.
Chrome will also report a number of statistics for each stream, such as available bandwidth, latency, bitrate of the encoded video and audio streams, and more. Even if you are not developing a WebRTC application, start a WebRTC session with a friend or between multiple browser windows, and head to chrome://webrtc-internals; it is an indispensable tool for familiarizing yourself with the internals of WebRTC.
We have covered a lot of ground: we’ve discussed signaling, the offer-answer workflow, session parameter negotiation with SDP, and took a deep dive into the inner workings of the ICE protocol required to establish a peer-to-peer connection. Finally, we now have all the necessary pieces to initiate a peer-to-peer connection over WebRTC.
We have been filling in all the necessary pieces bit by bit throughout the preceding pages, but now let’s take a look at a complete example for the peer responsible for initiating the WebRTC connection:
<video id="local_video" autoplay></video>if (evt.candidate) { signalingChannel.send(evt.candidate); } } signalingChannel.onmessage = function(msg) {
if (msg.candidate) { pc.addIceCandidate(msg.candidate); } } pc.onaddstream = function (evt) {
var remote_video = document.getElementById('remote_video'); remote_video.src = window.URL.createObjectURL(evt.stream); } function logError() { ... } </script>
Video element for output of local stream
Video element for output of remote stream
Initialize shared signaling channel
Initialize peer connection object
Acquire local audio and video streams
Register local MediaStream with peer connection
Output local video stream to video element (self view)
Generate SDP offer describing peer connection and send to peer
Trickle ICE candidates to the peer via the signaling channel
Register remote ICE candidate to begin connectivity checks
Output remote video stream to video element (remote view)
The entire process can be a bit daunting on the first pass, but now that we understand how all the pieces work, it is fairly straightforward: initialize the peer connection and the signaling channel, acquire and register media streams, send the offer, trickle ICE candidates, and finally output the acquired media streams. A more complete implementation can also register additional callbacks to track ICE gathering and connection states and provide more feedback to the user.
The process to answer the request for a new WebRTC connection is very similar, with the only major difference being that most of the logic is executed when the signaling channel delivers the SDP offer. Let’s take a hands-on look:
<video id="local_video" autoplay></video>
<video id="remote_video" autoplay></video>
<script>
var signalingChannel = new SignalingChannel();
var pc = null;
var ice = {"iceServers": [
{"url": "stun:stunserver.com:12345"},
{"url": "turn:turnserver.com", "username": "user", "credential": "pass"}
]};
signalingChannel.onmessage = function(msg) {
if (msg.offer) {
pc = new RTCPeerConnection(ice);
pc.setRemoteDescription(msg.offer);
pc.onicecandidate = function(evt) {
if (evt.candidate) {
signalingChannel.send(evt.candidate);
}
}
pc.onaddstream = function (evt) {
var remote_video = document.getElementById('remote_video');
remote_video.src = window.URL.createObjectURL(evt.stream);
}
navigator.getUserMedia({ "audio": true, "video": true },
gotStream, logError);
} else if (msg.candidate) {
pc.addIceCandidate(msg.candidate);
}
}
function gotStream(evt) {
pc.addStream(evt.stream);
var local_video = document.getElementById('local_video');
local_video.src = window.URL.createObjectURL(evt.stream);
pc.createAnswer(function(answer) {
pc.setLocalDescription(answer);
signalingChannel.send(answer.sdp);
});
}
function logError() { ... }
</script>
Not surprisingly, the code looks very similar. The only major difference, aside from initiating the peer connection workflow based on an offer message delivered via the shared signaling channel, is that the preceding code is generating an SDP answer (via createAnswer) instead of an offer object. Otherwise, the process is symmetric: initialize the peer connection, acquire and register media streams, send the answer, trickle ICE candidates, and finally output the acquired media streams.
With that, we can copy the code, add an implementation for the signaling channel, and we have a real-time, peer-to-peer video and audio session videoconferencing application running in the browser—not bad for fewer than 100 lines of JavaScript code!
Establishing a peer-to-peer connection takes quite a bit of work. However, even once the clients complete the answer-offer workflow and each client performs its NAT traversals and STUN connectivity checks, we are still only halfway up our WebRTC protocol stack (Figure 18-3). At this point, both peers have raw UDP connections open to each other, which provides a no-frills datagram transport, but as we know that is not sufficient on its own; see Optimizing for UDP.
Without flow control, congestion control, error checking, and some mechanism for bandwidth and latency estimation, we can easily overwhelm the network, which would lead to degraded performance for both peers and those around them. Further, UDP transfers data in the clear, whereas WebRTC requires that we encrypt all communication! To address this, WebRTC layers several additional protocols on top of UDP to fill in the gaps:
WebRTC specification requires that all transferred data—audio, video, and custom application payloads—must be encrypted while in transit. The Transport Layer Security protocol would, of course, be a perfect fit, except that it cannot be used over UDP, as it relies on reliable and in-order delivery offered by TCP. Instead, WebRTC uses DTLS, which provides equivalent security guarantees.
DTLS is deliberately designed to be as similar to TLS as possible. In fact, DTLS is TLS, but with a minimal number of modifications to make it compatible with datagram transport offered by UDP. Specifically, DTLS addresses the following problems:
Refer to TLS Handshake and TLS Record Protocol for a full discussion on the handshake sequence and layout of the record protocol.
There are no simple workarounds for fixing the TLS handshake sequence: each record serves a purpose, each must be sent in the exact order required by the handshake algorithm, and some records may easily span multiple packets. As a result, DTLS implements a “mini-TCP” (Figure 18-11) just for the handshake sequence.
DTLS extends the base TLS record protocol by adding an explicit fragment offset and sequence number for each handshake record. This addresses the in-order delivery requirement and allows large records to be fragmented across packets and reassembled by the other peer. DTLS handshake records are transmitted in the exact order specified by the TLS protocol; any other order is an error. Finally, DTLS must also deal with packet loss: both sides use simple timers to retransmit handshake records if the reply is not received within an expected interval.
The combination of the record sequence number, offset, and retransmission timer allows DTLS to perform the handshake (Figure 18-12) over UDP. To complete this sequence, both network peers generate self-signed certificates and then follow the regular TLS handshake protocol.
The DTLS handshake requires two roundtrips to complete—an important aspect to keep in mind, as it adds extra latency to setup of the peer-to-peer connection.
The WebRTC client automatically generates self-signed certificates for each peer. As a result, there is no certificate chain to verify. DTLS provides encryption and integrity, but defers authentication to the application; see Encryption, Authentication, and Integrity. Finally, with the handshake requirements satisfied, DTLS adds two important rules to account for possible fragmentation and out-of-order processing of regular records:
A regular TLS record can be up to 16 KB in size. TCP handles the fragmentation and reassembly, but UDP provides no such services. As a result, to preserve the out-of-order and best-effort semantics of the UDP protocol, each DTLS record carrying application data must fit into a single UDP packet. Similarly, stream ciphers are disallowed because they implicitly rely on in-order delivery of record data.
WebRTC provides media acquisition and delivery as a fully managed service: from camera to the network, and from network to the screen. The WebRTC application specifies the media constraints to acquire the streams and then registers them with the RTCPeerConnection object (Figure 18-13). From there, the rest is handled by the WebRTC media and network engines provided by the browser: encoding optimization, dealing with packet loss, network jitter, error recovery, flow, control, and more.
The implication of this architecture is that beyond specifying the initial constraints of the acquired media streams (e.g., 720p vs. 360p video), the application does not have any direct control over how the video is optimized or delivered to the other peer. This design choice is intentional: delivering a high-quality, real-time audio and video stream over an unreliable transport with fluctuating bandwidth and packet latency is a nontrivial problem. The browser solves it for us:
The WebRTC network engine cannot guarantee that an HD video stream provided by the application will be delivered at its highest quality: there may be insufficient bandwidth between the peers or high packet loss. Instead, the engine will attempt to adapt the provided stream to match the current conditions of the network.
An audio or video stream may be delivered at a lower quality than that of the original stream acquired by the application. However, the inverse is not true: WebRTC will not upgrade the quality of the stream. If the application provides a 360p video constraint, then that serves as a cap on the amount of bandwidth that will be used.
How does WebRTC optimize and adapt the quality of each media stream? Turns out WebRTC is not the first application to run up against the challenge of implementing real-time audio and video delivery over IP networks. As a result, WebRTC is reusing existing transport protocols used by VoIP phones, communication gateways, and numerous commercial and open source communication services:
Real-Time Transport Protocol (RTP) is defined by RFC 3550. However, WebRTC requires that all communication must be encrypted while in transit. As a result, WebRTC uses the “secure profile” (RFC 3711) of RTP—hence the S in SRTP and SRTCP.
SRTP defines a standard packet format (Figure 18-14) for delivering audio and video over IP networks. By itself, SRTP does not provide any mechanism or guarantees on timeliness, reliability, or error recovery of the transferred data. Instead, it simply wraps the digitized audio samples and video frames with additional metadata to assist the receiver in processing each stream.
The SRTP packet provides all the essential information required by the media engine for real-time playback of the stream. However, the responsibility to control how the individual SRTP packets are delivered falls to the SRTCP protocol, which implements a separate, out-of-band feedback channel for each media stream.
SRTCP tracks the number of sent and lost bytes and packets, last received sequence number, inter-arrival jitter for each SRTP packet, and other SRTP statistics. Then, periodically, both peers exchange this data and use it to adjust the sending rate, encoding quality, and other parameters of each stream.
In short, SRTP and SRTCP run directly over UDP and work together to adapt and optimize the real-time delivery of the audio and video streams provided by the application. The WebRTC application is never exposed to the internals of SRTP or SRTCP protocols: if you are building a custom WebRTC client, then you will have to deal with these protocols directly, but otherwise, the browser implements all the necessary infrastructure on your behalf.
Curious to see SRTCP statistics for your WebRTC session? Check the latency, bitrate, and bandwidth reports in Chrome; see Inspecting WebRTC Connection Status with Google Chrome.
In addition to transferring audio and video data, WebRTC allows peer-to-peer transfers of arbitrary application data via the DataChannel API. The SRTP protocol we covered in the previous section is specifically designed for media transfers and unfortunately is not a suitable transport for application data. As a result, DataChannel relies on the Stream Control Transmission Protocol (SCTP), which runs on top (Figure 18-3) of the established DTLS tunnel between the peers.
However, before we dive into the SCTP protocol itself, let’s first examine the WebRTC requirements for the RTCDataChannel interface and its transport protocol:
Transport must support multiplexing of multiple independent channels.
Transport must provide a message-oriented API.
The good news is that the use of DTLS already satisfies the last criteria: all application data is encrypted within the payload of the record, and confidentiality and integrity are guaranteed. However, the remaining requirements are a nontrivial set to satisfy! UDP provides unreliable, out-of-order datagram delivery, but we also need TCP-like reliable delivery, channel multiplexing, priority support, message fragmentation, and more. That’s where SCTP comes in.
| TCP | UDP | SCTP | |
Reliability | reliable | unreliable | configurable |
Delivery | ordered | unordered | configurable |
Transmission | byte-oriented | message-oriented | message-oriented |
Flow control | yes | no | yes |
Congestion control | yes | no | yes |
SCTP is a transport protocol, similar to TCP and UDP, which can run directly on top of the IP protocol. However, in the case of WebRTC, SCTP is tunneled over a secure DTLS tunnel, which itself runs on top of UDP.
SCTP provides the best features of TCP and UDP: message-oriented API, configurable reliability and delivery semantics, and built-in flow and congestion-control mechanisms. A full analysis of the protocol is outside the scope of our discussion, but, briefly, let’s introduce some SCTP concepts and terminology:
A single SCTP association between two endpoints may carry multiple independent streams, each of which communicates by transferring application messages. In turn, each message may be split into one or more chunks, which are delivered within SCTP packets (Figure 18-15) and then get reassembled at the other end.
Does this description sound familiar? It definitely should! The terms are different, but the core concepts are identical to those of the HTTP/2 framing layer; see Streams, Messages, and Frames. The difference here is that SCTP implements this functionality at a “lower layer,” which enables efficient transfer and multiplexing of arbitrary application data.
An SCTP packet consists of a common header and one or more control or data chunks. The header carries 12 bytes of data, which identify the source and destination ports, a randomly generated verification tag for the current SCTP association, and the checksum for the entire packet. Following the header, the packet carries one or more control or data chunks; the previous diagram is showing an SCTP packet with a single data chunk:
DataChannel uses the PPID field in the SCTP header to communicate the type of transferred data: 0×51 for UTF-8 and 0×52 for binary application payloads.
That’s a lot of detail to absorb in one go. Let’s review it once again, this time in the context of the earlier WebRTC and DataChannel API requirements:
B, E and TSN fields in the header: each chunk indicates its position (first, middle, or last), and the TSN value is used to order the middle chunks.
In total, SCTP adds 28 bytes of overhead to each data chunk: 12 bytes for the common header and 16 bytes for the data chunk header followed by the application payload.
How does an SCTP negotiate the starting parameters for the association? Each SCTP connection requires a handshake sequence similar to TCP! Similarly, SCTP also implements TCP-friendly flow and congestion control mechanisms: both protocols use the same initial congestion window size and implement similar logic to grow and reduce the congestion window once the connection enters the congestion-avoidance phase.
For a review on TCP handshake latencies, slow-start, and flow control, refer to Chapter 2. The SCTP handshake and congestion and flow-control algorithms used for WebRTC are different but serve the same purpose and have similar costs and performance implications.
We are getting close to satisfying all the WebRTC requirements, but unfortunately, even with all of that functionality, we are still short of a few required features:
In short, SCTP provides similar services as TCP, but because it is tunneled over UDP and is implemented by the WebRTC client, it offers a much more powerful API: in-order and out-of-order delivery, partial reliability, message-oriented API, and more. At the same time, SCTP is also subject to handshake latencies, slow-start, and flow and congestion control—all critical components to consider when thinking about performance of the DataChannel API.
DataChannel enables bidirectional exchange of arbitrary application data between peers—think WebSocket, but peer-to-peer, and with customizable delivery properties of the underlying transport. Once the RTCPeerConnection is established, connected peers can open one or more channels to exchange text or binary data:
function handleChannel(chan) {
chan.onerror = function(error) { ... }
chan.onclose = function() { ... }
chan.onopen = function(evt) {
chan.send("DataChannel connection established. Hello peer!")
}
chan.onmessage = function(msg) {
if(msg.data instanceof Blob) {
processBlob(msg.data);
} else {
processText(msg.data);
}
}
}
var signalingChannel = new SignalingChannel();
var pc = new RTCPeerConnection(iceConfig);
var dc = pc.createDataChannel("namedChannel", {reliable: false});
...
handleChannel(dc);
pc.ondatachannel = handleChannel;
The DataChannel API intentionally mirrors that of WebSocket: each established channel fires the same onerror, onclose, onopen, and onmessage callbacks, as well as exposes the same binaryType, bufferedAmount, and protocol fields on the channel.
However, because DataChannel is peer-to-peer and runs over a more flexible transport protocol, it also offers a number of additional features not available to WebSocket. The preceding code example highlights some of the most important differences:
ondatachannel callback is fired when a new DataChannel session is established.
Regardless of the type of transferred data—audio, video, or application data—the two participating peers must first complete the full offer/answer workflow, negotiate the used protocols and ports, and successfully complete their connectivity checks; see Establishing a Peer-to-Peer Connection.
In fact, as we now know, media transfers run over SRTP, whereas DataChannel uses the SCTP protocol. As a result, when the initiating peer first makes the connection offer, or when the answer is generated by the other peer, the two must specifically advertise the parameters for the SCTP association within the generated SDP strings:
(... snip ...) m=application 1 DTLS/SCTP 5000
As previously, the RTCPeerConnection object handles all the necessary generation of the SDP parameters as long as one of the peers registers a DataChannel prior to generating the SDP description of the session. In fact, the application can establish a data-only peer-to-peer connection by setting explicit constraints to disable audio and video transfers:
var signalingChannel = new SignalingChannel();
var pc = new RTCPeerConnection(iceConfig);
var dc = pc.createDataChannel("namedChannel", {reliable: false});
var mediaConstraints = {
mandatory: {
OfferToReceiveAudio: false,
OfferToReceiveVideo: false
}
};
pc.createOffer(function(offer) { ... }, null, mediaConstraints);
...
With the SCTP parameters negotiated between the peers, we are almost ready to begin exchanging application data. Notice that the SDP snippet we saw earlier doesn’t mention anything about the parameters of each DataChannel—e.g., protocol, reliability, or in-order or out-of-order flags. As a result, before any application data can be sent, the WebRTC client initiating the connection also sends a DATA_CHANNEL_OPEN message (Figure 18-16) which describes the type, reliability, used application protocol, and other parameters of the channel.
The DATA_CHANNEL_OPEN message is similar to the HEADERS frame in HTTP/2: it implicitly opens a new stream, and data frames can be sent immediately after it; see Initiating a New Stream. For more information on the DataChannel protocol, refer to http://tools.ietf.org/html/draft-jesup-rtcweb-data-protocol.
Once the channel parameters are communicated, both peers can begin exchanging application data. Under the hood, each established channel is delivered as an independent SCTP stream: the channels are multiplexed over the same SCTP association, which avoids head-of-line blocking between the different streams and allows for simultaneous delivery of multiple channels over the same SCTP association.
DataChannel also allows out-of-band negotiation of channel parameters. When calling the createDataChannel method, the application can set the negotiated parameter to true, which skips the automatic dispatch of the DATA_CHANNEL_OPEN message. However, when doing so, both peers also have to specify the same id parameter, which is otherwise automatically generated by the browser:
signalingChannel.send({
newchannel: true,
label: "negotiated channel",
options: {
negotiated: true,
id: 10,
reliable: true,
ordered: true,
protocol: "appProtocol-v3"
}
});
signalingChannel.onmessage = function(msg) {
if (msg.newchannel) {
dc = pc.createDataChannel(msg.label, msg.options);
}
}
In practice, there are no additional performance benefits to using out-of-band negotiation with few participating peers. Let the RTCPeerConnection object handle the negotiation for you. However, where this workflow can be useful is in cases with many participating peers, where the signaling server can generate the same description and simultaneously distribute it to all the participating parties.
DataChannel enables peer-to-peer transfers of arbitrary application data via a WebSocket-compatible API: this by itself is a unique and a powerful feature. However, DataChannel also offers a much more flexible transport, which allows us to customize the delivery semantics of each channel to match the requirements of the application and the type of data being transferred.
Configuring the channel to use in-order and reliable delivery is, of course, equivalent to TCP: the same delivery guarantees as a regular WebSocket connection. However, and this is where it starts to get really interesting, DataChannel also offers two different policies for configuring partial reliability of each channel:
Both strategies are implemented by the WebRTC client, which means that all the application has to do is decide on the appropriate delivery model and set the right parameters on the channel. There is no need to manage application timers or retransmission counters. Let’s take a closer look at our configuration options:
| Ordered | Reliable | Partial reliability policy | |
Ordered + reliable | yes | yes | n/a |
Unordered + reliable | no | yes | n/a |
Ordered + partially reliable (retransmit) | yes | partial | retransmission count |
Unordered + partially reliable (retransmit) | no | partial | retransmission count |
Ordered + partially reliable (timed) | yes | partial | timeout (ms) |
Unordered + partially reliable (timed) | no | partial | timeout (ms) |
Ordered and reliable delivery is self-explanatory: it’s TCP. On the other hand, unordered and reliable delivery is already much more interesting—it’s TCP, but without the head-of-line blocking problem; see Head-of-Line Blocking.
When configuring a partially reliable channel, it is important to keep in mind that the two retransmission strategies are mutually exclusive. The application can specify either a timeout or a retransmission count, but not both; doing so will raise an error. With that, let’s take a look at the JavaScript API for configuring the channel:
conf = {};
conf = { ordered: false };
conf = { ordered: true, maxRetransmits: customNum };
conf = { ordered: false, maxRetransmits: customNum };
conf = { ordered: true, maxRetransmitTime: customMs };
conf = { ordered: false, maxRetransmitTime: customMs };
conf = { ordered: false, maxRetransmits: 0 };
var signalingChannel = new SignalingChannel();
var pc = new RTCPeerConnection(iceConfig);
...
var dc = pc.createDataChannel("namedChannel", conf);
if (dc.reliable) {
...
} else {
...
}
Default to ordered and reliable delivery (TCP)
Reliable, unordered delivery
Ordered, partially reliable with custom retransmit count
Unordered, partially reliable with custom retransmit count
Ordered, partially reliable with custom retransmit timeout
Unordered, partially reliable with custom retransmit timeout
Unordered, unreliable delivery (UDP)
Initialize DataChannel with specified order and reliability configuration
Once a DataChannel is initialized, the application can access the maxRetransmits and maxRetransmitTime as read-only attributes. Also, as a convenience, the DataChannel provides a reliable attribute, which returns false if either of the partial-reliability strategies are used.
Each DataChannel can be configured with custom order and reliability parameters, and the peers can open multiple channels, all of which will be multiplexed over the same SCTP association. As a result, each channel is independent of the others, and the peers can use different channels for different types of data—e.g., reliable and in-order delivery for peer-to-peer chat and partially reliable and out-of-order delivery for transient or low-priority application updates.
The use of a partially reliable channel requires additional design consideration from the application. Specifically, the application must pay close attention to the message size: nothing is stopping the application from passing in a large message, which will be fragmented across multiple packets, but doing so will likely yield very poor results. To illustrate this in action, let’s assume the following scenario:
Two peers have negotiated an out-of-order, unreliable DataChannel.
WebRTC clients set the maximum transmission unit for an SCTP packet to 1,280 bytes, which is the minimum and recommended MTU for an IPv6 packet. But we must also account for the overhead of IP, UDP, DTLS, and SCTP protocols: 20–40 bytes, 8 bytes, 20–40 bytes, and 28 bytes, respectively. Let’s round this up to ~130 bytes of overhead, which leaves us with ~1,150 bytes of payload data per packet and a total of 107 packets to deliver the 120 KB application message.
So far so good, but the packet loss probability for each individual packet is 1%. As a result, if we fire off all 107 packets over the unreliable channel, we are now looking at a very high probability of losing at least one of them en route! What will happen in this case? Even if all but one of the packets make it, the entire message will be dropped.
To address this, an application has two strategies: it can add a retransmit strategy (based on count or timeout), and it can decrease the size of the transferred message. In fact, for best results, it should do both.
Packet-loss rates and latency between the peers are unpredictable and vary based on current network weather. As a result, there is no one single and optimal setting for the retransmit count or timeout values. To deliver the best results over an unreliable channel, keep the messages as small as possible.
Implementing a low-latency, peer-to-peer transport is a nontrivial engineering challenge: there are NAT traversals and connectivity checks, signaling, security, congestion control, and myriad other details to take care of. WebRTC handles all of the above and more, on our behalf, which is why it is arguably one of the most significant additions to the web platform since its inception. In fact, it’s not just the individual pieces offered by WebRTC, but the fact that all the components work together to deliver a simple and unified API for building peer-to-peer applications in the browser.
However, even with all the built-in services, designing efficient and high-performance peer-to-peer applications still requires a great amount of careful thought and planning: peer-to-peer does not mean high performance on its own. If anything, the increased variability in bandwidth and latency between the peers, and the high demands of media transfers, as well as the peculiarities of unreliable delivery, make it an even harder engineering challenge.
Peer-to-peer audio and video streaming are one of the central use cases for WebRTC: getUserMedia API enables the application to acquire the media streams, and the built-in audio and video engines handle the optimization, error recovery, and synchronization between streams. However, it is important to keep in mind that even with aggressive optimization and compression, audio and video delivery are still likely to be constrained by latency and bandwidth:
The good news is that the average bandwidth capacity is continuing to grow around the world: users are switching to broadband, and 3.5G+ and 4G adoption is ramping up. However, even with optimistic growth projections, while HD streaming is now becoming viable, it is not a guarantee! Similarly, latency is a perennial problem, especially for real-time delivery, and doubly so for mobile clients. 4G will definitely help, but 3G networks are not going away anytime soon either.
To complicate matters further, the connections offered by most ISPs and mobile carriers are not symmetric: most users have significantly higher downlink throughput than uplink throughput. In fact, 10-to-1 relationships are not uncommon—e.g., 10 Mbps down, 1 Mbps up.
The net result is that you should not be surprised to see a single, peer-to-peer audio and video stream saturate a significant amount of users’ bandwidth, especially for mobile clients. Thinking of providing a multiparty stream? You will likely need to do some careful planning for the amount of available bandwidth:
The good news is that the WebRTC audio and video engines work together with the underlying network transport to probe the available bandwidth and optimize delivery of the media streams. However, DataChannel transfers require additional application logic: the application must monitor the amount of buffered data and be ready to adjust as needed.
When acquiring the audio and video streams, make sure to set the video constraints to match the use case; see Acquiring Audio and Video with getUserMedia.
A single peer-to-peer connection with bidirectional HD media streams can easily use up a significant fraction of users’ bandwidth. As a result, multiparty applications should carefully consider the architecture (Figure 18-17) of how the individual streams are aggregated and distributed between the peers.
One-to-one connections are easy to manage and deploy: the peers talk directly to each other and no further optimization is required. However, extending the same strategy to an N-way call, where each peer is responsible for connecting to every other party (a mesh network) would result in 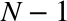 connections for each peer, and a total of
connections for each peer, and a total of 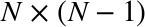 connections! If bandwidth is at a premium, as it often is due to the much lower uplink speeds, then this type of architecture will quickly saturate most users’ links with just a few participants.
connections! If bandwidth is at a premium, as it often is due to the much lower uplink speeds, then this type of architecture will quickly saturate most users’ links with just a few participants.
While mesh networks are easy to set up, they are often inefficient for multiparty systems. To address this, an alternative strategy is to use a “star” topology instead, where the individual peers connect to a “supernode,” which is then responsible for distributing the streams to all connected parties. This way only one peer has to pay the cost of handling and distributing  streams, and everyone else talks directly to the supernode.
streams, and everyone else talks directly to the supernode.
A supernode can be another peer, or it can be a dedicated service specifically optimized for processing and distributing real-time data; which strategy is more appropriate depends on the context and the application. In the simplest case, the initiator can act as a supernode—simple, and it might just work. A better strategy might be to pick the peer with the best available throughput, but that also requires additional “election” and signaling mechanisms.
The criteria and the process for picking the supernode is left up to the application, which by itself can be a big engineering challenge. WebRTC does not provide any infrastructure to assist in this process.
Finally, the supernode could be a dedicated and even a third-party service. WebRTC enables peer-to-peer communication, but this does not mean that there is no room for centralized infrastructure! Individual peers can establish peer connections with a proxy server and still get the benefit of both the WebRTC transport infrastructure and the additional services offered by the server.
Many existing videoconferencing solutions (e.g., Google’s Hangouts) rely on “proxy servers” to aggregate the individual media streams, composite them, and then distribute the optimized versions to all the connected parties. Delivering a single stream reduces the amount of bandwidth and the amount of CPU and GPU resources required by each peer; each client sees only one stream instead of  !
!
Similarly, a game server can aggregate updates from all the players and filter and distribute only the necessary updates; e.g., it won’t send updates for players that are out of view or otherwise don’t affect the other player.
Two-party streaming is simple and efficient to deploy, whereas multiparty architectures require a lot more thought and planning. As much as WebRTC is about enabling direct peer-to-peer communication, it is also a catalyst for a wide variety of services, both commercial and open source, that will help make it more efficient and feature-rich.
In addition to planning and anticipating the bandwidth requirements of individual peer connections, every WebRTC application will require some centralized infrastructure for signaling, NAT and firewall traversal, identity verification, and other additional services offered by the application.
WebRTC defers all signaling to the application, which means that the application must at a minimum provide the ability to send and receive messages to the other peer. The volume of signaling data sent will vary by the number of users, the protocol, encoding of the data, and frequency of updates. Similarly the latency of the signaling service will have a great impact on the “call setup” time and other signaling exchanges.
Due to the prevalence of NATs and firewalls, most WebRTC applications will require a STUN server to perform the necessary IP lookups to establish the peer-to-peer connection. The good news is that the STUN server is used only for connection setup, but nonetheless, it must speak the STUN protocol and be provisioned to handle the necessary query load.
Even with STUN in place, 8%–10% of peer-to-peer connections will likely fail due to the peculiarities of their network policies. For example, a network administrator could block UDP outright for all the users on the network; see STUN and TURN in Practice. As a result, to deliver a reliable experience, the application may also need a TURN server to relay the data between the peers.
Multiparty services may require centralized infrastructure to help optimize the delivery of many streams and provide additional services as part of the RTC experience. In some ways, multiparty gateways serve the same role as TURN but in this case for different reasons. Having said that, unlike TURN servers, which act as simple packet proxies, a “smart proxy” may require significantly more CPU and GPU resources to process each individual stream prior to forwarding the final output to each connected party.
WebRTC audio and video engines will dynamically adjust the bitrate of the media streams to match the conditions of the network link between the peers. The application can set and update the media constraints (e.g., video resolution, framerate, and so on), and the engines do the rest—this part is easy.
Unfortunately, the same can’t be said for DataChannel, which is designed to transport arbitrary application data. Similar to WebSocket, the DataChannel API will accept binary and UTF-8–encoded application data, but it does not apply any further processing to reduce the size of transferred data: it is the responsibility of the WebRTC application to optimize the binary payloads and compress the UTF-8 content.
Further, unlike WebSocket, which runs on top of a reliable and in-order transport, WebRTC applications must account for both the extra overhead incurred by the UDP, DTLS, and SCTP protocols and the peculiarities of data delivery over a partially reliable transport; see Partially Reliable Delivery and Message Size.
Peer-to-peer architectures pose their own unique set of performance challenges for the application. Direct, one-to-one communication is relatively straightforward, but things get much more complex when more than two parties are involved, at least as far as performance is concerned. A short list of criteria to put on the agenda:
The animal on the cover of High Performance Browser Networking is a Madagascar harrier (Circus macrosceles). The harrier is primarily found on the Comoro Islands and Madagascar, though due to various threats, including habitat loss and degradation, populations are declining. Recently found to be rarer than previously thought, this bird’s broad distribution occurs at low densities with a total population estimated in the range of 250–500 mature individuals.
Associated with the wetlands of Madagascar, the harrier’s favored hunting grounds are primarily vegetation-lined lakes, marshes, coastal wetlands, and rice paddies. The harrier hunts small invertebrates and insects, including small birds, snakes, lizards, rodents, and domestic chickens. Its appetite for domestic chickens (accounting for only 1% of the species’ prey) is cause for persecution of the species by the local people.
During the dry season—late August and September—the harrier begins its mating season. By the start of the rainy season, incubation (~32–34 days) has passed and nestlings fledge at around 42–45 days. However, the harrier reproduction rates remain low, averaging at 0.9 young fledged per breeding attempt and a success rate of three-quarter of nests. This poor nesting success—owing partly to egg-hunting and nest destruction by local people—can also be attributed to regular and comprehensive burning of grasslands and marshes for the purposes of fresh grazing and land clearing, which often coincides with the species’ breeding season. Populations continue to dwindle as interests conflict: the harrier requiring undisturbed and unaltered savannah, and increasing human land-use activities in many areas of Madagascar.
Several conservation actions proposed include performing further surveys to confirm the size of the total population; studying the population’s dynamics; obtaining more accurate information regarding nesting success; reducing burning at key sites, especially during breeding season; and identifying and establishing protected areas of key nesting sites.
The cover image is from Histoire Naturelle, Ornithologie, Bernard Direxit. The cover font is Adobe ITC Garamond. The text font is Adobe Minion Pro; the heading font is Adobe Myriad Condensed; and the code font is Dalton Maag’s Ubuntu Mono.
| Revision History | |
| 2013-09-09 | First release |
| Revision History | |
| 2014-05-23 | Second release |
| 2015-09-16 | Third release |
Copyright © 2013 Ilya Grigorik
O’Reilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://safaribooksonline.com). For more information, contact our corporate/institutional sales department: 800-998-9938 or corporate@oreilly.com.
Nutshell Handbook, the Nutshell Handbook logo, and the O’Reilly logo are registered trademarks of O’Reilly Media, Inc. High-Performance Browser Networking, the image of a Madagascar harrier, and related trade dress are trademarks of O’Reilly Media, Inc.
Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and O’Reilly Media, Inc., was aware of a trademark claim, the designations have been printed in caps or initial caps.
1005 Gravenstein Highway North
Sebastopol, CA 95472
“Good developers know how things work. Great developers know why things work.”
We all resonate with this adage. We want to be that person who understands and can explain the underpinning of the systems we depend on. And yet, if you’re a web developer, you might be moving in the opposite direction.
Web development is becoming more and more specialized. What kind of web developer are you? Frontend? Backend? Ops? Big data analytics? UI/UX? Storage? Video? Messaging? I would add “Performance Engineer” making that list of possible specializations even longer.
It’s hard to balance studying the foundations of the technology stack with the need to keep up with the latest innovations. And yet, if we don’t understand the foundation our knowledge is hollow, shallow. Knowing how to use the topmost layers of the technology stack isn’t enough. When the complex problems need to be solved, when the inexplicable happens, the person who understands the foundation leads the way.
That’s why High Performance Browser Networking is an important book. If you’re a web developer, the foundation of your technology stack is the Web and the myriad of networking protocols it rides on: TCP, TLS, UDP, HTTP, and many others. Each of these protocols has its own performance characteristics and optimizations, and to build high performance applications you need to understand why the network behaves the way it does.
Thank goodness you’ve found your way to this book. I wish I had this book when I started web programming. I was able to move forward by listening to people who understood the why of networking and read specifications to fill in the gaps. High Performance Browser Networking combines the expertise of a networking guru, Ilya Grigorik, with the necessary information from the many relevant specifications, all woven together in one place.
In High Performance Browser Networking, Ilya explains many whys of networking: Why latency is the performance bottleneck. Why TCP isn’t always the best transport mechanism and UDP might be your better choice. Why reusing connections is a critical optimization. He then goes even further by providing specific actions for improving networking performance. Want to reduce latency? Terminate sessions at a server closer to the client. Want to increase connection reuse? Enable connection keep-alive. The combination of understanding what to do and why it matters turns this knowledge into action.
Ilya explains the foundation of networking and builds on that to introduce the latest advances in protocols and browsers. The benefits of HTTP/2 are explained. XHR is reviewed and its limitations motivate the introduction of Cross-Origin Resource Sharing. Server-Sent Events, WebSockets, and WebRTC are also covered, bringing us up to date on the latest in browser networking.
Viewing the foundation and latest advances in networking from the perspective of performance is what ties the book together. Performance is the context that helps us see the why of networking and translate that into how it affects our website and our users. It transforms abstract specifications into tools that we can wield to optimize our websites and create the best user experience possible. That’s important. That’s why you should read this book.
The web browser is the most widespread deployment platform available to developers today: it is installed on every smartphone, tablet, laptop, desktop, and every other form factor in between. In fact, current cumulative industry growth projections put us on track for 20 billion connected devices by 2020—each with a browser, and at the very least, WiFi or a cellular connection. The type of platform, manufacturer of the device, or the version of the operating system do not matter—each and every device will have a web browser, which by itself is getting more feature rich each day.
The browser of yesterday looks nothing like what we now have access to, thanks to all the recent innovations: HTML and CSS form the presentation layer, JavaScript is the new assembly language of the Web, and new HTML5 APIs are continuing to improve and expose new platform capabilities for delivering engaging, high-performance applications. There is simply no other technology, or platform, that has ever had the reach or the distribution that is made available to us today when we develop for the browser. And where there is big opportunity, innovation always follows.
In fact, there is no better example of the rapid progress and innovation than the networking infrastructure within the browser. Historically, we have been restricted to simple HTTP request-response interactions, and today we have mechanisms for efficient streaming, bidirectional and real-time communication, ability to deliver custom application protocols, and even peer-to-peer videoconferencing and data delivery directly between the peers—all with a few dozen lines of JavaScript.
The net result? Billions of connected devices, a swelling userbase for existing and new online services, and high demand for high-performance web applications. Speed is a feature, and in fact, for some applications it is the feature, and delivering a high-performance web application requires a solid foundation in how the browser and the network interact. That is the subject of this book.
Our goal is to cover what every developer should know about the network: what protocols are being used and their inherent limitations, how to best optimize your applications for the underlying network, and what networking capabilities the browser offers and when to use them.
In the process, we will look at the internals of TCP, UDP, and TLS protocols, and how to optimize our applications and infrastructure for each one. Then we’ll take a deep dive into how the wireless and mobile networks work under the hood—this radio thing, it’s very different—and discuss its implications for how we design and architect our applications. Finally, we will dissect how the HTTP protocol works under the hood and investigate the many new and exciting networking capabilities in the browser:
Understanding how the individual bits are delivered, and the properties of each transport and protocol in use are essential knowledge for delivering high-performance applications. After all, if our applications are blocked waiting on the network, then no amount of rendering, JavaScript, or any other form of optimization will help! Our goal is to eliminate this wait time by getting the best possible performance from the network.
High-Performance Browser Networking will be of interest to anyone interested in optimizing the delivery and performance of her applications, and more generally, curious minds that are not satisfied with a simple checklist but want to know how the browser and the underlying protocols actually work under the hood. The “how” and the “why” go hand in hand: we’ll cover practical advice about configuration and architecture, and we’ll also explore the trade-offs and the underlying reasons for each optimization.
Our primary focus is on the protocols and their properties with respect to applications running in the browser. However, all the discussions on TCP, UDP, TLS, HTTP, and just about every other protocol we will cover are also directly applicable to native applications, regardless of the platform.
The following typographical conventions are used in this book:
Constant width
Constant width bold
Constant width italic
This icon signifies a tip, suggestion, or general note.
This icon indicates a warning or caution.
Safari Books Online is an on-demand digital library that delivers expert content in both book and video form from the world’s leading authors in technology and business.
Technology professionals, software developers, web designers, and business and creative professionals use Safari Books Online as their primary resource for research, problem solving, learning, and certification training.
Safari Books Online offers a range of product mixes and pricing programs for organizations, government agencies, and individuals. Subscribers have access to thousands of books, training videos, and prepublication manuscripts in one fully searchable database from publishers like O’Reilly Media, Prentice Hall Professional, Addison-Wesley Professional, Microsoft Press, Sams, Que, Peachpit Press, Focal Press, Cisco Press, John Wiley & Sons, Syngress, Morgan Kaufmann, IBM Redbooks, Packt, Adobe Press, FT Press, Apress, Manning, New Riders, McGraw-Hill, Jones & Bartlett, Course Technology, and dozens more. For more information about Safari Books Online, please visit us online.
Please address comments and questions concerning this book to the publisher:
| O’Reilly Media, Inc. |
| 1005 Gravenstein Highway North |
| Sebastopol, CA 95472 |
| 800-998-9938 (in the United States or Canada) |
| 707-829-0515 (international or local) |
| 707-829-0104 (fax) |
We have a web page for this book, where we list errata, examples, and any additional information. You can access this page at http://oreil.ly/high-performance-browser.
To comment or ask technical questions about this book, send email to bookquestions@oreilly.com.
For more information about our books, courses, conferences, and news, see our website at http://www.oreilly.com.
Find us on Facebook: http://facebook.com/oreilly
Follow us on Twitter: http://twitter.com/oreillymedia
Watch us on YouTube: http://www.youtube.com/oreillymedia
The emergence and the fast growth of the web performance optimization (WPO) industry within the past few years is a telltale sign of the growing importance and demand for speed and faster user experiences by the users. And this is not simply a psychological need for speed in our ever accelerating and connected world, but a requirement driven by empirical results, as measured with respect to the bottom-line performance of the many online businesses:
Simply put, speed is a feature. And to deliver it, we need to understand the many factors and fundamental limitations that are at play. In this chapter, we will focus on the two critical components that dictate the performance of all network traffic: latency and bandwidth (Figure 1-1).
Armed with a better understanding of how bandwidth and latency work together, we will then have the tools to dive deeper into the internals and performance characteristics of TCP, UDP, and all application protocols above them.
Latency is the time it takes for a message, or a packet, to travel from its point of origin to the point of destination. That is a simple and useful definition, but it often hides a lot of useful information—every system contains multiple sources, or components, contributing to the overall time it takes for a message to be delivered, and it is important to understand what these components are and what dictates their performance.
Let’s take a closer look at some common contributing components for a typical router on the Internet, which is responsible for relaying a message between the client and the server:
The total latency between the client and the server is the sum of all the delays just listed. Propagation time is dictated by the distance and the medium through which the signal travels—as we will see, the propagation speed is usually within a small constant factor of the speed of light. On the other hand, transmission delay is dictated by the available data rate of the transmitting link and has nothing to do with the distance between the client and the server. As an example, let’s assume we want to transmit a 10 Mb file over two links: 1 Mbps and 100 Mbps. It will take 10 seconds to put the entire file on the “wire” over the 1 Mbps link and only 0.1 seconds over the 100 Mbps link.
Next, once the packet arrives at the router, the router must examine the packet header to determine the outgoing route and may run other checks on the data—this takes time as well. Much of this logic is now often done in hardware, so the delays are very small, but they do exist. And, finally, if the packets are arriving at a faster rate than the router is capable of processing, then the packets are queued inside an incoming buffer. The time data spends queued inside the buffer is, not surprisingly, known as queuing delay.
Each packet traveling over the network will incur many instances of each of these delays. The farther the distance between the source and destination, the more time it will take to propagate. The more intermediate routers we encounter along the way, the higher the processing and transmission delays for each packet. Finally, the higher the load of traffic along the path, the higher the likelihood of our packet being delayed inside an incoming buffer.
As Einstein outlined in his theory of special relativity, the speed of light is the maximum speed at which all energy, matter, and information can travel. This observation places a hard limit, and a governor, on the propagation time of any network packet.
The good news is the speed of light is high: 299,792,458 meters per second, or 186,282 miles per second. However, and there is always a however, that is the speed of light in a vacuum. Instead, our packets travel through a medium such as a copper wire or a fiber-optic cable, which will slow down the signal (Table 1-1). This ratio of the speed of light and the speed with which the packet travels in a material is known as the refractive index of the material. The larger the value, the slower light travels in that medium.
The typical refractive index value of an optical fiber, through which most of our packets travel for long-distance hops, can vary between 1.4 to 1.6—slowly but surely we are making improvements in the quality of the materials and are able to lower the refractive index. But to keep it simple, the rule of thumb is to assume that the speed of light in fiber is around 200,000,000 meters per second, which corresponds to a refractive index of ~1.5. The remarkable part about this is that we are already within a small constant factor of the maximum speed! An amazing engineering achievement in its own right.
| Route | Distance | Time, light in vacuum | Time, light in fiber | Round-trip time (RTT) in fiber |
New York to San Francisco | 4,148 km | 14 ms | 21 ms | 42 ms |
New York to London | 5,585 km | 19 ms | 28 ms | 56 ms |
New York to Sydney | 15,993 km | 53 ms | 80 ms | 160 ms |
Equatorial circumference | 40,075 km | 133.7 ms | 200 ms | 200 ms |
The speed of light is fast, but it nonetheless takes 160 milliseconds to make the round-trip (RTT) from New York to Sydney. In fact, the numbers in Table 1-1 are also optimistic in that they assume that the packet travels over a fiber-optic cable along the great-circle path (the shortest distance between two points on the globe) between the cities. In practice, no such cable is available, and the packet would take a much longer route between New York and Sydney. Each hop along this route will introduce additional routing, processing, queuing, and transmission delays. As a result, the actual RTT between New York and Sydney, over our existing networks, works out to be in the 200–300 millisecond range. All things considered, that still seems pretty fast, right?
We are not accustomed to measuring our everyday encounters in milliseconds, but studies have shown that most of us will reliably report perceptible “lag” once a delay of over 100–200 milliseconds is introduced into the system. Once the 300 millisecond delay threshold is exceeded, the interaction is often reported as “sluggish,” and at the 1,000 milliseconds (1 second) barrier, many users have already performed a mental context switch while waiting for the response—anything from a daydream to thinking about the next urgent task.
The conclusion is simple: to deliver the best experience and to keep our users engaged in the task at hand, we need our applications to respond within hundreds of milliseconds. That doesn’t leave us, and especially the network, with much room for error. To succeed, network latency has to be carefully managed and be an explicit design criteria at all stages of development.
Content delivery network (CDN) services provide many benefits, but chief among them is the simple observation that distributing the content around the globe, and serving that content from a nearby location to the client, will allow us to significantly reduce the propagation time of all the data packets.
We may not be able to make the packets travel faster, but we can reduce the distance by strategically positioning our servers closer to the users! Leveraging a CDN to serve your data can offer significant performance benefits.
Ironically, it is often the last few miles, not the crossing of oceans or continents, where significant latency is introduced: the infamous last-mile problem. To connect your home or office to the Internet, your local ISP needs to route the cables throughout the neighborhood, aggregate the signal, and forward it to a local routing node. In practice, depending on the type of connectivity, routing methodology, and deployed technology, these first few hops can take tens of milliseconds just to get to your ISP’s main routers! According to the “Measuring Broadband America” report conducted by the Federal Communications Commission in early 2013, during peak hours:
Fiber-to-the-home, on average, has the best performance in terms of latency, with 18 ms average during the peak period, with cable having 26 ms latency and DSL 44 ms latency.
— FCC February 2013
This translates into 18–44 ms of latency just to the closest measuring node within the ISP’s core network, before the packet is even routed to its destination! The FCC report is focused on the United States, but last-mile latency is a challenge for all Internet providers, regardless of geography. For the curious, a simple traceroute can often tell you volumes about the topology and performance of your Internet provider.
$> traceroute google.comtraceroute to google.com (74.125.224.102), 64 hops max, 52 byte packets 1 10.1.10.1 (10.1.10.1) 7.120 ms 8.925 ms 1.199 ms
In the previous example, the packet started in the city of Sunnyvale, bounced to Santa Clara, then Oakland, returned to San Jose, got routed to the “529 Bryant” datacenter, at which point it was routed toward Google and arrived at its destination on the 11th hop. This entire process took, on average, 18 milliseconds. Not bad, all things considered, but in the same time the packet could have traveled across most of the continental USA!
The last-mile latency can vary wildly based on your provider, the deployed technology, topology of the network, and even the time of day. As an end user, if you are looking to improve your web browsing speeds, low latency is worth optimizing for when picking a local ISP.
Latency, not bandwidth, is the performance bottleneck for most websites! To understand why, we need to understand the mechanics of TCP and HTTP protocols—subjects we’ll be covering in subsequent chapters. However, if you are curious, feel free to skip ahead to More Bandwidth Doesn’t Matter (Much).
An optical fiber acts as a simple “light pipe,” slightly thicker than a human hair, designed to transmit light between the two ends of the cable. Metal wires are also used but are subject to higher signal loss, electromagnetic interference, and higher lifetime maintenance costs. Chances are, your packets will travel over both types of cable, but for any long-distance hops, they will be transmitted over a fiber-optic link.
Optical fibers have a distinct advantage when it comes to bandwidth because each fiber can carry many different wavelengths (channels) of light through a process known as wavelength-division multiplexing (WDM). Hence, the total bandwidth of a fiber link is the multiple of per-channel data rate and the number of multiplexed channels.
As of early 2010, researchers have been able to multiplex over 400 wavelengths with the peak capacity of 171 Gbit/s per channel, which translates to over 70 Tbit/s of total bandwidth for a single fiber link! We would need thousands of copper wire (electrical) links to match this throughput. Not surprisingly, most long-distance hops, such as subsea data transmission between continents, is now done over fiber-optic links. Each cable carries several strands of fiber (four strands is a common number), which translates into bandwidth capacity in hundreds of terabits per second for each cable.
The backbones, or the fiber links, that form the core data paths of the Internet are capable of moving hundreds of terabits per second. However, the available capacity at the edges of the network is much, much less, and varies wildly based on deployed technology: dial-up, DSL, cable, a host of wireless technologies, fiber-to-the-home, and even the performance of the local router. The available bandwidth to the user is a function of the lowest capacity link between the client and the destination server (Figure 1-1).
Akamai Technologies operates a global CDN, with servers positioned around the globe, and provides free quarterly reports at Akamai’s website on average broadband speeds, as seen by their servers. Table 1-2 captures the macro bandwidth trends as of Q1 2013.
| Rank | Country | Average Mbps | Year-over-year change |
- | Global | 3.1 | 17% |
1 | South Korea | 14.2 | -10% |
2 | Japan | 11.7 | 6.8% |
3 | Hong Kong | 10.9 | 16% |
4 | Switzerland | 10.1 | 24% |
5 | Netherlands | 9.9 | 12% |
… | |||
9 | United States | 8.6 | 27% |
The preceding data excludes traffic from mobile carriers, a topic we will come back to later to examine in closer detail. For now, it should suffice to say that mobile speeds are highly variable and generally slower. However, even with that in mind, the average global broadband bandwidth in early 2013 was just 3.1 Mbps! South Korea led the world with a 14.2 Mbps average throughput, and United States came in 9th place with 8.6 Mbps.
As a reference point, streaming an HD video can require anywhere from 2 to 10 Mbps depending on resolution and the codec. So an average user can stream a lower-resolution video stream at the network edge, but doing so would consume much of their link capacity—not a very promising story for a household with multiple users.
Figuring out where the bandwidth bottleneck is for any given user is often a nontrivial but important exercise. Once again, for the curious, there are a number of online services, such as speedtest.net operated by Ookla (Figure 1-2), which provide upstream and downstream tests to some local server—we will see why picking a local server is important in our discussion on TCP. Running a test on one of these services is a good way to check that your connection meets the advertised speeds of your local ISP.
However, while a high-bandwidth link to your ISP is desirable, it is also not a guarantee of stable end-to-end performance. The network could be congested at any intermediate node at some point in time due to high demand, hardware failures, a concentrated network attack, or a host of other reasons. High variability of throughput and latency performance is an inherent property of our data networks—predicting, managing, and adapting to the continuously changing “network weather” is a complex task.
Our demand for higher bandwidth is growing fast, in large part due to the rising popularity of streaming video, which is now responsible for well over half of all Internet traffic. The good news is, while it may not be cheap, there are multiple strategies available for us to grow the available capacity: we can add more fibers into our fiber-optic links, we can deploy more links across the congested routes, or we can improve the WDM techniques to transfer more data through existing links.
TeleGeography, a telecommunications market research and consulting firm, estimates that as of 2011, we are using, on average, just 20% of the available capacity of the deployed subsea fiber links. Even more importantly, between 2007 and 2011, more than half of all the added capacity of the trans-Pacific cables was due to WDM upgrades: same fiber links, better technology on both ends to multiplex the data. Of course, we cannot expect these advances to go on indefinitely, as every medium reaches a point of diminishing returns. Nonetheless, as long as economics of the enterprise permit, there is no fundamental reason why bandwidth throughput cannot be increased over time—if all else fails, we can add more fiber links.
Improving latency, on the other hand, is a very different story. The quality of the fiber links could be improved to get us a little closer to the speed of light: better materials with lower refractive index and faster routers along the way. However, given that our current speeds are within ~1.5 of the speed of light, the most we can expect from this strategy is just a modest 30% improvement. Unfortunately, there is simply no way around the laws of physics: the speed of light places a hard limit on the minimum latency.
Alternatively, since we can’t make light travel faster, we can make the distance shorter—the shortest distance between any two points on the globe is defined by the great-circle path between them. However, laying new cables is also not always possible due to the constraints imposed by the physical terrain, social and political reasons, and of course, the associated costs.
As a result, to improve performance of our applications, we need to architect and optimize our protocols and networking code with explicit awareness of the limitations of available bandwidth and the speed of light: we need to reduce round trips, move the data closer to the client, and build applications that can hide the latency through caching, pre-fetching, and a variety of similar techniques, as explained in subsequent chapters.
At the heart of the Internet are two protocols, IP and TCP. The IP, or Internet Protocol, is what provides the host-to-host routing and addressing, and TCP, or Transmission Control Protocol, is what provides the abstraction of a reliable network running over an unreliable channel. TCP/IP is also commonly referred to as the Internet Protocol Suite and was first proposed by Vint Cerf and Bob Kahn in their 1974 paper titled “A Protocol for Packet Network Intercommunication.”
The original proposal (RFC 675) was revised several times, and in 1981 the v4 specification of TCP/IP was published not as one, but as two separate RFCs:
Since then, there have been a number of enhancements proposed and made to TCP, but the core operation has not changed significantly. TCP quickly replaced previous protocols and is now the protocol of choice for many of the most popular applications: World Wide Web, email, file transfers, and many others.
TCP provides an effective abstraction of a reliable network running over an unreliable channel, hiding most of the complexity of network communication from our applications: retransmission of lost data, in-order delivery, congestion control and avoidance, data integrity, and more. When you work with a TCP stream, you are guaranteed that all bytes sent will be identical with bytes received and that they will arrive in the same order to the client. As such, TCP is optimized for accurate delivery, rather than a timely one. This, as it turns out, also creates some challenges when it comes to optimizing for web performance in the browser.
The HTTP standard does not specify TCP as the only transport protocol. If we wanted, we could deliver HTTP via a datagram socket (User Datagram Protocol or UDP), or any other transport protocol of our choice, but in practice all HTTP traffic on the Internet today is delivered via TCP due to the many great features it provides out of the box.
Because of this, understanding some of the core mechanisms of TCP is essential knowledge for building an optimized web experience. Chances are you won’t be working with TCP sockets directly in your application, but the design choices you make at the application layer will dictate the performance of TCP and the underlying network over which your application is delivered.
All TCP connections begin with a three-way handshake (Figure 2-1). Before the client or the server can exchange any application data, they must agree on starting packet sequence numbers, as well as a number of other connection specific variables, from both sides. The sequence numbers are picked randomly from both sides for security reasons.
x and sends a SYN packet, which may also include additional TCP flags and options.
x by one, picks own random sequence number y, appends its own set of flags and options, and dispatches the response.
x and y by one and completes the handshake by dispatching the last ACK packet in the handshake.
Once the three-way handshake is complete, the application data can begin to flow between the client and the server. The client can send a data packet immediately after the ACK packet, and the server must wait for the ACK before it can dispatch any data. This startup process applies to every TCP connection and carries an important implication for performance of all network applications using TCP: each new connection will have a full roundtrip of latency before any application data can be transferred.
For example, if our client is in New York, the server is in London, and we are starting a new TCP connection over a fiber link, then the three-way handshake will take a minimum of 56 milliseconds (Table 1-1): 28 milliseconds to propagate the packet in one direction, after which it must return back to New York. Note that bandwidth of the connection plays no role here. Instead, the delay is governed by the latency between the client and the server, which in turn is dominated by the propagation time between New York and London.
The delay imposed by the three-way handshake makes new TCP connections expensive to create, and is one of the big reasons why connection reuse is a critical optimization for any application running over TCP.
In early 1984, John Nagle documented a condition known as “congestion collapse,” which could affect any network with asymmetric bandwidth capacity between the nodes:
Congestion control is a recognized problem in complex networks. We have discovered that the Department of Defense’s Internet Protocol (IP), a pure datagram protocol, and Transmission Control Protocol (TCP), a transport layer protocol, when used together, are subject to unusual congestion problems caused by interactions between the transport and datagram layers. In particular, IP gateways are vulnerable to a phenomenon we call “congestion collapse”, especially when such gateways connect networks of widely different bandwidth…
Should the roundtrip time exceed the maximum retransmission interval for any host, that host will begin to introduce more and more copies of the same datagrams into the net. The network is now in serious trouble. Eventually all available buffers in the switching nodes will be full and packets must be dropped. The roundtrip time for packets that are delivered is now at its maximum. Hosts are sending each packet several times, and eventually some copy of each packet arrives at its destination. This is congestion collapse.
This condition is stable. Once the saturation point has been reached, if the algorithm for selecting packets to be dropped is fair, the network will continue to operate in a degraded condition.
— John Nagle RFC 896
The report concluded that congestion collapse had not yet become a problem for ARPANET because most nodes had uniform bandwidth, and the backbone had substantial excess capacity. However, neither of these assertions held true for long. In 1986, as the number (5,000+) and the variety of nodes on the network grew, a series of congestion collapse incidents swept throughout the network—in some cases the capacity dropped by a factor of 1,000 and the network became unusable.
To address these issues, multiple mechanisms were implemented in TCP to govern the rate with which the data can be sent in both directions: flow control, congestion control, and congestion avoidance.
Advanced Research Projects Agency Network (ARPANET) was the precursor to the modern Internet and the world’s first operational packet-switched network. The project was officially launched in 1969, and in 1983 the TCP/IP protocols replaced the earlier NCP (Network Control Program) as the principal communication protocols. The rest, as they say, is history.
Flow control is a mechanism to prevent the sender from overwhelming the receiver with data it may not be able to process—the receiver may be busy, under heavy load, or may only be willing to allocate a fixed amount of buffer space. To address this, each side of the TCP connection advertises (Figure 2-2) its own receive window (rwnd), which communicates the size of the available buffer space to hold the incoming data.
When the connection is first established, both sides initiate their rwnd values by using their system default settings. A typical web page will stream the majority of the data from the server to the client, making the client’s window the likely bottleneck. However, if a client is streaming large amounts of data to the server, such as in the case of an image or a video upload, then the server receive window may become the limiting factor.
If, for any reason, one of the sides is not able to keep up, then it can advertise a smaller window to the sender. If the window reaches zero, then it is treated as a signal that no more data should be sent until the existing data in the buffer has been cleared by the application layer. This workflow continues throughout the lifetime of every TCP connection: each ACK packet carries the latest rwnd value for each side, allowing both sides to dynamically adjust the data flow rate to the capacity and processing speed of the sender and receiver.
Despite the presence of flow control in TCP, network congestion collapse became a real issue in the mid to late 1980s. The problem was that flow control prevented the sender from overwhelming the receiver, but there was no mechanism to prevent either side from overwhelming the underlying network: neither the sender nor the receiver knows the available bandwidth at the beginning of a new connection, and hence need a mechanism to estimate it and also to adapt their speeds to the continuously changing conditions within the network.
To illustrate one example where such an adaptation is beneficial, imagine you are at home and streaming a large video from a remote server that managed to saturate your downlink to deliver the maximum quality experience. Then another user on your home network opens a new connection to download some software updates. All of the sudden, the amount of available downlink bandwidth to the video stream is much less, and the video server must adjust its data rate—otherwise, if it continues at the same rate, the data will simply pile up at some intermediate gateway and packets will be dropped, leading to inefficient use of the network.
In 1988, Van Jacobson and Michael J. Karels documented several algorithms to address these problems: slow-start, congestion avoidance, fast retransmit, and fast recovery. All four quickly became a mandatory part of the TCP specification. In fact, it is widely held that it was these updates to TCP that prevented an Internet meltdown in the ’80s and the early ’90s as the traffic continued to grow at an exponential rate.
To understand slow-start, it is best to see it in action. So, once again, let us come back to our client, who is located in New York, attempting to retrieve a file from a server in London. First, the three-way handshake is performed, during which both sides advertise their respective receive window (rwnd) sizes within the ACK packets (Figure 2-2). Once the final ACK packet is put on the wire, we can start exchanging application data.
The only way to estimate the available capacity between the client and the server is to measure it by exchanging data, and this is precisely what slow-start is designed to do. To start, the server initializes a new congestion window (cwnd) variable per TCP connection and sets its initial value to a conservative, system-specified value (initcwnd on Linux).
The cwnd variable is not advertised or exchanged between the sender and receiver—in this case, it will be a private variable maintained by the server in London. Further, a new rule is introduced: the maximum amount of data in flight (not ACKed) between the client and the server is the minimum of the rwnd and cwnd variables. So far so good, but how do the server and the client determine optimal values for their congestion window sizes? After all, network conditions vary all the time, even between the same two network nodes, as we saw in the earlier example, and it would be great if we could use the algorithm without having to hand-tune the window sizes for each connection.
The solution is to start slow and to grow the window size as the packets are acknowledged: slow-start! Originally, the cwnd start value was set to 1 network segment; RFC 2581 updated this value to a maximum of 4 segments in April 1999, and most recently the value was increased once more to 10 segments by RFC 6928 in April 2013.
The maximum amount of data in flight for a new TCP connection is the minimum of the rwnd and cwnd values; hence the server can send up to four network segments to the client, at which point it must stop and wait for an acknowledgment. Then, for every received ACK, the slow-start algorithm indicates that the server can increment its cwnd window size by one segment—for every ACKed packet, two new packets can be sent. This phase of the TCP connection is commonly known as the “exponential growth” algorithm (Figure 2-3), as the client and the server are trying to quickly converge on the available bandwidth on the network path between them.
So why is slow-start an important factor to keep in mind when we are building applications for the browser? Well, HTTP and many other application protocols run over TCP, and no matter the available bandwidth, every TCP connection must go through the slow-start phase—we cannot use the full capacity of the link immediately!
Instead, we start with a small congestion window and double it for every roundtrip—i.e., exponential growth. As a result, the time required to reach a specific throughput target is a function (Equation 2-1) of both the roundtrip time between the client and server and the initial congestion window size.
For a hands-on example of slow-start impact, let’s assume the following scenario:
We will be using the old (RFC 2581) value of four network segments for the initial congestion window in this and the following examples, as it is still the most common value for most servers. Except, you won’t make this mistake—right? The following examples should serve as good motivation for why you should update your servers!
Despite the 64 KB receive window size, the throughput of a new TCP connection is initially limited by the size of the congestion window. In fact, to reach the 64 KB limit, we will need to grow the congestion window size to 45 segments, which will take 224 milliseconds:
That’s four roundtrips (Figure 2-4), and hundreds of milliseconds of latency, to reach 64 KB of throughput between the client and server! The fact that the client and server may be capable of transferring at Mbps+ data rates has no effect—that’s slow-start.
To decrease the amount of time it takes to grow the congestion window, we can decrease the roundtrip time between the client and server—e.g., move the server geographically closer to the client. Or we can increase the initial congestion window size to the new RFC 6928 value of 10 segments.
Slow-start is not as big of an issue for large, streaming downloads, as the client and the server will arrive at their maximum window sizes after a few hundred milliseconds and continue to transmit at near maximum speeds—the cost of the slow-start phase is amortized over the lifetime of the larger transfer.
However, for many HTTP connections, which are often short and bursty, it is not unusual for the request to terminate before the maximum window size is reached. As a result, the performance of many web applications is often limited by the roundtrip time between server and client: slow-start limits the available bandwidth throughput, which has an adverse effect on the performance of small transfers.
To illustrate the impact of the three-way handshake and the slow-start phase on a simple HTTP transfer, let’s assume that our client in New York requests a 20 KB file from the server in London over a new TCP connection (Figure 2-5), and the following connection parameters are in place:
)
|
|
Client begins the TCP handshake with the SYN packet. |
|
|
Server replies with SYN-ACK and specifies its rwnd size. |
|
|
Client ACKs the SYN-ACK, specifies its rwnd size, and immediately sends the HTTP GET request. |
|
|
Server receives the HTTP request. |
|
|
Server completes generating the 20 KB response and sends 4 TCP segments before pausing for an ACK (initial cwnd size is 4). |
|
|
Client receives four segments and ACKs each one. |
|
|
Server increments its cwnd for each ACK and sends eight segments. |
|
|
Client receives eight segments and ACKs each one. |
|
|
Server increments its cwnd for each ACK and sends remaining segments. |
|
|
Client receives remaining segments, ACKs each one. |
As an exercise, run through Figure 2-5 with cwnd value set to 10 network segments instead of 4. You should see a full roundtrip of network latency disappear—a 22% improvement in performance!
264 ms to transfer the 20 KB file on a new TCP connection with 56 ms roundtrip time between the client and server! By comparison, let’s now assume that the client is able to reuse the same TCP connection (Figure 2-6) and issues the same request once more.
|
|
Client sends the HTTP request. |
|
|
Server receives the HTTP request. |
|
|
Server completes generating the 20 KB response, but the cwnd value is already greater than the 15 segments required to send the file; hence it dispatches all the segments in one burst. |
|
|
Client receives all 15 segments, ACKs each one. |
The same request made on the same connection, but without the cost of the three-way handshake and the penalty of the slow-start phase, now took 96 milliseconds, which translates into a 275% improvement in performance!
In both cases, the fact that both the server and the client have access to 5 Mbps of upstream bandwidth had no impact during the startup phase of the TCP connection. Instead, the latency and the congestion window sizes were the limiting factors.
In fact, the performance gap between the first and the second request dispatched over an existing connection will only widen if we increase the roundtrip time; as an exercise, try it with a few different values. Once you develop an intuition for the mechanics of TCP congestion control, dozens of optimizations such as keepalive, pipelining, and multiplexing will require little further motivation.
It is important to recognize that TCP is specifically designed to use packet loss as a feedback mechanism to help regulate its performance. In other words, it is not a question of if, but rather of when the packet loss will occur. Slow-start initializes the connection with a conservative window and, for every roundtrip, doubles the amount of data in flight until it exceeds the receiver’s flow-control window, a system-configured congestion threshold (ssthresh) window, or until a packet is lost, at which point the congestion avoidance algorithm (Figure 2-3) takes over.
The implicit assumption in congestion avoidance is that packet loss is indicative of network congestion: somewhere along the path we have encountered a congested link or a router, which was forced to drop the packet, and hence we need to adjust our window to avoid inducing more packet loss to avoid overwhelming the network.
Once the congestion window is reset, congestion avoidance specifies its own algorithms for how to grow the window to minimize further loss. At a certain point, another packet loss event will occur, and the process will repeat once over. If you have ever looked at a throughput trace of a TCP connection and observed a sawtooth pattern within it, now you know why it looks as such: it is the congestion control and avoidance algorithms adjusting the congestion window size to account for packet loss in the network.
Finally, it is worth noting that improving congestion control and avoidance is an active area both for academic research and commercial products: there are adaptations for different network types, different types of data transfers, and so on. Today, depending on your platform, you will likely run one of the many variants: TCP Tahoe and Reno (original implementations), TCP Vegas, TCP New Reno, TCP BIC, TCP CUBIC (default on Linux), or Compound TCP (default on Windows), among many others. However, regardless of the flavor, the core performance implications of congestion control and avoidance hold for all.
The built-in congestion control and congestion avoidance mechanisms in TCP carry another important performance implication: the optimal sender and receiver window sizes must vary based on the roundtrip time and the target data rate between them.
To understand why this is the case, first recall that the maximum amount of unacknowledged, in-flight data between the sender and receiver is defined as the minimum of the receive (rwnd) and congestion (cwnd) window sizes: the current receive windows are communicated in every ACK, and the congestion window is dynamically adjusted by the sender based on the congestion control and avoidance algorithms.
If either the sender or receiver exceeds the maximum amount of unacknowledged data, then it must stop and wait for the other end to ACK some of the packets before proceeding. How long would it have to wait? That’s dictated by the roundtrip time between the two!
If either the sender or receiver are frequently forced to stop and wait for ACKs for previous packets, then this would create gaps in the data flow (Figure 2-7), which would consequently limit the maximum throughput of the connection. To address this problem, the window sizes should be made just big enough, such that either side can continue sending data until an ACK arrives back from the client for an earlier packet—no gaps, maximum throughput. Consequently, the optimal window size depends on the roundtrip time! Pick a low window size, and you will limit your connection throughput, regardless of the available or advertised bandwidth between the peers.
So how big do the flow control (rwnd) and congestion control (cwnd) window values need to be? The actual calculation is a simple one. First, let us assume that the minimum of the cwnd and rwnd window sizes is 16 KB, and the roundtrip time is 100 ms:
Regardless of the available bandwidth between the sender and receiver, this TCP connection will not exceed a 1.31 Mbps data rate! To achieve higher throughput we need to raise the minimum window size or lower the roundtrip time.
Similarly, we can compute the optimal window size if we know the roundtrip time and the available bandwidth on both ends. In this scenario, let’s assume that the roundtrip time stays the same (100 ms), but the sender has 10 Mbps of available bandwidth, and the receiver is on a high-throughput 100 Mbps+ link. Assuming there is no network congestion between them, our goal is to saturate the 10 Mbps link available to the client:
The window size needs to be at least 122.1 KB to saturate the 10 Mbps link. Recall that the maximum receive window size in TCP is 64 KB unless window scaling—see Window Scaling (RFC 1323)—is present: double-check your client and server settings!
The good news is that the window size negotiation and tuning is managed automatically by the network stack and should adjust accordingly. The bad news is sometimes it will still be the limiting factor on TCP performance. If you have ever wondered why your connection is transmitting at a fraction of the available bandwidth, even when you know that both the client and the server are capable of higher rates, then it is likely due to a small window size: a saturated peer advertising low receive window, bad network weather and high packet loss resetting the congestion window, or explicit traffic shaping that could have been applied to limit throughput of your connection.
TCP provides the abstraction of a reliable network running over an unreliable channel, which includes basic packet error checking and correction, in-order delivery, retransmission of lost packets, as well as flow control, congestion control, and congestion avoidance designed to operate the network at the point of greatest efficiency. Combined, these features make TCP the preferred transport for most applications.
However, while TCP is a popular choice, it is not the only, nor necessarily the best choice for every occasion. Specifically, some of the features, such as in-order and reliable packet delivery, are not always necessary and can introduce unnecessary delays and negative performance implications.
To understand why that is the case, recall that every TCP packet carries a unique sequence number when put on the wire, and the data must be passed to the receiver in-order (Figure 2-8). If one of the packets is lost en route to the receiver, then all subsequent packets must be held in the receiver’s TCP buffer until the lost packet is retransmitted and arrives at the receiver. Because this work is done within the TCP layer, our application has no visibility into the TCP retransmissions or the queued packet buffers, and must wait for the full sequence before it is able to access the data. Instead, it simply sees a delivery delay when it tries to read the data from the socket. This effect is known as TCP head-of-line (HOL) blocking.
The delay imposed by head-of-line blocking allows our applications to avoid having to deal with packet reordering and reassembly, which makes our application code much simpler. However, this is done at the cost of introducing unpredictable latency variation in the packet arrival times, commonly referred to as jitter, which can negatively impact the performance of the application.
Further, some applications may not even need either reliable delivery or in-order delivery: if every packet is a standalone message, then in-order delivery is strictly unnecessary, and if every message overrides all previous messages, then the requirement for reliable delivery can be removed entirely. Unfortunately, TCP does not provide such configuration—all packets are sequenced and delivered in order.
Applications that can deal with out-of-order delivery or packet loss and that are latency or jitter sensitive are likely better served with an alternate transport, such as UDP.
TCP is an adaptive protocol designed to be fair to all network peers and to make the most efficient use of the underlying network. Thus, the best way to optimize TCP is to tune how TCP senses the current network conditions and adapts its behavior based on the type and the requirements of the layers below and above it: wireless networks may need different congestion algorithms, and some applications may need custom quality of service (QoS) semantics to deliver the best experience.
The close interplay of the varying application requirements, and the many knobs in every TCP algorithm, make TCP tuning and optimization an inexhaustible area of academic and commercial research. In this chapter, we have only scratched the surface of the many factors that govern TCP performance. Additional mechanisms, such as selective acknowledgments (SACK), delayed acknowledgments, and fast retransmit, among many others, make each TCP session much more complicated (or interesting, depending on your perspective) to understand, analyze, and tune.
Having said that, while the specific details of each algorithm and feedback mechanism will continue to evolve, the core principles and their implications remain unchanged:
As a result, the rate with which a TCP connection can transfer data in modern high-speed networks is often limited by the roundtrip time between the receiver and sender. Further, while bandwidth continues to increase, latency is bounded by the speed of light and is already within a small constant factor of its maximum value. In most cases, latency, not bandwidth, is the bottleneck for TCP—e.g., see Figure 2-5.
As a starting point, prior to tuning any specific values for each buffer and timeout variable in TCP, of which there are dozens, you are much better off simply upgrading your hosts to their latest system versions. TCP best practices and underlying algorithms that govern its performance continue to evolve, and most of these changes are only available only in the latest kernels. In short, keep your servers up to date to ensure the optimal interaction between the sender’s and receiver’s TCP stacks.
On the surface, upgrading server kernel versions seems like trivial advice. However, in practice, it is often met with significant resistance: many existing servers are tuned for specific kernel versions, and system administrators are reluctant to perform the upgrade.
To be fair, every upgrade brings its risks, but to get the best TCP performance, it is also likely the single best investment you can make.
With the latest kernel in place, it is good practice to ensure that your server is configured to use the following best practices:
The combination of the preceding settings and the latest kernel will enable the best performance—lower latency and higher throughput—for individual TCP connections.
Depending on your application, you may also need to tune other TCP settings on the server to optimize for high connection rates, memory consumption, or similar criteria. However, these configuration settings are dependent on the platform, application, and hardware—consult your platform documentation as required.
Tuning performance of TCP allows the server and client to deliver the best throughput and latency for an individual connection. However, how an application uses each new, or established, TCP connection can have an even greater impact:
Eliminating unnecessary data transfers is, of course, the single best optimization—e.g., eliminating unnecessary resources or ensuring that the minimum number of bits is transferred by applying the appropriate compression algorithm. Following that, locating the bits closer to the client, by geo-distributing servers around the world—e.g., using a CDN—will help reduce latency of network roundtrips and significantly improve TCP performance. Finally, where possible, existing TCP connections should be reused to minimize overhead imposed by slow-start and other congestion mechanisms.
Optimizing TCP performance pays high dividends, regardless of the type of application, for every new connection to your servers. A short list to put on the agenda:
User Datagram Protocol, or UDP, was added to the core network protocol suite in August of 1980 by Jon Postel, well after the original introduction of TCP/IP, but right at the time when the TCP and IP specifications were being split to become two separate RFCs. This timing is important because, as we will see, the primary feature and appeal of UDP is not in what it introduces, but rather in all the features it chooses to omit. UDP is colloquially referred to as a null protocol, and RFC 768, which describes its operation, could indeed fit on a napkin.
The words datagram and packet are often used interchangeably, but there are some nuances. While the term “packet” applies to any formatted block of data, the term “datagram” is often reserved for packets delivered via an unreliable service—no delivery guarantees, no failure notifications. Because of this, you will frequently find the more descriptive term “Unreliable” substituted for the official term “User” in the UDP acronym, to form “Unreliable Datagram Protocol.” That is also why UDP packets are generally, and more correctly, referred to as datagrams.
Perhaps the most well-known use of UDP, and one that every browser and Internet application depends on, is the Domain Name System (DNS): given a human-friendly computer hostname, we need to discover its IP address before any data exchange can occur. However, even though the browser itself is dependent on UDP, historically the protocol has never been exposed as a first-class transport for pages and applications running within it. That is, until WebRTC entered into the picture.
The new Web Real-Time Communication (WebRTC) standards, jointly developed by the IETF and W3C working groups, are enabling real-time communication, such as voice and video calling and other forms of peer-to-peer (P2P) communication, natively within the browser via UDP. With WebRTC, UDP is now a first-class browser transport with a client-side API! We will investigate WebRTC in-depth in Chapter 18, but before we get there, let’s first explore the inner workings of the UDP protocol to understand why and where we may want to use it.
To understand UDP and why it is commonly referred to as a “null protocol,” we first need to look at the Internet Protocol (IP), which is located one layer below both TCP and UDP protocols.
The IP layer has the primary task of delivering datagrams from the source to the destination host based on their addresses. To do so, the messages are encapsulated within an IP packet (Figure 3-1) which identifies the source and the destination addresses, as well as a number of other routing parameters .
Once again, the word “datagram” is an important distinction: the IP layer provides no guarantees about message delivery or notifications of failure and hence directly exposes the unreliability of the underlying network to the layers above it. If a routing node along the way drops the IP packet due to congestion, high load, or for other reasons, then it is the responsibility of a protocol above IP to detect it, recover, and retransmit the data—that is, if that is the desired behavior!
The UDP protocol encapsulates user messages into its own packet structure (Figure 3-2), which adds only four additional fields: source port, destination port, length of packet, and checksum. Thus, when IP delivers the packet to the destination host, the host is able to unwrap the UDP packet, identify the target application by the destination port, and deliver the message. Nothing more, nothing less.
In fact, both the source port and the checksum fields are optional fields in UDP datagrams. The IP packet contains its own header checksum, and the application can choose to omit the UDP checksum, which means that all the error detection and error correction can be delegated to the applications above them. At its core, UDP simply provides “application multiplexing” on top of IP by embedding the source and the target application ports of the communicating hosts. With that in mind, we can now summarize all the UDP non-services:
TCP is a byte-stream oriented protocol capable of transmitting application messages spread across multiple packets without any explicit message boundaries within the packets themselves. To achieve this, connection state is allocated on both ends of the connection, and each packet is sequenced, retransmitted when lost, and delivered in order. UDP datagrams, on the other hand, have definitive boundaries: each datagram is carried in a single IP packet, and each application read yields the full message; datagrams cannot be fragmented.
UDP is a simple, stateless protocol, suitable for bootstrapping other application protocols on top: virtually all of the protocol design decisions are left to the application above it. However, before you run away to implement your own protocol to replace TCP, you should think carefully about complications such as UDP interaction with the many layers of deployed middleboxes (NAT traversal), as well as general network protocol design best practices. Without careful engineering and planning, it is not uncommon to start with a bright idea for a new protocol but end up with a poorly implemented version of TCP. The algorithms and the state machines in TCP have been honed and improved over decades and have taken into account dozens of mechanisms that are anything but easy to replicate well.
Unfortunately, IPv4 addresses are only 32 bits long, which provides a maximum of 4.29 billion unique IP addresses. The IP Network Address Translator (NAT) specification was introduced in mid-1994 (RFC 1631) as an interim solution to resolve the looming IPv4 address depletion problem—as the number of hosts on the Internet began to grow exponentially in the early ’90s, we could not expect to allocate a unique IP to every host.
The proposed IP reuse solution was to introduce NAT devices at the edge of the network, each of which would be responsible for maintaining a table mapping of local IP and port tuples to one or more globally unique (public) IP and port tuples (Figure 3-3). The local IP address space behind the translator could then be reused among many different networks, thus solving the address depletion problem.
Unfortunately, as it often happens, there is nothing more permanent than a temporary solution. Not only did the NAT devices resolve the immediate problem, but they also quickly became a ubiquitous component of many corporate and home proxies and routers, security appliances, firewalls, and dozens of other hardware and software devices. NAT middleboxes are no longer a temporary solution; rather, they have become an integral part of the Internet infrastructure.
The issue with NAT translation, at least as far as UDP is concerned, is precisely the routing table that it must maintain to deliver the data. NAT middleboxes rely on connection state, whereas UDP has none. This is a fundamental mismatch and a source of many problems for delivering UDP datagrams. Further, it is now not uncommon for a client to be behind many layers of NATs, which only complicates matters further.
Each TCP connection has a well-defined protocol state machine, which begins with a handshake, followed by application data transfer, and a well-defined exchange to close the connection. Given this flow, each middlebox can observe the state of the connection and create and remove the routing entries as needed. With UDP, there is no handshake or connection termination, and hence there is no connection state machine to monitor.
Delivering outbound UDP traffic does not require any extra work, but routing a reply requires that we have an entry in the translation table, which will tell us the IP and port of the local destination host. Thus, translators have to keep state about each UDP flow, which itself is stateless.
Even worse, the translator is also tasked with figuring out when to drop the translation record, but since UDP has no connection termination sequence, either peer could just stop transmitting datagrams at any point without notice. To address this, UDP routing records are expired on a timer. How often? There is no definitive answer; instead the timeout depends on the vendor, make, version, and configuration of the translator. Consequently, one of the de facto best practices for long-running sessions over UDP is to introduce bidirectional keepalive packets to periodically reset the timers for the translation records in all the NAT devices along the path.
Unpredictable connection state handling is a serious issue created by NATs, but an even larger problem for many applications is the inability to establish a UDP connection at all. This is especially true for P2P applications, such as VoIP, games, and file sharing, which often need to act as both client and server to enable two-way direct communication between the peers.
The first issue is that in the presence of a NAT, the internal client is unaware of its public IP: it knows its internal IP address, and the NAT devices perform the rewriting of the source port and address in every UDP packet, as well as the originating IP address within the IP packet. However, if the client communicates its private IP address as part of its application data with a peer outside of its private network, then the connection will inevitably fail. Hence, the promise of “transparent” translation is no longer true, and the application must first discover its public IP address if it needs to share it with a peer outside its private network.
However, knowing the public IP is also not sufficient to successfully transmit with UDP. Any packet that arrives at the public IP of a NAT device must also have a destination port and an entry in the NAT table that can translate it to an internal destination host IP and port tuple. If this entry does not exist, which is the most likely case if someone simply tries to transmit data from the public network, then the packet is simply dropped (Figure 3-4). The NAT device acts as a simple packet filter since it has no way to automatically determine the internal route, unless explicitly configured by the user through a port-forwarding or similar mechanism.
It is important to note that the preceding behavior is not an issue for client applications, which begin their interaction from the internal network and in the process establish the necessary translation records along the path. However, handling inbound connections (acting as a server) from P2P applications such as VoIP, game consoles, file sharing, and so on, in the presence of a NAT, is where we will immediately run into this problem.
To work around this mismatch in UDP and NATs, various traversal techniques (TURN, STUN, ICE) have to be used to establish end-to-end connectivity between the UDP peers on both sides.
Session Traversal Utilities for NAT (STUN) is a protocol (RFC 5389) that allows the host application to discover the presence of a network address translator on the network, and when present to obtain the allocated public IP and port tuple for the current connection (Figure 3-5). To do so, the protocol requires assistance from a well-known, third-party STUN server that must reside on the public network.
Assuming the IP address of the STUN server is known (through DNS discovery, or through a manually specified address), the application first sends a binding request to the STUN server. In turn, the STUN server replies with a response that contains the public IP address and port of the client as seen from the public network. This simple workflow addresses several problems we encountered in our earlier discussion:
With this mechanism in place, whenever two peers want to talk to each other over UDP, they will first send binding requests to their respective STUN servers, and following a successful response on both sides, they can then use the established public IP and port tuples to exchange data.
However, in practice, STUN is not sufficient to deal with all NAT topologies and network configurations. Further, unfortunately, in some cases UDP may be blocked altogether by a firewall or some other network appliance—not an uncommon scenario for many enterprise networks. To address this issue, whenever STUN fails, we can use the Traversal Using Relays around NAT (TURN) protocol (RFC 5766) as a fallback, which can run over UDP and switch to TCP if all else fails.
The key word in TURN is, of course, “relays.” The protocol relies on the presence and availability of a public relay (Figure 3-6) to shuttle the data between the peers.
Of course, the obvious downside in this exchange is that it is no longer peer-to-peer! TURN is the most reliable way to provide connectivity between any two peers on any networks, but it carries a very high cost of operating the TURN server—at the very least, the relay must have enough capacity to service all the data flows. As a result, TURN is best used as a last resort fallback for cases where direct connectivity fails.
Building an effective NAT traversal solution is not for the faint of heart. Thankfully, we can lean on Interactive Connectivity Establishment (ICE) protocol (RFC 5245) to help with this task. ICE is a protocol, and a set of methods, that seek to establish the most efficient tunnel between the participants (Figure 3-7): direct connection where possible, leveraging STUN negotiation where needed, and finally fallback to TURN if all else fails.
In practice, if you are building a P2P application over UDP, then you most definitely want to leverage an existing platform API, or a third-party library that implements ICE, STUN, and TURN for you. And now that you are familiar with what each of these protocols does, you can navigate your way through the required setup and configuration!
UDP is a simple and a commonly used protocol for bootstrapping new transport protocols. In fact, the primary feature of UDP is all the features it omits: no connection state, handshakes, retransmissions, reassembly, reordering, congestion control, congestion avoidance, flow control, or even optional error checking. However, the flexibility that this minimal message-oriented transport layer affords is also a liability for the implementer. Your application will likely have to reimplement some, or many, of these features from scratch, and each must be designed to play well with other peers and protocols on the network.
Unlike TCP, which ships with built-in flow and congestion control and congestion avoidance, UDP applications must implement these mechanisms on their own. Congestion insensitive UDP applications can easily overwhelm the network, which can lead to degraded network performance and, in severe cases, to network congestion collapse.
If you want to leverage UDP for your own application, make sure to research and read the current best practices and recommendations. One such document is the RFC 5405, which specifically focuses on design guidelines for applications delivered via unicast UDP. Here is a short sample of the recommendations:
Designing a new transport protocol requires a lot of careful thought, planning, and research—do your due diligence. Where possible, leverage an existing library or a framework that has already taken into account NAT traversal, and is able to establish some degree of fairness with other sources of concurrent network traffic.
On that note, good news: WebRTC is just such a framework!
The SSL protocol was originally developed at Netscape to enable ecommerce transaction security on the Web, which required encryption to protect customers’ personal data, as well as authentication and integrity guarantees to ensure a safe transaction. To achieve this, the SSL protocol was implemented at the application layer, directly on top of TCP (Figure 4-1), enabling protocols above it (HTTP, email, instant messaging, and many others) to operate unchanged while providing communication security when communicating across the network.
When SSL is used correctly, a third-party observer can only infer the connection endpoints, type of encryption, as well as the frequency and an approximate amount of data sent, but cannot read or modify any of the actual data.
When the SSL protocol was standardized by the IETF, it was renamed to Transport Layer Security (TLS). Many use the TLS and SSL names interchangeably, but technically, they are different, since each describes a different version of the protocol.
SSL 2.0 was the first publicly released version of the protocol, but it was quickly replaced by SSL 3.0 due to a number of discovered security flaws. Because the SSL protocol was proprietary to Netscape, the IETF formed an effort to standardize the protocol, resulting in RFC 2246, which became known as TLS 1.0 and is effectively an upgrade to SSL 3.0:
The differences between this protocol and SSL 3.0 are not dramatic, but they are significant to preclude interoperability between TLS 1.0 and SSL 3.0.
— The TLS Protocol RFC 2246
Since the publication of TLS 1.0 in January 1999, two new versions have been produced by the IETF working group to address found security flaws, as well as to extend the capabilities of the protocol: TLS 1.1 in April 2006 and TLS 1.2 in August 2008. Internally the SSL 3.0 implementation, as well as all subsequent TLS versions, are very similar, and many clients continue to support SSL 3.0 and TLS 1.0 to this day, although there are very good reasons to upgrade to newer versions to protect users from known attacks!
TLS was designed to operate on top of a reliable transport protocol such as TCP. However, it has also been adapted to run over datagram protocols such as UDP. The Datagram Transport Layer Security (DTLS) protocol, defined in RFC 6347, is based on the TLS protocol and is able to provide similar security guarantees while preserving the datagram delivery model.
The TLS protocol is designed to provide three essential services to all applications running above it: encryption, authentication, and data integrity. Technically, you are not required to use all three in every situation. You may decide to accept a certificate without validating its authenticity, but you should be well aware of the security risks and implications of doing so. In practice, a secure web application will leverage all three services.
In order to establish a cryptographically secure data channel, the connection peers must agree on which ciphersuites will be used and the keys used to encrypt the data. The TLS protocol specifies a well-defined handshake sequence to perform this exchange, which we will examine in detail in TLS Handshake. The ingenious part of this handshake, and the reason TLS works in practice, is its use of public key cryptography (also known as asymmetric key cryptography), which allows the peers to negotiate a shared secret key without having to establish any prior knowledge of each other, and to do so over an unencrypted channel.
As part of the TLS handshake, the protocol also allows both connection peers to authenticate their identity. When used in the browser, this authentication mechanism allows the client to verify that the server is who it claims to be (e.g., your bank) and not someone simply pretending to be the destination by spoofing its name or IP address. This verification is based on the established chain of trust; see Chain of Trust and Certificate Authorities). In addition, the server can also optionally verify the identity of the client—e.g., a company proxy server can authenticate all employees, each of whom could have his own unique certificate signed by the company.
Finally, with encryption and authentication in place, the TLS protocol also provides its own message framing mechanism and signs each message with a message authentication code (MAC). The MAC algorithm is a one-way cryptographic hash function (effectively a checksum), the keys to which are negotiated by both connection peers. Whenever a TLS record is sent, a MAC value is generated and appended for that message, and the receiver is then able to compute and verify the sent MAC value to ensure message integrity and authenticity.
Combined, all three mechanisms serve as a foundation for secure communication on the Web. All modern web browsers provide support for a variety of ciphersuites, are able to authenticate both the client and server, and transparently perform message integrity checks for every record.
Before the client and the server can begin exchanging application data over TLS, the encrypted tunnel must be negotiated: the client and the server must agree on the version of the TLS protocol, choose the ciphersuite, and verify certificates if necessary. Unfortunately, each of these steps requires new packet roundtrips (Figure 4-2) between the client and the server, which adds startup latency to all TLS connections.
Figure 4-2 assumes the same 28 millisecond one-way “light in fiber” delay between New York and London as used in previous TCP connection establishment examples; see Table 1-1.
|
|
TLS runs over a reliable transport (TCP), which means that we must first complete the TCP three-way handshake, which takes one full roundtrip. |
|
|
With the TCP connection in place, the client sends a number of specifications in plain text, such as the version of the TLS protocol it is running, the list of supported ciphersuites, and other TLS options it may want to use. |
|
|
The server picks the TLS protocol version for further communication, decides on a ciphersuite from the list provided by the client, attaches its certificate, and sends the response back to the client. Optionally, the server can also send a request for the client’s certificate and parameters for other TLS extensions. |
|
|
Assuming both sides are able to negotiate a common version and cipher, and the client is happy with the certificate provided by the server, the client initiates either the RSA or the Diffie-Hellman key exchange, which is used to establish the symmetric key for the ensuing session. |
|
|
The server processes the key exchange parameters sent by the client, checks message integrity by verifying the MAC, and returns an encrypted “Finished” message back to the client. |
|
|
The client decrypts the message with the negotiated symmetric key, verifies the MAC, and if all is well, then the tunnel is established and application data can now be sent. |
Negotiating a secure TLS tunnel is a complicated process, and there are many ways to get it wrong. The good news is all the work just shown will be done for us by the server and the browser, and all we need to do is provide and configure the certificates.
Having said that, while our web applications do not have to drive the preceding exchange, it is nonetheless important to realize that every TLS connection will require up to two extra roundtrips on top of the TCP handshake—that’s a long time to wait before any application data can be exchanged! If not managed carefully, delivering application data over TLS can add hundreds, if not thousands of milliseconds of network latency.
Due to a variety of historical and commercial reasons the RSA handshake has been the dominant key exchange mechanism in most TLS deployments: the client generates a symmetric key, encrypts it with the server’s public key, and sends it to the server to use as the symmetric key for the established session. In turn, the server uses its private key to decrypt the sent symmetric key and the key-exchange is complete. From this point forward the client and server use the negotiated symmetric key to encrypt their session.
The RSA handshake works, but has a critical weakness: the same public-private key pair is used both to authenticate the server and to encrypt the symmetric session key sent to the server. As a result, if an attacker gains access to the server’s private key and listens in on the exchange, then they can decrypt the the entire session. Worse, even if an attacker does not currently have access to the private key, they can still record the encrypted session and decrypt it at a later time once they obtain the private key.
By contrast, the Diffie-Hellman key exchange allows the client and server to negotiate a shared secret without explicitly communicating it in the handshake: the server’s private key is used to sign and verify the handshake, but the established symmetric key never leaves the client or server and cannot be intercepted by a passive attacker even if they have access to the private key.
For the curious, the Wikipedia article on Diffie-Hellman key exchange is a great place to learn about the algorithm and its properties.
Best of all, Diffie-Hellman key exchange can be used to reduce the risk of compromise of past communication sessions: we can generate a new “ephemeral” symmetric key as part of each and every key exchange and discard the previous keys. As a result, because the ephemeral keys are never communicated and are actively renegotiated for each the new session, the worst-case scenario is that an attacker could compromise the client or server and access the session keys of the current and future sessions. However, knowing the private key, or the ephemeral key, for those session does not help attacker decrypt any of the previous sessions!
The combination of Diffie-Hellman and the use of ephemeral session keys are what enables “Forward Secrecy”: even if an attacker gains access to the server’s private key they are not able to passively listen in on the active session, nor can they decrypt previously recorded sessions.
Despite the historical dominance of the RSA handshake, it is now being actively phased out to address the weaknesses we saw above: all the popular browsers prefer ciphers that enable forward secrecy (i.e., Diffie-Hellman key exchange), and may only enable certain protocol optimizations when forward secrecy is available. Long story short, consult your server documentation on how to enable forward secrecy.
Two network peers may want to use a custom application protocol to communicate with each other. One way to resolve this is to determine the protocol upfront, assign a well-known port to it (e.g., port 80 for HTTP, port 443 for TLS), and configure all clients and servers to use it. However, in practice, this is a slow and impractical process: each port assignment must be approved and, worse, firewalls and other intermediaries often permit traffic only on ports 80 and 443.
As a result, to enable easy deployment of custom protocols, we must reuse ports 80 or 443 and use an additional mechanism to negotiate the application protocol. Port 80 is reserved for HTTP, and the HTTP specification provides a special Upgrade flow for this very purpose. However, the use of Upgrade can add an extra network roundtrip of latency, and in practice is often unreliable in the presence of many intermediaries; see Proxies, Intermediaries, TLS, and New Protocols on the Web.
For a hands-on example of HTTP Upgrade flow, flip ahead to Upgrading to HTTP/2.
The solution is, you guessed it, to use port 443, which is reserved for secure HTTPS sessions (running over TLS). The use of an end-to-end encrypted tunnel obfuscates the data from intermediate proxies and enables a quick and reliable way to deploy new and arbitrary application protocols. However, while use of TLS addresses reliability, we still need a way to negotiate the protocol!
An HTTPS session could, of course, reuse the HTTP Upgrade mechanism to perform the require negotiation, but this would result in another full roundtrip of latency. What if we could negotiate the protocol as part of the TLS handshake itself?
As the name implies, Application Layer Protocol Negotiation (ALPN) is a TLS extension that introduces support for application protocol negotiation into the TLS handshake (Figure 4-2), thereby eliminating the need for an extra roundtrip required by the HTTP Upgrade workflow. Specifically, the process is as follows:
ProtocolNameList field, containing the list of supported application protocols, into the ClientHello message.
ProtocolNameList field and returns a ProtocolName field indicating the selected protocol as part of the ServerHello message.
The server may respond with only a single protocol name, and if it does not support any that the client requests, then it may choose to abort the connection. As a result, once the TLS handshake is complete, both the secure tunnel is established, and the client and server are in agreement as to which application protocol will be used, they can begin communicating immediately.
ALPN eliminates the need for the HTTP Upgrade exchange, saving an extra roundtrip of latency. However, note that the TLS handshake itself still must be performed; hence ALPN negotiation is not any faster than HTTP Upgrade over an unencrypted channel. Instead, it ensures that application protocol negotiation over TLS is not any slower.
An encrypted TLS tunnel can be established between any two TCP peers: the client only needs to know the IP address of the other peer to make the connection and perform the TLS handshake. However, what if the server wants to host multiple independent sites, each with its own TLS certificate, on the same IP address—how does that work? Trick question; it doesn’t.
To address the preceding problem, the Server Name Indication (SNI) extension was introduced to the TLS protocol, which allows the client to indicate the hostname the client is attempting to connect to at the start of the handshake. As a result, a web server can inspect the SNI hostname, select the appropriate certificate, and continue the handshake.
The extra latency and computational costs of the full TLS handshake impose a serious performance penalty on all applications that require secure communication. To help mitigate some of the costs, TLS provides an ability to resume or share the same negotiated secret key data between multiple connections.
The first Session Identifiers (RFC 5246) resumption mechanism was introduced in SSL 2.0, which allowed the server to create and send a 32-byte session identifier as part of its “ServerHello” message during the full TLS negotiation we saw earlier.
Internally, the server could then maintain a cache of session IDs and the negotiated session parameters for each peer. In turn, the client could then also store the session ID information and include the ID in the “ClientHello” message for a subsequent session, which serves as an indication to the server that the client still remembers the negotiated cipher suite and keys from previous handshake and is able to reuse them. Assuming both the client and the server are able to find the shared session ID parameters in their respective caches, then an abbreviated handshake (Figure 4-3) can take place. Otherwise, a full new session negotiation is required, which will generate a new session ID.
Leveraging session identifiers allows us to remove a full roundtrip, as well as the overhead of public key cryptography, which is used to negotiate the shared secret key. This allows a secure connection to be established quickly and with no loss of security, since we are reusing the previously negotiated session data.
In practice, most web applications attempt to establish multiple connections to the same host to fetch resources in parallel, which makes session resumption a must-have optimization to reduce latency and computational costs for both sides.
Most modern browsers intentionally wait for the first TLS connection to complete before opening new connections to the same server: subsequent TLS connections can reuse the SSL session parameters to avoid the costly handshake.
However, one of the practical limitations of the Session Identifiers mechanism is the requirement for the server to create and maintain a session cache for every client. This results in several problems on the server, which may see tens of thousands or even millions of unique connections every day: consumed memory for every open TLS connection, a requirement for session ID cache and eviction policies, and nontrivial deployment challenges for popular sites with many servers, which should, ideally, use a shared TLS session cache for best performance.
None of the preceding problems are impossible to solve, and many high-traffic sites are using session identifiers successfully today. But for any multiserver deployment, session identifiers will require some careful thinking and systems architecture to ensure a well operating session cache.
To address this concern for server-side deployment of TLS session caches, the “Session Ticket” (RFC 5077) replacement mechanism was introduced, which removes the requirement for the server to keep per-client session state. Instead, if the client indicated that it supports Session Tickets, in the last exchange of the full TLS handshake, the server can include a New Session Ticket record, which includes all of the session data encrypted with a secret key known only by the server.
This session ticket is then stored by the client and can be included in the SessionTicket extension within the ClientHello message of a subsequent session. Thus, all session data is stored only on the client, but the ticket is still safe because it is encrypted with a key known only by the server.
The session identifiers and session ticket mechanisms are respectively commonly referred to as session caching and stateless resumption mechanisms. The main improvement of stateless resumption is the removal of the server-side session cache, which simplifies deployment by requiring that the client provide the session ticket on every new connection to the server—that is, until the ticket has expired.
In practice, deploying session tickets across a set of load-balanced servers also requires some careful thinking and systems architecture: all servers must be initialized with the same session key, and an additional mechanism may be needed to periodically rotate the shared key across all servers.
Authentication is an integral part of establishing every TLS connection. After all, it is possible to carry out a conversation over an encrypted tunnel with any peer, including an attacker, and unless we can be sure that the computer we are speaking to is the one we trust, then all the encryption work could be for nothing. To understand how we can verify the peer’s identity, let’s examine a simple authentication workflow between Alice and Bob:
Trust is a key component of the preceding exchange. Specifically, public key encryption allows us to use the public key of the sender to verify that the message was signed with the right private key, but the decision to approve the sender is still one that is based on trust. In the exchange just shown, Alice and Bob could have exchanged their public keys when they met in person, and because they know each other well, they are certain that their exchange was not compromised by an impostor—perhaps they even verified their identities through another, secret (physical) handshake they had established earlier!
Next, Alice receives a message from Charlie, whom she has never met, but who claims to be a friend of Bob’s. In fact, to prove that he is friends with Bob, Charlie asked Bob to sign his own public key with Bob’s private key and attached this signature with his message (Figure 4-4). In this case, Alice first checks Bob’s signature of Charlie’s key. She knows Bob’s public key and is thus able to verify that Bob did indeed sign Charlie’s key. Because she trusts Bob’s decision to verify Charlie, she accepts the message and performs a similar integrity check on Charlie’s message to ensure that it is, indeed, from Charlie.
What we have just done is established a chain of trust: Alice trusts Bob, Bob trusts Charlie, and by transitive trust, Alice decides to trust Charlie. As long as nobody in the chain gets compromised, this allows us to build and grow the list of trusted parties.
Authentication on the Web and in your browser follows the exact same process as shown. Which means that at this point you should be asking: whom does your browser trust, and whom do you trust when you use the browser? There are at least three answers to this question:
In practice, it would be impractical to store and manually verify each and every key for every website (although you can, if you are so inclined). Hence, the most common solution is to use certificate authorities (CAs) to do this job for us (Figure 4-5): the browser specifies which CAs to trust (root CAs), and the burden is then on the CAs to verify each site they sign, and to audit and verify that these certificates are not misused or compromised. If the security of any site with the CA’s certificate is breached, then it is also the responsibility of that CA to revoke the compromised certificate.
Every browser allows you to inspect the chain of trust of your secure connection (Figure 4-6), usually accessible by clicking on the lock icon beside the URL.
The “trust anchor” for the entire chain is the root certificate authority, which in the case just shown, is the StartCom Certification Authority. Every browser ships with a pre-initialized list of trusted certificate authorities (“roots”), and in this case, the browser trusts and is able to verify the StartCom root certificate. Hence, through a transitive chain of trust in the browser, the browser vendor, and the StartCom certificate authority, we extend the trust to our destination site.
Every operating system vendor and every browser provide a public listing of all the certificate authorities they trust by default. Use your favorite search engine to find and investigate these lists.
In practice, there are hundreds of well-known and trusted certificate authorities, which is also a common complaint against the system. The large number of CAs creates a potentially large attack surface area against the chain of trust in your browser.
Occasionally the issuer of a certificate will need to revoke or invalidate the certificate due to a number of possible reasons: the private key of the certificate has been compromised, the certificate authority itself has been compromised, or due to a variety of more benign reasons such as a superseding certificate, change in affiliation, and so on. To address this, the certificates themselves contain instructions (Figure 4-7) on how to check if they have been revoked. Hence, to ensure that the chain of trust is not compromised, each peer can check the status of each certificate by following the embedded instructions, along with the signatures, as it walks up the certificate chain.
Certificate Revocation List (CRL) is defined by RFC 5280 and specifies a simple mechanism to check the status of every certificate: each certificate authority maintains and periodically publishes a list of revoked certificate serial numbers. Anyone attempting to verify a certificate is then able to download the revocation list and check the presence of the serial number within it—if it is present, then it has been revoked.
The CRL file itself can be published periodically or on every update and can be delivered via HTTP, or any other file transfer protocol. The list is also signed by the CA, and is usually allowed to be cached for a specified interval. In practice, this workflow works quite well, but there are instances where CRL mechanism may be insufficient:
To address some of the limitations of the CRL mechanism, the Online Certificate Status Protocol (OCSP) was introduced by RFC 2560, which provides a mechanism to perform a real-time check for status of the certificate. Unlike the CRL, which contains all the revoked serial numbers, OCSP allows the verifier to query the certificate database directly for just the serial number in question while validating the certificate chain.
As a result, the OCSP mechanism should consume much less bandwidth and is able to provide real-time validation. However, no mechanism is perfect! The requirement to perform real-time OCSP queries creates several problems of its own:
In practice, CRL and OCSP mechanisms are complementary, and most certificates will provide instructions and endpoints for both.
The more important part is the client support and behavior: some browsers distribute their own CRL lists, others fetch and cache the CRL files from the CAs. Similarly, some browsers will perform the real-time OCSP check but will differ in their behavior if the OCSP request fails. If you are curious, check your browser and OS certificate revocation settings!
Not unlike the IP or TCP layers below it, all data exchanged within a TLS session is also framed using a well-defined protocol (Figure 4-8). The TLS Record protocol is responsible for identifying different types of messages (handshake, alert, or data via the “Content Type” field), as well as securing and verifying the integrity of each message.
A typical workflow for delivering application data is as follows:
Once these steps are complete, the encrypted data is passed down to the TCP layer for transport. On the receiving end, the same workflow, but in reverse, is applied by the peer: decrypt data using negotiated cipher, verify MAC, extract and deliver the data to the application above it.
Once again, the good news is all the work just shown is handled by the TLS layer itself and is completely transparent to most applications. However, the record protocol does introduce a few important implications that you should be aware of:
Picking the right record size for your application, if you have the ability to do so, can be an important optimization. Small records incur a larger overhead due to record framing, whereas large records will have to be delivered and reassembled by the TCP layer before they can be processed by the TLS layer and delivered to your application.
Due to the layered architecture of the network protocols, running an application over TLS is no different from communicating directly over TCP. As such, there are no, or at most minimal, application modifications that you will need to make to deliver it over TLS. That is, assuming you have already applied the Optimizing for TCP best practices.
However, what you should investigate are the operational pieces of your TLS deployments: how and where you deploy your servers, size of TLS records and memory buffers, certificate sizes, support for abbreviated handshakes, and so on. Getting these parameters right on your servers can make an enormous positive difference in the user experience, as well as in your operational costs.
Establishing and maintaining an encrypted channel introduces additional computational costs for both peers. Specifically, first there is the asymmetric (public key) encryption used during the TLS handshake (explained in TLS Handshake). Then, once a shared secret is established, it is used as a symmetric key to encrypt all TLS records.
As we noted earlier, public key cryptography is more computationally expensive when compared with symmetric key cryptography, and in the early days of the Web often required additional hardware to perform “SSL offloading.” The good news is this is no longer the case. Modern hardware has made great improvements to help minimize these costs, and what once required additional hardware can now be done directly on the CPU. Large organizations such as Facebook, Twitter, and Google, which offer TLS to hundreds of millions of users, perform all the necessary TLS negotiation and computation in software and on commodity hardware.
In January this year (2010), Gmail switched to using HTTPS for everything by default. Previously it had been introduced as an option, but now all of our users use HTTPS to secure their email between their browsers and Google, all the time. In order to do this we had to deploy no additional machines and no special hardware. On our production frontend machines, SSL/TLS accounts for less than 1% of the CPU load, less than 10 KB of memory per connection and less than 2% of network overhead. Many people believe that SSL/TLS takes a lot of CPU time and we hope the preceding numbers (public for the first time) will help to dispel that.
If you stop reading now you only need to remember one thing: SSL/TLS is not computationally expensive anymore.
— Adam Langley (Google)
We have deployed TLS at a large scale using both hardware and software load balancers. We have found that modern software-based TLS implementations running on commodity CPUs are fast enough to handle heavy HTTPS traffic load without needing to resort to dedicated cryptographic hardware. We serve all of our HTTPS traffic using software running on commodity hardware.
— Doug Beaver (Facebook)
Elliptic Curve Diffie-Hellman (ECDHE) is only a little more expensive than RSA for an equivalent security level… In practical deployment, we found that enabling and prioritizing ECDHE cipher suites actually caused negligible increase in CPU usage. HTTP keepalives and session resumption mean that most requests do not require a full handshake, so handshake operations do not dominate our CPU usage. We find 75% of Twitter’s client requests are sent over connections established using ECDHE. The remaining 25% consists mostly of older clients that don’t yet support the ECDHE cipher suites.
— Jacob Hoffman-Andrews (Twitter)
Previous experiences notwithstanding, techniques such as TLS Session Resumption are still important optimizations, which will help you decrease the computational costs and latency of public key cryptography performed during the TLS handshake. There is no reason to spend CPU cycles on work that you don’t need to do.
Speaking of optimizing CPU cycles, make sure to upgrade your SSL libraries to the latest release, and build your web server or proxy against them! For example, recent versions of OpenSSL have made significant performance improvements, and chances are your system default OpenSSL libraries are outdated.
The connection setup latency imposed on every TLS connection, new or resumed, is an important area of optimization. First, recall that every TCP connection begins with a three-way handshake (explained in Three-Way Handshake), which takes a full roundtrip for the SYN/SYN-ACK packets. Following that, the TLS handshake (explained in TLS Handshake) requires up to two additional roundtrips for the full process, or one roundtrip if an abbreviated handshake (explained in Optimizing TLS handshake with Session Resumption and False Start) can be used.
In the worst case, before any application data can be exchanged, the TCP and TLS connection setup process will take three roundtrips! Following our earlier example of a client in New York and the server in London, with a roundtrip time of 56 milliseconds (Table 1-1), this translates to 168 milliseconds of latency for a full TCP and TLS setup, and 112 milliseconds for a TLS session that is resumed. Even worse, the higher the latency between the peers, the worse the penalty, and 56 milliseconds is definitely an optimistic number.
Because all TLS sessions run over TCP, all the advice for Optimizing for TCP applies here as well. If TCP connection reuse was an important consideration for unencrypted traffic, then it is a critical optimization for all applications running over TLS—if you can avoid doing the handshake, do so. However, if you have to perform the handshake, then you may want to investigate using the “early termination” technique.
As we discussed in Chapter 1, we cannot expect any dramatic improvements in latency in the future, as our packets are already traveling within a small constant factor of the speed of light. However, while we may not be able to make our packets travel faster, we can make them travel a shorter distance. Early termination is a simple technique of placing your servers closer to the user (Figure 4-9) to minimize the latency cost of each roundtrip between the client and the server.
The simplest way to accomplish this is to replicate or cache your data and services on servers around the world instead of forcing every user to traverse across oceans and continental links to the origin servers. Of course, this is precisely the service that many content delivery networks (CDNs) are set up to offer. However, the use case for geo-distributed servers does not stop at optimized delivery of static assets.
A nearby server can also terminate the TLS session, which means that the TCP and TLS handshake roundtrips are much quicker and the total connection setup latency is greatly reduced. In turn, the same nearby server can then establish a pool of long-lived, secure connections to the origin servers and proxy all incoming requests and responses to and from the origin servers.
In a nutshell, move the server closer to the client to accelerate TCP and TLS handshakes! Most CDN providers offer this service, and if you are adventurous, you can also deploy your own infrastructure with minimal costs: spin up cloud servers in a few data centers around the globe, configure a proxy server on each to forward requests to your origin, add geographic DNS load balancing, and you are in business.
Terminating the connection closer to the user is an optimization that will help decrease latency for your users in all cases, but once again, no bit is faster than a bit not sent—send fewer bits. Enabling TLS session caching and stateless resumption will allow you to eliminate an entire roundtrip and reduce computational overhead for repeat visitors.
Session identifiers, on which TLS session caching relies, were introduced in SSL 2.0 and have wide support among most clients and servers. However, if you are configuring TLS on your server, do not assume that session support will be on by default. In fact, it is more common to have it off on most servers by default—but you know better! You should double-check and verify your configuration:
In practice, and for best results, you should configure both session caching and session ticket mechanisms. These mechanisms are not exclusive and can work together to provide best performance coverage both for new and older clients.
Session resumption provides two important benefits: it eliminates an extra handshake roundtrip for returning visitors and reduces the computational cost of the handshake by allowing reuse of previously negotiated session parameters. However, it does not help in cases where the visitor is communicating with the server for the first time, or if the previous session has expired.
To get the best of both worlds—a one roundtrip handshake for new and repeat visitors, and computational savings for repeat visitors—we can use TLS False Start, which is an optional protocol extension that allows the sender to send application data (Figure 4-10) when the handshake is only partially complete.
False Start does not modify the TLS handshake protocol, rather it only affects the protocol timing of when the application data can be sent. Intuitively, once the client has sent the ClientKeyExchange record, it already knows the encryption key and can begin transmitting application data—the rest of the handshake is spent confirming that nobody has tampered with the handshake records, and can be done in parallel. As a result, False Start allows us to keep the TLS handshake at one roundtrip regardless of whether we are performing a full or abbreviated handshake.
All application data delivered via TLS is transported within a record protocol (Figure 4-8). The maximum size of each record is 16 KB, and depending on the chosen cipher, each record will add anywhere from 20 to 40 bytes of overhead for the header, MAC, and optional padding. If the record then fits into a single TCP packet, then we also have to add the IP and TCP overhead: 20-byte header for IP, and 20-byte header for TCP with no options. As a result, there is potential for 60 to 100 bytes of overhead for each record. For a typical maximum transmission unit (MTU) size of 1,500 bytes on the wire, this packet structure translates to a minimum of 6% of framing overhead.
The smaller the record, the higher the framing overhead. However, simply increasing the size of the record to its maximum size (16 KB) is not necessarily a good idea! If the record spans multiple TCP packets, then the TLS layer must wait for all the TCP packets to arrive before it can decrypt the data (Figure 4-11). If any of those TCP packets get lost, reordered, or throttled due to congestion control, then the individual fragments of the TLS record will have to be buffered before they can be decoded, resulting in additional latency. In practice, these delays can create significant bottlenecks for the browser, which prefers to consume data byte by byte and as soon as possible.
Small records incur overhead, large records incur latency, and there is no one value for the “optimal” record size. Instead, for web applications, which are consumed by the browser, the best strategy is to dynamically adjust the record size based on the state of the TCP connection:
If the TCP connection has been idle, and even if Slow-Start Restart is disabled on the server, the best strategy is to decrease the record size when sending a new burst of data: the conditions may have changed since last transmission, and our goal is to minimize the probability of buffering at the application layer due to lost packets, reordering, and retransmissions.
Using a dynamic strategy delivers the best performance for interactive traffic: small record size eliminates unnecessary buffering latency and improves the time-to-first-{HTML byte, …, video frame}, and a larger record size optimizes throughput by minimizing the overhead of TLS for long-lived streams.
To determine the optimal record size for each state let’s start with the initial case of a new or idle TCP connection where we want to avoid TLS records from spanning multiple TCP packets:
Assuming a common 1,500-byte starting MTU, this leaves 1,420 bytes for a TLS record delivered over IPv4, and 1,400 bytes for IPv6. To be future-proof, use the IPv6 size, which leaves us with 1,400 bytes for each TLS record payload—adjust as needed if your MTU is lower.
Next, the decision as to when the record size should be increased and reset if the connection has been idle, can be set based on pre-configured thresholds: increase record size to up to 16 KB after X KB of data have been transferred, and reset the record size after Y milliseconds of idle time.
Typically, configuring the TLS record size is not something we can control at the application layer. Instead, this is a setting and perhaps even a compile-time constant or flag on your TLS server. For details on how to configure these values, check the documentation of your server.
A little-known feature of TLS is built-in support for lossless compression of data transferred within the record protocol: the compression algorithm is negotiated during the TLS handshake, and compression is applied prior to encryption of each record. However, in practice, you should disable TLS compression on your server for several reasons:
Double compression will waste CPU time on both the server and the client, and the security breach implications are quite serious: disable TLS compression. In practice, most browsers disable support for TLS compression, but you should nonetheless also explicitly disable it in the configuration of your server to protect your users.
Verifying the chain of trust requires that the browser traverse the chain, starting from the site certificate, and recursively verifying the certificate of the parent until it reaches a trusted root. Hence, the first optimization you should make is to verify that the server does not forget to include all the intermediate certificates when the handshake is performed. If you forget, many browsers will still work, but they will instead be forced to pause the verification and fetch the intermediate certificate on their own, verify it, and then continue. This will most likely require a new DNS lookup, TCP connection, and an HTTP GET request, adding hundreds of milliseconds to your handshake.
How does the browser know from where to fetch it? The child certificate will usually contain the URL for the parent.
Conversely, make sure you do not include unnecessary certificates in your chain! Or, more generally, you should aim to minimize the size of your certificate chain. Recall that server certificates are sent during the TLS handshake, which is likely running over a new TCP connection that is in the early stages of its slow-start algorithm. If the certificate chain exceeds TCP’s initial congestion window (Figure 4-12), then we will inadvertently add yet another roundtrip to the handshake: certificate length will overflow the congestion window and cause the server to stop and wait for a client ACK before proceeding.
The certificate chain in Figure 4-12 is over 5 KB in size, which will overflow the initial congestion window size of older servers and force another roundtrip of delay into the handshake. One possible solution is to increase the initial congestion window; see Increasing TCP’s Initial Congestion Window. In addition, you should investigate if it is possible to reduce the size of the sent certificates:
Every new TLS connection requires that the browser must verify the signatures of the sent certificate chain. However, there is one more step we can’t forget: the browser also needs to verify that the certificate is not revoked. To do so, it may periodically download and cache the CRL of the certificate authority, but it may also need to dispatch an OCSP request during the verification process for a “real-time” check. Unfortunately, the browser behavior for this process varies wildly:
Unfortunately, it is a complicated space with no single best solution. However, one optimization that can be made for some browsers is OCSP stapling: the server can include (staple) the OCSP response from the CA to its certificate chain, allowing the browser to skip the online check. Moving the OCSP fetch to the server allows the server to cache the signed OCSP response and save the extra request for many clients. However, there are also a few things to watch out for:
Finally, to enable OCSP stapling, you will need a server that supports it. The good news is popular servers such as Nginx, Apache, and IIS meet this criteria. Check the documentation of your own server for support and configuration instructions.
HTTP Strict Transport Security is a security policy mechanism that allows the server to declare access rules to a compliant browser via a simple HTTP header—e.g., Strict-Transport-Security: max-age=31536000. Specifically, it instructs the user-agent to enforce the following rules:
max-age=31536000 is equal to a 365-day cache lifetime).
HSTS converts the origin to an HTTPS-only destination and helps protect the application from a variety of passive and active network attacks against the user. Performance wise, it also helps eliminate unnecessary HTTP-to-HTTPS redirects by shifting this responsibility to the client, which will automatically rewrite all links to HTTPS.
As of early 2013, HSTS is supported by Firefox 4+, Chrome 4+, Opera 12+, and Chrome and Firefox for Android. For the latest status, see caniuse.com/stricttransportsecurity.
As an application developer, you are shielded from virtually all the complexity of TLS. Short of ensuring that you do not mix HTTP and HTTPS content on your pages, your application will run transparently on both. However, the performance of your entire application will be affected by the underlying configuration of your server.
The good news is it is never too late to make these optimizations, and once in place, they will pay high dividends for every new connection to your servers! A short list to put on the agenda:
Finally, to verify and test your configuration, you can use an online service, such as the Qualys SSL Server Test to scan your public server for common configuration and security flaws. Additionally, you should familiarize yourself with the openssl command-line interface, which will help you inspect the entire handshake and configuration of your server locally.
$> openssl s_client -state -CAfile startssl.ca.crt -connect igvita.com:443CONNECTED(00000003) SSL_connect:before/connect initialization SSL_connect:SSLv2/v3 write client hello A SSL_connect:SSLv3 read server hello A depth=2 /C=IL/O=StartCom Ltd./OU=Secure Digital Certificate Signing /CN=StartCom Certification Authority verify return:1 depth=1 /C=IL/O=StartCom Ltd./OU=Secure Digital Certificate Signing /CN=StartCom Class 1 Primary Intermediate Server CA verify return:1 depth=0 /description=ABjQuqt3nPv7ebEG/C=US /CN=www.igvita.com/emailAddress=ilya@igvita.com verify return:1 SSL_connect:SSLv3 read server certificate A SSL_connect:SSLv3 read server done A
In the preceding example, we connect to igvita.com on the default TLS port (443), and perform the TLS handshake. Because the s_client makes no assumptions about known root certificates, we manually specify the path to the root certificate of StartSSL Certificate Authority—this is important. Your browser already has StartSSL’s root certificate and is thus able to verify the chain, but s_client makes no such assumptions. Try omitting the root certificate, and you will see a verification error in the log.
Inspecting the certificate chain shows that the server sent two certificates, which added up to 3,571 bytes, which is very close to the three- to four-segment initial TCP congestion window size. We should be careful not to overflow it or raise the cwnd size on the server. Finally, we can inspect the negotiated SSL session variables—chosen protocol, cipher, key—and we can also see that the server issued a session identifier for the current session, which may be resumed in the future.
One of the most transformative technology trends of the past decade is the availability and growing expectation of ubiquitous connectivity. Whether it is for checking email, carrying a voice conversation, web browsing, or myriad other use cases, we now expect to be able to access these online services regardless of location, time, or circumstance: on the run, while standing in line, at the office, on a subway, while in flight, and everywhere in between. Today, we are still often forced to be proactive about finding connectivity (e.g., looking for a nearby WiFi hotspot) but without a doubt, the future is about ubiquitous connectivity where access to the Internet is omnipresent.
Wireless networks are at the epicenter of this trend. At its broadest, a wireless network refers to any network not connected by cables, which is what enables the desired convenience and mobility for the user. Not surprisingly, given the myriad different use cases and applications, we should also expect to see dozens of different wireless technologies to meet the needs, each with its own performance characteristics and each optimized for a specific task and context. Today, we already have over a dozen widespread wireless technologies in use: WiFi, Bluetooth, ZigBee, NFC, WiMAX, LTE, HSPA, EV-DO, earlier 3G standards, satellite services, and more.
As such, given the diversity, it is not wise to make sweeping generalizations about performance of wireless networks. However, the good news is that most wireless technologies operate on common principles, have common trade-offs, and are subject to common performance criteria and constraints. Once we uncover and understand these fundamental principles of wireless performance, most of the other pieces will begin to automatically fall into place.
Further, while the mechanics of data delivery via radio communication are fundamentally different from the tethered world, the outcome as experienced by the user is, or should be, all the same—same performance, same results. In the long run all applications are and will be delivered over wireless networks; it just may be the case that some will be accessed more frequently over wireless than others. There is no such thing as a wired application, and there is zero demand for such a distinction.
All applications should perform well regardless of underlying connectivity. As a user, you should not care about the underlying technology in use, but as developers we must think ahead and architect our applications to anticipate the differences between the different types of networks. And the good news is every optimization that we apply for wireless networks will translate to a better experience in all other contexts. Let’s dive in.
A network is a group of devices connected to one another. In the case of wireless networks, radio communication is usually the medium of choice. However, even within the radio-powered subset, there are dozens of different technologies designed for use at different scales, topologies, and for dramatically different use cases. One way to illustrate this difference is to partition the use cases based on their “geographic range”:
| Type | Range | Applications | Standards | |
Personal area network (PAN) | Within reach of a person | Cable replacement for peripherals | Bluetooth, ZigBee, NFC | |
Local area network (LAN) | Within a building or campus | Wireless extension of wired network | IEEE 802.11 (WiFi) | |
Metropolitan area network (MAN) | Within a city | Wireless inter-network connectivity | IEEE 802.15 (WiMAX) | |
Wide area network (WAN) | Worldwide | Wireless network access | Cellular (UMTS, LTE, etc.) |
The preceding classification is neither complete nor entirely accurate. Many technologies and standards start within a specific use case, such as Bluetooth for PAN applications and cable replacement, and with time acquire more capabilities, reach, and throughput. In fact, the latest drafts of Bluetooth now provide seamless interoperability with 802.11 (WiFi) for high-bandwidth use cases. Similarly, technologies such as WiMAX have their origins as fixed-wireless solutions, but with time acquired additional mobility capabilities, making them a viable alternative to other WAN and cellular technologies.
The point of the classification is not to partition each technology into a separate bin, but to highlight the high-level differences within each use case. Some devices have access to a continuous power source; others must optimize their battery life at all costs. Some require Gbit/s+ data rates; others are built to transfer tens or hundreds of bytes of data (e.g., NFC). Some applications require always-on connectivity, while others are delay and latency tolerant. These and a large number of other criteria are what determine the original characteristics of each type of network. However, once in place, each standard continues to evolve: better battery capacities, faster processors, improved modulation algorithms, and other advancements continue to extend the use cases and performance of each wireless standard.
Each and every type of wireless technology has its own set of constraints and limitations. However, regardless of the specific wireless technology in use, all communication methods have a maximum channel capacity, which is determined by the same underlying principles. In fact, Claude E. Shannon gave us an exact mathematical model (Equation 5-1) to determine channel capacity, regardless of the technology in use.
C is the channel capacity and is measured in bits per second.
BW is the available bandwidth, and is measured in hertz.
S is signal and N is noise, and they are measured in watts.
Although somewhat simplified, the previous formula captures all the essential insights we need to understand the performance of most wireless networks. Regardless of the name, acronym, or the revision number of the specification, the two fundamental constraints on achievable data rates are the amount of available bandwidth and the signal power between the receiver and the sender.
Unlike the tethered world, where a dedicated wire can be run between each network peer, radio communication by its very nature uses a shared medium: radio waves, or if you prefer, electromagnetic radiation. Both the sender and receiver must agree up-front on the specific frequency range over which the communication will occur; a well-defined range allows seamless interoperability between devices. For example, the 802.11b and 802.11g standards both use the 2.4–2.5 GHz band across all WiFi devices.
Who determines the frequency range and its allocation? In short, local government (Figure 5-1). In the United States, this process is governed by the Federal Communications Commission (FCC). In fact, due to different government regulations, some wireless technologies may work in one part of the world, but not in others. Different countries may, and often do, assign different spectrum ranges to the same wireless technology.
Politics aside, besides having a common band for interoperability, the most important performance factor is the size of the assigned frequency range. As Shannon’s model shows, the overall channel bitrate is directly proportional to the assigned range. Hence, all else being equal, a doubling in available frequency range will double the data rate—e.g., going from 20 to 40 MHz of bandwidth can double the channel data rate, which is exactly how 802.11n is improving its performance over earlier WiFi standards!
Finally, it is also worth noting that not all frequency ranges offer the same performance. Low-frequency signals travel farther and cover large areas (macrocells), but at the cost of requiring larger antennas and having more clients competing for access. On the other hand, high-frequency signals can transfer more data but won’t travel as far, resulting in smaller coverage areas (microcells) and a requirement for more infrastructure.
Certain frequency ranges are more valuable than others for some applications. Broadcast-only applications (e.g., broadcast radio) are well suited for low-frequency ranges. On the other hand, two-way communication benefits from use of smaller cells, which provide higher bandwidth and less competition.
Besides bandwidth, the second fundamental limiting factor in all wireless communication is the signal power between the sender and receiver, also known as the signal-power-to-noise-power, S/N ratio, or SNR. In essence, it is a measure that compares the level of desired signal to the level of background noise and interference. The larger the amount of background noise, the stronger the signal has to be to carry the information.
By its very nature, all radio communication is done over a shared medium, which means that other devices may generate unwanted interference. For example, a microwave oven operating at 2.5 GHz may overlap with the frequency range used by WiFi, creating cross-standard interference. However, other WiFi devices, such as your neighbors’ WiFi access point, and even your coworker’s laptop accessing the same WiFi network, also create interference for your transmissions.
In the ideal case, you would be the one and only user within a certain frequency range, with no other background noise or interference. Unfortunately, that’s unlikely. First, bandwidth is scarce, and second, there are simply too many wireless devices to make that work. Instead, to achieve the desired data rate where interference is present, we can either increase the transmit power, thereby increasing the strength of the signal, or decrease the distance between the transmitter and the receiver—or both, of course.
Path loss, or path attenuation, is the reduction in signal power with respect to distance traveled—the exact reduction rate depends on the environment. A full discussion on this is outside the scope of this book, but if you are curious, consult your favorite search engine.
To illustrate the relationship between signal, noise, transmit power, and distance, imagine you are in a small room and talking to someone 20 feet away. If nobody else is present, you can hold a conversation at normal volume. However, now add a few dozen people into the same room, such as at a crowded party, each carrying their own conversations. All of the sudden, it would be impossible for you to hear your peer! Of course, you could start speaking louder, but doing so would raise the amount of “noise” for everyone around you. In turn, they would start speaking louder also and further escalate the amount of noise and interference. Before you know it, everyone in the room is only able to communicate from a few feet away from each other (Figure 5-2). If you have ever lost your voice at a rowdy party, or had to lean in to hear a conversation, then you have firsthand experience with SNR.
In fact, this scenario illustrates two important effects:
One, or more loud speakers beside you can block out weaker signals from farther away—the near-far problem. Similarly, the larger the number of other conversations around you, the higher the interference and the smaller the range from which you can discern a useful signal—cell-breathing. Not surprisingly, these same limitations are present in all forms of radio communication as well, regardless of protocol or underlying technology.
Available bandwidth and SNR are the two primary, physical factors that dictate the capacity of every wireless channel. However, the algorithm by which the signal is encoded can also have a significant effect.
In a nutshell, our digital alphabet (1’s and 0’s), needs to be translated into an analog signal (a radio wave). Modulation is the process of digital-to-analog conversion, and different “modulation alphabets” can be used to encode the digital signal with different efficiency. The combination of the alphabet and the symbol rate is what then determines the final throughput of the channel. As a hands-on example:
The choice of the modulation algorithm depends on the available technology, computing power of both the receiver and sender, as well as the SNR ratio. A higher-order modulation alphabet comes at a cost of reduced robustness to noise and interference—there is no free lunch!
Don’t worry, we are not planning to dive headfirst into the world of signal processing. Rather, it is simply important to understand that the choice of the modulation algorithm does affect the capacity of the wireless channel, but it is also subject to SNR, available processing power, and all other common trade-offs.
Our brief crash course on signal theory can be summed up as follows: the performance of any wireless network, regardless of the name, acronym, or the revision number, is fundamentally limited by a small number of well-known parameters. Specifically, the amount of allocated bandwidth and the signal-to-noise ratio between receiver and sender. Further, all radio-powered communication is:
All wireless technologies advertise a peak, or a maximum data rate. For example, the 802.11g standard is capable of 54 Mbit/s, and the 802.11n standard raises the bar up to 600 Mbit/s. Similarly, some mobile carriers are advertising 100+ MBit/s throughput with LTE. However, the most important part that is often overlooked when analyzing all these numbers is the emphasis on in ideal conditions.
What are ideal conditions? You guessed it: maximum amount of allotted bandwidth, exclusive use of the frequency spectrum, minimum or no background noise, highest-throughput modulation alphabet, and, increasingly, multiple radio streams (multiple-input and multiple-output, or MIMO) transmitting in parallel. Needless to say, what you see on the label and what you experience in the real world might be (read, will be) very different.
Just a few factors that may affect the performance of your wireless network:
In other words, if you want maximum throughput, then try to remove any noise and interference you can control, place your receiver and sender as close as possible, give them all the power they desire, and make sure both select the best modulation method. Or, if you are bent on performance, just run a physical wire between the two! The convenience of wireless communication does have its costs.
Measuring wireless performance is a tricky business. A small change, on the order of a few inches, in the location of the receiver can easily double throughput, and a few instants later the throughput could be halved again because another receiver has just woken up and is now competing for access to the radio channel. By its very nature, wireless performance is highly variable.
Finally, note that all of the previous discussions have been focused exclusively on throughput. Are we omitting latency on purpose? In fact, we have so far, because latency performance in wireless networks is directly tied to the specific technology in use, and that is the subject we turn to next.
WiFi operates in the unlicensed ISM spectrum; it is trivial to deploy by anyone, anywhere; and the required hardware is simple and cheap. Not surprisingly, it has become one of the most widely deployed and popular wireless standards.
The name itself is a trademark of the WiFi Alliance, which is a trade association established to promote wireless LAN technologies, as well as to provide interoperability standards and testing. Technically, a device must be submitted to and certified by the WiFi Alliance to carry the WiFi name and logo, but in practice, the name is used to refer to any product based on the IEEE 802.11 standards.
The first 802.11 protocol was drafted in 1997, more or less as a direct adaptation of the Ethernet standard (IEEE 802.3) to the world of wireless communication. However, it wasn’t until 1999, when the 802.11b standard was introduced, that the market for WiFi devices took off. The relative simplicity of the technology, easy deployment, convenience, and the fact that it operated in the unlicensed 2.4 GHz ISM band allowed anyone to easily provide a “wireless extension” to their existing local area network. Today, most every new desktop, laptop, tablet, smartphone, and just about every other form-factor device is WiFi enabled.
The 802.11 wireless standards were primarily designed as an adaptation and an extension of the existing Ethernet (802.3) standard. Hence, while Ethernet is commonly referred to as the LAN standard, the 802.11 family (Figure 6-1) is correspondingly commonly known as the wireless LAN (WLAN). However, for the history geeks, technically much of the Ethernet protocol was inspired by the ALOHAnet protocol, which was the first public demonstration of a wireless network developed in 1971 at the University of Hawaii. In other words, we have come full circle.
The reason why this distinction is important is due to the mechanics of how the ALOHAnet, and consequently Ethernet and WiFi protocols, schedule all communication. Namely, they all treat the shared medium, regardless of whether it is a wire or the radio waves, as a “random access channel,” which means that there is no central process, or scheduler, that controls who or which device is allowed to transmit data at any point in time. Instead, each device decides on its own, and all devices must work together to guarantee good shared channel performance.
The Ethernet standard has historically relied on a probabilistic carrier sense multiple access (CSMA) protocol, which is a complicated name for a simple “listen before you speak” algorithm. In brief, if you have data to send:
Of course, it takes time to propagate any signal; hence collisions can still occur. For this reason, the Ethernet standard also added collision detection (CSMA/CD): if a collision is detected, then both parties stop transmitting immediately and sleep for a random interval (with exponential backoff). This way, multiple competing senders won’t synchronize and restart their transmissions simultaneously.
WiFi follows a very similar but slightly different model: due to hardware limitations of the radio, it cannot detect collisions while sending data. Hence, WiFi relies on collision avoidance (CSMA/CA), where each sender attempts to avoid collisions by transmitting only when the channel is sensed to be idle, and then sends its full message frame in its entirety. Once the WiFi frame is sent, the sender waits for an explicit acknowledgment from the receiver before proceeding with the next transmission.
There are a few more details, but in a nutshell that’s all there is to it: the combination of these techniques is how both Ethernet and WiFi regulate access to the shared medium. In the case of Ethernet, the medium is a physical wire, and in the case of WiFi, it is the shared radio channel.
In practice, the probabilistic access model works very well for lightly loaded networks. In fact, we won’t show the math here, but we can prove that to get good channel utilization (minimize number of collisions), the channel load must be kept below 10%. If the load is kept low, we can get good throughput without any explicit coordination or scheduling. However, if the load increases, then the number of collisions will quickly rise, leading to unstable performance of the entire network.
If you have ever tried to use a highly loaded WiFi network, with many peers competing for access—say, at a large public event, like a conference hall—then chances are, you have firsthand experience with “unstable WiFi performance.” Of course, the probabilistic scheduling is not the only factor, but it certainly plays a role.
The 802.11b standard launched WiFi into everyday use, but as with any popular technology, the IEEE 802 Standards Committee has not been idle and has actively continued to release new protocols (Table 6-1) with higher throughput, better modulation techniques, multistreaming, and many other new features.
| 802.11 protocol | Release | Freq (GHz) | Bandwidth (MHz) | Data rate per stream (Mbit/s) |
b | Sep 1999 | 2.4 | 20 | 1, 2, 5.5, 11 |
g | Jun 2003 | 2.4 | 20 | 6, 9, 12, 18, 24, 36, 48, 54 |
n | Oct 2009 | 2.4 | 20 | 7.2, 14.4, 21.7, 28.9, 43.3, 57.8, 65, 72.2 |
n | Oct 2009 | 5 | 40 | 15, 30, 45, 60, 90, 120, 135, 150 |
ac | ~2014 | 5 | 20, 40, 80, 160 | up to 866.7 |
Today, the “b” and “g” standards are the most widely deployed and supported. Both utilize the unlicensed 2.4 GHz ISM band, use 20 MHz of bandwidth, and support at most one radio data stream. Depending on your local regulations, the transmit power is also likely fixed at a maximum of 200 mW. Some routers will allow you to adjust this value but will likely override it with a regional maximum.
So how do we increase performance of our future WiFi networks? The “n” and upcoming “ac” standards are doubling the bandwidth from 20 to 40 MHz per channel, using higher-order modulation, and adding multiple radios to transmit multiple streams in parallel—multiple-input and multiple-output (MIMO). All combined, and in ideal conditions, this should enable gigabit-plus throughput with the upcoming “ac” wireless standard.
By this point you should be skeptical of the notion of “ideal conditions,” and for good reason. The wide adoption and popularity of WiFi networks also created one of its biggest performance challenges: inter- and intra-cell interference. The WiFi standard does not have any central scheduler, which also means that there are no guarantees on throughput or latency for any client.
The new WiFi Multimedia (WMM) extension enables basic Quality of Service (QoS) within the radio interface for latency-sensitive applications (e.g., voice, video, best effort), but few routers, and even fewer deployed clients, are aware of it. In the meantime, all traffic both within your own network, and in nearby WiFi networks must compete for access for the same shared radio resource.
Your router may allow you to set some Quality of Service (QoS) policy for clients within your own network (e.g., maximum total data rate per client, or by type of traffic), but you nonetheless have no control over traffic generated by other, nearby WiFi networks. The fact that WiFi networks are so easy to deploy is what made them ubiquitous, but the widespread adoption has also created a lot of performance problems: in practice it is now not unusual to find several dozen different and overlapping WiFi networks (Figure 6-2) in any high-density urban or office environment.
The most widely used 2.4 GHz band provides three non-overlapping 20 MHz radio channels: 1, 6, and 11 (Figure 6-3). Although even this assignment is not consistent among all countries. In some, you may be allowed to use higher channels (13, 14), and in others you may be effectively limited to an even smaller subset. However, regardless of local regulations, what this effectively means is that the moment you have more than two or three nearby WiFi networks, some must overlap and hence compete for the same shared bandwidth in the same frequency ranges.
Your 802.11g client and router may be capable of reaching 54 Mbps, but the moment your neighbor, who is occupying the same WiFi channel, starts streaming an HD video over WiFi, your bandwidth is cut in half, or worse. Your access point has no say in this arrangement, and that is a feature, not a bug!
Unfortunately, latency performance fares no better. There are no guarantees for the latency of the first hop between your client and the WiFi access point. In environments with many overlapping networks, you should not be surprised to see high variability, measured in tens and even hundreds of milliseconds for the first wireless hop. You are competing for access to a shared channel with every other wireless peer.
The good news is, if you are an early adopter, then there is a good chance that you can significantly improve performance of your own WiFi network. The 5 GHz band, used by the new 802.11n and 802.11ac standards, offers both a much wider frequency range and is still largely interference free in most environments. That is, at least for the moment, and assuming you don’t have too many tech-savvy friends nearby, like yourself! A dual-band router, which is capable of transmitting both on the 2.4 GHz and the 5 GHz bands will likely offer the best of both worlds: compatibility with old clients limited to 2.4 GHz, and much better performance for any client on the 5 GHz band.
Putting it all together, what does this tell us about the performance of WiFi?
There is no such thing as “typical” WiFi performance. The operating range will vary based on the standard, location of the user, used devices, and the local radio environment. If you are lucky, and you are the only WiFi user, then you can expect high throughput, low latency, and low variability in both. But once you are competing for access with other peers, or nearby WiFi networks, then all bets are off—expect high variability for latency and bandwidth.
The probabilistic scheduling of WiFi transmissions can result in a high number of collisions between multiple wireless peers in the area. However, even if that is the case, this does not necessarily translate to higher amounts of observed TCP packet loss. The data and physical layer implementations of all WiFi protocols have their own retransmission and error correction mechanisms, which hide these wireless collisions from higher layers of the networking stack.
In other words, while TCP packet loss is definitely a concern for data delivered over WiFi, the absolute rate observed by TCP is often no higher than that of most wired networks. Instead of direct TCP packet loss, you are much more likely to see higher variability in packet arrival times due to the underlying collisions and retransmissions performed by the lower link and physical layers.
The preceding performance characteristics of WiFi may paint an overly stark picture against it. In practice, it seems to work “well enough” in most cases, and the simple convenience that WiFi enables is hard to beat. In fact, you are now more likely to have a device that requires an extra peripheral to get an Ethernet jack for a wired connection than to find a computer, smartphone, or tablet that is not WiFi enabled.
With that in mind, it is worth considering whether your application can benefit from knowing about and optimizing for WiFi networks.
In practice, a WiFi network is usually an extension to a wired LAN, which is in turn connected via DSL, cable, or fiber to the wide area network. For an average user in the U.S., this translates to 8.6 Mbps of edge bandwidth and a 3.1 Mbps global average (Table 1-2). In other words, most WiFi clients are still likely to be limited by the available WAN bandwidth, not by WiFi itself. That is, when the “radio network weather” is nice!
However, bandwidth bottlenecks aside, this also frequently means that a typical WiFi deployment is backed by an unmetered WAN connection—or, at the very least, a connection with much higher data caps and maximum throughput. While many users may be sensitive to large downloads over their 3G or 4G connections due to associated costs and bandwidth caps, frequently this is not as much of a concern when on WiFi.
Of course, the unmetered assumption is not true in all cases (e.g., a WiFi tethered device backed by a 3G or 4G connection), but in practice it holds true more often than not. Consequently, large downloads, updates, and streaming use cases are best done over WiFi when possible. Don’t be afraid to prompt the user to switch to WiFi on such occasions!
As we saw, WiFi provides no bandwidth or latency guarantees. The user’s router may have some application-level QoS policies, which may provide a degree of fairness to multiple peers on the same wireless network. However, the WiFi radio interface itself has very limited support for QoS. Worse, there are no QoS policies between multiple, overlapping WiFi networks.
As a result, the available bandwidth allocation may change dramatically, on a second-to-second basis, based on small changes in location, activity of nearby wireless peers, and the general radio environment.
As an example, an HD video stream may require several megabits per second of bandwidth (Table 6-3), and while most WiFi standards are sufficient in ideal conditions, in practice you should not be surprised to see, and should anticipate, intermittent drops in throughput. In fact, due to the dynamic nature of available bandwidth, you cannot and should not extrapolate past download bitrate too far into the future. Testing for bandwidth rate just at the beginning of the video will likely result in intermittent buffering pauses as the radio conditions change during playback.
| Container | Video resolution | Encoding | Video bitrate (Mbit/s) |
mp4 | 360p | H.264 | 0.5 |
mp4 | 480p | H.264 | 1–1.5 |
mp4 | 720p | H.264 | 2–2.9 |
mp4 | 1080p | H.264 | 3–4.3 |
Instead, while we can’t predict the available bandwidth, we can and should adapt based on continuous measurement through techniques such as adaptive bitrate streaming.
Just as there are no bandwidth guarantees when on WiFi, similarly, there are no guarantees on the latency of the first wireless hop. Further, things get only more unpredictable if multiple wireless hops are needed, such as in the case when a wireless bridge (relay) access point is used.
In the ideal case, when there is minimum interference and the network is not loaded, the wireless hop can take less than one millisecond with very low variability. However, in practice, in high-density urban and office environments the presence of dozens of competing WiFi access points and peers creates a lot of contention for the same radio frequencies. As a result, you should not be surprised to see a 1–10 millisecond median for the first wireless hop, with a long latency tail: expect an occasional 10–50 millisecond delay and, in the worst case, even as high as hundreds of milliseconds.
If your application is latency sensitive, then you may need to think carefully about adapting its behavior when running over a WiFi network. In fact, this may be a good reason to consider WebRTC, which offers the option of an unreliable UDP transport. Of course, switching transports won’t fix the radio network, but it can help lower the protocol and application induced latency overhead.
As of early 2013, there are now an estimated 6.4 billion worldwide cellular connections. For 2012 alone, IDC market intelligence reports show an estimated 1.1 billion shipments for smart connected devices—smartphones, tablets, laptops, PCs, and so on. However, even more remarkable are the hockey stick growth projections for the years to come: the same IDC reports forecast the new device shipment numbers to climb to over 1.8 billion by 2016, and other cumulative forecasts estimate a total of over 20 billion connected devices by 2020.
With an estimated human population of 7 billion in 2012, rising to 7.5 billion by 2020, these trends illustrate our insatiable appetite for smart connected devices: apparently, most of us are not satisfied with just one.
However, the absolute number of connected devices is only one small part of the overall story. Implicit in this growth is also the insatiable demand for high-speed connectivity, ubiquitous wireless broadband access, and the connected services that must power all of these new devices! This is where, and why, we must turn our conversation to the performance of the various cellular technologies, such as GSM, CDMA, HSPA, and LTE. Chances are, most of your users will be using one of these technologies, some exclusively, to access your site or service. The stakes are high, we have to get this right, and mobile networks definitely pose their own set of performance challenges.
Navigating the forest of the various cellular standards, release versions, and the pros and cons of each could occupy not chapters, but entire books. Our goal here is much more humble: we need to develop an intuition for the operating parameters, and their implications, of the major past and future milestones (Table 7-1) of the dominant wireless technologies in the market.
| Generation | Peak data rate | Description |
1G | no data | Analog systems |
2G | Kbit/s | First digital systems as overlays or parallel to analog systems |
3G | Mbit/s | Dedicated digital networks deployed in parallel to analog systems |
4G | Gbit/s | Digital and packet-only networks |
The first important realization is that the underlying standards for each wireless generation are expressed in terms of peak spectral efficiency (bps/Hz), which is then translated to impressive numbers such as Gbit/s+ peak data rates for 4G networks. However, you should now recognize the key word in the previous sentence: peak! Think back to our earlier discussion on Measuring Real-World Wireless Performance—peak data rates are achieved in ideal conditions.
Regardless of the standard, the real performance of every network will vary by provider, their configuration of the network, the number of active users in a given cell, the radio environment in a specific location, the device in use, plus all the other factors that affect wireless performance. With that in mind, while there are no guarantees for data rates in real-world environments, a simple but effective strategy to calibrate your performance expectations (Table 7-2) is to assume much closer to the lower bound for data throughput, and toward the higher bound for packet latency for every generation.
| Generation | Data rate | Latency |
2G | 100–400 Kbit/s | 300–1000 ms |
3G | 0.5–5 Mbit/s | 100–500 ms |
4G | 1–50 Mbit/s | < 100 ms |
To complicate matters further, the classification of any given network as 3G or 4G is definitely too coarse, and correspondingly so is the expected throughput and latency. To understand why this is the case, and where the industry is heading, we first need to take a quick survey of the history of the different technologies and the key players behind their evolution.
The first commercial 1G network was launched in Japan in 1979. It was an analog system and offered no data capabilities. In 1991, the first 2G network was launched in Finland based on the emerging GSM (Global System for Mobile Communications, originally Groupe Spécial Mobile) standard, which introduced digital signaling within the radio network. This enabled first circuit-switched mobile data services, such as text messaging (SMS), and packet delivery at a whopping peak data rate of 9.6 Kbit/s!
It wasn’t until the mid 1990s, when general packet radio service (GPRS) was first introduced to the GSM standard that wireless Internet access became a practical, albeit still very slow, possibility: with GPRS, you could now reach 172 Kbit/s, with typical roundtrip latency hovering in high hundreds of milliseconds. The combination of GPRS and earlier 2G voice technologies is often described as 2.5G. A few years later, these networks were enhanced by EDGE (Enhanced Data rates for GSM Evolution), which increased the peak data rates to 384 Kbit/s. The first EDGE networks (2.75G) were launched in the U.S. in 2003.
At this point, a pause and some reflection is warranted. Wireless communication is many decades old, but practical, consumer-oriented data services over mobile networks are a recent phenomenon! 2.75G networks are barely a decade old, which is recent history, and are also still widely used around the world. Yet, most of us now simply can’t imagine living without high-speed wireless access. The rate of adoption, and the evolution of the wireless technologies, has been nothing short of breathtaking.
Once the consumer demand for wireless data services began to grow, the question of radio network interoperability became a hot issue for everyone involved. For one, the telecom providers must buy and deploy the hardware for the radio access network (RAN), which requires significant capital investments and ongoing maintenance—standard hardware means lower costs. Similarly, without industry-wide standards, the users would be restricted to their home networks, limiting the use cases and convenience of mobile data access.
In response, the European Telecommunication Standards Institute (ETSI) developed the GSM standard in the early 1990’s, which was quickly adopted by many European countries and around the globe. In fact, GSM would go on to become the most widely deployed wireless standard, by some estimates, covering 80%–85% of the market (Figure 7-1). But it wasn’t the only one. In parallel, the IS-95 standard developed by Qualcomm also captured 10%–15% of the market, most notably with many network deployments across North America. As a result, a device designed for the IS-95 radio network cannot operate on the GSM network, and vice versa—an unfortunate property that is familiar to many international travelers.
In 1998, recognizing the need for global evolution of the deployed standards, as well as defining the requirements for the next generation (3G) networks, the participants in GSM and IS-95 standards organizations formed two global partnership projects:
Consequently, the development of both types of standards (Table 7-3) and associated network infrastructure has proceeded in parallel. Perhaps not directly in lockstep, but nonetheless following mostly similar evolution of the underlying technologies.
| Generation | Organization | Release |
2G | 3GPP | GSM |
3GPP2 | IS-95 (cdmaOne) | |
2.5G, 2.75G | 3GPP | GPRS, EDGE (EGPRS) |
3GPP2 | CDMA2000 | |
3G | 3GPP | UMTS |
3GPP2 | CDMA 2000 1x EV-DO Release 0 | |
3.5G, 3.75G, 3.9G | 3GPP | HSPA, HSPA+, LTE |
3GPP2 | EV-DO Revision A, EV-DO Revision B, EV-DO Advanced | |
4G | 3GPP | LTE-Advanced, HSPA+ Revision 11+ |
Chances are, you should see some familiar labels on the list: EV-DO, HSPA, LTE. Many network operators have invested significant marketing resources, and continue to do so, to promote these technologies as their “latest and fastest mobile data networks.” However, our interest and the reason for this historical detour is not for the marketing, but for the macro observations of the evolution of the mobile wireless industry:
There is no one 4G or 3G technology. The International Telecommunication Union (ITU) sets the international standards and performance characteristics, such as data rates and latency, for each wireless generation, and the 3GPP and 3GPP2 organizations then define the standards to meet and exceed these expectations within the context of their respective technologies.
How do you know which network type your carrier is using? Simple. Does your phone have a SIM card? If so, then it is a 3GPP technology that evolved from GSM. To find out more detailed information about the network, check your carrier’s FAQ, or if your phone allows it, check the network information directly on your phone.
For Android users, open your phone dial screen and type in: *#*#4636#*#*. If your phone allows it, it should open a diagnostics screen where you can inspect the status and type of your mobile connection, battery diagnostics, and more.
In the context of 3G networks, we have two dominant and competing standards: UMTS and CDMA-based networks, which are developed by 3GPP and 3GPP2, respectively. However as the earlier table of cellular standards (Table 7-3) shows, each is also split into several transitional milestones: 3.5G, 3.75G, and 3.9G technologies.
Why couldn’t we simply jump to 4G instead? Well, standards take a long time to develop, but even more importantly, there are big financial costs for deploying new network infrastructure. As we will see, 4G requires an entirely different radio interface and parallel infrastructure to 3G. Because of this, and also for the benefit of the many users who have purchased 3G handsets, both 3GPP and 3GPP2 have continued to evolve the existing 3G standards, which also enables the operators to incrementally upgrade their existing networks to deliver better performance to their existing users.
Not surprisingly, the throughput, latency, and other performance characteristics of the various 3G networks have improved, sometimes dramatically, with every new release. In fact, technically, LTE is considered a 3.9G transitional standard! However, before we get to LTE, let’s take a closer look at the various 3GPP and 3GPP2 milestones.
| Release | Date | Summary |
99 | 1999 | First release of the UMTS standard |
4 | 2001 | Introduced an all-IP core network |
5 | 2002 | Introduced High-Speed Packet Downlink Access (HSDPA) |
6 | 2004 | Introduced High-Speed Packet Uplink Access (HSUPA) |
7 | 2007 | Introduced High-Speed Packet Access Evolution (HSPA+) |
8 | 2008 | Introduced new LTE System Architecture Evolution (SAE) |
9 | 2009 | Improvements to SAE and WiMAX interoperability |
10 | 2010 | Introduced 4G LTE-Advanced architecture |
In the case of networks following the 3GPP standards, the combination of HSDPA and HSUPA releases is often known and marketed as a High-Speed Packet Access (HSPA) network. This combination of the two releases enabled low single-digit Mbit/s throughput in real-world deployments, which was a significant step up from the early 3G speeds. HSPA networks are often labeled as 3.5G.
From there, the next upgrade was HSPA+ (3.75G), which offered significantly lower latencies thanks to a simplified core network architecture and data rates in mid to high single-digit Mbit/s throughput in real-world deployments. However, as we will see, release 7, which introduced HSPA+, was not the end of the line for this technology. In fact, the HSPA+ standards have been continuously refined since then and are now competing head to head with LTE and LTE-Advanced!
| Release | Date | Summary |
Rel. 0 | 1999 | First release of the 1x EV-DO standard |
Rev. A | 2001 | Upgrade to peak data-rate, lower latency, and QoS |
Rev. B | 2004 | Introduced multicarrier capabilities to Rev. A |
Rev. C | 2007 | Improved core network efficiency and performance |
The CDMA2000 EV-DO standard developed by 3GPP2 followed a similar network upgrade path. The first release (Rel. 0) enabled low single digit Mbit/s downlink throughput but very low uplink speeds. The uplink performance was addressed with Rev. A, and both uplink and downlink speeds were further improved in Rev. B. Hence, a Rev. B network was able to deliver mid to high single-digit Mbit/s performance to its users, which makes it comparable to HSPA and early HSPA+ networks—aka, 3.5–3.75G.
The Rev. C release is also frequently referred to as EV-DO Advanced and offers significant operational improvements in capacity and performance. However, the adoption of EV-DO Advanced has not been nearly as strong as that of HSPA+. Why? If you paid close attention to the standards generation table (Table 7-3), you may have noticed that 3GPP2 does not have an official and competing 4G standard!
While 3GPP2 could have continued to evolve its CDMA technologies, at some point both the network operators and the network vendors agreed on 3GPP LTE as a common 4G successor to all types of networks. For this reason, many of the CDMA network operators are also some of the first to invest into early LTE infrastructure, in part to be able to compete with ongoing HSPA+ improvements.
In other words, most mobile operators around the world are converging on HSPA+ and LTE as the future mobile wireless standards—that’s the good news. Having said that, don’t hold your breath. Existing 2G and 3–3.75G technologies are still powering the vast majority of deployed mobile radio networks, and even more importantly, will remain operational for at least another decade.
3G is often described as “mobile broadband.” However, broadband is a relative term. Some pin it as a communication bandwidth of at least 256 Kbit/s, others as that exceeding 640 Kbit/s, but the truth is that the value keeps changing based on the experience we are trying to achieve. As the services evolve and demand higher throughput, so does the definition of broadband.
In that light, it might be more useful to think of 3G standards as those targeting and exceeding the Mbit/s bandwidth threshold. How far over the Mbit/s barrier? Well, that depends on the release version of the standard (as we saw earlier), the carrier configuration of the network, and the capabilities of the device in use.
Before we dissect the various 4G technologies, it is important to understand what stands behind the “4G” label. Just as with 3G, there is no one 4G technology. Rather, 4G is a set of requirements (IMT-Advanced) that was developed and published by the ITU back in 2008. Any technology that meets these requirements can be labeled as 4G.
Some example requirements of IMT-Advanced include the following:
The actual list is much, much longer but the preceding captures the highlights important for our discussion: much higher throughput and significantly lower latencies when compared to earlier generations. Armed with these criteria, we now know how to classify a 4G network—right? Not so fast, that would be too easy! The marketing departments also had to have their say.
LTE-Advanced is a standard that was specifically developed to satisfy all the IMT-Advanced criteria. In fact, it was also the first 3GPP standard to do so. However, if you were paying close attention, you would have noticed that LTE (release 8) and LTE-Advanced (release 10) are, in fact, different standards. Technically, LTE should really be considered a 3.9G transitional standard, even though it lays much of the necessary groundwork to meet the 4G requirements—it is almost there, but not quite!
However, this is where the marketing steps in. The 3G and 4G trademarks are held by the ITU, and hence their use should correspond to defined requirements for each generation. Except the carriers won a marketing coup and were able to redefine the “4G” trademark to include a set of technologies that are significantly close to the 4G requirements. For this reason, LTE (release 8) and most HSPA+ networks, which do not meet the actual technical 4G requirements, are nonetheless marketed as “4G.”
What about the real (LTE-Advanced) 4G deployments? Those are coming, but it remains to be seen how these networks will be marketed in light of their earlier predecessors. Regardless, the point is, the “4G” label as it is used today by many carriers is ambiguous, and you should read the fine print to understand the technology behind it.
Despite the continuous evolution of the 3G standards, the increased demand for high data transmission speeds and lower latencies exposed a number of inherent design limitations in the earlier UMTS technologies. To address this, 3GPP set out to redesign both the core and the radio networks, which led to the creation of the aptly named Long Term Evolution (LTE) standard:
Not surprisingly, the preceding list should read similar to the IMT-Advanced requirements we saw earlier. LTE (release 8) laid the groundwork for the new network architecture, and LTE-Advanced (release 10) delivered the necessary improvements to meet the true 4G requirements set by IMT-Advanced.
At this point it is important to note that due to radio and core network implementation differences, LTE networks are not simple upgrades to existing 3G infrastructure. Instead, LTE networks must be deployed in parallel and on separate spectrum from existing 3G infrastructure. However, since LTE is a common successor to both UMTS and CDMA standards, it does provide a way to interoperate with both: an LTE subscriber can be seamlessly handed off to a 3G network and be migrated back where LTE infrastructure is available.
Finally, as the name implies, LTE is definitely the long-term evolution plan for virtually all future mobile networks. The only question is, how distant is this future? A few carriers have already begun investing into LTE infrastructure, and many others are beginning to look for the spectrum, funds, or both, to do so. However, current industry estimates show that this migration will indeed be a long-term one—perhaps over the course of the next decade or so. In the meantime, HSPA+ is set to take the center stage.
Every LTE-capable device must have multiple radios for mandatory MIMO support. However, each device will also need separate radio interfaces for earlier 3G and 2G networks. If you are counting, that translates to three or four radios in every handset! For higher data rates with LTE, you will need 4x MIMO, which brings the total to five or six radios. You were wondering why your battery is drained so quickly?
HSPA+ was first introduced in 3GPP release 7, back in 2007. However, while the popular attention quickly shifted toward LTE, which was first introduced in 3GPP release 8 in 2008, what is often overlooked is that the development of HSPA+ did not cease and continued to coevolve in parallel. In fact, HSPA+ release 10 meets many of the IMT-Advanced criteria. But, you may ask, if we have LTE and everyone is in agreement that it is the standard for future mobile networks, why continue to develop and invest into HSPA+? As usual, the answer is a simple one: cost.
3GPP 3G technologies command the lion’s share of the established wireless market around the world, which translates into huge existing infrastructure investments by the carriers around the globe. Migrating to LTE requires development of new radio networks, which once again translates into significant capital expenditures. By contrast, HSPA+ offers a much more capital efficient route: the carriers can deploy incremental upgrades to their existing networks and get comparable performance.
Cost-effectiveness is the name of the game and the reason why current industry projections (Figure 7-2) show HSPA+ as responsible for the majority of 4G upgrades around the world for years to come. In the meantime, CDMA technologies developed by 3GPP2 will continue to coexist, although their number of subscriptions is projected to start declining slowly, while new LTE deployments will proceed in parallel with different rates in different regions—in part due to cost constraints, and in part due to different regulation and the availability of required radio spectrum.
For a variety of reasons, North America appears to be the leader in LTE adoption: current industry projections show the number of LTE subscribers in U.S. and Canada surpassing that of HSPA by 2016 (Figure 7-3). However, the rate of LTE adoption in North America appears to be significantly more aggressive than in most other countries. Within the global context, HSPA+ is set to be the dominant mobile wireless technology of the current decade.
While many are first surprised by the trends in the HSPA+ vs. LTE adoption, this is not an unexpected outcome. If nothing else, it serves to illustrate an important point: it takes roughly a decade from the first specification of a new wireless standard to its mainstream availability in real-world wireless networks.
By extension, it is a fairly safe bet that we will be talking about LTE-Advanced in earnest by the early 2020s! Unfortunately, deploying new radio infrastructure is a costly and time-consuming proposition.
Crystal ball gazing is a dangerous practice in our industry. However, by this point we have covered enough to make some reasonable predictions about what we can and should expect out of the currently deployed mobile networks, as well as where we might be in a few years’ time.
First, the wireless standards are evolving quickly, but the physical rollout of these networks is both a costly and a time-consuming exercise. Further, once deployed, the network must be maintained for significant amounts of time to recoup the costs and to keep existing customers online. In other words, while there is a lot of hype and marketing around 4G, older-generation networks will continue to operate for at least another decade. When building for the mobile web, plan accordingly.
Ironically, while 4G networks provide significant improvements for IP data delivery, 3G networks are still much more efficient in handling the old-fashioned voice traffic! Voice over LTE (VoLTE) is currently in active development and aims to enable efficient and reliable voice over 4G, but most current 4G deployments still rely on the older, circuit-switched infrastructure for voice delivery.
Consequently, when building applications for mobile networks, we cannot target a single type or generation of network, or worse, hope for specific throughput or latency performance. As we saw, the actual performance of any network is highly variable, based on deployed release, infrastructure, radio conditions, and a dozen other variables. Our applications should adapt to the continuously changing conditions within the network: throughput, latency, and even the availability of the radio connection. When the user is on the go, it is highly likely that he may transition between multiple generations of networks (LTE, HSPA+, HSPA, EV-DO, and even GPRS Edge) based on the available coverage and signal strength. If the application fails to account for this, then the user experience will suffer.
The good news is HSPA+ and LTE adoption is growing very fast, which enables an entirely new class of high-throughput and latency-sensitive applications previously not possible. Both are effectively on par in throughput and latency (Table 7-6): mid to high digit Mbps throughput in real-world environments, and sub-100-millisecond latency, which makes them comparable to many home and office WiFi networks.
| HSPA+ | LTE | LTE-Advanced | |
Peak downlink speed (Mbit/s) | 168 | 300 | 3,000 |
Peak uplink speed (Mbit/s) | 22 | 75 | 1,500 |
Maximum MIMO streams | 2 | 4 | 8 |
Idle to connected latency (ms) | < 100 | < 100 | < 50 |
Dormant to active latency (ms) | < 50 | < 50 | < 10 |
User-plane one-way latency (ms) | < 10 | < 5 | < 5 |
However, while 4G wireless performance is often compared to that of WiFi, or wired broadband, it would be incorrect to assume that we can get away with treating them as the same environments: that they are definitely not.
For example, most users and developers expect an “always on” experience where the device is permanently connected to the Internet and is ready to instantaneously react to user input or an incoming data packet. This assumption holds true in the tethered world but is definitely incorrect for mobile networks. Practical constraints such as battery life and device capabilities mean that we must design our applications with explicit awareness of the constraints of mobile networks. To understand these differences, let’s dig a little deeper.
What is often forgotten is that the deployed radio network is only half of the equation. It goes without saying that devices from different manufacturers and release dates will have very different characteristics: CPU speeds and core counts, amount of available memory, storage capacity, GPU, and more. Each of these factors will affect the overall performance of the device and the applications running on it.
However, even with all of these variables accounted for, when it comes to network performance, there is one more section that is often overlooked: radio capabilities. Specifically, the device that the user is holding in her hands must also be able to take advantage of the deployed radio infrastructure! The carrier may deploy the latest LTE infrastructure, but a device designed for an earlier release may simply not be able to take advantage of it, and vice versa.
Both the 3GPP and 3GPP2 standards continue to evolve and enhance the radio interface requirements: modulation schemes, number of radios, and so on. To get the best performance out of any network, the device must also meet the specified user equipment (UE) category requirements for each type of network. In fact, for each release, there are often multiple UE categories, each of which will offer very different radio performance.
An obvious and important question is, why? Once again, the answer is a simple one: cost. Availability of multiple categories of devices enables device differentiation, various price points for price-sensitive users, and ability to adapt to deployed network infrastructure on the ground.
The HSPA standard alone specifies over 36 possible UE categories! Hence, just saying that you have an “HSPA capable device” (Table 7-7) is not enough—you need to read the fine print. For example, assuming the radio network is capable, to get the 42.2 Mbps/s throughput, you would also need a category 20 (2x MIMO), or category 24 (dual-cell) device. Finally, to confuse matters further, a category 21 device does not automatically guarantee higher throughput over a category 20 handset.
| 3GPP Release | Category | MIMO, Multicell | Peak data rate (Mbit/s) |
5 | 8 | — | 7.2 |
5 | 10 | — | 14.0 |
7 | 14 | — | 21.1 |
8 | 20 | 2x MIMO | 42.2 |
8 | 21 | Dual-cell | 23.4 |
8 | 24 | Dual-cell | 42.2 |
10 | 32 | Quad-cell + MIMO | 168.8 |
Similarly, the LTE standard defines its own set of user equipment categories (Table 7-8): a high-end smartphone is likely to be a category 3–5 device, but it will also likely share the network with a lot of cheaper category 1–2 neighbors. Higher UE categories, which require 4x and even 8x MIMO, are more likely to be found in specialized devices—powering that many radios simultaneously consumes a lot of power, which may not be very practical for something in your pocket!
| 3GPP release | Category | MIMO | Peak downlink (Mbit/s) | Peak uplink (Mbit/s) |
8 | 1 | 1x | 10.3 | 5.2 |
8 | 2 | 2x | 51.0 | 25.5 |
8 | 3 | 2x | 102.0 | 51.0 |
8 | 4 | 2x | 150.8 | 51.0 |
8 | 5 | 4x | 299.6 | 75.4 |
10 | 6 | 2x or 4x | 301.5 | 51.0 |
10 | 7 | 2x or 4x | 301.5 | 102.0 |
10 | 8 | 8x | 2998.6 | 1497.8 |
In practice, most of the early LTE deployments are targeting category 1–3 devices, with early LTE-Advanced networks focusing on category 3 as their primary UE type.
If you own an LTE or an HSPA+ device, do you know its category classification? And once you figure that out, do you know which 3GPP release your network operator is running? To get the best performance, the two must match. Otherwise, you will be limited either by the capabilities of the radio network or the device in use.
Both 3G and 4G networks have a unique feature that is not present in tethered and even WiFi networks. The Radio Resource Controller (RRC) mediates all connection management between the device in use and the radio base station (Figure 7-4). Understanding why it exists, and how it affects the performance of every device on a mobile network, is critical to building high-performance mobile applications. The RRC has direct impact on latency, throughput, and battery life of the device in use.
When using a physical connection, such as an Ethernet cable, your computer has a direct and an always-on network link, which allows either side of this connection to send data packets at any time; this is the best possible case for minimizing latency. As we saw in From Ethernet to a Wireless LAN, the WiFi standard follows a similar model, where each device is able to transmit at any point in time. This too provides minimum latency in the best case, but due to the use of the shared radio medium can also lead to high collision rates and unpredictable performance if there are many active users. Further, because any WiFi peer could start transmitting at any time, all others must also be ready to receive. The radio is always on, which consumes a lot of power.
In practice, keeping the WiFi radio active at all times is simply too expensive, as battery capacity is a limited resource on most devices. Hence, WiFi offers a small power optimization where the access point broadcasts a delivery traffic indication message (DTIM) within a periodic beacon frame to indicate that it will be transmitting data for certain clients immediately after. In turn, the clients can listen for these DTIM frames as hints for when the radio should be ready to receive, and otherwise the radio can sleep until the next DTIM transmission. This lowers battery use but adds extra latency.
The upcoming WiFi Multimedia (WMM) standard will further improve the power efficiency of WiFi devices with the help of the new PowerSave mechanisms such as NoAck and APSD (Automatic Power Save Delivery).
Therein lies the problem for 3G and 4G networks: network efficiency and power. Or rather, lack of power, due to the fact that mobile devices are constrained by their battery capacity and a requirement for high network efficiency among a significantly larger number of active users in the cell. This is why the RRC exists.
As the name implies, the Radio Resource Controller assumes full responsibility over scheduling of who talks when, allocated bandwidth, the signal power used, the power state of each device, and a dozen other variables. Simply put, the RRC is the brains of the radio access network. Want to send data over the wireless channel? You must first ask the RRC to allocate some radio resources for you. Have incoming data from the Internet? The RRC will notify you for when to listen to receive the inbound packets.
The good news is all the RRC management is performed by the network. The bad news is, while you can’t necessarily control the RRC via an API, if you do want to optimize your application for 3G and 4G networks, then you need to be aware of and work within the constraints imposed by the RRC.
The RRC lives within the radio network. In 2G and 3G networks, the RRC lived in the core carrier network, and in 4G the RRC logic has been moved directly to the serving radio tower (eNodeB) to improve performance and reduce coordination latency.
The radio is one of the most power-hungry components of any handset. In fact, the screen is the only component that consumes higher amounts of power when active—emphasis on active. In practice, the screen is off for significant periods of time, whereas the radio must maintain the illusion of an “always-on” experience such that the user is reachable at any point in time.
One way to achieve this goal is to keep the radio active at all times, but even with the latest advances in battery capacity, doing so would drain the battery in a matter of hours. Worse, latest iterations of the 3G and 4G standards require parallel transmissions (MIMO, Multicell, etc.), which is equivalent to powering multiple radios at once. In practice, a balance must be struck between keeping the radio active to service low-latency interactive traffic and cycling into low-power states to enable reasonable battery performance.
How do the different technologies compare, and which is better for battery life? There is no one single answer. With WiFi, each device sets its own transmit power, which is usually in the 30–200 mW range. By comparison, the transmit power of the 3G/4G radio is managed by the network and can consume as low as 15 mW when in an idle state. However, to account for larger range and interference, the same radio can require 1,000–3,500 mW when transmitting in a high-power state!
In practice, when transferring large amounts of data, WiFi is often far more efficient if the signal strength is good. But if the device is mostly idle, then the 3G/4G radio is more effective. For best performance, ideally we would want dynamic switching between the different connection types. However, at least for the moment, no such mechanism exists. This is an active area of research, both in the industry and academia.
So how does the battery and power management affect networking performance? Signal power (explained in Signal Power) is one of the primary levers to achieve higher throughput. However, high transmit power consumes significant amounts of energy and hence may be throttled to achieve better battery life. Similarly, powering down the radio may also tear down the radio link to the radio tower altogether, which means that in the event of a new transmission, a series of control messages must be first exchanged to reestablish the radio context, which can add tens and even hundreds of milliseconds of latency.
Both throughput and latency performance are directly impacted by the power management profile of the device in use. In fact, and this is key, in 3G and 4G networks the radio power management is controlled by the RRC: not only does it tell you when to communicate, but it will also tell you the transmit power and when to cycle into different power states.
The radio state of every LTE device is controlled by the radio tower currently servicing the user. In fact, the 3GPP standard defines a well-specified state machine, which describes the possible power states of each device connected to the network (Figure 7-5). The network operator can make modifications to the parameters that trigger the state transitions, but the state machine itself is the same across all LTE deployments.
The device is either idle, in which case it is only listening to control channel broadcasts, such as paging notifications of inbound traffic, or connected, in which case the network has an established context and resource assignment for the client.
When in an idle state, the device cannot send or receive any data. To do so, it must first synchronize itself to the network by listening to the network broadcasts and then issue a request to the RRC to be moved to the “connected” state. This negotiation can take several roundtrips to establish, and the 3GPP LTE specification allocates a target of 100 milliseconds or less for this state transition. In LTE-Advanced, the target time was further reduced to 50 milliseconds.
Once in a connected state, a network context is established between the radio tower and the LTE device, and data can be transferred. However, once either side completes the intended data transfer, how does the RRC know when to transition the device to a lower power state? Trick question—it doesn’t!
IP traffic is bursty, optimized TCP connections are long-lived, and UDP traffic provides no “end of transmission” indicator by design. As a result, and not unlike the NAT connection-state timeouts solution covered in Connection-State Timeouts, the RRC state machine depends on a collection of timers to trigger the RRC state transitions.
Finally, because the connected state requires such high amounts of power, multiple sub-states are available (Figure 7-5) to allow for more efficient operation:
In the high-power state, the RRC creates a reservation for the device to receive and transmit data over the wireless interface and notifies the device for what these time-slots are, the transmit power that must be used, the modulation scheme, and a dozen other variables. Then, if the device has been idle for a configured period of time, it is transitioned to a Short DRX power state, where the network context is still maintained, but no specific radio resources are assigned. When in Short DRX state, the device only listens to periodic broadcasts from the network, which allows it to preserve the battery—not unlike the DTIM interval in WiFi.
If the radio remains idle long enough, it is then transitioned to the Long DRX state, which is identical to the Short DRX state, except that the device sleeps for longer periods of time between waking up to listen to the broadcasts (Figure 7-6).
What happens if the network or the mobile device must transmit data when the radio is in one of Short or Long DRX (dormant) states? The device and the RRC must first exchange control messages to negotiate when to transmit and when to listen to radio broadcasts. For LTE, this negotiation time (“dormant to connected”) is specified as less than 50 milliseconds, and further tightened to less than 10 milliseconds for LTE-Advanced.
So what does this all mean in practice? Depending on which power state the radio is in, an LTE device may first require anywhere from 10 to 100 milliseconds (Table 7-9) of latency to negotiate the required resources with the RRC. Following that, application data can be transferred over the wireless link, through the carrier’s network, and then out to the public Internet. Planning for these delays, especially when designing latency-sensitive applications, can be all the difference between “unpredictable performance” and an optimized mobile application.
Earlier generation 3GPP networks prior to LTE and LTE-Advanced have a very similar RRC state machine that is also maintained by the radio network. That’s the good news. The bad news is the state machine for earlier generations is a bit more complicated (Figure 7-7), and the latencies are much, much higher. In fact, one reason why LTE offers better performance is precisely due to the simplified architecture and improved performance of the RRC state transitions.
Idle and DCH states are nearly identical to that of idle and connected in LTE. However, the intermediate FACH state is unique to UMTS networks (HSPA, HSPA+) and allows the use of a common channel for small data transfers: slow, steady, and consuming roughly half the power of the DCH state. In practice, this state was designed to handle non-interactive traffic, such as periodic polling and status checks done by many background applications.
Not surprisingly, the transition from DCH to FACH is triggered by a timer. However, once in FACH, what triggers a promotion back to DCH? Each device maintains a buffer of data to be sent, and as long as the buffer does not exceed a network-configured threshold, typically anywhere from 100 to 1,000 bytes, then the device can remain in the intermediate state. Finally, if no data is transferred while in FACH for some period of time, another timer transitions the device down to the idle state.
Unlike LTE, which offers two intermediate states (Short DRX and Long DRX), UMTS devices have just a single intermediate state: FACH. However, even though LTE offers a theoretically higher degree of power control, the radios themselves tend to consume more power in LTE devices; higher throughput comes at a cost of increased battery consumption. Hence, LTE devices still have a much higher power profile than their 3G predecessors.
Individual power states aside, perhaps the biggest difference between the earlier-generation 3G networks and LTE is the latency of the state transitions. Where LTE targets sub-hundred milliseconds for idle to connected states, the same transition from idle to DCH can take up to two seconds and require tens of control messages between the 3G device and the RRC! FACH to DCH is not much better either, requiring up to one and a half seconds for the state transition.
The good news is the latest HSPA+ networks have made significant improvements in this department and are now competitive with LTE (Table 7-6). However, we can’t count on ubiquitous access to 4G or HSPA+ networks; older generation 3G networks will continue to exist for at least another decade. Hence, all mobile applications should plan for multisecond RRC latency delays when accessing the network over a 3G interface.
While 3GPP standards such as HSPA, HSPA+, and LTE are the dominant network standards around the globe, it is important that we don’t forget the 3GPP2 CDMA based networks. The growth curve for EV-DO networks may look comparatively flat, but even so, current industry projections show nearly half a billion CDMA powered wireless subscriptions by 2017.
Not surprisingly, regardless of the differences in the standards, the fundamental limitations are the same in UMTS- and CDMA-based networks: battery power is a constraining resource, radios are expensive to operate, and network efficiency is an important goal. Consequently, CDMA networks also have an RRC state machine (Figure 7-8), which controls the radio state of each device.
This is definitely the simplest RRC state machine out of all the ones we have examined: the device is either in a high-power state, with allocated network resources, or it is idle. Further, all network transfers require a transition to a connected state, the latency for which is similar to that of HSPA networks: hundreds to thousands of milliseconds depending on the revision of the deployed infrastructure. There are no other intermediate states, and transitions back to idle are also controlled via carrier configured timeouts.
An important consequence of the timeout-driven radio state transitions, regardless of the generation or the underlying standard, is that it is very easy to construct network access patterns that can yield both poor user experience for interactive traffic and poor battery performance. In fact, all you have to do is wait long enough for the radio to transition to a lower-power state, and then trigger a network access to force an RRC transition!
To illustrate the problem, let’s assume that the device is on an HSPA+ network, which is configured to move from DCH to FACH state after 10 seconds of radio inactivity. Next, we load an application that schedules an intermittent transfer, such as a real-time analytics beacon, on an 11-second interval. What’s the net result? The device may end up spending hundreds of milliseconds in data transfer and otherwise idle while in a high-power state. Worse, it would transition into the low-power state only to be woken up again a few hundred milliseconds later—worst-case scenario for latency and battery performance.
Every radio transmission, no matter how small, forces a transition to a high-power state. Then, once the transmission is done, the radio will remain in this high-power state until the inactivity timer has expired (Figure 7-9). The size of the actual data transfer does not influence the timer. Further, the device may then also have to cycle through several more intermediate states before it can return back to idle.
The “energy tails” generated by the timer-driven state transitions make periodic transfers a very inefficient network access pattern on mobile networks. First, you have to pay the latency cost of the state transition, then the transfer happens, and finally the radio idles, wasting power, until all the timers fire and the device can return to the low-power state.
Now that we have familiarized ourselves with the RRC and device capabilities, it is useful to zoom out and consider the overall end-to-end architecture of a carrier network. Our goal here is not to become experts in the nomenclature and function of every component, of which there are dozens, but rather to highlight the components that have a direct impact on how the data flows through the carrier network and reasons why it may affect the performance of our applications.
The specific infrastructure and names of various logical and physical components within a carrier network depend on the generation and type of deployed network: EV-DO vs. HSPA vs. LTE, and so on. However, there are also many similarities among all of them, and in this chapter we’ll examine the high-level architecture of an LTE network.
Why LTE? First, it is the most likely architecture for new carrier deployments. Second, and even more importantly, one of the key features of LTE is its simplified architecture: fewer components and fewer dependencies also enable improved performance.
The radio access network (RAN) is the first big logical component of every carrier network (Figure 7-10), whose primary responsibility is to mediate access to the provisioned radio channel and shuttle the data packets to and from the user’s device. In fact, this is the component controlled and mediated by the Radio Resource Controller. In LTE, each radio base station (eNodeB) hosts the RRC, which maintains the RRC state machine and performs all resource assignment for each active user in its cell.
Whenever a user has a stronger signal from a nearby cell, or if his current cell is overloaded, he may be handed off to a neighboring tower. However, while this sounds simple on paper, the hand-off procedure is also the reason for much of the additional complexity within every carrier network. If all users always remained in the same fixed position, and stayed within reach of a single tower, then a static routing topology would suffice. However, as we all know, that is simply not the case: users are mobile and must be migrated from tower to tower, and the migration process should not interrupt any voice or data traffic. Needless to say, this is a nontrivial problem.
First of all, if the user’s device can be associated with any radio tower, how do we know where to route the incoming packets? Of course, there is no magic: the radio access network must communicate with the core network to keep track of the location of every user. Further, to handle the transparent handoff, it must also be able to dynamically update its existing tunnels and routes without interrupting any existing, user-initiated voice and data sessions.
In LTE, a tower-to-tower handoff can be performed within hundreds of milliseconds, which will yield a slight pause in data delivery at the physical layer, but otherwise this procedure is completely transparent to the user and to all applications running on her device. In earlier-generation networks, this same process can take up to several seconds.
However, we’re not done yet. Radio handoffs can be a frequent occurrence, especially in high-density urban and office environments, and requiring the user’s device to continuously perform the cell handoff negotiations, even when the device is idle, would consume a lot of energy on the device. Hence, an additional layer of indirection was added: one or more radio towers are said to form a “tracking area,” which is a logical grouping of towers defined by the carrier network.
The core network must know the location of the user, but frequently it knows only the tracking area and not the specific tower currently servicing the user—as we will see, this has important implications on the latency of inbound data packets. In turn, the device is allowed to migrate between towers within the same tracking area with no overhead: if the device is in idle RRC state, no notifications are emitted by the device or the radio network, which saves energy on the mobile handset.
The core network (Figure 7-11), which is also known as the Evolved Packet Core (EPC) in LTE is responsible for the data routing, accounting, and policy management. Put simply, it is the piece that connects the radio network to the public Internet.
First, we have the packet gateway (PGW), which is the public gateway that connects the mobile carrier to the public Internet. The PGW is the termination point for all external connections, regardless of the protocol. When a mobile device is connected to the carrier network, the IP address of the device is allocated and maintained by the PGW.
Each device within the carrier network has an internal identifier, which is independent of the assigned IP address. In turn, once a packet is received by the PGW, it is encapsulated and tunneled through the EPC to the radio access network. LTE uses Stream Control Transmission Protocol (SCTP) for control-plane traffic and a combination of GPRS Tunneling Protocol (GTP) and UDP for all other data.
The PGW also performs all the common policy enforcement, such as packet filtering and inspection, QoS assignment, DoS protection, and more. The Policy and Charging Rules Function (PCRF) component is responsible for maintaining and evaluating these rules for the packet gateway. PCRF is a logical component, meaning it can be part of the PGW, or it can stand on its own.
Now, let’s say the PGW has received a packet from the public Internet for one of the mobile devices on its network; where does it route the data? The PGW has no knowledge of the actual location of the user, nor the different tracking areas within the radio access network. This next step is the responsibility of the Serving Gateway (SGW) and the Mobility Management Entity (MME).
The PGW routes all of its packets to the SGW. However, to make matters even more complicated, the SGW may not know the exact location of the user either. This function is, in fact, one of the core responsibilities of the MME. The Mobility Management Entity component is effectively a user database, which manages all the state for every user on the network: their location on the network, type of account, billing status, enabled services, plus all other user metadata. Whenever a user’s location within the network changes, the location update is sent to the MME; when the user turns on their phone, the authentication is performed by the MME, and so on.
Hence, when a packet arrives at the SGW, a query to the MME is sent for the location of the user. Then, once the MME returns the answer, which contains the tracking area and the ID of the specific tower serving the target device, the SGW can establish a connection to the tower if none exists and route the user data to the radio access network.
In a nutshell, that is all there is to it. This high-level architecture is effectively the same in all the different generations of mobile data networks. The names of the logical components may differ, but fundamentally all mobile networks are subject to the following workflow:
An important factor in the performance of any carrier network is the provisioned connectivity and capacity between all the logical and physical components. The LTE radio interface may be capable of reaching up to 100 Mbps between the user and the radio tower, but once the signal is received by the radio tower, sufficient capacity must be available to transport all this data through the carrier network and toward its actual destination. Plus, let’s not forget that a single tower should be able to service many active users simultaneously!
Delivering a true 4G experience is not a simple matter of deploying the new radio network. The core network must also be upgraded, sufficient capacity links must be present between the EPC and the radio network, and all the EPC components must be able to process much higher data rates with much lower latencies than in any previous generation network.
In practice, a single radio tower may serve up to three nearby radio cells, which can easily add up to hundreds of active users. With 10+ Mbps data rate requirements per user, each tower needs a dedicated fiber link!
Needless to say, all of these requirements make 4G networks a costly proposition to the carrier: running fiber to all the radio stations, high-performance routers, and so on. In practice, it is now not unusual to find the overall performance of the network being limited not by the radio interface, but by the available backhaul capacity of the carrier network.
These performance bottlenecks are not something we can control as developers of mobile applications, but they do, once again, illustrate an important fact: the architecture of our IP networks is based on a best effort delivery model, which makes no guarantees about end-to-end performance. Once we remove the bottleneck from the first hop, which is the wireless interface, we move the bottleneck to the next slowest link in the network, either within the carrier network or somewhere else on the path toward our destination. In fact, this is nothing new; recall our earlier discussion on Last-Mile Latency in wired networks.
Just because you are connected over a 4G interface doesn’t mean you are guaranteed the maximum throughput offered by the radio interface. Instead, our applications must adapt to the continuously changing network weather over the wireless channel, within the carrier network, and on the public Internet.
One of the primary complaints about designing applications for the mobile web is the high variability in latency. Well, now that we have covered the RRC and the high-level architecture of a mobile network, we can finally connect the dots and see the end-to-end flow of the data packets, which should also explain why this variability exists. Even better, as we will see, much of the variability is actually very much predictable!
To start, let’s assume that the user has already authenticated with a 4G network and the mobile device is idle. Next, the user types in a URL and hits “Go.” What happens next?
First, because the phone is in idle RRC state, the radio must synchronize with the nearby radio tower and send a request for a new radio context to be established (Figure 7-12, step 1)—this negotiation requires several roundtrips between the handset and the radio tower, which may take up to 100 milliseconds. For earlier-generation networks, where the RRC is managed by the serving gateway, this negotiation latency is much higher—up to several seconds.
Once the radio context is established, the device has a resource assignment from the radio tower and is able to transmit data (step 2) at a specified rate and signal power. The time to transmit a packet of data from the user’s radio to the tower is known as the “user-plane one-way latency” and takes up to five milliseconds for 4G networks. Hence, the first packet incurs a much higher delay due to the need to perform the RRC transition, but packets immediately after incur only the constant first-hop latency cost, as long as the radio stays in the high-power state.
However, we are not done yet, as we have only transferred our packets from the device to the radio tower! From here, the packets have to travel through the core network—through the SGW to the PGW (step 3)—and out to the public Internet (step 4). Unfortunately, the 4G standards make no guarantees on latency of this path, and hence this latency will vary from carrier to carrier.
In practice, the end-to-end latency of many deployed 4G networks tends to be in the 30–100 ms range once the device is in a connected state—that is to say, without the control plane latency incurred by the initial packet. Hence, if up to 5 ms of the total time is accounted for on the first wireless hop, then the rest (25–95 ms) is the routing and transit overhead within the core network of the carrier.
Next, let’s say the browser has fetched the requested page and the user is engaging with the content. The radio has been idle for a few dozen seconds, which means that the RRC has likely moved the user into a DRX state (LTE RRC State Machine) to conserve battery power and to free up network resources for other users. At this point, the user decides to navigate to a different destination in the browser and hence triggers a new request. What happens now?
Nearly the same workflow is repeated as we just saw, except that because the device was in a dormant (DRX) state, a slightly quicker negotiation (Figure 7-12, step 1) can take place between the device and the radio tower—up to 50 milliseconds (Table 7-9) for dormant to connected.
In summary, a user initiating a new request incurs several different latencies:
The first two latencies are bounded by the 4G requirements, the core network latency is carrier specific, and the final piece is something you can influence by strategically positioning your servers closer to the user; see the earlier discussion on Speed of Light and Propagation Latency.
Now let’s examine the opposite scenario: the user’s device is idle, but a data packet must be routed from the PGW to the user (Figure 7-13). Once again, recall that all connections are terminated at the PGW, which means that the device can be idle, with its radio off, but the connection the device may have established earlier, such as a long-lived TCP session, can still be active at the PGW.
As we saw earlier, the PGW routes the inbound packet to the SGW (step 1), which in turn queries the MME. However, the MME may not know the exact tower currently servicing the user; recall that a collection of radio towers form a “tracking area.” Whenever a user enters a different tracking area, its location is updated in the MME, but tower handoffs within the same tracking area do not trigger an update to the MME.
Instead, if the device is idle, the MME sends a paging message (step 2) to all the towers in the tracking area, which in turn all broadcast a notification (step 3) on a shared radio channel, indicating that the device should reestablish its radio context to receive the inbound data. The device periodically wakes to listen to the paging messages, and if it finds itself on the paging list, then it initiates the negotiation (step 4) with the radio tower to reestablish the radio context.
Once the radio context is established, the tower that performed the negotiation sends a message back (step 5) to the MME indicating where the user is, the MME returns the answer to the serving gateway, and the gateway finally routes the message (step 6) to the tower, which then delivers (step 7) the message to the device! Phew.
Once the device is in a connected state, a direct tunnel is established between the radio tower and the serving gateway, which means that further incoming packets are routed directly to the tower without the paging overhead, skipping steps 2–5. Once again, the first packet incurs a much higher latency cost on mobile networks! Plan for it.
The preceding packet workflow is transparent to IP and all layers above it, including our applications: the packets are buffered by the PGW, SGW, and the eNodeB at each stage until they can be routed to the device. In practice, this translates to observable latency jitter in packet arrival times, with the first packet incurring the highest delays due to control-plane negotiation.
Existing 4G radio and modulation technologies are already within reach of the theoretical limits of the wireless channel. Hence, the next order of magnitude in wireless performance will not come from improvements in the radio interfaces, but rather from smarter topologies of the wireless networks—specifically, through wide deployment of multilayer heterogeneous networks (HetNets), which will also require many improvements in the intra-cell coordination, handoff, and interference management.
The core idea behind HetNets is a simple one: instead of relying on just the macro coverage of a large geographic area, which creates a lot of competition for all users, we can also cover the area with many small cells (Figure 7-14), each of which can minimize path loss, require lower transmit power, and enable better performance for all users.
A single macrocell can cover up to tens of square miles in low-density wireless environments, but in practice, in high-density urban and office settings, can be limited to anywhere from just 50 to 300 meters! In other words, it can cover a small block, or a few buildings. By comparison, microcells are designed to cover a specific building; picocells can service one or more separate floors, and femtocells can cover a small apartment and leverage your existing broadband service as the wireless backhaul.
However, note that HetNets are not simply replacing the macrocells with many small cells. Instead, HetNets are layering multiple cells on top of one another! By deploying overlapping layers of wireless networks, HetNets can provide much better network capacity and improved coverage for all users. However, the outstanding challenges are in minimizing interference, providing sufficient uplink capacity, and creating and improving protocols for seamless handoff between the various layers of networks.
What does this mean for the developers building mobile applications? Expect the number of handoffs between different cells to increase significantly and adapt accordingly: the latency and throughput performance may vary significantly.
Picocells are often used by mobile carriers to extend coverage to indoor and outdoor areas where signal quality may be poor, or to add network capacity in areas with very dense phone usage—e.g., a large public area, a conference hall, stadium, train station, and so on. Some picocells may be deployed permanently, while others may be put up for a specific occasion: wireless capacity planning and modeling (Figure 7-15) is both an art and a science!
Dedicated modeling software, such as TamoGraph Site Survey shown earlier, is often used to model the physical environment, number of active users, and the wireless technology in use (WiFi in the previous example) to help determine the required number, placement, and configuration of networks.
By this point, one has to wonder whether all the extra protocols, gateways, and negotiation mechanisms within a 3G or 4G network are worth the additional complexity. By comparison, WiFi implementation is much simpler and seems to work well enough, doesn’t it? Answering this question requires a lot of caveats, since as we saw, measuring wireless performance is subject to dozens of environmental and technology considerations. Further, the answer also depends on chosen evaluation criteria:
However, while there are dozens of different stakeholders (users, carriers, and handset manufacturers, just to name a few), each with their own priority lists, early tests of the new 4G networks are showing very promising results. In fact, key metrics such as network latency, throughput, and network capacity are often outperforming WiFi!
As a concrete example, a joint research project between the University of Michigan and AT&T Labs ran a country-wide test (Figure 7-16) within the U.S., comparing 4G, 3G, and WiFi (802.11g, 2.4GHz) performance:
The box-and-whisker plot for each connection type packs a lot of useful information into a small graphic: the whiskers show the range of the entire distribution, the box shows the 25%–75% quantiles of the distribution, and the black horizontal line within the box is the median.
Of course, a single test does not prove a universal rule, especially when it comes to performance, but the results are nonetheless very promising: early LTE networks are showing great network throughput performance, and even more impressively, much more stable RTT and packet jitter latencies when compared with other wireless standards.
In other words, at least with respect to this test, LTE offers comparable and better performance than WiFi, which also shows that improved performance is possible, and all the extra complexity is paying off! The mobile web doesn’t have to be slow. In fact, we have all the reasons to believe that we can and will make it faster.
First off, minimizing latency through keepalive connections, geo-positioning your servers and data closer to the client, optimizing your TLS deployments, and all the other protocol optimizations we have covered are only more important on mobile applications, where both latency and throughput are always at a premium. Similarly, all the web application performance best practices are equally applicable. Feel free to flip ahead to Chapter 10; we’ll wait.
However, mobile networks also pose some new and unique requirements for our performance strategy. Designing applications for the mobile web requires careful planning and consideration of the presentation of the content within the constraints of the form factor of the device, the unique performance properties of the radio interface, and the impact on the battery life. The three are inextricably linked.
Perhaps because it is the easiest to control, the presentation layer, with topics such as responsive design, tends to receive the most attention. However, where most applications fall short, it is often due to the incorrect design assumptions about networking performance: the application protocols are the same, but the differences in the physical delivery layers impose a number of constraints that, if unaccounted for, will lead to slow response times, high latency variability, and ultimately a compromised experience for the user. To add insult to injury, poor networking decisions will also have an outsized negative impact on the battery life of the device.
There is no universal solution for these three constraints. There are best practices for the presentation layer, the networking, and the battery life performance, but frequently they are at odds; it is up to you and your application to find the balance in your requirements. One thing is for sure: simply disregarding any one of them won’t get you far.
With that in mind, we won’t elaborate too much on the presentation layer, as that varies with every platform and type of application—plus, there are plenty of existing books dedicated to this subject. But, regardless of the make or the operating system, the radio and battery constraints imposed by mobile networks are universal, and that is what we will focus on in this chapter.
Throughout this chapter and especially in the following pages, the term “mobile application” is used in its broadest definition: all of our discussions on the performance of mobile networks are equally applicable to native applications, regardless of the platform, and applications running in your browser, regardless of the browser vendor.
When it comes to mobile, conserving power is a critical concern for everyone involved: device manufacturers, carriers, application developers, and the end users of our applications. When in doubt, or wondering why or how certain mobile behaviors were put in place, ask a simple question: how does it impact or improve the battery life? In fact, this is a great question to ask for any and every feature in your application also.
Networking performance on mobile networks is inherently linked to battery performance. In fact, the physical layers of the radio interface are specifically built to optimize the battery life against the following constraints:
With that in mind, mobile applications should aim to minimize their use of the radio interface. To be clear, that is not to say that you should avoid using the radio entirely; after all we are building connected applications that rely on access to the network! However, because keeping the radio active is so expensive in terms of battery life, our applications should maximize the amount of transferred data while the radio is on and then seek to minimize the number of additional data transfers.
Even though WiFi uses a radio interface to transfer data, it is important to realize that the underlying mechanics of WiFi, and consequently the latency, throughput, and power profiles of WiFi, when compared with 2G, 3G, and 4G mobile networks are fundamentally different; see our earlier discussion on 3G, 4G, and WiFi Power Requirements. Consequently, the networking behavior can and often should be different when on WiFi vs. mobile networks.
Despite the high emphasis on optimizing energy use, most platforms currently lack the necessary tools to help developers measure and optimize their applications. Thankfully, there are third-party tools that can help, such as the free Application Resource Optimizer (ARO) toolkit developed by AT&T.
ARO consists of two components: a collector and an analyzer. The collector is an Android application that runs in the background (on a real phone, or within an emulator) and captures the transferred data packets, radio activity, and other interactions with the phone. To capture a trace, load the collector, hit Record, interact with your application, and then copy the trace to your system.
Once a trace is available, you can open it with the analyzer to get insights into radio states, energy consumption, and traffic patterns of your application. One of the great features about the analyzer is that it will also provide recommendations for common performance pitfalls, such as missing compression, redundant data transfers, and more.
Two important things to note: the battery consumption and radio states are generated via a specified model of the device and the type of radio network. In other words, the generated numbers are not exact measurements from the device in use but estimates based on specified parameters in the model. On the upside, this allows you to import different device and network models and compare their energy use—e.g., 3G vs. 4G.
Finally, the collector is Android only, but the ARO analyzer can also accept any regular packet trace (pcap) file produced by tcpdump or a compatible tool; iOS users will have to use the tcpdump method.
To get started with ARO, head to http://hpbn.co/attaro.
The fact that the mobile radio incurs a fixed power cost to cycle into the full power state, regardless of the amount of data to be transferred, tells us that there is no such thing as a “small request” as far as the battery is concerned. Intermittent network access is a performance anti-pattern on mobile networks; see Inefficiency of Periodic Transfers. In fact, extending this same logic yields the following rules:
In general, push delivery is more efficient than polling. However, a high-frequency push stream can be just as, if not more, expensive. Whenever there is a need for real-time updates, you should consider the following questions:
For push delivery, native applications have access to platform-specific push delivery services, which should be used when possible. For web applications, server-sent events (SSEs) and WebSocket delivery can be used to minimize latency and protocol overhead. Avoid polling and costly XHR techniques when possible.
A simple aggregation strategy of bundling multiple notifications into a single push event, based on an adaptive interval, user preference, or even the battery level on the device, can make a significant improvement to the power profile of any application, especially background applications, which often rely on this type of network access pattern.
Intermittent beacon requests such as audience measurement pings and real-time analytics can easily negate all of your careful battery optimizations. These pings are mostly harmless on wired and even WiFi networks but carry an outsized cost on mobile networks. Do these beacons need to happen instantaneously? There is a good chance that you can easily log and defer these requests until next time the radio is active. Piggyback your background pings, and pay close attention to the network access patterns of third-party libraries and snippets in your code.
Finally, while we have so far focused on the battery, intermittent network access required for techniques such as progressive enhancement and incremental loading also carries a large latency cost due to the RRC state transitions! Recall that every state transition incurs a high control-plane latency cost in mobile networks, which may inject hundreds or thousands of extra milliseconds of latency—an especially expensive proposition for user-initiated and interactive traffic.
To illustrate the impact of periodic polling on battery life, let’s do some simple math. The numbers are not exact but are within range of a typical 3G/4G mobile handset:
)
)
)
~3% of available battery capacity per hour for a single application! All it would take is a couple of applications with non-overlapping polling intervals to drain your battery by midday. Although, to be fair, a push application with frequent, unbuffered updates can have an even higher energy consumption profile.
Battery life optimization and frequency of updates are inherently at odds. Consider the requirements of your specific application to determine the optimal strategy: bundling of updates, adaptive update intervals, pull vs. push, and so on. Then, measure the impact with ARO or a similar tool and adjust accordingly.
The connection state and the lifecycle of any TCP or UDP connection is independent of the radio state on the device: the radio can be in a low-power state while the connections are maintained by the carrier network. Then, when a new packet arrives from the external network, the carrier radio network will notify the device, promote its radio to a connected state, and resume the data transfer.
The application does not need to keep the radio “active” to ensure that connections are not dropped. Unnecessary application keepalives can have an enormous negative impact on battery life performance and are often put in place due to simple misunderstanding of how the mobile radio works. Refer to Physical Layer vs. Application Layer Connectivity and Packet Flow in a Mobile Network.
Most mobile carriers set a 5–30 minute NAT connection timeout. Hence, you may need a periodic (5 minute) keepalive to keep an idle connection from being dropped. If you find yourself requiring more frequent keepalives, check your own server, proxy, and load balancer configuration first!
A single HTTP request for a required resource may incur anywhere from hundreds to thousands of milliseconds of network latency overhead in a mobile network. In part, this is due to the high roundtrip latencies, but we also can’t forget the overhead (Figure 8-2) of DNS, TCP, TLS, and control-plane costs!
In the best case, the radio is already in a high-power state, the DNS is pre-resolved, and an existing TCP connection is available: the client may be able to reuse an existing connection and avoid the overhead of establishing a new connection. However, if the connection is busy, or nonexistent, then we must incur a number of additional roundtrips before any application data can be sent.
To illustrate the impact of these extra network roundtrips, let’s assume an optimistic 100 ms roundtrip time for 4G and a 200 ms roundtrip time for 3.5G+ networks:
| 3G | 4G | |
Control plane | 200–2,500 ms | 50–100 ms |
DNS lookup | 200 ms | 100 ms |
TCP handshake | 200 ms | 100 ms |
TLS handshake | 200–400 ms | 100–200 ms |
HTTP request | 200 ms | 100 ms |
Total latency overhead | 200–3500 ms | 100–600 ms |
The RRC control-plane latency alone can add anywhere from hundreds to thousands of milliseconds of overhead to reestablish the radio context on a 3G network! Once the radio is active, we may need to resolve the hostname to an IP address and then perform the TCP handshake—two network roundtrips. Then, if a secure tunnel is required, we may need up to two extra network roundtrips (see TLS Session Resumption). Finally, the HTTP request can be sent, which adds a minimum of another roundtrip.
We have not accounted for the server response time or the size of the response, which may require several roundtrips, and yet we have already incurred up to half a dozen roundtrips. Multiply that by the roundtrip time, and we are looking at entire seconds of latency overhead for 3G, and roughly half a second for 4G networks.
If the mobile device has been idle for more than a few seconds, you should assume and anticipate that the first packet will incur hundreds, or even thousands of milliseconds of extra RRC latency. As a rule of thumb, add 100 ms for 4G, 150–500 ms for 3.5G+, and 500–2,500 ms for 3G networks, as a one-time, control-plane latency cost.
The RRC is specifically designed to help mitigate some of the cost of operating the power-hungry radio. However, what we gain in battery life is offset by increases in latency and lower throughput due to the presence of the various timers, counters, and the consequent overhead of required network negotiation to transition between the different radio states. However, the RRC is also a fact of life on mobile networks–there is no way around it–and if you want to build optimized applications for the mobile web, you must design with the RRC in mind.
A quick summary of what we have learned about the RRC:
We have already covered why preserving battery is such an important goal for mobile applications, and we have also highlighted the inefficiency of intermittent transfers, which are a direct result of the timeout-driven RRC state transitions. However, there is one more thing you need to take away: if the device radio has been idle, then initiating a new data transfer on mobile networks will incur an additional latency delay, which may take anywhere from 100 milliseconds on latest-generation networks to up to several seconds on older 3G and 2G networks.
While the network presents the illusion of an always-on experience to our applications, the physical or the radio layer controlled by the RRC is continuously connecting and disconnecting. On the surface, this is not an issue, but the delays imposed by the RRC are, in fact, often easily noticeable by many users when unaccounted for.
A well-designed application can feel fast by providing instant feedback even if the underlying connection is slow or the request is taking a long time to complete. Do not couple user interactions, user feedback, and network communication. To deliver the best experience, the application should acknowledge user input within hundreds of milliseconds; see Speed, Performance, and Human Perception.
If a network request is required, then initiate it in the background, and provide immediate UI feedback to acknowledge user input. The control plane latency alone will often push your application over the allotted budget for providing instant user feedback. Plan for high latencies—you cannot “fix” the latency imposed by the core network and the RRC—and work with your design team to ensure that they are aware of these limitations when designing the application.
Users dislike slow applications, but broken applications, due to transient network errors, are the worst experience of all. Your mobile application must be robust in the face of common networking failures: unreachable hosts, sudden drops in throughput or increases in latency, or outright loss of connectivity. Unlike the tethered world, you simply cannot assume that once the connection is established, it will remain established. The user may be on the move and may enter an area with high amounts of interference, many active users, or plain poor coverage.
Further, just as you cannot design your pages just for the latest browsers, you cannot design your application just for the latest-generation mobile networks. As we have covered earlier (Building for the Multigeneration Future), even users with the latest handsets will continuously transition between 4G, 3G, and even 2G networks based on the continuously changing conditions of their radio environments. Your application should subscribe to these interface transitions and adjust accordingly.
The application can subscribe to navigator.onLine notifications to monitor connection status. For a good introduction, also see Paul Kinlan’s article on HTML5Rocks: Working Off the Grid with HTML5 Offline.
Change is the only constant in mobile networks. Radio channel quality is always changing based on distance from the tower, congestion from nearby users, ambient interference, and dozens of other factors. With that in mind, while it may be tempting to perform various forms of bandwidth and latency estimation to optimize your mobile application, the results should be treated, at best, as transient data points.
The iPhone 4 “antennagate” serves as a great illustration of the unpredictable nature of radio performance: reception quality was affected by the physical location of your hand in regards to the phone’s antenna, which gave birth to the infamous “You’re holding it wrong.”
Latency and bandwidth estimates on mobile networks are stable on the order of tens to hundreds of milliseconds, at most a second, but not more. Hence, while optimizations such as adaptive bitrate streaming are still useful for long-lived streams, such as video, which is adapted in data chunks spanning a few seconds, these bandwidth estimates should definitely not be cached or used later to make decisions about the available throughput: even on 4G, you may measure your throughput as just a few hundred Kbit/s, and then move your radio a few inches and get Mbit/s+ performance!
End-to-end bandwidth and latency estimation is a hard problem on any network, but doubly so on mobile networks. Avoid it, because you will get it wrong. Instead, use coarse-grained information about the generation of the network, and adjust your code accordingly. To be clear, knowing the generation or type of mobile network does not make any end-to-end performance guarantees, but it does tell you important data about the latency of the first wireless hop and the end-to-end performance of the carrier network; see Latency and Jitter in Mobile Networks and Table 7-6.
Finally, throughput and latency aside, you should plan for loss of connectivity: assume this case is not an exception but the rule. Your application should remain operational, to the extent possible, when the network is unavailable or a transient failure happens and should adapt based on request type and specific error:
Mobile radio interface is optimized for bursty transfers, which is a property you should leverage whenever possible: group your requests together and download as much as possible, as quickly as possible, and then let the radio return to an idle state. This strategy will deliver the best network throughput and maximize battery life of the device.
The only accurate way to estimate the network’s speed is, well, to use it! Latest-generation networks, such as LTE and HSPA+, perform dynamic allocation of resources in one-millisecond intervals and prioritize bursty data flows. To go fast, keep it simple: batch and pre-fetch as much data as you can, and let the network do the rest.
An important corollary is that progressive loading of resources may do more harm than good on mobile networks. By downloading content in small chunks, we expose our applications to higher variability both in throughput and latency, not to mention the much higher energy costs to operate the radio. Instead, anticipate what your users will need next, download the content ahead of time, and let the radio idle:
Current industry estimates show that almost 90% of the worldwide wireless traffic is expected to originate indoors, and frequently in areas with WiFi connectivity within reach. Hence, while the latest 4G networks may compete with WiFi over peak throughput and latency, very frequently they still impose a monthly data cap: mobile access is metered and often expensive to the user. Further, WiFi connections are more battery efficient (see 3G, 4G, and WiFi Power Requirements) for large transfers and do not require an RRC.
Whenever possible, and especially if you are building a data-intensive application, you should leverage WiFi connectivity when available, and if not, then consider prompting the user to enable WiFi on her device to improve experience and minimize costs.
One of the great properties of the layered architecture of our network infrastructure is that it abstracts the physical delivery from the transport layer, and the transport layer abstracts the routing and data delivery from the application protocols. This separation provides great API abstractions, but for best end-to-end performance, we still need to consider the entire stack.
Throughout this chapter, we have focused on the unique properties of the physical layer of mobile networks, such as the presence of the RRC, concerns over the battery life of the device, and incurred routing latencies in mobile networks. However, on top of this physical layer reside the transport and session protocols we have covered in earlier chapters, and all of their optimizations are just as critical, perhaps doubly so:
Minimizing latency by reusing keepalive connections, geo-positioning servers and data closer to the client, optimizing TLS deployments, and all the other optimizations we outlined earlier are even more important on mobile networks, where roundtrip latencies are high and bandwidth is always at a premium.
Of course, our optimization strategy does not stop with transport and session protocols; they are simply the foundation. From there, we must also consider the performance implications of different application protocols (HTTP/1.0, 1.1, and 2), as well as general web application best practices—keep reading, we are not done yet!
The Hypertext Transfer Protocol (HTTP) is one of the most ubiquitous and widely adopted application protocols on the Internet: it is the common language between clients and servers, enabling the modern web. From its simple beginnings as a single keyword and document path, it has become the protocol of choice not just for browsers, but for virtually every Internet-connected software and hardware application.
In this chapter, we will take a brief historical tour of the evolution of the HTTP protocol. A full discussion of the varying HTTP semantics is outside the scope of this book, but an understanding of the key design changes of HTTP, and the motivations behind each, will give us the necessary background for our discussions on HTTP performance, especially in the context of the many upcoming improvements in HTTP/2.
The original HTTP proposal by Tim Berners-Lee was designed with simplicity in mind as to help with the adoption of his other nascent idea: the World Wide Web. The strategy appears to have worked: aspiring protocol designers, take note.
In 1991, Berners-Lee outlined the motivation for the new protocol and listed several high-level design goals: file transfer functionality, ability to request an index search of a hypertext archive, format negotiation, and an ability to refer the client to another server. To prove the theory in action, a simple prototype was built, which implemented a small subset of the proposed functionality:
However, even that sounds a lot more complicated than it really is. What these rules enable is an extremely simple, Telnet-friendly protocol, which some web servers support to this very day:
$> telnet google.com 80
Connected to 74.125.xxx.xxx
GET /about/
(hypertext response)
(connection closed)
The request consists of a single line: GET method and the path of the requested document. The response is a single hypertext document—no headers or any other metadata, just the HTML. It really couldn’t get any simpler. Further, since the previous interaction is a subset of the intended protocol, it unofficially acquired the HTTP 0.9 label. The rest, as they say, is history.
From these humble beginnings in 1991, HTTP took on a life of its own and evolved rapidly over the coming years. Let us quickly recap the features of HTTP 0.9:
Popular web servers, such as Apache and Nginx, still support the HTTP 0.9 protocol—in part, because there is not much to it! If you are curious, open up a Telnet session and try accessing google.com, or your own favorite site, via HTTP 0.9 and inspect the behavior and the limitations of this early protocol.
The period from 1991 to 1995 is one of rapid coevolution of the HTML specification, a new breed of software known as a “web browser,” and the emergence and quick growth of the consumer-oriented public Internet infrastructure.
The growing list of desired capabilities of the nascent Web and their use cases on the public Web quickly exposed many of the fundamental limitations of HTTP 0.9: we needed a protocol that could serve more than just hypertext documents, provide richer metadata about the request and the response, enable content negotiation, and more. In turn, the nascent community of web developers responded by producing a large number of experimental HTTP server and client implementations through an ad hoc process: implement, deploy, and see if other people adopt it.
From this period of rapid experimentation, a set of best practices and common patterns began to emerge, and in May 1996 the HTTP Working Group (HTTP-WG) published RFC 1945, which documented the “common usage” of the many HTTP/1.0 implementations found in the wild. Note that this was only an informational RFC: HTTP/1.0 as we know it is not a formal specification or an Internet standard!
Having said that, an example HTTP/1.0 request should look very familiar:
$> telnet website.org 80Connected to xxx.xxx.xxx.xxx GET /rfc/rfc1945.txt HTTP/1.0
The preceding exchange is not an exhaustive list of HTTP/1.0 capabilities, but it does illustrate some of the key protocol changes:
Both the request and response headers were kept as ASCII encoded, but the response object itself could be of any type: an HTML file, a plain text file, an image, or any other content type. Hence, the “hypertext transfer” part of HTTP became a misnomer not long after its introduction. In reality, HTTP has quickly evolved to become a hypermedia transport, but the original name stuck.
In addition to media type negotiation, the RFC also documented a number of other commonly implemented capabilities: content encoding, character set support, multi-part types, authorization, caching, proxy behaviors, date formats, and more.
Almost every server on the Web today can and will still speak HTTP/1.0. Except that, by now, you should know better! Requiring a new TCP connection per request imposes a significant performance penalty on HTTP/1.0; see Three-Way Handshake, followed by Slow-Start.
The work on turning HTTP into an official IETF Internet standard proceeded in parallel with the documentation effort around HTTP/1.0 and happened over a period of roughly four years: between 1995 and 1999. In fact, the first official HTTP/1.1 standard is defined in RFC 2068, which was officially released in January 1997, roughly six months after the publication of HTTP/1.0. Then, two and a half years later, in June of 1999, a number of improvements and updates were incorporated into the standard and were released as RFC 2616.
The HTTP/1.1 standard resolved a lot of the protocol ambiguities found in earlier versions and introduced a number of critical performance optimizations: keepalive connections, chunked encoding transfers, byte-range requests, additional caching mechanisms, transfer encodings, and request pipelining.
With these capabilities in place, we can now inspect a typical HTTP/1.1 session as performed by any modern HTTP browser and client:
$> telnet website.org 80Connected to xxx.xxx.xxx.xxx GET /index.html HTTP/1.1
Request for HTML file, with encoding, charset, and cookie metadata
Chunked response for original HTML request
Number of octets in the chunk expressed as an ASCII hexadecimal number (256 bytes)
End of chunked stream response
Request for an icon file made on same TCP connection
Inform server that the connection will not be reused
Icon response, followed by connection close
Phew, there is a lot going on in there! The first and most obvious difference is that we have two object requests, one for an HTML page and one for an image, both delivered over a single connection. This is connection keepalive in action, which allows us to reuse the existing TCP connection for multiple requests to the same host and deliver a much faster end-user experience; see Optimizing for TCP.
To terminate the persistent connection, notice that the second client request sends an explicit close token to the server via the Connection header. Similarly, the server can notify the client of the intent to close the current TCP connection once the response is transferred. Technically, either side can terminate the TCP connection without such signal at any point, but clients and servers should provide it whenever possible to enable better connection reuse strategies on both sides.
HTTP/1.1 changed the semantics of the HTTP protocol to use connection keepalive by default. Meaning, unless told otherwise (via Connection: close header), the server should keep the connection open by default.
However, this same functionality was also backported to HTTP/1.0 and enabled via the Connection: Keep-Alive header. Hence, if you are using HTTP/1.1, technically you don’t need the Connection: Keep-Alive header, but many clients choose to provide it nonetheless.
Additionally, the HTTP/1.1 protocol added content, encoding, character set, and even language negotiation, transfer encoding, caching directives, client cookies, plus a dozen other capabilities that can be negotiated on each request.
We are not going to dwell on the semantics of every HTTP/1.1 feature. This is a subject for a dedicated book, and many great ones have been written already. Instead, the previous example serves as a good illustration of both the quick progress and evolution of HTTP, as well as the intricate and complicated dance of every client-server exchange. There is a lot going on in there!
Since its publication, RFC 2616 has served as a foundation for the unprecedented growth of the Internet: billions of devices of all shapes and sizes, from desktop computers to the tiny web devices in our pockets, speak HTTP every day to deliver news, video, and millions of other web applications we have all come to depend on in our lives.
What began as a simple, one-line protocol for retrieving hypertext quickly evolved into a generic hypermedia transport, and now a decade later can be used to power just about any use case you can imagine. Both the ubiquity of servers that can speak the protocol and the wide availability of clients to consume it means that many applications are now designed and deployed exclusively on top of HTTP.
Need a protocol to control your coffee pot? RFC 2324 has you covered with the Hyper Text Coffee Pot Control Protocol (HTCPCP/1.0)—originally an April Fools’ Day joke by IETF, and increasingly anything but a joke in our new hyper-connected world.
The Hypertext Transfer Protocol (HTTP) is an application-level protocol for distributed, collaborative, hypermedia information systems. It is a generic, stateless, protocol that can be used for many tasks beyond its use for hypertext, such as name servers and distributed object management systems, through extension of its request methods, error codes and headers. A feature of HTTP is the typing and negotiation of data representation, allowing systems to be built independently of the data being transferred.
— RFC 2616: HTTP/1.1 June 1999
The simplicity of the HTTP protocol is what enabled its original adoption and rapid growth. In fact, it is now not unusual to find embedded devices—sensors, actuators, and coffee pots alike—using HTTP as their primary control and data protocols. But under the weight of its own success and as we increasingly continue to migrate our everyday interactions to the Web—social, email, news, and video, and increasingly our entire personal and job workspaces—it has also begun to show signs of stress. Users and web developers alike are now demanding near real-time responsiveness and protocol performance from HTTP/1.1, which it simply cannot meet without some modifications.
To meet these new challenges, HTTP must continue to evolve, and hence the HTTPbis working group announced a new initiative for HTTP/2 in early 2012:
There is emerging implementation experience and interest in a protocol that retains the semantics of HTTP without the legacy of HTTP/1.x message framing and syntax, which have been identified as hampering performance and encouraging misuse of the underlying transport.
The working group will produce a specification of a new expression of HTTP’s current semantics in ordered, bi-directional streams. As with HTTP/1.x, the primary target transport is TCP, but it should be possible to use other transports.
— HTTP/2 charter January 2012
The primary focus of HTTP/2 is on improving transport performance and enabling both lower latency and higher throughput. The major version increment sounds like a big step, which it is and will be as far as performance is concerned, but it is important to note that none of the high-level protocol semantics are affected: all HTTP headers, values, and use cases are the same.
Any existing website or application can and will be delivered over HTTP/2 without modification: you do not need to modify your application markup to take advantage of HTTP/2. The HTTP servers will have to speak HTTP/2, but that should be a transparent upgrade for the majority of users. The only difference if the working group meets its goal, should be that our applications are delivered with lower latency and better utilization of the network link!
Having said that, let’s not get ahead of ourselves. Before we get to the new HTTP/2 protocol features, it is worth taking a step back and examining our existing deployment and performance best practices for HTTP/1.1. The HTTP/2 working group is making fast progress on the new specification, but even if the final standard was already done and ready, we would still have to support older HTTP/1.1 clients for the foreseeable future—realistically, a decade or more.
In any complex system, a large part of the performance optimization process is the untangling of the interactions between the many distinct and separate layers of the system, each with its own set of constraints and limitations. So far, we have examined a number of individual networking components in close detail—different physical delivery methods and transport protocols—and now we can turn our attention to the larger, end-to-end picture of web performance optimization:
Optimizing the interaction among all the different layers is not unlike solving a family of equations, each dependent on the others, but nonetheless yielding many possible solutions. There is no one fixed set of recommendations or best practices, and the individual components continue to evolve: browsers are getting faster, user connectivity profiles change, and web applications continue to grow in their scope, ambition, and complexity.
Hence, before we dive into enumerating and analyzing individual performance best practices, it is important to step back and define what the problem really is: what a modern web application is, what tools we have at our disposal, how we measure web-performance, and which parts of the system are helping and hindering our progress.
The evolution of the Web over the course of the last few decades has given us at least three different classes of experience: the hypertext document, rich media web page, and interactive web application. Admittedly, the line between the latter two may at times be blurry to the user, but from a performance point of view, each requires a very different approach to our conversation, metrics, and the definition of performance.
An HTTP 0.9 session consisted of a single document request, which was perfectly sufficient for delivery of hypertext: single document, one TCP connection, followed by connection close. Consequently, tuning for performance was as simple as optimizing for a single HTTP request over a short-lived TCP connection.
The advent of the web page changed the formula from delivery of a single document to the document plus its dependent resources. Consequently, HTTP/1.0 introduced the notion of HTTP metadata (headers), and HTTP/1.1 enhanced it with a variety of performance-oriented primitives, such as well-defined caching, keepalive, and more. Hence, multiple TCP connections are now potentially at play, and the key performance metric has shifted from document load time to page load time, which is commonly abbreviated as PLT.
The simplest definition of PLT is “the time until the loading spinner stops spinning in the browser.” A more technical definition is time to onload event in the browser, which is an event fired by the browser once the document and all of its dependent resources (JavaScript, images, etc.) have finished loading.
Finally, the web application transformed the simple web page, which used media as an enhancement to the primary content in the markup, into a complex dependency graph: markup defines the basic structure, stylesheets define the layout, and scripts build up the resulting interactive application and respond to user input, potentially modifying both styles and markup in the process.
Consequently, page load time, which has been the de facto metric of the web performance world, is also an increasingly insufficient performance benchmark: we are no longer building pages, we are building dynamic and interactive web applications. Instead of, or in addition to, measuring the time to load each and every resource (PLT), we are now interested in answering application-specific questions:
The success of your performance and optimization strategy is directly correlated to your ability to define and iterate on application-specific benchmarks and criteria. Nothing beats application-specific knowledge and measurements, especially when linked to bottom-line goals and metrics of your business.
What exactly do we mean by “complex dependency graph of scripts, stylesheets, and markup” found in a modern web application? To answer this question, we need to take a quick detour into browser architecture and investigate how the parsing, layout, and scripting pipelines have to come together to paint the pixels to the screen.
The parsing of the HTML document is what constructs the Document Object Model (DOM). In parallel, there is an oft-forgotten cousin, the CSS Object Model (CSSOM), which is constructed from the specified stylesheet rules and resources. The two are then combined to create the “render tree,” at which point the browser has enough information to perform a layout and paint something to the screen. So far, so good.
However, this is where we must, unfortunately, introduce our favorite friend and foe: JavaScript. Script execution can issue a synchronous doc.write and block DOM parsing and construction. Similarly, scripts can query for a computed style of any object, which means that JavaScript can also block on CSS. Consequently, the construction of DOM and CSSOM objects is frequently intertwined: DOM construction cannot proceed until JavaScript is executed, and JavaScript execution cannot proceed until CSSOM is available.
The performance of your application, especially the first load and the “time to render” depends directly on how this dependency graph between markup, stylesheets, and JavaScript is resolved. Incidentally, recall the popular “styles at the top, scripts at the bottom” best practice? Now you know why! Rendering and script execution are blocked on stylesheets; get the CSS down to the user as quickly as you can.
What does a modern web application look like after all? HTTP Archive can help us answer this question. The project tracks how the Web is built by periodically crawling the most popular sites (300,000+ from Alexa Top 1M) and recording and aggregating analytics on the number of used resources, content types, headers, and other metadata for each individual destination.
An average web application, as of early 2013, is composed of the following:
90 requests, fetched from 15 hosts, with 1,311 KB total transfer size
By the time you read this, the preceding numbers have already changed and have grown even larger (Figure 10-2); the upward climb has been a stable and reliable trend with no signs of stopping. However, exact request and kilobyte count aside, it is the order of magnitude of these individual components that warrants some careful contemplation: an average web application is now well over 1 MB in size and is composed of roughly 100 sub-resources delivered from over 15 different hosts!
Unlike their desktop counterparts, web applications do not require a separate installation process: type in the URL, hit Enter, and we are up and running! However, desktop applications pay the installation cost just once, whereas web applications are running the “installation process” on each and every visit—resource downloads, DOM and CSSOM construction, and JavaScript execution. No wonder web performance is such a fast-growing field and a hot topic of discussion! Hundreds of resources, megabytes of data, dozens of different hosts, all of which must come together in hundreds of milliseconds to facilitate the desired instant web experience.
Speed and performance are relative terms. Each application dictates its own set of requirements based on business criteria, context, user expectations, and the complexity of the task that must be performed. Having said that, if the application must react and respond to a user, then we must plan and design for specific, user-centric perceptual processing time constants. Despite the ever-accelerating pace of life, or at least the feeling of it, our reaction times remain constant (Table 10-1), regardless of type of application (online or offline), or medium (laptop, desktop, or mobile device).
| Delay | User perception |
0–100 ms | Instant |
100–300 ms | Small perceptible delay |
300–1000 ms | Machine is working |
1,000+ ms | Likely mental context switch |
10,000+ ms | Task is abandoned |
The preceding table helps explain the unofficial rule of thumb in the web performance community: render pages, or at the very least provide visual feedback, in under 250 milliseconds to keep the user engaged!
For an application to feel instant, a perceptible response to user input must be provided within hundreds of milliseconds. After a second or more, the user’s flow and engagement with the initiated task is broken, and after 10 seconds have passed, unless progress feedback is provided, the task is frequently abandoned.
Now, add up the network latency of a DNS lookup, followed by a TCP handshake, and another few roundtrips for a typical web page request, and much, if not all, of our 100–1,000 millisecond latency budget can be easily spent on just the networking overhead; see Figure 8-2. No wonder so many users, especially when on a mobile or a wireless network, are demanding faster web browsing performance!
Jakob Nielsen’s Usability Engineering and Steven Seow’s Designing and Engineering Time are both excellent resources that every developer and designer should read! Time is measured objectively but perceived subjectively, and experiences can be engineered to improve perceived performance.
No discussion on web performance is complete without a mention of the resource waterfall. In fact, the resource waterfall is likely the single most insightful network performance and diagnostics tool at our disposal. Every browser provides some instrumentation to see the resource waterfall, and there are great online tools, such as WebPageTest, which can render it online for a wide variety of different browsers.
WebPageTest.org is an open-source project and a free web service that provides a system for testing the performance of web pages from multiple locations around the world: the browser runs within a virtual machine and can be configured and scripted with a variety of connection and browser-oriented settings. Following the test, the results are then available through a web interface, which makes WebPageTest an indispensable power tool in your web performance toolkit.
To start, it is important to recognize that every HTTP request is composed of a number of separate stages (Figure 10-3): DNS resolution, TCP connection handshake, TLS negotiation (if required), dispatch of the HTTP request, followed by content download. The visual display of these individual stages may differ slightly within each browser, but to keep things simple, we will use the WebPageTest version in this chapter. Make sure to familiarize yourself with the meaning of each color in your favorite browser.
Close analysis of Figure 10-3 shows that the Yahoo! homepage took 683 ms to download, and over 200 ms of that time was spent waiting on the network, which amounts to 30% of total latency of the request! However, the document request is only the beginning since, as we know, a modern web application also needs a wide variety of resources (Figure 10-4) to produce the final output. To be exact, to load the Yahoo! homepage, the browser will require 52 resources, fetched from 30 different hosts, all adding up to 486 KB in total.
The resource waterfall reveals a number of important insights about the structure of the page and the browser processing pipeline. First off, notice that while the content of the www.yahoo.com document is being fetched, new HTTP requests are being dispatched: HTML parsing is performed incrementally, allowing the browser to discover required resources early and dispatch the necessary requests in parallel. Hence, the scheduling of when the resource is fetched is in large part determined by the structure of the markup. The browser may reprioritize some requests, but the incremental discovery of each resource in the document is what creates the distinct resource “waterfall effect.”
Second, notice that the “Start Render” (green vertical line) occurs well before all the resources are fully loaded, allowing the user to begin interacting with the page while the page is being built. In fact, the “Document Complete” event (blue vertical line), also fires early and well before the remaining assets are loaded. In other words, the browser spinner has stopped spinning, the user is able to continue with his task, but the Yahoo! homepage is progressively filling in additional content, such as advertising and social widgets, in the background.
The difference between the first render time, document complete, and the time to finish fetching the last resource in the preceding example is a great illustration of the necessary context when discussing different web performance metrics. Which of those three metrics is the right one to track? There is no one single answer; each application is different! Yahoo! engineers have chosen to optimize the page to take advantage of incremental loading to allow the user to begin consuming the important content earlier, and in doing so they had to apply application-specific knowledge about which content is critical and which can be filled in later.
Different browsers implement different logic for when, and in which order, the individual resource requests are dispatched. As a result, the performance of the application will vary from browser to browser.
Tip: WebPageTest allows you to select both the location and the make and version of the browser when running the test!
The network waterfall is a power tool that can help reveal the chosen optimizations, or lack thereof, for any page or application. The previous process of analyzing and optimizing the resource waterfall is often referred to as front-end performance analysis and optimization. However, the name may be an unfortunate choice, as it misleads many to believe that all performance bottlenecks are now on the client. In reality, while JavaScript, CSS, and rendering pipelines are critical and resource-intensive steps, the server response times and network latency (“back-end performance”) are no less critical for optimizing the resource waterfall. After all, you can’t parse or execute a resource that is blocked on the network!
To illustrate this in action, we only have to switch from the resource waterfall to the connection view (Figure 10-5) provided by WebPageTest.
Unlike the resource waterfall, where each record represents an individual HTTP request, the connection view shows the life of each TCP connection—all 30 of them in this case—used to fetch the resources for the Yahoo! homepage. Does anything stand out? Notice that the download time, indicated in blue, is but a small fraction of the total latency of each connection: there are 15 DNS lookups, 30 TCP handshakes, and a lot of network latency (indicated in green) while waiting to receive the first byte of each response.
Wondering why some requests are showing the green bar (time to first byte) only? Many responses are very small, and consequently the download time does not register on the diagram. In fact, for many requests, response times are often dominated by the roundtrip latency and server processing times.
Finally, we have saved the best for last. The real surprise to many is found at the bottom of the connection view: examine the bandwidth utilization chart in Figure 10-5. With the exception of a few short data bursts, the utilization of the available connection is very low—it appears that we are not limited by bandwidth of our connection! Is this an anomaly, or worse, a browser bug? Unfortunately, it is neither. Turns out, bandwidth is not the limiting performance factor for most web applications. Instead, the bottleneck is the network roundtrip latency between the client and the server.
The execution of a web program primarily involves three tasks: fetching resources, page layout and rendering, and JavaScript execution. The rendering and scripting steps follow a single-threaded, interleaved model of execution; it is not possible to perform concurrent modifications of the resulting Document Object Model (DOM). Hence, optimizing how the rendering and script execution runtimes work together, as we saw in DOM, CSSOM, and JavaScript, is of critical importance.
However, optimizing JavaScript execution and rendering pipelines also won’t do much good if the browser is blocked on the network, waiting for the resources to arrive. Fast and efficient delivery of network resources is the performance keystone of each and every application running in the browser.
But, one might ask, Internet speeds are getting faster by the day, so won’t this problem solve itself? Yes, our applications are growing larger, but if the global average speed is already at 3.1 Mbps (Bandwidth at the Network Edge) and growing, as evidenced by ubiquitous advertising by every ISP and mobile carrier, why bother, right? Unfortunately, as you might intuit, and as the Yahoo! example shows, if that were the case then you wouldn’t be reading this book. Let’s take a closer look.
For a detailed discussion of the trends and interplay of bandwidth and latency, refer back to the “Primer on Latency and Bandwidth” in Chapter 1.
Hold your horses; of course bandwidth matters! After all, every commercial by our local ISP and mobile carrier continues to remind us of its many benefits: faster downloads, uploads, and streaming, all at up to speeds of [insert latest number here] Mbps!
Access to higher bandwidth data rates is always good, especially for cases that involve bulk data transfers: video and audio streaming or any other type of large data transfer. However, when it comes to everyday web browsing, which requires fetching hundreds of relatively small resources from dozens of different hosts, roundtrip latency is the limiting factor:
Depending on the quality and the encoding of the video you are trying to stream, you may need anywhere from a few hundred Kbps to several Mbps in bandwidth capacity—e.g., 3+ Mbps for an HD 1080p video stream. This data rate is now within reach for many users, which is evidenced by the growing popularity of streaming video services such as Netflix. Why, then, would downloading a much, much smaller web application be such a challenge for a connection capable of streaming an HD movie?
We have already covered all the necessary topics in preceding chapters to make a good qualitative theory as to why latency may be the limiting factor for everyday web browsing. However, a picture is worth a thousand words, so let’s examine the results of a quantitative study performed by Mike Belshe (Figure 10-6), one of the creators of the SPDY protocol, on the impact of varying bandwidth vs. latency on the page load times of some of the most popular destinations on the Web.
This study by Mike Belshe served as a launching point for the development of the SPDY protocol at Google, which later became the foundation of the HTTP/2 protocol.
In the first test, the connection latency is held fixed, and the connection bandwidth is incrementally increased from 1 Mbps up to 10 Mbps. Notice that at first, upgrading the connection from 1 to 2 Mbps nearly halves the page loading time—exactly the result we want to see. However, following that, each incremental improvement in bandwidth yields diminishing returns. By the time the available bandwidth exceeds 5 Mbps, we are looking at single-digit percent improvements, and upgrading from 5 Mbps to 10 Mbps results in a mere 5% improvement in page loading times!
Akamai’s broadband speed report (Bandwidth at the Network Edge) shows that an average consumer in the United States is already accessing the Web with 5 Mbps+ of available bandwidth—a number that many other countries are quickly approaching or have surpassed already. Ergo, we are led to conclude that an average consumer in the United States would not benefit much from upgrading the available bandwidth of her connection if she is interested in improving her web browsing speeds. She may be able to stream or upload larger media files more quickly, but the pages containing those files will not load noticeably faster: bandwidth doesn’t matter, much.
However, the latency experiment tells an entirely different story: for every 20 millisecond improvement in latency, we have a linear improvement in page loading times! Perhaps it is latency we should be optimizing for when deciding on an ISP, and not just bandwidth?
To speed up the Internet at large, we should look for more ways to bring down RTT. What if we could reduce cross-atlantic RTTs from 150 ms to 100 ms? This would have a larger effect on the speed of the internet than increasing a user’s bandwidth from 3.9 Mbps to 10 Mbps or even 1 Gbps.
Another approach to reducing page load times would be to reduce the number of round trips required per page load. Today, web pages require a certain amount of back and forth between the client and server. The number of round trips is largely due to the handshakes to start communicating between client and server (e.g., DNS, TCP, HTTP), and also round trips induced by the communication protocols (e.g., TCP slow start). If we can improve protocols to transfer this data with fewer round trips, we should also be able to improve page load times. This is one of the goals of SPDY.
— Mike Belshe More Bandwidth Doesn’t Matter (Much)
The previous results are a surprise to many, but they really should not be, as they are a direct consequence of the performance characteristics of the underlying protocols: TCP handshakes, flow and congestion control, and head-of-line blocking due to packet loss. Most of the HTTP data flows consist of small, bursty data transfers, whereas TCP is optimized for long-lived connections and bulk data transfers. Network roundtrip time is the limiting factor in TCP throughput and performance in most cases; see Optimizing for TCP. Consequently, latency is also the performance bottleneck for HTTP and most web applications delivered over it.
If we can measure it, we can improve it. The question is, are we measuring the right criteria, and is the process sound? As we noted earlier, measuring the performance of a modern web application is a nontrivial challenge: there is no one single metric that holds true for every application, which means that we must carefully define custom metrics in each case. Then, once the criteria are established, we must gather the performance data, which should be done through a combination of synthetic and real-user performance measurement.
Broadly speaking, synthetic testing refers to any process with a controlled measurement environment: a local build process running through a performance suite, load testing against staging infrastructure, or a set of geo-distributed monitoring servers that periodically perform a set of scripted actions and log the outcomes. Each and every one of these tests may test a different piece of the infrastructure (e.g., application server throughput, database performance, DNS timing, and so on), and serves as a stable baseline to help detect regressions or narrow in on a specific component of the system.
When configured well, synthetic testing provides a controlled and reproducible performance testing environment, which makes it a great fit for identifying and fixing performance regressions before they reach the user. Tip: identify your key performance metrics and set a “budget” for each one as part of your synthetic testing. If the budget is exceeded, raise an alarm!
However, synthetic testing is not sufficient to identify all performance bottlenecks. Specifically, the problem is that the gathered measurements are not representative of the wide diversity of the real-world factors that will determine the final user experience with the application. Some contributing factors to this gap include the following:
The combination of these and similar factors means that in addition to synthetic testing, we must augment our performance strategy with real-user measurement (RUM) to capture actual performance of our application as experienced by the user. The good news is the W3C Web Performance Working Group has made this part of our data-gathering process a simple one by introducing the Navigation Timing API (Figure 10-7), which is now supported across many of the modern desktop and mobile browsers.
As of early 2013, Navigation Timing is supported by IE9+, Chrome 6+, and Firefox 7+ across desktop and mobile platforms. The notable omissions are the Safari and Opera browsers. For the latest status, see caniuse.com/nav-timing.
The real benefit of Navigation Timing is that it exposes a lot of previously inaccessible data, such as DNS and TCP connect times, with high precision (microsecond timestamps), via a standardized performance.timing object in each browser. Hence, the data gathering process is very simple: load the page, grab the timing object from the user’s browser, and beacon it back to your analytics servers! By capturing this data, we can observe real-world performance of our applications as seen by real users, on real hardware, and across a wide variety of different networks.
When analyzing performance data, always look at the underlying distribution of the data: throw away the averages and focus on the histograms, medians, and quantiles. Averages lead to meaningless metrics when analyzing skewed and multimodal distributions. Figure 10-8 shows a hands-on, real-world example of both types of distributions on a single site: skewed distribution for the page load time and a multimodal distribution for the server response time (the two modes are due to cached vs. uncached page generation time by the application server).
Ensure that your analytics tool can provide the right statistical metrics for your performance data. The preceding data was taken from Google Analytics, which provides a histogram view within the standard Site Speed reports. Google Analytics automatically gathers Navigation Timing data when the analytics tracker is installed. Similarly, there are a wide variety of other analytics vendors who offer Navigation Timing data gathering and reporting.
Finally, in addition to Navigation Timing, the W3C Performance Group also standardized two other APIs: User Timing and Resource Timing. Whereas Navigation Timing provides performance timers for root documents only, Resource Timing provides similar performance data for each resource on the page, allowing us to gather the full performance profile of the page. Similarly, User Timing provides a simple JavaScript API to mark and measure application-specific performance metrics with the help of the same high-resolution timers:
function init() {
performance.mark("startTask1");
applicationCode1();
performance.mark("endTask1");
logPerformance();
}
function logPerformance() {
var perfEntries = performance.getEntriesByType("mark");
for (var i = 0; i < perfEntries.length; i++) {
console.log("Name: " + perfEntries[i].name +
" Entry Type: " + perfEntries[i].entryType +
" Start Time: " + perfEntries[i].startTime +
" Duration: " + perfEntries[i].duration + "\n");
}
console.log(performance.timing);
}
The combination of Navigation, Resource, and User timing APIs provides all the necessary tools to instrument and conduct real-user performance measurement for every web application; there is no longer any excuse not to do it right. We optimize what we measure, and RUM and synthetic testing are complementary approaches to help you identify regressions and real-world bottlenecks in the performance and the user experience of your applications.
Custom and application-specific metrics are the key to establishing a sound performance strategy. There is no generic way to measure or define the quality of user experience. Instead, we must define and instrument specific milestones and events in each application, a process that requires collaboration between all the stakeholders in the project: business owners, designers, and developers.
We would be remiss if we didn’t mention that a modern browser is much more than a simple network socket manager. Performance is one of the primary competitive features for each browser vendor, and given that the networking performance is such a critical criteria, it should not surprise you that the browsers are getting smarter every day: pre-resolving likely DNS lookups, pre-connecting to likely destinations, pre-fetching and prioritizing critical resources on the page, and more.
The exact list of performed optimizations will differ by browser vendor, but at their core the optimizations can be grouped into two broad classes:
The good news is all of these optimizations are done automatically on our behalf and often lead to hundreds of milliseconds of saved network latency. Having said that, it is important to understand how and why these optimizations work under the hood, because we can assist the browser and help it do an even better job at accelerating our applications. There are four techniques employed by most browsers:
For a deep dive into how these and other networking optimizations are implemented in Google Chrome, see High Performance Networking in Google Chrome.
From the outside, a modern browser network stack presents itself as simple resource-fetching mechanism, but from the inside, it is an elaborate and a fascinating case study for how to optimize for web performance. So how can we assist the browser in this quest? To start, pay close attention to the structure and the delivery of each page:
Further, aside from optimizing the structure of the page, we can also embed additional hints into the document itself to tip off the browser about additional optimizations it can perform on our behalf:
<link rel="dns-prefetch" href="//hostname_to_resolve.com">
Each of these is a hint for a speculative optimization. The browser does not guarantee that it will act on it, but it may use the hint to optimize its loading strategy. Unfortunately, not all browsers support all hints (Table 10-2), but if they don’t, then the hint is treated as a no-op and is harmless; make use of each of the techniques just shown where possible.
| Browser | dns-prefetch | subresource | prefetch | prerender |
Firefox | 3.5+ | n/a | 3.5+ | n/a |
Chrome | 1.0+ | 1.0+ | 1.0+ | 13+ |
Safari | 5.01+ | n/a | n/a | n/a |
IE | 9+ (prefetch) | n/a | 10+ | 11+ |
Internet Explorer 9 supports DNS pre-fetching, but calls it prefetch. In Internet Explorer 10+, dns-prefetch and prefetch are equivalent, resulting in a DNS pre-fetch in both cases.
To most users and even web developers, the DNS, TCP, and SSL delays are entirely transparent and are negotiated at network layers to which few of us descend. And yet each of these steps is critical to the overall user experience, since each extra network roundtrip can add tens or hundreds of milliseconds of network latency. By helping the browser anticipate these roundtrips, we can remove these bottlenecks and deliver much faster and better web applications.
A discussion on optimization strategies for HTTP/1.0 is a simple one: all HTTP/1.0 deployments should be upgraded to HTTP/1.1; end of story.
Improving performance of HTTP was one the key design goals for the HTTP/1.1 working group, and the standard introduced a large number of critical performance enhancements and features. A few of the best known include the following:
This list is incomplete, and a full discussion of the technical details of each and every HTTP/1.1 enhancement deserves a separate book. Once again, check out HTTP: The Definitive Guide by David Gourley and Brian Totty. Similarly, speaking of good reference books, Steve Souders’ High Performance Web Sites offers great advice in the form of 14 rules, half of which are networking optimizations:
Each of the preceding recommendations has stood the test of time and is as true today as when the book was first published in 2007. That is no coincidence, because all of them highlight two fundamental recommendations: eliminate and reduce unnecessary network latency, and minimize the amount of transferred bytes. Both are evergreen optimizations, which will always ring true for any application.
However, the same can’t be said for all HTTP/1.1 features and best practices. Unfortunately, some HTTP/1.1 features, like request pipelining, have effectively failed due to lack of support, and other protocol limitations, such as head-of-line response blocking, created further cracks in the foundation. In turn, the web developer community—always an inventive lot—has created and popularized a number of homebrew optimizations: domain sharding, concatenation, spriting, and inlining among dozens of others.
For many web developers, all of these are matter-of-fact optimizations: familiar, necessary, and universally accepted. However, in reality, these techniques should be seen for what they really are: stopgap workarounds for existing limitations in the HTTP/1.1 protocol. We shouldn’t have to worry about concatenating files, spriting images, sharding domains, or inlining assets. Unfortunately, “shouldn’t” is not a pragmatic stance to take: these optimizations exist for good reasons, and we have to rely on them until the underlying issues are fixed in the next revision of the protocol.
One of the primary performance improvements of HTTP/1.1 was the introduction of persistent, or keepalive HTTP connections—both names refer to the same feature. We saw keepalive in action in HTTP/1.1: Internet Standard, but let’s illustrate why this feature is such a critical component of our performance strategy.
To keep things simple, let’s restrict ourselves to a maximum of one TCP connection and examine the scenario (Figure 11-1) where we need to fetch just two small (<4 KB each) resources: an HTML document and a supporting CSS file, each taking some arbitrary amount of time on the server (40 and 20 ms, respectively).
Figure 11-1 assumes the same 28 millisecond one-way “light in fiber” delay between New York and London as used in previous TCP connection establishment examples; see Table 1-1.
Each TCP connection begins with a TCP three-way handshake, which takes a full roundtrip of latency between the client and the server. Following that, we will incur a minimum of another roundtrip of latency due to the two-way propagation delay of the HTTP request and response. Finally, we have to add the server processing time to get the total time for every request.
We cannot predict the server processing time, since that will vary by resource and the back-end behind it, but it is worth highlighting that the minimum total time for an HTTP request delivered via a new TCP connection is two network roundtrips: one for the handshake, one for the request-response cycle. This is a fixed cost imposed on all non-persistent HTTP sessions.
The faster your server processing time, the higher the impact of the fixed latency overhead of every network request! To prove this, try changing the roundtrip and server times in the previous example.
Hence, a simple optimization is to reuse the underlying connection! Adding support for HTTP keepalive (Figure 11-2) allows us to eliminate the second TCP three-way handshake, avoid another round of TCP slow-start, and save a full roundtrip of network latency.
In our example with two requests, the total savings is just a single roundtrip of latency, but let’s now consider the general case with a single TCP connection and N HTTP requests:
The total latency savings for N requests is (N–1) × RTT when connection keepalive is enabled. Finally, recall that the average value of N is 90 resources and growing (Anatomy of a Modern Web Application), and we quickly arrive at potential latency savings measured in seconds! Needless to say, persistent HTTP is a critical optimization for every web application.
Persistent HTTP allows us to reuse an existing connection between multiple application requests, but it implies a strict first in, first out (FIFO) queuing order on the client: dispatch request, wait for the full response, dispatch next request from the client queue. HTTP pipelining is a small but important optimization to this workflow, which allows us to relocate the FIFO queue from the client (request queuing) to the server (response queuing).
To understand why this is beneficial, let’s revisit Figure 11-2. First, observe that once the first request is processed by the server, there is an entire roundtrip of latency—response propagation latency, followed by request propagation latency—during which the server is idle. Instead, what if the server could begin processing the second request immediately after it finished the first one? Or, even better, perhaps it could even process both in parallel, on multiple threads, or with the help of multiple workers.
By dispatching our requests early, without blocking on each individual response, we can eliminate another full roundtrip of network latency, taking us from two roundtrips per request with no connection keepalive, down to two network roundtrips (Figure 11-3) of latency overhead for the entire queue of requests!
Eliminating the wait time imposed by response and request propagation latencies is one of the primary benefits of HTTP/1.1 pipelining. However, the ability to process the requests in parallel can have just as big, if not bigger, impact on the performance of your application.
At this point, let’s pause and revisit our performance gains so far. We began with two distinct TCP connections for each request (Figure 11-1), which resulted in 284 milliseconds of total latency. With keepalive enabled (Figure 11-2), we were able to eliminate an extra handshake roundtrip, bringing the total down to 228 milliseconds. Finally, with HTTP pipelining in place, we eliminated another network roundtrip in between requests. Hence, we went from 284 milliseconds down to 172 milliseconds, a 40% reduction in total latency, all through simple protocol optimization.
Further, note that the 40% improvement is not a fixed performance gain. This number is specific to our chosen network latencies and the two requests in our example. As an exercise for the reader, try a few additional scenarios with higher latencies and more requests. You may be surprised to discover that the savings can be much, much larger. In fact, the larger the network latency, and the more requests, the higher the savings. It is worth proving to yourself that this is indeed the case! Ergo, the larger the application, the larger the impact of networking optimization.
However, we are not done yet. The eagle-eyed among you have likely spotted another opportunity for optimization: parallel request processing on the server. In theory, there is no reason why the server could not have processed both pipelined requests (Figure 11-3) in parallel, eliminating another 20 milliseconds of latency.
Unfortunately, this optimization introduces a lot of subtle implications and illustrates an important limitation of the HTTP/1.x protocol: strict serialization of returned responses. Specifically, HTTP/1.x does not allow data from multiple responses to be interleaved (multiplexed) on the same connection, forcing each response to be returned in full before the bytes for the next response can be transferred. To illustrate this in action, let’s consider the case (Figure 11-4) where the server processes both of our requests in parallel.
Figure 11-4 demonstrates the following:
Even though the client issued both requests in parallel, and the CSS resource is available first, the server must wait to send the full HTML response before it can proceed with delivery of the CSS asset. This scenario is commonly known as head-of-line blocking and results in suboptimal delivery: underutilized network links, server buffering costs, and worst of all, unpredictable latency delays for the client. What if the first request hangs indefinitely or simply takes a very long time to generate on the server? With HTTP/1.1, all requests behind it are blocked and have to wait.
We have already encountered head-of-line blocking when discussing TCP: due to the requirement for strict in-order delivery, a lost TCP packet will block all packets with higher sequence numbers until it is retransmitted, inducing extra application latency; see TCP Head-of-Line Blocking.
In practice, due to lack of multiplexing, HTTP pipelining creates many subtle and undocumented implications for HTTP servers, intermediaries, and clients:
Due to these and similar complications, and lack of guidance in the HTTP/1.1 standard for these cases, HTTP pipelining adoption has remained very limited despite its many benefits. Today, some browsers support pipelining, usually as an advanced configuration option, but most have it disabled. In other words, if the web browser is the primary delivery vehicle for your web application, then we can’t count on HTTP pipelining to help with performance.
In absence of multiplexing in HTTP/1.x, the browser could naively queue all HTTP requests on the client, sending one after another over a single, persistent connection. However, in practice, this is too slow. Hence, the browser vendors are left with no other choice than to open multiple TCP sessions in parallel. How many? In practice, most modern browsers, both desktop and mobile, open up to six connections per host.
Before we go any further, it is worth contemplating the implications, both positive and negative, of opening multiple TCP connections in parallel. Let’s consider the maximum case with six independent connections per host:
The maximum request parallelism, in absence of pipelining, is the same as the number of open connections. Further, the TCP congestion window is also effectively multiplied by the number of open connections, allowing the client to circumvent the configured packet limit dictated by TCP slow-start. So far, this seems like a convenient workaround! However, let’s now consider some of the costs:
In practice, the CPU and memory costs are nontrivial, resulting in much higher per-client overhead on both client and server—higher operational costs. Similarly, we raise the implementation complexity on the client—higher development costs. Finally, this approach still delivers only limited benefits as far as application parallelism is concerned. It’s not the right long-term solution. Having said that, there are three valid reasons why we have to use it today:
Both TCP considerations (window scaling and cwnd) are best addressed by a simple upgrade to the latest OS kernel release; see Optimizing for TCP. The cwnd value has been recently raised to 10 packets, and all the latest platforms provide robust support for TCP window scaling. That’s the good news. The bad news is there is no simple workaround for fixing multiplexing in HTTP/1.x.
As long as we need to support HTTP/1.x clients, we are stuck with having to juggle multiple TCP streams. Which brings us to the next obvious question: why and how did the browsers settle on six connections per host? Unfortunately, as you may have guessed, the number is based on a collection of trade-offs: the higher the limit, the higher the client and server overhead, but at the additional benefit of higher request parallelism. Six connections per host is simply a safe middle ground. For some sites, this may provide great results; for many it is insufficient.
A gap in the HTTP/1.X protocol has forced browser vendors to introduce and maintain a connection pool of up to six TCP streams per host. The good news is all of the connection management is handled by the browser itself. As an application developer, you don’t have to modify your application at all. The bad news is six parallel streams may still not be enough for your application.
According to HTTP Archive, an average page is now composed of 90+ individual resources, which if delivered all by the same host would still result in significant queuing delays (Figure 11-5). Hence, why limit ourselves to the same host? Instead of serving all resources from the same origin (e.g., www.example.com), we can manually “shard” them across multiple subdomains: {shard1, shardn}.example.com. Because the hostnames are different, we are implicitly increasing the browser’s connection limit to achieve a higher level of parallelism. The more shards we use, the higher the parallelism!
Of course, there is no free lunch, and domain sharding is not an exception: every new hostname will require an additional DNS lookup, consume additional resources on both sides for each additional socket, and, worst of all, require the site author to manually manage where and how the resources are split.
In practice, it is not uncommon to have multiple hostnames (e.g., shard1.example.com, shard2.example.com) resolve to the same IP address. The shards are CNAME DNS records pointing to the same server, and browser connection limits are enforced with respect to the hostname, not the IP. Alternatively, the shards could point to a CDN or any other reachable server.
What is the formula for the optimal number of shards? Trick question, as there is no such simple equation. The answer depends on the number of resources on the page (which varies per page) and the available bandwidth and latency of the client’s connection (which varies per client). Hence, the best we can do is make an informed guess and use some fixed number of shards. With luck, the added complexity will translate to a net win for most clients.
In practice, domain sharding is often overused, resulting in tens of underutilized TCP streams, many of them never escaping TCP slow-start, and in the worst case, actually slowing down the user experience. Further, the costs are even higher when HTTPS must be used, due to the extra network roundtrips incurred by the TLS handshake. A few considerations to keep in mind:
Domain sharding is a legitimate but also an imperfect optimization. Always begin with the minimum number of shards (none), and then carefully increase the number and measure the impact on your application metrics. In practice, very few sites actually benefit from more than a dozen connections, and if you do find yourself at the top end of that range, then you may see a much larger benefit by reducing the number of resources or consolidating them into fewer requests.
HTTP 0.9 started with a simple, one-line ASCII request to fetch a hypertext document, which incurred minimal overhead. HTTP/1.0 extended the protocol by adding the notion of request and response headers to allow both sides to exchange additional request and response metadata. Finally, HTTP/1.1 made this format a standard: headers are easily extensible by any server or client and are always sent as plain text to remain compatible with previous versions of HTTP.
Today, each browser-initiated HTTP request will carry an additional 500–800 bytes of HTTP metadata: user-agent string, accept and transfer headers that rarely change, caching directives, and so on. Even worse, the 500–800 bytes is optimistic, since it omits the largest offender: HTTP cookies, which are now commonly used for session management, personalization, analytics, and more. Combined, all of this uncompressed HTTP metadata can, and often does, add up to multiple kilobytes of protocol overhead for each and every HTTP request.
RFC 2616 (HTTP/1.1) does not define any limit on the size of the HTTP headers. However, in practice, many servers and proxies will try to enforce either an 8 KB or a 16 KB limit.
The growing list of HTTP headers is not bad in and of itself, as most headers exist for a good reason. However, the fact that all HTTP headers are transferred in plain text (without any compression), can lead to high overhead costs for each and every request, which can be a serious bottleneck for some applications. For example, the rise of API-driven web applications, which frequently communicate with compact serialized messages (e.g., JSON payloads) means that it is now not uncommon to see the HTTP overhead exceed the payload data by an order of magnitude:
$> curl --trace-ascii - -d'{"msg":"hello"}' http://www.igvita.com/api== Info: Connected to www.igvita.com => Send header, 218 bytes
In the preceding example, our brief 15-character JSON message is wrapped in 352 bytes of HTTP headers, all transferred as plain text on the wire—96% protocol byte overhead, and that is the best case without any cookies. Reducing the transferred header data, which is highly repetitive and uncompressed, could save entire roundtrips of network latency and significantly improve the performance of many web applications.
Cookies are a common performance bottleneck for many applications; many developers forget that they add significant overhead to each request. See Eliminate Unnecessary Request Bytes for a full discussion.
The fastest request is a request not made. Reducing the number of total requests is the best performance optimization, regardless of protocol used or application in question. However, if eliminating the request is not an option, then an alternative strategy for HTTP/1.x is to bundle multiple resources into a single network request:
In the case of JavaScript and CSS, we can safely concatenate multiple files without affecting the behavior and the execution of the code as long as the execution order is maintained. Similarly, multiple images can be combined into an “image sprite,” and CSS can then be used to select and position the appropriate parts of the sprite within the browser viewport. The benefits of both of these techniques are twofold:
Both concatenation and spriting techniques are examples of content-aware application layer optimizations, which can yield significant performance improvements by reducing the networking overhead costs. However, these same techniques also introduce extra application complexity by requiring additional preprocessing, deployment considerations, and code (e.g., extra CSS markup for managing sprites). Further, bundling multiple independent resources may also have a significant negative impact on cache performance and execution speed of the page.
To understand why these techniques may hurt performance, consider the not-unusual case of an application with a few dozen individual JavaScript and CSS files, all combined into two requests in a production environment, one for the CSS and one for the JavaScript assets:
In practice, most web applications are not single pages but collections of different views, each with different resource requirements but also with significant overlap: common CSS, JavaScript, and images. Hence, combining all assets into a single bundle often results in loading and processing of unnecessary bytes on the wire—although this can be seen as a form of pre-fetching, but at the cost of slower initial startup.
Updates are an even larger problem for many applications. A single update to an image sprite or a combined JavaScript file may result in hundreds of kilobytes of new data transfers. We sacrifice modularity and cache granularity, which can quickly backfire if there is high churn on the asset, and especially if the bundle is large. If such is the case for your application, consider separating the “stable core,” such as frameworks and libraries, into separate bundles.
Memory use can also become a problem. In the case of image sprites, the browser must decode the entire image and keep it in memory, regardless of the actual size of displayed area. The browser does not magically clip the rest of the bitmap from memory!
All decoded images are stored as memory-backed RGBA bitmaps within the browser. In turn, each RGBA image pixel requires four bytes of memory: one byte each for red, green, and blue channels, and one byte for the alpha (transparency) channel. Hence, the total memory used is simply .
As an exercise, how much memory will a 800 × 600 pixel bitmap require?
800 × 600 × 4 bytes = 1,920,000 bytes ≈ 1.83 MB
On resource-constrained devices, such as mobile handsets, the memory overhead can quickly become your new bottleneck. This is especially true for image-heavy applications, such as games, which often depend on large numbers of image assets.
Finally, why would the execution speed be affected? Unfortunately, unlike HTML processing, which is parsed incrementally as soon as the bytes arrive on the client, both JavaScript and CSS parsing and execution is held back until the entire file is downloaded—neither JavaScript nor CSS processing models allow incremental execution.
In summary, concatenation and spriting are application-layer optimizations for the limitations of the underlying HTTP/1.x protocol: lack of reliable pipelining support and high request overhead. Both techniques can deliver significant performance improvements when applied correctly, but at the cost of added application complexity and with many additional caveats for caching, update costs, and even speed of execution and rendering of the page. Apply these optimizations carefully, measure the results, and consider the following questions in the context of your own application:
Finding the right balance among all of these criteria is an imperfect science.
Resource inlining is another popular optimization that helps reduce the number of outbound requests by embedding the resource within the document itself: JavaScript and CSS code can be included directly in the page via the appropriate script and style HTML blocks, and other resources, such as images and even audio or PDF files, can be inlined via the data URI scheme (data:[mediatype][;base64],data):
<imgsrc="data:image/gif;base64,R0lGODlhAQABAIAAAAAAAAAAACH5BAAAAAAALAAAAAABAAEAAAICTAEAOw=="alt="1x1 transparent (GIF) pixel"/>
The previous example embeds a 1×1 transparent GIF pixel within the document, but any other MIME type, as long as the browser understands it, could be similarly inlined within the page: PDF, audio, video, etc. However, some browsers enforce a limit on the size of data URIs: IE8 has a maximum limit of 32 KB.
Data URIs are useful for small and ideally unique assets. When a resource is inlined within a page, it is by definition part of the page and cannot be cached individually by the browser, a CDN, or any caching proxy as a standalone resource. Hence, if the same resource is inlined across multiple pages, then the same resource will have to be transferred as part of each and every page, increasing the overall size of each page. Further, if the inlined resource is updated, then all pages on which it previously appeared must be invalidated and refetched by the client.
Finally, while text-based resources such as CSS and JavaScript are easily inlined directly into the page with no extra overhead, base64 encoding must be used for non-text assets, which adds a significant overhead: 33% byte expansion as compared with the original resource!
Base64 encodes any byte stream into an ASCII string via 64 ASCII symbols, plus whitespace. In the process, base64 expands encoded stream by a factor of 4/3, incurring a 33% byte overhead.
In practice, a common rule of thumb is to consider inlining for resources under 1–2 KB, as resources below this threshold often incur higher HTTP overhead than the resource itself. However, if the inlined resource changes frequently, then this may lead to an unnecessarily high cache invalidation rate of host document: inlining is an imperfect science. A few criteria to consider if your application has many small, individual files:
HTTP/2 will make our applications faster, simpler, and more robust—a rare combination—by allowing us to undo many of the HTTP/1.1 workarounds previously done within our applications and address these concerns within the transport layer itself. Even better, it also opens up a number of entirely new opportunities to optimize our applications and improve performance!
The primary goals for HTTP/2 are to reduce latency by enabling full request and response multiplexing, minimize protocol overhead via efficient compression of HTTP header fields, and add support for request prioritization and server push. To implement these requirements, there is a large supporting cast of other protocol enhancements, such as new flow control, error handling, and upgrade mechanisms, but these are the most important features that every web developer should understand and leverage in their applications.
HTTP/2 does not modify the application semantics of HTTP in any way. All the core concepts, such as HTTP methods, status codes, URIs, and header fields, remain in place. Instead, HTTP/2 modifies how the data is formatted (framed) and transported between the client and server, both of whom manage the entire process, and hides all the complexity from our applications within the new framing layer. As a result, all existing applications can be delivered without modification. That’s the good news.
However, we are not just interested in delivering a working application; our goal is to deliver the best performance! HTTP/2 enables a number of new optimizations our applications can leverage, which were previously not possible, and our job is to make the best of them. Let’s take a closer look under the hood.
SPDY was an experimental protocol, developed at Google and announced in mid-2009, whose primary goal was to try to reduce the load latency of web pages by addressing some of the well-known performance limitations of HTTP/1.1. Specifically, the outlined project goals were set as follows:
To achieve the 50% PLT improvement, SPDY aimed to make more efficient use of the underlying TCP connection by introducing a new binary framing layer to enable request and response multiplexing, prioritization, and header compression; see Latency as a Performance Bottleneck.
Not long after the initial announcement, Mike Belshe and Roberto Peon, both software engineers at Google, shared their first results, documentation, and source code for the experimental implementation of the new SPDY protocol:
So far we have only tested SPDY in lab conditions. The initial results are very encouraging: when we download the top 25 websites over simulated home network connections, we see a significant improvement in performance—pages loaded up to 55% faster.
— A 2x Faster Web Chromium Blog
Fast-forward to 2012 and the new experimental protocol was supported in Chrome, Firefox, and Opera, and a rapidly growing number of sites, both large (e.g., Google, Twitter, Facebook) and small, were deploying SPDY within their infrastructure. In effect, SPDY was on track to become a de facto standard through growing industry adoption.
Observing the above trend, the HTTP Working Group (HTTP-WG) kicked off a new effort to take the lessons learned from SPDY, build and improve on them, and deliver an official “HTTP/2” standard: a new charter was drafted, an open call for HTTP/2 proposals was made, and after a lot of discussion within the working group, the SPDY specification was adopted as a starting point for the new HTTP/2 protocol.
Over the next few years SPDY and HTTP/2 would continue to coevolve in parallel, with SPDY acting as an experimental branch that was used to test new features and proposals for the HTTP/2 standard: what looks good on paper may not work in practice, and vice versa, and SPDY offered a route to test and evaluate each proposal before its inclusion in the HTTP/2 standard. In the end, this process spanned three years and resulted in a over a dozen intermediate drafts:
In early 2015 the IESG reviewed and approved the new HTTP/2 standard for publication. Shortly after that, the Google Chrome team announced their schedule to deprecate SPDY and NPN extension for TLS:
HTTP/2’s primary changes from HTTP/1.1 focus on improved performance. Some key features such as multiplexing, header compression, prioritization and protocol negotiation evolved from work done in an earlier open, but non-standard protocol named SPDY. Chrome has supported SPDY since Chrome 6, but since most of the benefits are present in HTTP/2, it’s time to say goodbye. We plan to remove support for SPDY in early 2016, and to also remove support for the TLS extension named NPN in favor of ALPN in Chrome at the same time. Server developers are strongly encouraged to move to HTTP/2 and ALPN.
We’re happy to have contributed to the open standards process that led to HTTP/2, and hope to see wide adoption given the broad industry engagement on standardization and implementation.
— Hello HTTP/2, Goodbye SPDY Chromium Blog
The coevolution of SPDY and HTTP/2 enabled server, browser, and site developers to gain real-world experience with the new protocol as it was being developed. As a result, the HTTP/2 standard is one of the best and most extensively tested standards right out of the gate. By the time HTTP/2 was approved by the IESG, there were dozens of thoroughly tested and production-ready client and server implementations. In fact, just weeks after the final protocol was approved, many users were already enjoying its benefits as several popular browsers (and many sites) deployed full HTTP/2 support.
First versions of the HTTP protocol were intentionally designed for simplicity of implementation: HTTP/0.9 was a one-line protocol to bootstrap the World Wide Web; HTTP/1.0 documented the popular extensions to HTTP/0.9 in an informational standard; HTTP/1.1 introduced an official IETF standard; see Chapter 9. As such, HTTP/0.9-1.x delivered exactly what it set out to do: HTTP is one of the most ubiquitous and widely adopted application protocols on the Internet.
Unfortunately, implementation simplicity also came at a cost of application performance: HTTP/1.x clients need to use multiple connections to achieve concurrency and reduce latency; HTTP/1.x does not compress request and response headers, causing unnecessary network traffic; HTTP/1.x does not allow effective resource prioritization, resulting in poor use of the underlying TCP connection; and so on.
These limitations were not fatal, but as the web applications continued to grow in their scope, complexity, and importance in our everyday lives, they imposed a growing burden on both the developers and users of the web, which is the exact gap that HTTP/2 was designed to address:
HTTP/2 enables a more efficient use of network resources and a reduced perception of latency by introducing header field compression and allowing multiple concurrent exchanges on the same connection… Specifically, it allows interleaving of request and response messages on the same connection and uses an efficient coding for HTTP header fields. It also allows prioritization of requests, letting more important requests complete more quickly, further improving performance.
The resulting protocol is more friendly to the network, because fewer TCP connections can be used in comparison to HTTP/1.x. This means less competition with other flows, and longer-lived connections, which in turn leads to better utilization of available network capacity. Finally, HTTP/2 also enables more efficient processing of messages through use of binary message framing.
— Hypertext Transfer Protocol version 2, Draft 17
It is important to note that HTTP/2 is extending, not replacing, the previous HTTP standards. The application semantics of HTTP are the same, and no changes were made to the offered functionality or core concepts such as HTTP methods, status codes, URIs, and header fields—these changes were explicitly out of scope for the HTTP/2 effort. That said, while the high-level API remains the same, it is important to understand how the low-level changes address the performance limitations of the previous protocols. Let’s take a brief tour of the binary framing layer and its features.
At the core of all performance enhancements of HTTP/2 is the new binary framing layer (Figure 12-1), which dictates how the HTTP messages are encapsulated and transferred between the client and server.
The “layer” refers to a design choice to introduce a new optimized encoding mechanism between the socket interface and the higher HTTP API exposed to our applications: the HTTP semantics, such as verbs, methods, and headers, are unaffected, but the way they are encoded while in transit is what’s different. Unlike the newline delimited plaintext HTTP/1.x protocol, all HTTP/2 communication is split into smaller messages and frames, each of which is encoded in binary format.
As a result, both client and server must use the new binary encoding mechanism to understand each other: an HTTP/1.x client won’t understand an HTTP/2 only server, and vice versa. Thankfully, our applications remain blissfully unaware of all these changes, as the client and server perform all the necessary framing work on our behalf.
The introduction of the new binary framing mechanism changes how the data is exchanged (Figure 12-2) between the client and server. To describe this process, let’s familiarize ourselves with the HTTP/2 terminology:
The smallest unit of communication in HTTP/2, each containing a frame header, which at a minimum identifies the stream to which the frame belongs.
In short, HTTP/2 breaks down the HTTP protocol communication into an exchange of binary-encoded frames, which are then mapped to messages that belong to a particular stream, and all of which are multiplexed within a single TCP connection. This is the foundation that enables all other features and performance optimizations provided by the HTTP/2 protocol.
With HTTP/1.x, if the client wants to make multiple parallel requests to improve performance, then multiple TCP connections must be used; see Using Multiple TCP Connections. This behavior is a direct consequence of the HTTP/1.x delivery model, which ensures that only one response can be delivered at a time (response queuing) per connection. Worse, this also results in head-of-line blocking and inefficient use of the underlying TCP connection.
The new binary framing layer in HTTP/2 removes these limitations, and enables full request and response multiplexing, by allowing the client and server to break down an HTTP message into independent frames (Figure 12-3), interleave them, and then reassemble them on the other end.
The snapshot in Figure 12-3 captures multiple streams in flight within the same connection: the client is transmitting a DATA frame (stream 5) to the server, while the server is transmitting an interleaved sequence of frames to the client for streams 1 and 3. As a result, there are three parallel streams in flight!
The ability to break down an HTTP message into independent frames, interleave them, and then reassemble them on the other end is the single most important enhancement of HTTP/2. In fact, it introduces a ripple effect of numerous performance benefits across the entire stack of all web technologies, enabling us to:
The new binary framing layer in HTTP/2 resolves the head-of-line blocking problem found in HTTP/1.x and eliminates the need for multiple connections to enable parallel processing and delivery of requests and responses. As a result, this makes our applications faster, simpler, and cheaper to deploy.
Once an HTTP message can be split into many individual frames, and we allow for frames from multiple streams to be multiplexed, the order in which the frames are interleaved and delivered both by the client and server becomes a critical performance consideration. To facilitate this, the HTTP/2 standard allows each stream to have an associated weight and dependency:
The combination of stream dependencies and weights allows the client to construct and communicate a “prioritization tree” (Figure 12-4) that expresses how it would prefer to receive the responses. In turn, the server can use this information to prioritize stream processing by controlling the allocation of CPU, memory, and other resources, and once the response data is available, allocation of bandwidth to ensure optimal delivery of high-priority responses to the client.
A stream dependency within HTTP/2 is declared by referencing the unique identifier of another stream as its parent; if omitted the stream is said to be dependent on the “root stream”. Declaring a stream dependency indicates that, if possible, the parent stream should be allocated resources ahead of its dependencies—e.g., please process and deliver response D before response C.
Streams that share the same parent (i.e., sibling streams) should be allocated resources in proportion to their weight. For example, if stream A has a weight of 12 and its one sibling B has a weight of 4, then to determine the proportion of the resources that each of these streams should receive:
,
Thus, stream A should receive three-quarters and stream B should receive one-quarter of available resources; stream B should receive one-third of the resources allocated to stream A. Let’s work through a few more hands-on examples in Figure 12-4. From left to right:
As the above examples illustrate, the combination of stream dependencies and weights provides an expressive language for resource prioritization, which is a critical feature for improving browsing performance where we have many resource types with different dependencies and weights. Even better, the HTTP/2 protocol also allows the client to update these preferences at any point, which enables further optimizations in the browser—e.g., we can change dependencies and reallocate weights in response to user interaction and other signals.
Stream dependencies and weights express a transport preference, not a requirement, and as such do not guarantee a particular processing or transmission order. That is, the client cannot force the server to process the stream in particular order using stream prioritization. While this may seem counterintuitive, it is in fact the desired behavior: we do not want to block the server from making progress on a lower priority resource if a higher priority resource is blocked.
With the new binary framing mechanism in place, HTTP/2 no longer needs multiple TCP connections to multiplex streams in parallel; each stream is split into many frames, which can be interleaved and prioritized. As a result, all HTTP/2 connections are persistent, and only one connection per origin is required, which offers numerous performance benefits.
For both SPDY and HTTP/2 the killer feature is arbitrary multiplexing on a single well congestion controlled channel. It amazes me how important this is and how well it works. One great metric around that which I enjoy is the fraction of connections created that carry just a single HTTP transaction (and thus make that transaction bear all the overhead). For HTTP/1 74% of our active connections carry just a single transaction—persistent connections just aren’t as helpful as we all want. But in HTTP/2 that number plummets to 25%. That’s a huge win for overhead reduction.
— HTTP/2 is Live in Firefox Patrick McManus
Most HTTP transfers are short and bursty, whereas TCP is optimized for long-lived, bulk data transfers. By reusing the same connection HTTP/2 is able to both make more efficient use of each TCP connection, and also significantly reduce the overall protocol overhead. Further, the use of fewer connections reduces the memory and processing footprint along the full connection path (i.e., client, intermediaries, and origin servers), which reduces the overall operational costs and improves network utilization and capacity. As a result, the move to HTTP/2 should not only reduce the network latency, but also help improve throughput and reduce the operational costs.
Reduced number of connections is a particularly important feature for improving performance of HTTPS deployments: this translates to fewer expensive TLS handshakes, better session reuse, and an overall reduction in required client and server resources.
Flow control is a mechanism to prevent the sender from overwhelming the receiver with data it may not want or be able to process: the receiver may be busy, under heavy load, or may only be willing to allocate a fixed amount of resources for a particular stream. For example, the client may have requested a large video stream with high priority, but the user has paused the video and the client now wants to pause or throttle its delivery from the server to avoid fetching and buffering unnecessary data. Alternatively, a proxy server may have a fast downstream and slow upstream connections and similarly wants to regulate how quickly the downstream delivers data to match the speed of upstream to control its resource usage; and so on.
Do the above requirements remind you of TCP flow control? They should, as the problem is effectively identical—see Flow Control. However, because the HTTP/2 streams are multiplexed within a single TCP connection, TCP flow control is both not granular enough, and does not provide the necessary application-level APIs to regulate the delivery of individual streams. To address this, HTTP/2 provides a set of simple building blocks that allow the client and server to implement own stream- and connection-level flow control:
DATA frame and incremented via a WINDOW_UPDATE frame sent by the receiver.
SETTINGS frames, which set the flow control window sizes in both directions. The default value of the flow control window is set to 65,535 bytes, but the receiver can set a large maximum window size ( bytes) and maintain it by sending a WINDOW_UPDATE frame whenever any data is received.
HTTP/2 does not specify any particular algorithm for implementing flow control. Instead, it provides the simple building blocks and defers the implementation to the client and server, which can use it to implement custom strategies to regulate resource use and allocation, as well as implement new delivery capabilities that may help improve both the real and perceived performance (see Speed, Performance, and Human Perception) of our web applications.
For example, application-layer flow control allows the browser to fetch only a part of a particular resource, put the fetch on hold by reducing the stream flow control window down to zero, and then resume it later—e.g., fetch a preview or first scan of an image, display it and allow other high priority fetches to proceed, and resume the fetch once more critical resources have finished loading.
Another powerful new feature of HTTP/2 is the ability of the server to send multiple responses for a single client request. That is, in addition to the response to the original request, the server can push additional resources to the client (Figure 12-5), without the client having to request each one explicitly!
HTTP/2 breaks away from the strict request-response semantics and enables one-to-many and server-initiated push workflows that open up a world of new interaction possibilities both within and outside the browser. This is an enabling feature that will have important long-term consequences both for how we think about the protocol, and where and how it is used.
Why would we need such a mechanism in a browser? A typical web application consists of dozens of resources, all of which are discovered by the client by examining the document provided by the server. As a result, why not eliminate the extra latency and let the server push the associated resources ahead of time? The server already knows which resources the client will require; that’s server push.
In fact, if you have ever inlined a CSS, JavaScript, or any other asset via a data URI (see Resource Inlining), then you already have hands-on experience with server push! By manually inlining the resource into the document, we are, in effect, pushing that resource to the client, without waiting for the client to request it. With HTTP/2 we can achieve the same results, but with additional performance benefits:
Each pushed resource is a stream that, unlike an inlined resource, allows it to be individually multiplexed, prioritized, and processed by the client. The only security restriction, as enforced by the browser, is that pushed resources must obey the same-origin policy: the server must be authoritative for the provided content.
Each HTTP transfer carries a set of headers that describe the transferred resource and its properties. In HTTP/1.x, this metadata is always sent as plain text and adds anywhere from 500–800 bytes of overhead per transfer, and sometimes kilobytes more if HTTP cookies are being used; see Measuring and Controlling Protocol Overhead. To reduce this overhead and improve performance, HTTP/2 compresses request and response header metadata using the HPACK compression format that uses two simple but powerful techniques:
Huffman coding allows the individual values to be compressed when transferred, and the indexed list of previously transferred values allows us to encode duplicate values (Figure 12-6) by transferring index values that can be used to efficiently look up and reconstruct the full header keys and values.
As one further optimization, the HPACK compression context consists of a static and dynamic tables: the static table is defined in the specification and provides a list of common HTTP header fields that all connections are likely to use (e.g., valid header names); the dynamic table is initially empty and is updated based on exchanged values within a particular connection. As a result, the size of each request is reduced by using static Huffman coding for values that haven’t been seen before, and substitution of indexes for values that are already present in the static or dynamic tables on each side.
The definitions of the request and response header fields in HTTP/2 remain unchanged, with a few minor exceptions: all header field names are lowercase, and the request line is now split into individual :method, :scheme, :authority, and :path pseudo-header fields.
The switch to HTTP/2 cannot happen overnight: millions of servers must be updated to use the new binary framing, and billions of clients must similarly update their networking libraries, browsers, and other applications.
The good news is, all modern browsers have committed to supporting HTTP/2, and most modern browsers use efficient background update mechanisms, which have already enabled HTTP/2 support with minimal intervention for a large proportion of existing users. That said, some users will be stuck on legacy browsers, and servers and intermediaries will also have to be updated to support HTTP/2, which is a much longer (and labor- and capital-intensive) process.
HTTP/1.x will be around for at least another decade, and most servers and clients will have to support both HTTP/1.x and HTTP/2 standards. As a result, an HTTP/2 client and server must be able to discover and negotiate which protocol will be used prior to exchanging application data. To address this, the HTTP/2 protocol defines the following mechanisms:
The HTTP/2 standard does not require use of TLS, but in practice it is the most reliable way to deploy a new protocol in the presence of large number of existing intermediaries; see Proxies, Intermediaries, TLS, and New Protocols on the Web. As a result, the use of TLS and ALPN is the recommended mechanism to deploy and negotiate HTTP/2: the client and server negotiate the desired protocol as part of the TLS handshake without adding any extra latency or roundtrips; see TLS Handshake and Application Layer Protocol Negotiation (ALPN). Further, as an additional constraint, while all popular browsers have committed to supporting HTTP/2 over TLS, some have also indicated that they will only enable HTTP/2 over TLS—e.g., Firefox and Google Chrome. As a result, TLS with ALPN negotiation is a de facto requirement for enabling HTTP/2 in the browser.
Establishing an HTTP/2 connection over a regular, non-encrypted channel is still possible, albeit perhaps not with a popular browser, and with some additional complexity. Because both HTTP/1.x and HTTP/2 run on the same port (80), in absence of any other information about server support for HTTP/2, the client has to use the HTTP Upgrade mechanism to negotiate the appropriate protocol:
GET /page HTTP/1.1 Host: server.example.com Connection: Upgrade, HTTP2-Settings Upgrade: h2c
Using the preceding Upgrade flow, if the server does not support HTTP/2, then it can immediately respond to the request with HTTP/1.1 response. Alternatively, it can confirm the HTTP/2 upgrade by returning the 101 Switching Protocols response in HTTP/1.1 format and then immediately switch to HTTP/2 and return the response using the new binary framing protocol. In either case, no extra roundtrips are incurred.
Finally, if the client chooses to, it may also remember or obtain the information about HTTP/2 support through some other means—e.g., DNS record, manual configuration, and so on—instead of having to rely on the Upgrade workflow. Armed with this knowledge, it may choose to send HTTP/2 frames right from the start, over an unencrypted channel, and hope for the best. In the worst case, the connection will fail, and the client will fall back to Upgrade workflow or switch to a TLS tunnel with ALPN negotiation.
Secure communication between client and server, server to server, and all other permutations, is a security best practice: all in-transit data should be encrypted, authenticated, and checked against tampering. In short, use TLS with ALPN negotiation to deploy HTTP/2.
At the core of all HTTP/2 improvements is the new binary, length-prefixed framing layer. Compared with the newline-delimited plaintext HTTP/1.x protocol, binary framing offers more compact representation that is both more efficient to process and easier to implement correctly.
Once an HTTP/2 connection is established, the client and server communicate by exchanging frames, which serve as the smallest unit of communication within the protocol. All frames share a common 9-byte header (Figure 12-7), which contains the length of the frame, its type, a bit field for flags, and a 31-bit stream identifier.
bytes of data.
Technically, the length field allows payloads of up to bytes (~16MB) per frame. However, the HTTP/2 standard sets the default maximum payload size of DATA frames to bytes (~16KB) per frame and allows the client and server to negotiate the higher value. Bigger is not always better: smaller frame size enables efficient multiplexing and minimizes head-of-line blocking.
Given this knowledge of the shared HTTP/2 frame header, we can now write a simple parser that can examine any HTTP/2 bytestream and identify different frame types, report their flags, and report the length of each by examining the first nine bytes of every frame. Further, because each frame is length-prefixed, the parser can skip ahead to the beginning of the next frame both quickly and efficiently—a big performance improvement over HTTP/1.x.
Once the frame type is known, the remainder of the frame can be interpreted by the parser. The HTTP/2 standard defines the following types:
|
|
Used to transport HTTP message bodies |
|
|
Used to communicate header fields for a stream |
|
|
Used to communicate sender-advised priority of a stream |
|
|
Used to signal termination of a stream |
|
|
Used to communicate configuration parameters for the connection |
|
|
Used to signal a promise to serve the referenced resource |
|
|
Used to measure the roundtrip time and perform “liveness” checks |
|
|
Used to inform the peer to stop creating streams for current connection |
WINDOW_UPDATE
CONTINUATION
You will need some tooling to inspect the low-level HTTP/2 frame exchange. Your favorite hex viewer is, of course, an option. Or, for a more human-friendly representation, you can use a tool like Wireshark, which understands the HTTP/2 protocol and can capture, decode, and analyze the exchange.
The good news is that the exact semantics of the preceding taxonomy of frames is mostly only relevant to server and client implementers, who will need to worry about the semantics of flow control, error handling, connection termination, and other details. The application layer features and semantics of the HTTP protocol remain unchanged: the client and server take care of the framing, multiplexing, and other details, while the application can enjoy the benefits of faster and more efficient delivery.
Having said that, even though the framing layer is hidden from our applications, it is useful for us to go just one step further and look at the two most common workflows: initiating a new stream and exchanging application data. Having an intuition for how a request, or a response, is translated into individual frames will give you the necessary knowledge to debug and optimize your HTTP/2 deployments. Let’s dig a little deeper.
Before any application data can be sent, a new stream must be created and the appropriate request metadata must be sent: optional stream dependency and weight, optional flags, and the HPACK-encoded HTTP request headers describing the request. The client initiates this process by sending a HEADERS frame (Figure 12-8) with all of the above.
Wireshark decodes and displays the frame fields in the same order as encoded on the wire—e.g., compare the fields in the common frame header to the frame layout in Figure 12-7.
The HEADERS frame is used to declare and communicate metadata about the new request. The application payload, if available, is delivered independently within the DATA frames. This separation allows the protocol to separate processing of “control traffic” from delivery of application data—e.g., flow control is applied only to DATA frames, and non-DATA frames are always processed with high priority.
Once a new stream is created, and the HTTP headers are sent, DATA frames (Figure 12-9) are used to send the application payload if one is present. The payload can be split between multiple DATA frames, with the last frame indicating the end of the message by toggling the END_STREAM flag in the header of the frame.
The “End Stream” flag is set to “false” in Figure 12-9, indicating that the client has not finished transmitting the application payload; more DATA frames are coming.
Aside from the length and flags fields, there really isn’t much more to say about the DATA frame. The application payload may be split between multiple DATA frames to enable efficient multiplexing, but otherwise it is delivered exactly as provided by the application—i.e., the choice of the encoding mechanism (plain text, gzip, or other encoding formats) is deferred to the application.
Armed with knowledge of the different frame types, we can now revisit the diagram (Figure 12-10) we encountered earlier in Request and Response Multiplexing and analyze the HTTP/2 exchange:
DATA frames for stream 1, which carry the application response to the client’s earlier request.
HEADERS and DATA frames for stream 3 between the DATA frames for stream 1—response multiplexing in action!
DATA frame for stream 5, which indicates that a HEADERS frame was transferred earlier.
The above analysis is, of course, based on a simplified representation of an actual HTTP/2 exchange, but it still illustrates many of the strengths and features of the new protocol. By this point, you should have the necessary knowledge to successfully record and analyze a real-world HTTP/2 trace—give it a try!
High-performance browser networking relies on a host of networking technologies (Figure 13-1), and the overall performance of our applications is the sum total of each of their parts.
We cannot control the network weather between the client and server, nor the client hardware or the configuration of their device, but the rest is in our hands: TCP and TLS optimizations on the server, and dozens of application optimizations to account for the peculiarities of the different physical layers, versions of HTTP protocol in use, as well as general application best practices. Granted, getting it all right is not an easy task, but it is a rewarding one! Let’s pull it all together.
The physical properties of the communication channel set hard performance limits on every application: speed of light and distance between client and server dictate the propagation latency, and the choice of medium (wired vs. wireless) determines the processing, transmission, queuing, and other delays incurred by each data packet. In fact, the performance of most web applications is limited by latency, not bandwidth, and while bandwidth speeds will continue to increase, unfortunately the same can’t be said for latency:
As a result, while we cannot make the bits travel any faster, it is crucial that we apply all the possible optimizations at the transport and application layers to eliminate unnecessary roundtrips, requests, and minimize the distance traveled by each packet—i.e., position the servers closer to the client.
Every application can benefit from optimizing for the unique properties of the physical layer in wireless networks, where latencies are high, and bandwidth is always at a premium. At the API layer, the differences between the wired and wireless networks are entirely transparent, but ignoring them is a recipe for poor performance. Simple optimizations in how and when we schedule resource downloads, beacons, and the rest can translate to significant impact on the experienced latency, battery life, and overall user experience of our applications:
Moving up the stack from the physical layer, we must ensure that each and every server is configured to use the latest TCP and TLS best practices. Optimizing the underlying protocols ensures that each client can get the best performance—high throughput and low latency—when communicating with the server:
Finally, we arrive at the application layer. By all accounts and measures, HTTP is an incredibly successful protocol. After all, it is the common language between billions of clients and servers, enabling the modern Web. However, it is also an imperfect protocol, which means that we must take special care in how we architect our applications:
The secret to a successful web performance strategy is simple: invest into monitoring and measurement tools to identify problems and regressions (see Synthetic and Real-User Performance Measurement), link business goals to performance metrics, and optimize from there—i.e., treat performance as a feature.
Regardless of the type of network or the type or version of the networking protocols in use, all applications should always seek to eliminate or reduce unnecessary network latency and minimize the number of transferred bytes. These two simple rules are the foundation for all of the evergreen performance best practices:
By this point, all of these recommendations should require no explanation: latency is the bottleneck, and the fastest byte is a byte not sent. However, HTTP provides some additional mechanisms, such as caching and compression, as well as its set of version-specific performance quirks:
Each of these warrants closer examination. Let’s dive in.
The fastest network request is a request not made. Maintaining a cache of previously downloaded data allows the client to use a local copy of the resource, thereby eliminating the request. For resources delivered over HTTP, make sure the appropriate cache headers are in place:
Whenever possible, you should specify an explicit cache lifetime for each resource, which allows the client to use a local copy, instead of re-requesting the same object all the time. Similarly, specify a validation mechanism to allow the client to check if the expired resource has been updated: if the resource has not changed, we can eliminate the data transfer.
Finally, note that you need to specify both the cache lifetime and the validation method! A common mistake is to provide only one of the two, which results in either redundant transfers of resources that have not changed (i.e., missing validation), or redundant validation checks each time the resource is used (i.e., missing or unnecessarily short cache lifetime).
For hands-on advice on optimizing your caching strategy, see the “HTTP caching” section on Google’s Web Fundamentals.
Leveraging a local cache allows the client to avoid fetching duplicate content on each request. However, if and when the resource must be fetched, either because it has expired, it is new, or it cannot be cached, then it should be transferred with the minimum number of bytes. Always apply the best compression method for each asset.
The size of text-based assets, such as HTML, CSS, and JavaScript, can be reduced by 60%–80% on average when compressed with Gzip. Images, on the other hand, require more nuanced consideration:
Images account for over half of the transferred bytes of an average page, which makes them a high-value optimization target: the simple choice of an optimal image format can yield dramatically improved compression ratios; lossy compression methods can reduce transfer sizes by orders of magnitude; sizing the image to its display width will reduce both the transfer and memory footprints (see Calculating Image Memory Requirements) on the client. Invest into tools and automation to optimize image delivery on your site.
For hands-on advice on reducing the transfer size of text, image, webfont, and other resources, see the “Optimizing Content Efficiency” section on Google’s Web Fundamentals.
HTTP is a stateless protocol, which means that the server is not required to retain any information about the client between different requests. However, many applications require state for session management, personalization, analytics, and more. To enable this functionality, the HTTP State Management Mechanism (RFC 2965) extension allows any website to associate and update “cookie” metadata for its origin: the provided data is saved by the browser and is then automatically appended onto every request to the origin within the Cookie header.
The standard does not specify a maximum limit on the size of a cookie, but in practice most browsers enforce a 4 KB limit. However, the standard also allows the site to associate many cookies per origin. As a result, it is possible to associate tens to hundreds of kilobytes of arbitrary metadata, split across multiple cookies, for each origin!
Needless to say, this can have significant performance implications for your application. Associated cookie data is automatically sent by the browser on each request, which, in the worst case can add entire roundtrips of network latency by exceeding the initial TCP congestion window, regardless of whether HTTP/1.x or HTTP/2 is used:
Cookie size should be monitored judiciously: transfer the minimum amount of required data, such as a secure session token, and leverage a shared session cache on the server to look up other metadata. And even better, eliminate cookies entirely wherever possible—chances are, you do not need client-specific metadata when requesting static assets, such as images, scripts, and stylesheets.
To achieve the fastest response times within your application, all resource requests should be dispatched as soon as possible. However, another important point to consider is how these requests will be processed on the server. After all, if all of our requests are then serially queued by the server, then we are once again incurring unnecessary latency. Here’s how to get the best performance:
Without connection keepalive, a new TCP connection is required for each HTTP request, which incurs significant overhead due to the TCP handshake and slow-start. Make sure to identify and optimize your server and proxy connection timeouts to avoid closing the connection prematurely. With that in place, and to get the best performance, use HTTP/2 to allow the client and server to reuse the same connection for all requests. If HTTP/2 is not an option, use multiple TCP connections to achieve request parallelism with HTTP/1.x.
Identifying the sources of unnecessary client and server latency is both an art and science: examine the client resource waterfall (see Analyzing the Resource Waterfall), as well as your server logs. Common pitfalls often include the following:
The order in which we optimize HTTP/1.x deployments is important: configure servers to deliver the best possible TCP and TLS performance, and then carefully review and apply mobile and evergreen application best practices: measure, iterate.
With the evergreen optimizations in place, and with good performance instrumentation within the application, evaluate whether the application can benefit from applying HTTP/1.x specific optimizations (read, protocol workarounds):
Pipelining has limited support, and each of the remaining optimizations comes with its set of benefits and trade-offs. In fact, it is often overlooked that each of these techniques can hurt performance when applied aggressively, or incorrectly; review Chapter 11 for an in-depth discussion.
HTTP/2 eliminates the need for all of the above HTTP/1.x workarounds, making our applications both simpler and more performant. Which is to say, the best optimization for HTTP/1.x is to deploy HTTP/2.
HTTP/2 enables more efficient use of network resources and reduced latency by enabling request and response multiplexing, header compression, prioritization, and more—see Design and Technical Goals. Getting the best performance out of HTTP/2, especially in light of the one-connection-per-origin model, requires a well-tuned server network stack. Review Optimizing for TCP and Optimizing for TLS for an in-depth discussion and optimization checklists.
Next up—surprise—apply the evergreen application best practices: send fewer bytes, eliminate requests, and adapt resource scheduling for wireless networks. Reducing the amount of data transferred and eliminating unnecessary network latency are the best optimizations for any application, web or native, regardless of the version or type of the application and transport protocols in use.
Finally, undo and unlearn the bad habits of domain sharding, concatenation, and image spriting. With HTTP/2 we are no longer constrained by limited parallelism: requests are cheap, and both requests and responses can be multiplexed efficiently. These workarounds are no longer necessary and omitting them can improve performance.
HTTP/2 achieves the best performance by multiplexing requests over the same TCP connection, which enables effective request and response prioritization, flow control, and header compression. As a result, the optimal number of connections is exactly one and domain sharding is an anti-pattern.
HTTP/2 also provides a TLS connection-coalescing mechanism that allows the client to coalesce requests from different origins and dispatch them over the same connection when the following conditions are satisfied:
For example, if example.com provides a wildcard TLS certificate that is valid for all of its subdomains (i.e., *.example.com) and references an asset on static.example.com that resolves to the same server IP address as example.com, then the HTTP/2 client is allowed to reuse the same TCP connection to fetch resources from example.com and static.example.com.
An interesting side effect of HTTP/2 connection coalescing is that it enables an HTTP/1.x friendly deployment model: some assets can be served from alternate origins, which enables higher parallelism for HTTP/1 clients, and if those same origins satisfy the above criteria then the HTTP/2 clients can coalesce requests and reuse the same connection. Alternatively, the application can be more hands-on and inspect the negotiated protocol and deliver alternate resources for each client: with sharded asset references for HTTP/1.x clients and with same-origin asset references for HTTP/2 clients.
Depending on the architecture of your application you may be able to rely on connection coalescing, you may need to serve alternate markup, or you may use both techniques as necessary to provide the optimal HTTP/1.x and HTTP/2 experience. Alternatively, you might consider focusing on optimizing HTTP/2 performance only; the client adoption is growing rapidly, and the extra complexity of optimizing for both protocols may be unnecessary.
Due to third-party dependencies it may not be possible to fetch all the resources via the same TCP connection—that’s OK. Seek to minimize the number of origins regardless of the protocol and eliminate sharding when HTTP/2 is in use to get the best performance.
Bundling multiple assets into a single response was a critical optimization for HTTP/1.x where limited parallelism and high protocol overhead typically outweighed all other concerns—see Concatenation and Spriting. However, with HTTP/2, multiplexing is no longer an issue, and header compression dramatically reduces the metadata overhead of each HTTP request. As a result, we need to reconsider the use of concatenation and spriting in light of its new pros and cons:
In practice, while HTTP/1.x provides the mechanisms for granular cache management of each resource, the limited parallelism forced us to bundle resources together. The latency penalty of delayed fetches outweighed the costs of decreased effectiveness of caching, more frequent and more expensive invalidations, and delayed execution.
HTTP/2 removes this unfortunate trade-off by providing support for request and response multiplexing, which means that we can now optimize our applications by delivering more granular resources: each resource can have an optimized caching policy (expiry time and revalidation token) and be individually updated without invalidating other resources in the bundle. In short, HTTP/2 enables our applications to make better use of the HTTP cache.
That said, HTTP/2 does not eliminate the utility of concatenation and spriting entirely. A few additional considerations to keep in mind:
There is no single optimal strategy for all applications: delivering a single large bundle is unlikely to yield best results, and issuing hundreds of requests for small resources may not be the optimal strategy either. The right trade-off will depend on the type of content, frequency of updates, access patterns, and other criteria. To get the best results, gather measurement data for your own application and optimize accordingly.
Server push is a powerful new feature of HTTP/2 that enables the server to send multiple responses for a single client request. That said, recall that the use of resource inlining (e.g., embedding an image into an HTML document via a data URI) is, in fact, a form of application-layer server push. As such, while this is not an entirely new capability for web developers, the use of HTTP/2 server push offers many performance benefits over inlining: pushed resources can be cached individually, reused across pages, canceled by the client, and more—see Server Push.
With HTTP/2 there is no longer a reason to inline resources just because they are small; we’re no longer constrained by the lack of parallelism and request overhead is very low. As a result, server push acts as a latency optimization that removes a full request-response roundtrip between the client and server—e.g., if, after sending a particular response, we know that the client will always come back and request a specific subresource, we can eliminate the roundtrip by pushing the subresource to the client.
If the client does not support, or disables the use of server push, it will initiate the request for the same resource on its own—i.e., server push is a safe and transparent latency optimization.
Critical resources that block page construction and rendering (see DOM, CSSOM, and JavaScript) are prime candidates for the use of server push, as they are often known or can be specified upfront. Eliminating a full roundtrip from the critical path can yield savings of tens to hundreds of milliseconds, especially for users on mobile networks where latencies are often both high and highly variable.
Note that even the most naive server push strategy that opts to push assets regardless of their caching policy is, in effect, equivalent to inlining: the resource is duplicated on each page and transferred each time the parent resource is requested. However, even there, server push offers important performance benefits: the pushed response can be prioritized more effectively, it affords more control to the client, and it provides an upgrade path towards implementing much smarter strategies that leverage caching and other mechanisms that can eliminate redundant transfers. In short, if your application is using inlining, then you should consider replacing it with server push.
A naive implementation of an HTTP/2 server, or proxy, may “speak” the protocol, but without well implemented support for features such as flow control and request prioritization, it can easily yield less that optimal performance. For example, it might saturate the user’s bandwidth by sending large low priority resources (such as images), while the browser is blocked from rendering the page until it receives higher priority resources (such as HTML, CSS, or JavaScript).
With HTTP/2 the client places a lot of trust on the server. To get the best performance, an HTTP/2 client has to be “optimistic”: it annotates requests with priority information (see Stream Prioritization) and dispatches them to the server as soon as possible; it relies on the server to use the communicated dependencies and weights to optimize delivery of each response. A well-optimized HTTP server has always been important, but with HTTP/2 the server takes on additional and critical responsibilities that, previously, were out of scope.
Do your due diligence when testing and deploying your HTTP/2 infrastructure. Common benchmarks measuring server throughput and requests per second do not capture these new requirements and may not be representative of the actual experience as seen by your users when loading your application.
A modern browser is a platform specifically designed for fast, efficient, and secure delivery of web applications. In fact, under the hood, a modern browser is an entire operating system with hundreds of components: process management, security sandboxes, layers of optimization caches, JavaScript VMs, graphics rendering and GPU pipelines, storage, sensors, audio and video, networking, and much more.
Not surprisingly, the overall performance of the browser, and any application that it runs, is determined by a number of components: parsing, layout, style calculation of HTML and CSS, JavaScript execution speed, rendering pipelines, and of course the networking stack. Each component plays a critical role, but networking often doubly so, since if the browser is blocked on the network, waiting for the resources to arrive, then all other steps are blocked!
As a result, it is not surprising to discover that the networking stack of a modern browser is much more than a simple socket manager. From the outside, it may present itself as a simple resource-fetching mechanism, but from the inside it is its own platform (Figure 14-1), with its own optimization criteria, APIs, and services.
When designing a web application, we don’t have to worry about the individual TCP or UDP sockets; the browser manages that for us. Further, the network stack takes care of imposing the right connection limits, formatting our requests, sandboxing individual applications from one another, dealing with proxies, caching, and much more. In turn, with all of this complexity removed, our applications can focus on the application logic.
However, out of sight does not mean out of mind! As we saw, understanding the performance characteristics of TCP, HTTP, and mobile networks can help us build faster applications. Similarly, understanding how to optimize for the various browser networking APIs, protocols, and services can make a dramatic difference in performance of any application.
Web applications running in the browser do not manage the lifecycle of individual network sockets, and that’s a good thing. By deferring this work to the browser, we allow it to automate a number of critical performance optimizations, such as socket reuse, request prioritization and late binding, protocol negotiation, enforcing connection limits, and much more. In fact, the browser intentionally separates the request management lifecycle from socket management. This is a subtle but critical distinction.
Sockets are organized in pools (Figure 14-2), which are grouped by origin, and each pool enforces its own connection limits and security constraints. Pending requests are queued, prioritized, and then bound to individual sockets in the pool. Consequently, unless the server intentionally closes the connection, the same socket can be automatically reused across multiple requests!
Automatic socket pooling automates TCP connection reuse, which offers significant performance benefits; see Benefits of Keepalive Connections. However, that’s not all. This architecture also enables a number of additional optimization opportunities:
In short, the browser networking stack is our strategic ally on our quest to deliver high-performance applications. None of the functionality we have covered requires any work on our behalf! However, that’s not to say that we can’t help the browser. Design decisions in our applications that determine the network communication patterns, type and frequency of transfers, choice of protocols, and tuning and optimization of our server stacks play critical roles in the end performance of every application.
Deferring management of individual sockets serves another important purpose: it allows the browser to sandbox and enforce a consistent set of security and policy constraints on untrusted application code. For example, the browser does not permit direct API access to raw network sockets, as that would allow a malicious application to initiate arbitrary connections to any host—e.g., run a port scan, connect to a mail server and start sending unintended messages, and so on.
The previous list is not complete, but it highlights the principle of “least privilege” at work. The browser exposes only the APIs and resources that are necessary for the application code: the application supplies the data and URL, and the browser formats the request and handles the full lifecycle of each connection.
It is worth noting that there is no single “same-origin policy.” Instead, there is a set of related mechanisms that enforce restrictions on DOM access, cookie and session state management, networking, and other components of the browser.
A full discussion on browser security requires its own separate book. If you are curious, Michal Zalewski’s The Tangled Web: A Guide to Securing Modern Web Applications is a fantastic resource.
The best and fastest request is a request not made. Prior to dispatching a request, the browser automatically checks its resource cache, performs the necessary validation checks, and returns a local copy of the resources if the specified constraints are satisfied. Similarly, if a local resource is not available in cache, then a network request is made and the response is automatically placed in cache for subsequent access if permitted.
Managing an efficient and optimized resource cache is hard. Thankfully, the browser takes care of all of the complexity on our behalf, and all we need to do is ensure that our servers are returning the appropriate cache directives; see Cache Resources on the Client. You are providing Cache-Control, ETag, and Last-Modified response headers for all the resources on your pages, right?
Finally, an often-overlooked but critical function of the browser is to provide authentication, session, and cookie management. The browser maintains separate “cookie jars” for each origin, provides necessary application and server APIs to read and write new cookie, session, and authentication data and automatically appends and processes appropriate HTTP headers to automate the entire process on our behalf.
Walking up the ladder of provided network services we finally arrive at the application APIs and protocols. As we saw, the lower layers provide a wide array of critical services: socket and connection management, request and response processing, enforcement of various security policies, caching, and much more. Every time we initiate an HTTP or an XMLHttpRequest, a long-lived Server-Sent Events or WebSocket session, or open a WebRTC connection, we are interacting with some or all of these underlying services.
There is no one best protocol or API. Every nontrivial application will require a mix of different transports based on a variety of requirements: interaction with the browser cache, protocol overhead, message latency, reliability, type of data transfer, and more. Some protocols may offer low-latency delivery (e.g., Server-Sent Events, WebSocket), but may not meet other critical criteria, such as the ability to leverage the browser cache or support efficient binary transfers in all cases.
| XMLHttpRequest | Server-Sent Events | WebSocket | |
Request streaming | no | no | yes |
Response streaming | limited | yes | yes |
Framing mechanism | HTTP | event stream | binary framing |
Binary data transfers | yes | no (base64) | yes |
Compression | yes | yes | limited |
Application transport protocol | HTTP | HTTP | WebSocket |
Network transport protocol | TCP | TCP | TCP |
We are intentionally omitting WebRTC from this comparison, as its peer-to-peer delivery model offers a significant departure from XHR, SSE, and WebSocket protocols.
This comparison of high-level features is incomplete—that’s the subject of the following chapters—but serves as a good illustration of the many differences among each protocol. Understanding the pros, cons, and trade-offs of each, and matching them to the requirements of our applications, can make all the difference between a high-performance application and a consistently poor experience for the user.
XMLHttpRequest (XHR) is a browser-level API that enables the client to script data transfers via JavaScript. XHR made its first debut in Internet Explorer 5, became one of the key technologies behind the Asynchronous JavaScript and XML (AJAX) revolution, and is now a fundamental building block of nearly every modern web application.
XMLHTTP changed everything. It put the “D” in DHTML. It allowed us to asynchronously get data from the server and preserve document state on the client… The Outlook Web Access (OWA) team’s desire to build a rich Win32 like application in a browser pushed the technology into IE that allowed AJAX to become a reality.
— Jim Van Eaton Outlook Web Access: A catalyst for web evolution
Prior to XHR, the web page had to be refreshed to send or fetch any state updates between the client and server. With XHR, this workflow could be done asynchronously and under full control of the application JavaScript code. XHR is what enabled us to make the leap from building pages to building interactive web applications in the browser.
However, the power of XHR is not only that it enabled asynchronous communication within the browser, but also that it made it simple. XHR is an application API provided by the browser, which is to say that the browser automatically takes care of all the low-level connection management, protocol negotiation, formatting of HTTP requests, and much more:
Free from worrying about all the low-level details, our applications can focus on the business logic of initiating requests, managing their progress, and processing returned data from the server. The combination of a simple API and its ubiquitous availability across all the browsers makes XHR the “Swiss Army knife” of networking in the browser.
As a result, nearly every networking use case (scripted downloads, uploads, streaming, and even real-time notifications) can and have been built on top of XHR. Of course, this doesn’t mean that XHR is the most efficient transport in each case—in fact, as we will see, far from it—but it is nonetheless often used as a fallback transport for older clients, which may not have access to newer browser networking APIs. With that in mind, let’s take a closer look at the latest capabilities of XHR, its use cases, and performance do’s and don’ts.
An exhaustive analysis of the full XHR API and its capabilities is outside the scope of our discussion—our focus is on performance! Refer to the official W3C standard for an overview of the XMLHttpRequest API.
Despite its name, XHR was never intended to be tied to XML specifically. The XML prefix is a vestige of a decision to ship the first version of what became known as XHR as part of the MSXML library in Internet Explorer 5:
This was the good-old-days when critical features were crammed in just days before a release…I realized that the MSXML library shipped with IE and I had some good contacts over in the XML team who would probably help out—I got in touch with Jean Paoli who was running that team at the time and we pretty quickly struck a deal to ship the thing as part of the MSXML library. Which is the real explanation of where the name XMLHTTP comes from—the thing is mostly about HTTP and doesn’t have any specific tie to XML other than that was the easiest excuse for shipping it so I needed to cram XML into the name.
— Alex Hopmann The story of XMLHTTP
Mozilla modeled its own implementation of XHR against Microsoft’s and exposed it via the XMLHttpRequest interface. Safari, Opera, and other browsers followed, and XHR became a de facto standard in all major browsers—hence the name and why it stuck. In fact, the official W3C Working Draft specification for XHR was only published in 2006, well after XHR came into widespread use!
However, despite its popularity and key role in the AJAX revolution, the early versions of XHR provided limited capabilities: text-based-only data transfers, restricted support for handling uploads, and inability to handle cross-domain requests. To address these shortcomings, the “XMLHttpRequest Level 2” draft was published in 2008, which added a number of new features:
In 2011, “XMLHttpRequest Level 2” specification was merged with the original XMLHttpRequest working draft. Hence, while you will often find references to XHR version or level 1 and 2, these distinctions are no longer relevant; today, there is only one, unified XHR specification. In fact, all the new XHR2 features and capabilities are offered via the same XMLHttpRequest API: same interface, more features.
New XHR2 features are now supported by all the modern browsers; see caniuse.com/xhr2. Hence, whenever we refer to XHR, we are implicitly referring to the XHR2 standard.
XHR is a browser-level API that automatically handles myriad low-level details such as caching, handling redirects, content negotiation, authentication, and much more. This serves a dual purpose. First, it makes the application APIs much easier to work with, allowing us to focus on the business logic. But, second, it allows the browser to sandbox and enforce a set of security and policy constraints on the application code.
The XHR interface enforces strict HTTP semantics on each request: the application supplies the data and URL, and the browser formats the request and handles the full lifecycle of each connection. Similarly, while the XHR API allows the application to add custom HTTP headers (via the setRequestHeader() method), there are a number of protected headers that are off-limits to application code:
The browser will refuse to override any of the unsafe headers, which guarantees that the application cannot impersonate a fake user-agent, user, or the origin from where the request is being made. In fact, protecting the origin header is especially important, as it is the key piece of the “same-origin policy” applied to all XHR requests.
An “origin” is defined as a triple of application protocol, domain name, and port number—e.g., (http, example.com, 80) and (https, example.com, 443) are considered as different origins. For more details see The Web Origin Concept.
The motivation for the same-origin policy is simple: the browser stores user data, such as authentication tokens, cookies, and other private metadata, which cannot be leaked across different applications—e.g., without the same origin sandbox an arbitrary script on example.com could access and manipulate users’ data on thirdparty.com!
To address this specific problem, early versions of XHR were restricted to same-origin requests only, where the requesting origin had to match the origin of the requested resource: an XHR initiated from example.com could request another resource only from the same example.com origin. Alternatively, if the same origin precondition failed, then the browser would simply refuse to initiate the XHR request and raise an error.
However, while necessary, the same-origin policy also places severe restrictions on the usefulness of XHR: what if the server wants to offer a resource to a script running in a different origin? That’s where “Cross-Origin Resource Sharing” (CORS) comes in! CORS provides a secure opt-in mechanism for client-side cross-origin requests:
// script origin: (http, example.com, 80)
var xhr = new XMLHttpRequest();
xhr.open('GET', '/resource.js');
xhr.onload = function() { ... };
xhr.send();
var cors_xhr = new XMLHttpRequest();
cors_xhr.open('GET', 'http://thirdparty.com/resource.js');
cors_xhr.onload = function() { ... };
cors_xhr.send();
CORS requests use the same XHR API, with the only difference that the URL to the requested resource is associated with a different origin from where the script is being executed: in the previous example, the script is executed from (http, example.com, 80), and the second XHR request is accessing resource.js from (http, thirdparty.com, 80).
The opt-in authentication mechanism for the CORS request is handled at a lower layer: when the request is made, the browser automatically appends the protected Origin HTTP header, which advertises the origin from where the request is being made. In turn, the remote server is then able to examine the Origin header and decide if it should allow the request by returning an Access-Control-Allow-Origin header in its response:
=> Request GET /resource.js HTTP/1.1 Host: thirdparty.com Origin: http://example.com
In the preceding example, thirdparty.com decided to opt into cross-origin resource sharing with example.com by returning an appropriate access control header in its response. Alternatively, if it wanted to disallow access, it could simply omit the Access-Control-Allow-Origin header, and the client’s browser would automatically fail the sent request.
If the third-party server is not CORS aware, then the client request will fail, as the client always verifies the presence of the opt-in header. As a special case, CORS also allows the server to return a wildcard (Access-Control-Allow-Origin: *) to indicate that it allows access from any origin. However, think twice before enabling this policy!
With that, we are all done, right? Turns out, not quite, as CORS takes a number of additional security precautions to ensure that the server is CORS aware:
To enable cookies and HTTP authentication, the client must set an extra property (withCredentials) on the XHR object when making the request, and the server must also respond with an appropriate header (Access-Control-Allow-Credentials) to indicate that it is knowingly allowing the application to include private user data. Similarly, if the client needs to write or read custom HTTP headers or wants to use a “non-simple method” for the request, then it must first ask for permission from the third-party server by issuing a preflight request:
=> Preflight request OPTIONS /resource.js HTTP/1.1
The official W3C CORS specification defines when and where a preflight request must be used: “simple” requests can skip it, but there are a variety of conditions that will trigger it and add a minimum of a full roundtrip of network latency to verify permissions. The good news is, once a preflight request is made, it can be cached by the client to avoid the same verification on each request.
CORS is supported by all modern browsers; see caniuse.com/cors. For a deep dive on various CORS policies and implementation refer to the official W3C standard.
XHR can transfer both text-based and binary data. In fact, the browser offers automatic encoding and decoding for a variety of native data types, which allows the application to pass these types directly to XHR to be properly encoded, and vice versa, for the types to be automatically decoded by the browser:
ArrayBuffer
Blob
Document
JSON
Text
Either the browser can rely on the HTTP content-type negotiation to infer the appropriate data type (e.g., decode an application/json response into a JSON object), or the application can explicitly override the data type when initiating the XHR request:
var xhr = new XMLHttpRequest();
xhr.open('GET', '/images/photo.webp');
xhr.responseType = 'blob';
xhr.onload = function() {
if (this.status == 200) {
var img = document.createElement('img');
img.src = window.URL.createObjectURL(this.response);
img.onload = function() {
window.URL.revokeObjectURL(this.src);
}
document.body.appendChild(img);
}
};
xhr.send();
Note that we are transferring an image asset in its native format, without relying on base64 encoding, and adding an image element to the page without relying on data URIs. There is no network transmission overhead or encoding overhead when handling the received binary data in JavaScript! XHR API allows us to script efficient, dynamic applications, regardless of the data type, right from JavaScript.
The blob interface is part of the HTML5 File API and acts as an opaque reference for an arbitrary chunk of data (binary or text). By itself, a blob reference has limited functionality: you can query its size, MIME type, and split it into smaller blobs. However, its real role is to serve as an efficient interchange mechanism between various JavaScript APIs.
Uploading data via XHR is just as simple and efficient for all data types. In fact, the code is effectively the same, with the only difference that we also pass in a data object when calling send() on the XHR request. The rest is handled by the browser:
var xhr = new XMLHttpRequest();
xhr.open('POST','/upload');
xhr.onload = function() { ... };
xhr.send("text string");
var formData = new FormData();
formData.append('id', 123456);
formData.append('topic', 'performance');
var xhr = new XMLHttpRequest();
xhr.open('POST', '/upload');
xhr.onload = function() { ... };
xhr.send(formData);
var xhr = new XMLHttpRequest();
xhr.open('POST', '/upload');
xhr.onload = function() { ... };
var uInt8Array = new Uint8Array([1, 2, 3]);
xhr.send(uInt8Array.buffer);
The XHR send() method accepts one of DOMString, Document, FormData, Blob, File, or ArrayBuffer objects, automatically performs the appropriate encoding, sets the appropriate HTTP content-type, and dispatches the request. Need to send a binary blob or upload a file provided by the user? Simple: grab a reference to the object and pass it to XHR. In fact, with a little extra work, we can also split a large file into smaller chunks:
var blob = ...;
XHR does not support request streaming, which means that we must provide the full payload when calling send(). However, this example illustrates a simple application workaround: the file is split and uploaded in chunks via multiple XHR requests. This implementation pattern is by no means a replacement for a true request streaming API, but it is nonetheless a viable solution for some applications.
Network connectivity can be intermittent, and latency and bandwidth are highly variable. So how do we know if an XHR request has succeeded, timed out, or failed? The XHR object provides a convenient API for listening to progress events (Table 15-1), which indicate the current status of the request.
| Event type | Description | Times fired |
loadstart | Transfer has begun | once |
progress | Transfer is in progress | zero or more |
error | Transfer has failed | zero or once |
abort | Transfer is terminated | zero or once |
load | Transfer is successful | zero or once |
loadend | Transfer has finished | once |
Each XHR transfer begins with a loadstart and finishes with a loadend event, and in between, one or more additional events are fired to indicate the status of the transfer. Hence, to monitor progress the application can register a set of JavaScript event listeners on the XHR object:
var xhr = new XMLHttpRequest();
xhr.open('GET','/resource');
xhr.timeout = 5000;
xhr.addEventListener('load', function() { ... });
xhr.addEventListener('error', function() { ... });
var onProgressHandler = function(event) {
if(event.lengthComputable) {
var progress = (event.loaded / event.total) * 100;
...
}
}
xhr.upload.addEventListener('progress', onProgressHandler);
xhr.addEventListener('progress', onProgressHandler);
xhr.send();
Either the load or error event will fire once to indicate the final status of the XHR transfer, whereas the progress event can fire any number of times and provides a convenient API for tracking transfer status: we can compare the loaded attribute against total to estimate the amount of transferred data.
To estimate the amount of transferred data, the server must provide a content length in its response: we can’t estimate progress of chunked transfers, since by definition, the total size of the response is unknown.
Also, XHR requests do not have a default timeout, which means that a request can be “in progress” indefinitely. As a best practice, always set a meaningful timeout for your application and handle the error!
In some cases an application may need or want to process a stream of data incrementally: upload the data to the server as it becomes available on the client, or process the downloaded data as it arrives from the server. Unfortunately, while this is an important use case, today there is no simple, efficient, cross-browser API for XHR streaming:
Streaming has never been an official use case within the official XHR specification. As a result, short of manually splitting an upload into smaller, individual XHRs, there is no API for streaming data from client to server. Similarly, while the XHR2 specification does provide some ability to read a partial response from the server, the implementation is inefficient and very limited. That’s the bad news.
The good news is that there is hope on the horizon! Lack of streaming support as a first-class use case for XHR is a well-recognized limitation, and there is work in progress to address the problem:
Web applications should have the ability to acquire and manipulate data in a wide variety of forms, including as a sequence of data made available over time. This specification defines the basic representation for Streams, errors raised by Streams, and programmatic ways to read and create Streams.
— W3C Streams API
The combination of XHR and Streams API will enable efficient XHR streaming in the browser. However, the Streams API is still under active discussion, and is not yet available in any browser. So, with that, we’re stuck, right? Well, not quite. As we noted earlier, streaming uploads with XHR is not an option, but we do have limited support for streaming downloads with XHR:
var xhr = new XMLHttpRequest();
xhr.open('GET', '/stream');
xhr.seenBytes = 0;
xhr.onreadystatechange = function() {
if(xhr.readyState > 2) {
var newData = xhr.responseText.substr(xhr.seenBytes);
// process newData
xhr.seenBytes = xhr.responseText.length;
}
};
xhr.send();
This example will work in most modern browsers. However, performance is not great, and there are a large number of implementation caveats and gotchas:
In short, currently, XHR streaming is neither efficient nor convenient, and to make matters worse, the lack of a common specification also means that the implementations differ from browser to browser. As a result, at least until the Streams API is available, XHR is not a good fit for streaming.
No need to despair! While XHR may not meet the criteria, we do have other transports that are optimized for the streaming use case: Server-Sent Events offers a convenient API for streaming text-based data from server to client, and WebSocket offers efficient, bidirectional streaming for both binary and text-based data.
XHR enables a simple and efficient way to synchronize client updates with the server: whenever necessary, an XHR request is dispatched by the client to update the appropriate data on the server. However, the same problem, but in reverse, is much harder. If data is updated on the server, how does the server notify the client?
HTTP does not provide any way for the server to initiate a new connection to the client. As a result, to receive real-time notifications, the client must either poll the server for updates or leverage a streaming transport to allow the server to push new notifications as they become available. Unfortunately, as we saw in the preceding section, support for XHR streaming is limited, which leaves us with XHR polling.
“Real-time” has different meanings for different applications: some applications demand submillisecond overhead, while others may be just fine with delays measured in minutes. To determine the optimal transport, first define clear latency and overhead targets for your application!
One of the simplest strategies to retrieve updates from the server is to have the client do a periodic check: the client can initiate a background XHR request on a periodic interval (poll the server) to check for updates. If new data is available on the server, then it is returned in the response, and otherwise the response is empty.
Polling is simple to implement but frequently is also very inefficient. The choice of the polling interval is critical: long polling intervals translate to delayed delivery of updates, whereas short intervals result in unnecessary traffic and high overhead both for the client and the server. Let’s consider the simplest possible example:
function checkUpdates(url) {
var xhr = new XMLHttpRequest();
xhr.open('GET', url);
xhr.onload = function() { ... };
xhr.send();
}
setInterval(function() { checkUpdates('/updates') }, 60000);
What is the optimal polling interval? There isn’t one. The frequency depends on the requirements of the application, and there is an inherent trade-off between efficiency and message latency. As a result, polling is a good fit for applications where polling intervals are long, new events are arriving at a predictable rate, and the transferred payloads are large. This combination offsets the extra HTTP overhead and minimizes message delivery delays.
To illustrate the trade-off between latency and overhead of XHR polling, let’s consider a simple email application that is using XHR polling to check for message updates on the server. The implementation is as follows:
An average HTTP 1.x request adds 800 bytes of request and response overhead (see Measuring and Controlling Protocol Overhead). Because the client is logged in, we will also have an extra authentication cookie and the message ID; let’s say this adds another 50 bytes. Hence, a request that returns no new messages will incur 850 bytes! Now imagine we have 10,000 clients, all polling on a 60-second interval:
Each client sends 850 bytes of data on each request, which translates to 167 requests per second and a sustained rate of 1.13 Mbps of ingress throughput on the server! And that’s a constant rate without actually delivering any new messages to any of the clients.
Is the 30-second delay too high? We can decrease the polling interval, but in doing so, we would incur higher throughput and overhead: the same 10,000 clients, but on a 1-second interval, would generate over 60 Mbps of throughput! In short, unless the polling intervals are long, polling is expensive.
The challenge with periodic polling is that there is potential for many unnecessary and empty checks. With that in mind, what if we made a slight modification (Figure 15-1) to the polling workflow: instead of returning an empty response when no updates are available, could we keep the connection idle until an update is available?
The technique of leveraging a long-held HTTP request (“a hanging GET”) to allow the server to push data to the browser is commonly known as “Comet.” However, you may also encounter it under other names, such as “reverse AJAX,” “AJAX push,” and “HTTP push.”
By holding the connection open until an update is available (long-polling), data can be sent immediately to the client once it becomes available on the server. As a result, long-polling offers the best-case scenario for message latency, and it also eliminates empty checks, which reduces the number of XHR requests and the overall overhead of polling. Once an update is delivered, the long-poll request is finished and the client can issue another long-poll request and wait for the next available message:
function checkUpdates(url) {
var xhr = new XMLHttpRequest();
xhr.open('GET', url);
xhr.onload = function() {
...
checkUpdates('/updates');
};
xhr.send();
}
checkUpdates('/updates');
With that, is long-polling always a better choice than periodic polling? Unless the message arrival rate is known and constant, long-polling will always deliver better message latency. If that’s the primary criteria, then long-polling is the winner.
On the other hand, the overhead discussion requires a more nuanced view. First, note that each delivered message still incurs the same HTTP overhead; each new message is a standalone HTTP request. However, if the message arrival rate is high, then long-polling will issue more XHR requests than periodic polling!
Long-polling dynamically adapts to the message arrival rate by minimizing message latency, which is a behavior you may or may not want. If there is some tolerance for message latency, then polling may be a more efficient transport—e.g., if the update rate is high, then polling provides a simple “message aggregation” mechanism, which can reduce the number of requests and improve battery life on mobile handsets.
In practice, not all messages have the same priority or latency requirements. As a result, you may want to consider a mix of strategies: aggregate low-priority updates on the server, and trigger immediate delivery for high priority updates; see Nagle and Efficient Server Push.
XMLHttpRequest is what enabled us to make the leap from building pages to building interactive web applications in the browser. First, it enabled asynchronous communication within the browser, but just as importantly, it also made the process simple. Dispatching and controlling a scripted HTTP request takes just a few lines of JavaScript code, and the browser handles all the rest:
As such, XHR is a versatile and a high-performance transport for any transfers that follow the HTTP request-response cycle. Need to fetch a resource that requires authentication, should be compressed while in transfer, and should be cached for future lookups? The browser takes care of all of this and more, allowing us to focus on the application logic!
However, XHR also has its limitations. As we saw, streaming has never been an official use case in the XHR standard, and the support is limited: streaming with XHR is neither efficient nor convenient. Different browsers have different behaviors, and efficient binary streaming is impossible. In short, XHR is not a good fit for streaming.
Similarly, there is no one best strategy for delivering real-time updates with XHR. Periodic polling incurs high overhead and message latency delays. Long-polling delivers low latency but still has the same per-message overhead; each message is its own HTTP request. To have both low latency and low overhead, we need XHR streaming!
As a result, while XHR is a popular mechanism for “real-time” delivery, it may not be the best-performing transport for the job. Modern browsers support both simpler and more efficient options, such as Server-Sent Events and WebSocket. Hence, unless you have a specific reason why XHR polling is required, use them.
Server-Sent Events enables efficient server-to-client streaming of text-based event data—e.g., real-time notifications or updates generated on the server. To meet this goal, SSE introduces two components: a new EventSource interface in the browser, which allows the client to receive push notifications from the server as DOM events, and the “event stream” data format, which is used to deliver the individual updates.
The combination of the EventSource API in the browser and the well-defined event stream data format is what makes SSE both an efficient and an indispensable tool for handling real-time data in the browser:
Under the hood, SSE provides an efficient, cross-browser implementation of XHR streaming; the actual delivery of the messages is done over a single, long-lived HTTP connection. However, unlike dealing XHR streaming on our own, the browser handles all the connection management and message parsing, allowing our applications to focus on the business logic! In short, SSE makes working with real-time data simple and efficient. Let’s take a look under the hood.
The EventSource interface abstracts all the low-level connection establishment and message parsing behind a simple browser API. To get started, we simply need to specify the URL of the SSE event stream resource and register the appropriate JavaScript event listeners on the object:
var source = new EventSource("/path/to/stream-url");
source.onopen = function () { ... };
source.onerror = function () { ... };
source.addEventListener("foo", function (event) {
processFoo(event.data);
});
source.onmessage = function (event) {
log_message(event.id, event.data);
if (event.id == "CLOSE") {
source.close();
}
}
Open new SSE connection to stream endpoint
Optional callback, invoked when connection is established
Optional callback, invoked if the connection fails
Subscribe to event of type “foo”; invoke custom logic
Subscribe to all events without an explicit type
Close SSE connection if server sends a “CLOSE” message ID
EventSource can stream event data from remote origins by leveraging the same CORS permission and opt-in workflow as a regular XHR.
That’s all there is to it for the client API. The implementation logic is handled for us: the connection is negotiated on our behalf, received data is parsed incrementally, message boundaries are identified, and finally a DOM event is fired by the browser. EventSource interface allows the application to focus on the business logic: open new connection, process received event notifications, terminate stream when finished.
SSE provides a memory-efficient implementation of XHR streaming. Unlike a raw XHR connection, which buffers the full received response until the connection is dropped, an SSE connection can discard processed messages without accumulating all of them in memory.
As icing on the cake, the EventSource interface also provides auto-reconnect and tracking of the last seen message: if the connection is dropped, EventSource will automatically reconnect to the server and optionally advertise the ID of the last seen message, such that the stream can be resumed and lost messages can be retransmitted.
How does the browser know the ID, type, and boundary of each message? This is where the event stream protocol comes in. The combination of a simple client API and a well-defined data format is what allows us to offload the bulk of the work to the browser. The two go hand in hand, even though the low-level data protocol is completely transparent to the application in the browser.
An SSE event stream is delivered as a streaming HTTP response: the client initiates a regular HTTP request, the server responds with a custom “text/event-stream” content-type, and then streams the UTF-8 encoded event data. However, even that sounds too complicated, so an example is in order:
=> Request GET /stream HTTP/1.1
Client connection initiated via EventSource interface
Server response with “text/event-stream” content-type
Server sets client reconnect interval (15s) if the connection drops
Simple text event with no message type
JSON payload with no message type
Simple text event of type “foo”
Multiline event with message ID and type
Simple text event with optional ID
The event-stream protocol is trivial to understand and implement:
On the receiving end, the EventSource interface parses the incoming stream by looking for newline separators, extracts the payload from data fields, checks for optional ID and type, and finally dispatches a DOM event to notify the application. If a type is present, then a custom DOM event is fired, and otherwise the generic “onmessage” callback is invoked; see EventSource API for both cases.
Finally, in addition to automatic event parsing, SSE provides built-in support for reestablishing dropped connections, as well as recovery of messages the client may have missed while disconnected. By default, if the connection is dropped, then the browser will automatically reestablish the connection. The SSE specification recommends a 2–3 second delay, which is a common default for most browsers, but the server can also set a custom interval at any point by sending a retry command to the client.
Similarly, the server can also associate an arbitrary ID string with each message. The browser automatically remembers the last seen ID and will automatically append a “Last-Event-ID” HTTP header with the remembered value when issuing a reconnect request. Here’s an example:
(existing SSE connection) retry: 4500
The client application does not need to provide any extra logic to reestablish the connection or remember the last seen event ID. The entire workflow is handled by the browser, and we rely on the server to handle the recovery. Specifically, depending on the requirements of the application and the data stream, the server can implement several different strategies:
The exact implementation details of how far back the messages are persisted are, of course, specific to the requirements of the application. Further, note that the ID is an optional event stream field. Hence, the server can also choose to checkpoint specific messages or milestones in the delivered event stream. In short, evaluate your requirements, and implement the appropriate logic on the server.
SSE is a high-performance transport for server-to-client streaming of text-based real-time data: messages can be pushed the moment they become available on the server (low latency), there is minimum message overhead (long-lived connection, event-stream protocol, and gzip compression), the browser handles all the message parsing, and there are no unbounded buffers. Add to that a convenient EventSource API with auto-reconnect and message notifications as DOM events, and SSE becomes an indispensable tool for working with real-time data!
There are two key limitations to SSE. First, it is server-to-client only and hence does not address the request streaming use case—e.g., streaming a large upload to the server. Second, the event-stream protocol is specifically designed to transfer UTF-8 data: binary streaming, while possible, is inefficient.
Having said that, the UTF-8 limitation can often be resolved at the application layer: SSE delivers a notification to the application about a new binary asset available on the server, and the application dispatches an XHR request to fetch it. While this incurs an extra roundtrip of latency, it also has the benefit of leveraging the numerous services provided by the XHR: response caching, transfer-encoding (compression), and so on. If an asset is streamed, it cannot be cached by the browser cache.
Real-time push, just as polling, can have a large negative impact on battery life. First, consider batching messages to avoid waking up the radio. Second, eliminate unnecessary keepalives; an SSE connection is not “dropped” while the radio is idle. For more details, see Eliminate Periodic and Inefficient Data Transfers.
WebSocket enables bidirectional, message-oriented streaming of text and binary data between client and server. It is the closest API to a raw network socket in the browser. Except a WebSocket connection is also much more than a network socket, as the browser abstracts all the complexity behind a simple API and provides a number of additional services:
WebSocket is one of the most versatile and flexible transports available in the browser. The simple and minimal API enables us to layer and deliver arbitrary application protocols between client and server—anything from simple JSON payloads to custom binary message formats—in a streaming fashion, where either side can send data at any time.
However, the trade-off with custom protocols is that they are, well, custom. The application must account for missing state management, compression, caching, and other services otherwise provided by the browser. There are always design constraints and performance trade-offs, and leveraging WebSocket is no exception. In short, WebSocket is not a replacement for HTTP, XHR, or SSE, and for best performance it is critical that we leverage the strengths of each transport.
WebSocket is a set of multiple standards: the WebSocket API is defined by the W3C, and the WebSocket protocol (RFC 6455) and its extensions are defined by the HyBi Working Group (IETF).
The WebSocket API provided by the browser is remarkably small and simple. Once again, all the low-level details of connection management and message processing are taken care of by the browser. To initiate a new connection, we need the URL of a WebSocket resource and a few application callbacks:
var ws = new WebSocket('wss://example.com/socket');
ws.onerror = function (error) { ... }
ws.onclose = function () { ... }
ws.onopen = function () {
ws.send("Connection established. Hello server!");
}
ws.onmessage = function(msg) {
if(msg.data instanceof Blob) {
processBlob(msg.data);
} else {
processText(msg.data);
}
}
Open a new secure WebSocket connection (wss)
Optional callback, invoked if a connection error has occurred
Optional callback, invoked when the connection is terminated
Optional callback, invoked when a WebSocket connection is established
Client-initiated message to the server
A callback function invoked for each new message from the server
Invoke binary or text processing logic for the received message
The API speaks for itself. In fact, it should look very similar to the EventSource API we saw in the preceding chapter. This is intentional, as WebSocket offers similar and extended functionality. Having said that, there are a number of important differences as well. Let’s take a look at them one by one.
The WebSocket resource URL uses its own custom scheme: ws for plain-text communication (e.g., ws://example.com/socket), and wss when an encrypted channel (TCP+TLS) is required. Why the custom scheme, instead of the familiar http?
The primary use case for the WebSocket protocol is to provide an optimized, bi-directional communication channel between applications running in the browser and the server. However, the WebSocket wire protocol can be used outside the browser and could be negotiated via a non-HTTP exchange. As a result, the HyBi Working Group chose to adopt a custom URL scheme.
Despite the non-HTTP negotiation option enabled by the custom scheme, in practice there are no existing standards for alternative handshake mechanisms for establishing a WebSocket session.
WebSocket communication consists of messages and application code and does not need to worry about buffering, parsing, and reconstructing received data. For example, if the server sends a 1 MB payload, the application’s onmessage callback will be called only when the entire message is available on the client.
Further, the WebSocket protocol makes no assumptions and places no constraints on the application payload: both text and binary data are fair game. Internally, the protocol tracks only two pieces of information about the message: the length of payload as a variable-length field and the type of payload to distinguish UTF-8 from binary transfers.
When a new message is received by the browser, it is automatically converted to a DOMString object for text-based data, or a Blob object for binary data, and then passed directly to the application. The only other option, which acts as performance hint and optimization for the client, is to tell the browser to convert the received binary data to an ArrayBuffer instead of Blob:
var ws = new WebSocket('wss://example.com/socket');
ws.binaryType = "arraybuffer";
ws.onmessage = function(msg) {
if(msg.data instanceof ArrayBuffer) {
processArrayBuffer(msg.data);
} else {
processText(msg.data);
}
}
User agents can use this as a hint for how to handle incoming binary data: if the attribute is set to “blob”, it is safe to spool it to disk, and if it is set to “arraybuffer”, it is likely more efficient to keep the data in memory. Naturally, user agents are encouraged to use more subtle heuristics to decide whether to keep incoming data in memory or not…
— The WebSocket API W3C Candidate Recommendation
A Blob object represents a file-like object of immutable, raw data. If you do not need to modify the data and do not need to slice it into smaller chunks, then it is the optimal format—e.g., you can pass the entire Blob object to an image tag (see the example in Downloading Data with XHR). On the other hand, if you need to perform additional processing on the binary data, then ArrayBuffer is likely the better fit.
Once a WebSocket connection is established, the client can send and receive UTF-8 and binary messages at will. WebSocket offers a bidirectional communication channel, which allows message delivery in both directions over the same TCP connection:
var ws = new WebSocket('wss://example.com/socket');
ws.onopen = function () {
socket.send("Hello server!");
socket.send(JSON.stringify({'msg': 'payload'}));
var buffer = new ArrayBuffer(128);
socket.send(buffer);
var intview = new Uint32Array(buffer);
socket.send(intview);
var blob = new Blob([buffer]);
socket.send(blob);
}
The WebSocket API accepts a DOMString object, which is encoded as UTF-8 on the wire, or one of ArrayBuffer, ArrayBufferView, or Blob objects for binary transfers. However, note that the latter binary options are simply an API convenience: on the wire, a WebSocket frame is either marked as binary or text via a single bit. Hence, if the application, or the server, need other content-type information about the payload, then they must use an additional mechanism to communicate this data.
The send() method is asynchronous: the provided data is queued by the client, and the function returns immediately. As a result, especially when transferring large payloads, do not mistake the fast return for a signal that the data has been sent! To monitor the amount of data queued by the browser, the application can query the bufferedAmount attribute on the socket:
var ws = new WebSocket('wss://example.com/socket');
ws.onopen = function () {
subscribeToApplicationUpdates(function(evt) {
if (ws.bufferedAmount == 0)
ws.send(evt.data);
});
};
The preceding example attempts to send application updates to the server, but only if the previous messages have been drained from the client’s buffer. Why bother with such checks? All WebSocket messages are delivered in the exact order in which they are queued by the client. As a result, a large backlog of queued messages, or even a single large message, will delay delivery of messages queued behind it—head-of-line blocking!
To work around this problem, the application can split large messages into smaller chunks, monitor the bufferedAmount value carefully to avoid head-of-line blocking, and even implement its own priority queue for pending messages instead of blindly queuing them all on the socket.
WebSocket protocol makes no assumptions about the format of each message: a single bit tracks whether the message contains text or binary data, such that it can be efficiently decoded by the client and server, but otherwise the message contents are opaque.
Further, unlike HTTP or XHR requests, which communicate additional metadata via HTTP headers of each request and response, there is no such equivalent mechanism for a WebSocket message. As a result, if additional metadata about the message is required, then the client and server must agree to implement their own subprotocol to communicate this data:
This list is just a small sample of possible strategies. The flexibility and low overhead of a WebSocket message come at the cost of extra application logic. However, message serialization and management of metadata are only part of the problem! Once we determine the serialization format for our messages, how do we ensure that both client and server understand each other, and how do we keep them in sync?
Thankfully, WebSocket provides a simple and convenient subprotocol negotiation API to address the second problem. The client can advertise which protocols it supports to the server as part of its initial connection handshake:
var ws = new WebSocket('wss://example.com/socket',
['appProtocol', 'appProtocol-v2']);
ws.onopen = function () {
if (ws.protocol == 'appProtocol-v2') {
...
} else {
...
}
}
As the preceding example illustrates, the WebSocket constructor accepts an optional array of subprotocol names, which allows the client to advertise the list of protocols it understands or is willing to use for this connection. The specified list is sent to the server, and the server is allowed to pick one of the protocols advertised by the client.
If the subprotocol negotiation is successful, then the onopen callback is fired on the client, and the application can query the protocol attribute on the WebSocket object to determine the chosen protocol. On the other hand, if the server does not support any of the client protocols advertised by the client, then the WebSocket handshake is incomplete: the onerror callback is invoked, and the connection is terminated.
The WebSocket wire protocol (RFC 6455) developed by the HyBi Working Group consists of two high-level components: the opening HTTP handshake used to negotiate the parameters of the connection and a binary message framing mechanism to allow for low overhead, message-based delivery of both text and binary data.
The WebSocket Protocol attempts to address the goals of existing bidirectional HTTP technologies in the context of the existing HTTP infrastructure; as such, it is designed to work over HTTP ports 80 and 443… However, the design does not limit WebSocket to HTTP, and future implementations could use a simpler handshake over a dedicated port without reinventing the entire protocol.
— WebSocket Protocol RFC 6455
WebSocket protocol is a fully functional, standalone protocol that can be used outside the browser. Having said that, its primary application is as a bidirectional transport for browser-based applications.
Client and server WebSocket applications communicate via a message-oriented API: the sender provides an arbitrary UTF-8 or binary payload, and the receiver is notified of its delivery when the entire message is available. To enable this, WebSocket uses a custom binary framing format (Figure 17-1), which splits each application message into one or more frames, transports them to the destination, reassembles them, and finally notifies the receiver once the entire message has been received.
The decision to fragment an application message into multiple frames is made by the underlying implementation of the client and server framing code. Hence, the applications remain blissfully unaware of the individual WebSocket frames or how the framing is performed. Having said that, it is still useful to understand the highlights of how each WebSocket frame is represented on the wire:
Payload length is represented as a variable-length field:
The payload of all client-initiated frames is masked using the value specified in the frame header: this prevents malicious scripts executing on the client from performing a cache poisoning attack against intermediaries that may not understand the WebSocket protocol. For full details of this attack, refer to “Talking to Yourself for Fun and Profit”, presented at W2SP 2011.
As a result, each server-sent WebSocket frame incurs 2–10 bytes of framing overhead. The client must also send a masking key, which adds an extra 4 bytes to the header, resulting in 6–14 bytes over overhead. No other metadata, such as header fields or other information about the payload, is available: all WebSocket communication is performed by exchanging frames that treat the payload as an opaque blob of application data.
WebSocket specification allows for protocol extensions: the wire format and the semantics of the WebSocket protocol can be extended with new opcodes and data fields. While somewhat unusual, this is a very powerful feature, as it allows the client and server to implement additional functionality on top of the base WebSocket framing layer without requiring any intervention or cooperation from the application code.
What are some examples of WebSocket protocol extensions? The HyBi Working Group, which is responsible for the development of the WebSocket specification, lists two official extensions in development:
As we noted earlier, each WebSocket connection requires a dedicated TCP connection, which is inefficient. Multiplexing extension addresses this problem by extending each WebSocket frame with an additional “channel ID” to allow multiple virtual WebSocket channels to share a single TCP connection.
Similarly, the base WebSocket specification provides no mechanism or provisions for compression of transferred data: each frame carries payload data as provided by the application. As a result, while this may not be a problem for optimized binary data structures, this can result in high byte transfer overhead unless the application implements its own data compression and decompression logic. In effect, compression extension enables an equivalent of transfer-encoding negotiation provided by HTTP.
To enable one or more extensions, the client must advertise them in the initial Upgrade handshake, and the server must select and acknowledge the extensions that will be used for the lifetime of the negotiated connection. For a hands-on example, let’s now take a closer look at the Upgrade sequence.
The WebSocket protocol delivers a lot of powerful features: message-oriented communication, its own binary framing layer, subprotocol negotiation, optional protocol extensions, and more. As a result, before any messages can be exchanged, the client and server must negotiate the appropriate parameters to establish the connection.
Leveraging HTTP to perform the handshake offers several advantages. First, it makes WebSockets compatible with existing HTTP infrastructure: WebSocket servers can run on port 80 and 443, which are frequently the only open ports for the client. Second, it allows us to reuse and extend the HTTP Upgrade flow with custom WebSocket headers to perform the negotiation:
Sec-WebSocket-Version
Sec-WebSocket-Key
Sec-WebSocket-Accept
Sec-WebSocket-Protocol
Sec-WebSocket-Extensions
With that, we now have all the necessary pieces to perform an HTTP Upgrade and negotiate a new WebSocket connection between the client and server:
GET /socket HTTP/1.1 Host: thirdparty.com Origin: http://example.com Connection: Upgrade Upgrade: websocket
Just like any other client-initiated connection in the browser, WebSocket requests are subject to the same-origin policy: the browser automatically appends the Origin header to the upgrade handshake, and the remote server can use CORS to accept or deny the cross origin request; see Cross-Origin Resource Sharing (CORS). To complete the handshake, the server must return a successful “Switching Protocols” response and confirm the selected options advertised by the client:
HTTP/1.1 101 Switching Protocols
All RFC6455-compatible WebSocket servers use the same algorithm to compute the answer to the client challenge: the contents of the Sec-WebSocket-Key are concatenated with a unique GUID string defined in the standard, a SHA1 hash is computed, and the resulting string is base-64 encoded and sent back to the client.
At a minimum, a successful WebSocket handshake must contain the protocol version and an auto-generated challenge value sent by the client, followed by a 101 HTTP response code (Switching Protocols) from the server with a hashed challenge-response to confirm the selected protocol version:
Sec-WebSocket-Version and Sec-WebSocket-Key.
Sec-WebSocket-Accept.
Sec-WebSocket-Protocol.
Sec-WebSocket-Protocol. If the server does not support any, then the connection is aborted.
Sec-WebSocket-Extensions.
Sec-WebSocket-Extensions. If no extensions are provided, then the connection proceeds without them.
Finally, once the preceding handshake is complete, and if the handshake is successful, the connection can now be used as a two-way communication channel for exchanging WebSocket messages. From here on, there is no other explicit HTTP communication between the client and server, and the WebSocket protocol takes over.
WebSocket API provides a simple interface for bidirectional, message-oriented streaming of text and binary data between client and server: pass in a WebSocket URL to the constructor, set up a few JavaScript callback functions, and we are up and running—the rest is handled by the browser. Add to that the WebSocket protocol, which offers binary framing, extensibility, and subprotocol negotiation, and WebSocket becomes a perfect fit for delivering custom application protocols in the browser.
However, just as with any discussion on performance, while the implementation complexity of the WebSocket protocol is hidden from the application, it nonetheless has important performance implications for how and when WebSocket should be used. WebSocket is not a replacement for XHR or SSE, and for best performance it is critical that we leverage the strengths of each transport!
Refer to XHR Use Cases and Performance and SSE Use Cases and Performance for a review of the performance characteristics of each transport.
WebSocket is the only transport that allows bidirectional communication over the same TCP connection (Figure 17-2): the client and server can exchange messages at will. As a result, WebSocket provides low latency delivery of text and binary application data in both directions.
Once a WebSocket connection is established, the client and server exchange data via the WebSocket protocol: application messages are split into one or more frames, each of which adds from 2 to 14 bytes of overhead. Further, because the framing is done via a custom binary format, both UTF-8 and binary application data can be efficiently encoded via the same mechanism. How does that compare with XHR and SSE?
Keep in mind that these overhead numbers do not include the overhead of IP, TCP, and TLS framing, which add 60–100 bytes of combined overhead per message, regardless of the application protocol; see TLS Record Size.
Every XHR request can negotiate the optimal transfer encoding format (e.g., gzip for text-based data), via regular HTTP negotiation. Similarly, because SSE is restricted to UTF-8–only transfers, the event stream data can be efficiently compressed by applying gzip across the entire session.
With WebSocket, the situation is more complex: WebSocket can transfer both text and binary data, and as a result it doesn’t make sense to compress the entire session. The binary payloads may be compressed already! As a result, WebSocket must implement its own compression mechanism and selectively apply it to each message.
The good news is the HyBi working group is developing the per-message compression extension for the WebSocket protocol. However, it is not yet available in any of the browsers. As a result, unless the application implements its own compression logic by carefully optimizing its binary payloads (see Decoding Binary Data with JavaScript) and implementing its own compression logic for text-based messages, it may incur high byte overhead on the transferred data!
Chrome and some WebKit-based browsers support an older revision (per-frame compression) of the compression extension to the WebSocket protocol; see WebSocket Multiplexing and Compression in the Wild.
The browser is optimized for HTTP data transfers: it understands the protocol, and it provides a wide array of services, such as authentication, caching, compression, and much more. As a result, XHR requests inherit all of this functionality for free.
By contrast, streaming allows us to deliver custom protocols between client and server, but at the cost of bypassing many of the services provided by the browser: the initial HTTP handshake may be able to perform some negotiation of the parameters of the connection, but once the session is established, all further data streamed between the client and server is opaque to the browser. As a result, the flexibility of delivering a custom protocol also has its downsides, and the application may have to implement its own logic to fill in the missing gaps: caching, state management, delivery of message metadata, and so on!
HTTP is optimized for short and bursty transfers. As a result, many of the servers, proxies, and other intermediaries are often configured to aggressively timeout idle HTTP connections, which, of course, is exactly what we don’t want to see for long-lived WebSocket sessions. To address this, there are three pieces to consider:
We have no control over the policy of the client’s network. In fact, some networks may block WebSocket traffic entirely, which is why you may need a fallback strategy. Similarly, we don’t have control over the proxies on the external network. However, this is where TLS may help! By tunneling over a secure end-to-end connection, WebSocket traffic can bypass all the intermediate proxies.
Using TLS does not prevent the intermediary from timing out an idle TCP connection. However, in practice, it significantly increases the success rate of negotiating the WebSocket session and often also helps to extend the connection timeout intervals.
Finally, there is the infrastructure that we deploy and manage ourselves, which also often requires attention and tuning. As easy as it is to blame the client or external networks, all too often the problem is close to home. Each load-balancer, router, proxy, and web server in the serving path must be tuned to allow long-lived connections.
For example, Nginx 1.3.13+ can proxy WebSocket traffic, but defaults to aggressive 60-second timeouts! To increase the limit, we must explicitly define the longer timeouts:
location /websocket {
proxy_pass http://backend;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_read_timeout 3600;
proxy_send_timeout 3600;
}
Similarly, it is not uncommon to have a load balancer, such as HAProxy, in front of one or more Nginx servers. Not surprisingly, we need to apply similar explicit configuration here as well—e.g., for HAProxy:
defaults http
timeout connect 30s
timeout client 30s
timeout server 30s
timeout tunnel 1h
The gotcha with the preceding example is the extra “tunnel” timeout. In HAProxy the connect, client, and server timeouts are applied only to the initial HTTP Upgrade handshake, but once the upgrade is complete, the timeout is controlled by the tunnel value.
Nginx and HAProxy are just two of hundreds of different servers, proxies, and load balancers running in our data centers. We can’t enumerate all the configuration possibilities in these pages. The previous examples are just an illustration that most infrastructure requires custom configuration to handle long-lived sessions. Hence, before implementing application keepalives, double-check your infrastructure first.
Long-lived and idle sessions occupy memory and socket resources on all the intermediate servers. Hence, short timeouts are often justified as a security, resource, and operational precaution. Deploying WebSocket, SSE, and HTTP/2, each of which relies on long-lived sessions, brings its own class of new operational challenges.
Deploying a high-performance WebSocket service requires careful tuning and consideration, both on the client and on the server. A short list of criteria to put on the agenda:
Last, but definitely not least, optimize for mobile! Real-time push can be a costly performance anti-pattern on mobile handsets, where battery life is always at a premium. That’s not to say that WebSocket should not be used on mobile. To the contrary, it can be a highly efficient transport, but make sure to account for its requirements:
Web Real-Time Communication (WebRTC) is a collection of standards, protocols, and JavaScript APIs, the combination of which enables peer-to-peer audio, video, and data sharing between browsers (peers). Instead of relying on third-party plug-ins or proprietary software, WebRTC turns real-time communication into a standard feature that any web application can leverage via a simple JavaScript API.
Delivering rich, high-quality, RTC applications such as audio and video teleconferencing and peer-to-peer data exchange requires a lot of new functionality in the browser: audio and video processing capabilities, new application APIs, and support for half a dozen new network protocols. Thankfully, the browser abstracts most of this complexity behind three primary APIs:
All it takes is a dozen lines of JavaScript code, and any web application can enable a rich teleconferencing experience with peer-to-peer data transfers. That’s the promise and the power of WebRTC! However, the listed APIs are also just the tip of the iceberg: signaling, peer discovery, connection negotiation, security, and entire layers of new protocols are just a few components required to bring it all together.
Not surprisingly, the architecture and the protocols powering WebRTC also determine its performance characteristics: connection setup latency, protocol overhead, and delivery semantics, to name a few. In fact, unlike all other browser communication, WebRTC transports its data over UDP. However, UDP is also just a starting point. It takes a lot more than raw UDP to make real-time communication in the browser a reality. Let’s take a closer look.
WebRTC is already enabled for 1B+ users: the latest Chrome and Firefox browsers provide WebRTC support to all of their users! Having said that, WebRTC is also under active construction, both at the browser API level and at the transport and protocol levels. As a result, the specific APIs and protocols discussed in the following chapters may still change in the future.
Enabling real-time communication in the browser is an ambitious undertaking, and arguably, one of the most significant additions to the web platform since its very beginning. WebRTC breaks away from the familiar client-to-server communication model, which results in a full re-engineering of the networking layer in the browser, and also brings a whole new media stack, which is required to enable efficient, real-time processing of audio and video.
As a result, the WebRTC architecture consists of over a dozen different standards, covering both the application and browser APIs, as well as many different protocols and data formats required to make it work:
WebRTC is not a blank-slate standard. While its primary purpose is to enable real-time communication between browsers, it is also designed such that it can be integrated with existing communication systems: voice over IP (VOIP), various SIP clients, and even the public switched telephone network (PSTN), just to name a few. The WebRTC standards do not define any specific interoperability requirements, or APIs, but they do try to reuse the same concepts and protocols where possible.
In other words, WebRTC is not only about bringing real-time communication to the browser, but also about bringing all the capabilities of the Web to the telecommunications world—a $4.7 trillion industry in 2012! Not surprisingly, this is a significant development and one that many existing telecom vendors, businesses, and startups are following closely. WebRTC is much more than just another browser API.
Enabling a rich teleconferencing experience in the browser requires that the browser be able to access the system hardware to capture both audio and video—no third-party plug-ins or custom drivers, just a simple and a consistent API. However, raw audio and video streams are also not sufficient on their own: each stream must be processed to enhance quality, synchronized, and the output bitrate must adjust to the continuously fluctuating bandwidth and latency between the clients.
On the receiving end, the process is reversed, and the client must decode the streams in real-time and be able to adjust to network jitter and latency delays. In short, capturing and processing audio and video is a complex problem. However, the good news is that WebRTC brings fully featured audio and video engines to the browser (Figure 18-1), which take care of all the signal processing, and more, on our behalf.
The full implementation and technical details of the audio and video engines is easily a topic for a dedicated book, and is outside the scope of our discussion. To learn more, head to http://www.webrtc.org.
The acquired audio stream is processed for noise reduction and echo cancellation, then automatically encoded with one of the optimized narrowband or wideband audio codecs. Finally, a special error-concealment algorithm is used to hide the negative effects of network jitter and packet loss—that’s just the highlights! The video engine performs similar processing by optimizing image quality, picking the optimal compression and codec settings, applying jitter and packet-loss concealment, and more.
All of the processing is done directly by the browser, and even more importantly, the browser dynamically adjusts its processing pipeline to account for the continuously changing parameters of the audio and video streams and networking conditions. Once all of this work is done, the web application receives the optimized media stream, which it can then output to the local screen and speakers, forward to its peers, or post-process using one of the HTML5 media APIs!
The Media Capture and Streams W3C specification defines a set of new JavaScript APIs that enable the application to request audio and video streams from the platform, as well as a set of APIs to manipulate and process the acquired media streams. The MediaStream object (Figure 18-2) is the primary interface that enables all of this functionality.
A MediaStream object represents a real-time media stream and allows the application code to acquire data, manipulate individual tracks, and specify outputs. All the audio and video processing, such as noise cancellation, equalization, image enhancement, and more are automatically handled by the audio and video engines.
However, the features of the acquired media stream are constrained by the capabilities of the input source: a microphone can emit only an audio stream, and some webcams can produce higher-resolution video streams than others. As a result, when requesting media streams in the browser, the getUserMedia() API allows us to specify a list of mandatory and optional constraints to match the needs of the application:
<video autoplay></video>
This example illustrates one of the more elaborate scenarios: we are requesting audio and video tracks, and we are specifying both the minimum resolution and type of camera that must be used, as well as a list of optional constraints for 720p HD video! The getUserMedia() API is responsible for requesting access to the microphone and camera from the user, and acquiring the streams that match the specified constraints—that’s the whirlwind tour.
The provided APIs also enable the application to manipulate individual tracks, clone them, modify constraints, and more. Further, once the stream is acquired, we can feed it into a variety of other browser APIs:
To make a long story short, getUserMedia() is a simple API to acquire audio and video streams from the underlying platform. The media is automatically optimized, encoded, and decoded by the WebRTC audio and video engines and is then routed to one or more outputs. With that, we are halfway to building a real-time teleconferencing application—we just need to route the data to a peer!
For a full list of capabilities of the Media Capture and Streams APIs, head to the official W3C standard.
Real-time communication is time-sensitive; that should come as no surprise. As a result, audio and video streaming applications are designed to tolerate intermittent packet loss: the audio and video codecs can fill in small data gaps, often with minimal impact on the output quality. Similarly, applications must implement their own logic to recover from lost or delayed packets carrying other types of application data. Timeliness and low latency can be more important than reliability.
Audio and video streaming in particular have to adapt to the unique properties of our brains. Turns out we are very good at filling in the gaps but highly sensitive to latency delays. Add some variable delays into an audio stream, and “it just won’t feel right,” but drop a few samples in between, and most of us won’t even notice!
The requirement for timeliness over reliability is the primary reason why the UDP protocol is a preferred transport for delivery of real-time data. TCP delivers a reliable, ordered stream of data: if an intermediate packet is lost, then TCP buffers all the packets after it, waits for a retransmission, and then delivers the stream in order to the application. By comparison, UDP offers the following “non-services”:
Before we go any further, you may want to revisit Chapter 3 and in particular the section Null Protocol Services, for a refresher on the inner workings (or lack thereof) of UDP.
UDP offers no promises on reliability or order of the data, and delivers each packet to the application the moment it arrives. In effect, it is a thin wrapper around the best-effort delivery model offered by the IP layer of our network stacks.
WebRTC uses UDP at the transport layer: latency and timeliness are critical. With that, we can just fire off our audio, video, and application UDP packets, and we are good to go, right? Well, not quite. We also need mechanisms to traverse the many layers of NATs and firewalls, negotiate the parameters for each stream, provide encryption of user data, implement congestion and flow control, and more!
UDP is the foundation for real-time communication in the browser, but to meet all the requirements of WebRTC, the browser also needs a large supporting cast (Figure 18-3) of protocols and services above it.
ICE: Interactive Connectivity Establishment (RFC 5245)
ICE, STUN, and TURN are necessary to establish and maintain a peer-to-peer connection over UDP. DTLS is used to secure all data transfers between peers; encryption is a mandatory feature of WebRTC. Finally, SCTP and SRTP are the application protocols used to multiplex the different streams, provide congestion and flow control, and provide partially reliable delivery and other additional services on top of UDP.
Yes, that is a complicated stack, and not surprisingly, before we can talk about the end-to-end performance, we need to understand how each works under the hood. It will be a whirlwind tour, but that’s our focus for the remainder of the chapter. Let’s dive in.
We didn’t forget about SDP! As we will see, SDP is a data format used to negotiate the parameters of the peer-to-peer connection. However, the SDP “offer” and “answer” are communicated out of band, which is why SDP is missing from the protocol diagram.
Despite the many protocols involved in setting up and maintaining a peer-to-peer connection, the application API exposed by the browser is relatively simple. The RTCPeerConnection interface (Figure 18-4) is responsible for managing the full life cycle of each peer-to-peer connection.
In short, RTCPeerConnection encapsulates all the connection setup, management, and state within a single interface. However, before we dive into the details of each configuration option of the RTCPeerConnection API, we need to understand signaling and negotiation, the offer-answer workflow, and ICE traversal. Let’s take it step by step.
Initiating a peer-to-peer connection requires (much) more work than opening an XHR, EventSource, or a new WebSocket session: the latter three rely on a well-defined HTTP handshake mechanism to negotiate the parameters of the connection, and all three implicitly assume that the destination server is reachable by the client—i.e., the server has a publicly routable IP address or the client and server are located on the same internal network.
By contrast, it is likely that the two WebRTC peers are within their own, distinct private networks and behind one or more layers of NATs. As a result, neither peer is directly reachable by the other. To initiate a session, we must first gather the possible IP and port candidates for each peer, traverse the NATs, and then run the connectivity checks to find the ones that work, and even then, there are no guarantees that we will succeed.
Refer to UDP and Network Address Translators and NAT Traversal for an in-depth discussion of the challenges posed by NATs for UDP and peer-to-peer communication in particular.
However, while NAT traversal is an issue we must deal with, we may have gotten ahead of ourselves already. When we open an HTTP connection to a server, there is an implicit assumption that the server is listening for our handshake; it may wish to decline it, but it is nonetheless always listening for new connections. Unfortunately, the same can’t be said about a remote peer: the peer may be offline or unreachable, busy, or simply not interested in initiating a connection with the other party.
As a result, in order to establish a successful peer-to-peer connection, we must first solve several additional problems:
The good news is that WebRTC solves one of the problems on our behalf: the built-in ICE protocol performs the necessary routing and connectivity checks. However, the delivery of notifications (signaling) and initial session negotiation is left to the application.
Before any connectivity checks or session negotiation can occur, we must find out if the other peer is reachable and if it is willing to establish the connection. We must extend an offer, and the peer must return an answer (Figure 18-5). However, now we have a dilemma: if the other peer is not listening for incoming packets, how do we notify it of our intent? At a minimum, we need a shared signaling channel.
WebRTC defers the choice of signaling transport and protocol to the application; the standard intentionally does not provide any recommendations or implementation for the signaling stack. Why? This allows interoperability with a variety of other signaling protocols powering existing communications infrastructure, such as the following:
A “signaling channel” can be as simple as a shout across the room—that is, if your intended peer is within shouting distance! The choice of the signaling medium and the protocol is left to the application.
A WebRTC application can choose to use any of the existing signaling protocols and gateways (Figure 18-6) to negotiate a call or a video conference with an existing communication system—e.g., initiate a “telephone” call with a PSTN client! Alternatively, it can choose to implement its own signaling service with a custom protocol.
The signaling server can act as a gateway to an existing communications network, in which case it is the responsibility of the network to notify the target peer of a connection offer and then route the answer back to the WebRTC client initiating the exchange. Alternatively, the application can also use its own custom signaling channel, which may consist of one or more servers and a custom protocol to communicate the messages: if both peers are connected to the same signaling service, then the service can shuttle messages between them.
Assuming the application implements a shared signaling channel, we can now perform the first steps required to initiate a WebRTC connection:
var signalingChannel = new SignalingChannel();
Initialize the shared signaling channel
Initialize the RTCPeerConnection object
Request audio stream from the browser
Register local audio stream with RTCPeerConnection object
Create SDP (offer) description of the peer connection
Apply generated SDP as local description of peer connection
Send generated SDP offer to remote peer via signaling channel
We will be using unprefixed APIs in our examples, as they are defined by the W3C standard. Until the browser implementations are finalized, you may need to adjust the code for your favorite browser.
WebRTC uses Session Description Protocol (SDP) to describe the parameters of the peer-to-peer connection. SDP does not deliver any media itself; instead it is used to describe the “session profile,” which represents a list of properties of the connection: types of media to be exchanged (audio, video, and application data), network transports, used codecs and their settings, bandwidth information, and other metadata.
In the preceding example, once a local audio stream is registered with the RTCPeerConnection object, we call createOffer() to generate the SDP description of the intended session. What does the generated SDP contain? Let’s take a look:
(... snip ...) m=audio 1 RTP/SAVPF 111 ...
SDP is a simple text-based protocol (RFC 4568) for describing the properties of the intended session; in the previous case, it provides a description of the acquired audio stream. The good news is, WebRTC applications do not have to deal with SDP directly. The JavaScript Session Establishment Protocol (JSEP) abstracts all the inner workings of SDP behind a few simple method calls on the RTCPeerConnection object.
Once the offer is generated, it can be sent to the remote peer via the signaling channel. Once again, how the SDP is encoded is up to the application: the SDP string can be transferred directly as shown earlier (as a simple text blob), or it can be encoded in any other format—e.g., the Jingle protocol provides a mapping from SDP to XMPP (XML) stanzas.
To establish a peer-to-peer connection, both peers must follow a symmetric workflow (Figure 18-7) to exchange SDP descriptions of their respective audio, video, and other data streams.
With that, once the SDP session descriptions have been exchanged via the signaling channel, both parties have now negotiated the type of streams to be exchanged, and their settings. We are almost ready to begin our peer-to-peer communication! Now, there is just one more detail to take care of: connectivity checks and NAT traversal.
In order to establish a peer-to-peer connection, by definition, the peers must be able to route packets to each other. A trivial statement on the surface, but hard to achieve in practice due to the numerous layers of firewalls and NAT devices between most peers; see UDP and Network Address Translators.
First, let’s consider the trivial case, where both peers are located on the same internal network, and there are no firewalls or NATs between them. To establish the connection, each peer can simply query its operating system for its IP address (or multiple, if there are multiple network interfaces), append the provided IP and port tuples to the generated SDP strings, and forward it to the other peer. Once the SDP exchange is complete, both peers can initiate a direct peer-to-peer connection.
The earlier “SDP example” illustrates the preceding scenario: the a=candidate line lists a private (192.168.x.x) IP address for the peer initiating the session; see Reserved Private Network Ranges.
So far, so good. However, what would happen if one or both of the peers were on distinct private networks? We could repeat the preceding workflow, discover and embed the private IP addresses of each peer, but the peer-to-peer connections would obviously fail! What we need is a public routing path between the peers. Thankfully, the WebRTC framework manages most of this complexity on our behalf:
Once a session description (local or remote) is set, local ICE agent automatically begins the process of discovering all the possible candidate IP, port tuples for the local peer:
If you have ever had to answer the “What is my public IP address?” question, then you’ve effectively performed a manual “STUN lookup.” The STUN protocol allows the browser to learn if it’s behind a NAT and to discover its public IP and port; see STUN, TURN, and ICE.
Whenever a new candidate (an IP, port tuple) is discovered, the agent automatically registers it with the RTCPeerConnection object and notifies the application via a callback function (onicecandidate). Once the ICE gathering is complete, the same callback is fired to notify the application. Let’s extend our earlier example to work with ICE:
var ice = {"iceServers": [
{"url": "stun:stun.l.google.com:19302"},
{"url": "turn:turnserver.com", "username": "user", "credential": "pass"}
]};
var signalingChannel = new SignalingChannel();
var pc = new RTCPeerConnection(ice);
navigator.getUserMedia({ "audio": true }, gotStream, logError);
function gotStream(stream) {
pc.addStream(stream);
pc.createOffer(function(offer) {
pc.setLocalDescription(offer);
});
}
pc.onicecandidate = function(evt) {
if (evt.target.iceGatheringState == "complete") {
local.createOffer(function(offer) {
console.log("Offer with ICE candidates: " + offer.sdp);
signalingChannel.send(offer.sdp);
});
}
}
...
// Offer with ICE candidates:
// a=candidate:1862263974 1 udp 2113937151 192.168.1.73 60834 typ host ...
// a=candidate:2565840242 1 udp 1845501695 50.76.44.100 60834 typ srflx ...
STUN server, configured to use Google’s public test server
TURN server for relaying data if peer-to-peer connection fails
Apply local session description: initiates ICE gathering process
Subscribe to ICE events and listen for ICE gathering completion
Regenerate the SDP offer (now with discovered ICE candidates)
Private ICE candidate (192.168.1.73:60834) for the peer
Public ICE candidate (50.76.44.100:69834) returned by the STUN server
The previous example uses Google’s public demo STUN server. Unfortunately, STUN alone may not be sufficient (see STUN and TURN in Practice), and you may also need to provide a TURN server to guarantee connectivity for peers that cannot establish a direct peer-to-peer connection (~8% of users).
As the example illustrates, the ICE agent handles most of the complexity on our behalf: the ICE gathering process is triggered automatically, STUN lookups are performed in the background, and the discovered candidates are registered with the RTCPeerConnection object. Once the process is complete, we can generate the SDP offer and use the signaling channel to deliver it to the other peer.
Then, once the ICE candidates are received by the other peer, we are ready to begin the second phase of establishing a peer-to-peer connection: once the remote session description is set on the RTCPeerConnection object, which now contains a list of candidate IP and port tuples for the other peer, the ICE agent begins connectivity checks (Figure 18-8) to see if it can reach the other party.
The ICE agent sends a message (a STUN binding request), which the other peer must acknowledge with a successful STUN response. If this completes, then we finally have a routing path for a peer-to-peer connection! Conversely, if all candidates fail, then either the RTCPeerConnection is marked as failed, or the connection falls back to a TURN relay server to establish the connection.
The ICE agent automatically ranks and prioritizes the order in which the candidate connection checks are performed: local IP addresses are checked first, then public, and TURN is used as a last resort. Once a connection is established, the ICE agent continues to issue periodic STUN requests to the other peer. This serves as a connection keepalive.
Phew! As we said at the beginning of this section, initiating a peer-to-peer connection requires (much) more work than opening an XHR, EventSource, or a new WebSocket session. The good news is, most of this work is done on our behalf by the browser. However, for performance reasons, it is important to keep in mind that the process may incur multiple roundtrips between the STUN servers and between the individual peers before we can begin transmitting data—that is, assuming ICE negotiation is successful.
The ICE gathering process is anything but instantaneous: retrieving local IP addresses is fast, but querying the STUN server requires a roundtrip to the external server, followed by another round of STUN connectivity checks between the individual peers. Trickle ICE is an extension to the ICE protocol that allows incremental gathering and connectivity checks between the peers. The core idea is very simple:
In short, instead of waiting for the ICE gathering process to complete, we rely on the signaling channel to deliver incremental updates to the other peer, which helps accelerate the process. The WebRTC implementation is also fairly simple:
var ice = {"iceServers": [
{"url": "stun:stun.l.google.com:19302"},
{"url": "turn:turnserver.com", "username": "user", "credential": "pass"}
]};
var pc = new RTCPeerConnection(ice);
navigator.getUserMedia({ "audio": true }, gotStream, logError);
function gotStream(stream) {
pc.addStream(stream);
pc.createOffer(function(offer) {
pc.setLocalDescription(offer);
signalingChannel.send(offer.sdp);
});
}
pc.onicecandidate = function(evt) {
if (evt.candidate) {
signalingChannel.send(evt.candidate);
}
}
signalingChannel.onmessage = function(msg) {
if (msg.candidate) {
pc.addIceCandidate(msg.candidate);
}
}
Trickle ICE generates more traffic over the signaling channel, but it can yield a significant improvement in the time required to initiate the peer-to-peer connection. For this reason, it is also the recommended strategy for all WebRTC applications: send the offer as soon as possible, and then trickle ICE candidates as they are discovered.
The built-in ICE framework manages candidate discovery, connectivity checks, keepalives, and more. If all works well, then all of this work is completely transparent to the application: the only thing we have to do is specify the STUN and TURN servers when initializing the RTCPeerConnection object. However, not all connections will succeed, and it is important to be able to isolate and resolve the problem. To do so, we can query the status of the ICE agent and subscribe to its notifications:
var ice = {"iceServers": [
{"url": "stun:stun.l.google.com:19302"},
{"url": "turn:turnserver.com", "username": "user", "credential": "pass"}
]};
var pc = new RTCPeerConnection(ice);
logStatus("ICE gathering state: " + pc.iceGatheringState);
pc.onicecandidate = function(evt) {
logStatus("ICE gathering state change: " + evt.target.iceGatheringState);
}
logStatus("ICE connection state: " + pc.iceConnectionState);
pc.oniceconnectionstatechange = function(evt) {
logStatus("ICE connection state change: " + evt.target.iceConnectionState);
}
The iceGatheringState attribute, as its name implies, reports the status of the candidate gathering process for the local peer. As a result, it can be in three different states:
|
|
The object was just created and no networking has occurred yet. |
|
|
The ICE agent is in the process of gathering local candidates. |
|
|
The ICE agent has completed the gathering process. |
On the other hand, the iceConnectionState attribute reports the status of the peer-to-peer connection (Figure 18-9), which can be in one of seven possible states:
new
checking
connected
completed
failed
disconnected
closed
A WebRTC session may require multiple streams for delivering audio, video, and application data. As a result, a successful connection is one that is able to establish connectivity for all the requested streams. Further, due to the unreliable nature of peer-to-peer connectivity, there are no guarantees that once the connection is established that it will stay that way: the connection may periodically flip between connected and disconnected states while the ICE agent attempts to find the best possible path to re-establish connectivity.
The first and primary goal for the ICE agent is to identify a viable routing path between the peers. However, it doesn’t stop there. Even once connected, the ICE agent may periodically try other candidates to see if it can deliver better performance via an alternate route.
Google Chrome provides a simple and very useful tool to investigate the entire workflow and state of any WebRTC connection: open a new tab and load chrome://webrtc-internals. There, you can inspect (Figure 18-10) all of the open peer-to-peer connections, inspect the exchanged SDP descriptions, and more.
Chrome will also report a number of statistics for each stream, such as available bandwidth, latency, bitrate of the encoded video and audio streams, and more. Even if you are not developing a WebRTC application, start a WebRTC session with a friend or between multiple browser windows, and head to chrome://webrtc-internals; it is an indispensable tool for familiarizing yourself with the internals of WebRTC.
We have covered a lot of ground: we’ve discussed signaling, the offer-answer workflow, session parameter negotiation with SDP, and took a deep dive into the inner workings of the ICE protocol required to establish a peer-to-peer connection. Finally, we now have all the necessary pieces to initiate a peer-to-peer connection over WebRTC.
We have been filling in all the necessary pieces bit by bit throughout the preceding pages, but now let’s take a look at a complete example for the peer responsible for initiating the WebRTC connection:
<video id="local_video" autoplay></video>
Video element for output of local stream
Video element for output of remote stream
Initialize shared signaling channel
Initialize peer connection object
Acquire local audio and video streams
Register local MediaStream with peer connection
Output local video stream to video element (self view)
Generate SDP offer describing peer connection and send to peer
Trickle ICE candidates to the peer via the signaling channel
Register remote ICE candidate to begin connectivity checks
Output remote video stream to video element (remote view)
The entire process can be a bit daunting on the first pass, but now that we understand how all the pieces work, it is fairly straightforward: initialize the peer connection and the signaling channel, acquire and register media streams, send the offer, trickle ICE candidates, and finally output the acquired media streams. A more complete implementation can also register additional callbacks to track ICE gathering and connection states and provide more feedback to the user.
The process to answer the request for a new WebRTC connection is very similar, with the only major difference being that most of the logic is executed when the signaling channel delivers the SDP offer. Let’s take a hands-on look:
<video id="local_video" autoplay></video>
<video id="remote_video" autoplay></video>
<script>
var signalingChannel = new SignalingChannel();
var pc = null;
var ice = {"iceServers": [
{"url": "stun:stunserver.com:12345"},
{"url": "turn:turnserver.com", "username": "user", "credential": "pass"}
]};
signalingChannel.onmessage = function(msg) {
if (msg.offer) {
pc = new RTCPeerConnection(ice);
pc.setRemoteDescription(msg.offer);
pc.onicecandidate = function(evt) {
if (evt.candidate) {
signalingChannel.send(evt.candidate);
}
}
pc.onaddstream = function (evt) {
var remote_video = document.getElementById('remote_video');
remote_video.src = window.URL.createObjectURL(evt.stream);
}
navigator.getUserMedia({ "audio": true, "video": true },
gotStream, logError);
} else if (msg.candidate) {
pc.addIceCandidate(msg.candidate);
}
}
function gotStream(evt) {
pc.addStream(evt.stream);
var local_video = document.getElementById('local_video');
local_video.src = window.URL.createObjectURL(evt.stream);
pc.createAnswer(function(answer) {
pc.setLocalDescription(answer);
signalingChannel.send(answer.sdp);
});
}
function logError() { ... }
</script>
Not surprisingly, the code looks very similar. The only major difference, aside from initiating the peer connection workflow based on an offer message delivered via the shared signaling channel, is that the preceding code is generating an SDP answer (via createAnswer) instead of an offer object. Otherwise, the process is symmetric: initialize the peer connection, acquire and register media streams, send the answer, trickle ICE candidates, and finally output the acquired media streams.
With that, we can copy the code, add an implementation for the signaling channel, and we have a real-time, peer-to-peer video and audio session videoconferencing application running in the browser—not bad for fewer than 100 lines of JavaScript code!
Establishing a peer-to-peer connection takes quite a bit of work. However, even once the clients complete the answer-offer workflow and each client performs its NAT traversals and STUN connectivity checks, we are still only halfway up our WebRTC protocol stack (Figure 18-3). At this point, both peers have raw UDP connections open to each other, which provides a no-frills datagram transport, but as we know that is not sufficient on its own; see Optimizing for UDP.
Without flow control, congestion control, error checking, and some mechanism for bandwidth and latency estimation, we can easily overwhelm the network, which would lead to degraded performance for both peers and those around them. Further, UDP transfers data in the clear, whereas WebRTC requires that we encrypt all communication! To address this, WebRTC layers several additional protocols on top of UDP to fill in the gaps:
WebRTC specification requires that all transferred data—audio, video, and custom application payloads—must be encrypted while in transit. The Transport Layer Security protocol would, of course, be a perfect fit, except that it cannot be used over UDP, as it relies on reliable and in-order delivery offered by TCP. Instead, WebRTC uses DTLS, which provides equivalent security guarantees.
DTLS is deliberately designed to be as similar to TLS as possible. In fact, DTLS is TLS, but with a minimal number of modifications to make it compatible with datagram transport offered by UDP. Specifically, DTLS addresses the following problems:
Refer to TLS Handshake and TLS Record Protocol for a full discussion on the handshake sequence and layout of the record protocol.
There are no simple workarounds for fixing the TLS handshake sequence: each record serves a purpose, each must be sent in the exact order required by the handshake algorithm, and some records may easily span multiple packets. As a result, DTLS implements a “mini-TCP” (Figure 18-11) just for the handshake sequence.
DTLS extends the base TLS record protocol by adding an explicit fragment offset and sequence number for each handshake record. This addresses the in-order delivery requirement and allows large records to be fragmented across packets and reassembled by the other peer. DTLS handshake records are transmitted in the exact order specified by the TLS protocol; any other order is an error. Finally, DTLS must also deal with packet loss: both sides use simple timers to retransmit handshake records if the reply is not received within an expected interval.
The combination of the record sequence number, offset, and retransmission timer allows DTLS to perform the handshake (Figure 18-12) over UDP. To complete this sequence, both network peers generate self-signed certificates and then follow the regular TLS handshake protocol.
The DTLS handshake requires two roundtrips to complete—an important aspect to keep in mind, as it adds extra latency to setup of the peer-to-peer connection.
The WebRTC client automatically generates self-signed certificates for each peer. As a result, there is no certificate chain to verify. DTLS provides encryption and integrity, but defers authentication to the application; see Encryption, Authentication, and Integrity. Finally, with the handshake requirements satisfied, DTLS adds two important rules to account for possible fragmentation and out-of-order processing of regular records:
A regular TLS record can be up to 16 KB in size. TCP handles the fragmentation and reassembly, but UDP provides no such services. As a result, to preserve the out-of-order and best-effort semantics of the UDP protocol, each DTLS record carrying application data must fit into a single UDP packet. Similarly, stream ciphers are disallowed because they implicitly rely on in-order delivery of record data.
WebRTC provides media acquisition and delivery as a fully managed service: from camera to the network, and from network to the screen. The WebRTC application specifies the media constraints to acquire the streams and then registers them with the RTCPeerConnection object (Figure 18-13). From there, the rest is handled by the WebRTC media and network engines provided by the browser: encoding optimization, dealing with packet loss, network jitter, error recovery, flow, control, and more.
The implication of this architecture is that beyond specifying the initial constraints of the acquired media streams (e.g., 720p vs. 360p video), the application does not have any direct control over how the video is optimized or delivered to the other peer. This design choice is intentional: delivering a high-quality, real-time audio and video stream over an unreliable transport with fluctuating bandwidth and packet latency is a nontrivial problem. The browser solves it for us:
The WebRTC network engine cannot guarantee that an HD video stream provided by the application will be delivered at its highest quality: there may be insufficient bandwidth between the peers or high packet loss. Instead, the engine will attempt to adapt the provided stream to match the current conditions of the network.
An audio or video stream may be delivered at a lower quality than that of the original stream acquired by the application. However, the inverse is not true: WebRTC will not upgrade the quality of the stream. If the application provides a 360p video constraint, then that serves as a cap on the amount of bandwidth that will be used.
How does WebRTC optimize and adapt the quality of each media stream? Turns out WebRTC is not the first application to run up against the challenge of implementing real-time audio and video delivery over IP networks. As a result, WebRTC is reusing existing transport protocols used by VoIP phones, communication gateways, and numerous commercial and open source communication services:
Real-Time Transport Protocol (RTP) is defined by RFC 3550. However, WebRTC requires that all communication must be encrypted while in transit. As a result, WebRTC uses the “secure profile” (RFC 3711) of RTP—hence the S in SRTP and SRTCP.
SRTP defines a standard packet format (Figure 18-14) for delivering audio and video over IP networks. By itself, SRTP does not provide any mechanism or guarantees on timeliness, reliability, or error recovery of the transferred data. Instead, it simply wraps the digitized audio samples and video frames with additional metadata to assist the receiver in processing each stream.
The SRTP packet provides all the essential information required by the media engine for real-time playback of the stream. However, the responsibility to control how the individual SRTP packets are delivered falls to the SRTCP protocol, which implements a separate, out-of-band feedback channel for each media stream.
SRTCP tracks the number of sent and lost bytes and packets, last received sequence number, inter-arrival jitter for each SRTP packet, and other SRTP statistics. Then, periodically, both peers exchange this data and use it to adjust the sending rate, encoding quality, and other parameters of each stream.
In short, SRTP and SRTCP run directly over UDP and work together to adapt and optimize the real-time delivery of the audio and video streams provided by the application. The WebRTC application is never exposed to the internals of SRTP or SRTCP protocols: if you are building a custom WebRTC client, then you will have to deal with these protocols directly, but otherwise, the browser implements all the necessary infrastructure on your behalf.
Curious to see SRTCP statistics for your WebRTC session? Check the latency, bitrate, and bandwidth reports in Chrome; see Inspecting WebRTC Connection Status with Google Chrome.
In addition to transferring audio and video data, WebRTC allows peer-to-peer transfers of arbitrary application data via the DataChannel API. The SRTP protocol we covered in the previous section is specifically designed for media transfers and unfortunately is not a suitable transport for application data. As a result, DataChannel relies on the Stream Control Transmission Protocol (SCTP), which runs on top (Figure 18-3) of the established DTLS tunnel between the peers.
However, before we dive into the SCTP protocol itself, let’s first examine the WebRTC requirements for the RTCDataChannel interface and its transport protocol:
Transport must support multiplexing of multiple independent channels.
Transport must provide a message-oriented API.
The good news is that the use of DTLS already satisfies the last criteria: all application data is encrypted within the payload of the record, and confidentiality and integrity are guaranteed. However, the remaining requirements are a nontrivial set to satisfy! UDP provides unreliable, out-of-order datagram delivery, but we also need TCP-like reliable delivery, channel multiplexing, priority support, message fragmentation, and more. That’s where SCTP comes in.
| TCP | UDP | SCTP | |
Reliability | reliable | unreliable | configurable |
Delivery | ordered | unordered | configurable |
Transmission | byte-oriented | message-oriented | message-oriented |
Flow control | yes | no | yes |
Congestion control | yes | no | yes |
SCTP is a transport protocol, similar to TCP and UDP, which can run directly on top of the IP protocol. However, in the case of WebRTC, SCTP is tunneled over a secure DTLS tunnel, which itself runs on top of UDP.
SCTP provides the best features of TCP and UDP: message-oriented API, configurable reliability and delivery semantics, and built-in flow and congestion-control mechanisms. A full analysis of the protocol is outside the scope of our discussion, but, briefly, let’s introduce some SCTP concepts and terminology:
A single SCTP association between two endpoints may carry multiple independent streams, each of which communicates by transferring application messages. In turn, each message may be split into one or more chunks, which are delivered within SCTP packets (Figure 18-15) and then get reassembled at the other end.
Does this description sound familiar? It definitely should! The terms are different, but the core concepts are identical to those of the HTTP/2 framing layer; see Streams, Messages, and Frames. The difference here is that SCTP implements this functionality at a “lower layer,” which enables efficient transfer and multiplexing of arbitrary application data.
An SCTP packet consists of a common header and one or more control or data chunks. The header carries 12 bytes of data, which identify the source and destination ports, a randomly generated verification tag for the current SCTP association, and the checksum for the entire packet. Following the header, the packet carries one or more control or data chunks; the previous diagram is showing an SCTP packet with a single data chunk:
DataChannel uses the PPID field in the SCTP header to communicate the type of transferred data: 0×51 for UTF-8 and 0×52 for binary application payloads.
That’s a lot of detail to absorb in one go. Let’s review it once again, this time in the context of the earlier WebRTC and DataChannel API requirements:
B, E and TSN fields in the header: each chunk indicates its position (first, middle, or last), and the TSN value is used to order the middle chunks.
In total, SCTP adds 28 bytes of overhead to each data chunk: 12 bytes for the common header and 16 bytes for the data chunk header followed by the application payload.
How does an SCTP negotiate the starting parameters for the association? Each SCTP connection requires a handshake sequence similar to TCP! Similarly, SCTP also implements TCP-friendly flow and congestion control mechanisms: both protocols use the same initial congestion window size and implement similar logic to grow and reduce the congestion window once the connection enters the congestion-avoidance phase.
For a review on TCP handshake latencies, slow-start, and flow control, refer to Chapter 2. The SCTP handshake and congestion and flow-control algorithms used for WebRTC are different but serve the same purpose and have similar costs and performance implications.
We are getting close to satisfying all the WebRTC requirements, but unfortunately, even with all of that functionality, we are still short of a few required features:
In short, SCTP provides similar services as TCP, but because it is tunneled over UDP and is implemented by the WebRTC client, it offers a much more powerful API: in-order and out-of-order delivery, partial reliability, message-oriented API, and more. At the same time, SCTP is also subject to handshake latencies, slow-start, and flow and congestion control—all critical components to consider when thinking about performance of the DataChannel API.
DataChannel enables bidirectional exchange of arbitrary application data between peers—think WebSocket, but peer-to-peer, and with customizable delivery properties of the underlying transport. Once the RTCPeerConnection is established, connected peers can open one or more channels to exchange text or binary data:
function handleChannel(chan) {
chan.onerror = function(error) { ... }
chan.onclose = function() { ... }
chan.onopen = function(evt) {
chan.send("DataChannel connection established. Hello peer!")
}
chan.onmessage = function(msg) {
if(msg.data instanceof Blob) {
processBlob(msg.data);
} else {
processText(msg.data);
}
}
}
var signalingChannel = new SignalingChannel();
var pc = new RTCPeerConnection(iceConfig);
var dc = pc.createDataChannel("namedChannel", {reliable: false});
...
handleChannel(dc);
pc.ondatachannel = handleChannel;
The DataChannel API intentionally mirrors that of WebSocket: each established channel fires the same onerror, onclose, onopen, and onmessage callbacks, as well as exposes the same binaryType, bufferedAmount, and protocol fields on the channel.
However, because DataChannel is peer-to-peer and runs over a more flexible transport protocol, it also offers a number of additional features not available to WebSocket. The preceding code example highlights some of the most important differences:
ondatachannel callback is fired when a new DataChannel session is established.
Regardless of the type of transferred data—audio, video, or application data—the two participating peers must first complete the full offer/answer workflow, negotiate the used protocols and ports, and successfully complete their connectivity checks; see Establishing a Peer-to-Peer Connection.
In fact, as we now know, media transfers run over SRTP, whereas DataChannel uses the SCTP protocol. As a result, when the initiating peer first makes the connection offer, or when the answer is generated by the other peer, the two must specifically advertise the parameters for the SCTP association within the generated SDP strings:
(... snip ...) m=application 1 DTLS/SCTP 5000
As previously, the RTCPeerConnection object handles all the necessary generation of the SDP parameters as long as one of the peers registers a DataChannel prior to generating the SDP description of the session. In fact, the application can establish a data-only peer-to-peer connection by setting explicit constraints to disable audio and video transfers:
var signalingChannel = new SignalingChannel();
var pc = new RTCPeerConnection(iceConfig);
var dc = pc.createDataChannel("namedChannel", {reliable: false});
var mediaConstraints = {
mandatory: {
OfferToReceiveAudio: false,
OfferToReceiveVideo: false
}
};
pc.createOffer(function(offer) { ... }, null, mediaConstraints);
...
With the SCTP parameters negotiated between the peers, we are almost ready to begin exchanging application data. Notice that the SDP snippet we saw earlier doesn’t mention anything about the parameters of each DataChannel—e.g., protocol, reliability, or in-order or out-of-order flags. As a result, before any application data can be sent, the WebRTC client initiating the connection also sends a DATA_CHANNEL_OPEN message (Figure 18-16) which describes the type, reliability, used application protocol, and other parameters of the channel.
The DATA_CHANNEL_OPEN message is similar to the HEADERS frame in HTTP/2: it implicitly opens a new stream, and data frames can be sent immediately after it; see Initiating a New Stream. For more information on the DataChannel protocol, refer to http://tools.ietf.org/html/draft-jesup-rtcweb-data-protocol.
Once the channel parameters are communicated, both peers can begin exchanging application data. Under the hood, each established channel is delivered as an independent SCTP stream: the channels are multiplexed over the same SCTP association, which avoids head-of-line blocking between the different streams and allows for simultaneous delivery of multiple channels over the same SCTP association.
DataChannel also allows out-of-band negotiation of channel parameters. When calling the createDataChannel method, the application can set the negotiated parameter to true, which skips the automatic dispatch of the DATA_CHANNEL_OPEN message. However, when doing so, both peers also have to specify the same id parameter, which is otherwise automatically generated by the browser:
signalingChannel.send({
newchannel: true,
label: "negotiated channel",
options: {
negotiated: true,
id: 10,
reliable: true,
ordered: true,
protocol: "appProtocol-v3"
}
});
signalingChannel.onmessage = function(msg) {
if (msg.newchannel) {
dc = pc.createDataChannel(msg.label, msg.options);
}
}
In practice, there are no additional performance benefits to using out-of-band negotiation with few participating peers. Let the RTCPeerConnection object handle the negotiation for you. However, where this workflow can be useful is in cases with many participating peers, where the signaling server can generate the same description and simultaneously distribute it to all the participating parties.
DataChannel enables peer-to-peer transfers of arbitrary application data via a WebSocket-compatible API: this by itself is a unique and a powerful feature. However, DataChannel also offers a much more flexible transport, which allows us to customize the delivery semantics of each channel to match the requirements of the application and the type of data being transferred.
Configuring the channel to use in-order and reliable delivery is, of course, equivalent to TCP: the same delivery guarantees as a regular WebSocket connection. However, and this is where it starts to get really interesting, DataChannel also offers two different policies for configuring partial reliability of each channel:
Both strategies are implemented by the WebRTC client, which means that all the application has to do is decide on the appropriate delivery model and set the right parameters on the channel. There is no need to manage application timers or retransmission counters. Let’s take a closer look at our configuration options:
| Ordered | Reliable | Partial reliability policy | |
Ordered + reliable | yes | yes | n/a |
Unordered + reliable | no | yes | n/a |
Ordered + partially reliable (retransmit) | yes | partial | retransmission count |
Unordered + partially reliable (retransmit) | no | partial | retransmission count |
Ordered + partially reliable (timed) | yes | partial | timeout (ms) |
Unordered + partially reliable (timed) | no | partial | timeout (ms) |
Ordered and reliable delivery is self-explanatory: it’s TCP. On the other hand, unordered and reliable delivery is already much more interesting—it’s TCP, but without the head-of-line blocking problem; see Head-of-Line Blocking.
When configuring a partially reliable channel, it is important to keep in mind that the two retransmission strategies are mutually exclusive. The application can specify either a timeout or a retransmission count, but not both; doing so will raise an error. With that, let’s take a look at the JavaScript API for configuring the channel:
conf = {};
conf = { ordered: false };
conf = { ordered: true, maxRetransmits: customNum };
conf = { ordered: false, maxRetransmits: customNum };
conf = { ordered: true, maxRetransmitTime: customMs };
conf = { ordered: false, maxRetransmitTime: customMs };
conf = { ordered: false, maxRetransmits: 0 };
var signalingChannel = new SignalingChannel();
var pc = new RTCPeerConnection(iceConfig);
...
var dc = pc.createDataChannel("namedChannel", conf);
if (dc.reliable) {
...
} else {
...
}
Default to ordered and reliable delivery (TCP)
Reliable, unordered delivery
Ordered, partially reliable with custom retransmit count
Unordered, partially reliable with custom retransmit count
Ordered, partially reliable with custom retransmit timeout
Unordered, partially reliable with custom retransmit timeout
Unordered, unreliable delivery (UDP)
Initialize DataChannel with specified order and reliability configuration
Once a DataChannel is initialized, the application can access the maxRetransmits and maxRetransmitTime as read-only attributes. Also, as a convenience, the DataChannel provides a reliable attribute, which returns false if either of the partial-reliability strategies are used.
Each DataChannel can be configured with custom order and reliability parameters, and the peers can open multiple channels, all of which will be multiplexed over the same SCTP association. As a result, each channel is independent of the others, and the peers can use different channels for different types of data—e.g., reliable and in-order delivery for peer-to-peer chat and partially reliable and out-of-order delivery for transient or low-priority application updates.
The use of a partially reliable channel requires additional design consideration from the application. Specifically, the application must pay close attention to the message size: nothing is stopping the application from passing in a large message, which will be fragmented across multiple packets, but doing so will likely yield very poor results. To illustrate this in action, let’s assume the following scenario:
Two peers have negotiated an out-of-order, unreliable DataChannel.
WebRTC clients set the maximum transmission unit for an SCTP packet to 1,280 bytes, which is the minimum and recommended MTU for an IPv6 packet. But we must also account for the overhead of IP, UDP, DTLS, and SCTP protocols: 20–40 bytes, 8 bytes, 20–40 bytes, and 28 bytes, respectively. Let’s round this up to ~130 bytes of overhead, which leaves us with ~1,150 bytes of payload data per packet and a total of 107 packets to deliver the 120 KB application message.
So far so good, but the packet loss probability for each individual packet is 1%. As a result, if we fire off all 107 packets over the unreliable channel, we are now looking at a very high probability of losing at least one of them en route! What will happen in this case? Even if all but one of the packets make it, the entire message will be dropped.
To address this, an application has two strategies: it can add a retransmit strategy (based on count or timeout), and it can decrease the size of the transferred message. In fact, for best results, it should do both.
Packet-loss rates and latency between the peers are unpredictable and vary based on current network weather. As a result, there is no one single and optimal setting for the retransmit count or timeout values. To deliver the best results over an unreliable channel, keep the messages as small as possible.
Implementing a low-latency, peer-to-peer transport is a nontrivial engineering challenge: there are NAT traversals and connectivity checks, signaling, security, congestion control, and myriad other details to take care of. WebRTC handles all of the above and more, on our behalf, which is why it is arguably one of the most significant additions to the web platform since its inception. In fact, it’s not just the individual pieces offered by WebRTC, but the fact that all the components work together to deliver a simple and unified API for building peer-to-peer applications in the browser.
However, even with all the built-in services, designing efficient and high-performance peer-to-peer applications still requires a great amount of careful thought and planning: peer-to-peer does not mean high performance on its own. If anything, the increased variability in bandwidth and latency between the peers, and the high demands of media transfers, as well as the peculiarities of unreliable delivery, make it an even harder engineering challenge.
Peer-to-peer audio and video streaming are one of the central use cases for WebRTC: getUserMedia API enables the application to acquire the media streams, and the built-in audio and video engines handle the optimization, error recovery, and synchronization between streams. However, it is important to keep in mind that even with aggressive optimization and compression, audio and video delivery are still likely to be constrained by latency and bandwidth:
The good news is that the average bandwidth capacity is continuing to grow around the world: users are switching to broadband, and 3.5G+ and 4G adoption is ramping up. However, even with optimistic growth projections, while HD streaming is now becoming viable, it is not a guarantee! Similarly, latency is a perennial problem, especially for real-time delivery, and doubly so for mobile clients. 4G will definitely help, but 3G networks are not going away anytime soon either.
To complicate matters further, the connections offered by most ISPs and mobile carriers are not symmetric: most users have significantly higher downlink throughput than uplink throughput. In fact, 10-to-1 relationships are not uncommon—e.g., 10 Mbps down, 1 Mbps up.
The net result is that you should not be surprised to see a single, peer-to-peer audio and video stream saturate a significant amount of users’ bandwidth, especially for mobile clients. Thinking of providing a multiparty stream? You will likely need to do some careful planning for the amount of available bandwidth:
The good news is that the WebRTC audio and video engines work together with the underlying network transport to probe the available bandwidth and optimize delivery of the media streams. However, DataChannel transfers require additional application logic: the application must monitor the amount of buffered data and be ready to adjust as needed.
When acquiring the audio and video streams, make sure to set the video constraints to match the use case; see Acquiring Audio and Video with getUserMedia.
A single peer-to-peer connection with bidirectional HD media streams can easily use up a significant fraction of users’ bandwidth. As a result, multiparty applications should carefully consider the architecture (Figure 18-17) of how the individual streams are aggregated and distributed between the peers.
One-to-one connections are easy to manage and deploy: the peers talk directly to each other and no further optimization is required. However, extending the same strategy to an N-way call, where each peer is responsible for connecting to every other party (a mesh network) would result in connections for each peer, and a total of connections! If bandwidth is at a premium, as it often is due to the much lower uplink speeds, then this type of architecture will quickly saturate most users’ links with just a few participants.
While mesh networks are easy to set up, they are often inefficient for multiparty systems. To address this, an alternative strategy is to use a “star” topology instead, where the individual peers connect to a “supernode,” which is then responsible for distributing the streams to all connected parties. This way only one peer has to pay the cost of handling and distributing streams, and everyone else talks directly to the supernode.
A supernode can be another peer, or it can be a dedicated service specifically optimized for processing and distributing real-time data; which strategy is more appropriate depends on the context and the application. In the simplest case, the initiator can act as a supernode—simple, and it might just work. A better strategy might be to pick the peer with the best available throughput, but that also requires additional “election” and signaling mechanisms.
The criteria and the process for picking the supernode is left up to the application, which by itself can be a big engineering challenge. WebRTC does not provide any infrastructure to assist in this process.
Finally, the supernode could be a dedicated and even a third-party service. WebRTC enables peer-to-peer communication, but this does not mean that there is no room for centralized infrastructure! Individual peers can establish peer connections with a proxy server and still get the benefit of both the WebRTC transport infrastructure and the additional services offered by the server.
Many existing videoconferencing solutions (e.g., Google’s Hangouts) rely on “proxy servers” to aggregate the individual media streams, composite them, and then distribute the optimized versions to all the connected parties. Delivering a single stream reduces the amount of bandwidth and the amount of CPU and GPU resources required by each peer; each client sees only one stream instead of !
Similarly, a game server can aggregate updates from all the players and filter and distribute only the necessary updates; e.g., it won’t send updates for players that are out of view or otherwise don’t affect the other player.
Two-party streaming is simple and efficient to deploy, whereas multiparty architectures require a lot more thought and planning. As much as WebRTC is about enabling direct peer-to-peer communication, it is also a catalyst for a wide variety of services, both commercial and open source, that will help make it more efficient and feature-rich.
In addition to planning and anticipating the bandwidth requirements of individual peer connections, every WebRTC application will require some centralized infrastructure for signaling, NAT and firewall traversal, identity verification, and other additional services offered by the application.
WebRTC defers all signaling to the application, which means that the application must at a minimum provide the ability to send and receive messages to the other peer. The volume of signaling data sent will vary by the number of users, the protocol, encoding of the data, and frequency of updates. Similarly the latency of the signaling service will have a great impact on the “call setup” time and other signaling exchanges.
Due to the prevalence of NATs and firewalls, most WebRTC applications will require a STUN server to perform the necessary IP lookups to establish the peer-to-peer connection. The good news is that the STUN server is used only for connection setup, but nonetheless, it must speak the STUN protocol and be provisioned to handle the necessary query load.
Even with STUN in place, 8%–10% of peer-to-peer connections will likely fail due to the peculiarities of their network policies. For example, a network administrator could block UDP outright for all the users on the network; see STUN and TURN in Practice. As a result, to deliver a reliable experience, the application may also need a TURN server to relay the data between the peers.
Multiparty services may require centralized infrastructure to help optimize the delivery of many streams and provide additional services as part of the RTC experience. In some ways, multiparty gateways serve the same role as TURN but in this case for different reasons. Having said that, unlike TURN servers, which act as simple packet proxies, a “smart proxy” may require significantly more CPU and GPU resources to process each individual stream prior to forwarding the final output to each connected party.
WebRTC audio and video engines will dynamically adjust the bitrate of the media streams to match the conditions of the network link between the peers. The application can set and update the media constraints (e.g., video resolution, framerate, and so on), and the engines do the rest—this part is easy.
Unfortunately, the same can’t be said for DataChannel, which is designed to transport arbitrary application data. Similar to WebSocket, the DataChannel API will accept binary and UTF-8–encoded application data, but it does not apply any further processing to reduce the size of transferred data: it is the responsibility of the WebRTC application to optimize the binary payloads and compress the UTF-8 content.
Further, unlike WebSocket, which runs on top of a reliable and in-order transport, WebRTC applications must account for both the extra overhead incurred by the UDP, DTLS, and SCTP protocols and the peculiarities of data delivery over a partially reliable transport; see Partially Reliable Delivery and Message Size.
Peer-to-peer architectures pose their own unique set of performance challenges for the application. Direct, one-to-one communication is relatively straightforward, but things get much more complex when more than two parties are involved, at least as far as performance is concerned. A short list of criteria to put on the agenda:
The animal on the cover of High Performance Browser Networking is a Madagascar harrier (Circus macrosceles). The harrier is primarily found on the Comoro Islands and Madagascar, though due to various threats, including habitat loss and degradation, populations are declining. Recently found to be rarer than previously thought, this bird’s broad distribution occurs at low densities with a total population estimated in the range of 250–500 mature individuals.
Associated with the wetlands of Madagascar, the harrier’s favored hunting grounds are primarily vegetation-lined lakes, marshes, coastal wetlands, and rice paddies. The harrier hunts small invertebrates and insects, including small birds, snakes, lizards, rodents, and domestic chickens. Its appetite for domestic chickens (accounting for only 1% of the species’ prey) is cause for persecution of the species by the local people.
During the dry season—late August and September—the harrier begins its mating season. By the start of the rainy season, incubation (~32–34 days) has passed and nestlings fledge at around 42–45 days. However, the harrier reproduction rates remain low, averaging at 0.9 young fledged per breeding attempt and a success rate of three-quarter of nests. This poor nesting success—owing partly to egg-hunting and nest destruction by local people—can also be attributed to regular and comprehensive burning of grasslands and marshes for the purposes of fresh grazing and land clearing, which often coincides with the species’ breeding season. Populations continue to dwindle as interests conflict: the harrier requiring undisturbed and unaltered savannah, and increasing human land-use activities in many areas of Madagascar.
Several conservation actions proposed include performing further surveys to confirm the size of the total population; studying the population’s dynamics; obtaining more accurate information regarding nesting success; reducing burning at key sites, especially during breeding season; and identifying and establishing protected areas of key nesting sites.
The cover image is from Histoire Naturelle, Ornithologie, Bernard Direxit. The cover font is Adobe ITC Garamond. The text font is Adobe Minion Pro; the heading font is Adobe Myriad Condensed; and the code font is Dalton Maag’s Ubuntu Mono.
| Revision History | |
| 2013-09-09 | First release |
| Revision History | |
| 2014-05-23 | Second release |
| 2015-09-16 | Third release |
Copyright © 2013 Ilya Grigorik
O’Reilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://safaribooksonline.com). For more information, contact our corporate/institutional sales department: 800-998-9938 or corporate@oreilly.com.
Nutshell Handbook, the Nutshell Handbook logo, and the O’Reilly logo are registered trademarks of O’Reilly Media, Inc. High-Performance Browser Networking, the image of a Madagascar harrier, and related trade dress are trademarks of O’Reilly Media, Inc.
Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and O’Reilly Media, Inc., was aware of a trademark claim, the designations have been printed in caps or initial caps.
1005 Gravenstein Highway North
Sebastopol, CA 95472